< 누락 데이터 처리 >
머신러닝 등 데이터 분석의 정확도는 분석 데이터의 품질에 의해 좌우된다. 데이터 품질을 높이기 위해서는 누락 데이터, 중복 데이터 등 오류를 수정하고 분석 목적에 맞게 변형하는 과정이 필요하다. 수집한 데이터를 분석에 적합하도록 사전 처리(Preprocessing)하는 방법을 살펴보자.
데이터프레임에는 원소 데이터 값이 종종 누락되는 경우가 있다. 데이터를 파일로 입력할 때 빠트리거나 파일 형식을 변환하는 과정에서 데이터가 소실되는 것이 주요 원인이다. 일반적으로 유효한 데이터 값이 존재하지 않는 누락 데이터를 NaN(Not a Number)으로 표시한다.
머신러닝 분석 모형에 데이터를 입력하기 전에 반드시 누락 데이터를 제거하거나 다른 적절한 값으로 대체하는 과정이 필요하다. 누락 데이터가 많아지면 데이터의 품질이 떨어지고, 머신러닝 분석 알고리즘을 왜곡하는 현상이 발생하기 때문이다.
1. 누락 데이터 확인하는 법 info() value_counts(dropna=False) notnull() isnull().sum()
- info( )
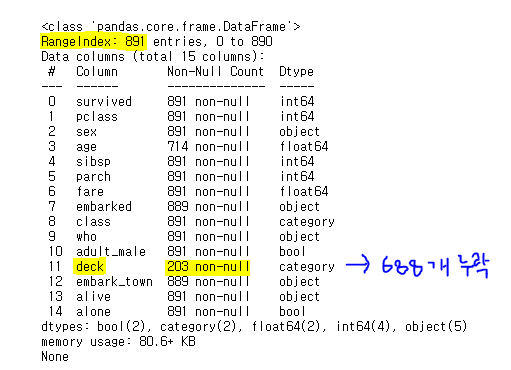
: info() 메소드로 데이터프레임의 요약 정보를 출력하면 각 열에 속하는 데이터 중에서 유효한(non-null, 즉 NaN 값이 아닌)값의 개수를 보여준다.
-
value_counts(dropna=False)
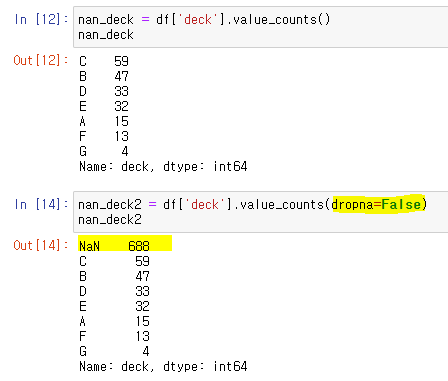
: value_counts() 메소드로 누락 데이터의 개수를 알 수 있다. 단, 누락 데이터의 개수를 확인하려면 반드시 dropna=False 옵션을 사용해야한다. 그렇지 않으면 NaN 값을 제외하고 유효한 데이터의 개수만 보여준다.
-
notnull( )
<-> insull()
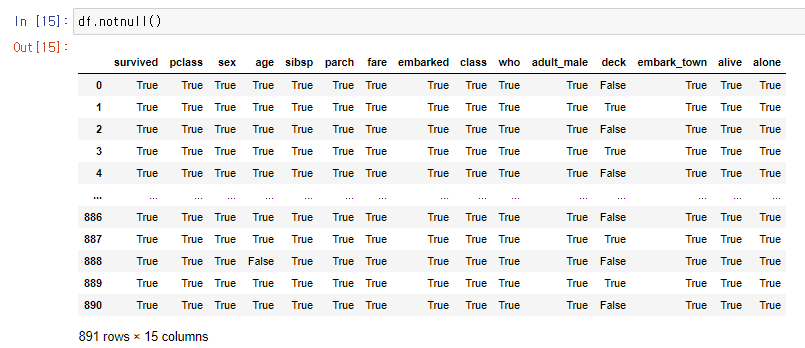
: notnull() 메소드는 유효한 값이 있을 경우 True를 반환하고 누락 데이터가 있는 경우 False를 반환한다. ( isnull()은 반대이다. )
-
isnull().sum()
: 누락데이터 개수구하기1) 총 누락데이터
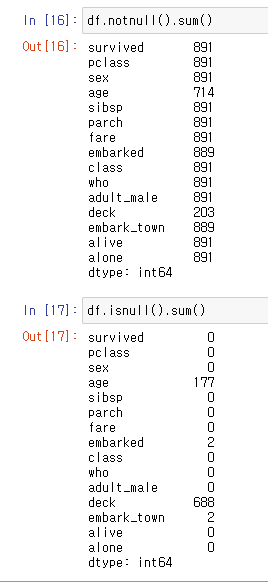
2) 5열 누락데이터 & axis=0
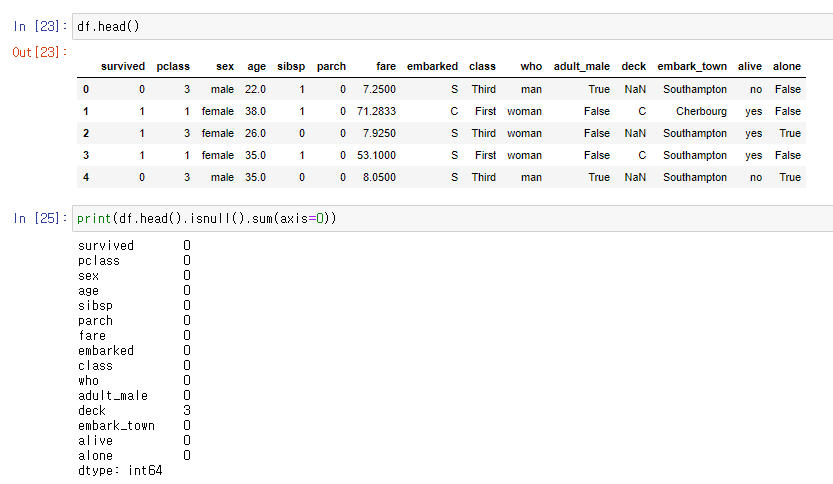
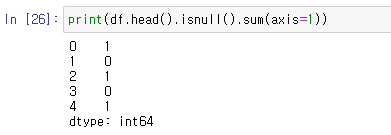
3) 5열 누락데이터 & axis=1
2. 누락데이터 제거하기 .dropna( )
열을 삭제하면 분석 대상이 갖는 특성(변수)를 제거하고, 행을 삭제하면 분석 대상의 관측값(레코드)을 제거하게 된다.
전체 891명 중 699명의 deck 데이터가 누락되어 있다. 누락데이터가 차지하는 비율이 높기 때문에 'deck' 열의 누락 데이터를 삭제하여 분석에서 제외하는 것이 의미가 있다.
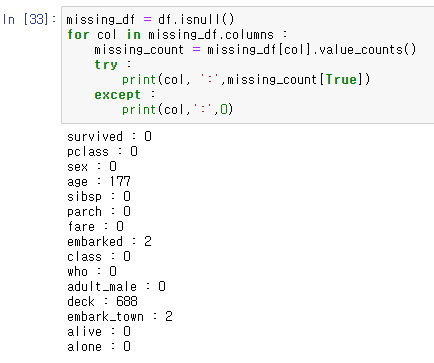
메소드
- .dropna(axis=0, thresh=500)
NaN의 개수가 500개 이상인 열만 제거
axis=0 (열 제거) axis=1 (행 제거)

- .dropna(subset=[''], how='', axis=)
< 옵션 >
subset['열이름'] : ['열이름'] 열의 행 중에서 NaN값이 있는 모든 행(axis=0) 삭제
how='any'(NaN 값이 하나라도 존재하면 삭제-기본값), 'all'(모든 데이터가 NaN값이 경우에만 삭제)177개 행을 삭제하고 나머지 714개의 행을 df_age에 저장한다

3. 누락데이터 치환하기 .fillna()
데이터셋의 품질을 높일 목적으로 누락 데이터를 무작정 삭제해 버린다면 어렵게 수집한 데이터를 활용하지 못하게 된다. 데이터 분석의 정확도는 데이터의 품질 외에도 제공되는 데이터의 양에 의해 상당한 영향을 받는다. 따라서 데이터 중에 일부가 누락되어 있더라도 나머지 데이터를 최대한 살려서 데이터 분석에 활용하는 것이 좋은 결과를 얻는 경우가 많다.
누락 데이터를 바꿔서 대체할 값으로는 데이터의 분포와 특성을 잘 나타낼 수 있는 평균값, 최빈값 등을 활용한다. 판다스 fillna() 메소드로 편리하게 처리할 수 있다.
-
.fillna( )
fillna() 메소드는 새로운 객체를 반환하기 때문에 원본 객체를 변경하려면 inplace=True 옵션을 추가해야한다.누락데이터 평균값으로 대체하기:
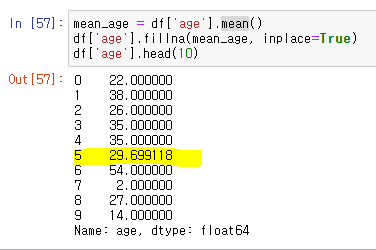
누락데이터 최빈값으로 대체하기:
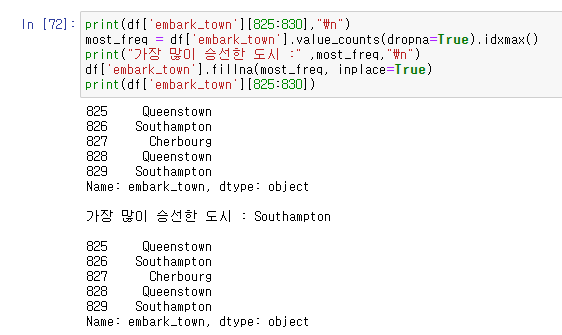
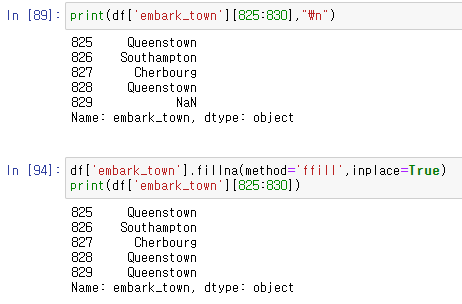
누락데이터 이웃값으로 치환해주기:
직전 행 : fillna(method='ffill') / 다음 행 : fillna(method='bfill')
< 중복데이터 처리하기 >
데이터프레임에서 각 행은 분석 대상이 갖고 있는 모든 속성(변수)에 대한 관측값(레코드)을 뜻한다. 하나의 데이터셋에서 동일한 관측값이 2개 이상 중복되는 경우 중복 데이터를 찾아서 삭제해야 한다. 동일한 대상이 중복으로 존재하는 것이므로 분석 결과를 왜곡하기 때문이다.
1. 중복 데이터 확인하는 법 duplicated()
메소드
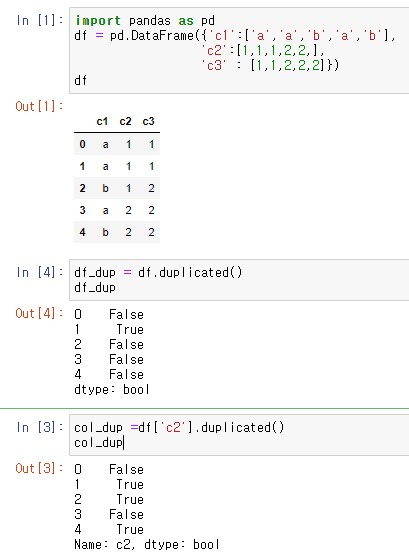
- duplicated( )
전에 나온 행들과 비교하여 중복되는 행이면 True를 반환하고, 처음 나오는 행이면 False를 반환한다. 데이터프레임의 열은 시리즈 객체이므로, duplicated() 메소드를 적용할 수 있다.
2. 중복 데이터 제거하기 drop_duplicates()
메소드
- drop_duplicates()
중복되는 행을 제거하고 고유한 관측값을 가진 행들만 남긴다. 원본 객체를 변경하려면 inplace=True 옵션을 추가한다.
df.drop_duplicates()
df.drop_duplicates(subset=['c2','c3'])
df['c2'].drop_duplicates()


< 데이터 표준화 >
실무에서 접하는 데이터셋은 다양한 사람들의 손을 거쳐 만들어진다. 여러 곳에서 수집한 자료들은 단위 선택, 대소문자 구분, 약칭 활용 등 여러가지 원인에 의해 다양한 형태로 표현된다. 잘 정리된 것으로 보이는 자료를 자세히 들여다보면, 서로 다른 단위가 섞여 있거나 같은 대상을 다른 형식으로 표현한 경우가 의외로 많다.
이처럼 동일한 대상을 표현하는 방법에 차이가 있으면, 분석의 정확도는 현저히 낮아진다. 따라서 데이터 포맷을 일관성 있게 표준화하는 작업이 필요하다.
1. 단위 환산 round()
측정 단위를 동일하게 맞출 필요가 있다. 흔히, 외국 데이터를 가져오면 국내에서 잘 사용하지 않는 도량형 단위를 사용하는 경우가 많다. 영미권에서 주로 사용하는 마일, 야드, 온스 등이 있는데, 한국에서 사용하는 미터, 평, 그램 등으로 변환하는 것이 좋다.
소숫점 반올림 : df[''].round(2) : 소숫점 둘째짜리 반올림
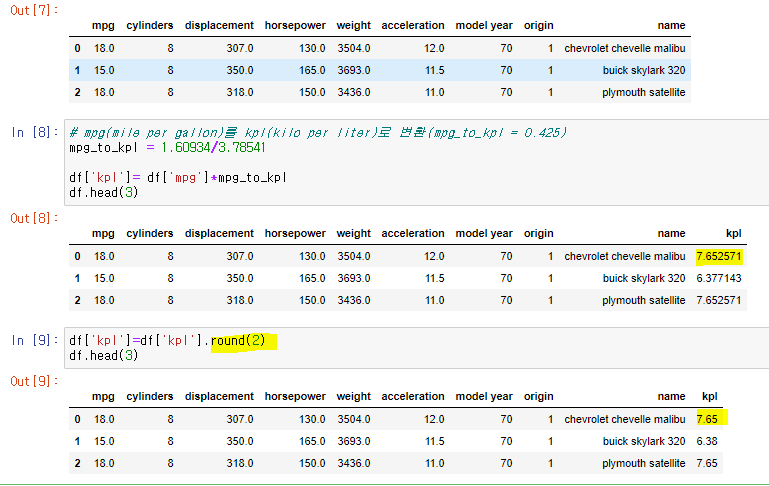
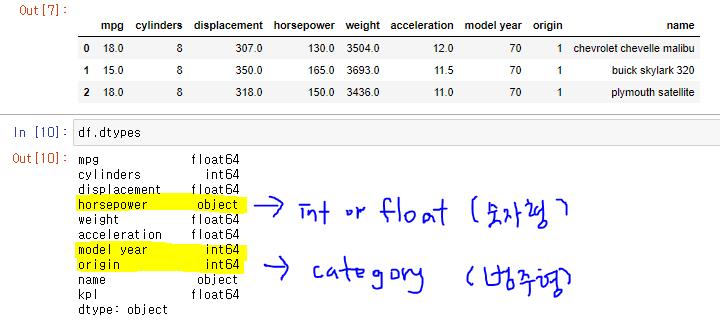
2. 자료형 변환 dtypes info() astype() replace() sample()
숫자가 문자열(object)로 저장된 경우에 숫자형(int 또는 float)으로 변환해야한다.
dtypes 속성 또는 info() 메소드로 자료형을 확인한다.
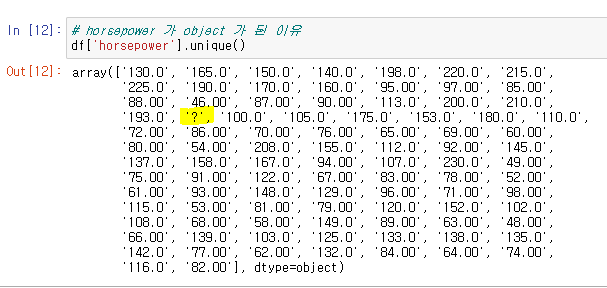
특정 열의 고유값 출력 : df[''].unique( )
중간에 문자열 '?'이 섞여있어 CSV 파일을 데이터프레임으로 변환하는 과정에서 문자열로 인식된 것으로 보인다.
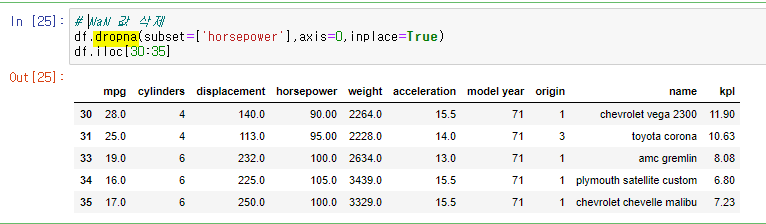
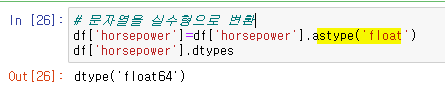
- 문자열 '?'를 NaN으로 변환 -> dropna() 메소드로 NaN값이 들어있는 모든 행을 삭제 -> astype('float') 명령을 이용해 문자열을 실수형으로 변환 -> dtypes 속성으로 변환된 결과 확인
누락 데이터가 NaN으로 표시되지 않은 경우 : 예를들면, 숫자 0이나 문자 '-','?' 같은 값으로 입력되기도 한다. 판다스에서 누락데이터를 다루려면 replace() 메소드를 활용하여 NumPy에서 지원하는 np.nan으로 변경해 주는 것이 좋다. 단, np.nan을 사용하기 위해서는 'import numpy as np'와 같이 NumPy 라이브러리를 먼저 임포트해야한다.
df.replace('?', np.nan, inplace=True)
df.replace({1:'A', 2:'B', 3:'C'}, inplace=True)

-
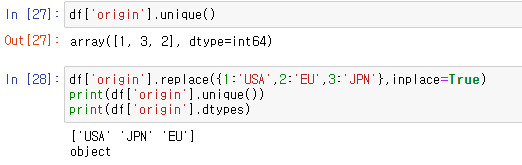
'origin'열에는 정수형 데이터 1,2,3이 들어있지만, 실제로는 국가이름인 'USA,EU,JPN'을 뜻한다. replace()메소드로 각 숫자 데이터를 국가이름으로 바꿔주면 문자열로 자동변경된다.
-
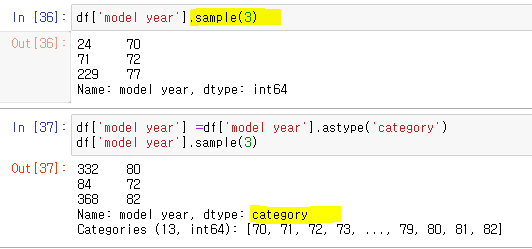
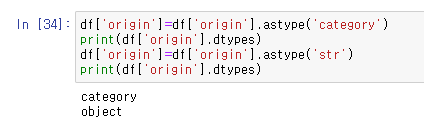
앞서 'origin'열의 국가이름은 문자열 데이터이다. 값을 확인해 보면 3개의 국가이름이 계속 반복된다. 이처럼 유한 개의 고유값이 반복적으로 나타나는 경우에는 범주형(category) 데이터로 표현하는 것이 효율적이다. astype('category')메소드를 이용하면 범주형 데이터로 변환한다. 범주형을 다시 문자열로 변환하려면 astype('str')메소드를 사용한다.
-
마지막으로 'model year'열의 자료형을 살펴보자. 'model year'은 연도를 뜻하기 때문에 숫자형으로 남겨둬도 무방하지만 연도는 시간적인 순서의 의미는 있으나 숫자의 상대적인 크기는 별 의미가 없다. 따라서 데이터는 숫자 형태를 갖더라도 자료형은 범주형으로 표현하는 것이 적절하다.