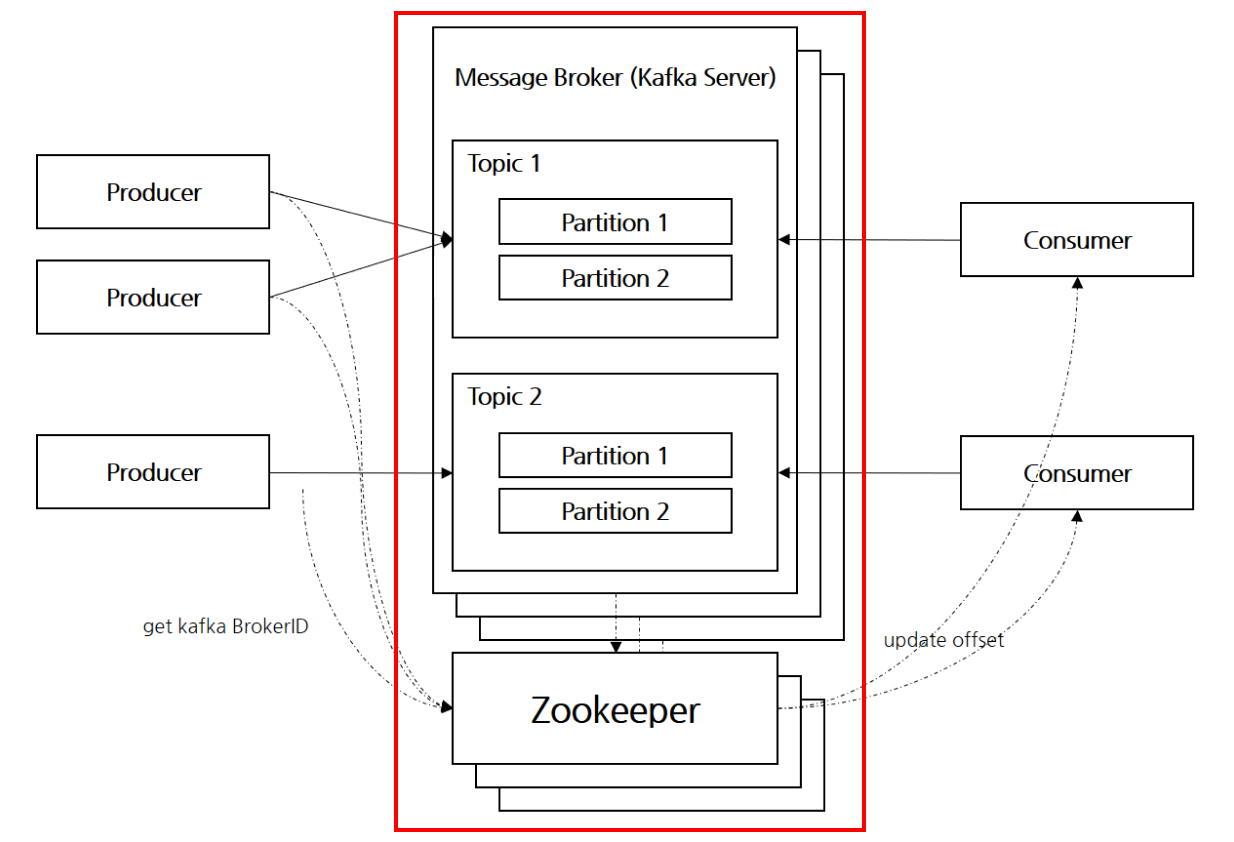
Broker & Zookeeper
-
Broker
카프카 서버 중 1대 / 여러 대로 구성하여 하나의 클러스터로 구성
Partition에 따라 리더(leader) 1개, 나머지 n-1개의 팔로워(follower)로 구분
리더의 데이터가 변경될 때 팔로워들에도 데이터가 동기화되기 때문에
리더 노드에 장애가 발생할 경우, 나머지 팔로워들 중 하나를 리더로 선정하여 동작
→ 가용성 유지 가능 -
Zookeeper
Zookeeper는 Kafka 클러스터를 관리하는 시스템
Broker목록, Topic과 Partition 의 구성, 리더 선출 정보와 같은 클러스터 메타데이터 관리
리더를 선출하는 것 또한 Zookeeper의 역할 → 리더 노드 장애 새로운 노드로 선출
Topic
-
Topic
Partition으로 구성된 일련의 로그 파일
Key와 Value 기반의 메시지 구조이며 , Value로 어떤 타입의 메시지도 가능
로그 파일과 같이 연속적으로 추가되는 발생하는 데이터를 저장하는 구조Partition은 Kafka의 병렬 성능과 가용성 기능의 핵심 요소
-
Partition
변경 할 수 없는 일련의 레코드로 구성된 로그 메시지
개별 레코드는 offset으로 불리는 일련 번호를 할당 받음
개별 파티션내에서 정렬되고 offset이 할당됨
파티션끼리는 독립적
-
Offset
각 Partition 마다 데이터가 저장되는 위치
Partition 마다 유니크 값 → Consumer 가 읽은 메시지의 위치를 추적 및 관리하는데 사용
Replication
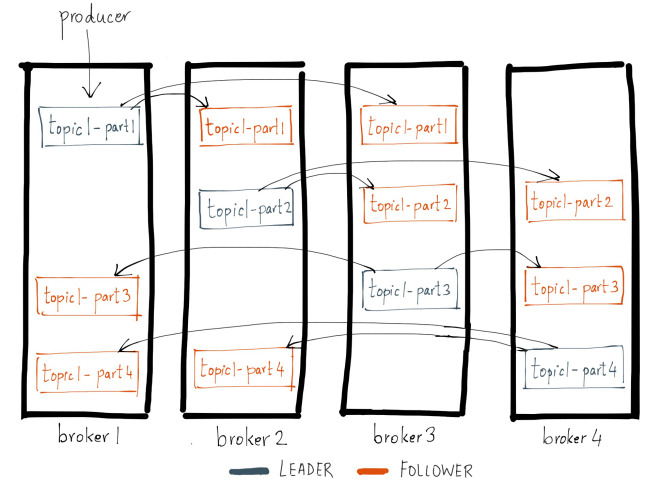
- Replication
메시지들을 여러 개로 복제해서 카프카 클러스터 내 브로커들에 분산시키는 동작
Broker에 문제가 생겨 작동이 중지 되면 해당 Broker내의 Partition의 데이터 접근 불가능
이러한 상황을 대비해 Broker의 해당 Partition을 다른 Broker에게 복사
원본 Partition을 가진 Broker는 그 Partition을 기준으로 Leader가 되고 나머지는 Follower
Replication의 갯수는 replication.factor로 설정 가능 단, Broker 개수보단 작거나 같아야함
위의 사진은 replication.factor = 3

25/08/12