kafka
1.Apache Kafka - 1

- Kafka? 실시간으로 기록 스트림을 게시, 구독, 저장 및 처리할 수 있는 분산형 데이터 스트리밍 플랫폼 Pub-Sub 모델의 메시지 큐 형태로 동작하며 분산환경에 특화 LinkedIn에서 사용중인 End-To-End 모델의 단점을 해결하고자 탄생
2.Apache Kafka - 2
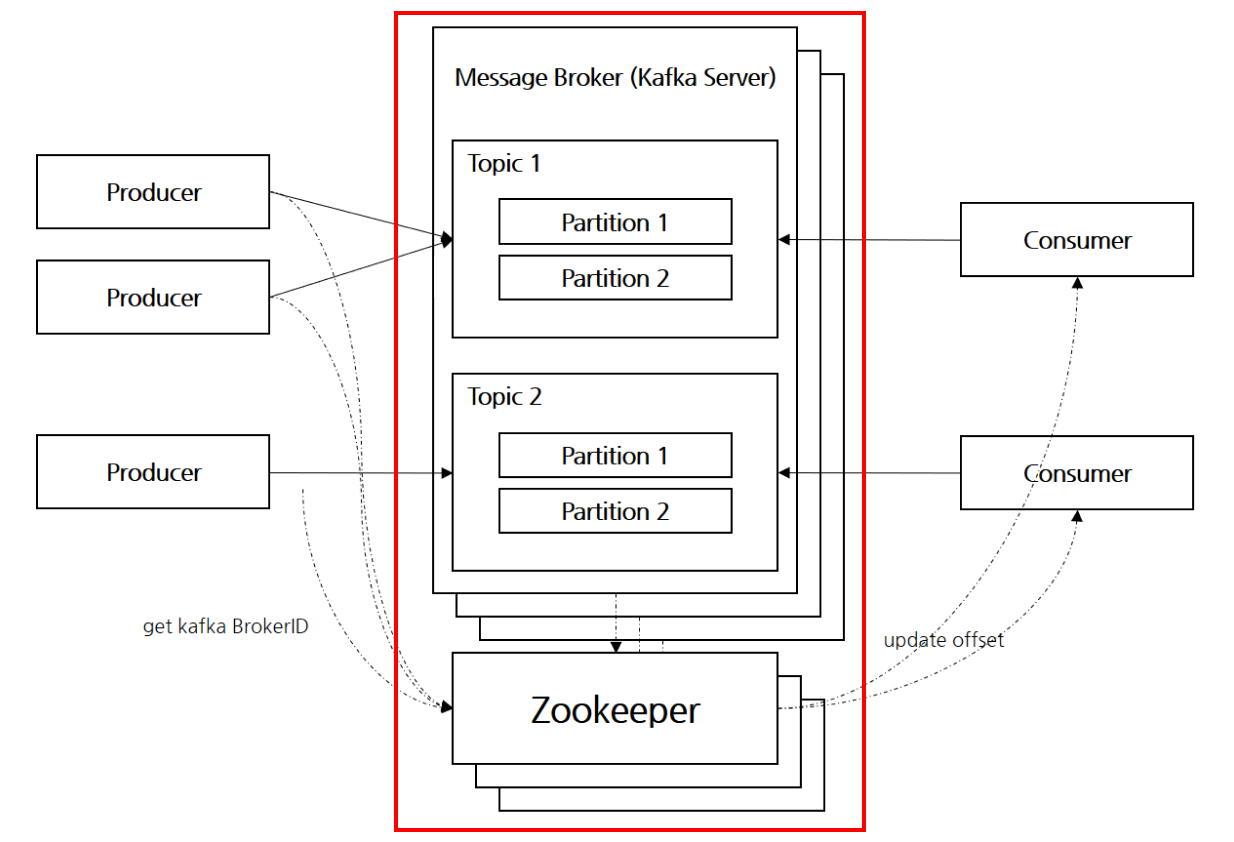
Broker카프카 서버 중 1대 / 여러 대로 구성하여 하나의 클러스터로 구성Partition에 따라 리더(leader) 1개, 나머지 n-1개의 팔로워(follower)로 구분리더의 데이터가 변경될 때 팔로워들에도 데이터가 동기화되기 때문에 리더 노드에 장애가 발생할
3.Apache Kafka - Producer 1
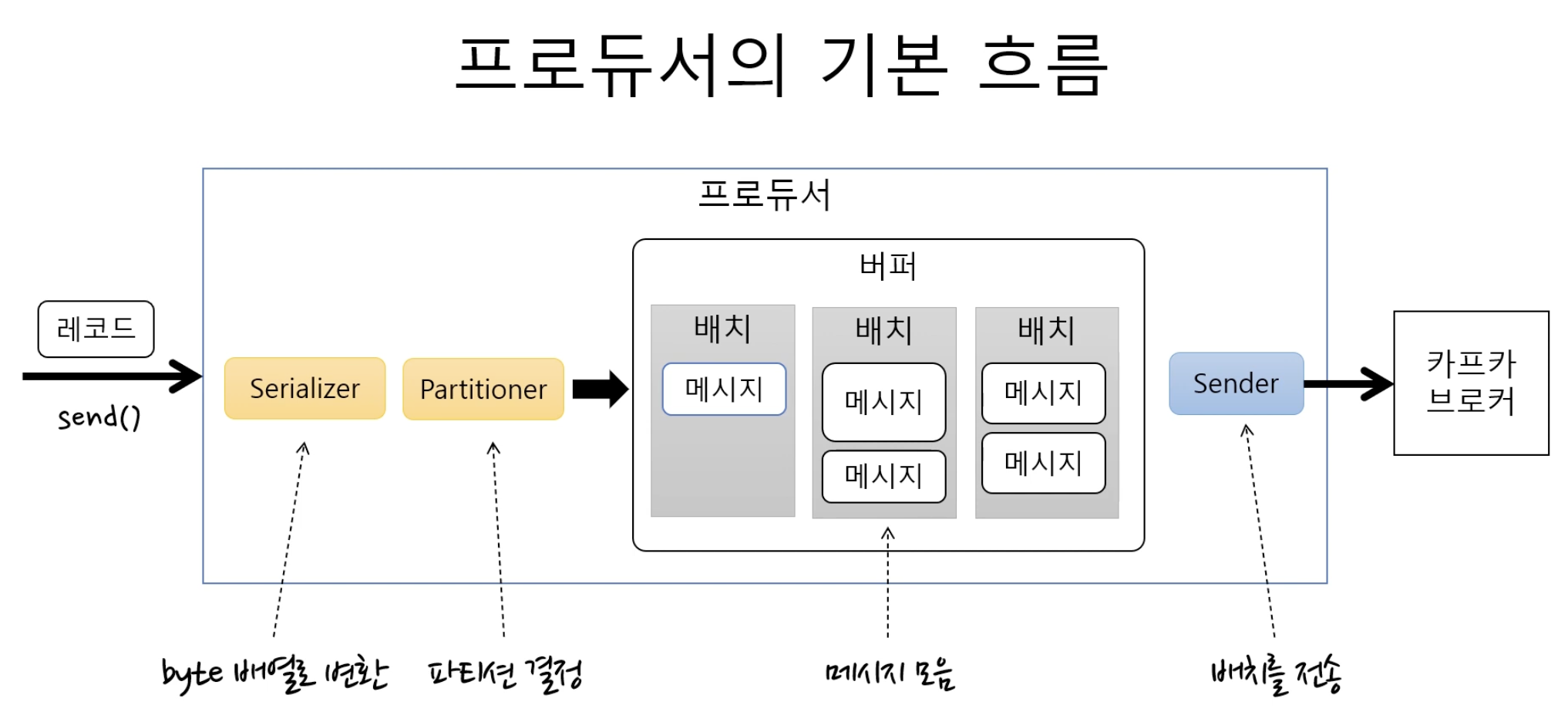
ProdcuerRecord에 담긴 정보에 따라 메시지를 보냄 (Topic,value 필수)어떤 브로커의 파티션으로 메시지를 보내야 할지 성능 가용성등을 고려하여 결정여러개의 Record로 구성된 Batch level로 메세지 전송이동, 저장, 복원을 자유롭게 하기 위해
4.Apache Kafka - Producer 2
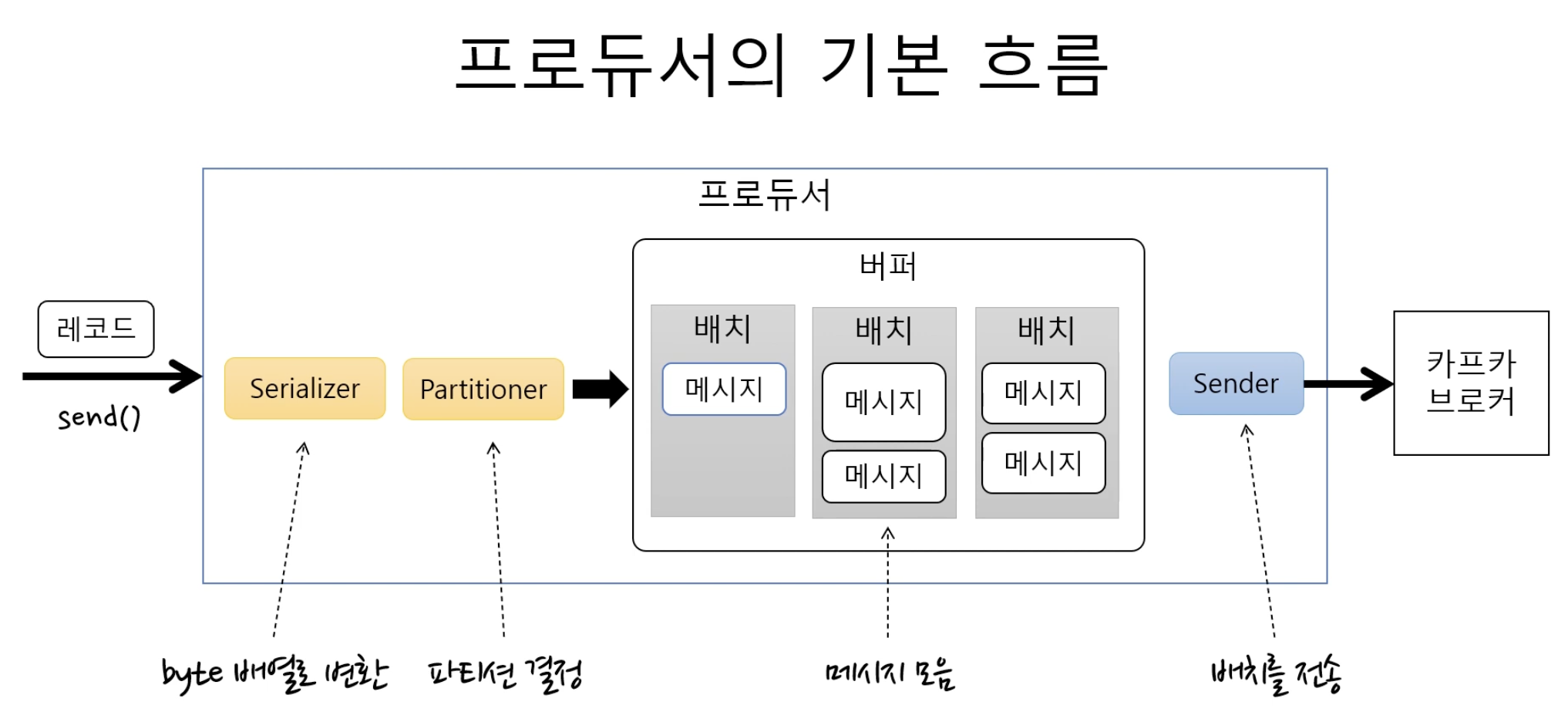
Serialize -> Partitioning -> Record Accumulator-> Sender Thread -> Brokersend() 하나의 ProducerRecord를 입력 -> 바로 전송 안됨내부 메모리에서 토픽파티션에 따라 Record Batch 단위
5.Kafka Consumer - 1
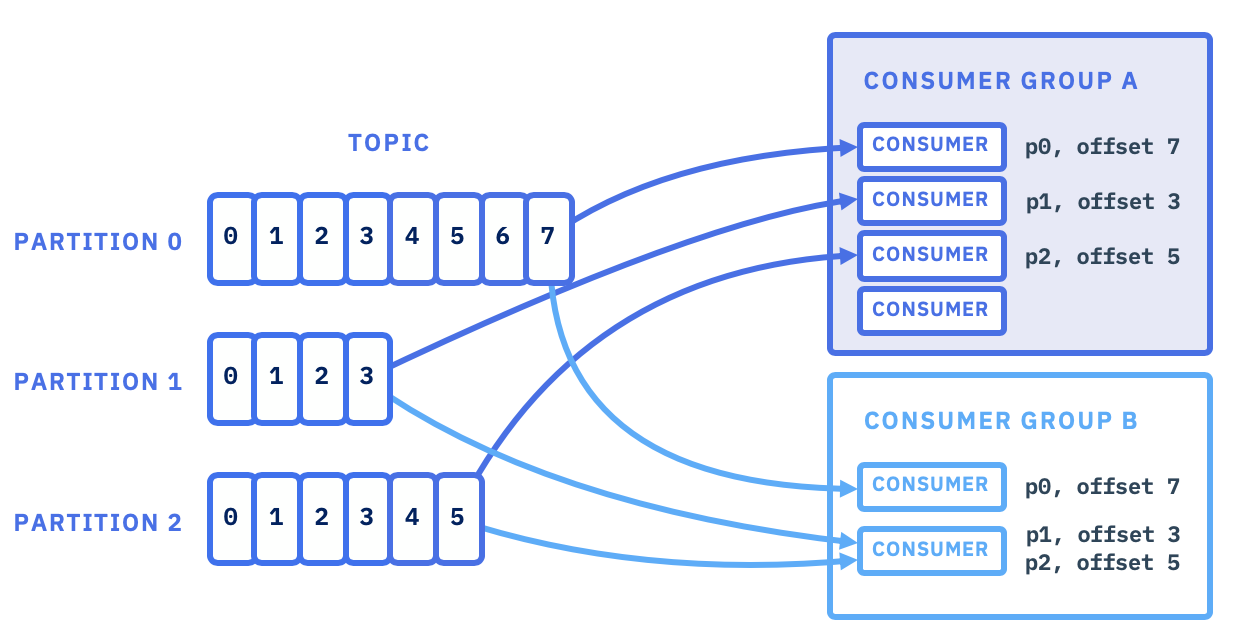
Kafka Consumer는 Kafka 메시징 시스템에서 데이터를 읽어들이는 중요한 역할을 담당해요.
6.Kafka Consumer - 2
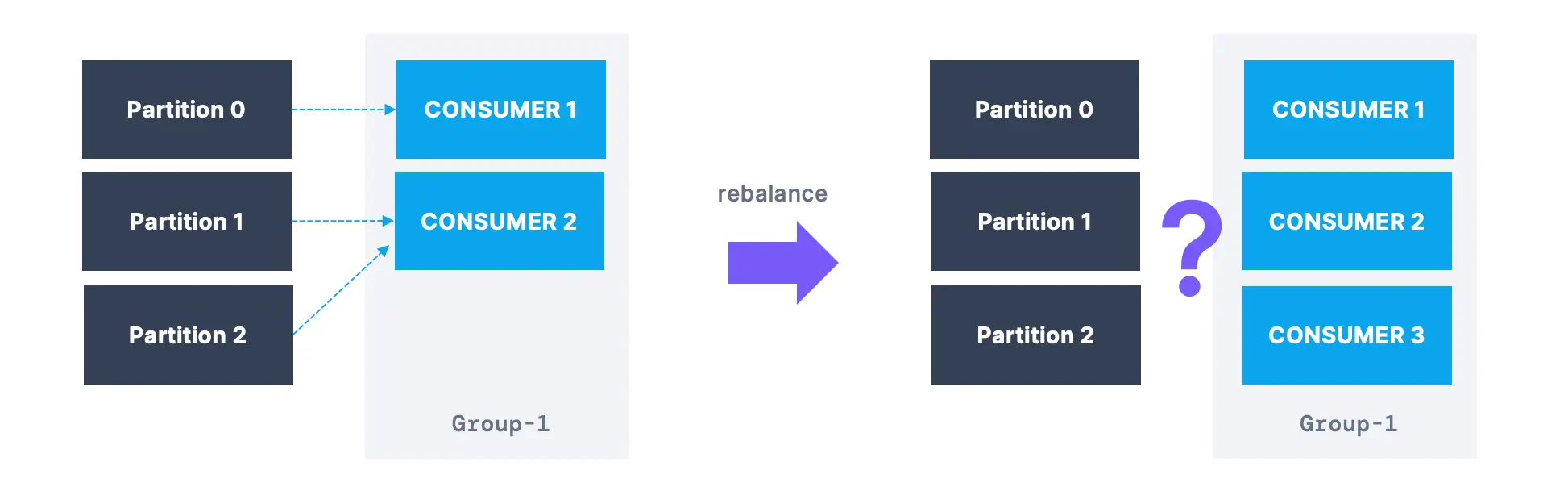
Kafka Consumer Rebalancing은 Kafka의 Consumer 그룹에서 새로운 Consumer가 추가되거나 기존 Consumer가 종료될 때, 또는 토픽에 새로운 파티션이 추가될 때 발생하는 중요한 과정이에요.
7.Kafka Multi Node
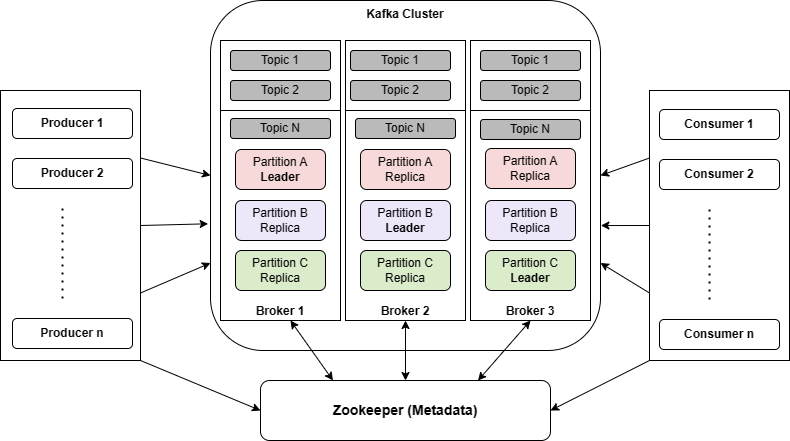
Kafka는 분산 시스템으로서 성능과 가용성을 향상시키기 위해 멀티 노드 클러스터 구성을 지원해요.
8.Log Segment
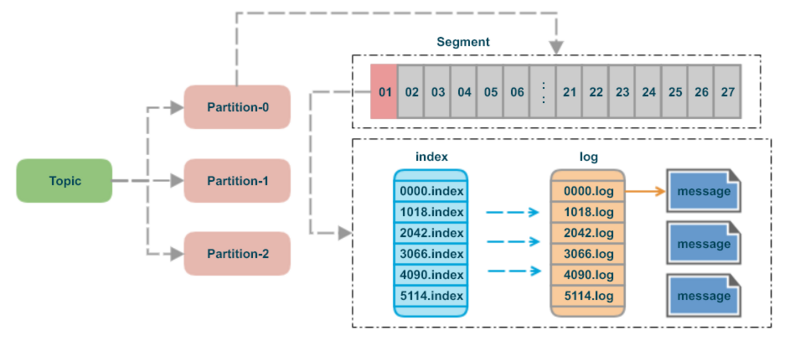
Kafka는 대량의 데이터를 효율적으로 저장하고 관리하기 위해 로그 세그먼트(Log Segment) 개념을 사용해요. 토픽(Topic)은 여러 개의 파티션(Partition)으로 나뉘고, 각 파티션은 내부적으로 여러 개의 로그 세그먼트로 구성돼요.
9.Compact Topic
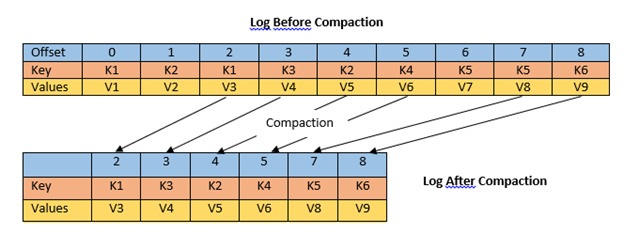
Kafka Topic은 데이터의 용량과 시간 조건을 기준으로 데이터를 삭제하는 방식이 기본이에요.
10.ksqlDB
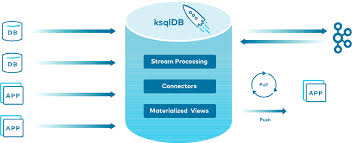
ksqlDB는 Kafka 위에서 동작하는 SQL 기반의 스트리밍 데이터베이스예요. Kafka의 데이터를 쉽게 처리하고 변환할 수 있도록 설계되어 있으며, 실시간 스트림 데이터를 활용한 애플리케이션을 구축하는 데 유용해요.