Kafka Consumer 개요
Kafka Consumer는 Kafka 메시징 시스템에서 데이터를 읽어들이는 중요한 역할을 담당해요. Consumer는 Broker에 저장된 Topic의 메시지를 읽어오는 작업을 주도하며, 여러 파티션으로 나뉜 데이터를 효율적으로 분배하고 처리할 수 있도록 해줘요. 이번 글에서는 Kafka Consumer가 어떻게 동작하는지, 그리고 그 동작을 제어하는 주요 설정과 개념들을 살펴볼게요.
1. Kafka Consumer 기본 개념
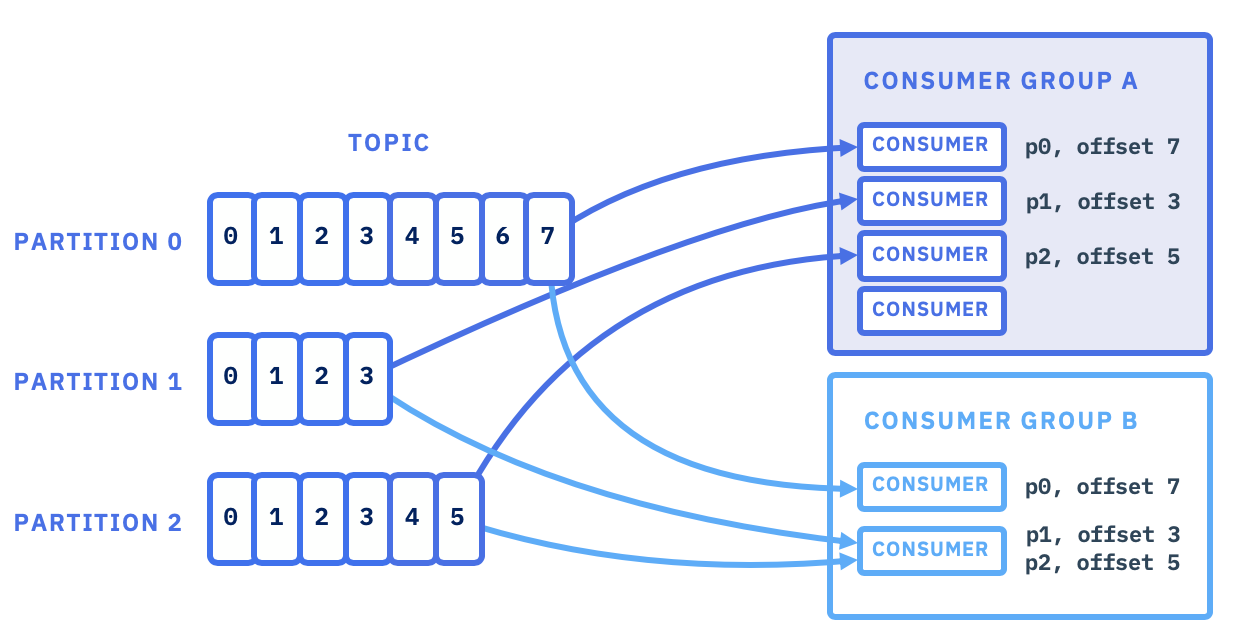
Kafka에서는 데이터가 Topic이라는 단위로 관리되며, Consumer는 Broker에서 해당 Topic에 쌓인 메시지를 읽어와 처리해요. 하지만 모든 Consumer는 Consumer Group이라는 그룹에 속해야 하고, 이 그룹 내에서 파티션을 분배받아 처리하는 방식으로 동작해요.
Consumer Group과 Partition 분배
-
Consumer Group: Consumer들이 속한 그룹으로, 각 Consumer는 그룹 내에서 특정 파티션을 나누어 읽어요. 같은 그룹에 속한 Consumer는 서로 다른 파티션을 할당받습니다.
-
Partition: Topic은 여러 파티션으로 나뉘고, 메시지들은 각 파티션에 저장됩니다.
Consumer Group 내에서는 각 Consumer가 하나의 파티션을 담당해 중복되지 않도록 메시지를 처리해요.
2. Kafka Consumer의 작동 방식
Kafka Consumer는 세 가지 주요 단계로 동작해요: subscribe, poll, commit.
1) Subscribe
Consumer는 subscribe() 메소드를 사용해 읽고 싶은 Topic을 구독해요.
구독된 Topic에 새로운 메시지가 쌓이면, Consumer는 그 메시지를 읽어들이기 시작해요.
consumer.subscribe(Collections.singletonList("topic_name"));2) Poll
poll() 메소드는 Consumer가 Broker로부터 주기적으로 메시지를 가져오는 역할을 해요.
이때 메시지가 있으면 바로 처리하고, 없으면 일정 시간 동안 기다린 후 처리합니다.
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> record : records) {
System.out.printf("key = %s, value = %s, offset = %d%n", record.key(), record.value(), record.offset());
}3) Commit
Consumer는 메시지를 성공적으로 처리한 후, commit()을 통해 처리한 메시지의 offset을 저장해요.
이렇게 하면 다음에 메시지를 읽을 때 어디서부터 시작해야 하는지 알 수 있어요.
3. Kafka Consumer의 내부 구성
Kafka Consumer는 Fetcher, ConsumerNetworkClient, 그리고 Heart Beat Thread 같은 여러 내부 구성 요소로 이루어져 있어요. 이 구성 요소들은 Consumer가 데이터를 효율적으로 가져오고, 정상적으로 동작하는지를 확인하는 역할을 해요.
-
Fetcher: 메시지를 가져오는 역할을 하며, Broker에서 데이터를 읽어와 Consumer에게 제공합니다.
-
ConsumerNetworkClient: 비동기 방식으로 Broker에서 데이터를 가져와 Linked Queue에 저장해요.
-
Heart Beat Thread: Consumer의 정상 동작을 모니터링하고, 문제 발생 시 Group Coordinator에 이를 보고해요.
4. Kafka Consumer의 처리 과정
- 설정 및 초기화: Consumer는 환경 설정을 통해 bootstrap.servers, group.id 등을 지정해 초기화됩니다.
- 구독: subscribe() 메소드를 통해 구독할 Topic을 설정해요.
- 메시지 가져오기: poll() 메소드를 통해 Broker에서 메시지를 지속적으로 가져와 처리합니다.
- 처리 후 종료: 처리 과정이 끝나면 close() 메소드를 호출해 Consumer를 종료해요.
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);
consumer.subscribe(Collections.singletonList("topic_name"));
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> record : records) {
System.out.printf("key = %s, value = %s, offset = %d%n", record.key(), record.value(), record.offset());
}
}
} finally {
consumer.close();
}5. Consumer의 주요 설정 파라미터
Kafka Consumer가 Broker에서 메시지를 가져오는 과정에서 여러 설정 파라미터가 Fetcher의 동작에 영향을 미칩니다. 특히 데이터를 가져오는 양과 대기 시간, 그리고 가져오는 데이터의 크기와 관련된 파라미터들이 중요해요.
fetch.min.bytes
Fetcher가 데이터를 가져올 때 최소한으로 가져와야 하는 바이트 수를 의미합니다. 기본값은 1바이트로 설정되어 있지만, 이 값을 높이면 Fetcher가 데이터를 모아서 한꺼번에 가져오게 돼요.
만약 Broker에서 fetch.min.bytes 이상의 데이터가 준비되지 않으면 Consumer는 데이터를 기다려요.
예를 들어, fetch.min.bytes를 16KB로 설정하면, Fetcher는 16KB 이상의 데이터를 받을 때까지 기다리게 돼요.
fetch.max.wait.ms
Broker가 fetch.min.bytes 이상의 데이터를 준비하는 데 필요한 최대 대기 시간입니다. 기본값은 500ms이에요.
Broker가 500ms 내에 충분한 데이터를 준비하지 못하면 그 시점에 가져올 수 있는 만큼 데이터를 가져옵니다. 즉, fetch.min.bytes만큼 데이터가 쌓이지 않아도 fetch.max.wait.ms 만큼 대기한 후에 데이터를 반환해요.
fetch.max.bytes
Fetcher가 한 번의 요청으로 가져올 수 있는 최대 데이터 양을 제한하는 설정입니다. 기본값은 50MB로, 한 번의 요청에서 너무 많은 데이터를 가져오는 것을 방지해요.
이를 통해 각 Consumer가 가져오는 데이터량을 조정하여 성능을 최적화할 수 있습니다.
max.partition.fetch.bytes
한 번에 각 파티션에서 가져올 수 있는 최대 데이터 양을 제한합니다. 기본적으로 1MB로 설정되어 있으며, Consumer는 각 파티션별로 이 값만큼 데이터를 가져옵니다.
여러 파티션에서 데이터를 읽을 때, 파티션별로 가져오는 데이터의 크기를 제한해 전체적인 성능을 관리할 수 있습니다.
max.poll.records
한 번의 poll() 호출에서 가져올 수 있는 최대 레코드 수를 의미합니다. 기본값은 500입니다.
이 설정은 한 번에 처리할 레코드 수를 제한하여 Consumer가 너무 많은 데이터를 한꺼번에 처리하지 않도록 방지합니다.
Consumer의 설정 파라미터 이해
1. 첫 번째 poll 호출 시
Consumer가 처음으로 poll() 메소드를 호출하면, Fetcher는 Linked Queue에서 데이터를 확인합니다. 만약 Queue에 데이터가 없으면 ConsumerNetworkClient를 통해 Broker에 메시지를 요청합니다.
2. 데이터 대기 및 반환
-
Fetcher는 fetch.min.bytes만큼 데이터를 모아서 가져오려 하지만, 만약 Broker에 충분한 데이터가 없다면 fetch.max.wait.ms 동안 대기합니다.
-
fetch.max.wait.ms 시간이 지나면 준비된 데이터를 가져옵니다. 즉, 대기 시간이 끝났을 때 fetch.min.bytes 만큼 데이터가 모이지 않았더라도 데이터를 반환합니다.
3.과거 데이터를 가져올 때
만약 Consumer가 과거의 오래된 데이터를 가져오는 경우, max.partition.fetch.bytes로 설정된 크기만큼 데이터를 한 번에 가져옵니다. 그렇지 않으면 가장 최신의 오프셋 데이터를 가져오게 됩니다.
4. 최신 오프셋 데이터를 가져올 때
만약 가장 최신의 오프셋 데이터를 가져오는 상황이라면, Fetcher는 fetch.min.bytes 만큼 데이터를 모아 가져오고, 충분한 데이터가 쌓이지 않으면 fetch.max.wait.ms 만큼 대기한 후 데이터를 반환합니다.
5. 파티션이 많은 경우
토픽에 파티션이 많더라도 한 번에 가져오는 데이터량은 fetch.max.bytes로 제한됩니다.
즉, 너무 많은 데이터를 한꺼번에 가져오는 것을 방지하여 Consumer의 메모리 사용을 관리할 수 있어요.
6. Linked Queue에 저장된 데이터 처리
Fetcher는 max.poll.records로 설정된 레코드 수만큼 데이터를 가져옵니다.
Consumer는 poll() 메소드를 호출하여 이 데이터를 가져와 처리합니다.
이 과정을 통해 Kafka Consumer는 데이터를 효율적으로 처리할 수 있으며, 각 설정 값을 조정하여 성능을 최적화할 수 있어요.
7. Consumer의 Offset 관리
Kafka Consumer는 메시지를 처리한 위치를 offset이라는 정보로 관리해요.
메시지를 처리한 후 commit을 통해 offset을 저장하고, 이를 기반으로 다음 번에 어디서부터 메시지를 읽을지 결정해요.
auto.offset.reset 설정을 통해 처음 메시지를 읽을 때 가장 오래된 메시지부터 읽을지(earliest), 아니면 가장 최신 메시지부터 읽을지(latest)를 설정할 수 있습니다.
마무리
Consumer가 메시지를 어떻게 가져오고 처리하는지, 그리고 Fetcher의 동작 방식이 Consumer의 성능에 어떤 영향을 미치는지 알아봤습니다.
다음 글에서는 Kafka의 Consumer Group Rebalance 와 HeartBeat에 대해 더 자세히 알아보도록 할게요!
