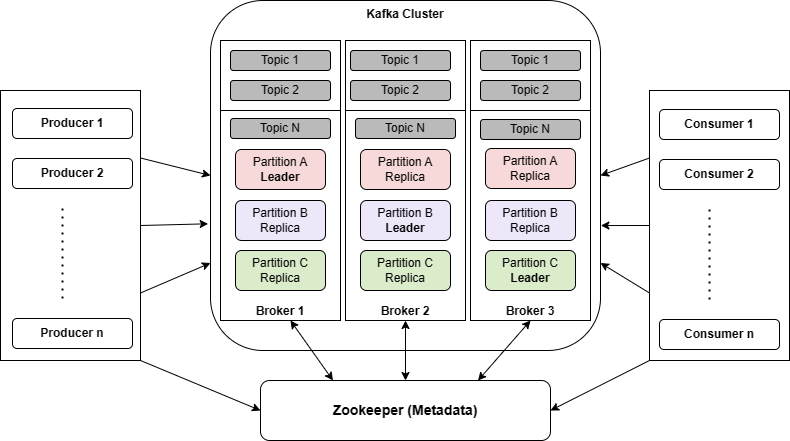
멀티 노드 카프카 클러스터와 데이터 복제
Kafka는 분산 시스템으로서 성능과 가용성을 향상시키기 위해 멀티 노드 클러스터 구성을 지원해요. 이를 통해 메시지 전송 및 읽기 성능을 거의 선형적으로 확장할 수 있고, 데이터 복제를 통해 높은 가용성을 보장해요.
멀티 노드 카프카 클러스터의 주요 특징, 분산 시스템 구성 요소, 리플리케이션 구조를 다뤄볼게요.
1. 멀티 노드 카프카 클러스터의 특징
Kafka는 멀티 노드 클러스터 구성을 통해 분산 시스템의 장점을 활용해요. 노드를 증설하여 시스템의 성능과 가용성을 거의 선형적으로 증가시킬 수 있으며, 장애 발생 시에도 데이터의 일관성과 안정성을 보장하도록 설계되어 있어요.
-
스케일 아웃 기반 확장성: 개별 노드 증설을 통해 데이터 전송 및 읽기 성능을 선형적으로 확장할 수 있어요.
-
데이터 복제: 데이터를 복제하여 높은 가용성을 보장해요. 데이터 복제 설정을 통해 각 노드의 장애에 대비하고 시스템의 안정성을 유지할 수 있어요.
2. 분산 시스템 구성을 위한 중요 요소
Kafka의 분산 시스템을 효과적으로 구성하기 위해 성능, 안정성, 가용성을 종합적으로 고려해야 해요. 분산 시스템은 대량 데이터를 여러 노드로 분산 처리하여 성능을 크게 향상시키지만, 관리 및 장애 복구 측면에서 도전 과제를 수반할 수 있어요.
-
성능: 여러 노드가 데이터를 병렬로 처리하므로 대용량 데이터 처리에 강점을 가지지만, 노드 간 데이터 일관성을 유지하기 위한 관리가 필요해요.
-
안정성: 다수의 노드를 통해 높은 성능을 보장하지만, 노드 중 일부가 장애를 겪으면 데이터 복제 구조를 통해 안정성을 유지해야 해요.
-
가용성: 노드 증설을 통한 확장과 함께 데이터 복제를 통해 시스템의 가용성을 극대화할 수 있어요.
3. 단일 노드 vs. 멀티 노드 구성
단일 노드 구성
-
확장성 제한: CPU, 메모리, 네트워크 대역폭 등을 통한 스케일 업 방식으로 확장할 수 있지만, 물리적 한계와 비용 문제가 있을 수 있어요.
-
안정성: 단일 노드의 가용성을 높이는 구성이 가능하므로 안정적인 시스템 운영이 용이해요.
-
성능 향상: 소프트웨어 성능 최적화 기법 적용이 용이해요.
멀티 노드 분산 구성
-
확장성 극대화: 노드를 스케일 아웃 방식으로 추가하여 대용량 데이터 처리를 선형적으로 향상시킬 수 있어요.
-
장애 발생 시 리스크: 여러 노드 중 한 개의 노드만 장애가 발생해도 데이터 처리가 중단될 수 있어요.
-
관리 부담 증가: 다수의 노드로 구성된 시스템은 장애 발생 가능성이 높아지고 관리 부담이 커질 수 있어요.
4. 카프카 리플리케이션 구조
Kafka는 개별 노드의 장애에 대비하여 높은 가용성을 제공하기 위해 리플리케이션(Replication) 구조를 제공해요. 데이터 복제를 통해 시스템 장애에도 데이터가 유실되지 않도록 보호해요.
-
Replication Factor: 각 토픽의 파티션을 설정된 수만큼 복제해요. 예를 들어, replication factor가 3이면 3개의 노드에 걸쳐 데이터가 복제돼요.
-
Leader와 Follower: 리플리케이션된 파티션은 1개의 Leader와 여러 개의 Follower로 구성돼요. 데이터 쓰기는 Leader를 통해 이뤄지고, Follower는 Leader로부터 데이터를 복제해요.
5. 리플리케이션과 Leader-Follower 구조
리플리케이션 구조에서 데이터는 파티션의 Leader와 Follower 간 복제를 통해 관리돼요. Consumer와 Producer는 Leader 파티션에 연결해 데이터를 읽고 쓰며, Follower는 Leader에서 데이터를 복제해요.
-
Leader: Producer와 Consumer는 데이터를 Leader 파티션에 쓰고 읽으며, Leader는 Follower에 데이터를 복제해요.
-
Follower: Leader에서 복제된 데이터를 받아와서, Leader 장애 시 차기 Leader 역할을 할 수 있도록 해요.
6. Kafka의 복제 설정과 파티션 관리
Kafka에서 데이터의 가용성과 일관성을 보장하기 위해 각 파티션에 대해 리플리케이션 설정을 할 수 있어요. 이를 통해 장애 시에도 데이터 손실을 최소화하고 빠르게 장애를 복구할 수 있어요.
-
Replication Factor 설정: 토픽 생성 시 replication factor 설정을 통해 복제본 개수를 정의해요.
-
Leader Election: Zookeeper가 각 파티션의 Leader와 Follower를 모니터링하여 필요 시 새로운 Leader를 선출해요.
7. Zookeeper의 역할
Kafka에서 Zookeeper는 Kafka 클러스터의 중요한 상태 정보를 관리하고 노드 간 동기화를 지원하며, Controller Broker 선출과 같은 핵심 조율 역할을 수행해요.
Controller Broker 선출
Zookeeper는 Kafka 클러스터에서 Controller Broker를 선출해요. Controller Broker는 파티션의 Leader를 지정하고 클러스터 상태를 조율하는 핵심적인 역할을 합니다.
만약 Controller Broker가 다운되면, Zookeeper는 모든 노드에게 이를 통보하고 가장 먼저 접속한 Broker를 새로운 Controller로 선출해 안정성을 유지해요.
ZNode를 통한 정보 관리
Zookeeper는 ZNode라는 디렉토리 구조로 클러스터의 Broker 목록, Topic 정보, 파티션 상태 등 중요한 정보를 관리해요.
모든 Broker는 이 ZNode를 지속적으로 모니터링하고, 변경 사항이 생기면 Watch Event를 통해 빠르게 통보받아 동기화할 수 있어요.
Broker Membership 관리
Zookeeper는 Kafka 클러스터의 Broker 목록을 관리하고 Broker가 추가되거나 제거될 때 이를 모든 노드에 즉시 통보해 클러스터의 일관성을 유지합니다.
Broker들은 정기적으로 Heartbeat를 Zookeeper에 보내며, 지정된 시간 내에 Heartbeat를 받지 못하면 해당 Broker의 정보를 삭제하고, 이를 Controller에 알리도록 해요.
클러스터 상태 동기화 및 Lock 관리
Zookeeper는 노드 간 상태 동기화를 위한 복잡한 Lock 관리 기능을 제공해 분산 환경에서도 안정적인 운영이 가능하도록 합니다.
8. In-Sync Replicas (ISR) 이해
ISR(In-Sync Replicas)은 Leader 파티션의 복제본 중 일관성을 유지하며 동기화된 Follower들을 의미해요. ISR 내에 있는 Follower만 Leader 장애 시 새로운 Leader로 선출될 수 있어요.
-
ISR 조건: ISR에 포함되려면 Zookeeper에 연결되어 있어야 하고, replica.lag.time.max.ms 이내에 Leader의 데이터를 동기화해야 해요.
-
Fetch 요청: Follower는 Fetch 요청을 통해 Leader로부터 데이터를 복제하고, Leader는 Follower의 동기화 상태를 모니터링해요.
9. Producer의 acks 설정과 데이터 안정성
Producer가 Kafka에 메시지를 전송할 때 acks 설정을 통해 데이터의 안정성을 보장할 수 있어요. acks=all 설정 시 Leader는 모든 ISR에 메시지가 복제될 때까지 기다린 후 Ack를 반환해요.
-
acks=all: 모든 ISR에 데이터가 복제된 후에만 Ack를 반환하므로, 메시지 손실 가능성이 최소화돼요.
-
min.insync.replicas 설정: 최소한의 ISR 개수를 설정해 데이터 손실 방지에 도움을 줘요.
10. Preferred Leader Election과 Unclean Leader Election
Kafka는 파티션의 Preferred Leader를 유지하도록 자동 조정할 수 있으며, Leader와 Follower 간 일관성 문제가 발생할 경우 Unclean Leader Election을 통해 복제되지 않은 Follower를 Leader로 선출할 수 있어요.
-
Preferred Leader Election: auto.leader.rebalance.enable 설정을 통해 처음 지정된 Leader를 유지해 안정성을 높여요.
-
Unclean Leader Election: 기존 Leader가 장기간 복구되지 않을 때 기존 데이터를 포기하고 새로운 Leader를 선출할 수 있어요. 기존 데이터 손실을 감수하고 Out of Sync Follower를 새로운 Leader로 설정해요.
