빅데이터란?
기존의 데이터베이스 관리도구 툴의 능력을 벗어 나는 규모의 대량의 정형 or 비정형의 데이터를 추출하여 가치를 창출하고 결과를 분석하는 기술을 의미한다.
기존의 해결하던 방식
큐잉(queueing)- queueing- 자료구조인 Queue의 형태로 순서대로 대기열을 세워서 순차적으로 처리함.
샤딩(sharding)- sharding- DB내에서 동일한 스키마를 가지고 있는 여러대의 데이터베이스 서버들에 데이터를 작은 단위(Shard)로 나누어서 분산 저장함. Hash Sharding과, Range Sharding이 있음.
- 다만 시스템의 복잡도가 증가하면서 유지 보수가 힘들어져서 아래와 같은 기술들이 등장하게 되었음.
GFS(Google File System)
- 논문 Google File System → 나중에 꼭 자세히 읽어보자
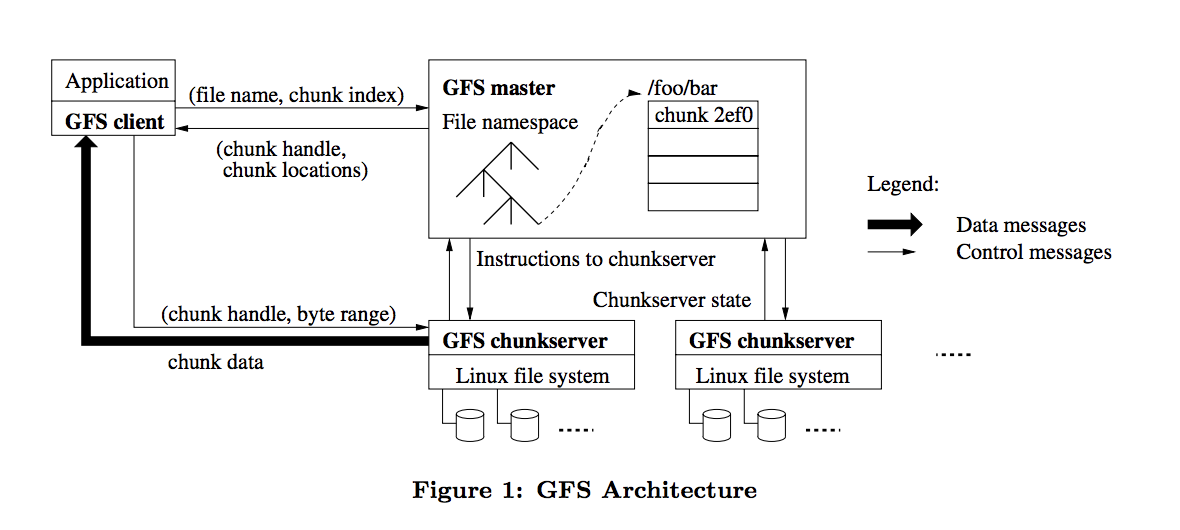
- 앞부분만 읽어봤을 때는 병목현상을 줄이기 위해 고안한 방법인거 같다. 직접적인 교환이 아니라 Chunk server를 통해 교환하는 방식을 사용하고, Hadoop의 원조격이라고 한다.
- 2003년 소개, 구글의 데이터 처리를 위하여 설계된 대용량 분산 파일 시스템이다.
구글에서 사용하는 많은 소프트웨어가 GFS로부터 데이터를 읽고 가공하여 다시 GFS에 여러 개로 복제하여 저장한다. - Master, chunk server, client로 구성되고 Master는 중앙 서버 역할, chunk server는 물리적인 하드 디스크에 입출력을 처리하고, Client는 파일을 읽고 쓰는 동작을 요청하는 어플리케이션을 말한다.
- 클라이언트로부터 마스터로 요청을 보내면 마스터에서는 가장 가까운 chunk server에서 응답하여 동작을 수행(정보를 전달)한다.
- Failuer tolerance, chunk server의 고장 시 마스터는 다른 chunk server를 사용하여 처리하고, 마스터 서버가 고장 시 외부 장비가 마스터의 고장여부를 판단하여 chunk server를 마스터로 사용하는 등의 무정지 기능을 구현하여 안정성이 뛰어난 시스템이다.
참고

데이터엔지니어입니다.