Hadoop
1.MapReduce란?
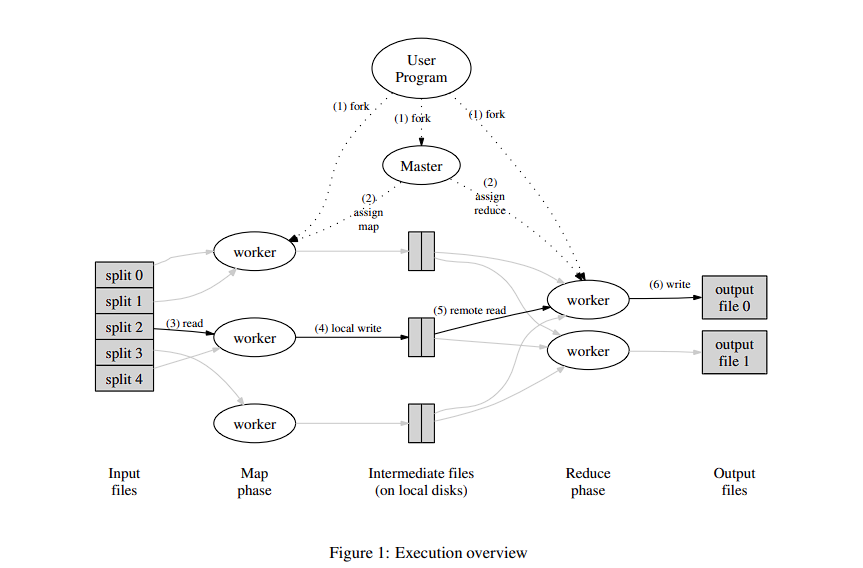
💡 MapReduce는 구글에서 공개한 논문인 MapReduce: Simplified Data Processing on Large Cluster에서 소개한 프로그래밍 모델과 구현한 모듈 자체를 모두 지칭하는 말로 한 가지 Task를 여러 대의 컴퓨터에게 분산해서 처리
2023년 3월 20일
2.GFS(Google File System)
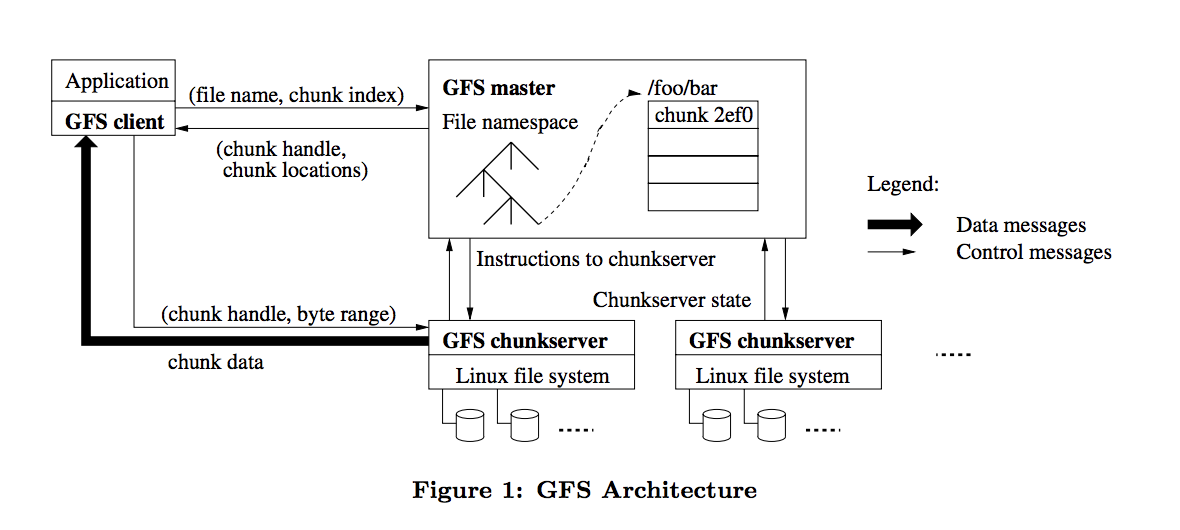
기존의 데이터베이스 관리도구 툴의 능력을 벗어 나는 규모의 대량의 정형 or 비정형의 데이터를 추출하여 가치를 창출하고 결과를 분석하는 기술을 의미한다.큐잉(queueing) - queueing자료구조인 Queue의 형태로 순서대로 대기열을 세워서 순차적으로 처리함.\
2023년 3월 20일
3.[Hadoop]Hadoop이란?

💡 <span style='color:여러 대의 컴퓨터를 사용하여 큰 크기의 데이터를 클러스터에서 병렬로 처리해서 속도를 latency를 줄이고 속도를 높이는 분산 처리가 주 목적입니다.방대한 비정형 데이터를 처리할 솔루션으로 Hadoop이 많이 사용되고 있으며
2023년 3월 21일
4.[Hadoop][HDFS] HDFS 란?
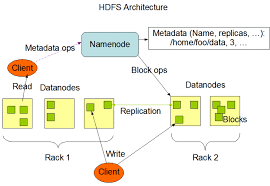
💡 하둡의 분산 파일 저장 시스템인 <span style='color:Hadoop Distrubution File System의 약자로 우리가 일반적으로 사용하는 하드웨어서도 동작하고, 파일 손상 시 복구를 할 수 있는 분산된 파일 시스템을 목표로 합니다.실시간
2023년 3월 21일
5.[Hadoop][HDFS] HDFS의 구조 (Architecture)
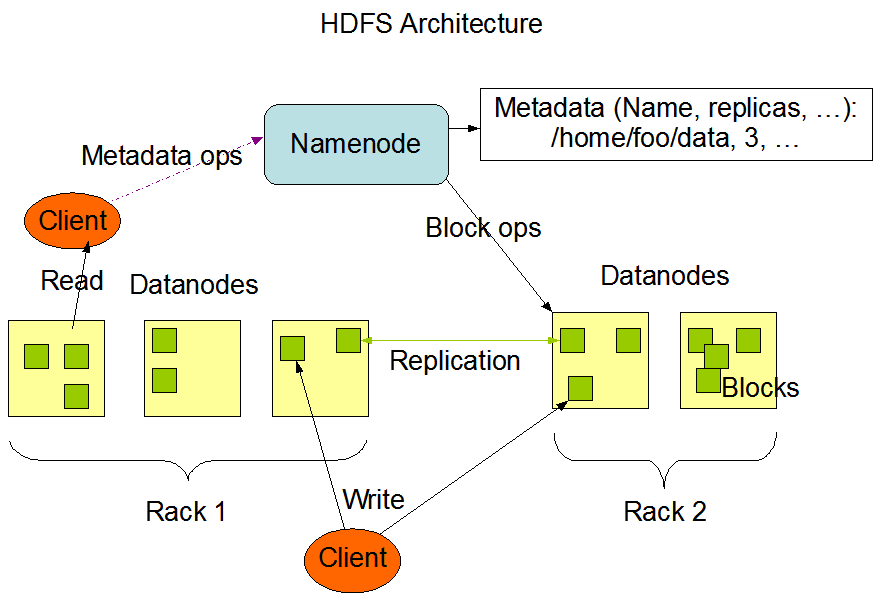
💡 HDFS의 구조에 대해 알아봅니다.HDFS는 Master, Slave 구조로 하나의 Namenode와 이에 할당된 여러 개의 Datanode로 구성됩니다. 네임노드는 메타데이터(데이터 노드의 위치정보 등등)를 가지고 있고 데이터는 블룩 단위로 나누어서 데이터노드에
2023년 3월 21일