[Paper Review] Blur2Blur: Blur Conversion for Unsupervised Image Deblurring on Unknown Domains
PaperReview
요즘 Super Resolution이나 Image Restoration하는 분야에 있어 Degradation을 학습하는 쪽보다는 모델이 학습한 Known Degradation으로 변환시켜 성능을 향상시키는 분야가 많이 연구되고 있습니다. 관심이 많아 이런 쪽의 논문을 읽고 리뷰 남겨봅니다.(사실상 논문 정리지만요)
해당 논문은 블로그로도 코드가 있고, 프로젝트 페이지가 쉽게 와닿아서 핵심 주장은 빠르게 파악할 수 있었습니다.
https://zero1778.github.io/blur2blur/
Abstract
이 논문은 특정 카메라에 맞춘 Image Deblurring 알고리즘을 train하기 위한 프레임워크에 대한 설명을 한다. “이 알고리즘은 Deblurring하기 어려운 Blur에 대해 더 쉬운 Blur로 변형해주는 식으로 작동한다.”
Blur → 다른 Blur로의 변환은 Target Camera에서 찍은 선명한 이미지와 Blur 이미지로 학습하는데 이때 둘은 Unpaired 관계이다. 이 Blur→ Blur는 Blur→Sharp 변환보다 더 간단하다.
그래서 정량적, 정성적 평가로 최고다.
Introduction
이미지와 비디오에서 motion blur는 흔히 발생하는 문제로, 카메라가 흔들릴때나 장면 내 빠른 움직임으로 발생한다. 이럴 때 콘텐츠의 품질을 떨어뜨릴 수도 있고, 이후 CV 활용을 저해할 수 있다. ⇒ 따라서 효과적인 Deblurring 방법론이 필요하다.
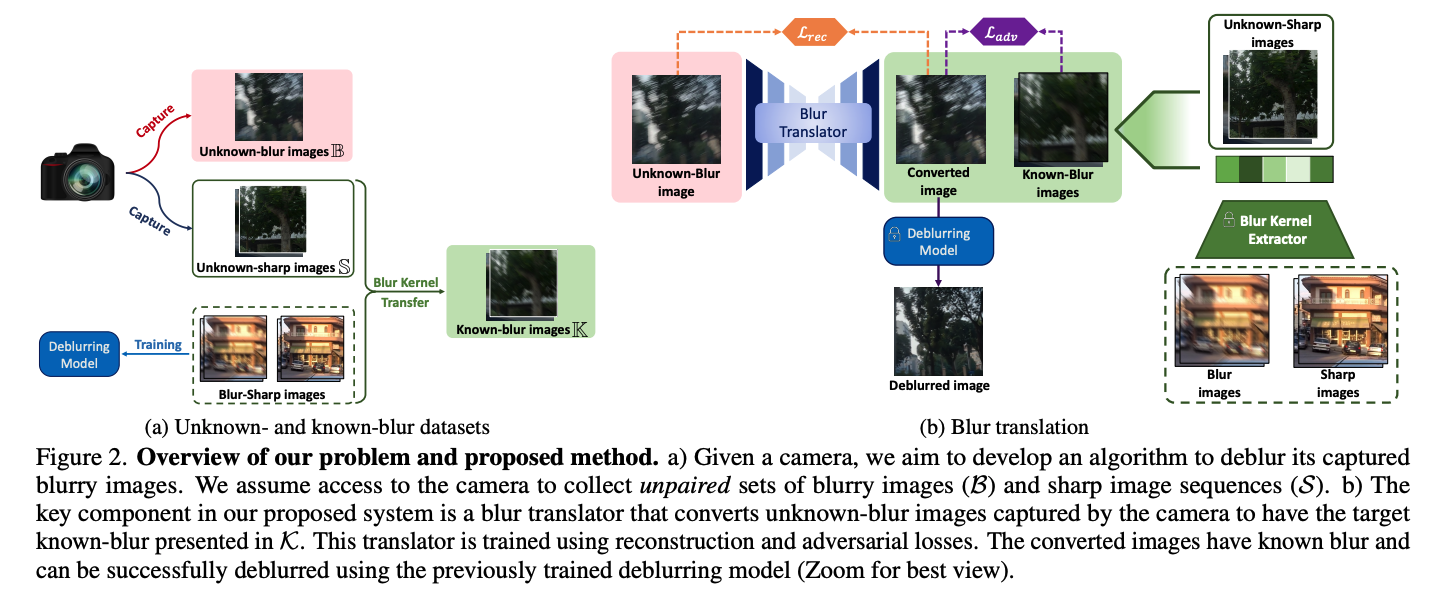
특정 시나리오에서 특정 카메라나 유형에 맞춘 Deblurring 알고리짐을 맞춤화하는 프레임워크의 개발이 중요하고 필요하다. 그래서 이 논문은 “특정 카메라로 촬영된 이미지를 어떻게 디블러링할 수 있을까?”라는 질문에서 시작한다. 이를 해결하기 위한 방법 별로 설명을 하는데, 먼저 전통적인 방식은 ⇒ 지나치게 단순화된 블러에 의존하기 때문에 실제로 사용할 수 없다. 머신러닝 방식으로 하게 되면, 방대한 양의 paired 이미미셋을 학습하여 블러를 선명하게 변환하도록 한다. 하지만 이런 방식은 종종 Overfitting이 일어나기도 하고, distribution이 training set에 있지 않는 다른 데이터가 들어오면 성능이 떨어진다. Pre-trained된 네트워크가 적합하지 않으면, 특정 카메라에 맞춘 Deblurring 방식을 개발하는 것인데, 이는 Paired Dataset를 만들어낼 수 없다는 점이 문제이다.
그래서 저자들은 unpaired data에 집중하고, 이렇게 되면 Blur한 input에서 왜곡되거나 누락된 details를 복원하는데 힘들 수 있다. 기존의 방법들은 이 부분을 재현해내려고 하지만, 실제로는 사용할 수 없다.
그래서 이 논문은 Blur2Blur라고 하는 plug&play 프레임워크를 소개한다. 이는 Pre-trained Deblurring 모델을 활용하여 특정 카메라 장치에 맞춘 이미지 Deblurring 알고리즘을 train한다.
해당 저자들은 목표 카메라로 Blur image, clear image를 촬영하는데 이는 일대일 대응이 될 필요가 없어 비교적 쉽게 데이터 수집을 할 수 있다. 또한 Blur ↔ Clear를 매핑시키지 않고, C 도메인의 Blur 이미지에서 C' 도메인의 Blur 이미지로 매핑을 하게 된다. 그런 다음 Pre-trained weight를 사용하여 Clear하게 해준다.
Blur↔Blur 매핑을 위해 perceptual, adversarial, and gradient penalty term loss를 사용한다.

Method
이때 x는 sharp image, y=noise image, n=noise, k= blur kernel이다.
보통은 라는 Deblur함수를 근사할 때 사용했는데, 성능이 좋지 못했다.
그래서 고유한 Blur 형태 ()를 우리 카메라 ()에 맞춰서 Blur2Blur를 제안하는데, 이때 의 Blur spacerk 알려지지 않았고, 일치하는 Blur와 Clear의 Pair로 얻기 어려워서 둘을 Pair 시키려면 빔, 다른 속도로 촬영하는 동일한 장치, 시간 동기화 등의 기능이 포함되어 선택할 수 있는 유일한 방법은 Unpaired Dataset를 사용하는 것이다.
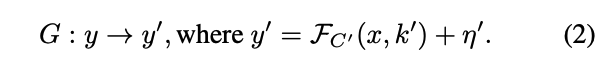
이때 C'은 Known Distribution을 뜻한다.
이 C→ C'를 변환해주는 작업(G)을 위해 두 개의 데이터셋이 필요하다. Unknown Blur Space에서 가져온 Blur 이미지로 구성된 B, 이미 Deblurring Model으로 train된 Known Blur Space에서 가져온 이미지로 구성된 K가 필요하다.
사용된 Loss 정리를 해보려고 한다.
1. Adversarial loss
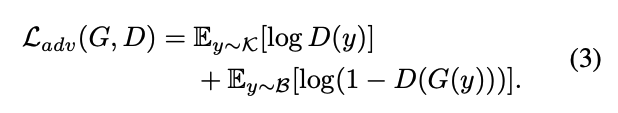
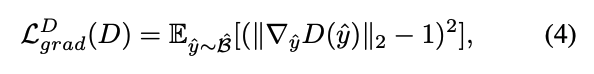
2. Reconstruction loss
(1) Loss만 사용하면 도메인 변환에는 도움이 되지만, Detail Reconstruction되기 어려우니까 생성된 Blur와 원본 y의 visual consistency를 유지하기 위해 Reconstruction loss를 도입한다.
해당 Loss를 사용하면, 1) G가 이미지 content를 수정하지 않고 Blur Kernel 변환에만 집중하고, 2) Network의 training에 안정성을 높인다.
또한 픽셀 단위의 정확성에 집중하는 것보다는 input의 semantic info에 보존을 위해 L1, L2 대신 Perceptual loss를 사용하고, multi scale deblurring architecture를 사용하여 coarse to fine을 단계적으로 Reconstruction할 수 있다.
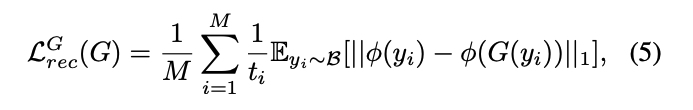
이때 는 input image at scale level이 일 때이고, M은 number of level이고, 는 pretrained extractor with VGG19를 뜻한다.
그래서 total loss는 Generation에서는 아래의 loss가 쓰이고,
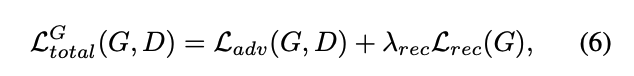
Discrimination에서는 이 아래의 Loss가 쓰인다.
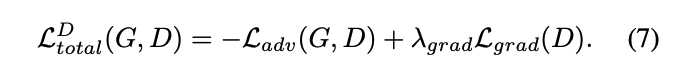
Known Blur Section
C'과 K의 선택은 중요하다. ⇒ Blur Transform Network를 학습하는 난이도는 두 Blur Domain 간의 차이에 따라 달라지기 때문이다. K (대표 데이터셋)은 Adversarial Loss에만 영향을 끼친다. Transform Network G는 B의 이미지를 K의 이미지와 유사한 Blur 특성을 갖도록 변환하는 것이 목표이다. 그러나 K와 B가 Blur kernel 외에도 색상, 해상도, 장치에 따른 노이즈등의 차이가 가지고 있다면, Discriminator는 이를 이용해 정답과 생성 이미지를 구별할 수 있다. ⇒ G는 수렴하지 않을 수도…
이를 피하기 위해 B와 같은 카메라로 촬영된 Clear image S 집합에서 K의 이미지를 생성하는 방법을 제안한다. ⇒ 이렇게 하면 동일한 특성을 공유하게 된다. Blur ↔ Clear Pair는 REDS, GOPRO, RSBlur, RB2V와 같은 데이터셋으로 선택할 수 있다.
Experiments
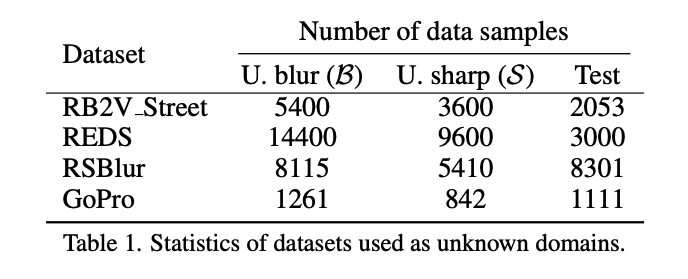
REDS에 있는 300 high speed video를 synthetic blur 만드는데 사용했다.
GOPRO도, RSBlur도 일부를 평가 데이터셋으로도 사용했다.
데이터셋 : Deblurring 평가를 위한 데이터셋을 선택할 때, 해당 훈련 데이터를 두개의 집합으로 나눠서 0.6:0.4로 사용한다.
0.6 ⇒ Blur image를 선택하여 unknown blur image와 형성
0.4 ⇒ Clear를 선택해서 Clear ↔ Blur로 형성
Implementation Detail
Blur - to - Blur translation network : G = MIMO-UNet with default config in Pix2Pix
hyper parameter : ,
Batch : 16
200K iter 후에 비율을 점점 확대하여 전체 Batch를 포함하도록 조정한다.
Deblurring Network는 NAFNet or Restormer등의 최신 Deblurring Network사용
Augmentation : Rotation, Flip, Color-jitter.
GPU : A100 2개, 3일


결론적으로 봤을 때 Fig에서 보이는 성능은 굉장히 좋다. Train Distribution이 아닌 Inference 시에 Distribution안에 없던 값들을 맞춰주기엔 좋은 것 같다. 다만, 우려스러운 점은 다른 도메인(의료 등)에는 이 상황이 먹힐까라는 고민도 든다.
Blur와 Noise가 학습 Distribution안에 있는 것으로 가정 상황이 잘 먹히면 좋을 것 같다는 생각이 드는 논문이다.
