https://arxiv.org/pdf/2103.14030.pdf 논문을 참조하여 정리된 포스팅입니다.
기존의 Transformer의 문제는 2가지가 존재한다.
- Scale이 고정되어있다는 점 (Ex. Text)
- Pixel의 Resolution의 상당히 High하다는 점 (Ex. Image)
ViT(기존 연구)와 다른 점은 하단의 그림과 같다.
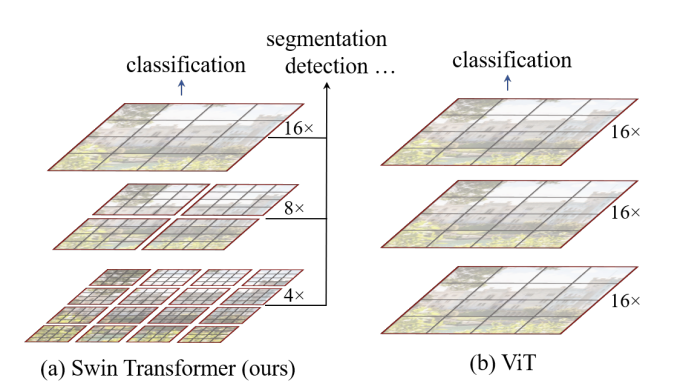
ViT는 (b)그림과 같이 모든 영역에 대해 Self-Attention을 실시하기 때문에 Computation Cost가 매우 높다.
그렇기 때문에 Image를 Patch로 보면서 (a)의 그림에서처럼 각 layer에서 다른 해상도를 다루게 된다.(hierarchical feature map)의 특징 ! ⇒ Object detection or Segmentation에서의 적합한 Backbone !
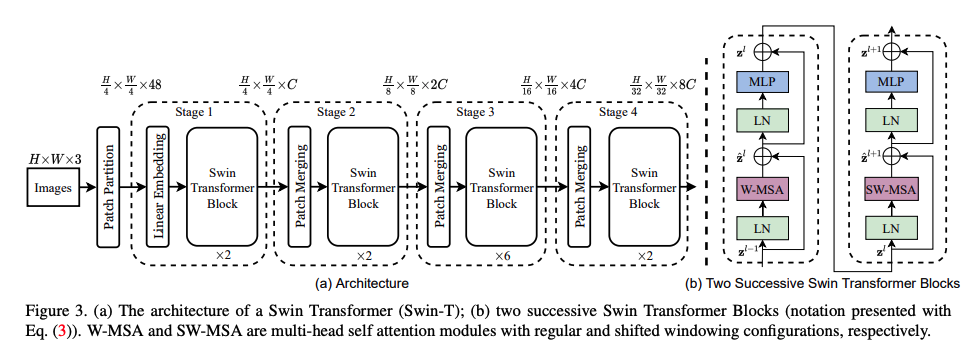
Swin Transformer에 대한 구조는 위의 그림과 같다.
전체적인 구조는 a와 같고, b의 경우 Swin Transformer Block에만 해당되는 경우인데, 이 Block의 경우 !
기존 Transformer의 구조와 달라진 부분은 딱 한가지다. Multi-Head Attention부분이 W-MSA로 변경됐고, Shifted Window-MSA로 변경됐다는 것!
또한 이때 사용하는 Patch Merging 방식의 사용 이유는 !
⇒ 각 stage에서 나온 feature 들을 단순히 concat만 해준다면 c의 차원이 너무 커지기 때문에 이를 방지하기 위한 방식으로 사용한다.
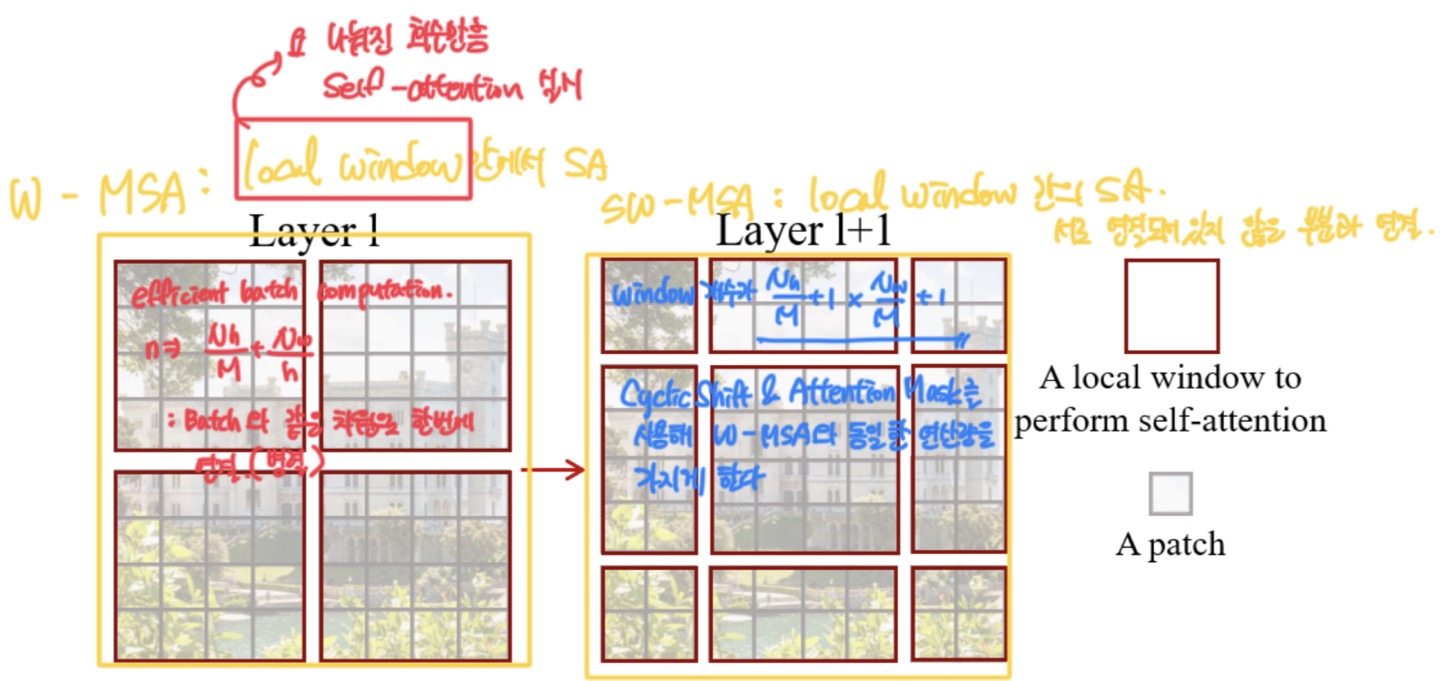
Shifted Window 관점은 상단의 이미지와 같은데, 이 부분의 핵심은 W-MSA와 동일한 window를 사용하여 연산한다.
W-MSA : Local Window 안에서 Self-Attention을 하는 것이고,
SW-MSA : Local Window간의 Self-Attention을 하는 것이라, 서로 연결되어있지 않은 부분들에 대해서 계산을 한다.
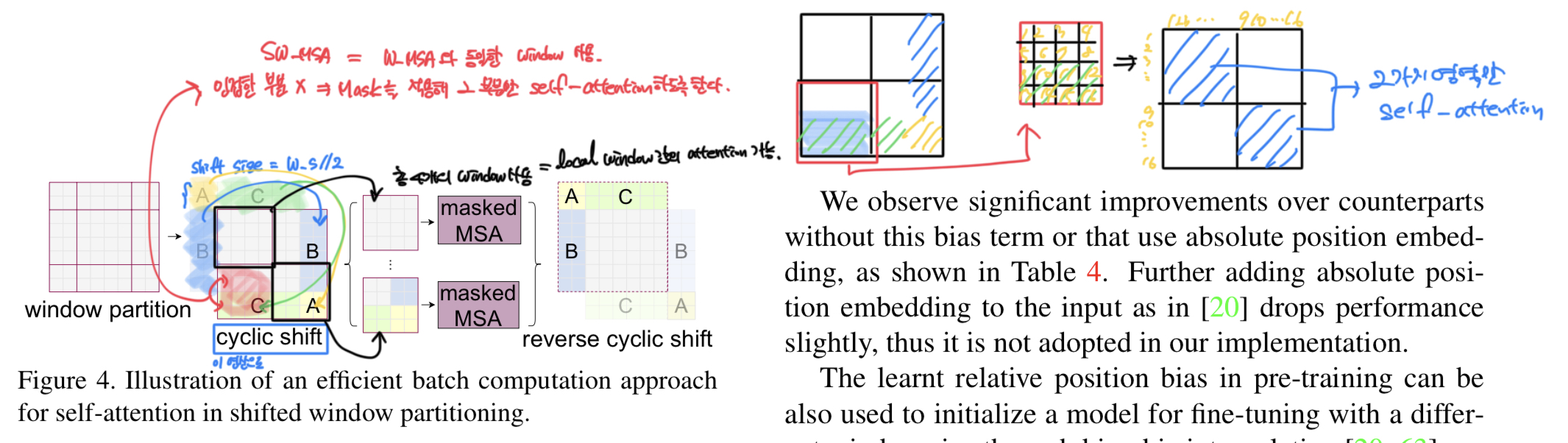
계산하는 방식은 다음과 같은데, 사용되는 Shift 방식은 Cyclic shift방식을 사용한다.
해당 연산과 관련한 방식은 상단 그림에 나와있다.
해당 부분을 연산하는 방식은 A,B,C에 대한 영역을 Cyclic Shift를 통해 원래 있던 형태(연한 그림)에서 진한 그림으로 형태가 변경이 된다. 여기서 선택되는 Shift size는 Window size//2로 설정된다.
이렇게 해주면 연관되어있지 않았던 부분(Like C 영역)에 대한 mask 연산이 실행되는데, 이 형역을 확대해보면 2가지 영역에 대해서만 Attention 연산이 진행되는 것을 볼 수 있다.
