job queue
기본적으로 Node.js는 비동기적(하나의 작업 처리중에 걸리지 않음)으로 작업을 처리하는데 이렇게 될 경우 고작 0.01~-0.00001ms 정도쯤의 차이로 다수의 유저가 자원에 접근하게 되면 어떻게 판별을 할까?

자 내가 바론 막타를 쳤다고 쳐보자.
근데 나보다 0.001ms 늦게 누가 바론 막타를 쳤다.
보통이라면 이제 내가 막타를 쳤으니까 내가 먹었다고 뜨는게 맞을 것이다.
그렇지만 만약 내 컴퓨터의 통신이 늦고 상대가 빠르다면?
상대가 먹힌 걸로 판정이 날 수 있지 않을까? 아... 망겜
그렇다면 이걸 어떻게 해결해야할까?
누가 먼저 바론 막타를 쳤는지 서버에서 이를 순서대로 판단을 내려줘야만 한다.
이를 위해서는 우리는 순서대로 처리하는 job queue의 개념에 대해서 알아야만 한다.
일반적으로 이벤트 루프는 call Stack(작업 공간)과 task Queue(저장 공간)으로 나뉘게 된다.
콜스택
자바스크립트 안에서 실행되는 모든 함수의 호출을 기록하고 추적한다. 모든 process와 thread안에는 각각 저마다의 Call Stack이 들어있다. 추가로 현재 작업중인 위치를 기억하고 있다.
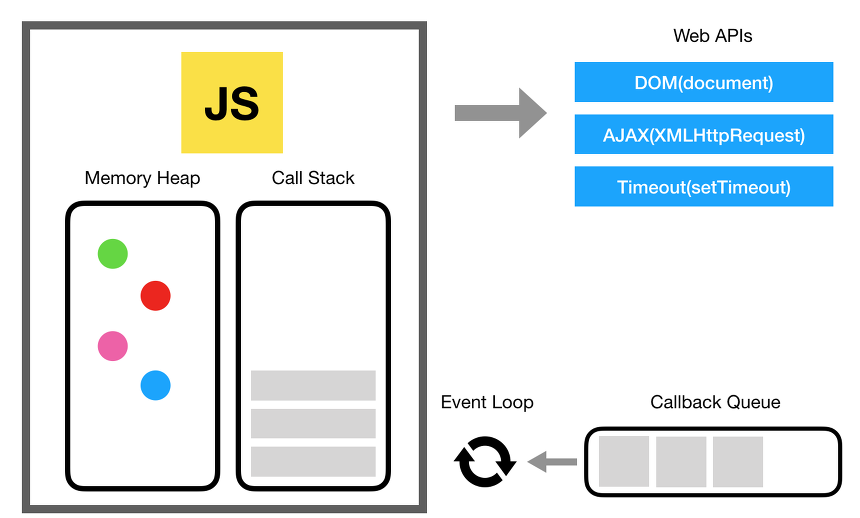
테스크 큐
스레드로부터 전달받은 태스크(task = 콜백 함수)들을 선입선출 구조로써 저장하고 있는 큐다.
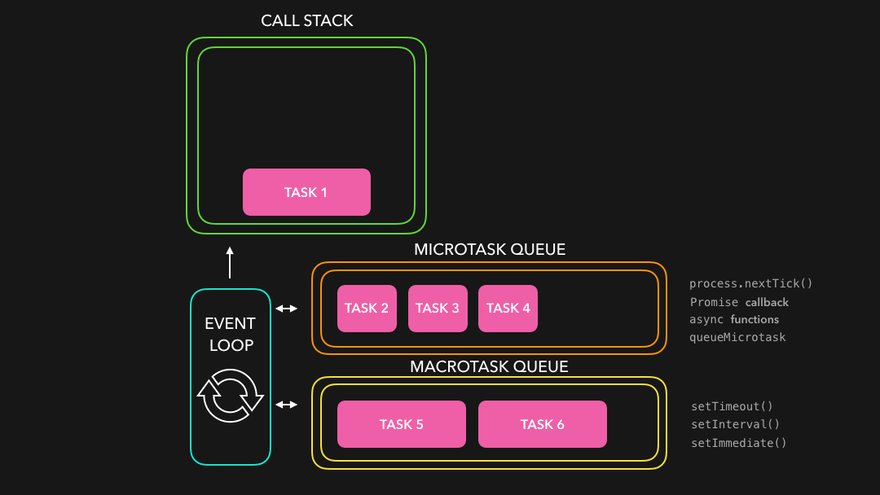
다른 개념
이벤트 루프:매 순간 스택이 비어있는지 여부와 태스크 큐에 콜백 함수가 기다리고 있는지 여부를 확인하며 콜백함수가 들어올 때마다 스택에 쌓는 역할을 하고 스택이 차있다면 스택에서 함수의 호출을 처리한다.
task: 매크로 태스크 큐에 들어가며, 콜백 함수가 호출되어 독립적으로 실행되는 작업 단위입니다. ex) setTimeout
job: 마이크로 태스크 큐에 들어가며, 태스크가 완료된 후 바로 실행되는 비동기 작업입니다. ex) Promise.then, MutationObserver
Microtasks Queue: promise 콜백(.then,.catch,.finally)나 process.nextTick 등에서 이벤트루프의 현재 실행 중인 테스크가 완료된 직후에 실행되며 높은 우선순위를 가져서 항상 마크로 태스크 보다 먼저 실행된다.
Macrotasks Queue: setTimeout, setInterval 등에서 이벤트 루프의 각 반복마다 실행되며 마이크로 태스크가 모두 완료된 이후에 실행되며 한번에 하나씩 실행된다.(대기열에 쌓인 순서대로 진행)
이렇게 기본적인 이벤트 루프 관련 개념을 확인했다면 우리는 이제 job queue가 뭔지 알아야만한다.
Job: 처리해야 할 작업 단위입니다. 예를 들어, 이메일 전송, 이미지 처리, 데이터베이스 업데이트 등이 하나의 작업(Job)으로 간주될 수 있습니다.
Queue: 작업이 들어오면 순서대로 저장되는 구조입니다. 일반적으로 FIFO(First In, First Out) 원칙을 따릅니다.
즉, Job Queue는 처리해야 할 작업(Job)을 정리해 두고, 이를 순차적 또는 병렬적으로 처리하는 메커니즘입니다.
이렇게 처리해야할 작업을 정리 및 순차적,병렬적으로 처리할 수 있는 메커니즘인데 이 중 하나인 bullmq를 직접 사용해 보았다.
import { Queue, QueueEvents, Worker } from 'bullmq';
import ioredis from 'ioredis';
import dotenv from 'dotenv';
import onData from '../../events/onData.js';
import onEnd from '../../events/onEnd.js';
import onError from '../../events/onError.js';
import onClose from '../../events/onClose.js';
import { connectedSocket } from '../../events/onConnection.js';
dotenv.config();
const redisOptions = {
maxRetriesPerRequest: null,
username: process.env.REDIS_USERNAME,
password: process.env.REDIS_PASSWORD,
};
export const queue = new Queue('on', {
connection: new ioredis(process.env.REDIS_URL, redisOptions),
});
export const worker = new Worker(
'on',
async (job) => {
const { name, data } = job;
console.log(`Processing job: ${name} for socketId: ${data.socketId}`);
console.log();
/**
* Todo:
* ! onData, onEnd, onError에서 bullMQ를 사용해서 처리하는게 맞는지?
* !
* ! 이렇게 버퍼를 하나씩 로딩하는 방식이 아닌 한번에 받아서 처리해도 되는가?
*/
switch (name) {
case 'onData':
await onData(connectedSocket.get(data.socketId), Buffer.from(data.data));
break;
case 'onEnd':
await onEnd(connectedSocket.get(data.socketId))(Buffer.from(data.data));
break;
case 'onError':
await onError(connectedSocket.get(data.socketId))(Buffer.from(data.data));
break;
case 'onClose':
await onClose(connectedSocket.get(data.socketId))(Buffer.from(data.data));
break;
default:
console.warn(`알수 없는 작업: ${name}`);
}
},
{
connection: new ioredis(process.env.REDIS_URL, redisOptions),
removeOnComplete: { count: 4 },
removeOnFail: { count: 4 },
concurrency: 4,
},
);
worker.on('completed', (job) => console.log(`${job.id} completed`));
worker.on('failed', (job) => console.log(`${job.id} failed`));
// export const eventQueue = new QueueEvents('on', {
// connection: new ioredis(process.env.REDIS_URL, redisOptions),
// });
queue에 등록하고 해당하는 queue에 원하는 작업을 추가하여 등록한다.
이렇게 등록하면 worker에서 이를 병렬적으로 처리하기 시작하는데 이 때 각 받은 이벤트에 따라서(이벤트 기반) 다르게 처리할 수 있다.(redis 기반)
또한 완료된 작업 수, 실패한 작업의 수를 지우거나 현재 몇개의 태스크를 병렬적으로 처리할 수 잇는지 설정하는 등 다양한 기능을 제공하고 있다.
순차적이 아니지 않나? 라는 생각이 들기도 했지만,
bullmq에서는 들어온 순서대로 병렬적으로 처리를 하기 때문에 일단 성립이 되지만 job queue와 같이 일정이상의 작업을 모아둔 후 flush로 쏘는 방식이 아니기 때문에 이 부분에 대해서는 내일 추가로 개발을 해보고자 한다.
