학습/ 검증/ 테스트 데이터 분활
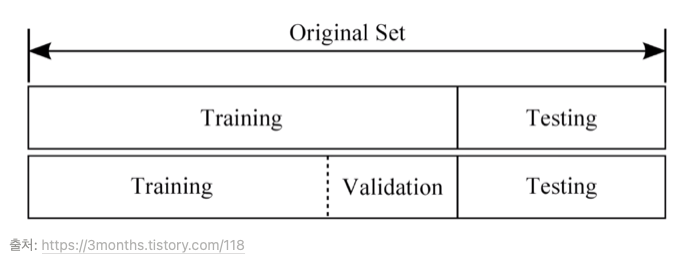
기계를 학습시킬 때, 데이터 전체를 학습에 사용하는 것이 아니라 나누어 사용하게 된다.
- Training set (학습 데이터셋, 트레이닝셋) = 교과서
머신러닝 모델을 학습시키는 용도이다. 전체 데이터셋의 약 80% 정도를 차지한다.
- Validation set (검증 데이터셋, 밸리데이션셋) = 모의고사
머신러닝 모델의 성능을 검증하고 튜닝하는 지표의 용도로 사용한다. 이 데이터는 정답 라벨이 있고, 학습 단계에서 사용하기는 하지만, 모델에게 데이터를 직접 보여주지는 않으므로 모델의 성능에 영향을 미치지는 않는다.
손실 함수, Optimizer 등을 바꾸면서 모델을 검증하는 용도로 사용한다.
전체 데이터셋의 약 20% 정도를 차지한다.
- Test set (평가 데이터셋, 테스트셋) = 수능
정답 라벨이 없는 실제 환경에서의 평가 데이터셋이다.
‼️ 검증 데이터셋에서 아무리 정확도가 높더라도 제품에서 제대로 동작하지 않는다면 무쓸모!

날마다 꾸준히 성장하는 Software Engineer