AI
1.합성곱 신경망 Convolutional Neural Networks
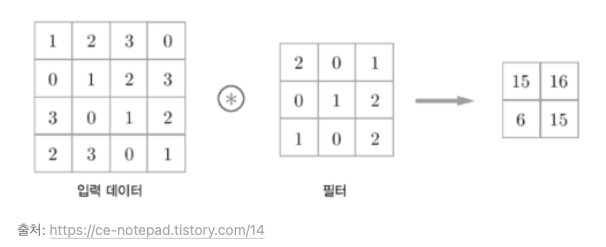
합성곱(Convolution)은 예전부터 컴퓨터 비전(Computer Vision, CV) 분야에서 많이 쓰이는 이미지 처리 방식이다. 입력데이터와 필터의 각각의 요소를 서로 곱한 후 다 더하면 출력값이 된다.보통 입력 데이터는 2차원이나 3차원인 경우가 많은데, 2차
2.딥러닝 주요 개념
모델을 학습시키는 데 쓰이는 단위.batch와 iteration약 10,000,000개의 데이터셋을 한꺼번에 메모리에 올리고 학습시키려면 엄청난 용량을 가진 메모리가 필요하고 그 메모리를 사는데 (메모리가 없다면 개발하는데) 천문학적인 비용이 든다.이를 해결하기 위해
3.[딥러닝]이란?
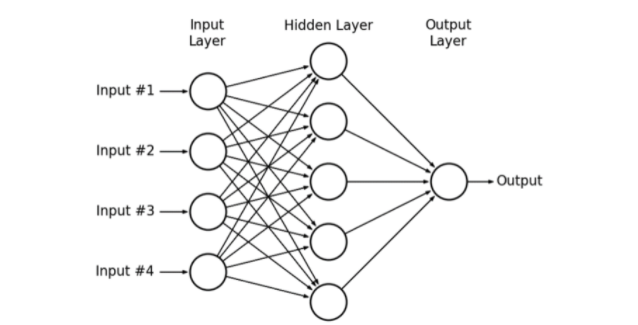
딥러닝은 러닝머신의 한 분야로 머신러닝의 하위집단에 속한다. 탄생배경: 과거에 선형회귀 논리회귀를 이용한 1차 함수로 모든 문제를 풀고자했지만 자연계에는 직선으로만 설명할 수 없는 문제들이 휠씬 많았다.이런 복잡한 문제를 해결하기 위해 선형회귀를 여러번 반복했지만 선형
4.머신러닝 전처리
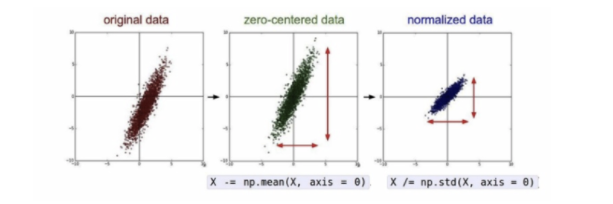
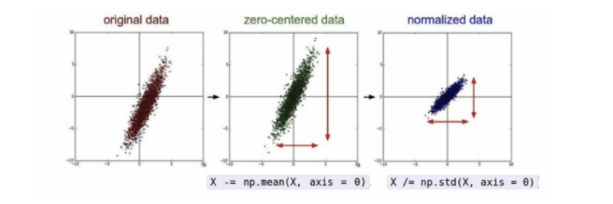
넓은 범위의 데이터를 정제 시키는 것을 말한다. 러닝머신의 성능을 높이기 위한 사전 작업인 것이다.전처리 작업으로는 정규화 Normalization 작업과 표준화 Standardization 작업이 있다.정규화 Normalization 기준이 다른 데이터를 0 ~ 1
5.다항 논리 회귀

Multinomial logistic regression입력값을 가지고 출력값을 3개 이상 클래스를 도출하는 것을 Multinomial logistic regression하고 한다.Multinomial logistic regression 문제를 풀 때, One-hot
6.논리 회귀 Logistic regression
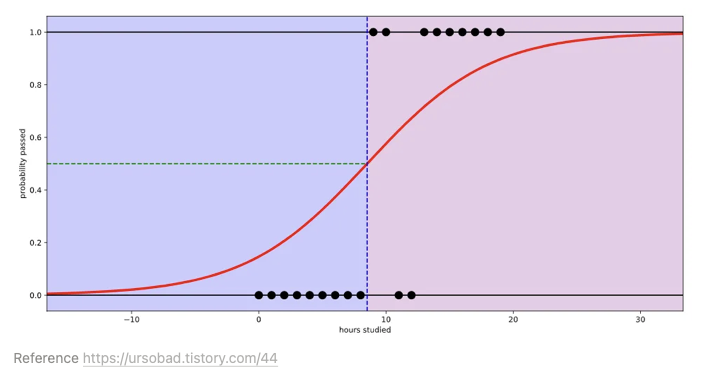
2주차의 핵심은 논리 회귀와 전처리이 문제를 풀기 위해서는 어떤 전처리 방법을 해야 하는지 아는 것이 능력이다.선형회귀로 풀 수 없는 문제를 논리회귀로 푼다.예로 입력값이 공부한 시간이고 출력값이 이수 여부가 되는 이진 클래스를 들 수 있다.logistic functi
7.데이터셋 분할
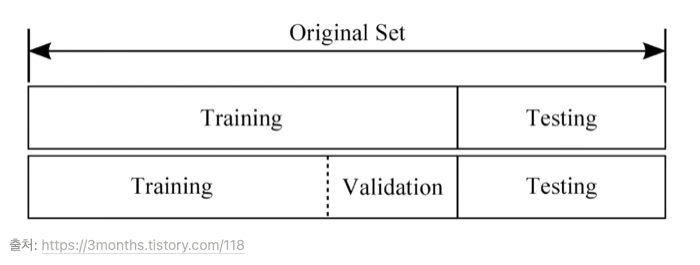
학습/ 검증/ 테스트 데이터 분활기계를 학습시킬 때, 데이터 전체를 학습에 사용하는 것이 아니라 나누어 사용하게 된다.Training set (학습 데이터셋, 트레이닝셋) = 교과서머신러닝 모델을 학습시키는 용도이다. 전체 데이터셋의 약 80% 정도를 차지한다.Vali
8.경사 하강법 Gradient descent method
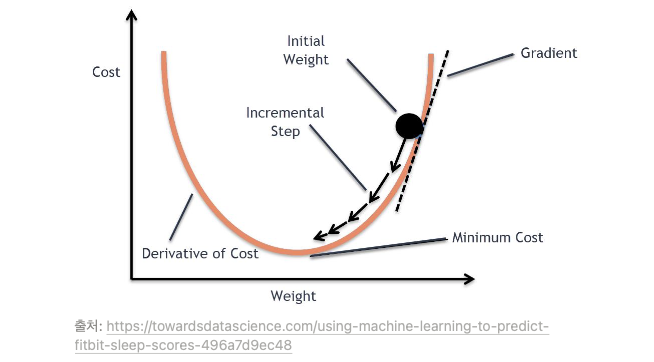
경사 하강법은 손실 함수를 최소화 하기 위해 그래프를 따라 점점 아래로 내려간다.$$H(x) = Wx + b$$가설에서 알아내야 하는 것은 W와 b이다. 컴퓨터는 값을 변경하면서 cost값을 본다. 따라서 컴퓨터는 W와 b값을 바꾸가면서 cost 값이 떨어졌는지, 안
9.선형 회귀 Linear Regression
가설을 먼저 세우고 가설과 정답값의 간격을 좁히도록 기계를 학습시킨다.회귀 문제는그래프 직선 하나로 예측할 수 있는 방법이다. 간단하지만 강력한 방법이다.과거에는 “이 세상의 모든 법칙은 선형적이다” 가정하고 문제에 접근했기 때문에 풀 수 있는 문제가 많았다.Regre
10.머신러닝

먼저, 알고리즘이란 문제를 풀기 위한 일련의 절차나 방법을 공식화한 것이다. 라면을 먹을 때도 만드는 절차가 있듯 수학에서도 문제를 풀기 위해 반복적인 절차가 있다. 즉, 절차적으로 수행하도록 만든 체계가 알고리즘이다.컴퓨터는 반복적으로 처리하는 경우가 많기에 컴퓨터