Convolutional Neural Networks
합성곱(Convolution)은 예전부터 컴퓨터 비전(Computer Vision, CV) 분야에서 많이 쓰이는 이미지 처리 방식이다. 입력데이터와 필터의 각각의 요소를 서로 곱한 후 다 더하면 출력값이 된다.
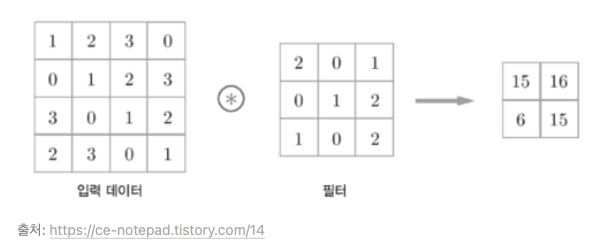
보통 [입력 데이터]는 2차원이나 3차원인 경우가 많은데, 2차원이라 가정한다.
[필터]는 앞으로 학습시켜야 하는 “가중치(Weight)”이다
개념만 알면 계산은 컴퓨터가 해준다^^
이러한 합성곱을 1998년 르쿤 교수의 논문으로 딥러닝에 활용하게 된다.
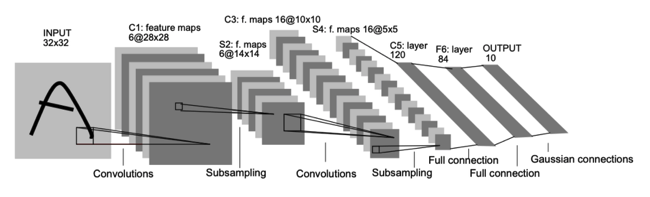
그림에 특성을 잘 반영한 feeture map 을 뽑아내고 > 차원을 축소시켜 핵심만 뽑아낸다 > 1차 Convolution subsampling> 2차 Convolution subsampling 반복 > 덴스레이어로 연결 > OUTPUT
이렇게 출력값을 뽑아내면 굉장히 성능이 좋다 논문을 발표하게 된다.
합성곱을 이용한 이 신경망 디자인을 합성곱 신경망(CNN)이라고 명칭했고 이미지 처리에서 엄청난 성능을 보이는 것을 증명했다. CNN의 발견 이후 딥러닝은 전성기를 이루었다. 이 후 CNN은 얼굴 인식, 사물 인식 등에 널리 사용되며 현재도 이미지 처리에서 가장 보편적으로 사용되는 네트워크 구조이다.
CNN 개념 Filter, Strides, Padding
- Filter 아래 그림을 보면 파랑색이 [입력값]이고 3x3짜리가 필터이다.
한 칸씩 오른쪽으로 움직이며 합성곱 연산을 하는데, 이동하는 간격을 스트라이드(Stride)라 한다.
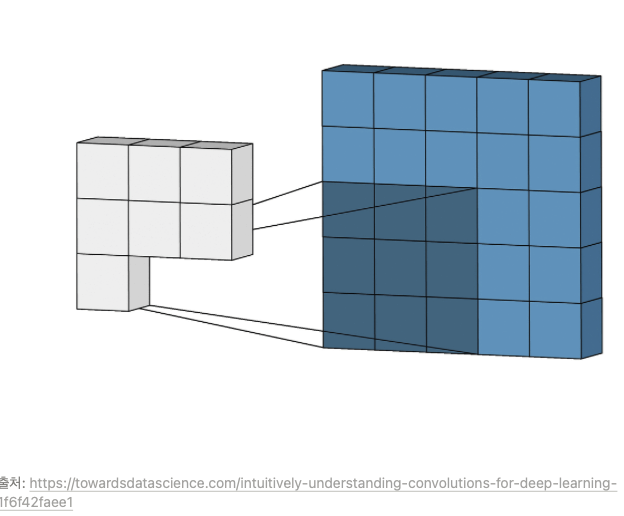
Filter만 사용하게 되면 입력값과 필터를 사용해서 얻은 feeture map의 크기가 입력값과 달라진다.
이러한 형상을 방지하기 위해 사용하는 방법이 Padding이다
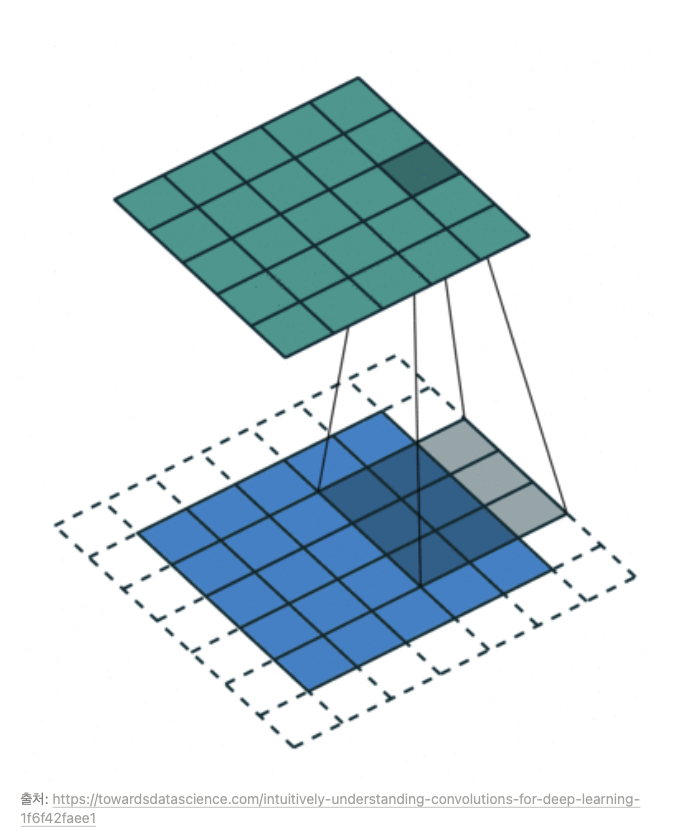
- Padding 패딩(Padding 또는 Margin)을 주어, 스트라이드가 1일 때 입력값과 특성 맵의 크기를 같게 만들 수 있다. 점선은 0으로 채워져 있는 배열이다. 이렇게하면 입력값과 feeture map 크기가 유지 된다.
여러개 필터 사용하기
위에서는 1개의 필터를 사용하여 연산을 하였지만 여러개의 필터를 이용하여 합성곱 신경망의 성능을 높일 수 있다. 그리고 이미지는 3차원(가로, 세로, 채널)이므로 아래와 같은 모양이 된다.
- 입력 이미지 크기: (10, 10, 3) → 보통 컬러 이미지는 3차원이다
- 필터의 크기: (4, 4, 3) → 3 채널 = 깊이
- 필터의 개수 :2 (다른 필터로 2번 반복)
- 출력 특성 맵의 크기: (10, 10, 2) → 출력 feeture map
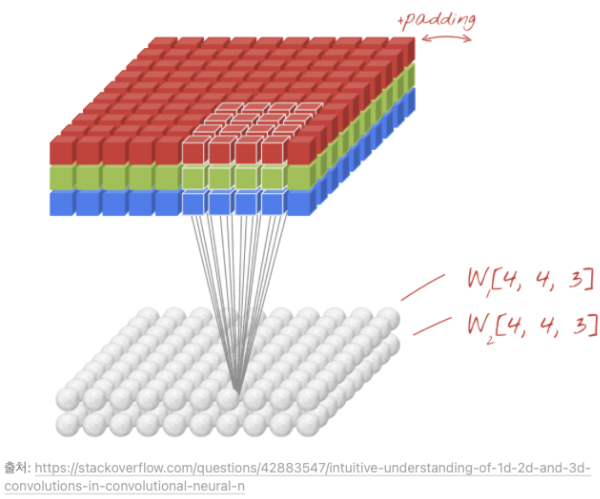
3차원 이미지에서 이렇게 Convolution 연산이 가능하다.
