introduction
기존 VL-NLE에서의 한계점
- NLEs for VL tasks의 데이터가 적고 unchallenging하고 noisy하다.
- no unified evaluation framework in VL-NLE field
- NLEs are difficult to evaluate- 질문과 정답에 대한 설명이 다양하게 존재한다. 하지만 현존하는 NLG metric은 다양한 설명들에 대한 평가가 형편없다.
- 과거 연구들에서 human evalution에 대해 서로다른 접근으로 객관적인 비교가 어렵다.
논문에서 제안하는 것
(1) VL-NLE tasks의 첫 벤치마크인 e-ViL제안하였다. e-ViL은 3개의 human written한 NLE로 구성되어 있다.
(2) e-ViL 데이터셋을 이용하여 4개의 VL-NLE model을 비교해보았다.
(3) e-SNLI-VE 데이터셋을 도입하였다. 430k의 요소들로 구성되어있어 VL-NLE에서 현존하는 가장 큰 데이터셋이다.
(4)새로운 e-UG 모델을 도입하였다. 해당 모델은 3개의 데이터셋에서 SOTA성능을 보인다.
(5)automatic NLG metrics 와human evaluation of NLE의 상관관계를 연구하였다.
기존 VL-NLE Datasets
VQA-X
- VQA v2에 바탕으로 제작됨
- 33k QA pairs (28k images)
- VQA-X의 NLEs는 퀄리티가 낮고 이미지 없이도 맞출 수 있다.
VQA-E
- VQA v2에 바탕으로 제작됨
- explanations이 낮은 퀄리티
VCR dataset
- VQA instance에 상당한 상식 지식을 필요로하는 NLE를 제공한다
- 질문이 어려운 수준이고 정답과 NLE에 대해서 multiple-choice options형태로 주어진다.
e-SNLI-VE

e-SNLI의 설명과 SNLI-VE의 image-sentence pairs를 합쳤다.
Correcting SNLI-VE
- e-SNLI의 설명과 SNLI-VE의 image-sentence pairs를 합쳤다.
- SNLI-VE는 image와 hypothesis가 주어지고 entailment/contradiction/neutral로 분류된다.
- SNLI-VE의 제작 과정상 neural labels에 오류가 생길 가능성이 높았고 실제로도 error수치가 높았다(38.6%). entailment와 contradiction는 1%로 낮았다.
- 39%의 neural label이 수정되었다.
- Ent/Neut/Con비율은 validation에서 39%/20%/41%, test에서 39%/21%/40%이다.
training set에서 false neutrals를 자동적으로 제거하는 방법을 제안하였다. 이미지에서 나오는 5개의 captions에서 실제로 neutral인지에 대한 증거를 제공한다.
i: image-hypothesis pair
Mnli: natural language inference model
pi,c: caption-hypothesis pair
c: caption
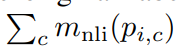
original labels이 중립이지만 model에 caption-hypothesis pair를 넣은 결과 높은 확률로 중립이 아니다라고 나온경우 해당 instance를 데이터셋에서 삭제했다. 해당 연구에서는 Roberta-large 모델을 이용하여 수식 결과에서 entailment와 contradiction class에 대해서 2를 초과한 instance를 삭제하였고 그 결과 neutral labels에서의 error가 39%에서 24%로 낮아졌다.
Adding Explanations to SNLI-VE
- e-SNLI-VE을 위해 e-SNLE의 설명을 소스로 사용하였다.
- e-SNLE는 premise-hypothesis pairs에 맞춰져있고 image-hypothesis pair에 잘 맞지 않는다.
- 단순히 e-SNLI와 SNLI-VE를 합쳤을때 설명들이 36%(incorrect), 22%(correct but there is better choice), and 42%(correct)를 보였다.
Re-annotation: neutral pairs의 설명들을 새로 작성하였다
Keyword Filter: “synonym”, “mention”, “rephrasing”, “sentence”, “way
to say”, and “another word for”와 같이 언어적 특징을 언급하는 키워드가 들어간 설명을 제거하였다. samples subset에서 확인해본 결과 filter된 설명들은 모두 low quality의 설명들이었음을 확인하였다.
Similarity Filter: premise와 hypothesis가 유사할때 low-quality의 explanations이 entailment 예제에서 높게 나왔고 ROUGE-1 score(문장간 유사도 측정)에서 0.57이상나온것들을 제거하였다.
Uncertainty Filter: 높은 불확실성의image-hypothesis쌍이 contradictions에서 낮은 퀄리티의 설명과 상관성이 있었다. mnli(pi,c)의 수식을 이용해 uncertainty를 측정하였다.
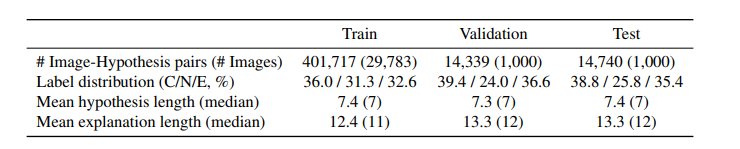
The e-ViL Benchmark
task
- MT (V, L) = a(정답)
- ME(V, L) = e(설명)
- M = (MT , ME) and M(V, L) = a, e
benchmark 측정에 e-SNLI-VE, VQA-X, VCR 3가지 데이터를 사용하였다
- VQA-X: VQA v2 dataset의 이미지, 질문, 정답 세트에 human written 설명이 추가되었다.
- VCR(Visual Commonsense Reasoning): 영화 속 이미지에 대해서 multiple-choice의 질문을 하는 VL
dataset이다.
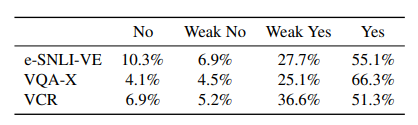
- 12명의 annotator가 각 300개씩, 총 3600갱의 예제에 평가를 내린 결과이다
- yes와 weak yes에 대해 e-SNLI-VE는 82.8%, s VCR과 VQA-X는 각각 87.9%와 91.4%이다.
Evaluation
Evaluation Scores
- SO = ST X SE
- 정답이 틀린경우 score는 0이된다 -> 맞는 정답에 대해서만 설명 score가 나오게됨
- model이 task를 무시하고 좋은 정답만 도출하는것을 막을 수 있다.
Human Evaluation Framework
- 평가자들이 yes, weak yes, weak no,
and no로 이미지와 정답에 대한 설명을 평가하고 이를 1, 2/3, 1/3, 0으로 매칭함 - 부적절한 설명은 3가지로 나뉜다.
- insufficiently justify the answer: 정답“the sea is not calm”에 대해서 “because it’s cloudy”는 충분히 설명을 하지못함
- incorrectly describe the image: dog surfing의 이미지에 대해 “There is a person riding a surfboard on a wave”라 설명을 진행하는 경우
- nonsensical: “a man cannot be a man”
model-dataset pair
- 각 model마다 맞게 답한 300개의 데이터를 랜덤하게 선정하여 평가를 진행하였다(모든 모델들에 대해서 같은 instance로 평가하는건 불가능)
- 모든 모델이 다 맞게 답한 샘플을 사용하면 (1)추후 연구에서 모델의 벤치마크를 측정할때 해당 데이터셋에 대해 모델이 틀린 정답을 낼 경우 벤치마크를 사용할 수 없게 되고,(2)데이터가 편향되어 낮은 성능의 모델도 높은 결과가 나오게될 가능성이 있다.
Models
 ]
]
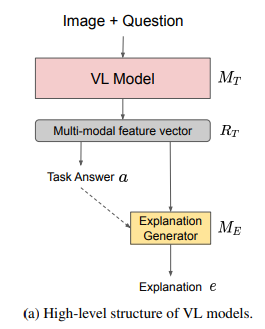
- 존재하는 VL-NLE 모델은 다음과 같은 구조를 보인다
- 이러한 구조의 모델은 질문, 이미지, joint representation, 정답을 조합하여 설명을 도출한다
- PJ-X, FME, RVT가
- PJ-X: MT에서 VQA v2로 pre-train된 MCB network를 사용하였다.
- FME: VQA v2로 pre-train된 UpDown를 사용하였다.
- RVT(Rationale-VT Transformer): varying vision algorithms으로 이미지에서 정보를 추출하는데 사용되고 이 정보를 질문과 정답과 함께 GPT-2에 들어간다. MT로 BERT를 사용하여 object tags와 질문을 입력으로 넣어 정답을 예측한다.
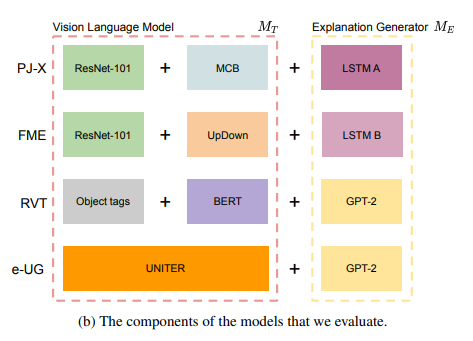
e-UG
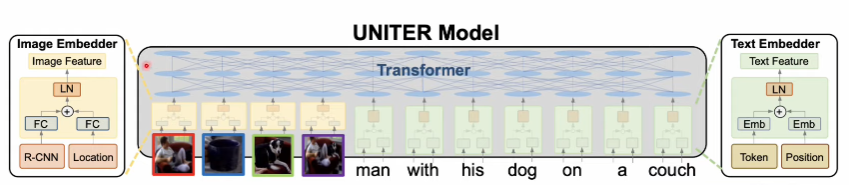
- UNITER + GPT-2 구조
- UNITER는 transformer-based VL model이다
- UNITER의 출력은 image-text pair에서의 word tokens과 image regions의 임베딩이다.
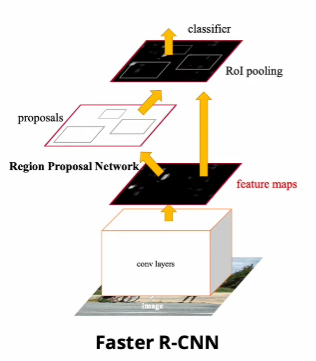
- Faster R-CNN을 통해서 visual features을 추출하고 이미지의 location features을 인코딩하여 이미지가 임베딩된다.
- 임베딩된 이미지와 질문이 testual question과 predicted answer로 GPT-2에 입력으로 들어가 설명을 출력한다.
Training
- training시 각 모델들을 각 데이터마다 학습이된다.
- PJ-X와 FME는 동일하게 ImageNet으로 pre-trained된 ResNet-101을 이용해 image features를 얻어낸다
- VQA-X는 사이즈가 작아 MT models을 VQA v2에서 pre-traine한다.
- RVT는 object tags를 Faster R-CNN에서 얻었다.
- 논문의 모든 모델들에 대해서 MT와 ME를 jointly/separately의 경우를 실험하였다.
- RVT의 경우 MT와 ME를 합쳐서 train해도 차이가 없었다. 이는 설명 생성에 MT의 learnable representation이 반영되지않기 때문이라 본다(RVT에서는 각 이미지의 고정된 object tags가 사용되기때문).
- 다른 모델들에 대해서는 MT와 ME를 같이 training하는것이 도움이 될 수 있기에 두 방법모두 이용해 학습했다.
Hyperparameters
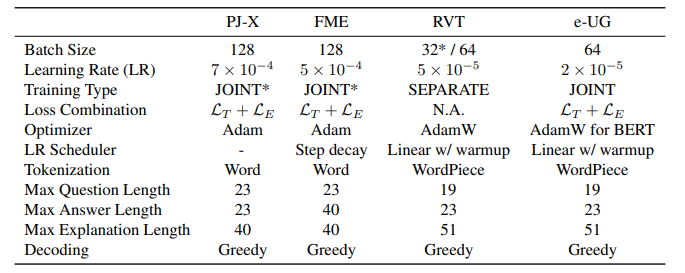
hyperparameters선정에 NLG metrics를 사용하였다.
Results
Human Evaluation
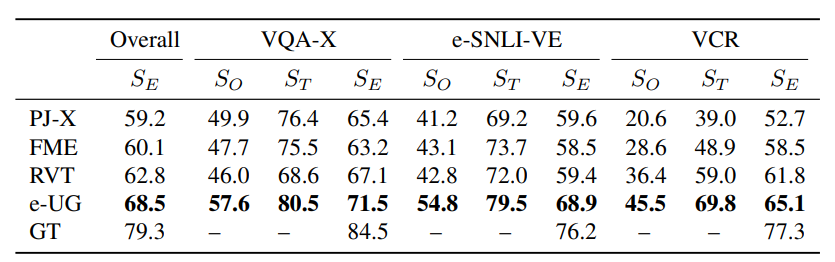
- e-UG가 모든 데이터셋에서 성능이 뛰어났다
- RVT가 GPT-2의 성능으로 PJ-X, FME보다 성능이 더 좋게나왔다.
- VQA-X에서 SE의 점수가 높게 나왔는데 이는 VQA-X데이터셋의 난이도가 낮다고 판단할 수 있다.
- e-UG가 전반적인 SO가 다른 모델들에 비해 높게 나왔다. 이는 UNITER가 다른 MT모델보다 높은 성능을 보이기 떄문이다.

e-UG만 잘 설명하고있다.



Correlation of NLG Metrics with Human Evaluation
human evaluation results are not always reflected by the automatic metrics
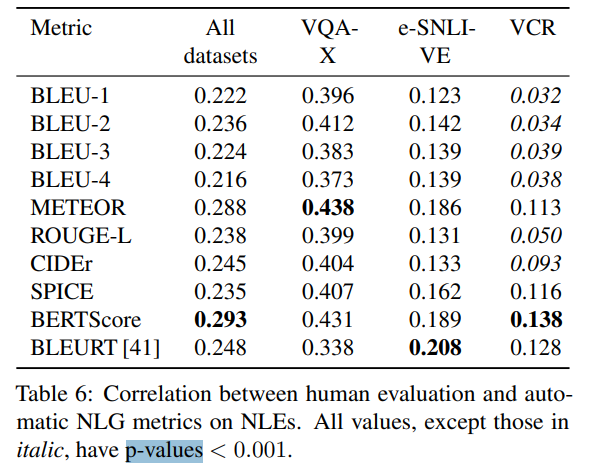
- NLG metric과 human evaluation을 비교한 결과 BERTScore랑 METEOR가 다른 METRIC에 비해 높은 상관관계를 보였지만 절대적으로 낮은 수치이다.
- automatic metrics이 human evaluation results을 반영한다고 보기 어렵다.
- 또한 VQA-X에서는 높고 VCR에서 낮아 데이터셋마다 들쑥날쑥하다.
- VCR에서 낮은 이유는 VCR이 좀더 의미론적이고 복잡하기때문에 같은 현상도 다양하게 설명할 수 있기 때문이다.
- BLEU, ROUGE, CIDER등은 VCR에서 전혀 human evaluation과 상관관계가 없다고 이해할 수 있다.
- n-gram metrics: 두 문장간 유사도를 분석하는 방법
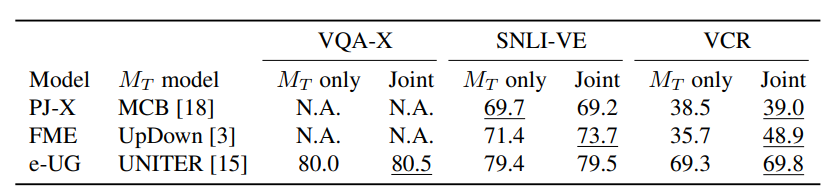
- 논문의 저자는 MT와 ME를 같이 학습할 경우 MT에게 이미지와 질문으로부터 정답뿐만 아니라 설명에 대한 근거를 학습할 수 있어 모델의 표현능력을 MT만 학습할때보다 향상시킬 수 있다고 가설을 세웠다.
- 실험 높아지기했지만 별반 차이가 없다.
Conclusion
- VL-NLE에서 앞으로 나올 모델들의 성능 비교를 위해 e-ViL Benchmark를 만들었다.
- e-SNLI-VE 데이터셋을 제공하였다
- NLG metrics과 human evaluation과 낮은 상관관계를 보인다.
- e-UG모델을 제안하였다.

