
Introduction
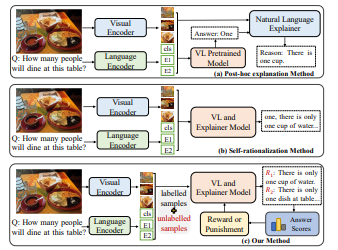
기존방법론
1.Post-hoc explanation Method
UNITER 또는 Oscar과 같은 pre-trained VL models로 정답을 얻고 multi-modal features과 predicted answers을 결합하여 LSTM, Transformer과 같은 language model에 input으로 넣어서 설명을 만들어내는 방법이다.
2.Self-rationalization Method
united VL model을 통해서 정답과 설명을 동시에 생성한다.
challenges
(1) Post-hoc explanation Method에서 decision-making model과 interpretation part가 분리되어있다. 이러한 구조는 decision models이 내놓은 결과에 대한 설명의 신뢰도가 낮을 수 밖에 없다.
(2) Self-rationalization Method:기존 연구에서 straightforward self-rationalization frameworks에서 명시적인 logical relationship modeling이 부족하여 logical inconsistency 문제를 겪는다고 한다.
(3) 위 전력들을 모두 expensive한 human annotated explanation을 필요로 한다.
합리적인 이론적 해석이 model이 맞는 정답을 얻는데 도움을 줄 수 있고 정답이 평가 지표로서 설명에 사용될 수도있다.
S3C에서는 self-critical method으로 reward로 answer scores를 이용하여 model이 answer scores를 향상시키는 방향으로 학습이 되도록한다.
expensive한 human annotated explanation를 해결하고자 추후 model을 unlabelled samples를 사용하는 semi-supervised version으로 확대한다.
self-critical strategy와 semi-supervised learning을 통해서 정답과 설명사이의 연관성과 논리성을 높일 수 있었다.
summary
1) S3C에서 새로운 self-critical VQA-NLE method을 제안하였다. 정답과 설명 쌍을 논리적으로 연결시키고 answering rewards를 통해서 평가한다.
2)VQA-NLE의 semi-supervised learning을 발전시켰다. human-annotated explanation이 없는 많은 양의 샘플들로 모델의 self-interpretability를 향상시켰다. 아마 VQA Natural Language Explanation분야의 첫 semi-supervised learning
3)S3C가 VQA-X와 A-OKVQA 벤치마크 데이터셋에서 sota성능을 보였다.
Related work
Pre-trained models and Prompt learning
Pre-trained models
Pre-trained model은 NLP tasks, VL tasks등 많은 분야에서 적용되고있다. 대부분의 Pre-trained model은 transfomer구조를 사용하고 이전 연구들에서는 fine-tune을 통해서 downstream vl tasks에 적용하였다. 하지만 pre-trained tasks와 downstream tasks의 간극으로 인해서 pre-trained model의 성능이 제한되고 이러한 문제로 prompt learning이 제안되었다.
논문에서는 image caption task를 기반으로한 pre-trained model을 사용하였다. 다른 image feature regression or mask language tokens들과 같은 pre-train tasks는 설명에 대한 성능 향상을 기대할 수 없다고 밝혀져 image caption task를 사용하였다.
Semi-supervised learning
별 내용없더라
Method
Our aim is to strengthen the logical consistency between answer-explanation pairs and improve the reliability of the rationales
개요
s3c는 “Answer-Explanation Prompt”모듈과 “Self-Critical Reinforcement”모듈로 구성되어있다. prompting mechanism에서 정답과 설명을 생성하고 answer scores를 이러한'reason'을 평가하기위해 reward로 변환하는 self-critical module을 고안하였다. 이러한 전력은 라벨링되지않은 QA Pair를 쉽게 사용할 수 있게하여 trainind data수를 증가하고 model의 self-interpretability를 향샹실킬 수 있다.
Pre-trained Vision-Language Backbone
CLIP vision encoder와 pre-trained image caption model을 basic backbone으로 채택하였다. pre-training에서는 VL model는 CLIP으로부터의 Prefix를 사용하여 language model을 fine-tune한다
※ Prefix : Clip image encoder를 통해서 추출된 image embedding vectors
CLIPCAP
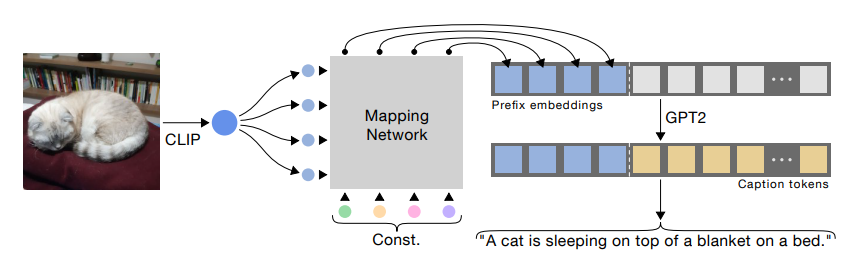
요약:
CLIP와 GPT-2를 이용해서 CLIPCAP을 만들었다. 논문의 핵심 주제는 CLIP에서 나온 image vectors와 text embedding vector을 연결하는 방법론이다. MAPPING NETWORK를 이용하여 CLIP embedding을 GPT-2 space로 번역을 하여 연결지었다.
CLIPCAP의 방법론이 이 논문에서도 동일하게 적용되고있다. image I와 question Q를 answer-explanation sequences의 prefix로 사용된다.
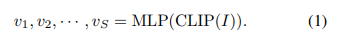
(1) CLIP을 통해 image features을 얻고 해당 image features을 768차원의, image sequence length S = 10으로 변환시킨다. 변환하는 작업을 MLP를 이용해 수행하게된다. 학습시에는 MLP만 train하게된다.
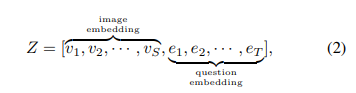
(2)질문 Q에서 각 글자 qt는 pre-trained caption model을 통해서 et의 word embedding에 대응된다. 결과적으로 z는 concatenate된 prefix
Beam Search
beam search는 평가값이 우수한 일정 개수의 확장 가능한 노드만을 메모리에 관리하면서 최상 우선 탐색을 적용하는 기법이다.
Answer-Explanation Prompt Module
prompting mechanism: TEXT를 문장형태로 고쳐서 text encoder에 넣는 방식
Base Answer Template
논문에서 S3C의 핵심 아이디어는 answer score를 평가 지표로 사용하는것이다.
- base answer template Za = [Z;⟨answer⟩]
- Z와 natural language tokens “the answer is”를 이용해서 model이 정답을 생성해내게한다.
- A는 ground-true answer label이다.
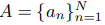
- Za에 대해서 answer loss를 다음과 같이 구한다.
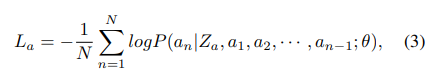
그러고 아래에서 말하는데 average probability를 얻을 수 있다는데 갑자기? 어떻게? 왜?
Moreover, based on the indexes of ground-true answers, we can acquire average probability pbθ(A) as our base answer score.
Explanation Generation Template
앞서 “the answer is”라는 prompt로 정답을 도출 한것처럼 설명도 같은 방식으로 생성한다.
Ze = [Z;⟨reason⟩]
Self-Critical Reinforcement Module
이 module파트에서는 beam search알고리즘을 통해서 searching space를 확장하고 설명 후보들의 집합을 만든다.
Candidate Explanation Generation
VL model 확률 분포에서 매 time step마다 beam search를 이용해서 top-K words를 얻고 생성된 문장들은 설명 후보군 집합에 들어간다.
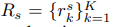
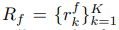
Rs는 unlabelled된 데이터에서 얻은 rationale(근거들), Rf는 labelled된 샘플에서 얻은것이다. 이렇게 여러 근거들을 모아 놓음으로서 얻는 장점은 다음과 같다
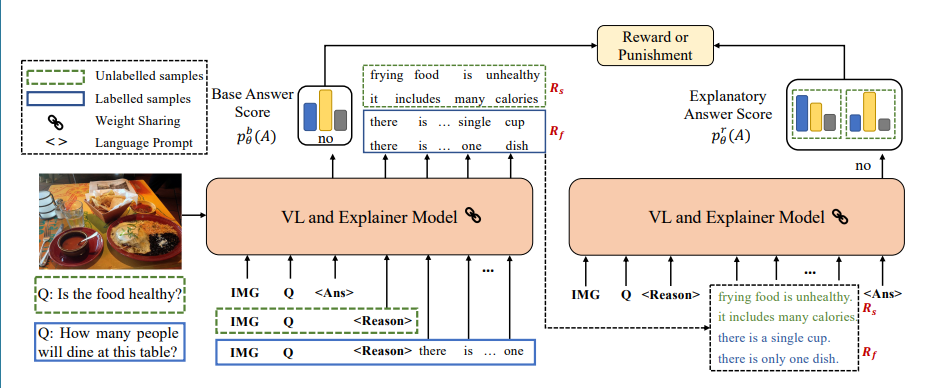
(1)Larger search space
그림에서 질문에 대한 설명으로 “frying food is unhealthy” 와 “it includes many calories”을 얻었는데 두 대답 모두 no라는 정잡을 잘 설명한다. 하나의 설명만 도출할때보다 더 높은 설명의 신뢰도를 보여줄 수 있다.
(2) Avoid overfitting
labelled samples에 대해서 이미 human explanations으로 model을 train할 수 있지만 이는 한쪽으로 치우쳐질 수 있고 전에도 말했다시피 여러가지 답이 존재할 수 있기때문에 sequence sampling strategy를 통해서 model의 overfitting을 막을 수 있다.
학습과정에서 labelled, unlabelled samples이 mini-batch에 통합되서 들어가기 때문에 Rf와 Rs도 R로 통합한다.
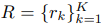
Self-Critical Reward
ideal rational이 model로 하여금 정답을 더 잘 추론할 수 있다는 아이디어를 바탕으로 answer score가 self-critical rewards로 바뀌어 candidate explanation들을 평가할 수 있다.
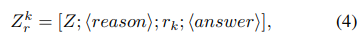
수식(4)는 평가를 위한 새로운 input template로 Z와 그에대한 설명 후보 rk로 template를 구성하여 다시 model에 fed back하여 정답A에 대한 확률을 얻는다.
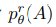
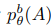
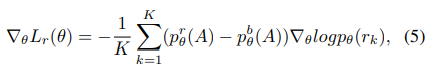
수식(5)설명:
- 강화학습을 적용하여 학습
- pθ(rk)는 k-th explanations의 확률
Loss
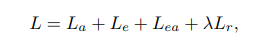
전반적인 loss function은 다음과 같다. 람다를 통해 다른 종류의 loss 비율을 조절한다.
궁금점
- 어떻게 확률을 얻는지 감이 안옴
- base 확률과 평균 확률로 강화학습을 진행하여 더 좋은 성능을 얻는다는데 방법에 대한 자세한 설명 좀 알고싶다!
Datasets
총 4개의 데이터셋을 사용한다.
-
VQANLE datasets- VQA-X, A-OKVQA
A-OKVQA가 VQA-X와 비교하면 질문에서 좀더 상식을 필요로한다. -
VQA & OK-VQA
VQA와 OK-VQA의 대량의 unlabelled 데이터를 이용해 semi-supervised learning을 한다.
Evaluation Measures
Automatic Metering
BLEU, METEOR, ROUGE-L,SPICE, CIDEr을 통해 평가를 진행하였다.
Human Evaluation
- 3명이서 설명이 정답을 정당화하는지 판단한다.
- “yes, weak yes, weak no , no"로 판단하고 1, 2/3, 1/3, 0으로 매칭된다.
- 부적절한 설명에대해서 irrelevant explanations, insufficient explanation, meaningless explanations으로 구분
Quantitative evaluation
Automatic Evaluation
- BLEU-4, METEOR, ROUGE-L, SPICE, CIDEr, Answer precision, Human evaluation을 통해서 평가측정
- 평가에서 “unfiltered”는 정답이 맞는지와 상관없이 설명이 평가된것을 말한다.
- “filtered”는 정확한 정답에서만 설명을 평가한것이다.
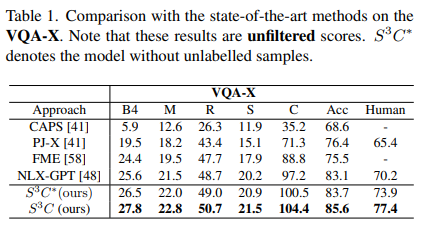
- NLX-GPT가 더 성능좋은 pre-trained VL model과 더 많은 양의 pre-trained datasets을 사용했지만 s3c의 성능이 더 좋았다.
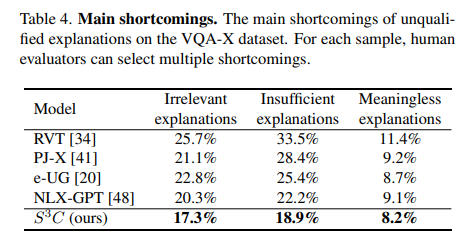
평가자들에게 VQA-X dataset에 대해서 미달된 설명에 대해 irrelevant explanations, insufficient explanation, meaningless explanation로 분류해달라하였고 위와 같이 결과가 나왔다.

저도 개발자인데 같이 교류 많이 해봐요 ㅎㅎ! 서로 화이팅합시다!