https://github.com/VSFe/Tech-Interview/blob/main/02-OPERATING_SYSTEM.md 의 면접질문들에 대한 답을 나름대로 정리한 포스팅
시스템 콜
-
사용자 프로그램이 I/O 작업과 같은 커널 모드 명령어를 수행하고 싶을 때 사용하는 인터페이스
- 즉, 사용자 프로그램이 OS에게 커널 모드 명령어 실행을 요청하는 것
-
System call 을 호출하면 사용자 프로그램에서 OS로 CPU 가 넘어간다.
-
CPU는 OS의 핵심 부분인 커널 주소 공간에 접근하여 커널 모드 명령어를 수행한 뒤, 다시 사용자 프로그램에게 CPU 를 넘긴다.
시스템 콜의 예시
-
마우스를 움직이거나 키보드 입력을 할 때, system call 을 호출한다.
-
프로세스를 생성하거나 종료할때도 system call 을 호출한다.
-
특정 파일 내용을 복사하여 다른 파일에 붙여 넣을때도 system call 을 호출한다.
시스템 콜의 실행 과정
-
각 system call 에는 번호가 할당된다
-
OS 는 system call 번호와 system call 처리 루틴이 위치한 주소가 매핑된 system call 테이블을 갖고 있다.
-
OS는 테이블을 참조하여 system call 번호와 매핑된 system call 처리 루틴을 실행한다.
시스템 콜의 유형
-
프로세스 컨트롤
-
프로세스 생성 및 종료
-
프로세스 속성 값 확인 및 지정
-
메모리에 프로세스 적재 및 실행
-
-
파일 매니지먼트
-
파일 생성 및 삭제
-
파일 열기, 닫기, 읽기, 쓰기 등
-
-
디바이스 매니지먼트
-
디바이스 연결 및 해제
-
디바이스의 입출력 관리
-
-
정보 관리
-
시스템 시간 확인 및 설정
-
시스템 데이터 확인 및 설정
-
-
보안
-
통신
Dual Mode
-
OS와 사용자 프로그램은 시스템 자원을 공유한다.
-
사용자 프로그램에 제한을 두지 않으면 중요한 시스템 자원을 망가뜨려 OS에게도 악영향을 미칠 수 있다.
-
따라서 사용자 프로그램이 시스템 자원에 접근하지 못하도록 하는 보호 장치가 바로 Dual Mode 이다.
-
사용자 프로그램을 실행할 수 있는 User mode 와 시스템 자원에 접근, 조작할 수 있는 Kernel mode가 있다.
-
이를 통해 악의적인 사용자 프로그램이 시스템 자원과 OS에게 악영향을 끼치지 않도록 보호할 수 있다.
- 만약 User mode 에서 시스템 자원에 접근하는 Kernel mode 명령어를 실행하려고 시도하면 trap (소프트웨어 인터럽트) 을 발생시킨다.
인터럽트
-
하드웨어 장치에서 예외상황이 발생하여 처리가 필요한 경우에 CPU에게 이를 알리는 것
- 타이머나 하드웨어가 발생시킨다.
-
또는 사용자 프로그램이 커널 모드 명령어를 실행하기 위해 의도적으로 소프트웨어 인터럽트를 발생시키거나, 사용자 프로그램의 오류 발생으로 소프트웨어 인터럽트를 발생시켜 CPU에게 처리가 필요한 예외 상황 발생을 알릴 수 있다.
인터럽트 처리 과정
-
인터럽트에는 각각의 번호가 할당되어 있다.
-
인터럽트 벡터 테이블에는 인터럽트 번호와 매핑되는 인터럽트 벡터가 저장되어 있다.
- 인터럽트 벡터는 인터럽트 처리 루틴의 시작 주소이다.
-
CPU는 인터럽트 발생 시, 현재 진행사항을 저장한 후, 테이블을 참조하여 알맞는 인터럽트 처리 루틴을 실행한다.
Polling vs Interrupt
-
Polling 은 대상을 주기적으로 감시하다가 예외 상황이 발생하면 해당 상황을 처리하는 루틴을 실행한다.
-
CPU가 주기적으로 장치들의 상태를 파악해야 한다.
- CPU의 자원 낭비
-
CPU 작업이 진행되는 동안은 상태 파악이 힘들다.
- 데이터 손실 위험 ↑
-
-
반면 Interrupt 는 장치가 CPU에게 예외 상황이 발생했으니 해결해달라고 직접 요청하는 방식이다.
- CPU 자원 낭비가 적고 데이터 손실 위험 ↓
Hardware, Software 인터럽트
-
Hardware 인터럽트
-
일반적인 인터럽트를 지칭한다.
-
하드웨어 상에서 발생한 예외 상황을 CPU에게 알린다.
-
예시
-
전원에 문제가 생겼을 때
-
I/O 작업이 완료됐을 때
-
타이머가 완료됐을 때
-
-
-
Software 인터럽트
-
프로그램 내부에서 발생한, 프로그램이 처리 불가능한 예외 상황을 CPU 에게 알린다.
-
trap 이라고도 한다.
-
예시
-
system call
-
잘못된 메모리 공간에 접근을 시도할 때
-
-
다중 인터럽트 처리
-
동시에 2개 이상의 인터럽트가 발생하는 다중 인터럽트 처리 방식에는 크게 2가지가 있다.
-
Sequential 방식
-
Interrupt Disabled 상태
-
중단할 수 없는 인터럽트 처리 루틴 실행 중에 다른 인터럽트가 들어온다면, 새로 들어온 인터럽트 요구를 무시한다.
-
이전에 실행중이던 인터럽트 처리 루틴이 끝난 후에 새로 들어온 인터럽트 처리 루틴을 실행한다.
-
-
Nested 방식
-
Interrupt Enabled 상태
-
중단할 수 있는 인터럽트 처리 루틴 실행 중에 다른 인터럽트가 들어온다면, 새로 들어온 인터럽트의 우선순위를 체크한다.
-
둘 중 우선순위가 높은 인터럽트의 인터럽트 처리 루틴을 실행한다.
-
이후 우선순위가 낮은 인터럽트의 인터럽트 처리 루틴을 실행한다.
-
프로세스
- code, data, stack 영역이 메모리에 올라와 실행중인 프로그램을 프로세스라 한다.
프로그램, 프로세스, 스레드
-
프로그램
- 특정 목적을 수행하기 위한 명령어들의 집합
-
프로세스
- 메모리에 올라온 실행중인 프로그램
-
스레드
-
프로세스 내부에 존재하는 여러개의 CPU 수행 단위
-
각 스레드마다 Program Counter, 레지스터, stack 과 같은 CPU 수행 관련 정보를 별도로 갖는다.
-
메모리 주소 공간, 프로세스 상태와 같은 프로세스 정보들은 모두 공유한다.
-
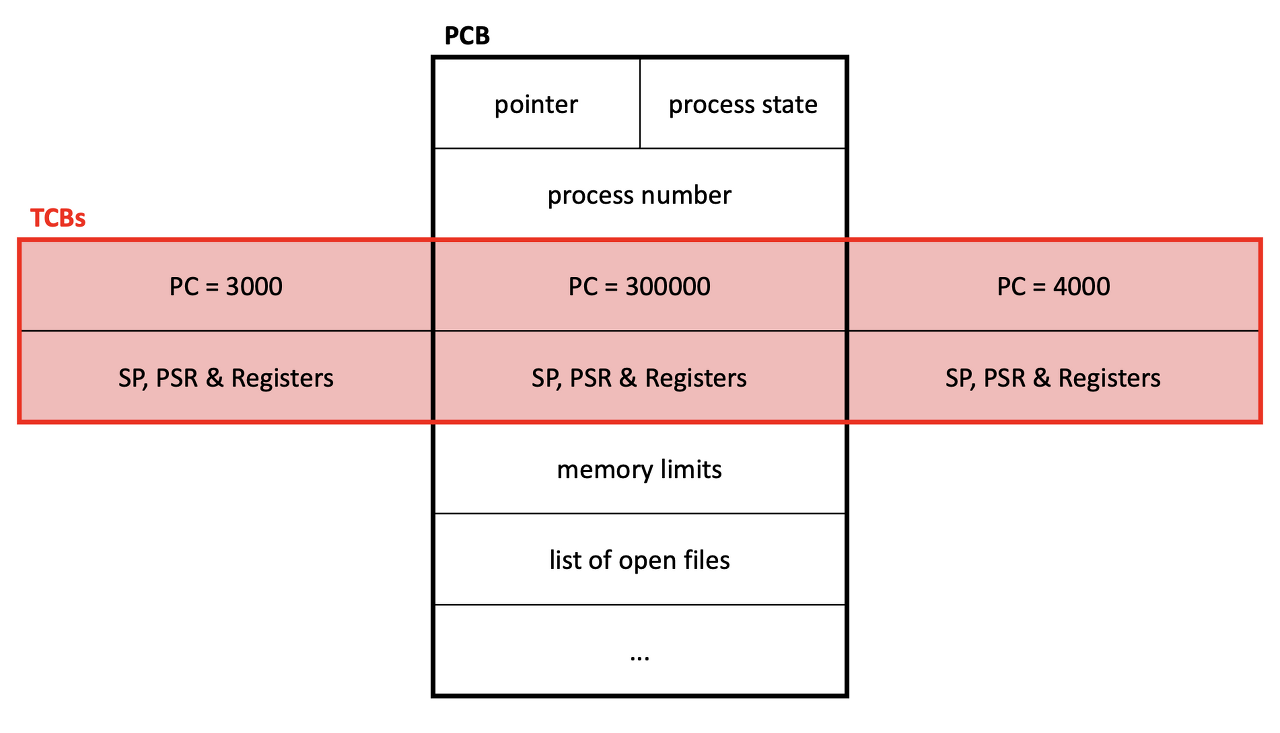
PCB
-
Process Controll Block
-
OS가 프로세스를 관리하기 위해 각각의 프로세스마다 유지하는 정보
-
프로세스 상태와 번호
-
Program Counter, 레지스터
-
메모리의 위치 정보나 파일 관련 정보
-
-
OS에 의해 CPU 를 사용하는 프로세스가 전환되기 때문에, CPU를 빼앗기기 직전의 작업 정보들 (프로세스 문맥) 을 저장해야 한다.
- PCB 는 프로세스 문맥의 일종이다.
스레드는 PCB를 갖고 있을까?
-
스레드는 PCB 대신 TCB를 갖고 있다.
- Thread Control Block
-
따라서 스레드의 문맥 정보는 TCB에 저장된다.
-
TCB는 PCB 내에 저장된다.
- 스레드가 늘어나면 PCB 내의 TCB 개수도 늘어난다.
프로세스의 생성
-
fork()와exec()2가지 방식으로 프로세스를 생성할 수 있다. -
forK()system call-
부모 프로세스가 자식 프로세스를 복제 생성한다.
-
자식 프로세스는 부모의 Program Counter 를 그대로 복제한다.
-
부모 프로세스에서
fork()의 반환값은 자식 프로세스 번호이다. -
자식 프로세스에 write 가 발생하지 않는다면 부모 프로세스의 주소 공간을 그대로 사용한다.
-
자식 프로세스에 write 가 발생한다면 부모 프로세스의 자원들을 복사하여 자식 프로세스의 새로운 주소 공간을 만든다. (copy-on-write)
- 이 경우, 부모 프로세스와 자식 프로세스 모두 자신의 주소 공간을 갖는다.
-
-
exec()system call-
부모 프로세스의 주소 공간과 프로세스 정보를 자식 프로세스가 사용하도록 완전히 덮어 씌운다.
- 이전 프로세스 (부모 프로세스) 로 돌아갈 수 없다.
-
자식 프로세스는 프로그램의 첫 주소부터 명령어를 실행한다.
-
부모 프로세스를 자식 프로세스가 완전히 덮어쓰므로, 자식 프로세스의 주소 공간만 남게된다.
-
좀비 프로세스 & 고아 프로세스
-
좀비 프로세스
-
프로세스가 작업을 모두 완료하면
exit()system call 을 호출하여 OS가 프로세스를 종료하도록 한다. -
OS는 부모 프로세스에게 자식 프로세스의 종료를 알리고, 자식 프로세스에게 할당된 자원들을 모두 다시 가져간다.
-
그러나 부모 프로세스가
wait()system call 을 호출하기 전까지 자식 프로세스는 상태와 PID를 여전히 가지고 시스템 프로세스 테이블에 남아있다.- 이렇게 남아있는 자식 프로세스를 좀비 프로세스라 한다.
-
좀비 프로세스는 이미 자원을 반납했기 때문에 시스템 리소스를 소모하지 않는다.
-
그러나 PID는 여전히 갖고 있기 때문에 대부분의 PID를 좀비 프로세스가 차지한다면 다른 프로세스의 실행을 방해할 수 있다.
-
-
고아 프로세스
-
부모 프로세스가 자식 프로세스보다 먼저 종료되면, 자식 프로세스가 부모가 없는 고아 프로세스가 된다.
-
UNIX 는 고아 프로세스의 새로운 부모 프로세스를 init 프로세스로 지정하여 자식 프로세스가 좀비 프로세스가 되지 않도록 한다.
- init 프로세스는 주기적으로
wait함수를 호출한다.
- init 프로세스는 주기적으로
-
데몬 프로세스
-
부팅 시 자동으로 켜지며, 서비스의 요청에 대해 응답하기 위해 오랫동안 실행중인 백그라운드 프로세스
- unix 에서
d로 끝나는 프로세스들로,inetd,httpd,sshd등이 있다.
- unix 에서
-
터미널 입력을 받지 않고 스스로 동작한다.
-
Parent PID 가 1 (init 프로세스) 이거나 다른 데몬 프로세스이다.
init 프로세스
-
시스템 부팅 중 최초의 프로세스로, 프로세스 트리의 루트 노드에 위치한다.
- 프로세스 식별자 1을 갖는다.
-
시스템이 종료될 때까지 계속 실행되는 데몬 프로세스이다.
-
다른 모든 프로세스의 직간접적으로 부모 프로세스이다.
-
주기적으로 고아 프로세스들을 입양한 후
wait()을 실행한다.- 좀비 프로세스 제거
프로세스 주소공간
-
프로세스가 할당 받은 메모리 공간을 관리하는 방식, 구조를 프로세스 주소 공간이라 한다.
-
프로세스의 주소 공간은 0번지부터
-
Text Segment
- 프로그램 코드 (기계어 코드) 가 들어간다.
-
Data
- 초기화 된 전역 변수나 상수 영역
-
BSS (Block Started by Symbol)
- 초기화가 이루어지지 않은 전역 변수 영역
-
Heap
-
런타임시 크기가 결정되는 동적 공간
- 사용자에 의해 공간이 동적으로 할당된다.
-
낮은 주소에서 높은 주소 방향 (스택 방향)으로 데이터가 쌓인다.
-
할당한 공간의 주소는 스택에 저장된다.
-
-
Stack
-
지역 변수와 주소가 저장된다.
-
높은 주소에서 낮은 주소 방향 (Heap 방향) 으로 데이터가 쌓인다.
-
함수가 호출될 때마다 stack frame 이 쌓이고, 함수가 종료되면 stack frame 이 제거된다.
-
-
초기화하지 않은 변수들은 어디에 저장될까?
- 초기화하지 않은 전역 변수는 BSS에 저장된다.
Stack 과 Heap 의 크기
-
스택과 힙의 크기는 메인 메모리의 크기를 넘을 수 없다.
- 한정된 크기
-
스레드가 생성될 때, 스택도 같이 생성되어 스택의 크기가 결정된다.
- 스택의 크기는 고정된다.
-
힙의 크기는 프로세스 시작 시 설정되지만 메모리 할당이 많아짐에 따라 힙의 크기가 늘어날 수 있다.
Stack 과 Heap 의 접근 속도
-
스택이 더 빠른 접근 속도를 갖는다.
-
스택은 일반적으로 함수의 지역 변수와 같은 작은 데이터가 저장된다.
- 캐싱이 쉽다.
-
스택은 스택 프레임 내에서만 데이터를 접근 및 조작한다.
- 따라서 단순한 정수 연산을 통해 데이터에 접근할 수 있다.
-
반면 힙은 객체 인스턴스와 같은 대용량 데이터가 저장된다.
- 캐싱이 어렵다.
-
프로세스 내의 여러 스레드가 데이터에 접근 및 조작한다.
-
메모리 할당 및 해제에 복잡한 분석이 필요하다.
-
스택 대비 더 많은 명령어 실행이 필요하다.
-
스택과 힙을 분할하는 이유
-
힙만 사용하지 않는 이유
-
힙은 느리고, 메모리 파편화가 발생할 수 있다.
-
따라서 힙만 사용하면 비효율적이다.
-
-
스택만 사용하지 않는 이유
-
스택은 현재 실행중인 함수의 스택 프레임 내부의 데이터들에만 접근할 수 있다.
-
다른 함수에서 생성한 객체에 접근할 수가 없다.
-
-
따라서 스택과 힙을 구분하여 둘을 모두 사용하는 것이다.
스레드의 주소 공간
-
각 스레드가 개인적으로 사용하는 코드 영역과 데이터 영역이 있지만, 기본적으로는 프로세스의 코드 영역과 데이터 영역을 공유한다.
-
프로세스의 힙 영역은 공유한다.
-
스택 영역은 각 스레드마다 독자적으로 생성하여 갖는다.
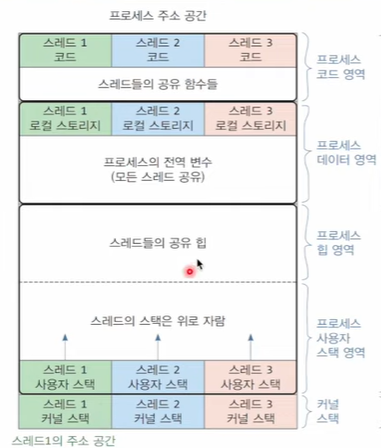
스택 영역과 힙 영역, 자료구조와의 연관성
-
힙 영역은 자료구조의 힙과 연관이 없다.
-
스택 영역은 자료구조의 스택과 연관이 있다.
-
스택이 접근할 수 있는 데이터는 top 인덱스 부분 밖에 없다.
-
스택 영역 역시 마찬가지로 현재 실행중인 함수의 스택 프레임이 위치한 맨 위의 스택 프레임에만 접근할 수 있다.
-
만약 A 함수가 B 함수를 호출하면, A 함수 스택 프레임 위에 B 함수 스택 프레임이 쌓이게 되고
-
B 함수가 종료되면 B 함수 스택 프레임은 제거되고, A 함수 스택 프레임이 맨 위의 스택 프레임이 된다.
-
이는 마치 함수의 호출이
push, 함수의 종료가pop인 것과 같다.
-
단기, 중기, 장기 스케줄러
-
단기 스케줄러
-
CPU 스케줄러
-
어떤 프로세스에게 CPU를 줄지 결정한다.
-
-
중기 스케줄러
-
Swapper
-
메모리에 너무 많은 프로세스가 올라가 있다면, 메모리의 여유공간 마련을 위해 프로세스 몇 개를 통째로 메모리에서 쫓아낸다.
-
-
장기 스케줄러
-
메모리에 올라갈 프로세스들을 결정한다.
-
time sharing system 에서는 사용하지 않는다.
- time sharing system 에서는 프로그램을 실행시키면, 바로 메모리에 올라가 CPU를 사용할 수 있는 상태가 된다.
-
현대 OS에서 사용하는 스케줄러
- 현대 OS (Time Sharing System) 에서는 장기 스케줄러는 사용하지 않는다.
프로세스의 상태
-
Running
- CPU를 점유하며 명령어를 실행중인 상태
-
Ready
- CPU를 기다리는 상태
-
Blocked
-
CPU를 주어도 당장 명령어를 실행할 수 없는 상태
-
I/O 와 같은 이벤트의 완료를 기다리는 상태
-
이벤트가 완료되면 Ready 상태로 전환된다.
-
-
Suspended
-
중기 스케줄러나 사용자 요청등으로 프로세스 수행이 정지된 상태
-
프로세스가 메모리에서 통째로 쫓겨나 디스크로 swap out 된다.
-
외부에서 resume 해주어야 다시 메모리로 올라올 수 있다.
-
Preemptive & Nonpreemptive
-
Preemptive
- 프로세스로부터 CPU를 강제로 빼앗는 방식
-
Nonpreemptive
- 프로세스가 CPU를 자진 반납하는 방식
Memory 가 부족할 경우, 프로세스의 상태 변화
-
중기 스케줄러에 의해 디스크로 swap out 된다.
- 프로세스는 suspended 상태가 된다.
컨텍스트 스위칭
-
현재 실행중인 프로세스 A에게서 CPU를 빼앗아 프로세스 B에게 CPU를 주게되면
-
현재 실행중인 CPU의 레지스터, Program Counter 와 같은 문맥 정보들을 프로세스 A의 PCB에 저장하고
-
프로세스 B의 PCB에 저장되어 있는 프로세스 B의 문맥정보들을 CPU에 가져와 실행한다.
-
이러한 일련의 과정들을 컨텍스트 스위칭이라 한다.
프로세스와 스레드의 컨텍스트 스위칭
-
프로세스간의 컨텍스트 스위칭이 발생하면
-
현재 실행중인 프로세스의 context 를 백업
-
CPU 캐시를 비움
-
다른 프로세스 공간을 침범하지 않도록
-
TLB 를 비움
-
MMU를 변경
-
-
-
그러나 스레드간의 컨텍스트 스위칭이 발생하면
-
현재 실행중인 스레드의 context 를 백업해주기만 하면된다.
-
캐시를 비우는 큰 오버헤드가 발생하지 않기 때문에 프로세스 간의 컨텍스트 스위칭 대비 상대적으로 빠르다.
-
프로세스 스케줄링 알고리즘
-
FCFS
-
First-Come First-Served
-
먼저 도착한 프로세스가 CPU를 점유한다.
- Nonpreemptive 방식
-
짧은 작업시간을 갖는 프로세스가 먼저 온 긴 작업시간을 갖는 프로세스때문에 오랜시간 기다리게 된다.
- 평균 대기 시간 ↑
-
-
SJF
-
Shorted Job First
-
CPU burst time 이 가장 짧은 프로세스가 먼저 CPU를 점유한다.
- preemptive, nonpreemptive 방식 둘다 있다.
-
가장 작은 average waiting time 을 갖는다.
-
긴 CPU burst time 을 갖는 프로세스는 영원히 CPU를 가지지 못할 수 있다.
-
CPU burst time 은 추정값이다.
-
-
Round Robin
-
각 프로세스는 동일한 크기의 CPU 할당 시간을 갖는다.
-
할당 시간이 끝나면 CPU를 빼앗기고 ready queue 의 맨 뒤로 간다.
- preemptive 방식
-
각 프로세스들의 response time 이 짧다.
-
-
Multi-level Queue
-
ready queue 를 여러개로 분할하여 각 ready queue 마다 다른 CPU 스케줄링 알고리즘을 적용할 수 있다.
-
여러개의 ready queue 간에 이동이 가능한 Multi-level Feedback Queue 도 있다.
-
RR 과 Time Slice
-
Time Slice (CPU 할당 시간) 가 아주 커지면 FCFS 방식이 된다.
- 짧은 response time 이라는 RR의 장점이 희미해진다.
-
Time Slice (CPU 할당 시간) 가 아주 작아지면 Context Switch 가 빈번히 발생하여 큰 오버헤드가 발생한다.
싱글 스레드 CPU 에서 상시로 돌아가야 하는 프로세스가 있는 경우, 적절한 CPU 스케줄링 알고리즘
-
Round Robin
-
FCFS 의 경우, 상시로 돌아가야 하는 프로세스가 CPU를 무한정 점유하게 되므로 안되고
-
SJF 의 경우, 상시로 돌아가야 하는 프로세스가 CPU를 선점하지 못하고 starvation 이 발생하므로 안된다.
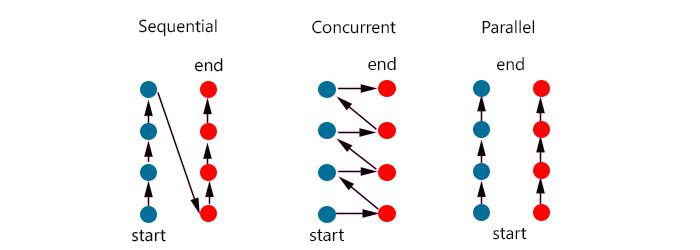
동시성 vs 병렬성
-
동시성은 여러개의 작업들을 빠른 속도로 번갈아가며 하나씩 조금씩 수행한다.
-
이러면 마치 여러개의 동작이 동시에 끝난것처럼 보인다.
-
그러나 실제로는 하나의 작업을 조금씩 번갈아가며 수행한 것이다.
-
-
병렬성은 작업을 실행하는 주체가 여러개있어, 여러개의 작업을 각각의 주체들이 분담하여 수행한다.
- 여러개의 작업이 동시에 수행된다.
Multi-level Feedback Queue
-
Multi-level Feedback Queue 는 입출력 중심의 프로세스와 CPU 작업 중심 프로세스를 분류하여 response time과 turn-around time을 모두 줄이려는 목표를 가지고 있다.
-
RR은 response time 은 작지만, 모든 프로세스들을 교대로 실행하기에 turn-around time 은 크다.
-
따라서 짧은 CPU burst time 을 갖는 프로세스들은 높은 우선순위 큐에서 처리하고, 긴 CPU burst time 을 갖는 프로세스들은 낮은 우선순위 큐로 이동시켜 처리함으로써 response time 과 turn-around time 을 모두 효율적으로 줄일 수 있다.
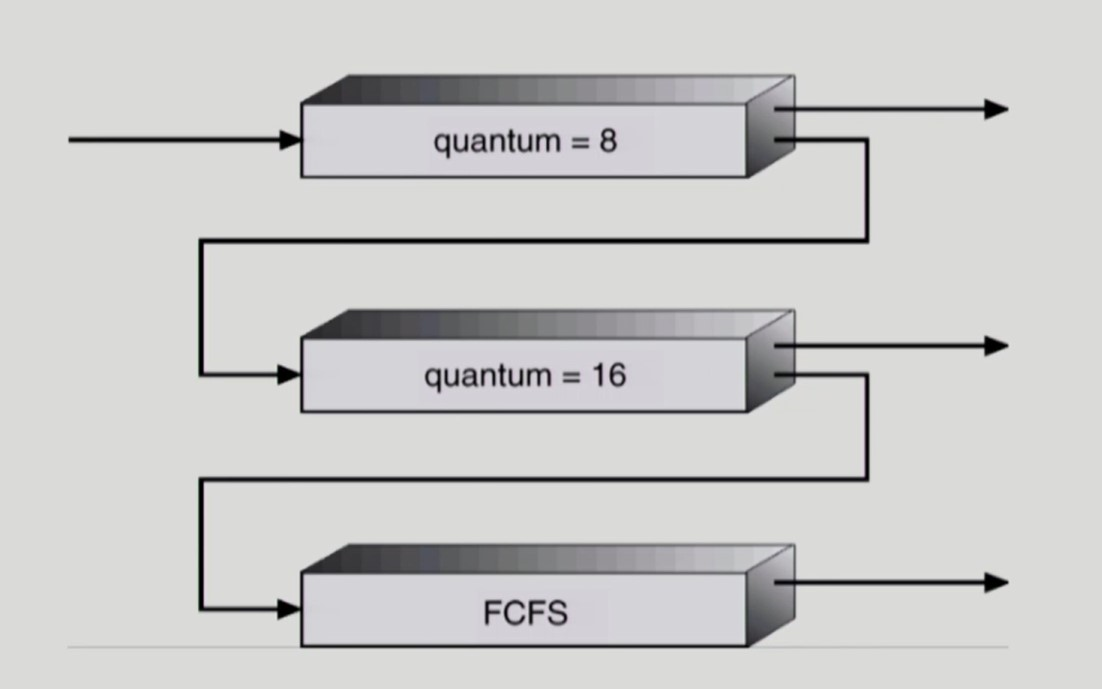
- 높은 우선순위 큐에서는 짧은 시간 CPU를 점유하도록 한다.
- 해당 큐에서 끝나지 못한 CPU bound 프로세스들은 차상위 큐로 내려간다.
- 프로세스의 response time 을 줄인다.
- 낮은 우선순위 큐에서는 긴 시간 CPU를 점유하도록 한다.
- 긴 시간 CPU를 주거나 FCFS 방식을 사용하여 프로세스의 turn-around time 을 줄인다.
FCFS 스케줄러는 쓸모가 없을까?
-
CPU burst time 이 긴 CPU bound 프로세스들은 RR을 적용하면 프로세스들의 turn-around time 이 엄청나게 길어진다.
-
따라서 MLFQ 의 낮은 우선순위 큐에 쌓이는 CPU bound 프로세스들은 FCFS 방식으로 처리하는 것이 turn-around time 측면에서 효과적이다.
스레드 스케줄링
-
Local 스케줄링
-
OS가 존재를 인식하지 못하는 User level thread 가 해당된다.
-
사용자 프로세스 내부에서 자체적으로 어떤 스레드에게 CPU를 줄 지 결정한다.
-
-
Global 스케줄링
-
OS가 존재를 인식하는 kernel level thread 가 해당된다.
-
OS 의 CPU 스케줄러가 어떤 스레드에게 CPU를 줄 지 결정한다.
-
세마포어와 뮤텍스
-
공유 데이터를 조작할 때, 공유 데이터의 일관성을 위해 여러 프로세스간의 동기화가 필요하다.
- 이러한 프로세스 동기화를 코드를 사용해 해결하는 것은 어렵다.
-
이러한 복잡한 해결방식을 추상화한 자료형인 세마포어를 사용해 쉽게 해결할 수 있다.
-
세마포어 자원이 있는 경우, 프로세스는 공유 데이터에 접근 가능
-
세마포어 자원이 없는 경우, 프로세스는 공유 데이터에 접근 불가
-
세마포어의 정수값은 자원의 개수를 의미한다.
-
만약 세마포어의 정수값이 0 또는 1만 가능하고, Critical Section Problem 을 해결하기 위해 사용한다면 이를 뮤텍스라 한다.
-
critical section problem: 하나의 프로세스가 공유 데이터를 접근, 조작하는 코드를 실행할 때 다른 모든 프로세스들은 해당 코드 영역에 들어갈 수 없어야 한다.
-
뮤텍스를 획득한 경우 critical section 에 접근 가능
-
뮤텍스가 없는 경우 critical section 에 접근 불가
-
이진 세마포어 vs 뮤텍스
-
공통점은 두 자료구조 모두 0 도는 1로 이루어진 정수값을 가진다.
-
뮤텍스는 lock/unlock 으로 사용하며, Critical Section 의 Mutual exclusion 을 보장한다.
- 뮤텍스는 뮤텍스를 가져간 스레드가 소유권을 가지므로 작업을 마치고 뮤텍스를 반납해야 다른 스레드가 뮤텍스를 얻을 수 있다.
-
이진 세마포어는 다른 세마포어와 마찬가지로 resource (프로세스 공유 자원) counting 을 위해 사용한다.
- 이진 세마포어를 가져간 스레드가 소유권을 갖지 않기 때문에, 우선순위가 높은 다른 스레드가 자원을 빼앗아 반납시킬 수 있다.
즉, 뮤텍스와 이진 세마포어는 사용 목적이 다르다.
Spin Lock
-
세마포어가 0 이하인 경우 프로세스가 대기하는 방식 중 하나로, Busy-Wait 방식이다.
- 다른 방식으로는 Sleep Lock (Block-Wakeup 방식) 이 있다.
-
프로세스는 무한 루프를 돌며 CPU를 아무 의미없이 사용한다.
-
장점
- 구현이 쉽고 세마포어가 정수값 이외에 특별한 구조체를 필요로 하지 않는다.
-
단점
- 아무런 의미없이 CPU를 낭비한다.
-
따라서 멀티코어 환경에서 Critical Section 이 엄청나게 짧은 경우가 아니라면, CPU를 사용하지 않는 block queue 에 프로세스를 넣고 대기시키는 sleep lock 을 사용하는 것이 효율적이다.
Deadlock
- 프로세스들이 서로가 가진 자원을 기다리며 block 된 상태
Deadlock 발생 조건
-
Mutual exclusion
- 하나의 프로세스만 자원을 사용할 수 있다.
-
No preemption
- 프로세스는 자원을 빼앗기지 않고 자진 반납한다.
-
Hold and wait
- 프로세스가 자원을 보유한 채 다른 자원을 기다린다.
-
Circular wait
- 자원을 기다리는 프로세스간에 사이클이 형성된다.
발생 조건을 모두 만족하지 않으면, Deadlock 이 발생하지 않는 이유
Mutual exclusion 조건은 데이터 일관성을 위해 반드시 존재해야 한다.
-
No preemption 조건을 만족하지 않는다면, 프로세스가 필요한 자원을 다른 프로세스로부터 빼앗아 작업을 수행하여 deadlock 을 빠져나갈 수 있다.
-
Hold and wait 조건을 만족하지 않는다면, 프로세스가 해당 작업을 완료하기 위한 자원이 없으면 애초에 작업을 시작하지 않기에 deadlock 이 발생하지 않는다.
- 작업을 시작한 프로세스는 반드시 해당 작업을 완료하고 자원들을 다시 반납한다.
-
Circular wait 조건을 만족하지 않는다면, 프로세스들이 서로가 가진 자원을 기다리는 상황이 아니므로 deadlock 이 발생하지 않는다.
Deadlock 예방
-
Deadlock 을 예방하는 방식인 Deadlock Prevention 은 자원할당시에 deadlock 발생 조건 중 어느 하나가 만족되지 않도록 한다.
-
데이터 일관성을 위해 Mutual Exclusion 조건은 반드시 성립해야 한다.
-
Hold and wait 조건을 깨는 방법
-
프로세스가 자원을 요청할 때, 어떤 자원도 가지고 있지 않도록 한다.
-
프로세스 작업에 필요한 모든 자원이 있는 경우에만 해당 프로세스에게 모든 자원들을 할당한다.
-
만약 프로세스 작업에 필요한 모든 자원이 존재하지 않는다면, 해당 프로세스에게 자원들을 주지 않는다.
-
-
No preemption 조건을 깨는 방법
- 프로세스가 필요한 자원을 다른 프로세스로부터 빼앗도록 한다.
-
Circular wait 조건을 깨는 방법
- 자원에 할당 순서를 정하여 정해진 순서대로만 자원을 할당하도록 한다.
현대 OS 가 Deadlock을 처리하지 않는 이유
-
deadlock 은 매우 드물게 발생한다.
-
따라서 deadlock 을 처리하기 위한 여러 조치들과 제약 조건이 더 큰 오버헤드가 되어 CPU 이용률을 낮추고 starvation 을 발생시킬 수 있다.
-
따라서 OS는 deadlock 을 신경쓰지 않고, deadlock 발생 시 사용자가 직접 프로세스를 종료하도록 한다.
Lock-Free 와 Wait-Free
-
Lock-Free 알고리즘
-
lock 을 사용하여 멀티 쓰레드 프로그래밍을 하면 병렬성이 감소한다.
-
따라서 lock 을 사용하지 않고
-
멀티 쓰레드가 동시에 호출해도 정확한 결과를 만들어주며
-
호출이 다른 쓰레드와 충돌하였을 경우에도 적어도 하나의 승자가 있어서 승자는 delay 없이 작업을 완료하면
-
Lock-Free 알고리즘이다.
-
주로 CAS 연산을 사용한다.
- 내가 변경하려는 자료구조가 다른 쓰레드에 의해 이미 변경되었다면 작업을 중단하고 다시한다.
-
-
Wait-Free 알고리즘
-
Lock-Free 알고리즘의 모든 조건을 만족하고
-
호출이 다른 쓰레드와 충돌하였을 경우에도 모든 쓰레드가 delay 없이 작업을 완료하면
-
Wait-Free 알고리즘이다.
-
프로그램의 컴파일 및 실행
C 프로그램이 컴파일 되어, 실행되는 과정은 다음과 같다.
-
프로그래머가 작성한 C 프로그램을 컴파일러가 어셈블리 프로그램으로 변환한다.
-
어셈블러가 어셈블리 프로그램을 기계어 프로그램 (object 파일) 으로 변환한다.
-
링커는 프로그램 실행에 필요한 라이브러리들의 object 파일과 앞서 만든 object 파일을 합쳐 실행파일을 만든다. (Static Linking 방식)
- 만약 Dynamic Linking 방식이라면 링커는 라이브러리들의 object 파일 대신 라이브러리 루틴의 포인터만 추가하여 실행파일을 만든다.
-
로더는 Disk 에 존재하는 실행 파일을 메모리위로 올려 프로그램을 실행시킨다.
링커와 로더
-
링커
-
프로그램 실행에 필요한 라이브러리의 object 파일을, 사용자가 만든 object 파일에 합쳐 하나의 실행 파일을 만드는 역할을 한다.
-
만약 Dynamic Linking 방식이라면 링커는 라이브러리들의 object 파일 대신 라이브러리 루틴의 포인터만 추가하여 실행 파일을 만든다.
-
-
로더
-
Disk 에 존재하는 실행 파일을 메모리위로 올려 프로그램을 실행시킨다.
-
만약 Dynamic Linking 방식이라면 프로세스가 실행 중에 해당 라이브러리 루틴을 사용하려는 시점에, 해당 라이브러리 루틴을 메모리 위로 올린다.
-
컴파일 언어 vs 인터프리터 언어
-
컴파일 언어
-
소스 코드를 기계가 읽을 수 있는 목적 코드로 변경한 뒤 실행 파일을 만든다.
-
실행 플랫폼에 대한 정보를 바탕으로 컴파일 중 여러 최적화를 수행할 수 있다.
- 따라서 특정 시스템 간 이식성이 좋지 않다.
-
이미 만들어진 실행 파일 실행 시에는 컴파일 과정을 거치지 않으므로, 코드 실행 속도가 빠르다.
-
-
인터프리터 언어
-
소스 코드를 바로 실행한다.
- 컴파일을 수행하지 않는다.
-
실행 파일 없이 실행 시마다 소스 코드를 번역하며 실행하므로 상대적으로 느리다.
-
컴파일 에러가 발생하지 않는다.
- 런타임 에러만 발생
-
시스템 간 이식성이 뛰어나다.
- 시스템 별로 최적화하기 어렵다.
-
컴파일을 하지 않으므로 코드 수정 후 실행이 쉽다.
-
JIT
-
Just In Time 컴파일러
-
자바 기준으로, 평소에는 바이트코드를 인터프리터를 사용해서 번역하며 실행한다.
-
그러나, 자주 실행되는 코드 영역은 JIT 컴파일러가 런타임 중에 기계어로 컴파일하여 사용한다.
-
즉, 컴파일 임계치를 만족하는 코드는 컴파일이 수행된다.
- JVM 의 경우, 메소드 호출 횟수 + 메소드 내의 반복문 회전 횟수 를 측정하여 컴파일 임계치를 넘는지 체크한다.
자바의 프로그램 컴파일 및 실행
-
프로그래머가 만든 자바 소스 파일 (.java) 을 JDK 내의 컴파일러가 바이트코드 파일 (.class) 로 컴파일한다.
- 바이트코드 파일은 JVM 이 실행할 수 있는 목적 코드이다.
-
Class Loader 는 프로그래머가 작성한 바이트코드 파일을 실행하기 위해 필요한 클래스 파일들을 찾아 JVM 위에 올리고 검증 및 초기화 작업들을 수행한다.
-
이후 프로그램 수행을 위한 메모리 영역 (JVM 의 Runtime Data Area) 을 할당받아 프로그램을 실행한다.
- 자바는 JIT 컴파일러와 인터프리터를 사용하여 바이트코드 파일을 실행한다.
Python 구현체의 종류
-
CPython
-
표준 파이썬 구현으로 C로 작성되었다.
-
Python 소스 코드를 CPython VM 이 이해할 수 있는 바이트코드로 만들고, 해당 가상머신위에서 실행한다.
-
-
Jython
-
JVM 을 활용하는 Python 구현체이다.
-
Python 소스코드를 JVM 이 이해할 수 있는 바이트코드로 만들고, JVM 내에서 실행한다.
-
-
PyPy
-
Python 언어로 작성된 구현체이다.
-
Python 소스 코드를 JIT 컴파일러를 사용해 바이트코드로 변환한다.
- 이후 똑같은 코드에 대해 다시 컴파일하지 않고 앞서 캐싱해둔 바이트코드를 재사용한다.
-
추가적인 메모리 공간이 필요해 CPython 대비 메모리를 많이 사용하나, 실행시간이 긴 프로그램의 경우 효율적이다.
-
IPC
-
Inter Process Communication
-
프로세스들 사이에 서로 데이터를 주고 받는 것 (통신)
-
서로 협력하는 프로세스들은 서로 통신하기 위한 방법이 필요하다.
-
IPC mechanism 에는 크게 2가지 모델이 있다.
-
shared memory
-
message passing
-
-
Shared memory
-
서로 협력하는 프로세스들이 데이터를 주고 받기위해 특정 메모리 영역을 공유한다.
- 협력 프로세스들이 모두 접근할 수 있다.
-
애플리케이션 개발자가 공유 메모리에 접근 및 조작하는 코드를 명시적으로 작성해야 한다.
-
-
Message passing
-
OS가 프로세스 협력에 필요한 기능들을 제공한다.
- send, receive API
-
애플리케이션 개발자가 공유 메모리에 접근 및 조작하는 코드를 작성할 필요 없다.
-
다양한 통신 방식이 있다.
-
direct communication
-
송신자와 수신자를 명시하여 데이터를 보내는 방식
-
정확히 하나의 communication link 가 생긴다.
-
-
indirect communication
-
송신자는 port 에 데이터를 보내고, 수신자는 port 에서 데이터를 꺼내보는 방식
-
여러개의 communication link 가 생길 수 있다.
-
-
-
Shared memory
-
서로 협력하는 프로세스들이 데이터를 주고 받기위해 특정 메모리 영역을 공유한다.
- 협력 프로세스들이 모두 접근할 수 있다.
-
각 프로세스는 자신의 논리 주소 공간에 공유 메모리 영역을 추가한다.
-
공유 공간이기 때문에 데이터 일관성을 유지할 수 있도록 프로세스 동기화를 신경써야 하고 공유 메모리 사용이 끝나면 공유 메모리를 사용하는 모든 프로세스에서 공유 메모리 영역을 해제해주어야 공유 메모리 영역이 해제된다.
Thread Safe
- 여러개의 스레드가 어떤 공유 자원에 동시에 접근하더라도, 해당 자원의 일관성을 유지할 수 있는 것
- 즉, 멀티 스레드 프로그래밍 환경에서 Race Condition 이 발생하지 않는 것
Thread Safe 를 보장하기 위한 방법
-
Lock 을 사용하여 Critical Section Problem 을 해결함으로써 데이터 일관성을 유지하거나
-
직접 코드로 해결하기
-
Mutex 사용하기
-
Monitor 사용하기
-
-
Lock-Free 알고리즘 (CAS) 을 사용함으로써 데이터 일관성을 유지한다.
Peterson's Algorithm
-
Critical Section Problem 을 해결하는 알고리즘
- 어떤 시점에 CPU를 빼앗겨도 잘 동작한다.
-
동기화를 위한 공유 변수로
turn과flag를 사용한다. -
상대방이 critical section 에 들어가겠다는 의사표현을 하고 (
flag[상대] = true), 상대방의 차례라면 (turn = 상대), 나는 critical section 에 들어가지 않고 대기한다.- 이외의 경우엔, 내가 critical section 에 들어가 작업할 수 있다.
Process 0
flag[0] = true; // 내가 (Process 0) critical section 에 들어가겠다는 의사 표현
turn = 1; // 상대 차례 (Process 1) 로 변경
while (flag[1] && turn == 1); // 상대가 (Process 1) 이 의사 표현을 했고, 상대 차례이면 대기
critical section
flag[0] = false; // 나의 (Process 0) 의사 표현을 제거
remainder sectionRace Condition
-
공유 자원에 대해 여러개의 프로세스가 접근하여 조작하는 경우, 조작의 타이밍이나 순서등이 결과값에 영향을 줄 수 있는 상태
- 데이터 일관성이 깨져 이상한 결과값이 산출된다.
Lock 을 사용하지 않는 Thread Safe 구현
-
Lock 을 사용하지 않고 CAS 방식 (Lock-Free) 으로 Thread Safe 를 구현할 수도 있다.
-
CAS: 내가 접근 및 조작하려는 값이 다른 쓰레드에 의해 이미 변경되었다면 나의 작업을 종료하고 다시 재시작한다.
Thread Pool, Monitor, Fork-Join
-
Thread Pool
-
쓰레드 풀 없이 매 요청마다 스레드를 생성한다면
-
스레드 생성 오버헤드 ↑
-
스레드가 많아져 컨텍스트 스위칭이 자주 발생해 CPU 오버헤드 ↑
-
스레드가 점유하는 메모리가 많아진다.
-
-
이러한 단점들을 해결하기 위해 미리 정해진 개수만큼 스레드들을 만들어 모아놓은 곳이 스레드 풀이다.
- 요청이 오면 스레드 풀에서 스레드를 꺼내 사용하고, 반납하는 방식으로 스레드를 재사용한다.
-
스레드 생성 시간을 절약하고, 너무 많은 스레드가 만들어지는 것을 막는다.
-
-
Monitor
-
프로그래밍 언어 차원에서 공유 데이터에 대한 Process Synchronization 을 모두 처리해주는 동기화 메커니즘
-
프로그래머가 직접 lock 을 얻을 필요없이 Monitor 에서 제공하는 API를 사용하여 공유 데이터에 접근 및 조작한다.
-
모니터 내부에는 Condition Variable 이라는 block queue 가 있다.
-
해당 큐에
wait연산과signal연산을 사용할 수 있다. -
wait(): 호출 프로세스가 block queue 에서 block 된 채로 대기한다. -
signal(): 호출 프로세스는 block queue 에서 대기하는 프로세스를 깨운다.
-
-
-
Fork-Join
-
하나의 작업을 작은 단위로 나눠 병렬처리 후 작은 결과물들을 합치는 것을 쉽게 도와주는 프레임워크
-
자바의 경우,
RecursiveTask클래스의 추상 메서드compute()를 구현하여 병렬 처리를 수행한다. -
태스크를 더 이상 쪼개지지 않는 작은 서브 태스크로 분할한 뒤 (
Fork), 각 서브 태스크들의 결과를 합쳐 결과를 산출한다. (Join)
-
Thread Pool 의 스레드 수
-
I/O bound job 이 많다면 스레드 개수가 많은 것이 좋다.
- I/O bound job 은 CPU는 조금만 쓰고 대기시간이 길기때문에 block 된 스레드가 반납한 CPU를 I/O 작업을 시작하려는 다른 스레드가 가져가 사용할 수 있다.
-
CPU bound job 이 많다면 스레드 수가 프로세서 코어 수를 넘지 않는 것이 좋다.
- CPU bound job 은 스레드가 block 없이 CPU를 반납하지 않고 작업하기 때문에, 스레드가 많으면 쓸데없는 컨텍스트 스위칭 비용만 추가된다.
메모리 계층 구조와 캐시 메모리
-
메모리 계층 구조
-
CPU에 가까운 상위 계층일 수록 데이터 접근 속도가 빠르고, 저장용량이 작고, 비트당 비용이 증가한다.
-
CPU와 먼 하위 계층일 수록 데이터 접근 속도가 느리고, 저장용량이 크고, 비트당 비용이 감소한다.
-
-
캐시 메모리
-
CPU와 가장 근접한 메모리
-
CPU와 메인 메모리 사이에 있다.
-
SRAM 기반의 저장 장치
-
캐싱: CPU가 자주 사용하는 메인 메모리 데이터를 더 가깝고 빠른 캐시 메모리로 가져와 저장하는 것
-
캐시 메모리의 위치
- L1, L2 캐시는 CPU 코어 내부에, L3 캐시는 CPU 코어 외부에 위치한다.
Cache 저장 단위
-
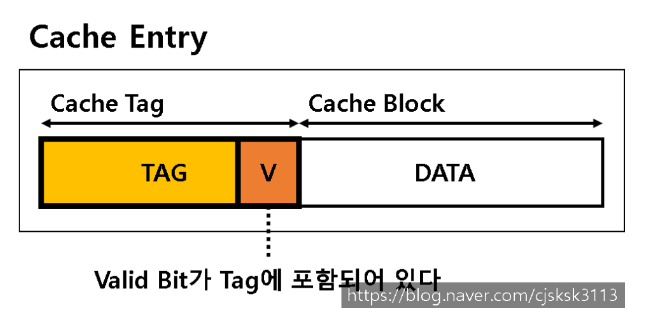
Cache Entry
-
캐시 태그와 Valid Bit, 데이터가 하나로 묶여 Cache Entry 를 구성한다.
-
데이터가 올바르지 않거나 비어있다면 유효비트는 0으로 설정된다.
-
유효 비트와 태그 필드를 이용하여
O(1)시간 복잡도로 데이터에 접근할 수 있다.
-
-
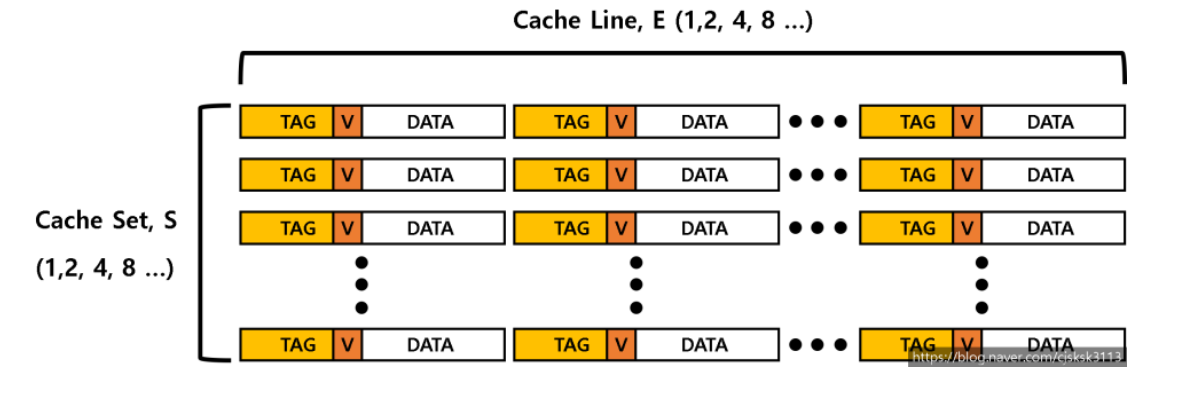
Chche Line
- Cache Entry 여러개는 Cache Line 단위로 묶여 캐시에 저장된다.
캐시 메모리의 매핑 방식
-
Direct Mapping
-
메인 메모리를 적절한 크기로 나눈 각 블록들은 캐시 내에 저장될 위치가 한 곳으로 정해져있다.
-
예를 들어 0, 4, 8 번 블록은 캐시의 0번 인덱스에 캐싱된다.
-
1, 5, 9 번 블록들은 캐시의 1번 인덱스에 캐싱된다.
-
따라서 0, 4, 8 번 순서로 데이터에 접근하려 한다면 3번의 캐시 미스가 발생한다.
-
-
-
Associative Mapping
-
메인 메모리를 적절한 크기로 나눈 각 블록들은 캐시 내에서 n개의 배치 가능한 위치를 갖는다.
- 이를 n-way set associative mapping 이라 한다.
-
만약 배치 가능한 위치의 개수 n 이 캐시 전체 크기라면, 각 블록은 캐시 어느곳에나 저장될 수 있는 fully associative mapping 이다.
-
direct mapping 은 1-way set associative mapping 이라 할 수 있다.
-
캐시의 지역성
-
프로그램은 어떤 특정 시간에 주소 공간 내의 비교적 작은 부분에만 접근한다.
-
이러한 성질을 이용해, 자주 접근할 것 같은 정보들을 캐시에 저장함으로써 성능을 향상시킬 수 있다.
-
이를 지역성의 원칙이라 하며 크게 2가지가 있다.
-
-
Temporal Locality
-
시간적 지역성
-
최근 찾은 정보를 가까운 시간 내에 다시 찾을 확률이 높다.
-
-
Spatial Locality
-
공간적 지역성
-
최근 찾은 정보의 근처에 있는 정보들을 뒤이어 찾을 확률이 높다.
-
캐시의 공간 지역성 구현 방법
- 메인 메모리의 연속된 주소들을 block 단위로 가져와 캐시에 저장함으로써 spatial locality 를 활용할 수 있다.
메모리 연속 할당
-
contiguous allocation
-
가상 메모리에 존재하는 프로세스 영역을 물리 메모리의 연속적인 공간에 통째로 올린다.
-
relocation레지스터를 통해 해당 프로세스의 physical address 시작 지점을 찾고 -
limit레지스터를 통해 CPU가 참조하는 logical address 주소가 해당 프로세스를 벗어나는지 체크한다. -
이렇게 여러개의 프로세스들을 통째로 메모리위에 올리다보면 프로그램이 들어가지 못하고 낭비되는 공간인 fragmentation 이 생긴다.
-
프로세스를 올릴 수 있는 물리 메모리 공간을 Hole 이라 한다.
- 프로세스를 올릴 Hole 을 찾는 방식은 크게 3가지가 있다.
-
First-fit
- 프로그램을 넣을 수 있는 크기의, 제일 처음 발견된 hole 에 프로그램을 올린다.
-
Best-fit
- 전체 hole 중에 프로그램을 넣을 수 있는 크기의, 가장 작은 hole 에 프로그램을 올린다.
-
Worst-fit
- 전체 hole 중에 프로그램을 넣을 수 있는 크기의, 가장 큰 hole 에 프로그램을 올린다.
-
어떠한 방식을 사용하던 fragmentation 이 생긴다.
Thrashing
-
프로세스가 원활하게 수행되기 위한 최소한의 페이지 frame 수를 할당받지 못한 경우 발생한다.
-
page fault rate 이 매우 높아져 프로세스가 대부분의 시간을 페이지를 swapping 하는 Disk I/O 작업으로 보내고
-
CPU 는 대부분의 시간을 놀게된다.
-
결국 Thrashing 발생을 막으려면 프로세스가 원활히 수행되기 위한 어느정도 페이지 frame 수를 보장해주어야 한다.
Thrashing 예방책
-
Working-Set Model
-
프로세스는 특정 시간동안 일정 장소만을 집중적으로 참조하는 경향이 있다.
- 집중적으로 참조되는 페이지들의 집합을 working set 이라 한다.
-
현재 시점부터 window 크기만큼의 과거의 참조된 모든 페이지들이 working set이다.
- 이는 참조된 페이지를 window 시간동안 물리 메모리에 유지한 후 swap out 함을 의미한다.
-
working-set 모델은 프로세스의 working set 전체가 물리 메모리에 있어야만 해당 프로세스를 실행한다.
- 전체를 올릴 수 없는 경우엔 해당 프로세스의 모든 페이지 프레임을 반납하고 프로세스를 중지한다.
-
이러한 방식을 통해 Thrashing 을 방지한다.
-
-
PFF Scheme
-
Page-Fault Frequency
-
특정 프로세스의 page-fault rate 이 상한값을 넘으면, frame을 더 할당한다.
- 할당할 수 있는 빈 frame이 없다면 이미 할당된 해당 프로세스의 페이지 frame 들을 모두 반납하고 프로세스를 중지한다.
-
특정 프로세스의 page-fault rate 이 하한값보다 작으면, 할당 frame 수를 줄인다.
-
가상 메모리
-
각 프로세스가 갖는 가상의 메모리 공간
-
만약 가상 메모리를 사용하지 않고, 프로그램이 사용하는 주소 공간 그대로 물리 메모리위에 올려 사용한다면
-
물리 메모리의 크기보다 큰 프로그램은 실행할 수 없다.
-
여러개의 프로그램을 동시 수행할 수 없다.
-
가상 메모리가 가능한 이유
-
프로세스의 가상 메모리를 동일한 사이즈의 page 단위로 나눈다.
-
프로세스의 특정 page 영역을 실제로 사용할 시점에 물리 메모리위에 올리는 Demand Paging 을 사용함으로써 가상 메모리가 가능하다.
-
프로그램에서 현재 사용하는 page는 물리 메모리위로 올리고, 현재 사용하지 않는 page는 backing storage 에 대기시킨다.
-
이를 통해 더 많은 프로그램을 동시에 물리 메모리위에 올릴 수 있다.
-
Page Fault 처리 방법
-
Logical Address 의 Page 번호가 invalid 상태라면 page fault가 발생했다고 한다.
-
이 경우 MMU 가 trap 을 발생시켜 OS 에게 CPU가 넘어간다.
- page fault 는 OS 가 해결한다.
-
-
프로그램의 범위를 벗어난 페이지 요청이라면 해당 프로세스를 추방한다.
-
프로그램 범위의 페이지 요청이라면 비어있는 물리 메모리 frame 을 찾는다.
- 비어있는 frame 이 없으면 우선순위가 낮은 page 를 frame 에서 추방시켜 빈 frame 을 만든다.
-
Logical Address 의 page 를 disk 에서 찾아 물리 메모리의 frame 에 올린다.
-
disk I/O 작업이 끝나면 page table 을 갱신한다.
-
해당 page 를 valid 로 설정
-
해당 page 가 물리 메모리에 위치한 frame number를 적는다.
-
-
-
이후에는, 해당 프로세스가 CPU를 다시 사용하면 Logical Address 의 page 번호가 valid 상태로 Logical Address Translation 을 정상적으로 수행할 수 있다.
페이지 크기
-
페이지 크기가 작으면
-
페이지 수와 page table 크기가 증가한다.
-
물리 메모리에서 페이지를 더 이상 할당할 수 없는 자투리 공간은 작아진다.
-
필요한 정보만 물리 메모리에 올라온다.
-
-
페이지 크기가 커지면
-
페이지 수와 page table 크기가 감소한다.
-
locality 활용도가 높아진다.
-
Disk 에서 크게 덩어리로 페이지를 찾아오므로 Disk I/O 작업 빈도를 줄일 수 있다.
-
페이지 크기와 page fault
-
페이지 크기가 어느정도 커지면 page table 크기가 작아지기에 page fault rate 이 증가한다.
-
그러나 페이지 크기가 더욱 커지면 페이지 하나에 프로세스의 많은 내용이 들어가기에 참조지역성 효과가 커지고, page fault rate 은 다시 감소한다.
세그멘테이션 방식과 가상 메모리
-
프로세스의 가상 메모리를 segment 로 나누고 필요한 segment 만 물리 메모리위에 올림으로써 demand paging 방식과 유사하게 운영이 가능하다.
-
따라서 가상 메모리를 사용할 수 있다.
세그멘테이션과 페이징의 차이점
-
segmentation 은 프로그램을 의미 단위인 여러개의 segment 로 나눈다.
-
page 와 다르게 각 segment 의 크기는 같지 않다.
-
따라서 물리 메모리상에 fragmentation 이 생길 수 있다.
-
-
segmentation 은 의미 단위로 프로그램을 쪼개기 때문에 protection 설정과 sharing 설정이 쉽다.
- page는 크기가 동일하여 설정이 애매한 경우가 있다.
-
segmentation 의 segment table 은 일반적으로 page table 보다 작다.
- 각 프로세스당 segment 개수는 그렇게 많지 않다.
내부 단편화와 외부 단편화
-
Internal Fragmentation
-
물리 메모리 고정 분할 방식에서 발생한다.
-
물리 메모리를 고정된 분할 영역으로 나누고, 분할 영역에는 한 개의 프로그램이 올라갈 수 있다.
-
만약 분할영역의 크기가 프로그램의 크기보다 커서, 분할 영역내에 생기는 잉여 공간을 Internal Fragmentation 이라 한다.
-
-
External Fragmentation
-
물리 메모리 가변 분할 방식에서 발생한다.
-
고정된 분할 영역 없이, 프로그램, page 혹은 segment 가 아무렇게나 들어갈 수 있다.
-
물리 메모리위에서 실행되던 작은 프로그램이나 segment가 종료되어 작은 메모리 공간이 생겼는데
-
다음에 실행하려는 프로그램이나 segment 가 크기가 크다면 작은 메모리 공간에 들어갈 수 없다.
-
이때 낭비되는 작은 메모리 공간을 External Fragmentation 이라 한다.
-
페이지에서 실제 주소를 가져오는 방법
-
Logical Address 는 가상 메모리에서의 page 번호와, page 내에서의 명령어 위치를 나타내는 offset 으로 이루어져 있다.
-
page table 에서 page 번호를 인덱스로 하여 page 가 올라간 물리 메모리의 frame number 를 구한다.
-
구한 frame number 에서 offset 만큼 더한 주소가 대응되는 Physical Address 이다.
어떤 주소공간이 있을 때, 이 공간이 수정 가능한지 확인하는 방법
-
주소 공간이 속한 page 를 찾는다.
-
page table 에서 해당 page 에 대응되는 page table entry 를 찾는다.
-
page table entry 의 Protection bit 를 확인하여 접근 권한을 확인할 수 있다.
- Protection bit 는 rwx 설정 가능
32비트 운영체제에서, 페이지 크기가 1kb 라면 페이지 테이블의 크기는?
-
32 bit 운영체제는 메모리 주소 레지스터의 크기가 32bit 이다.
- 표현할 수 있는 메모리 주소 개수가 2^32 - 1 개 이므로 메인 메모리를 최대 4GB 까지만 사용할 수 있다.
-
페이지 크기가 1kb 라고 하면 4GB / 1kb = 4M 으로, 메인 메모리를 4M개의 페이지로 나눌 수 있다.
-
따라서 페이지 테이블은 400만개의 엔트리로 구성된다.
TLB
-
Translation Look-aside buffer
-
page table 은 레지스터나 캐시로 저장하기엔 너무 커서 물리 메모리에 저장한다.
-
따라서 간단한 paging 의 경우 Logical Address 를 Physical Address 로 변환하기 위해서2번의 물리 메모리 접근이 필요하다.
- 이는 CPU 입장에서 큰 오버헤드이다.
-
물리 메모리 접근 횟수를 줄이기 위해 TLB 캐시를 둔다.
-
TLB는 자주 사용된 page 번호와 page 가 올라간 물리 메모리 frame number 를 쌍으로 저장한다.
- Address 변환시에 TLB 캐시를 먼저 뒤져 일치하는 page 번호가 있다면 cache hit, 없다면 page table 에 접근하여 frame number 를 찾아낸다.
-
프로세스마다 다른 page table 을 갖기 때문에 프로세스가 바뀌면 TLB를 모두 비워야한다.
TLB를 쓰면 빨라지는 이유
- TLB cache hit 시에 물리 메모리 접근 횟수가 줄어들어 Address Translation 에 걸리는 시간이 줄어든다.
MMU
-
Memory Management Unit
-
Logical Address 를 Physical Address 로 매핑해주는 하드웨어 장치
-
CPU 가 참조하는 프로그램의 Logical Address 를 MMU가 중간에서 Physical Address 로 변환해줌으로써, CPU는 실제 물리 메모리에 있는 프로그램의 명령어나 데이터에 접근할 수 있다.
TLB와 MMU의 위치
-
MMU는 일반적으로 CPU 내부에 위치한다.
-
TLB 는 MMU 내부에 존재한다.
TLB 와 Context Switching
- 프로세스마다 다른 page table 을 갖기 때문에 프로세스가 바뀌면 TLB를 모두 비워야한다.
하드웨어 차원에서의 동기화 지원
-
Race Condition 이 발생하는 이유는 공유 변수를 읽는 동작과 공유 변수를 변경하는 동작이 2개 이상의 명령어로 이루어져있기 때문이다.
-
한 스레드가 공유 변수를 읽는 동작만 완료한 상태에서 CPU를 빼앗기고
-
다른 스레드가 공유 변수를 변경해버린다면
-
Race Condition 이 발생할 수 있다.
-
-
따라서 하드웨어적으로 Read 와 Write 를 하나의 명령어로 수행할 수 있도록 지원하면 더 쉽게 동기화를 구현할 수 있다.
-
대표적으로
test_and_set(lock)이 있다.-
critical section 에 들어가는 스레드가 lock 의 값을 Read 한 뒤, lock 을 true로 Write 하는 연산을 원자적으로 수행한다.
-
lock이 true 이면 다른 스레드는 critical section 에 들어갈 수 없다.
-
volatile
-
volatile 키워드가 붙은 변수는 최적화에서 제외된다.
-
즉, CPU 에 캐싱되지 않으므로 항상 메인 메모리에서 읽어와야 한다.
-
또한 해당 변수의 변경 사항은 CPU에 캐싱되지 않고 바로 메인 메모리에 반영된다.
-
-
volatile 키워드를 사용함으로써 스레드들이 공유 변수의 변경을 즉각적으로 볼 수 있는 가시성을 제공한다.
-
volatile 키워드는 하나의 스레드만 공유 변수에 쓰기 작업을 하고 다른 스레드들은 읽기 작업만 하는 경우에 유용하게 사용할 수 있다.
- 여러 스레드가 공유 변수에 쓰기 작업을 하는 경우에 Race Condition 이 발생할 수 있다.
페이지 교체 알고리즘
-
Optimal Algorithm
-
가장 먼 미래에 참조되는 페이지를 교체한다.
-
가장 효율적인 알고리즘
-
미래를 알 수 없으므로 실제 구현할 수는 없고 다른 교체 알고리즘 성능에 대한 uppper bound 를 제공한다.
-
-
FIFO Algorithm
-
First In First Out
-
가장 먼저 들어온 페이지를 교체한다.
-
페이지 frame 을 늘렸을 때 성능이 더 나빠지는 이상현상이 발생할 수 있다.
-
-
LRU Algorithm
-
Least Recently Used
-
가장 오래전에 참조된 페이지를 교체한다.
-
최근에 참조된 페이지가 다시 참조될 확률이 높음을 이용한다.
-
-
LFU Algorithm
-
Least Frequently Used
-
참조 횟수가 가장 작은 페이지를 교체한다.
-
많이 참조된 페이지는 도다시 참조될 확률이 높음을 이용한다.
-
-
Clock Algorithm
-
Paging System 에서 실제로 적용할 수 있는 알고리즘
-
LRU, LFU 는 실제로 구현할 수 없다.
-
OS가 페이지 관계를 계속해서 갱신해야 하는데, 사실 OS는 page fault 가 발생했을때만 CPU 제어권을 가지기 때문
-
-
reference bit 을 사용해 교체 대상 페이지를 선정한다.
-
특정 페이지를 참조하면 하드웨어가 해당 페이지의 reference bit 을 1로 세팅한다.
-
reference bit 이 0인 페이지를 찾을 때까지 포인터가 이동한다.
-
포인터는 이동하면서 reference bit 1을 모두 0으로 바꾼다.
-
포인터가 reference bit 이 0인 페이지를 찾으면 해당 페이지를 교체한다.
-
-
LRU 와 유사하게 오랫동안 사용되지 않은 페이지를 솎아낸다.
-
LRU 알고리즘은 어떤 특성을 이용한 알고리즘인가
- 최근에 참조된 페이지가 다시 참조될 확률이 높다는 특성을 이용한 알고리즘이다.
LRU 알고리즘의 구현
-
Doubly Linked List 자료구조로 구현한다.
-
특정 페이지가 참조되면 해당 페이지를 자료구조의 맨 앞으로 옮긴다.
- 특정 페이지의 주소값은 맵으로 관리한다.
-
페이지 교체가 필요한 경우 자료구조의 맨 뒤에 위치한 페이지를 제거하고 새로운 페이지를 자료구조의 맨 앞에 넣는다.
LRU 알고리즘의 단점과 대안
-
LRU 알고리즘은 실제 Paging System 에서 구현할 수 없는 알고리즘이다.
-
페이지가 참조될 때마다, 해당 페이지가 최근에 참조되었음을 OS가 체크하고 관리해야하는데
-
실제로 OS에게 제어권이 넘어가는 건, Page Fault 가 발생했을 때 뿐이다.
-
따라서 LRU 대신 Clock Algorithm 을 사용할 수 있다.
File System과 File Descriptor
-
File System
-
OS 에서 파일을 관리하는 부분
-
파일을 어떻게 저장할지, 관리할지, 보호할지 정한다.
-
-
File Descriptor
-
특정 파일의 메타데이터 주소는 open file table 에 위치한다.
- 해당 주소를 참조하여 디스크의 특정 파일에 접근하여 내용을 읽을 수 있다.
-
특정 프로세스에서 이용하려는 파일의 메타데이터가 open file table 의 어느 위치에 있는지는 file descriptor에 저장한다.
- 프로세스별로 PCB에서 file descriptor 를 관리한다.
-
즉, 프로세스가 특정한 파일에 접근하기 위한 추상적인 키값이다.
-
I-Node
-
Unix 파일 시스템 구조 중 Inode list가 있다.
-
Inode list 는 inode 로 이루어져 있다.
-
inode 는 파일이름을 제외한 파일의 모든 메타 데이터를 갖는다.
-
파일의 크기에 따라 실제 파일 데이터에 접근하는 포인터를 관리하는 방식이 다르다.
-
파일의 크기가 아주 작으면 파일 데이터로 바로가는 포인터를 갖는다.
-
파일의 크기가 적당하면 파일 데이터의 인덱스 블록으로 가는 포인터를 갖는다.
-
파일의 크기가 아주 크면 인덱스 블록의 인덱스 블록으로 가는 포인터를 갖는다.
-
파일을 읽는 과정
-
파일 작업에 사용되는 명령어들은 모두 system call 명령어이다.
-
파일을 여는 명령어를 사용 시, 파일의 메타데이터를 메모리로 가지고 온다.
-
해당 파일의 메타데이터는 open file table 에 저장된다.
-
특정 파일의 메타데이터가 open file table 의 어느 위치에 있는지는 file descriptor 에 저장된다.
-
파일을 읽는 명령어를 사용시, file descriptor 를 바탕으로 해당 파일의 내용을 Disk 에서 읽어와 OS의 버퍼캐시에 저장한다.
-
이후, 버퍼 캐시의 내용을 복사하여 사용자 프로세스에 붙여넣는다.
동기와 비동기, 블로킹과 논블로킹
-
Synchronous vs Asynchronous
-
작업들이 요청 순서대로 순차적으로 수행되는지 여부에 따라 둘을 분류한다.
-
Synchronous (동기)
-
작업들이 요청 순서대로 순차적으로 수행된다.
-
즉, 선행 작업이 완료되지 않았다면 후행 작업은 시작되지 않는다.
- 선행 작업의 완료 알림을 받아야 다음 요청 작업을 수행할 수 있다.
-
-
Asynchronous (비동기)
-
작업들이 요청 순서대로 수행되지 않아도 된다.
-
먼저 요청받은 작업이 완료되지 않았더라도 다른 작업을 수행할 수 있다.
-
-
-
Blocking vs Non-Blocking
-
다른 요청 작업을 처리하기 위해, 현재 작업을 중지하는지 여부에 따라 둘을 분류한다.
-
Blocking
-
요청한 작업이 완료될때까지 현재 수행중이던 작업은 중지한다.
-
요청한 작업 결과를 기다린다.
-
-
Non-Blocking
-
요청한 작업 완료 여부와 상관없이, 현재 수행중인 작업을 계속해서 진행한다.
-
요청한 작업 결과를 기다리지 않는다.
- 요청한 작업 결과는 나중에 필요할 때 가져온다.
-
-
동기이면서 논블로킹, 비동기이면서 블로킹인 경우
-
동기이면서 논블로킹인 경우는 의미가 있다.
-
만약 순차적으로 진행되야 하는 작업 A, B가 있고, 이를 관리하는 메인 스레드도 따로 할 일이 있다고 가정하면
-
메인 스레드는 먼저 A 작업을 다른 스레드에게 맡겨놓고, 메인 스레드의 작업을 진행한다.
-
메인 스레드는 A 작업의 완료 요청을 받고 나면, B 작업을 다른 스레드에게 맡겨 놓고, 다시 메인 스레드의 작업을 진행한다.
-
이런 방식으로 동기-논블로킹 이 구현될 수 있다.
-
-
비동기이면서 블로킹인 경우는 의미가 없다.
- 동기-블로킹 방식과 성능상 차이가 없고, 코드의 복잡성만 올라가는 안티 패턴이다.
출처
dual mode
https://neos518.tistory.com/115interrupt (1)
https://ko.wikipedia.org/wiki/%EC%9D%B8%ED%84%B0%EB%9F%BD%ED%8A%B8interrupt (2)
https://www.youtube.com/watch?v=v30ilCpITnYinterrupt (3)
https://huistorage.tistory.com/111system call == s/w interrupt ?
http://www.iamroot.org/xe/index.php?document_srl=14631&mid=Programming다중 인터럽트
https://blog.naver.com/hislunacy/50096200117TCB
https://eunajung01.tistory.com/55프로세스 생성
https://www.youtube.com/watch?v=RzN18na94Wc좀비 프로세스
https://wildeveloperetrain.tistory.com/180데몬 프로세스
https://blogger.pe.kr/770/init 프로세스
https://ko.wikipedia.org/wiki/Initdata 영역
https://ko.wikipedia.org/wiki/Init스택 vs 힙 (1)
https://stack-queue.tistory.com/18스택 vs 힙 (2)
https://m.todayhumor.co.kr/view.php?table=programmer&no=5516스택 vs 힙 (3)
https://luv-n-interest.tistory.com/1046스택의 크기
https://gpgstudy.com/forum/viewtopic.php?t=2224스레드 스택
https://www.youtube.com/watch?v=4x4yHKf-LI0프로세스 컨텍스트 스위칭 vs 스레드 컨텍스트 스위칭
https://easy-code-yo.tistory.com/31파이썬 동시성과 병렬성
https://www.youtube.com/watch?v=Iv3e9Dxt9WYMLFQ
https://lipcoder.tistory.com/62binary semaphore vs mutex
https://stackoverflow.com/questions/62814/difference-between-binary-semaphore-and-mutexlock free
https://ndc.vod.nexoncdn.co.kr/NDC2014/slides/NDC2014_0048/index.html컴파일러 vs 인터프리터 (1)
https://velog.io/@congaweb/compiler-interpreter컴파일러 vs 인터프리터 (2)
https://ongoing-yang.tistory.com/5PyPy
https://www.itworld.co.kr/news/302293CPython
https://sysgongbu.tistory.com/205IPC
https://www.youtube.com/watch?v=Bgdii8FppOU스레드 풀
https://www.youtube.com/watch?v=B4Of4UgLfWc캐시 엔트리
https://blog.naver.com/techref/222290234374캐시 일관성
https://www.anyflow.net/sw-engineer/cache-coherency페이지 크기와 pafe fault rate
https://lordofkangs.tistory.com/245자바와 volatile
https://parkcheolu.tistory.com/16
