
KOCW 운영체제 (반효경 교수님) 강의를 보고
- 중요하다고 생각되는 내용을 나름대로 구조화하여 정리하였다.
정리한 Chapter
-
운영체제 (OS)
-
컴퓨터 시스템 구조
-
프로세스
-
프로세스 관리
-
CPU Scheduling
-
Process Synchronization
-
Deadlocks
-
Memory Management
-
Virtual Memory
-
File Systems
-
Disk
운영체제 (OS)
-
Operating System
-
컴퓨터 하드웨어와 사용자 소프트웨어의 중간다리 역할을 하는 소프트웨어
- 컴퓨터 하드웨어 위에 바로 설치된다.
-
컴퓨터 시스템을 편리하게 사용할 수 있는 환경 제공
-
컴퓨터 시스템의 자원을 효율적으로 관리하는 것이 운영체제의 목표이다.
- 자원: 프로세서, 기억장치 (메모리), 입출력 장치
-
커널은 운영체제의 핵심 부분으로 항상 메모리에 상주하는 부분이다.
운영체제 분류
-
동시 작업 가능 여부
-
Single Tasking
- 한 번에 하나의 작업만 처리
-
Multi Tasking
-
동시에 두 개 이상의 작업 처리
-
오늘날 대부분의 운영체제들이 해당된다.
-
-
-
지원해주는 사용자의 수
-
Single User
- 한 사람만 사용할 수 있는 OS
-
Multi User
- 여러명이 사용할 수 있는 OS
-
-
작업 처리 방식
-
Batch Processing (일괄 처리)
-
작업들을 모아서 한꺼번에 처리한다.
-
작업이 완전 종료될 때까지 기다려야 한다.
-
초기 Punch Card 처리 시스템이 이에 해당한다.
-
-
Time Sharing (시분할)
-
여러 작업을 일정한 시간 단위로 분할하여 조금씩 조금씩 번갈아가며 처리한다.
-
Batch Processing 방식에 비해 짧은 응답시간을 가진다.
-
오늘날 범용 컴퓨터에서 사용하는 대부분의 운영체제들이 이에 해당
-
-
Realtime OS
-
특수한 목적을 가진 시스템에서 사용
-
정해진 시간에 어떤일이 반드시 처리되어야하는 실시간 시스템을 위한 OS
-
ex) 원자로 제어, 미사일 제어...
-
-
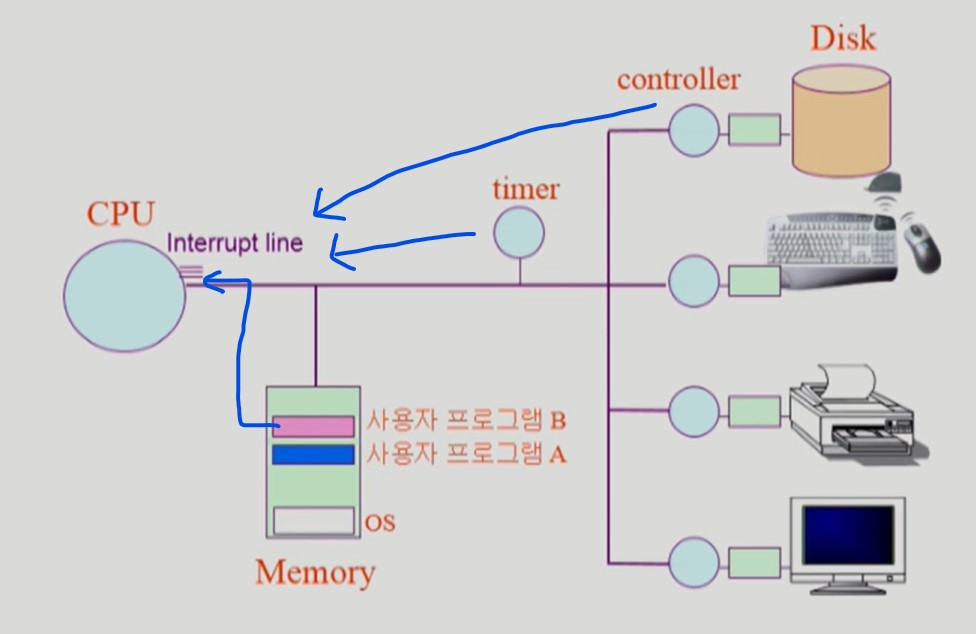
컴퓨터 시스템 구조
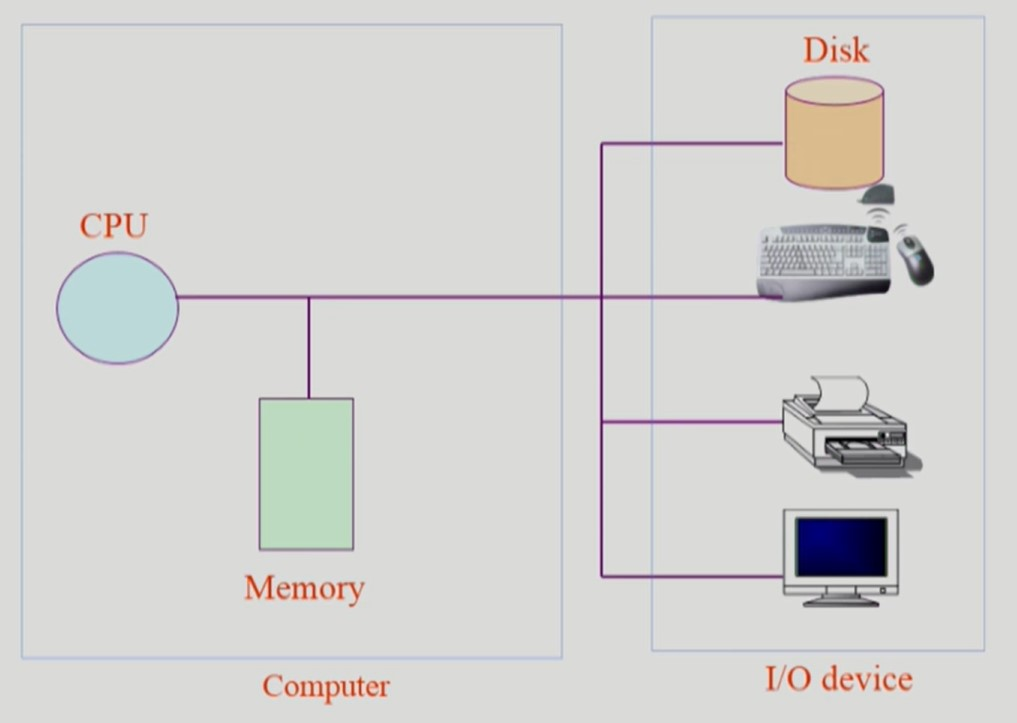
CPU 는 매 클럭마다 메모리의 명령어를 읽어서 실행한다.
Timer
-
특정 프로그램이 CPU를 독점하는 것을 막기 위한 장치
-
운영체제는 사용자 프로그램에 CPU를 넘겨줄 때 타이머에 제한시간을 세팅한다.
-
사용자 프로그램의 CPU 점유시간이 제한시간을 초과하면 타이머 인터럽트 발생
-
인터럽트에 의해 CPU가 사용자 프로그램에서 OS로 넘어간다.
-
이로써 OS는 다른 사용자 프로그램에게 CPU를 넘겨줄 수 있다.
-
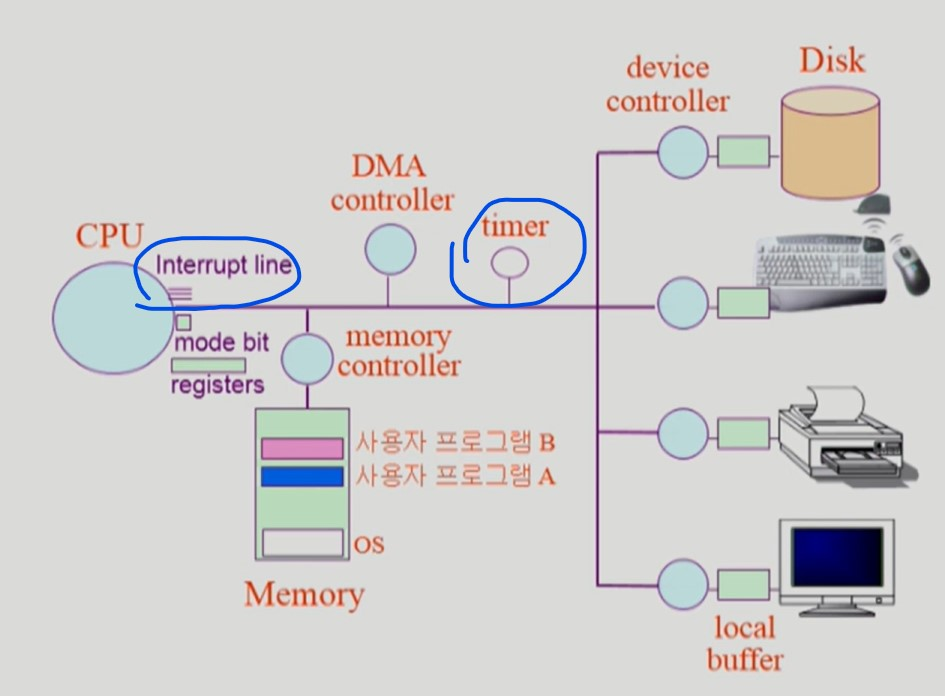
Mode bit
-
보안을 위해 사용자 프로그램은 제한된 명령어만 실행할 수 있어야 한다.
-
CPU가 사용자 프로그램과 운영체제를 구별하기 위해 mode bit 을 사용한다.
-
mode bit 0 ➔ 커널 모드
mode bit 1 ➔ 사용자 모드 -
인터럽트 발생 시, mode bit 을 0으로 만들고 OS에게 CPU를 넘긴다.
-
OS는 작업이 끝나면, mode bit 을 1로 만들고, 사용자 프로그램에게 CPU를 넘긴다.
- 만약 사용자 프로그램이 커널 모드 명령어를 실행하려 한다면 CPU는 mode bit 이 1이기 때문에 이를 거부한다.
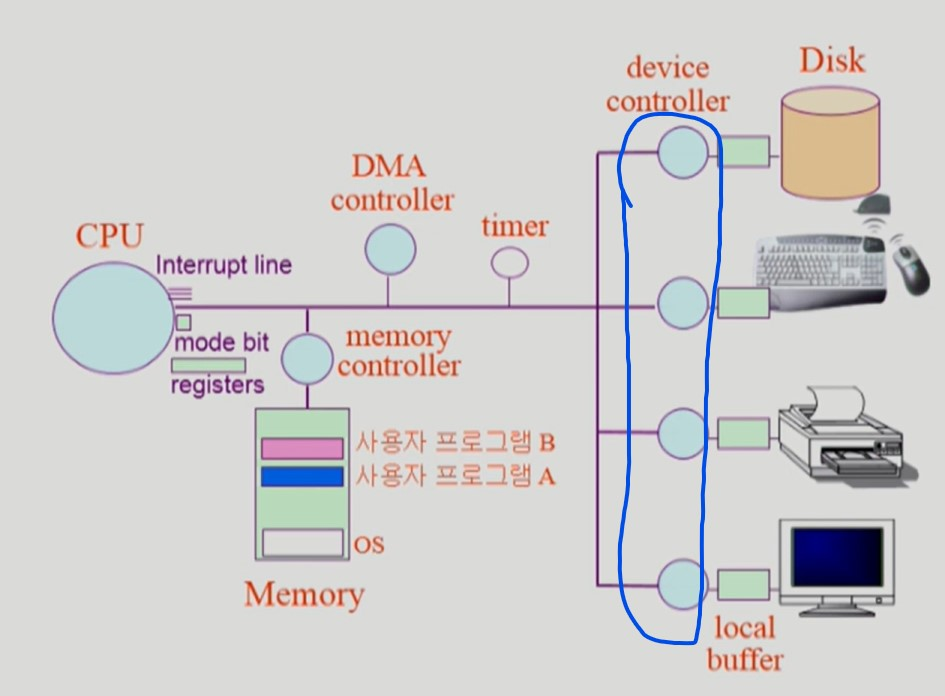
Device Controller
-
CPU와 I/O device 는 성능차이가 심하다.
-
따라서 CPU는 I/O device 에 직접 접근하지 않는다.
-
CPU는 I/O 작업을 device controller 에게 맡기고 자기는 메모리의 명령어를 읽는 일을 계속해서 수행한다.
-
-
device controller 는 해당 I/O 장치를 관리하는 일종의 작은 CPU이다.
-
I/O 가 끝난 경우 인터럽트를 발생시킨다.
device driver 는 OS의 device 처리 루틴 코드로 소프트웨어이다. 반면 device controller는 device controller 는 하드웨어이다.
DMA controller (Direct Memory Access)
-
device controller 는 I/O 작업이 끝나면 인터럽트를 발생시킨다.
-
CPU 에 인터럽트를 걸면
-
CPU가 현재 실행하고 있는 프로그램을 중지시키고 local buffer 에 있는 데이터를 직접 복사해서 메모리 영역에 옮겨 넣는다.
-
빈번한 인터럽트는 CPU의 실행성능을 떨어뜨린다.
-
-
-
DMA controller 를 사용해 CPU에 걸리는 인터럽트를 줄일 수 있다.
-
I/O 작업이 끝나도 바로 CPU에 인터럽트를 걸지 않는다.
-
local buffer 의 데이터가 쌓여 일정 크기의 블록을 이루면 DMA controller 가 블록 데이터를 메모리 영역에 옮겨 넣는다.
-
이때 한번, CPU에 인터럽트를 발생시킨다.
-
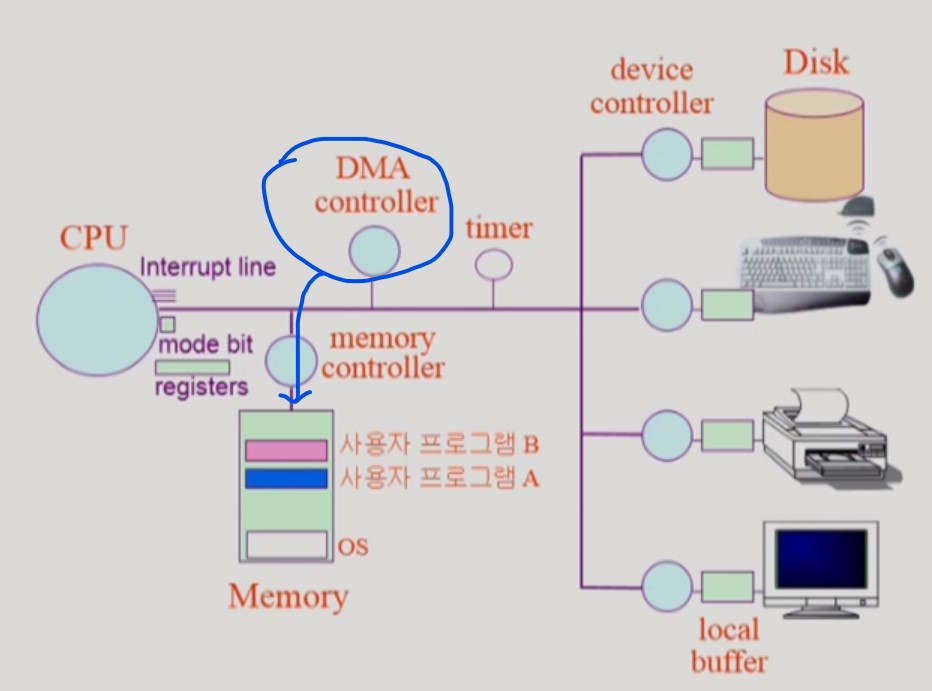
memory controller 는 CPU와 DMA controller 가 동시에 메모리에 접근하여 충돌하는 것을 막기 위한 장치이다.
인터럽트
-
타이머나 하드웨어가 발생시키는 인터럽트가 있다.
-
사용자 프로그램은 mode bit 이 1이기 때문에 I/O 명령어를 직접 사용할 수 없다.
-
사용자 프로그램이 software 인터럽트 (trap) 를 발생시킨다.
-
이를 통해 CPU 제어권을 OS에게 넘긴다.
-
-
사용자 프로그램의 오류 발생시에도 trap 을 발생시킨다.
-
CPU는 인터럽트 발생 시 현재 진행사항을 저장한 후, CPU 제어를 인터럽트 처리 루틴 (OS 커널 함수) 에 넘긴다.
- 인터럽트 처리 루틴 주소는 인터럽트 벡터가 갖고 있다.
-
현대의 운영체제는 인터럽트에 의해 구동된다.
- 인터럽트가 없다면 CPU는 항상 사용자 프로그램이 사용한다.
동기식 입출력 vs 비동기식 입출력
-
동기식 입출력 (Synchronous I/O)
-
I/O 작업이 완료되어야 사용자 프로그램이 진행될 수 있다.
-
I/O 가 끝날 때까지 다른 프로그램에 CPU를 넘기는 방식으로 작동한다.
- CPU의 낭비를 막는다.
-
-
비동기식 입출력 (Asynchronous I/O)
- I/O 작업 완료 여부와 상관없이 사용자 프로그램이 진행된다.
저장장치 계층 구조
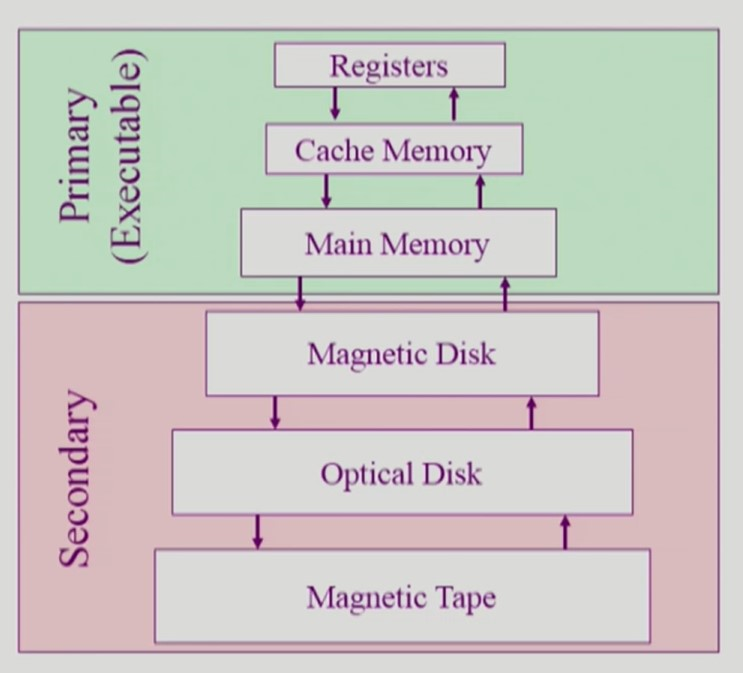
-
Primary 계층 저장장치는 빠르고, 비싸고, 휘발성이다.
-
Primary 계층 저장장치는 바이트 단위 주소를 갖기 때문에 CPU가 직접 접근하여 실행할 수 있다.
-
Secondary 계층 저장장치는 느리고, 저렴하고, 비휘발성이다.
-
Secondary 계층 저장장치는 섹터 단위 주소를 갖기 때문에 CPU가 직접 접근하여 실행할 수 없다.
프로그램의 실행
-
프로그램을 실행한다는 것은 프로그램을 이루는 code, data, stack 을 메모리 영역에 적재하는 것이다.
- 파일 시스템 ➔ 메모리
-
프로그램 실행파일을 물리 메모리에 모두 올린다면 많은 프로그램을 동시에 실행할 수 없다.
-
프로그램 실행 중에, 실행 파일의 모든 영역이 물리 메모리에 적재될 필요는 없다.
-
프로그램 실행에 당장 필요한 일부분만 적재하면 된다.
-
프로그램을 이루는 아직 실행하지 않은 다른 부분들은 swap area 에 존재하며, 필요할 때 교체한다.
-
이를 통해 보다 많은 프로그램들을 동시에 실행할 수 있다.
-
-
프로그램을 이루는 code, data, stack 은 가상 메모리에서만 연속적인 형태로 존재한다.
- 실제 물리 메모리에서는 현재 실행에 필요한 일부분만이 존재하고 나머지는 파편화되어 있다.
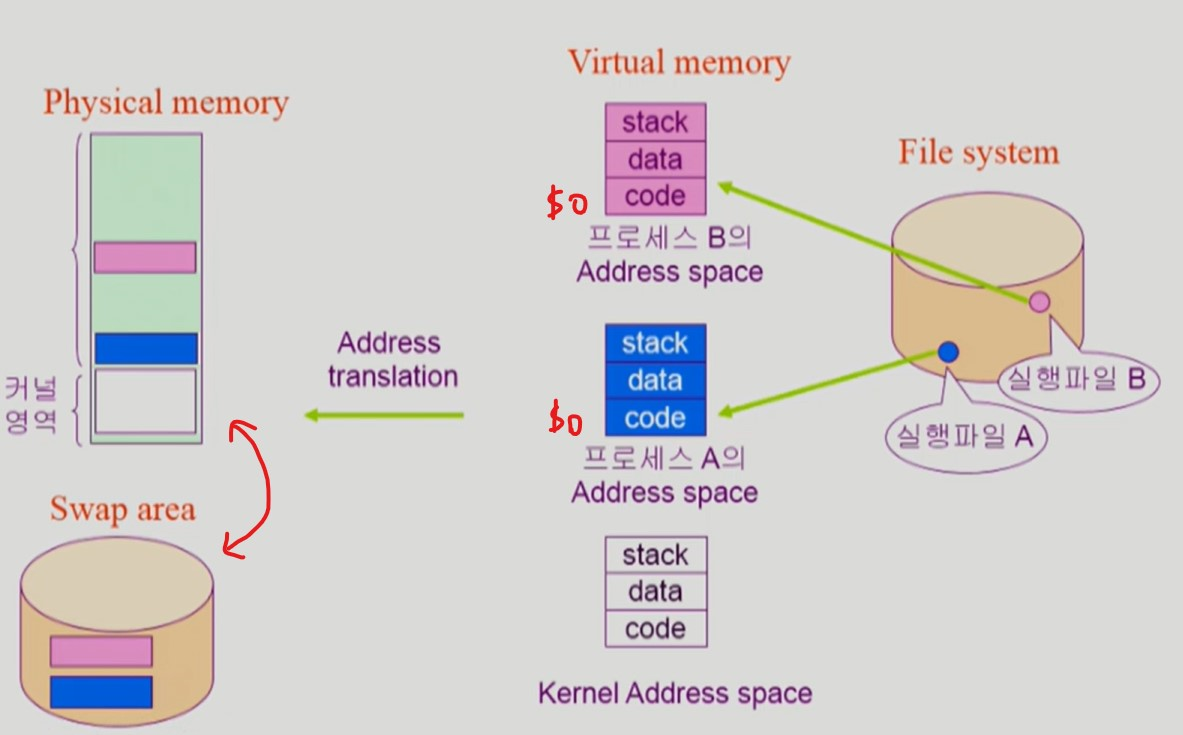
커널 영역 code, data, stack 은 모든 부분이 메모리에 항상 상주해 있다.
-
사용자 프로그램은 I/O 작업과 같은 커널 모드 명령어를 실행할 수 없다.
-
이 경우 system call 을 호출하여 OS에 CPU를 넘긴다.
-
CPU는 OS가 위치한 주소 공간 (커널 주소 공간) 에 접근하여 적절한 처리를 수행한 뒤, 다시사용자 프로그램에게 CPU 제어권을 넘긴다.
-
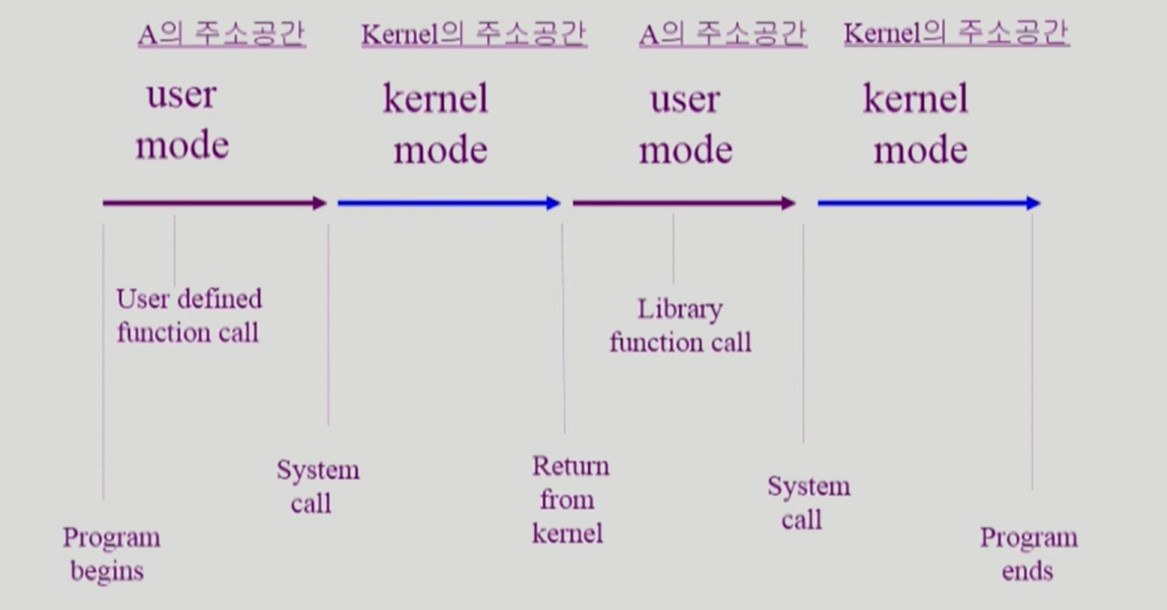
프로세스
- code, data, stack 이 메모리에 올라와 실행중인 프로그램을 프로세스라 한다.
프로세스 문맥
-
time sharing system 의 경우 OS에 의해 CPU를 사용하는 프로세스가 전환된다.
-
CPU를 빼앗겼던 프로세스가 다시 CPU를 점유할 때, 뺏기기 직전의 작업 정보들을 토대로 작업을 진행해야 한다.
- CPU를 뺏기기 직전의 프로세스 작업 정보들을 프로세스 문맥이라 하며, PCB, 커널 스택을 통해 OS가 관리한다.
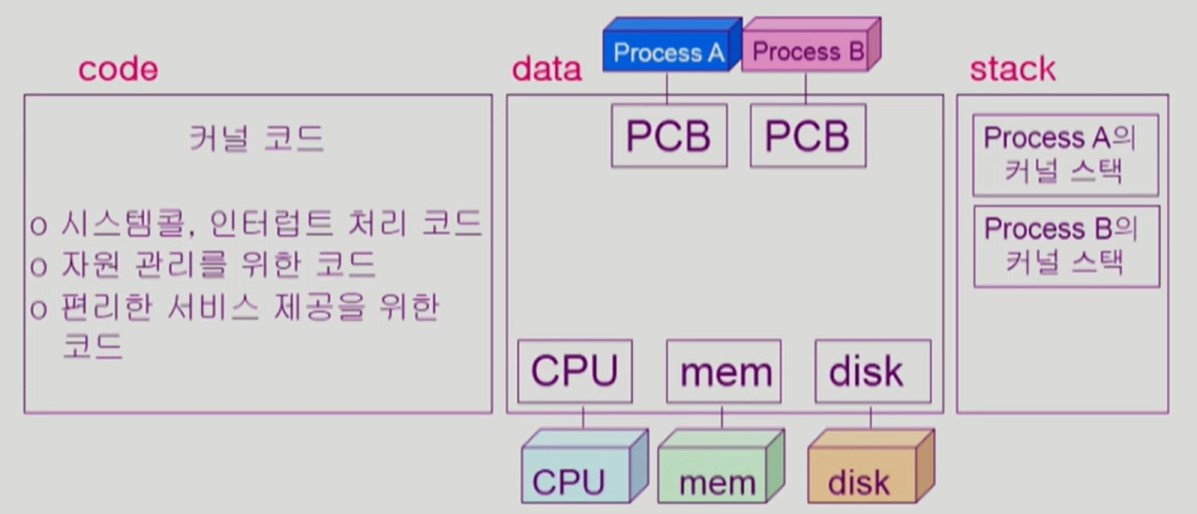
각각의 프로세스마다 각각의 커널 스택을 두어, 다른 프로세스와 섞이지 않고 독립된 커널 모드 작업을 처리한다.
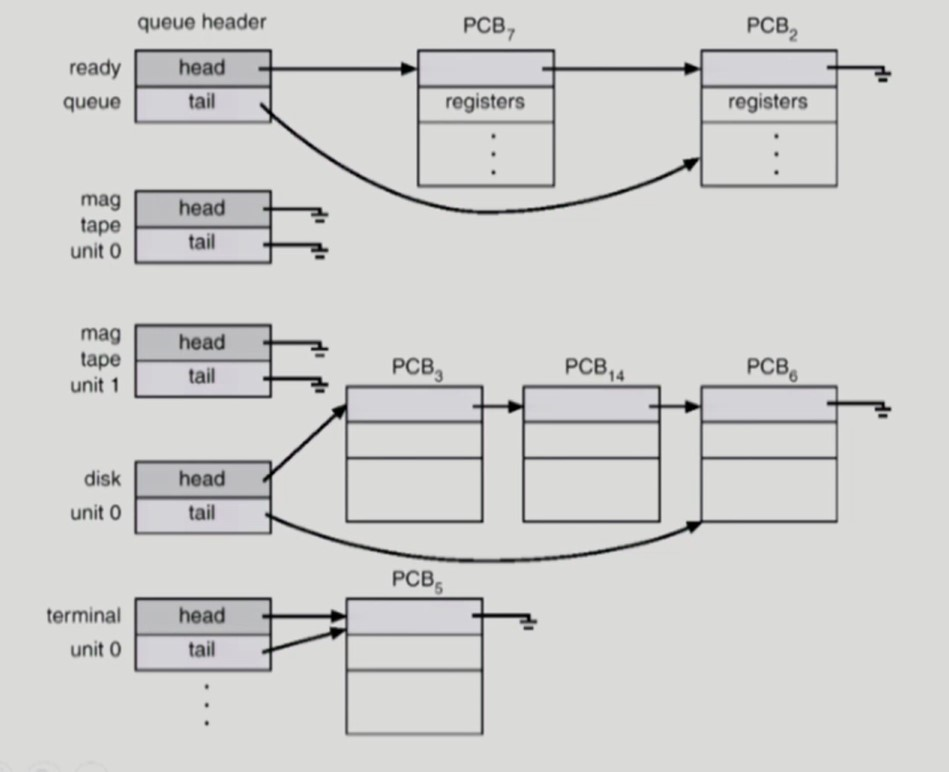
PCB
-
Process Control Block
-
OS가 프로세스를 관리하기 위해 각각의 프로세스마다 유지하는 정보
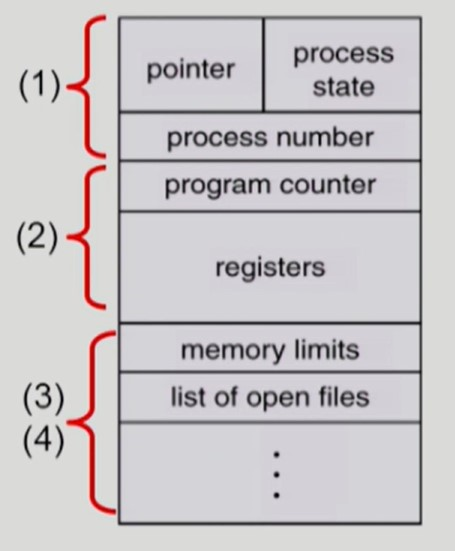
(1) OS가 관리하기 위해 사용하는 정보
(2) CPU 수행 시 필요한 하드웨어 값
(3), (4) code, data, stack 의 위치정보같은 메모리 정보와 파일 관련 정보
Context Switch
-
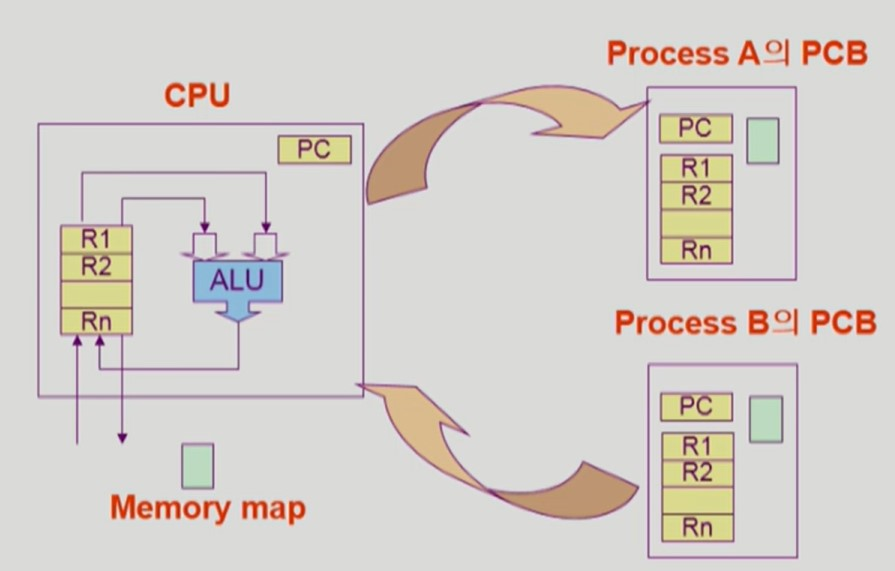
만약 현재 실행중인 프로세스 A 에서 CPU를 빼앗아 프로세스 B 에게 CPU를 주는 상황을 가정하자
-
현재 실행중인 CPU의 레지스터, Program Counter 와 같은 문맥 정보들을 프로세스 A의 PCB에 저장한다.
-
프로세스 B의 PCB에 저장되어 있는 프로세스 B의 문맥 정보들을 CPU에 가져와 실행한다.
-
이를 Context Switch 라 한다.
- 사용자 프로세스가 커널 모드 작업을 위해 system call 을 호출한 뒤, 다시 같은 사용자 프로세스로 돌아가는 것은 context switch 가 아니다.
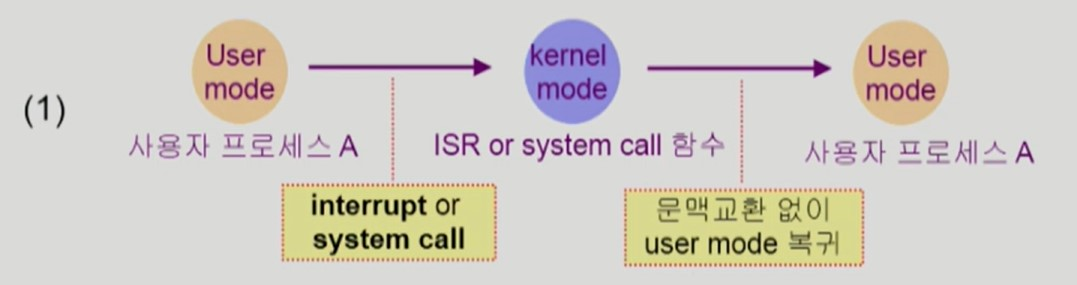
system call 호출 시 사용자 프로세스의 문맥을 PCB에 저장하긴 하지만, cache memory flush 와 같은 큰 오버헤드가 발생하지 않는다.
- 사용자 프로세스가 바뀌는 경우엔 context switch 가 발생한다.
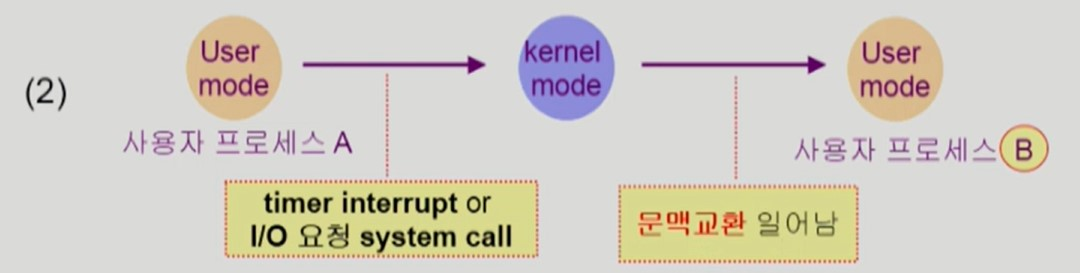
cache memory flush 와 같은 큰 오버헤드가 발생한다.
스케줄러
-
Short-term Scheduler (CPU Scheduler)
-
어떤 프로세스를 다음번에 실행시킬지 결정한다.
- 프로세스에 CPU를 준다.
-
-
Medium-term Scheduler (Swapper)
- 메모리에 너무 많은 프로세스가 올라가있다면, 메모리의 여유공간 마련을 위해 프로세스 몇 개를 통째로 메모리에서 쫓아낸다.
-
Long-term Scheduler
-
메모리에 올라갈 프로세스들을 결정한다.
-
time sharing system 에서는 사용하지 않는다.
- time sharing system 에서는 프로그램을 실행시키면, 바로 메모리에 올라가 CPU를 사용할 수 있는 상태가 된다.
-
프로세스의 상태
-
Running
- CPU를 잡고 명령어를 실행중인 상태
-
Ready
- CPU를 기다리는 상태
-
Blocked
-
CPU를 주어도 당장 명령어를 실행할 수 없는 상태
-
프로세스 자신이 요청한 이벤트 (I/O와 같은) 의 완료를 기다리는 상태
-
자신이 요청한 이벤트가 만족되면 Ready 로 전환한다.
-
-
Suspended (Stopped)
-
중기 스케줄러나 사용자의 요청등으로 프로세스 수행이 정지된 상태
-
프로세스가 메모리에서 통째로 쫓겨나 디스크에 swap out 된다.
-
외부에서 resume 해주어야 active 된다.
-
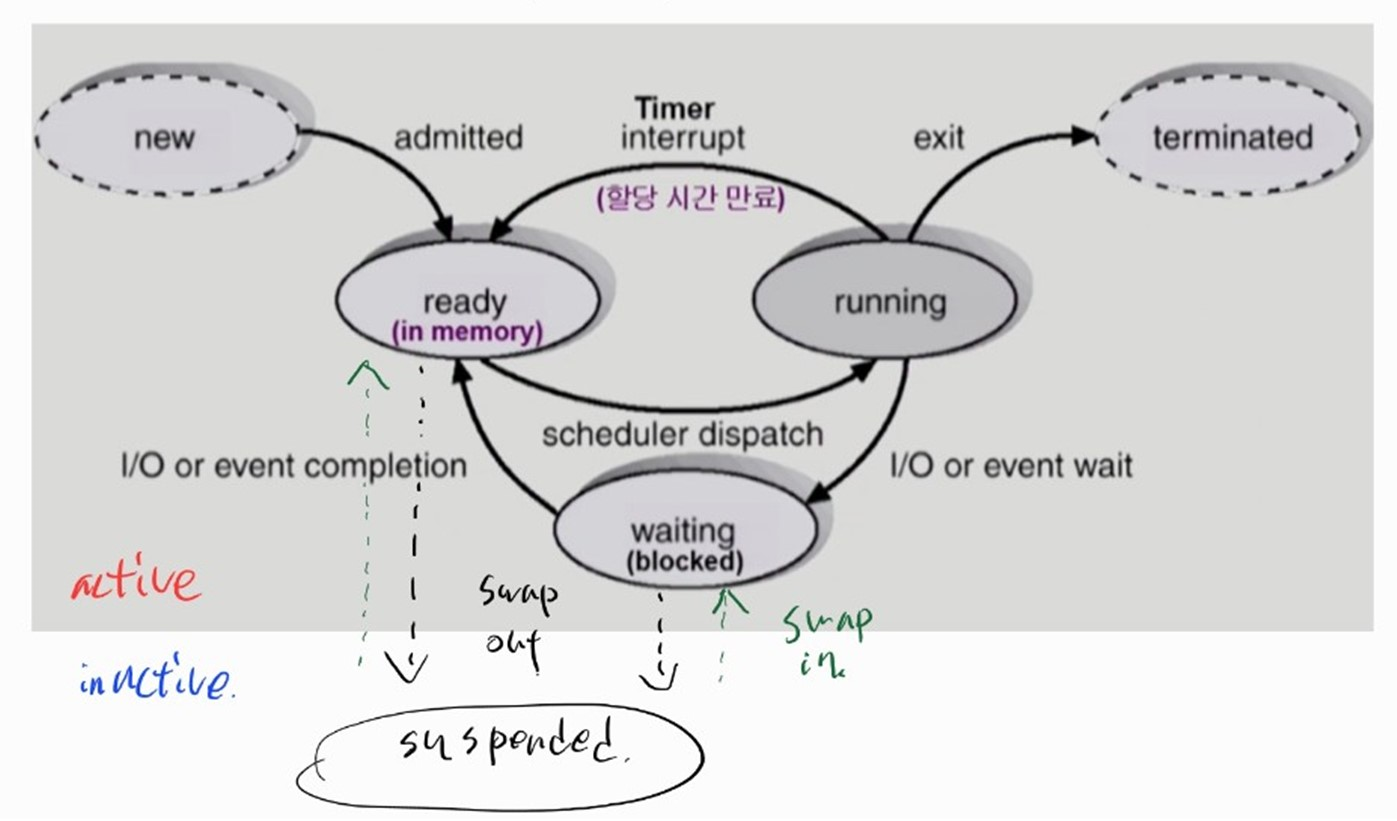
suspended 상태는 메모리에서 디스크로 쫓겨난 상태로 CPU 작업은 아무것도 할 수 없지만, 진행중이던 I/O 작업은 계속해서 할 수 있다.
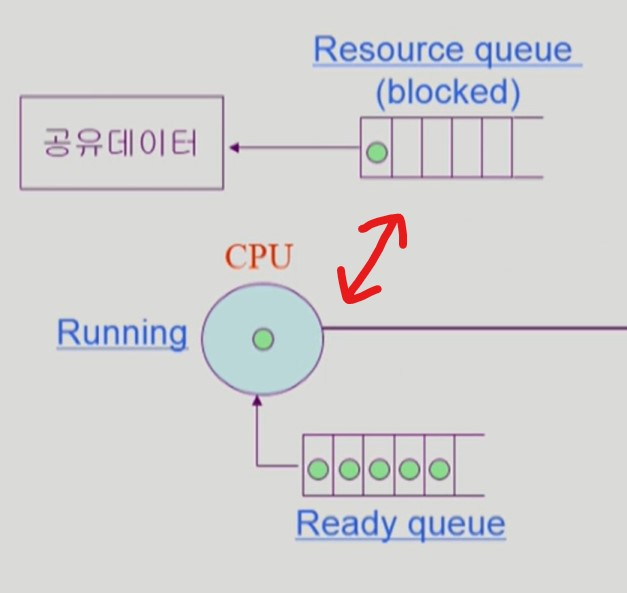
프로세스와 컴퓨터 시스템
- CPU 작업만 하는 프로세스
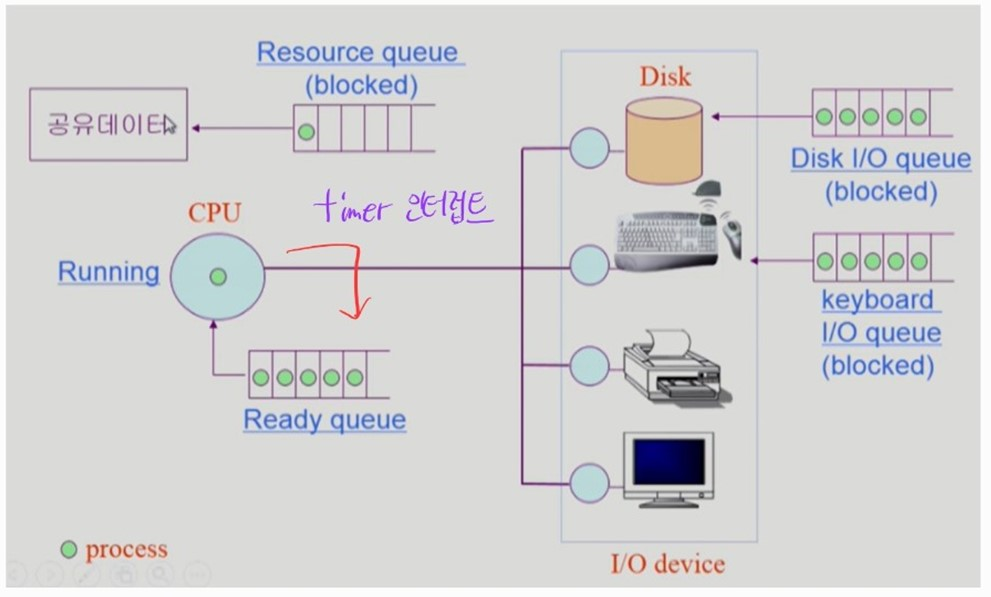
타이머 인터럽트가 발생하면 CPU를 점유하던 프로세스는 다시 CPU의 Ready queue 에서 대기한다.
- I/O 작업을 하는 프로세스
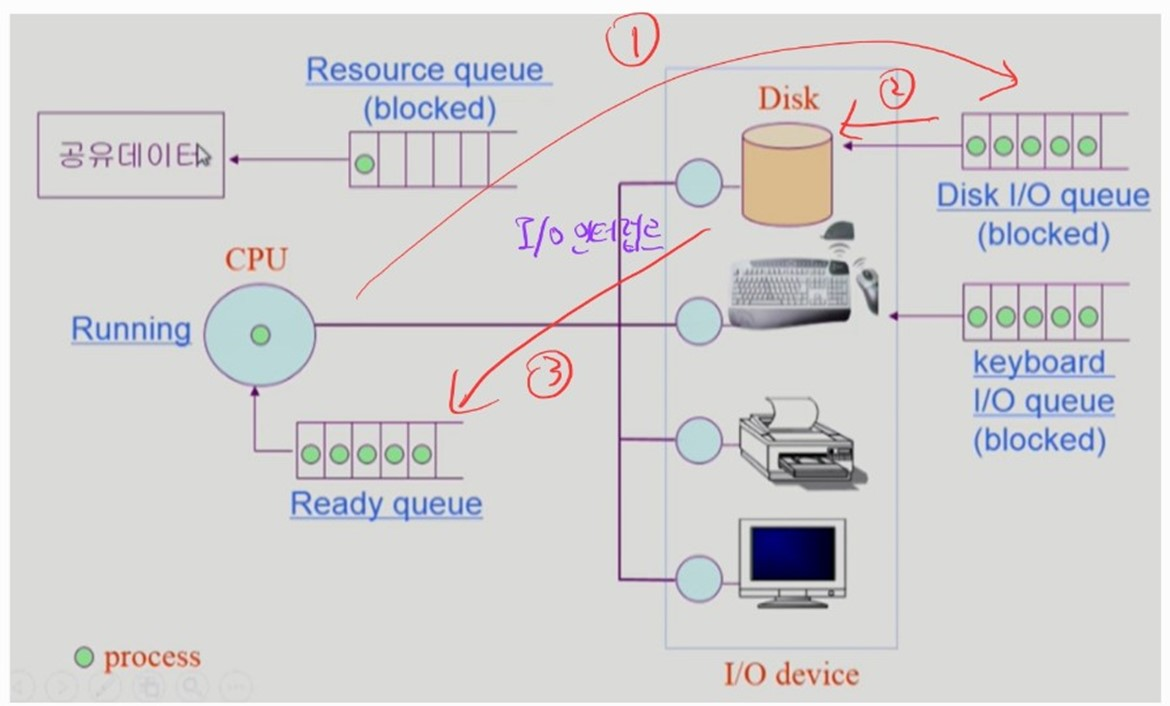
- CPU 작업 도중 I/O 작업이 필요하면, 해당 I/O 장치의 queue 에 프로세스를 넣는다. (프로세스 blocked)
- 프로세스의 I/O 작업을 처리한다.
- I/O 작업이 완료되면 I/O 인터럽트를 발생시킨다.
OS 는 해당 프로세스를 CPU Ready queue 에 넣는다. (프로세스 Ready)
- 공유 데이터를 사용하는 프로세스
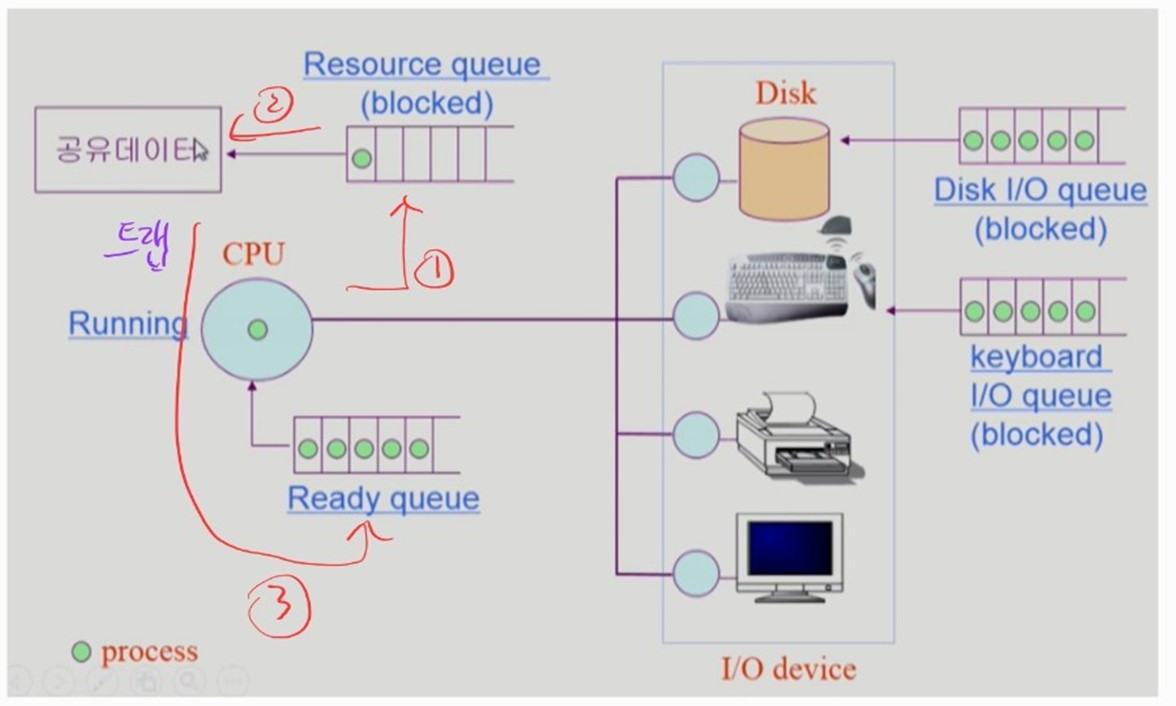
I/O 작업과 유사한 과정을 갖는다.
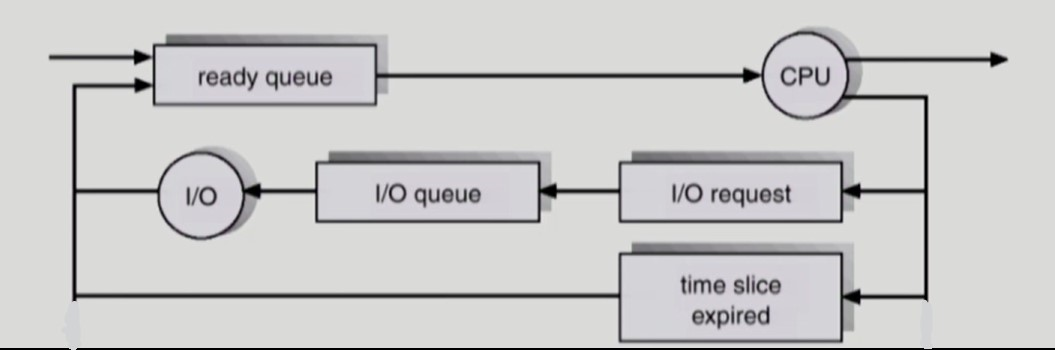
이러한 일련의 작업과정들을 이와같이 도식화할 수 있다.
- 이러한 queue 는 커널 주소 공간의 data 영역에서 관리된다.
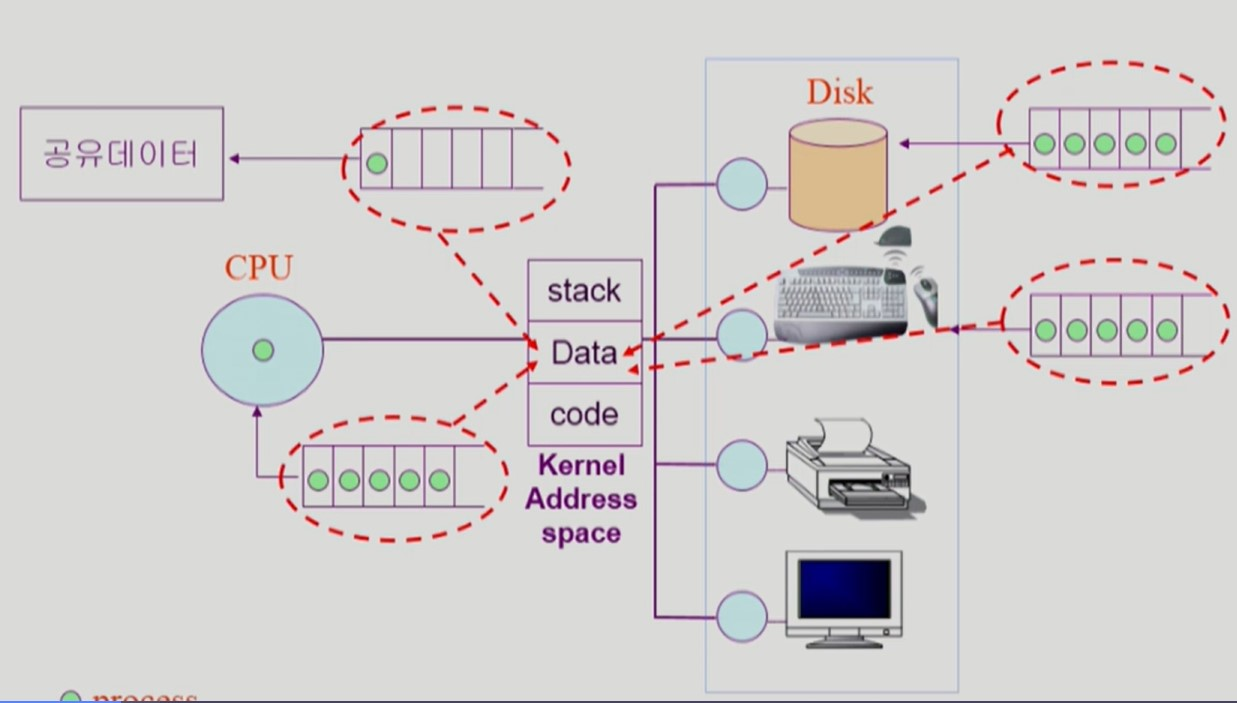
- data 영역에서 queue 를 관리한다.
- ready queue 는 CPU 작업을 기대하는 queue, 나머지는 I/O 작업을 기다리는 queue 이다.
- 실제 줄을 세우는 것은 프로세스 그 자체가 아니라 PCB이다.
스레드
-
프로세스 내부에 존재하는 여러개의 CPU 수행 단위
-
프로세스는 code, data, stack 의 주소 공간을 갖는다.
-
만약 동일한 작업을 하는 프로세스가 여러개라면 메모리에 많은 공간이 필요하다.
-
따라서 동일한 작업을 하는 여러개의 프로세스가 필요하다면 하나의 프로세스 주소공간을 공유하며 코드의 다른 부분을 실행할 수 있는 경량화된 미니 프로세스 여러개를 내부적으로 갖는 것이 효율적이다.
- 프로세스 내부에 존재하는 경량화된 미니 프로세스가 바로 스레드이다.
-
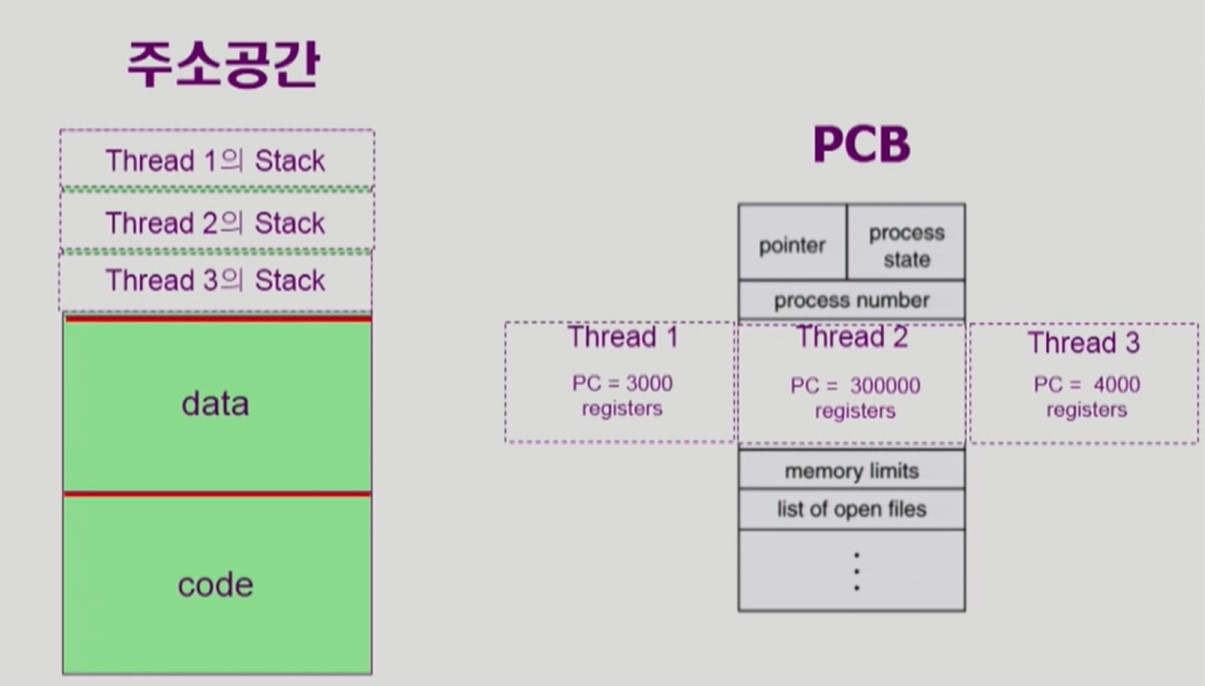
프로세스 하나에 여러개의 CPU 수행 단위 (스레드) 를 가진 경우
- 각 스레드마다 Program Counter, 레지스터, stack 을 갖는다.
- cpu 수행 관련 정보만 각 스레드가 별도로 갖는다.
- 그 외의 프로세스 정보들은 모두 공유한다.
- 메모리 주소 공간, 프로세스 상태 등
스레드의 장점
-
작업 처리의 효율성이 높아진다.
-
하나의 서버 스레드가 I/O 작업 등에 의해 blocked 상태인 동안에도, 다른 서버 스레드가 실행되어 필요한 작업을 처리할 수 있다.
-
멀티 코어인 경우, 병렬 작업 처리로 효율성을 높일 수 있다.
-
-
프로세스 자원을 공유하기 때문에 메모리 공간의 낭비를 줄일 수 있다.
-
프로세스 생성 및 프로세스간의 context switching 보다는 스레드 생성 및 스레드 간의 context switching 오버헤드가 훨씬 작다.
프로세스 관리
프로세스 생성
-
부모 프로세스가 자식 프로세스를 복제 생성한다.
-
fork()system call 호출 -
부모 프로세스의 Program Counter 를 포함한 부모 프로세스 문맥을 그대로 복제한다.
-
-
프로세스는 트리 구조를 형성한다.
-
일반적으로 부모 프로세스와 자식 프로세스는 CPU를 두고 경쟁한다.
- 예외적으로, 부모 프로세스가 자식 프로세스의 작업 처리를 기다리는 방식으로 협력할 수도 있다.
-
만약 자식 프로세스에 write 가 발생하지 않는다면 부모 프로세스의 주소 공간을 그대로 사용한다.
- write 가 발생하면 부모 프로세스의 자원들을 복사하여 자식 프로세스의 새로운 주소 공간을 만든다. (Copy-on-Write)
-
복제된 자식 프로세스에서 부모와 전혀 다른 프로그램을 실행하고 싶다면
exec()system call을 호출한다.- 이를 통해 새로운 프로그램을 메모리에 올린다.
forK()system call
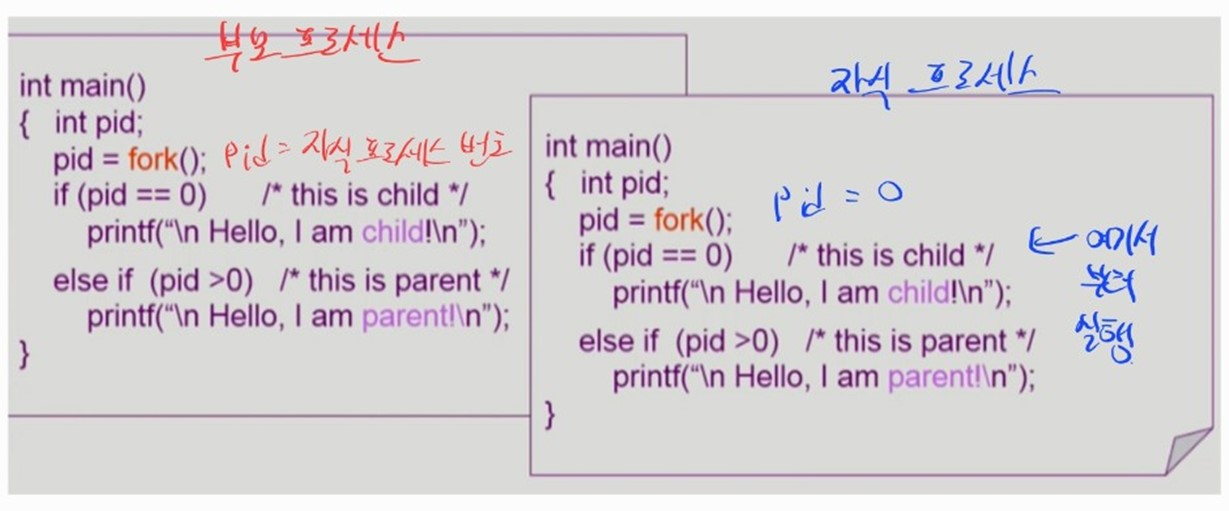
- 부모 프로세스가
pid = fork()를 실행하여 자식 프로세스를 복제 생성한다.
- 자식 프로세스는 부모 프로세스의 Program Counter 를 그대로 복제하므로, 자식의 다음 실행 명령어는
if (pid == 0)이다.
- 부모 프로세스에서
fork()의 반환값은 자식 프로세스의 번호이다.
- 자식 프로세스는
fork()를 호출하지 않았으므로pid = 0이다.
exec()system call
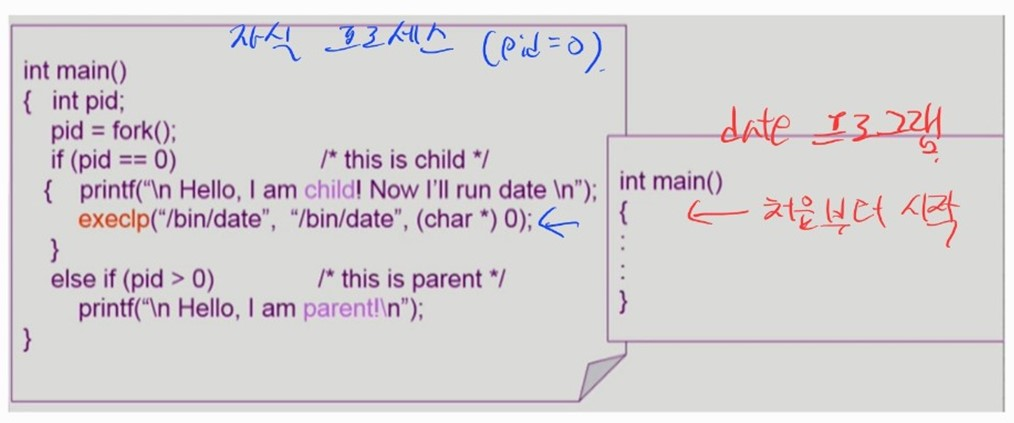
- 현재 프로세스를
exec()system call 에서 지정하는 프로그램으로 완전히 덮어 씌운다.
- 이렇게 실행하는 프로세스는 처음 주소부터 명령어를 실행한다.
exec()이후의 코드들은 실행할 수 없다.
- 이전 프로세스로 절대 돌아갈 수 없다.
프로세스 종료
-
자발적 종료
-
프로세스가 작업을 모두 완료하면
exit()system call 을 호출하여 OS가 프로세스를 종료하도록 한다.-
OS는 부모 프로세스에게 프로세스 종료를 알린다.
-
OS는 프로세스에 할당된 자원들을 모두 다시 가져간다.
-
-
-
비자발적 종료
-
부모 프로세스가 종료되는 경우, 자식 프로세스들도 모두 종료된다.
-
부모 프로세스가 자식 프로세스를 종료시킬 수도 있다.
- 자식이 할당 자원의 한계치름 넘어서거나, 자식의 태스크가 더 이상 필요없는 경우
-
wait()system call

wait()system call 호출 시, 부모 프로세스는 자식 프로세스의 작업이 종료될 때까지 block 된다.- 자식 프로세스 작업이 종료되면 부모 프로세스는 CPU를 점유할 수 있는 ready 상태가 된다.
CPU Scheduling
-
다양한 작업 시간을 갖는 프로세스들이 있다.
-
사용자와 상호작용하는 Interactive 프로세스(I/O bound job) 의 경우 적절한 응답시간이 필요하다.
- 이 경우 CPU bound job 보다 우선적으로 CPU를 주어 응답성을 높여야 한다.
-
이처럼 다양한 종류의 프로세스들 사이에서 CPU를 효율적으로 사용하기 위해서 CPU Scheduling 이 필요하다.
CPU Scheduler & Dispatcher
-
운영체제 안에 존재하는 코드이다.
-
CPU Scheduler
-
Ready 상태의 프로세스 중에서 다음에 CPU를 줄 프로세스를 고른다.
-
프로세스가 CPU를 자진 반납하는 nonpreemptive 방식과 프로세스로부터 CPU를 강제로 빼앗는 preemptive 방식이 있다.
-
-
Dispatcher
-
CPU Scheduler 에 의해 선택된 프로세스에게 CPU를 넘긴다.
-
Context switching 이 발생한다.
-
CPU Scheduling 성능 척도
-
CPU utilization (이용률)
- 전체 시간 중에서 CPU가 놀지 않고 일한시간의 비율
-
Throughput (처리량)
- 주어진 시간 동안 처리한 작업 개수
-
Turn-around time
-
특정 프로세스가 ready queue 에 들어온 시간부터, 작업을 모두 끝내거나 I/O 사용을 위해 ready queue 에서 나가기까지의 시간
-
특정 프로세스의 CPU burst time 을 의미한다.
-
-
Waiting time
-
특정 프로세스가 ready queue 에서 대기한 시간의 총합
-
CPU를 점유한 시간은 포함되지 않는다.
-
-
Response time
- 특정 프로세스가 ready queue 에 들어와서 처음으로 CPU를 얻기까지 걸린 시간
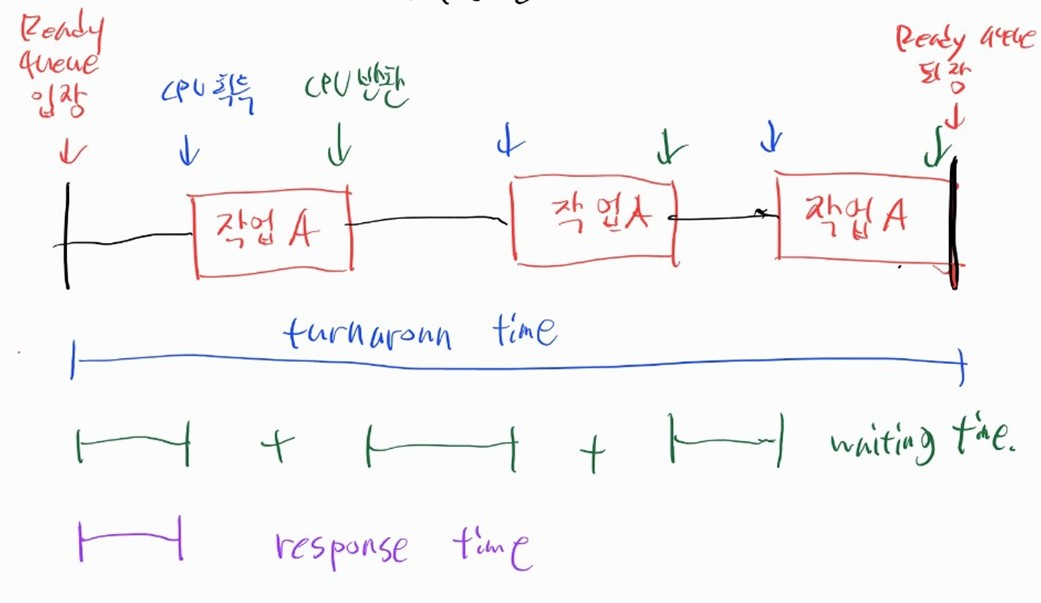
주의사항
-
Turn-around time, Waiting time, Response time 은 프로세스의 시작부터 종료까지의 시간동안 측정하는 것이 아니다.
-
ready queue 에 들어온 시간부터 나가는 시간까지인 CPU burst 시간동안 측정하는 것이다.
-
따라서 Turn-around time, Waiting time 에 I/O burst 시간은 포함되지 않는다.
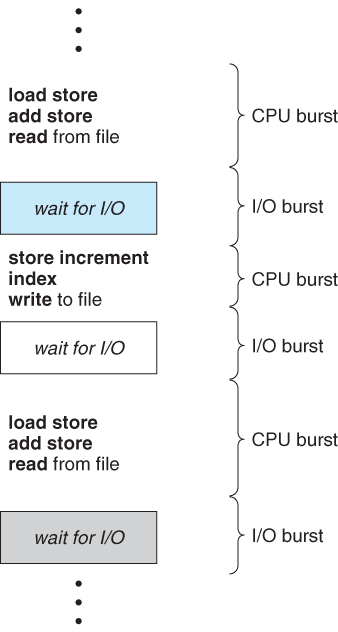
- 프로세스 종료 여부와 상관없이 CPU burst time이 중요하다.
- 프로세스가 종료되지 않고 I/O 작업을 하러 ready queue 를 나갔더래도, 해당 시점에 turn-around time 측정을 종료한다.
CPU Scheduling 알고리즘
-
FCFS
-
First-Come First-Served
-
먼저 도착한 프로세스가 CPU를 갖는다.
-
해당 프로세스가 CPU를 자진 반납하기 전까지 뒤늦게 온 프로세스들은 기다린다.
-
nonpreemptive 방식
-
-
짧은 작업시간을 갖는 프로세스가 먼저 온 긴 작업시간을 갖는 프로세스때문에 오랜시간 기다리게 된다.
-
convoy effect 발생
-
average waiting time 이 증가한다.
-
-
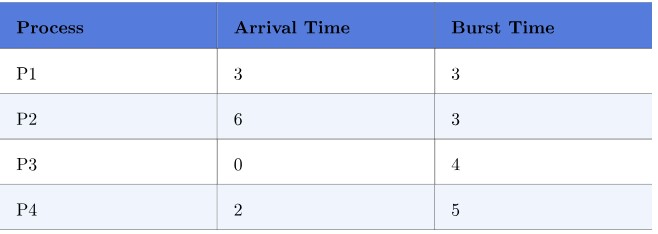
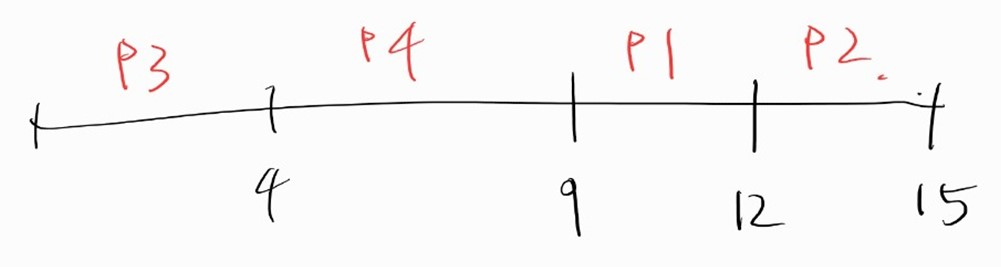
- waiting time
- P1 : 9-3 = 6
- P2 : 12-6 = 6
- P3 : 0
- P4 : 4-2 = 2
- average waiting time = (6+6+0+2)/4 = 3.5
-
SJF
-
Shortest Job First
-
CPU burst time 이 가장 짧은 프로세스가 제일 먼저 CPU를 갖는다.
-
preemptive 방식과 nonpreemptive 방식이 있다.
-
preemptive 방식은 현재 CPU 를 갖고 있는 프로세스의 남은 CPU burst time 보다 더 짧은 CPU burst time 을 갖는 새로운 프로세스가 ready queue 에 도착하면 CPU를 빼앗긴다.
-
nonpreemptive 방식은 일단 CPU를 점유하면 자신의 CPU burst 가 끝날때까지 CPU를 빼앗기지 않는다.
-
-
가장 작은 average waiting time 을 갖는 알고리즘이다.
- preemptive 방식이 nonpreemptive 방식 보다 더욱 작은 average waiting time 을 갖는다.
-
긴 CPU burst time 을 갖는 프로세스는 영원히 CPU를 가질 수 없는 starvation 이 발생할 수 있다.
-
CPU burst time 을 정확하게 예측할 수 없다.
-
CPU burst time 을 추정하여 SJF 를 구현할 수 있다.
-
이때 추정치는 과거의 CPU burst time 을 이용해 예측한다.
-
-
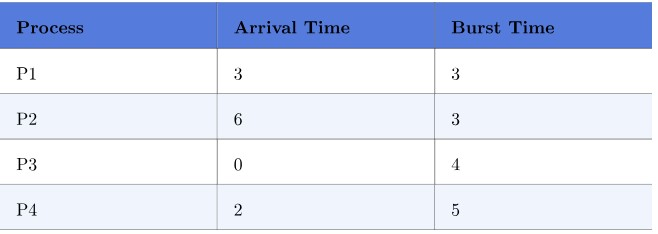
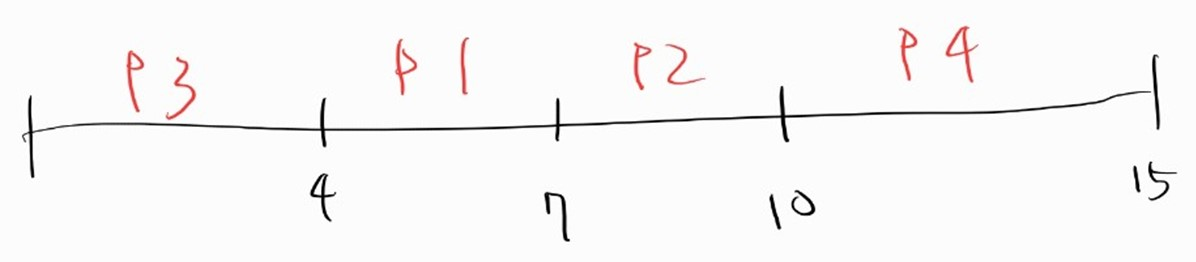
- waiting time
- P1 : 4-3 = 1
- P2 : 7-6 = 1
- P3 : 0
- P4 : 10-2 = 8
- average waiting time = (1+1+0+8)/4 = 1.25
-
Priority Scheduling
-
우선순위가 높은 프로세스에게 CPU를 할당한다.
-
preemptive 방식으로 구현할 수도 있고, nonpreemptive 방식으로 구현할 수도 있다.
-
SJF 는 짧은 CPU burst time 을 우선순위로 하는 Priority Scheduling 이다.
-
낮은 우선순위의 프로세스가 절대 CPU를 가질 수 없는 starvation 이 일어날 수 있다.
- 이를 해결하기 위해 오랫동안 대기한 프로세스의 우선순위를 올려주는 Aging 을 적용할 수 있다.
-
-
Round Robin
-
현재 OS에서 주로 사용하는 스케줄링 방식
-
각 프로세스는 동일한 크기의 CPU 할당 시간을 가진다.
-
할당 시간이 지나면 프로세스는 CPU를 빼앗기고 ready queue 에 맨 뒤로 가서 다시 줄을 선다.
-
preemptive 방식
-
-
각 프로세스들의 response time 이 짧아진다.
- n 개의 프로세스가 ready queue 에 있고, 할당시간이 q 라고 하면 어떤 프로세스도 CPU를 얻기 위해 (n-1)q 시간 이상 기다리지 않는다.
-
CPU 할당 시간이 아주 커지면 FCFS 방식이 된다.
-
CPU 할당 시간이 아주 작아지면 Context switch 가 빈번히 발생하여 큰 오버헤드가 발생한다.
-
만약 대기하는 프로세스들의 작업시간이 비슷하다면, average waiting time 은 증가한다.
-
작업을 하나씩 처리하여 ready queue 를 빨리 비우는 것이 waiting time 과 turn-around time 을 줄이는 측면에서 효율적이다.
-
Round Robin 방식은 ready queue 를 빨리 비우지 못한다.
-
그러나 일반적으로는 CPU burst time 이 짧고 긴 프로세스가 섞여 있으므로 average waiting time 은 아주 크게 증가하지 않고, response time 이 짧다는 점에서 Round Robin 방식이 효과적이다.
-
-
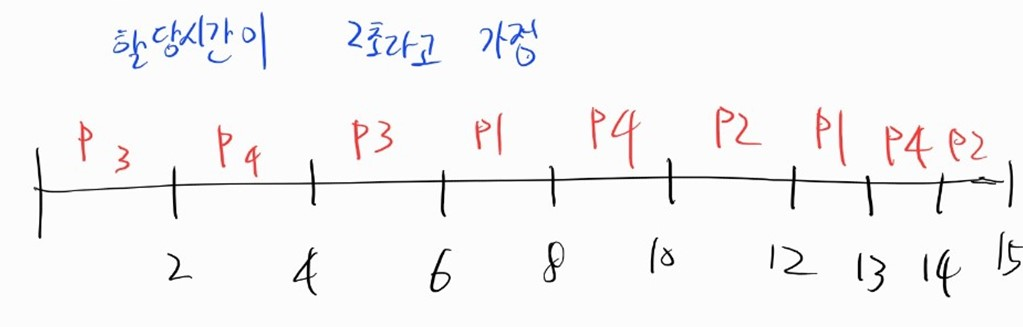
- waiting time
- P1 : 7
- P2 : 6
- P3 : 2
- P4 : 7
- average waiting time = (7+6+2+7)/4 = 5.5
- response time
- P1 : 3
- P2 : 4
- P3 : 0
- P4 : 0
Multilevel Queue
-
ready queue 를 여러개로 분할하여 각 ready queue 마다 다른 CPU Scheduling 알고리즘을 적용할 수도 있다.
-
낮은 우선순위를 가진 ready queue 에 존재하는 프로세스들은 starvation 을 겪을 수 있다.
-
각 ready queue 에 CPU time 을 적절한 비율로 할당하여 이를 해결할 수 있다.
-
ex) 높은 우선순위의 ready queue 는 80% CPU time 을 가지고 낮은 우선순위의 ready queue 는 20% CPU time 을 가지도록 나눌 수 있다.
-
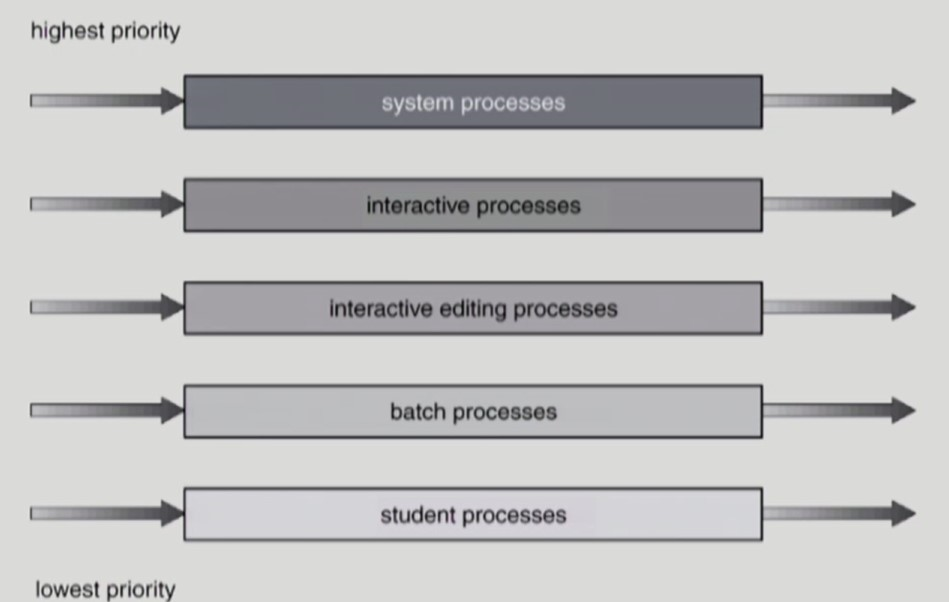
- 사용자와 상호작용하는 interactive process 는 보다 높은 우선순위 큐에 넣고, response time 을 줄이기 위해 Round Robin Scheduling 을 사용할 수 있다.
- CPU bound 작업인 batch process 는 보다 낮은 우선순위 큐에 넣고, 빨리 작업을 처리하여 ready queue 를 비우기 위해 FCFS Scheduling 을 사용할 수 있다.
- 여러개의 ready queue 간에 이동이 가능한 Multilevel Feedback Queue 도 있다.
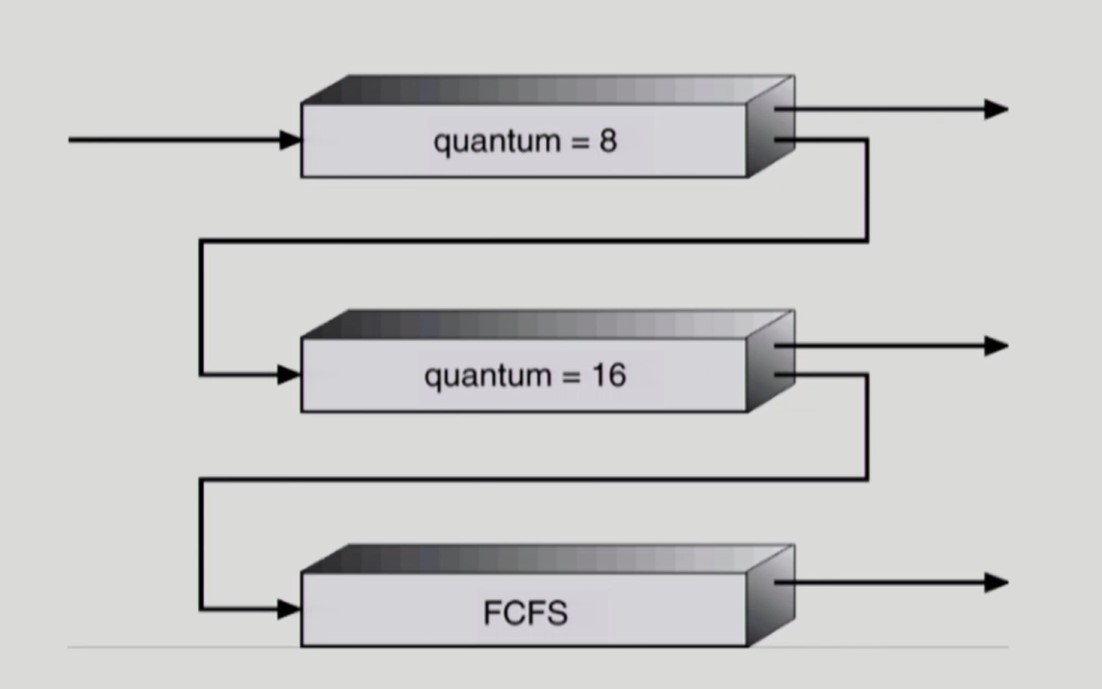
- CPU burst time 이 짧은 프로세스가 높은 우선순위를 갖고, CPU burst time 이 긴 프로세스는 낮은 우선순위를 갖게 되는 Multilevel Feedback Queue 이다.
- 최상위 우선순위 큐에 들어온 프로세스는 8초간 CPU를 가질 수 있다.
- CPU burst 작업이 남은 프로세스는 차상위 우선순위 큐에 들어가 16초간 CPU를 가질 수 있다.
- CPU burst 작업이 남은 프로세스는 최하위 우선순위 큐에 들어간 순서대로 CPU burst 작업이 끝날 때까지 CPU를 점유한다.
Thread Scheduling
-
Local Scheduling
-
OS 가 존재를 인식하지 못하는 User level thread 가 해당
-
사용자 프로세스 내부에서 자체적으로 어떤 스레드에게 CPU를 줄지 결정한다.
-
-
Global Scheduling
-
OS 가 존재를 인식하는 Kernel level thread 가 해당
-
OS의 CPU Scheduler 가 어떤 스레드에게 CPU를 줄지 결정한다.
-
Process Synchronization
-
프로세스 동기화란
-
프로세스의 실행 순서를 정해주어 Race Condition 을 막는 것
-
여러 프로세스가 사용하는 공유 자원의 일관성을 유지하도록 한다.
-
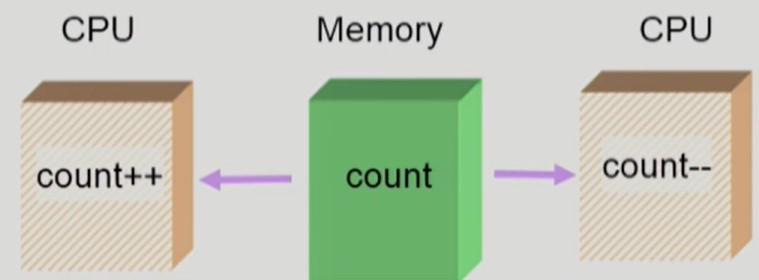
데이터의 접근과 연산
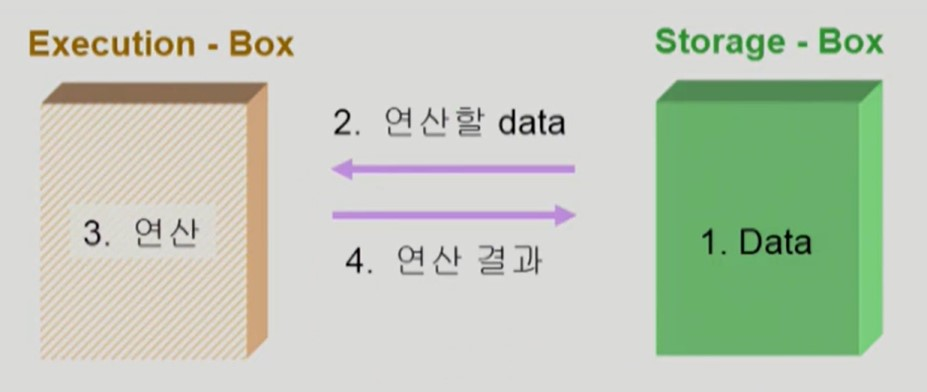
ex) Execution-Box: CPU,
Storage-Box: Memory
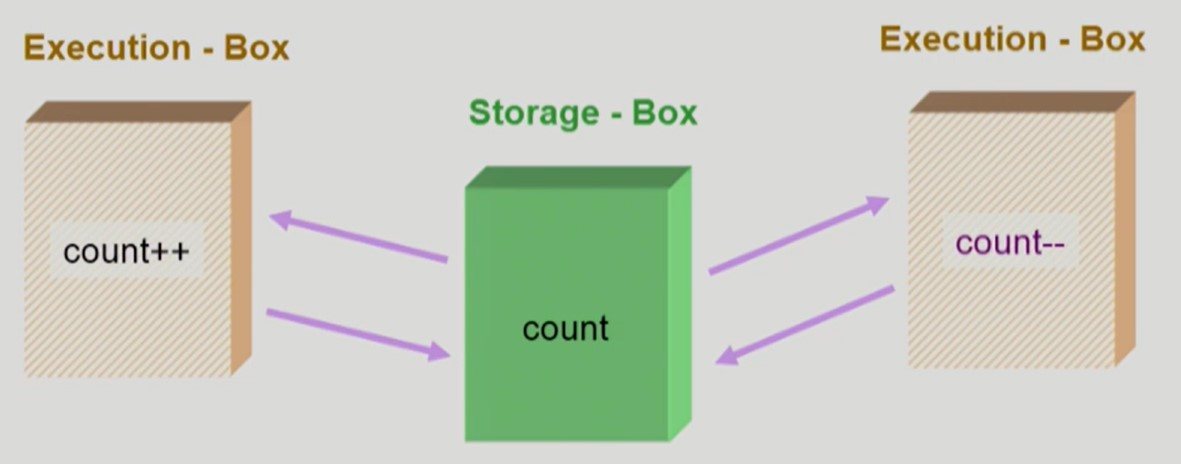
- 다음과 같이 Storage-Box 를 공유하는 Execution-Box 가 여러개인 경우, Race Condition 이 일어날 수 있다.
- Execution-Box 2개가 모두 동시에 Storage-Box 의
count를 읽어간 뒤, 각자의 연산을 수행하면 뒤늦게 한 연산만 반영될 수 있다.
OS Race Condition
-
공유 자원에 대해 여러개의 프로세스가 접근하여 조작하는 경우, 조작의 타이밍이나 순서등이 결과값에 영향을 줄 수 있는 상태
-
크게 3가지 경우에서 발생할 수 있다.
-
OS 코드 (Kernel) 수행 중 인터럽트 발생 시
-
사용자 프로세스가 system call 을 통해 kernel mode 수행 중인데, 다른 프로세스로의 context switch 가 발생한 경우
-
멀티 프로세서 환경
-
-
사용자 프로세스는 각자의 주소 공간에 데이터가 있고, 이 데이터는 다른 프로세스가 접근할 수 없기 때문에 사용자 프로세스 데이터에 대한 Race Condition 은 일반적으로 발생하지 않는다.
- 주로 커널 모드에서 커널의 데이터에 대한 Race Condition 이 발생한다.
OS 코드 수행 중 인터럽트 발생 시의 Race Condition
-
커널 모드 실행 중 인터럽트가 발생하여 인터럽트 루틴을 처리할 때 발생할 수 있다.
-
커널 모드와 인터럽트 루틴이 커널의 공유자원을 동시에 접근하여 조작하는 경우 데이터 일관성이 깨진다.
- OS Race Condition
-
커널 모드 작업과 인터럽트 루틴 모두 커널 코드이므로 커널의 주소 공간을 공유한다.
-
-
단일 CPU 환경에서도 발생할 수 있다.
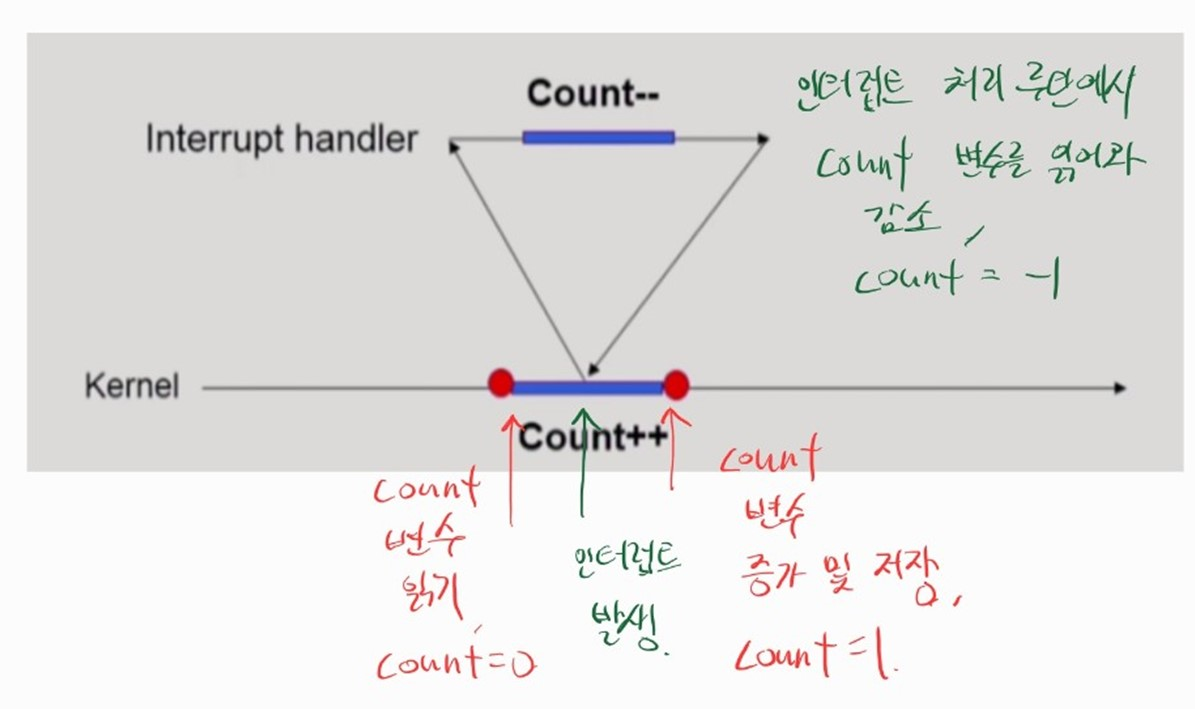
Count는 커널의 공유 자원이므로 초기값을 0으로 가정한다.- 결과적으로 인터럽트 처리루틴에서의
Count--작업은 반영되지 않는다.
- 이러한 문제를 해결하기 위해서 커널 모드에서 공유 자원을 조작하는 도중에, 인터럽트가 들어와도 바로 인터럽트를 처리하지 않고 커널 모드 작업이 끝나기를 기다린다.
사용자 프로세스가 system call을 통해 kernel mode 수행중인데, 다른 프로세스로의 context switch 가 발생한 경우 Race Condition
-
사용자 프로세스가 system call 을 통해 커널 모드를 수행하며 커널의 공유 자원을 읽은 상태에서
-
다른 사용자 프로세스로 CPU가 넘어간 뒤 (Context Switching)
-
다른 사용자 프로세스가 system call 을 통해 커널 모드에서 앞선 프로세스가 읽어온 커널의 공유 자원을 조작한다.
-
다시 CPU가 처음의 사용자 프로세스에게 넘어가 커널의 공유 자원을 조작하면 데이터 일관성이 깨진다. (OS Race Condition)
- 단일 CPU 환경에서도 발생할 수 있다.
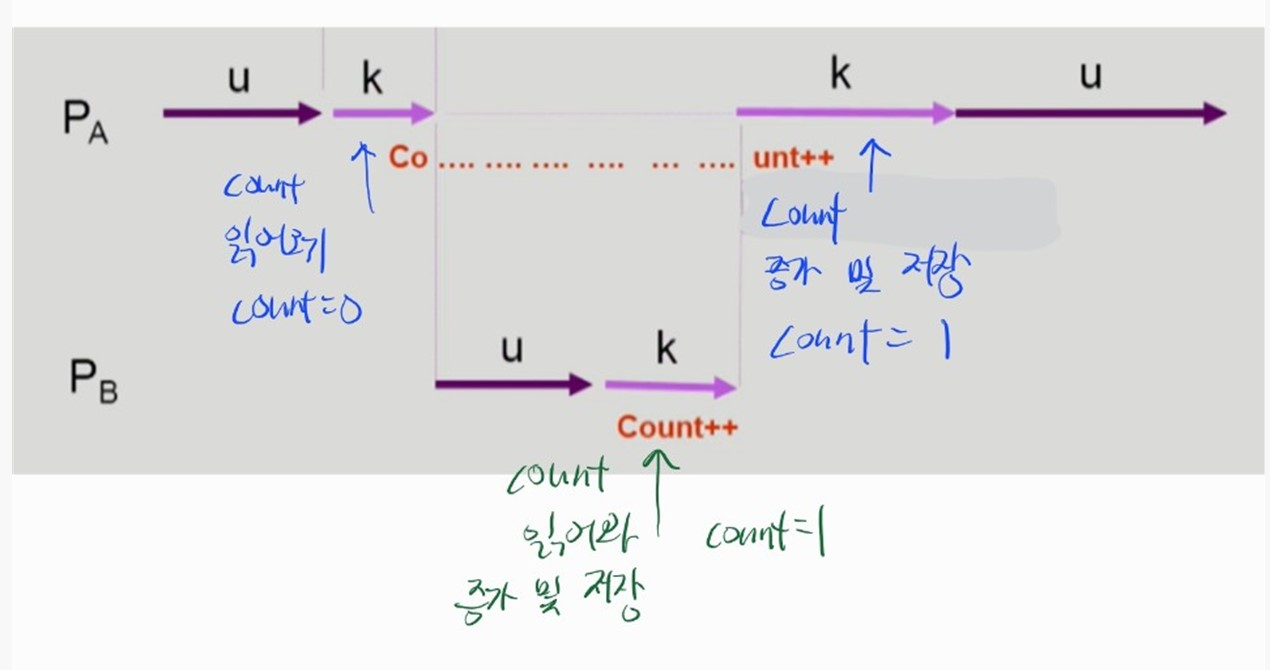
Count는 커널의 공유자원으로 초기값을 0으로 가정한다.- 결과적으로 사용자 프로세스 B에서의
Count++작업은 반영되지 않는다.
- 이러한 문제를 해결하기 위해서 커널 모드 작업중엔 CPU 점유시간이 끝나도 CPU를 빼앗기지 않고, 커널 모드 작업이 끝나면 CPU를 바로 뺏기도록 설정한다.
멀티 프로세서 환경에서의 Race Condition
-
여러개의 CPU가 공유 자원에 접근하는 경우 발생한다.
-
앞선 Race Condition 의 해결책인 인터럽트 enable/disable 로는 해결할 수 없다.
-
커널 모드를 한 개의 CPU 만 들어갈 수 있도록 하거나, 공유 자원에 대한 lock/unlock 을 통해 Race Condition 을 막을 수 있다.
Critical Section Problem
-
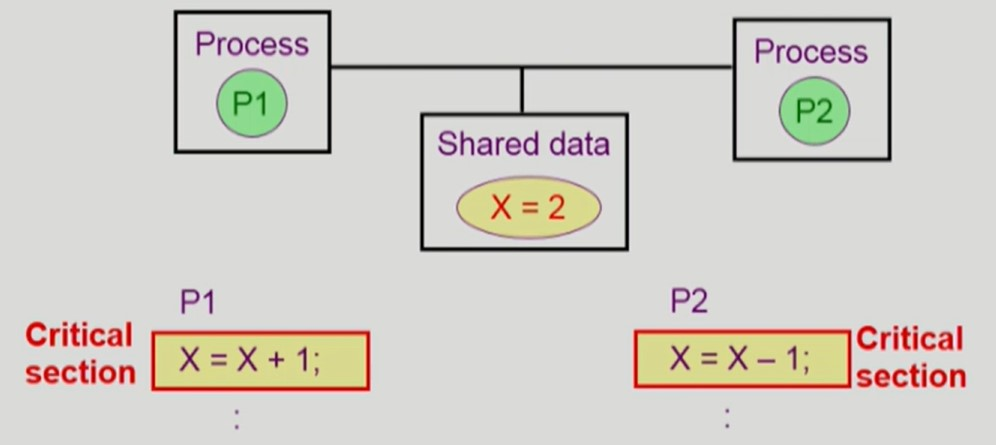
Critical Section
-
각 프로세스의 code 영역에서 공유 데이터를 접근하는 코드
- Race Condition 이 발생할 수 있는 코드
-
-
Critical Section Problem
- 하나의 프로세스가 Critical Section 에 있을 때, 다른 모든 프로세스는 Critical Section 에 들어갈 수 없어야 한다.

-
Critical Section Problem 을 해결하기 위한 조건
-
Mutual Exclusion
- 특정 프로세스가 Critical Section 에 있으면, 다른 모든 프로세스들은 그들의 Critical Section 에 들어가면 안된다.
-
Progress
-
아무도 Critical Section 에 없는 상태에서 어떤 프로세스가 Critical Section 에 들어가려 한다면 Critical Section 에 들어가게 해줘야 한다.
-
이를 만족하지 않는 경우로는 deadlock 이 있다.
-
-
Bounded Waiting
-
프로세스가 Critical Section 에 들어가려고 요청한 후엔, 다른 프로세스들이 Critical Section 에 들어가는 횟수에 한계가 있어야 한다.
-
이를 만족하지 않는 경우로는 starvation 이 있다.
-
ex) 프로세스 A 가 Critical Section 에 들어가려고 줄을 섰는데, 프로세스 B, 프로세스 C가 둘만 계속해서 Critical Section 에 들어가선 안된다.
-
-
Critical Section Problem 해결 (직접 코드로 해결하기)
- Algorithm 1
Process 0 코드
while (turn != 0); // 내 차례 (Process 0) 이 아니면 대기
critical section
turn = 1; // 상대 차례 (Process 1) 로 변경
remainder section
===========================================
Process 1 코드
while (turn != 1); // 내 차례 (Process 1) 이 아니면 대기
critical section
turn = 0; // 상대 차례 (Process 0) 로 변경
remainder section
- 동기화를 위한 공유변수는 차례를 나타내는
turn이다.
- 자신의 차례가 아니면 critical section 에 들어가지 않고 대기한다.
- 만약 Process 0 이 작업을 완료해
turn = 1인 상태에서 Process 1 이 작업을 하지 않으면 아무도 critical section 에 없지만 Process 0 은 critical section 에 들어갈 수 없다.
- Progress 조건 위반
- 따라서 제대로 동작하지 않는 알고리즘이다.
- Algorithm 2
Process 0 코드
flag[0] = true; // 내가 (Process 0) critical section 에 들어가겠다는 의사 표현
while (flag[1]); // 상대가 (Process 1) 이 의사 표현을 했다면 대기
critical section
flag[0] = false; // 나의 (Process 0) 의사 표현을 제거
remainder section
===========================================================
Process 1 코드
flag[1] = true; // 내가 (Process 1) critical section 에 들어가겠다는 의사 표현
while (flag[0]); // 상대가 (Process 0) 이 의사 표현을 했다면 대기
critical section
flag[1] = false; // 나의 (Process 1) 의사 표현을 제거
remainder section
- 동기화를 위한 공유변수는
flag배열이다.
flag[n]이true이면, n 번째 프로세스가 critical section 에 들어가고 싶음을 의미한다.
- 상대방이 critical section 에 들어가고 싶다면, 상대방이 critical section 에 들어가 작업을 끝낼 때까지 대기한다.
- 만약 Process 0 이
flag[0] = true로 설정 후, CPU 를 Process 1 에게 빼앗기면
- Process 1 은
flag[1] = true로 설정 후while(flag[0])에서 대기하다가 CPU 를 Process 0 에게 뺏긴다.- Process 0 은
while(flag[1])에서 대기하다가 CPU를 Process 1 에게 뺏긴다.- 무한히 기다리게 된다.
- Progress 조건 위반 (deadlock)
- 따라서 제대로 동작하지 않는 알고리즘이다.
- Peterson's Algorithm
Process 0
flag[0] = true; // 내가 (Process 0) critical section 에 들어가겠다는 의사 표현
turn = 1; // 상대 차례 (Process 1) 로 변경
while (flag[1] && turn == 1); // 상대가 (Process 1) 이 의사 표현을 했고, 상대 차례이면 대기
critical section
flag[0] = false; // 나의 (Process 0) 의사 표현을 제거
remainder section
- 동기화를 위한 공유변수로
turn,flag배열을 모두 사용한다.
- 상대방이 critical section 에 들어가겠다는 의사표현을 했고, 상대방의 차례인 경우에만 critical section 에 들어가지 않고 대기한다.
- 어떤 시점에서 CPU를 빼앗겨도 잘 동작한다.
- Mutual Exclusion, Progress, Bounded Waiting 모두 만족
- CPU 와 메모리를 사용하면서 대기하는 Busy Waiting (spin lock) 이 있어 비효율적이다.
while (flag[1] && turn == 1)
-
Synchronization 을 위한 명령어 사용
-
대부분의 Race Condition 문제는 데이터의 Read와 Write 가 CPU 명령어 측면에서 여러개로 쪼개져 수행되기 때문에 발생한다.
-
하드웨어적으로, Read 와 Write를 atomic 하게 수행할 수 있는 명령어를 제공하면 좀 더 쉽게 Critical Section Problem 을 해결할 수 있다.
-
Process i
while (test_and_set(lock)); // lock 의 값을 읽어오고, lock 을 True로 세팅한다. (하나의 명령어)
critical section
lock = false; // 자원을 다 사용했으므로, lock 을 False 로 세팅한다.
remainder section
- 동기화를 위한 공유 변수로 공유 자원의 잠금을 의미하는
lock사용
lock이true이면 critical section 에 들어갈 수 없다.
test_and_set(lock)
lock의 값을 읽어온 뒤,lock을true로 세팅하는 명령어이다.- 하나의 명령어기 때문에 Read 도중에 CPU를 빼앗길 수 없다.
- Race Condition 발생 X
- 만약 읽어온
lock이false이면While문은 탈출함과 동시에lock을true로 바꿔준다.
- 만약 읽어온
lock이true이면While문에서 대기하는 동시에lock을true로 다시 바꾼다. (유지)
Semaphores
-
공유 데이터를 조작할 때, 공유 데이터의 일관성을 위해 여러 프로세스간의 동기화가 필요하다.
- 프로세스 동기화를 코드를 사용해 해결하는 것은 어렵다.
-
개발자는 이러한 복잡한 해결방식을 추상화한 자료형인 세마포어를 사용해 쉽게 해결할 수 있다.
-
Semaphore 자료형의 특징
-
정수값을 가진다.
-
2가지 atomic 연산에 의해서만 사용할 수 있다.
-
P 연산
-
Semaphore 를 가져가는 연산
-
Semaphore 감소
-
-
V 연산
-
Semaphore 를 반납하는 연산
-
Semaphore 증가
-
-
-
-
Semaphore 의 값이 0 이상인 임의의 정수 값을 가질 수 있으면 Counting Semaphore 라 한다.
- Resource Counting 에 주로 사용한다.
-
Semaphore 의 값이 0 또는 1만 가능하고, Critical Section Problem 을 해결하기 위해 사용한다면, Mutex 라 한다.
-
주로 lock/unlock 으로 사용한다.
-
critical section 의 mutual exclusion 보장을 위해 사용한다.
-
Semaphore 와 프로세스 대기 방식
-
Semaphore 가 0 이하인 경우 프로세스가 대기하는 방식에 따라 Semaphore 를 사용하는 2가지 방식이 있다.
-
Busy-Wait 방식 (spin lock)


- P 연산과 V 연산
- 대기하면서 CPU를 아무 의미없이 사용한다.
- Block & Wakeup 방식 (sleep lock)

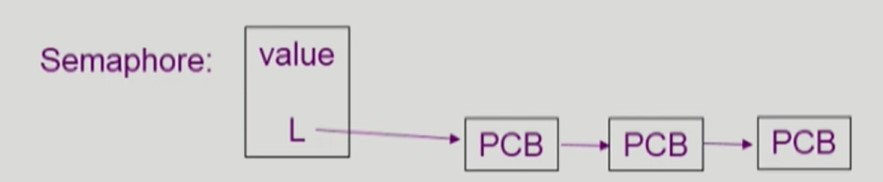
semaphore 구조체
- 정수값(
value) 과 대기하는 프로세스들을 줄 세우기 위한 block queue (L) 를 갖는다.

P 연산
S.value--
- Semaphore 획득
- 공유 데이터 사용 여부와 상관 없이 무조건 획득
if (S.value < 0)
- Semaphore 가 음수이면 공유 데이터를 사용할 수 없으므로, 현재 프로세스는 block queue 에서 대기한다.
block()
- 현재 프로세스는 CPU를 의미 없이 사용하는 busy-wait 이 아니라 CPU를 점유하지 않는 block 상태가 된다.

V 연산
S.value++
- Semaphore 반납
if (S.value <= 0)
- Semaphore 가 양수이면 다른 block 된 프로세스들이 공유 데이터를 사용할 수 있으므로 block queue 에서 대기중인 프로세스 한 개를 깨운다.
wakeup(P)
- block queue 에서 기다리고 있던 다음차례 프로세스를 CPU Ready queue 에 넣는다.
-
Critical Section 의 길이와 Block/Wakeup 오버헤드를 비교하여 2가지 방식 중 한가지를 채택한다.
-
Critical Section 의 길이가 길면 Busy-Wait 시간이 길어지므로, Block/Wake up 방식이 좋다.
-
멀티 코어 환경에서, Critical Section 의 길이가 매우 짧으면 무한 루프 (spin-lock) 도중에 Critical Section 작업이 끝나게 되어 현재 프로세스가 작업을 시작할 수 있다.
-
Block/Wakeup 방식이었다면 context switch 오버헤드가 발생했다.
-
이러한 경우엔, Busy-Wait 시간이 Block/Wakeup 오버헤드보다 짧으므로 Busy-Wait 방식이 좋다.
-
-
일반적으로는 Block/Wakeup 방식이 좋다.
-
Process Synchronization - Semaphores
Process i
P(mutex); // lock 획득
critical section
V(mutex); // lock 반납
remainder exction직접 코드로 짜는 것보다, 개발자 입장에서 쉽게 Critical Section Problem 을 해결할 수 있다.
-
Bounded-Buffer Problem
-
Producer-Consumer Problem
-
제한된 크기의 버퍼들에 값을 넣고 빼는 문제
-
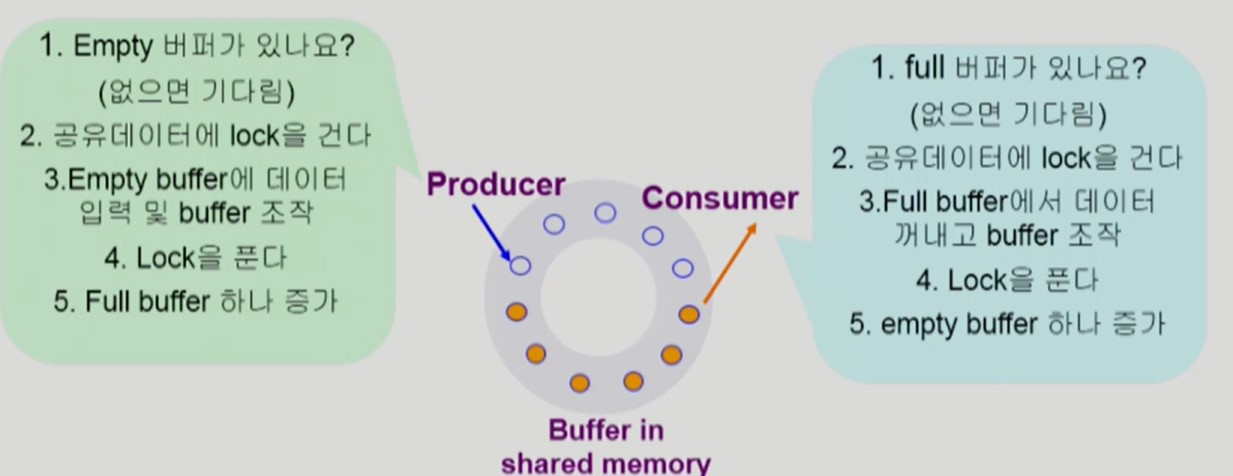
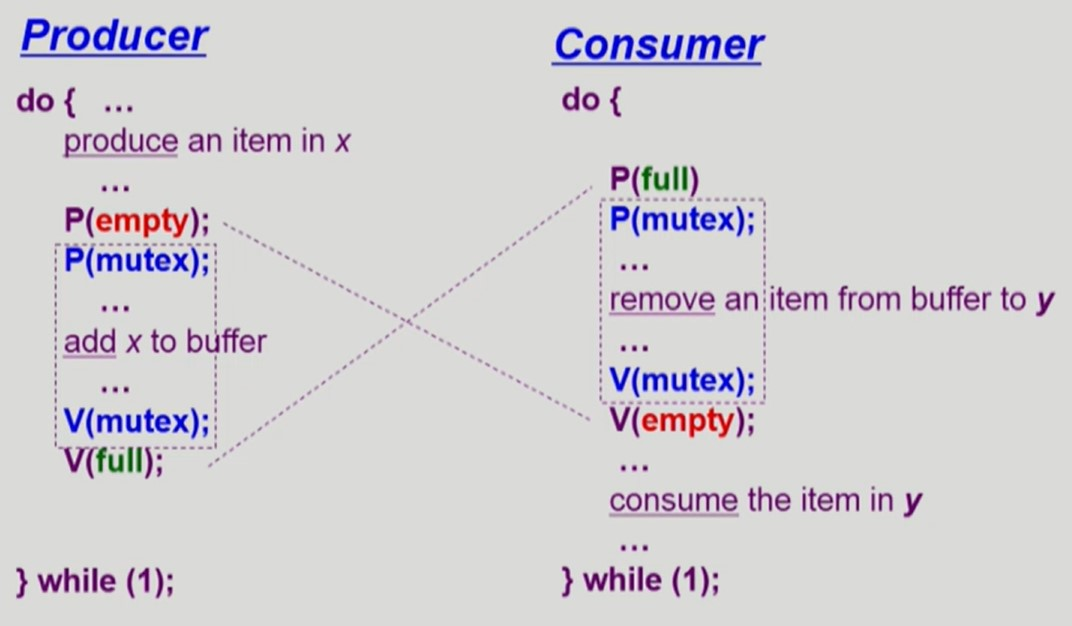
- Producer 프로세스와 Consumer 프로세스의 pseudocode
- 공유 자원
buffer: 값을 저장하거나 뺄 수 있는 버퍼
- 동기화 변수
mutex:buffer에 값을 넣고 뺄 때 필요한 lockfull,empty: 꽉 찬buffer개수, 빈buffer개수를 나타내는 semaphore
-
Readers-Writers Problem
-
한 프로세스가 DB에 write 중일 땐 다른 프로세스가 접근할 수 없다.
-
한 프로세스가 DB에 read 중일 땐 다른 프로세스가 접근할 수 있다.
-
read 는 여러 프로세스가 동시에 할 수 있다.
-
read 중인 프로세스가 있다면, 다른 프로세스가 동시에 write 할 수는 없다.
-
-

- Reader 프로세스와 Writer 프로세스의 pseudocode
- 공유 자원
- DB 자체
readcount: 현재 DB를 read 하는 프로세스 수
- 동기화 변수
mutex:readcount를 접근 및 조작할 때 필요한 lockdb: Reader 프로세스와 Writer 프로세스가 DB에 올바르게 접근하도록 하는 lock
if (readcount == 1) P(db)
- 최초의 Reader 프로세스인 경우 DB에 lock을 건다.
- 이미 누군가가 DB에 lock 을 걸고 읽고 있다면, 그냥 바로 DB를 읽는다.
if (readcount == 0) V(db)
- 내가 마지막으로 남은 Reader 프로세스인 경우 DB에 대한 lock을 반납한다.
- Writer 프로세스 입장에선 reader 가 계속해서 들어오면 무한히 대기한다. (starvation)
-
Dining-Philosophers Problem
-
철학자가 식사를 하기 위해선 왼쪽 젓가락을 먼저 집고, 그 다음 오른쪽 젓가락을 집어야 한다.
-
식사를 마치면 왼쪽 젓가락과 오른쪽 젓가락을 모두 내려놓는다.
-
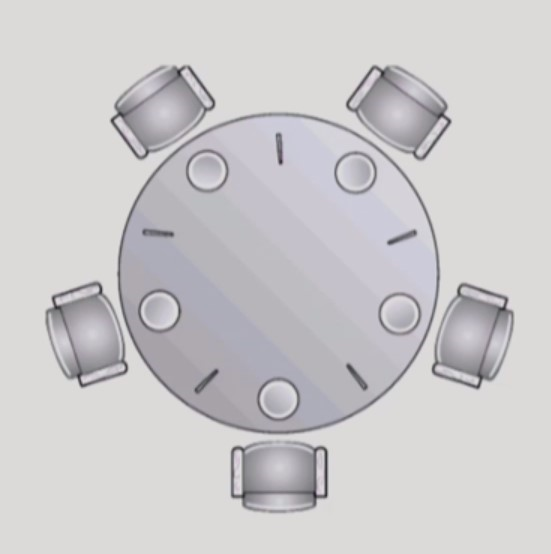

- deadlock 에 걸릴 수 있는 Philosopher 프로세스 pseudocode
- 모든 철학자가 동시에 왼쪽 젓가락을 집은 채로, 오른쪽 젓가락을 요구하게 되면 deadlock 이 발생한다.
- 젓가락을 두 개 모두 집을 수 있을 때만 젓가락을 모두 집는다면 deadlock 을 해결할 수 있다.

- deadlock 이 걸리지 않는 Philosopher 프로세스 pseudocode
- 공유 자원
state배열: 철학자의 상태 (thinking,hungry,eating) 를 나타낸다.- 젓가락: 코드상엔 없는 추상적인 자원
- 동기화 변수
mutex:state,self배열과 같은 공유 변수를 참조 및 조작하기 위한 lockself배열 : n 번째 철학자가 식사를 할 수 있는지를 나타내는 lock (즉, 양쪽의 젓가락을 집을 수 있는 지 여부)
test메서드를 통해 젓가락을 두 개 모두 집을 수 있을 때만 젓가락을 집는다.
- 양 옆사람이 먹지 않고, 내가 배고프면 내 상태를
eating으로 바꾸고V(self[i])를 통해 내가 젓가락을 잡을 수 있는 권한을 준다.
pickup메서드 내의P(self[i])
- 양쪽 젓가락을 잡아 식사를 한 뒤, 젓가락을 반환한다.
- 만약 내가 젓가락을 집을 수 없다면 대기한다.
putdown메서드 내의test((i+4) % 5),test((i+1) % 5)
- 내가 젓가락을 내려놓음으로써 양 옆의 철학자들의 젓가락을 잡을 수 있는 권한을 갱신한다.
Semaphores 한계점
-
개발자의 실수로 쉽게 deadlock 이나 starvation 이 발생할 수 있다.
-
정확성의 입증이 어렵다.
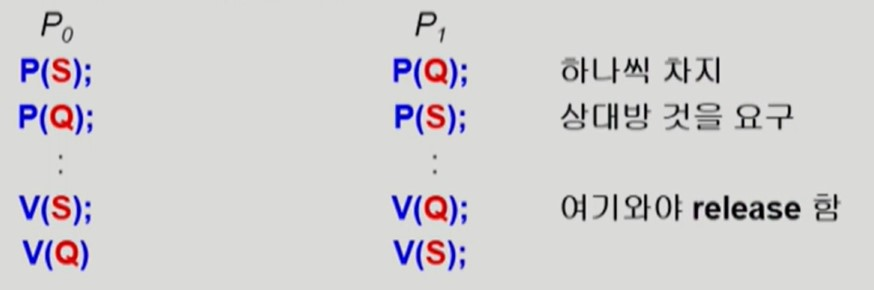
- S와 Q는 mutex라 가정한다.
- deadlock 발생 코드
- critical section 에 들어가기 위해 무한정 대기한다.
- 서로가 자신의 lock 을 반납하지 않은 채 상대방의 lock 이 반납되기를 무한히 기다린다.
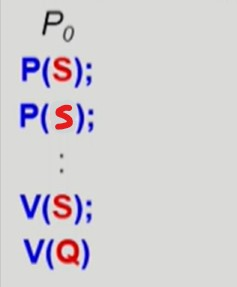
- S는 mutex 이다.
- starvation 발생 코드
- 앞서
P(S)로 lock 을 획득하였는데 또 lock 을 달라하면서 프로세스가 무한히 진행되지 못한다.
Monitor
-
프로그래밍 언어 차원에서 공유 데이터에 대한 Process Synchronization 을 모두 처리해준다.
-
프로그래머가 직접 lock 을 걸 필요없이 Monitor 에서 제공하는 API를 사용하여 공유 데이터에 접근 및 조작한다.
-
Condition Variable
-
프로세스가 모니터안에서 기다리도록 하는 block queue
-
wait 연산과 signal 연산만 사용할 수 있다.
-
wait()-
wait()을 호출한 프로세스는 다른 프로세스가 깨우기 전까지 block 된 채로 block queue 에서 대기한다. -
즉,
wait()을 호출한 코드라인에서 깨우기전까지 대기한다.
-
-
signal()-
signal()을 호출한 프로세스는 block queue 에서 대기하는 프로세스를 깨운다. -
즉,
wait()에서 대기하는 프로세스를 깨워 진행하도록 한다.
-
-
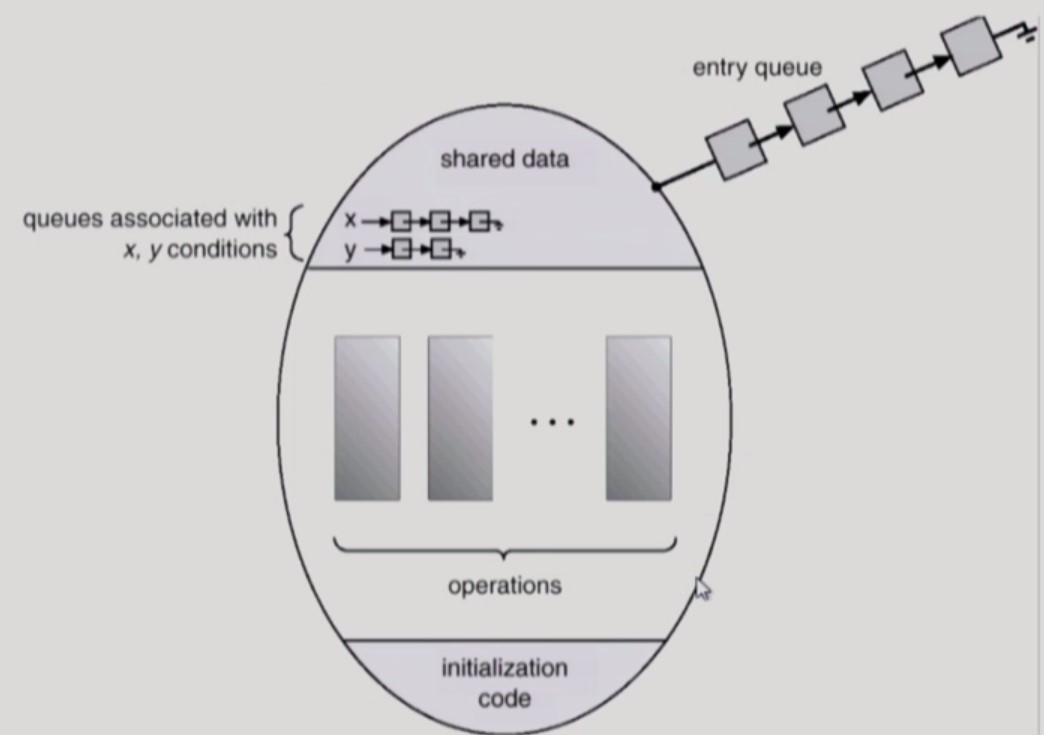
- 공유 데이터는 Monitor 내부에 존재한다.
x,y는 Condition Variable 이다.
Process Synchronization - Monitor
- Bounded-Buffer Problem
monitor bounded_buffer {
int buffer[N];
condition full, empty; // 데이터가 찬 버퍼를 기다리는 full block queue,
// 데이터가 빈 버퍼를 기다리는 empty block queue,
void produce(int x) {
if there is no empty buffer
empty.wait(); // 빈 버퍼가 없으므로, 현재 프로세스는 empty block queue 에서 대기
add x to an empty buffer
full.signal(); // full block queue 에서 프로세스 한 개를 깨운다.
}
void consume(int *x) {
if there is no full buffer
full.wait(); // 소비할 버퍼가 없으므로, 현재 프로세스는 full block queue 에서 대기
remove an item from buffer and store it to *x
empty.signal(); // empty block queue 에서 프로세스 한 개를 깨운다.
}
}
- 프로그래머 입장에선 Monitor 에서 제공하는
produce,consume메서드만 호출하면 된다.wait()코드라인에서 대기하며 잠든 프로세스는 다른 프로세스가signal()호출 시, 잠에서 깨어나 코드를 진행한다.empty.wait()에서 대기하는 프로세스 A 는,empty.signal()을 호출한 프로세스 B에 의해 코드를 진행할 수 있다.full.wait()에서 대기하는 프로세스 A 는,full.signal()을 호출한 프로세스 B에 의해 코드를 진행할 수 있다.
- Dining-Philosophers Problem
Each Philosopher:
while (true) {
pickup(i);
eat();
putdown(i);
think();
}
- 모든 철학자 프로세스들은 다음 동작을 반복 수행한다.
pickup(i)와putdown(i)는 monitor 에 정의된 메서드이다.
monitor dining_philosopher {
enum {thinking, hungry, eating} state[5] = {thinking, thinking, thinking, thinking, thinking};
condition self[5]; // i 번째 철학자 프로세스의 block queue
void pickup(int i) { // 내가 양쪽 젓가락을 집을 수 있는 지 체크하며 젓가락을 집거나 대기한다.
state[i] = hungry;
test(i);
if (state[i] != eating) // 만약 현재 양쪽 젓가락을 집을 수 없어 먹을 수 없으면
self[i].wait(); // i 번째 철학자 프로세스 sleep (현재 코드 라인에서 대기한다.)
}
void putdown(int i) { // 내가 양쪽 젓가락을 내려놓으며, 양쪽에 있는 배고픈 철학자들이 젓가락을 집을 수 있는 지 체크한다.
state[i] = thinking;
test((i + 4) % 5);
test((i + 1) % 5);
}
void test(int i) { // i 번째 철학자가 젓가락을 집을 수 있는 지 체크한다.
if ((state[(i + 4) % 5] != eating) && (state[i] == hungry) && (state[(i + 1) % 5] != eating)) { // 내가 배고프고, 양쪽 젓가락을 집을 수 있으면
state[i] = eating; // 먹는 상태로 바꾸고
self[i].signal(); // block queue 에 자고있는 프로세스를 깨운다.
}
}
}철학자 프로세스들은 monitor 에 정의된 메서드들을 호출하여 프로세스 동기화를 달성한다.
Deadlocks
- 프로세스들이 서로가 가진 자원을 기다리며 block 된 상태
Deadlock 발생 조건
-
Mutual exclusion
- 하나의 프로세스만 자원을 사용할 수 있다.
-
No preemption
- 프로세스는 자원을 빼앗기지 않고, 자진 반납한다.
-
Hold and wait
- 프로세스가 자원을 보유한 채 다른 자원을 기다린다.
-
Circular wait
- 자원을 기다리는 프로세스 간에 사이클이 형성된다.
deadlock을 판별하는 방법
-
Resource-Allocation Graph
-
P: 프로세스, R: 자원
-
P ➔ R 은 프로세스의 해당 자원 요청
-
R ➔ P 는 프로세스가 해당 자원을 가지고 있음을 의미한다.
-
그래프를 통해 현재 상태가 deadlock 인지 아닌지 판별한다.
-
그래프에 cycle 이 없으면 deadlock 이 아니다.
-
자원이 1개이고, cycle 이 있으면 deadlock 이다.
-
자원이 여러개이고, cycle 이 있으면 직접 deadlock 가능성을 체크해봐야 한다.
-
-
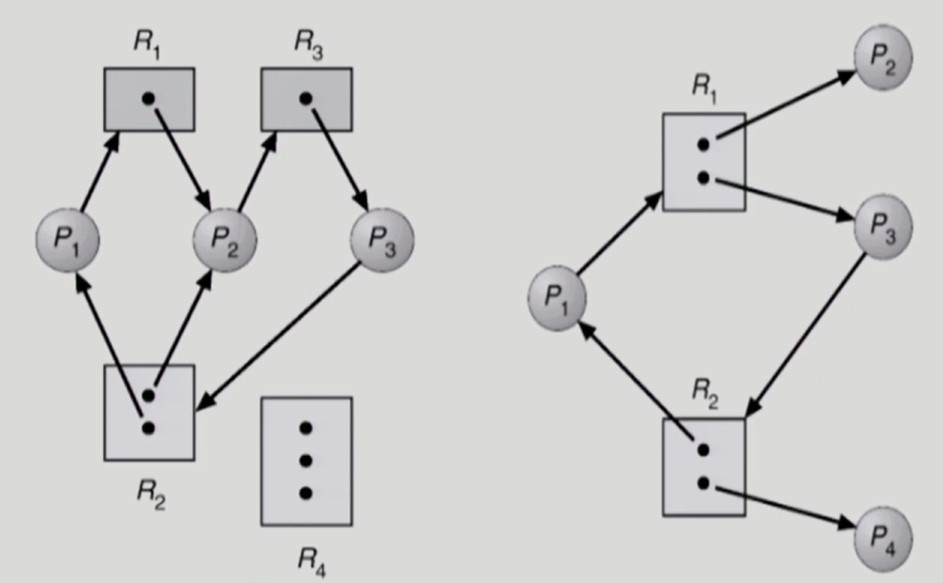
좌측 그래프는 deadlock, 우측 그래프는 deadlock 이 아니다.
-
표를 사용하는 방법
-
시스템의 모든 자원 개수를 바탕으로 특정 시점에
-
프로세스에 할당된 자원
-
프로세스가 요청한 자원
-
현재 남은 시스템 자원을 계산한다.
-
-
-
더 이상 요청할 자원이 없는 프로세스는 무조건 자원을 반납한다는 낙관적인 가정을 한다.
- 만약 요청할 자원이 남아있는 상태에서 사용가능한 남은 자원이 없다면 deadlock 이다.
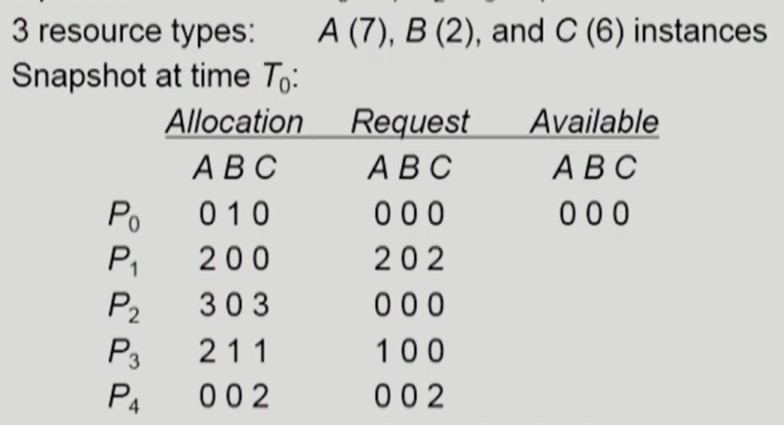
- P0, P2 는 자원을 반납한다.
- Avaliable: A(3), B(1), C(3)
- P1, P3 에게 자원을 할당한다.
- Avaliable: A(0), B(1), C(1)
- P1, P3 는 자원을 반납한다.
- Avaliable: A(3), B(1), C(3)
- P4 에게 자원을 할당한다.
- deadlock 발생 x
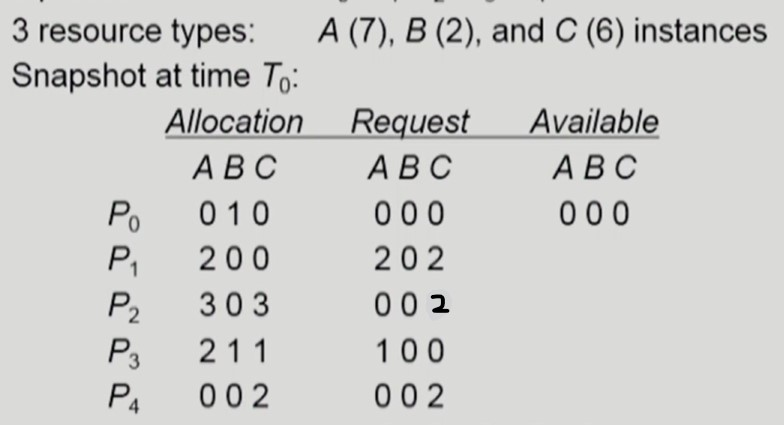
- P0는 자원을 반납한다
- Avaliable: A(0), B(1), C(0)
- 어떤 프로세스도 자원을 반납할 수 없는 상황 발생
- deadlock 발생
deadlock 처리 방법
-
Deadlock Prevention
-
자원 할당 시 deadlock 발생 조건 중 어느 하나가 만족되지 않도록 하는 것
-
Mutual Exclusion 조건은 데이터 일관성을 위해 반드시 성립해야 한다.
-
Hold and wait 조건을 깨는 방법
-
프로세스가 자원을 요청할 때 다른 어떤 자원도 가지고 있지 않도록 한다.
-
프로세스 작업에 필요한 모든 자원이 있는 경우에만 해당 프로세스에게 모든 자원들을 할당해준다.
-
만약 프로세스 작업에 필요한 모든 자원이 존재하지 않는다면, 해당 프로세스에게 자원들을 주지 않는다.
-
-
No preemption 조건을 깨는 방법
- 프로세스가 필요한 자원을 다른 프로세스로부터 빼앗도록 한다.
-
Circular Wait 조건을 깨는 방법
-
자원에 할당 순서를 정하여 정해진 순서대로만 자원을 할당하도록 한다.
-
ex) 1번 자원이 있는 경우에만 2번 자원을 요구할 수 있다.
-
circular 는 어떤 프로세스는 1번 자원을 선점한 뒤 2번 자원을 요구하고, 다른 프로세스는 2번 자원을 선점한 뒤 1번 자원을 요구하기 때문에 발생하는데, 자원의 할당 순서를 정함으로써 해결할 수 있다.
-
-
이를 통해 cycle 의 발생을 막는다.
-
-
-
Deadlock Avoidance
-
deadlock 가능성이 없는 경우에만 자원을 할당한다.
-
시스템이 deadlock 가능성이 있는 unsafe state 에 들어가지 않도록 한다.
- safe state 에서만 자원을 할당한다.
-
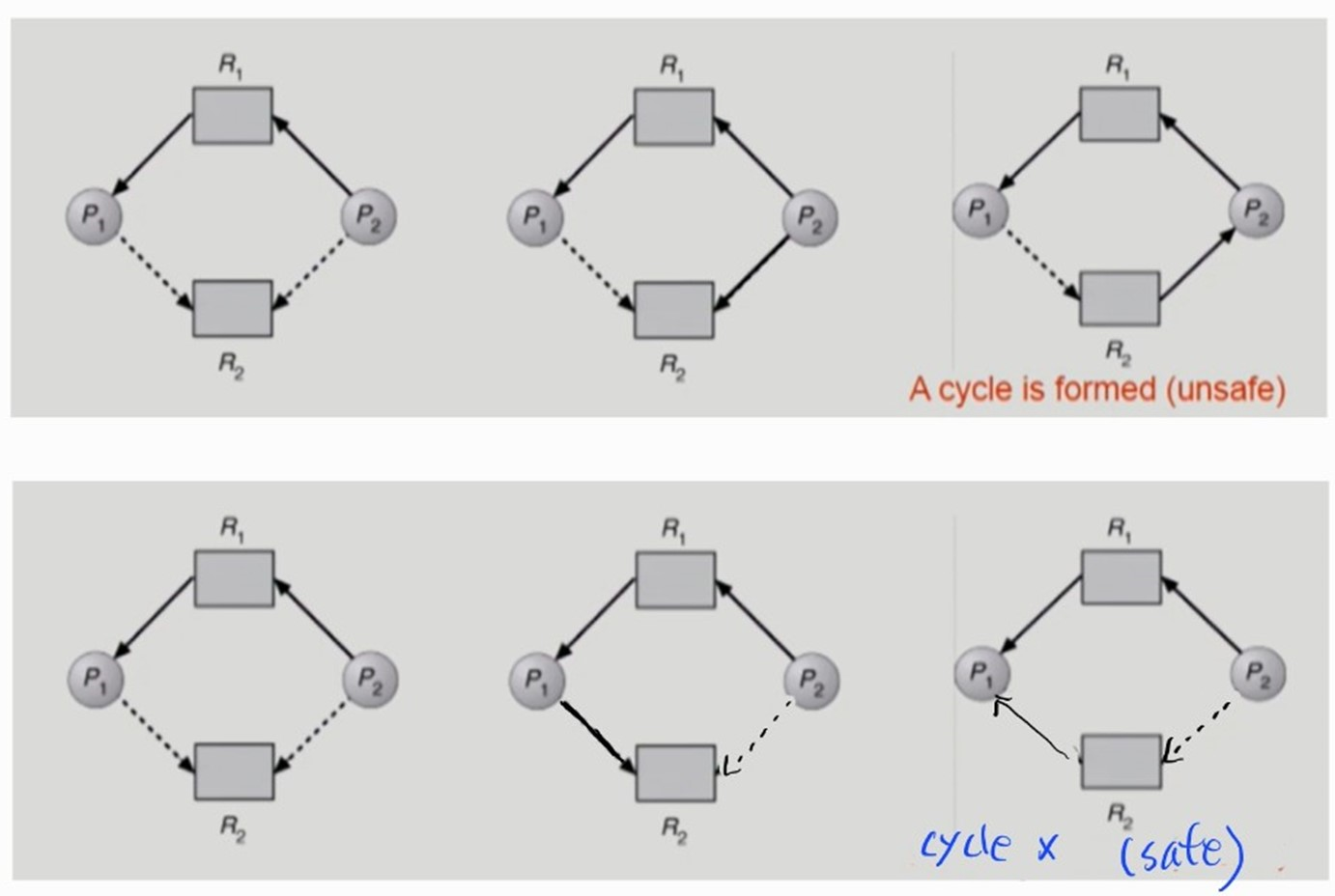
- Resource Allocation Graph Algorithm 사용
- 다음 상태에서 P2 가 R2 를 요청하여 R2 를 선점하면 deadlock 이 발생할 수 있으므로 P2 는 R2를 요청해도 자원을 받을 수 없다.
- 다음 상태에서 P1 가 R2 를 요청하여 R2 를 선점해도 deadlock 이 발생할 수 없으므로 P1 은 R2를 요청해 자원을 받을 수 있다.
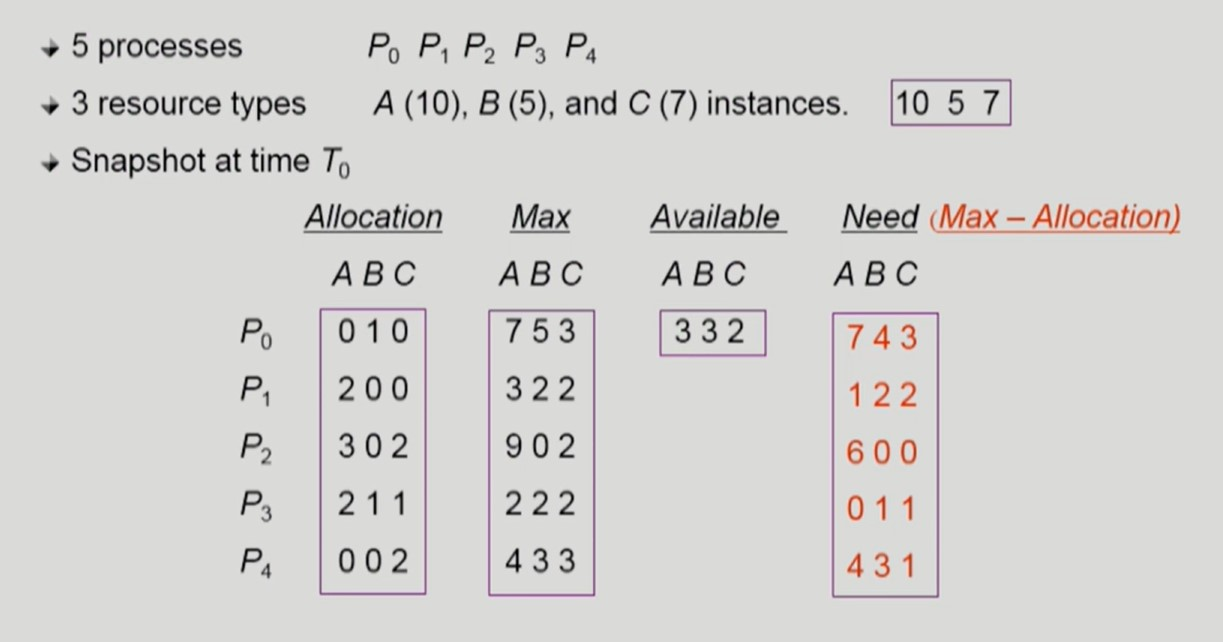
- Banker's Algorithm
- Allocation: 현재 프로세스들에 할당된 자원 개수를 의미한다.
- Max: 프로세스가 종료되기까지 필요로하는 모든 자원들의 개수를 미리 계산한다.
- Available: 시스템 내에서 현재 사용가능한 자원 개수를 의미한다.
- Need:
Max - Allocation, 해당 프로세스가 추가로 요청할 수 있는 자원 양을 의미한다.
- Available 한도 내에서 Need 를 만족시킬 수 있다면 해당 프로세스에게 자원을 주어도 safe 하다.
- P1, P3 에게 자원을 주면 필요한 모든 자원을 가졌기에, 무조건 작업을 마치고 자원을 반환한다.
- Available 한도 내에서 Need 를 만족시킬 수 없다면 해당 프로세스에게 자원을 주면 unsafe 하다.
- P0, P2, P4 에게 자원을 주면 필요한 모든 자원을 가지지 못했기에, 다른 프로세스가 자원을 반납하지 않은 상태에서 추가 자원을 요구하여 deadlock 에 빠질 수 있다.
-
Deadlock Detection and Recovery
-
deadlock 발생을 허용하되 deadlock detection 루틴을 두어 deadlock 발견 시 recovery 를 수행한다.
-
그래프나 표를 통해 deadlock 을 탐지한다.
-
recovery 방법은 2가지가 있다.
-
Process 종료
- 모든 프로세스를 종료하거나, deadlock 이 풀릴 때까지 프로세스를 하나씩 종료시킨다.
-
자원 뺏기
-
특정 프로세스 (victim) 의 자원을 빼앗아 deadlock 을 푼다.
-
동일한 프로세스가 계속해서 victim 이 되어 자원을 뺏기지 않도록 victim 선정 횟수도 victim 선정 기준으로 반영한다.
-
-
-
-
Deadlock Ignorance
-
deadlock 은 매우 드물게 발생한다.
-
deadlock 에 대한 여러 조치들과 제약조건이 더 큰 오버헤드가 되어 CPU 이용률을 낮추고 starvation 을 발생시킬 수 있다.
-
따라서 deadlock 을 신경쓰지 않는 방식이 있다.
- deadlock 발생 시 사람이 직접 프로세스를 종료하도록 한다.
-
대부분의 범용 OS가 채택하는 방식
-
Memory Management
Logical Address vs Physical Address
-
Logical Address
-
프로세스마다 독립적으로 가지는 주소 공간
-
각 프로세스마다 0번지부터 시작한다.
-
-
Physical Address
- 프로그램이 메모리에 실제 올라가는 주소
-
프로그램은 Logical Address 바탕으로 작성되어 있다.
-
따라서, CPU 는 Logical Address 를 참조한다.
-
그래서 중간 과정에서 하드웨어 장치가 Logical Address 를 Physical Address 로 변환해주어야 한다.
-
이를 통해 CPU가 실제 물리 메모리에 위치한 명령어나 데이터에 접근할 수 있다.
-
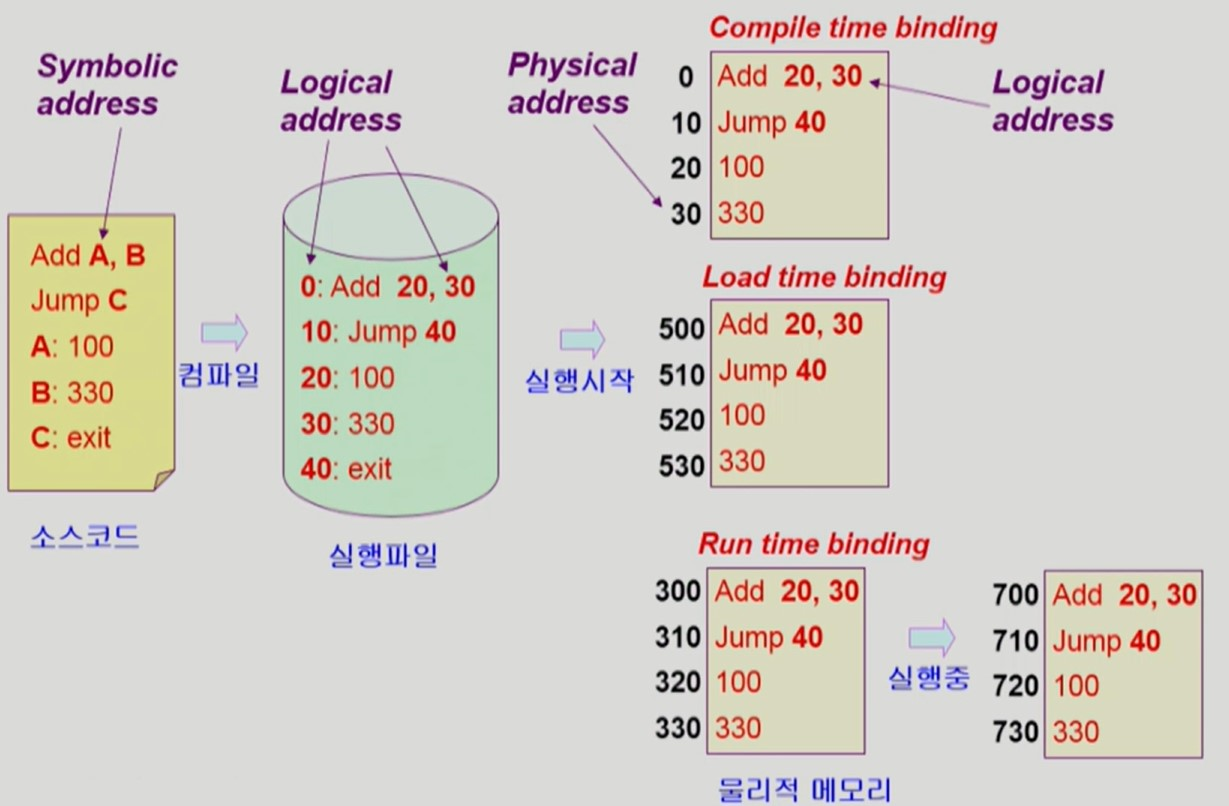
Address Binding
-
Compile-time Binding
-
프로세스의 Logical address 를 그대로 Physical address 로 사용한다.
-
해당 시스템은 프로그램 1개만 실행할 수 있다.
- 프로그램 여러개 동시 실행 불가능
-
비효율적이다.
-
-
Load-time Binding
-
프로그램을 컴파일하는 시점에 Physical address 를 결정한다.
-
프로그램 실행 도중엔 Physical address 가 변하지 않는다.
- Physical address 를 바꾸려면 다시 컴파일해야 한다.
-
-
Run-time binding
-
프로그램을 실행하는 중에도 상황에 따라 Physical address 가 바뀐다.
-
따라서 CPU 가 Logical address 를 참조할 때마다 대응되는 Physical address 가 어디인지 binding 을 점검해야 한다.
-
Memory Management Unit
-
MMU
-
logical address 를 physical address 로 매핑해주는 하드웨어 장치
-
사용자 프로그램은 logical adddress 만을 다루기에 CPU 역시 logical address 를 참조한다.
-
그러나 실제 메모리에 올라가있는 프로그램 영역의 physical address 는 logical address 와 다르므로 MMU가 중간에서 변환을 해준다.
-
변환을 통해 CPU는 실제 메모리의 physical address 에 있는 프로그램 명령어나 데이터에 접근할 수 있다.
-
-
구현 방식은 메모리 관리 방식에 따라 다르다.
물리 메모리의 프로세스 할당 방법
-
Contiguous allocation (연속 할당)
-
프로세스가 물리 메모리의 연속적인 공간에 적재되는 방식
-
즉, 프로세스를 물리 메모리에 통째로 올린다.
-
-
Non-contiguous allocation (불연속 할당)
-
하나의 프로세스가 물리 메모리의 여러 영역에 분산되어 올라가는 방식
-
Paging
-
Segmentation
-
Paged Segmentation 방식이 있다.
-

물리 메모리
- OS 는 항상 상주한다.
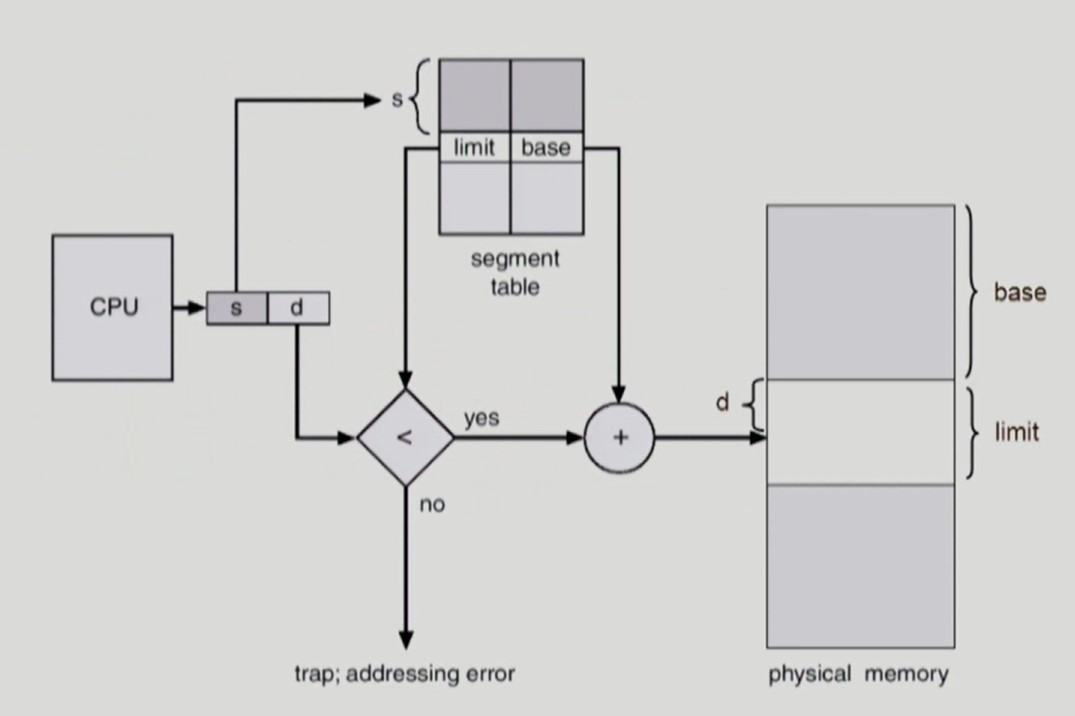
Contiguous allocation
-
가상 메모리에 존재하는 프로세스 영역을 물리 메모리의 연속적인 공간에 통째로 올린다.
-
relocation 레지스터와 limit 레지스터를 사용한다.
-
relocation 레지스터를 통해 해당 프로세스의 physical address 시작 지점을 찾는다.
-
limit 레지스터를 통해 CPU가 접근하려는 logical address 주소가 해당 프로세스를 벗어나는지 체크한다.
-
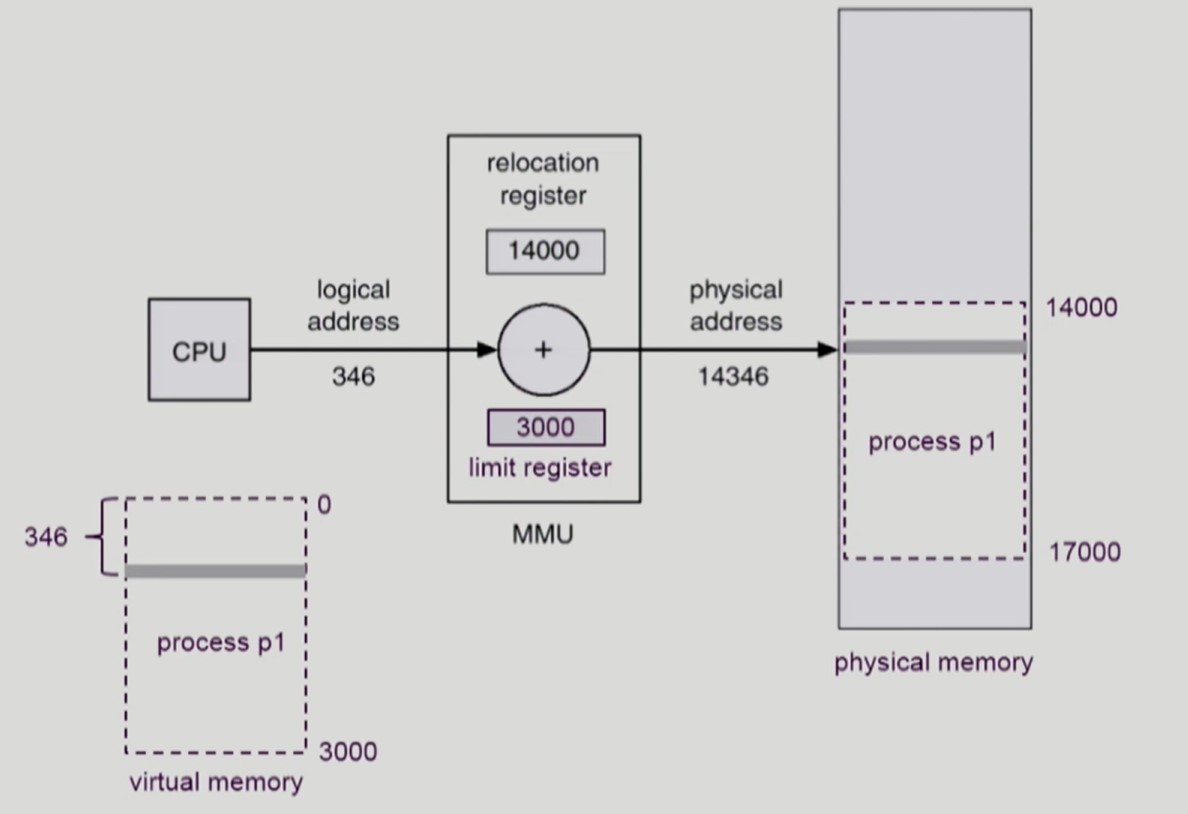
- 해당 프로세스는 물리 메모리의 14000 번지부터 3000 크기 만큼 위치한다.
- CPU가 접근해야하는 실제 메모리 주소는 14000 + 346 = 14346 번지이다.
- 만약 CPU 가 프로세스 영역을 벗어나는 logical address 접근 시 trap 이 발생하여 프로그램을 비정상 종료시킨다.
-
프로세스 전체를 물리 메모리에 연속적으로 올리기 때문에 비효율적이다.
-
프로그램의 전체 영역 중 실제로 사용하는 부분은 일부분이다.
-
예를 들어, 비정상 입력에 대한 검증 코드들은 많은 양에 비해 거의 사용하지 않는다.
-
-
고정 분할 방식과 가변 분할 방식이 있다.
-
고정 분할 방식: 고정된 분할 영역이 있어 해당 분할 영역에 프로그램 1개가 들어갈 수 있다.
-
가변 분할 방식: 고정된 분할 영역 없이 프로그램이 아무렇게나 들어갈 수 있다.
-
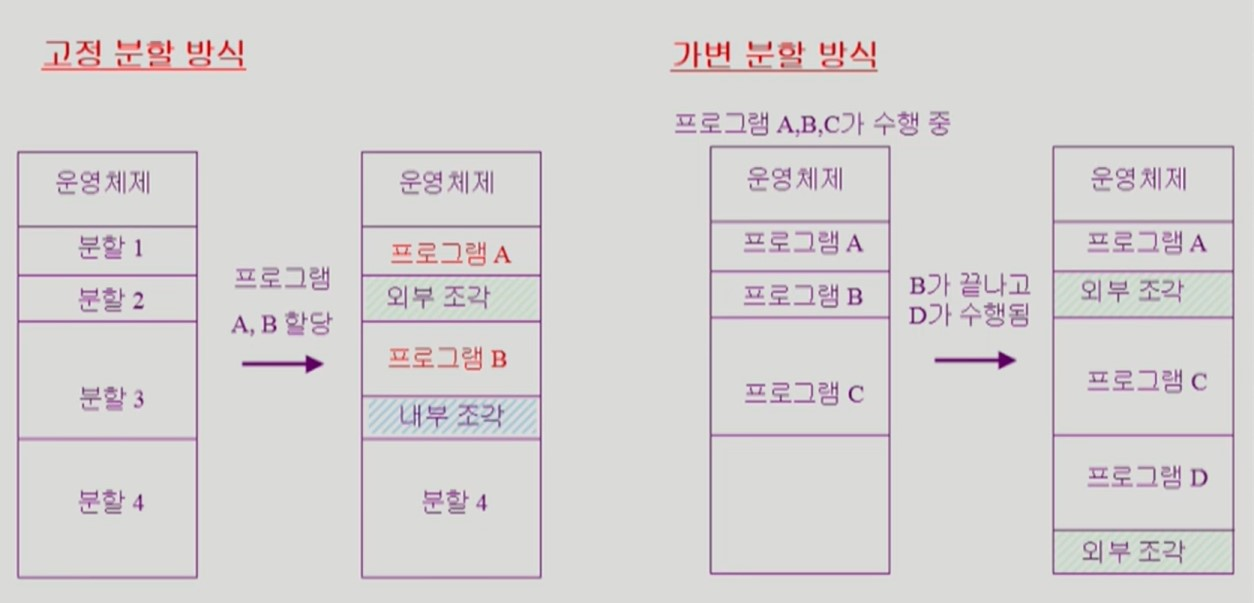
- 가변 분할 방식에서 프로그램D 는 크기가 커서 프로그램 B가 있던 위치에 들어갈 수 없다.
- 두 방식 모두 프로그램이 들어가지 못하고 낭비되는 공간인 fragmentation 이 생긴다.
Hole
-
사용할 수 있는 물리 메모리 공간
-
다양한 크기의 hole 들이 물리 메모리 여러 곳에 흩어져 있다.
-
프로그램을 물리 메모리에 적재할 경우 해당 프로그램을 수용 가능한 hole 을 찾아야 한다.
-
First-fit: 프로그램을 넣을 수 있는 크기의, 제일 처음 발견된 hole 에 프로그램을 적재한다.
-
Best-fit: 전체 hole 중에 프로그램을 넣을 수 있는 크기의 가장 작은 hole 에 프로그램을 적재한다.
-
어떠한 방식을 사용하던 fragmentation 이 생긴다.
-
-
Compaction 을 통해 사용중인 메모리 영역과 fragmentation 을 모아 하나의 큰 Hole 을 만들 수 있지만, 큰 비용이 든다.
물리 메모리 공간의 효율적 사용법
-
Dynamic Loading
- 프로세스 전체를 물리 메모리에 미리 올리지 않고 해당 영역을 사용할 때 물리 메모리로 올리는 것
-
Swapping
-
프로세스를 일시적으로 메모리에서 backing store (디스크의 swap area) 로 쫓아내는 것
-
OS의 중기 스케줄러에 의해 swap out 시킬 프로세스를 선정한다.
- priority 가 낮은 프로세스가 swap out 된다.
-
compile-time binding 이나 load-time binding 은 원래의 physical address 위치로 다시 swap in 해야 된다.
- 비효율적
-
run-time binding 은 메모리의 빈 영역 아무 위치로나 swap in 해도 된다.
-
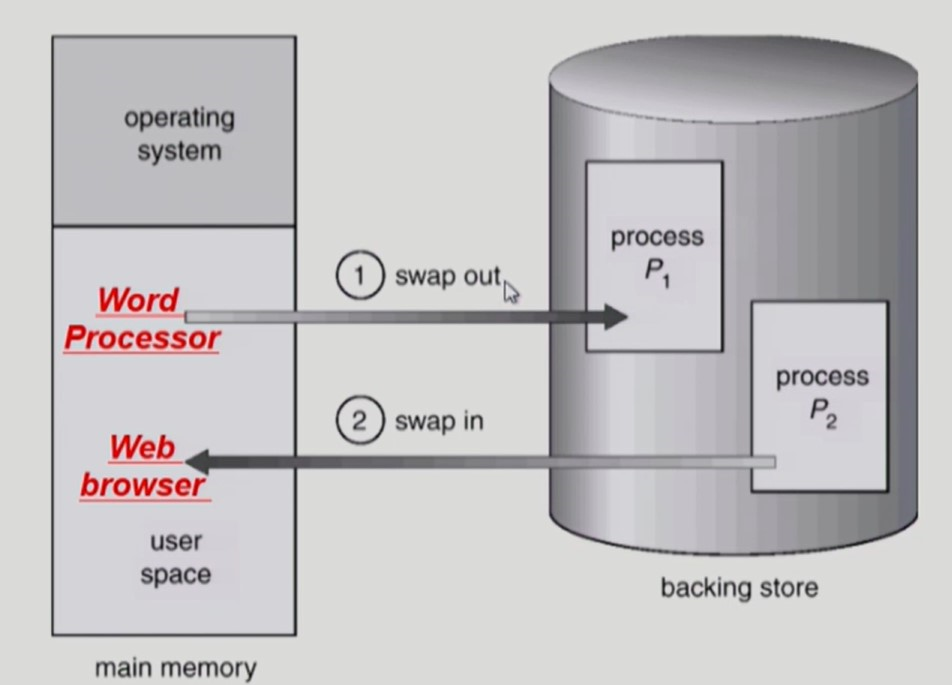
-
Dynamic Linking
-
라이브러리 Linking 을 런타임까지 미루는 기법
-
라이브러리 루틴이 디스크에 따로 저장되어 있어야 한다.
-
반대되는 개념인 Static Linking 은 라이브러리 코드가 프로그램의 실행 파일 코드에 포함되어 프로그램의 크기가 커진다.
-
Dynamic Linking 은 실행 파일 안의 라이브러리 호출 부분에 라이브러리 루틴의 포인터만 넣어놓는다.
-
다른 프로세스가 해당 라이브러리 루틴을 사용하느라 물리 메모리에 라이브러리 루틴을 올렸다면 해당 라이브러리 루틴을 사용하면 된다.
-
라이브러리 루틴이 물리 메모리에 없다면 디스크에서 해당 루틴을 찾아 물리 메모리에 올리고 사용한다.
-
이러한 과정들은 운영체제가 수행한다.
-
-
Paging
-
Non-contiguous allocation 방식 중 하나이다.
-
프로세스의 가상 메모리를 동일한 사이즈의 page 단위로 나눈다.
-
가상 메모리 영역이 page 단위로 물리 메모리에 불연속적으로 올라간다.
-
프로그램에서 현재 사용하는 page는 물리 메모리에 위치하고, 현재 사용하지 않는 page 는 backing storage 에 위치한다.
-
-
물리 메모리 역시 page 단위로 나눠 frame number를 붙인다.
- frame number를 통해 물리 메모리위에 올라간 프로세스 page 의 시작 주소를 알 수 있다.
-
프로세스의 크기 상관없이 동일한 page 단위로 물리 메모리에 적재하므로 fragmentation 이 생기지 않는다.
-
page table 을 사용하여 logical address 를 physical address 로 변환한다.
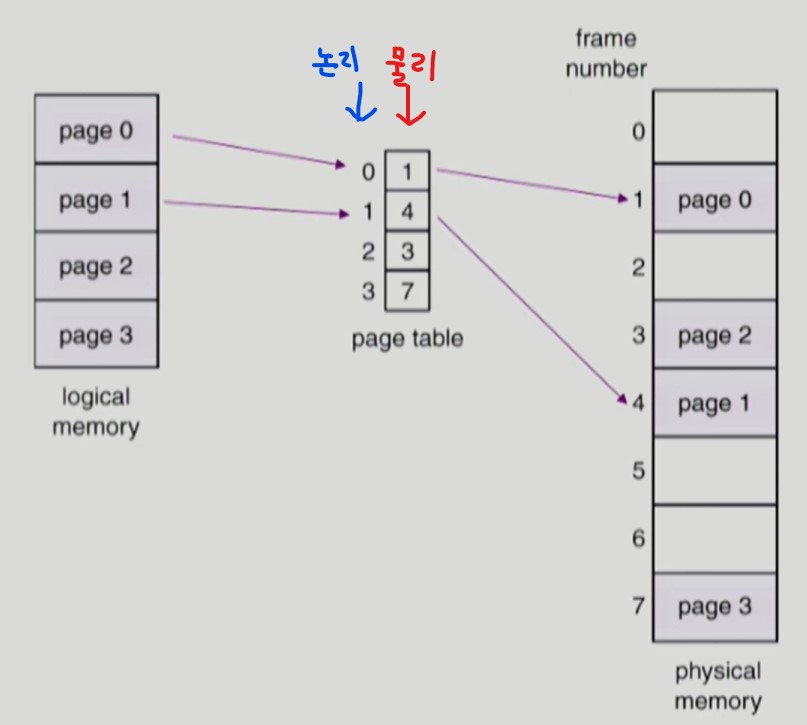
-
page table 은 모든 주소 공간을 표현할 수 있는 page table entry 개수를 가진다.
-
그러나 실제로 프로그램은 모든 주소 공간을 이용하지 않는다.
-
따라서 프로그램에서 사용하지 않는 page table entry 는 invalid 로 체크하여 접근하지 않도록 한다.
-
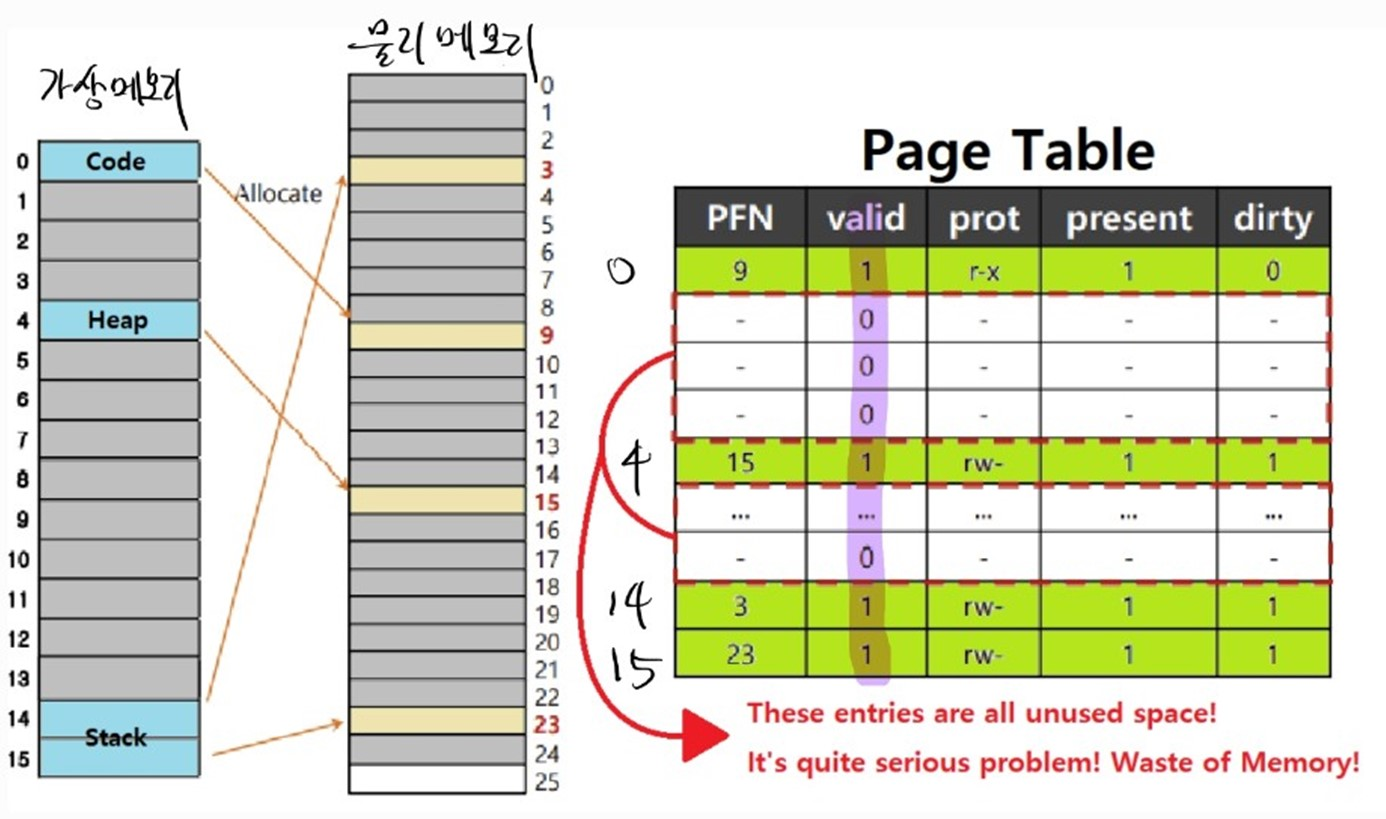
-
프로세스를 page 로 나누면 코드를 담고있는 page, 데이터를 담고있는 page 로 나뉠 수 있다.
-
코드를 담고 있는 page 는 변경되선 안되므로 read-only 권한을
-
데이터를 담고 있는 page 는 변경 가능하도록 write 권한을 주는 등의
-
각 page 에 대한 접근 권한을 주고 싶을 때 Protection bit 을 사용한다.
-
-
여러 프로세스가 같은 코드를 사용한다면 해당 공유 코드가 있는 페이지 (공유 페이지) 를 물리 메모리의 하나의 프레임에 넣는다.
-
각 프로세스의 page table 의 공유 페이지가 하나의 프레임을 가리키도록 한다.
-
공유 페이지는 read-only 이다.
-
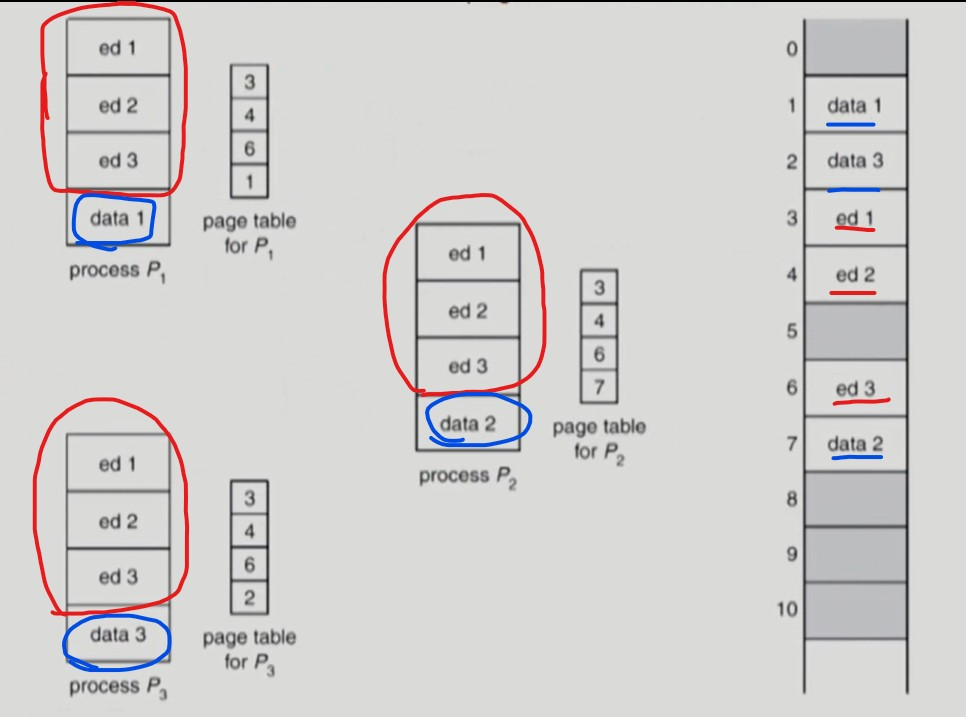
- ed 1, ed 2, ed 3 은 공유 페이지이므로 물리 메모리의 frame 3, 4, 6을 3개의 프로세스가 공유한다.
- data 1, data 2, data 3 은 독자적인 페이지이므로 독자적인 물리 메모리의 frame 을 사용한다.
- 간단한 Paging
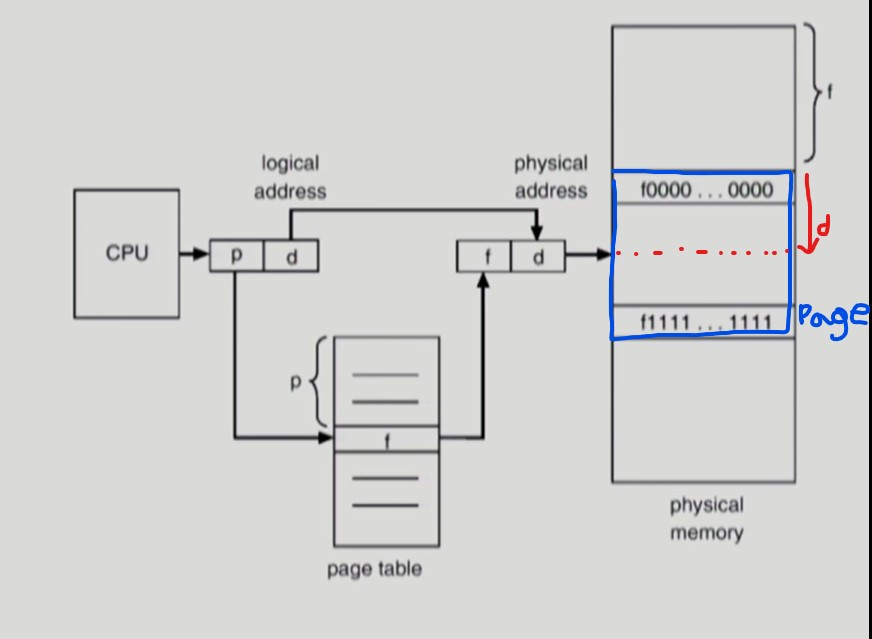
p: 논리적인 page 번호
f: 물리 메모리에 존재하는 page 의 frame number (물리 메모리에 올라간 page 의 시작 주소)
d: offset, 해당 page의 frame number (물리 메모리에 올라간 page 시작 주소) 에서 d 만큼 더한 주소가 physical address 이다.
-
보통 한 page 가 4KB 이다.
-
프로그램은 약 100만개의 page 로 이루어진다. (32bit 운영체제 기준)
- 4GB / 4KB = 1M
-
따라서 page table 은 100만개의 page 번호를 담아야 한다.
-
레지스터로 저장하기엔 너무 크다.
-
캐시로 모두 저장하기에도 크다.
-
-
-
따라서 page table 은 물리 메모리에 저장한다.
- TLB 적용 Paging
-
물리 메모리 접근 횟수는 다음과 같다.
-
page table 접근 1번,
-
실제 data/instruction 접근 1번
-
-
page table 접근 횟수를 줄이기 위해 translation look-aside buffer (TLB) 캐시를 둔다.
- cache hit 시 page table 에 접근하지 않아도 된다. (물리 메모리 접근 횟수 총 1번)
-
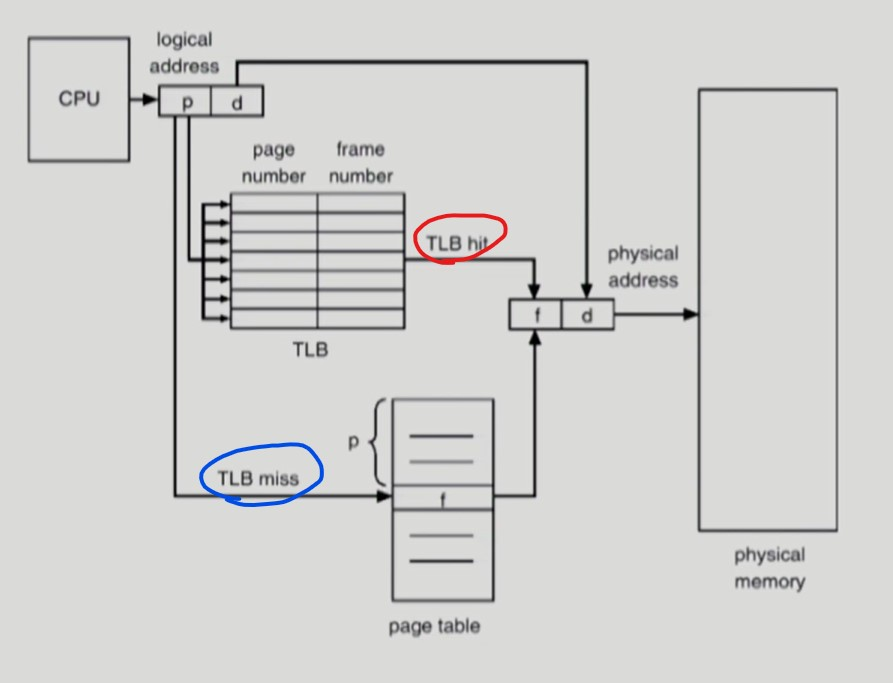
- page table 은 페이지 번호
p를 바탕으로 인덱스 접근한다. (O(1))
- TLB 는 자주 사용된 page 번호와 물리 메모리에 올라간 page 의 시작 주소인 frame number 쌍을 저장한다.
- 일치하는
p가 있는지 전부 탐색해야 한다. (O(N))- 따라서 parallel search 가 가능한 Associative register 들로 이루어져 있다.
- 프로세스마다 다른 page table 을 갖기 때문에 프로세스가 바뀌면 TLB를 모두 비운다.
-
Two-Level Page Table
-
32 bit 운영체제는 2^32 bit = 4GB 주소 공간을 표현한다.
-
page size 가 4KB라 하면 4GB / 4KB = 1M 로 프로세스당 백만개의 page 가 만들어진다.
-
따라서 백만개의 page table entry 가 필요하다.
-
page table entry = page table 인덱스
-
-
page table entry 당 4B 라 하면 1M * 4B = 4MB 크기의 page table 이 각 프로세스마다 만들어진다.
-
그러나 프로세스는 4GB 의 주소공간 중 일부만 사용하므로 page table 공간이 심하게 낭비된다.
-
이러한 낭비를 줄이기 위해 2단계의 테이블을 사용한다.
- 주소 공간이 더 커진다면 여러단계의 Multi-level Page table 을 사용해 주소 공간의 낭비를 더욱 줄일 수 있다.
-
physical address 에 접근하기 까지의 시간은 더 걸린다.
-
여러번 페이지 테이블에 접근해야 하기 때문이다.
-
캐시를 통해 시간적 손해를 크게 개선할 수 있다.
-
-
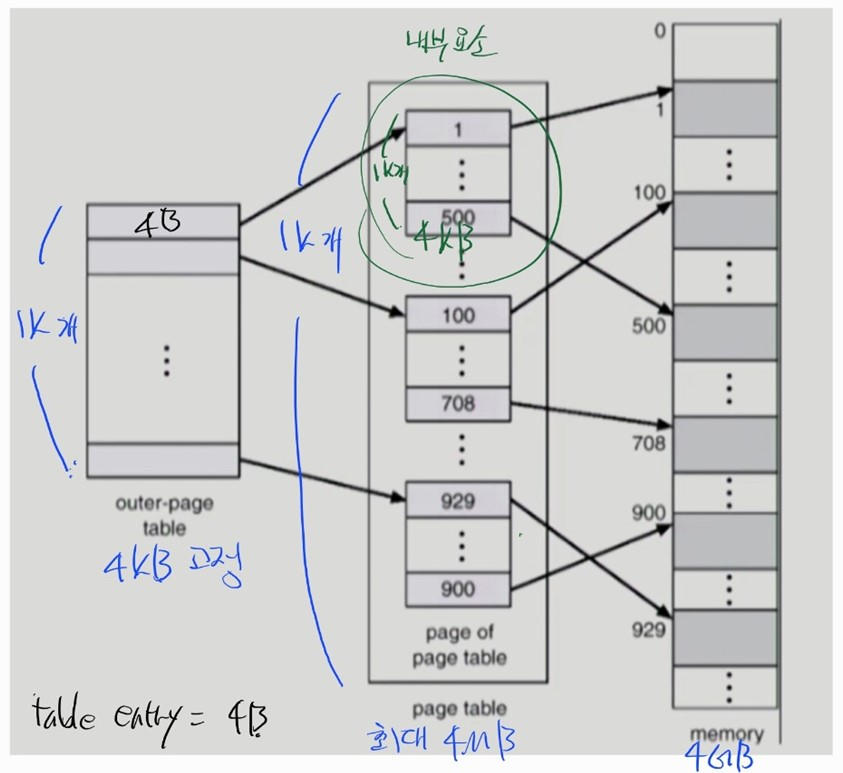
- outer-page table entry는 inner-page table의 page 를 가리킨다.
- outer-page table entry 는 1K 개로 총 1K * 4B = 4KB 의 고정된 page table 크기를 가진다.
- inner-page table 안의 각각의 요소들은 페이지이다. (page of inner-page table)
- inner-page table 안의 page 안의 각 요소들은 page table entry 이다.
- page table entry 는 물리 메모리의 frame number 를 가리킨다.
- page table entry 가 4B 이므로 page of inner-page table 는 4KB / 4B = 1K 개의 page table entry 를 가진다.
- inner-page table 의 각 요소들의 크기는 4KB 이다. (페이지니깐)
- inner-page table 안의 page 개수는 1K 개이다.
->(inner-page table 안의 page 개수) * (inner-page table 안의 page 안의 page table entry 개수)=1K * 1K=frame 1M 개
-> 따라서 4GB 의 모든 주소공간에 페이지를 할당할 수 있다.
- inner-page table 안의 page 가 최대 1K개 있으므로 inner-page table 은 최대 1K * 4KB = 4MB 의 크기를 갖는다.
- 그러나 inner-page table 안의 page 는 물리 메모리에 프로그램 페이지가 올라가 가리킬 frame number 가 필요한 경우에만 만들어진다.
- 실제로 물리 메모리에 올라가 사용되는 프로그램 페이지는 극히 일부분이므로 inner-page table 안의 page는 많이 만들어지지 않는다.
- inner-page table 의 총 크기는 왠만하면 4MB 보다 작다.
outer-page 범위에서 아무런 프로그램 페이지도 물리 메모리에 올라가지 않은 경우, inner-page table 안의 page 는 만들어지지 않고, outer-page table entry 는 null 을 가리킨다.
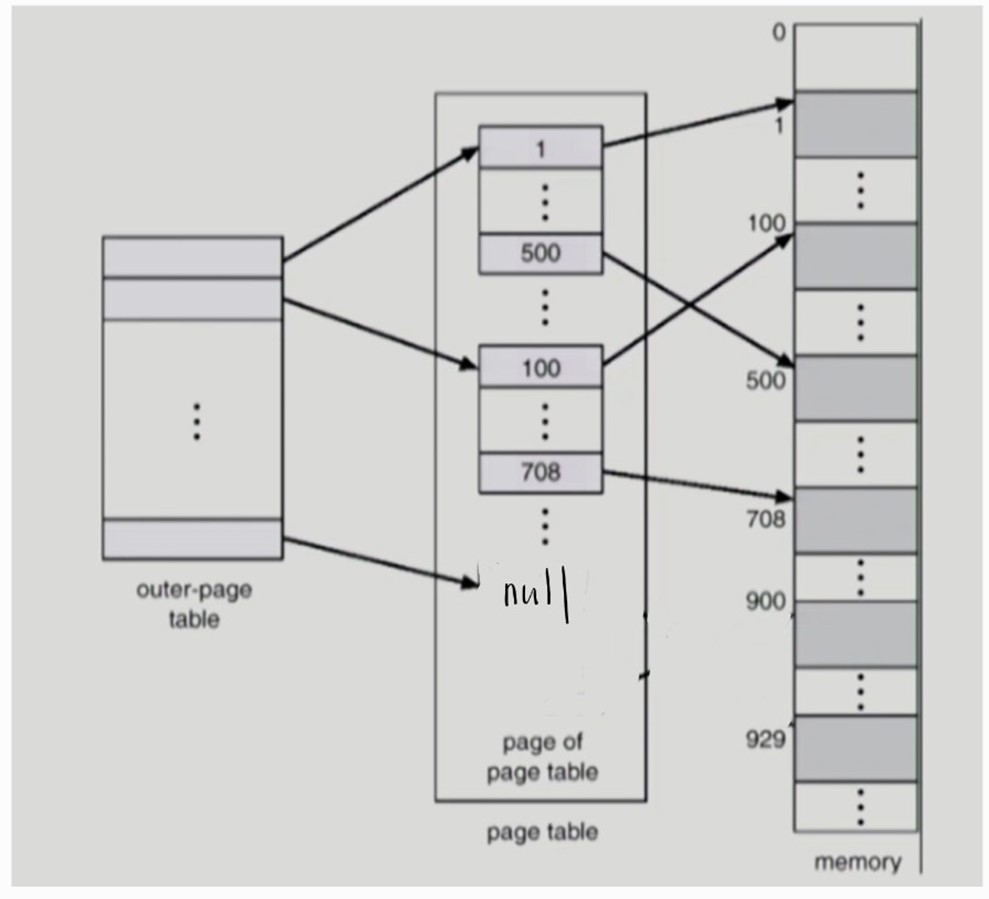
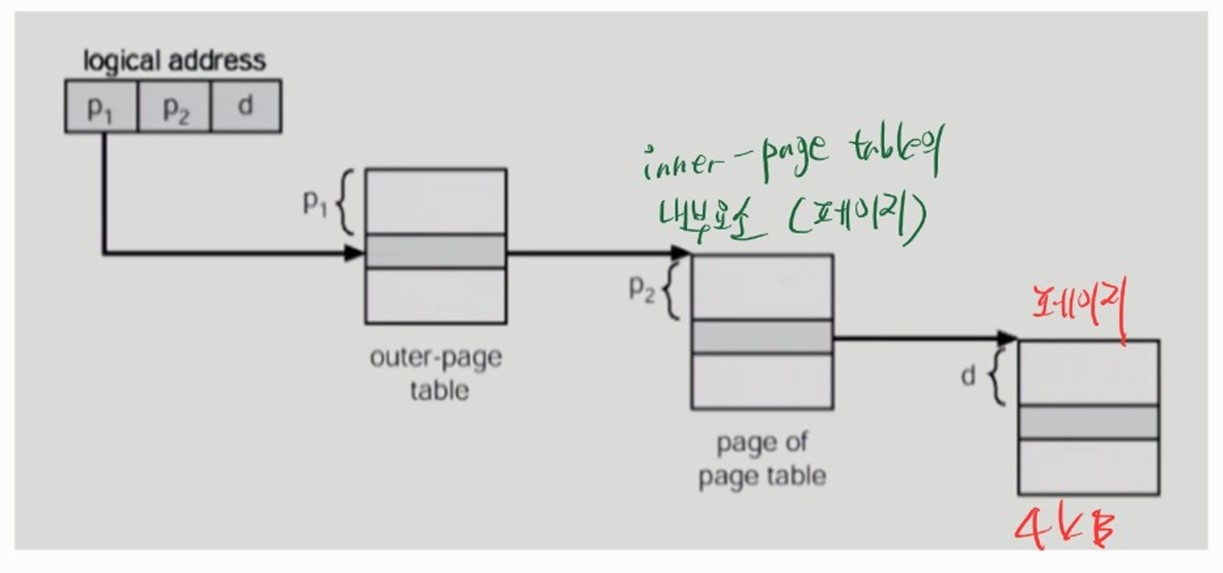
- CPU 가 접근할 실제 데이터/명령어의 physical address 로 변환하는 과정
- logical address 는 다음과 같이 변환된다.
- outer-page table 의 인덱스
p1을 통해 inner-page table 안의 page 를 찾는다.- inner page table 안의 page 에서 주어진 인덱스
p2를 사용해 frame number 를 찾는다.- 프로그램 페이지에서 주어진 offset
d만큼 이동해 physical address 를 찾는다.

- Logical Address 의 구성
p1은 1K개의 outer-page table entry 를 식별해야 하므로 2^10 = 1K, 10bit 가 필요하다.
p2는 1K개의 inner-page table 안의 page 들을 식별해야 하므로 2^10 = 1K, 10bit 가 필요하다.
d는 4KB 크기의 page 내에서 offset 주소를 더해야 하므로, 4 * 2^10 = 4K, 12bit 가 필요하다.
-
Inverted Page Table
-
프로세스 당 page table 을 별도로 두지 않고 시스템 내에서 한 개의 page table 만 두어 사용한다.
-
공간 절약
-
시간 손해
-
-
물리 메모리의 frame number와 page table 의 인덱스가 일치한다.
-
따라서 물리 메모리에 접근하기 위해서 현재 프로세스의 logical address 가 page table 에서 몇 번째에 위치하는 지 찾고
-
해당 위치의 frame number 로 이동하는 방식이다.
-
-
page table 의 인덱스 접근을 통해 frame number 를 알아내는 것이 아니고 page table 을 완전 탐색하여 frame number 를 알아낸다.
-
시간상의 큰 오버헤드 발생
-
따라서 병렬 처리가 가능하도록 associative 레지스터로 page table 을 만든다.
-
-
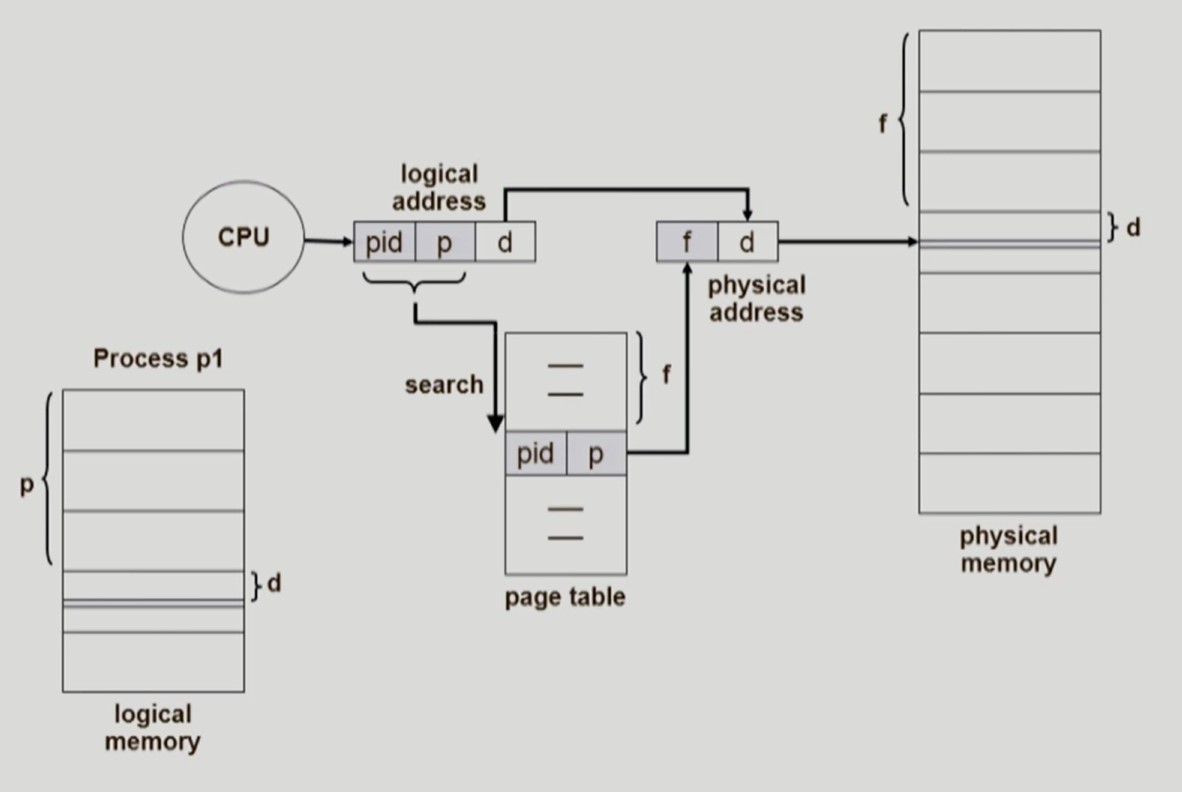
- 시스템 내에서 사용하는 한 개의 page table 에 프로세스 id
pid와 프로세스의 page 번호p를 저장한다.
- logical address 의
pid와p가 page table 의 몇 번째에 위치한 지 찾는다.
f번째에 위치한다.- 인덱스
f는 물리 메모리위에 해당 페이지가 올라간 위치인 frame number 와 같다.
- frame number 에서 offset
d만큼 더한 위치가 physical address 이다.
Segmentation
-
Non-contiguous allocation 방식 중 하나이다.
-
프로그램을 의미 단위인 여러개의 segment 로 나눈다.
-
code, data, stack 으로 segment를 나누거나
-
함수별로 segment 를 나눌 수 있다.
-
page 와 다르게 각 segment 의 크기는 같지 않다.
-
-
Segmentation 은 의미 단위로 프로그램을 쪼개기 때문에 Protection 설정과 Sharing 설정이 쉽고 효과적이다.
-
Paging 은 동일한 크기로 프로그램을 쪼개기 때문에 data 와 code 영역이 한 페이지에 공존할 수도 있다.
-
따라서 paging 은 Protection 설정과 Sharing 설정이 애매한 경우가 있다.
-
-
segment 의 길이가 일정하지 않으므로, 물리 메모리 상에 fragmentation 이 생긴다.
- 다른 크기의 segment 가 fragmentation 에 들어가지 못해 공간이 낭비될 수 있다.
-
segment table 은 일반적으로 page table 보다 크기가 작다.
-
각 프로세스당 segment 개수는 그렇게 많지 않다.
-
각 프로세스당 page 개수는 비교적 많다.
-
-
간단한 segmentation
-
page 와 유사하게 segment table 을 사용한다.
-
각 segment 의 길이는 다르므로, limit 레지스터를 통해 offset 이 segment 범위를 벗어나는지 체크한다.
-
각 프로세스마다 segment 개수는 다르므로 segment-table length register (STLR) 을 통해 segment table 인덱스가 segment 총 개수를 벗어나는지 체크한다.
-
- local address 는 segment table 인덱스
s와 offsetd를 가진다.
- segment table 의
s번째 인덱스에 접근하여 물리 메모리에 올라간 segment 의 시작 주소(base)를 알아낸다.
- 시작 주소에서 offset
d만큼 이동한 위치가 physical address 이다.
s가 STLR 이상이거나,d가 limit 레지스터보다 크면 trap 이 발생한다.
-
Segmentation with Paging
-
프로그램을 segmentation 단위로 나눈다.
-
각 segmentation 을 고정된 크기의 page 로 나눈다.
- 물리 메모리내에 사용할 수 없는 fragmentation 발생 문제 해결
-
Protection 설정, Sharing 설정과 같이 의미 단위 작업은 segmentation level 에서 수행하고, 물리 메모리에 프로그램을 적재할 땐 segmentation 범위내에서 page 단위로 올린다.
-
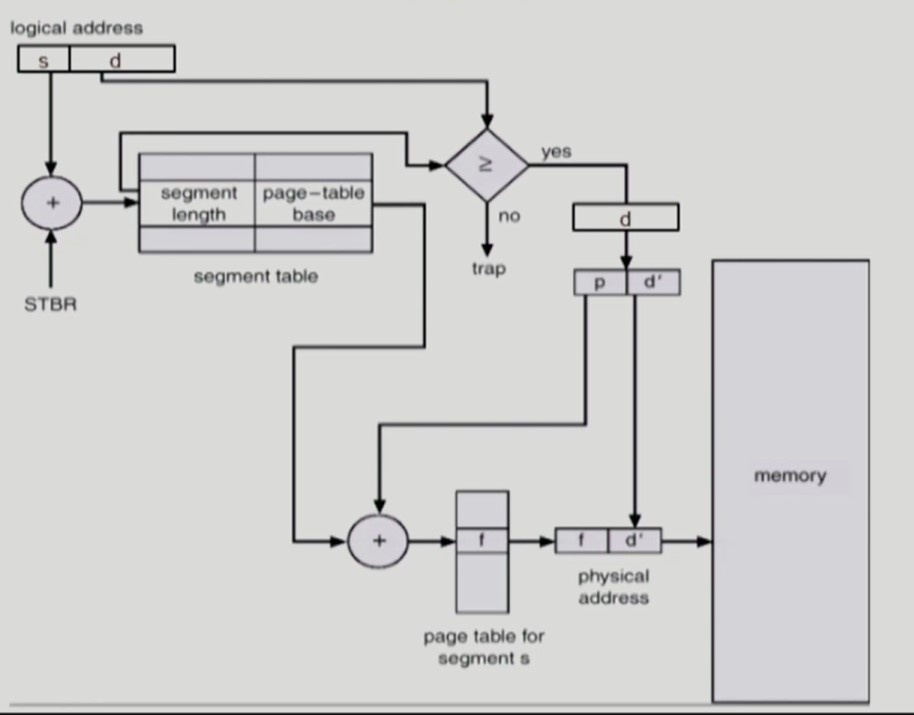
- logical address 의 segment table 인덱스
s의 사용
segment table[s] = page-table base- segment 를 이루는 page 들에 접근하기 위한 page table 의 시작주소를 알아낸다.
- logical address 의
d는 page table 인덱스p와 page 내에서의 offsetd'으로 이루어진다.
- logical address 의 page table 인덱스
p의 사용
page table[p] = f- 물리 메모리위에 페이지가 위치한 시작 주소인 frame number 를 알아낸다.
- logical address 의 offset
d'의 사용
- 물리 메모리위에 페이지 시작 주소에
d'만큼 더해 physical address 를 구한다.
Virtual Memory
- 각 프로세스가 갖는 가상의 메모리 공간
Demand Paging
-
프로세스의 특정 페이지 영역을 실제로 사용할 시점에 해당 페이지를 물리 메모리에 올리는 것
-
이를 통해 더 많은 프로그램을 동시에 물리 메모리위에 올릴 수 있다.
- 물리 메모리를 효율적으로 사용한다.
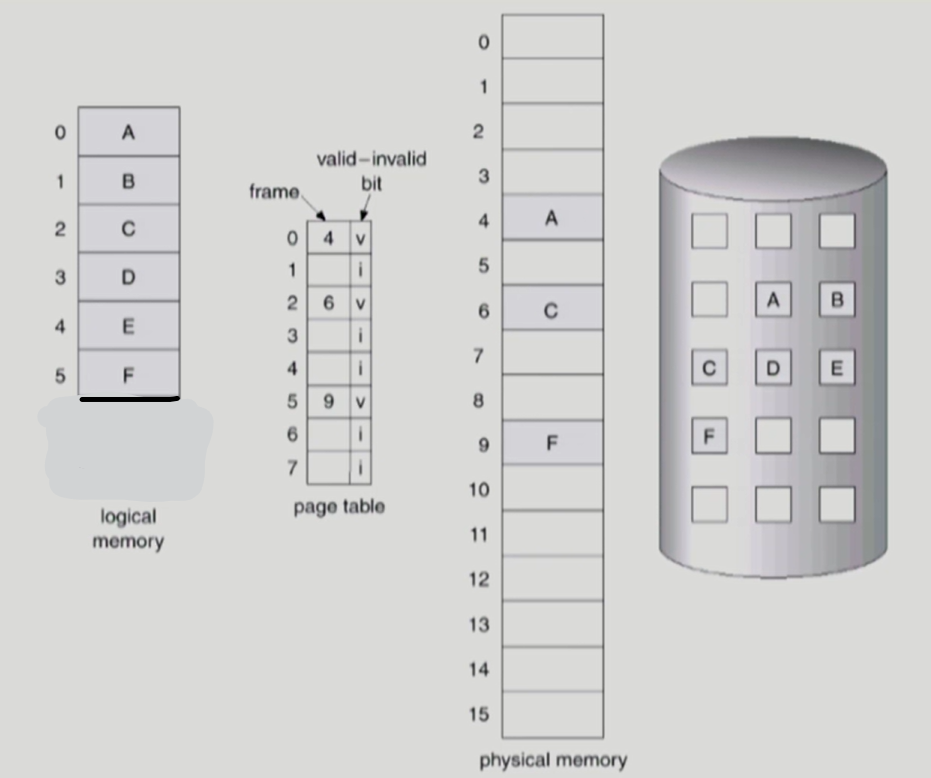
- invalid bit
- 유효하지 않은 페이지를 의미한다.
- 프로그램의 범위를 벗어나는 6번, 7번 페이지
- 현재 물리 메모리위에 존재하지 않고 backing store 에 있는 1번, 3번, 4번 페이지
- valid bit
- 바로 사용할 수 있는 페이지를 의미한다.
- 현재 물리 메모리위에 존재하는 0번, 2번, 5번 페이지
Page Fault
-
만약 Logical Address 의 페이지 번호가 invalid 상태라면 page fault 라 한다.
-
이 경우 MMU가 trap 을 발생시켜 OS에게 CPU가 넘어간다.
-
즉, page fault 는 OS가 해결한다.
-
-
프로그램 범위를 벗어난 페이지 요청이라면 해당 프로세스를 추방한다.
-
프로그램 범위의 페이지 요청이라면 비어있는 물리 메모리의 frame 을 찾는다.
- 비어있는 frame 이 없으면 우선순위가 낮은 페이지를 frame에서 추방시켜 빈 frame 을 만든다. (Page Replacement)
-
Logical Address 의 페이지를 disk에서 찾아 물리 메모리의 frame 에 올린다.
-
이때 disk I/O는 시간이 오래 걸리므로 해당 프로세스는 CPU를 반납하고 I/O queue 에서 대기한다. (block)
-
disk I/O 작업이 끝나면 page table 에 해당 페이지를 valid 로 설정하고, 해당 page가 물리 메모리에 위치한 frame number 를 적는다.
-
그 다음, 해당 프로세스는 CPU를 사용하기 위해 Ready queue 에서 대기한다.
-
-
이후, 해당 프로세스가 CPU를 선점하면 logical address translation 시 page fault 가 발생하지 않고 physical address 를 구할 수 있다.
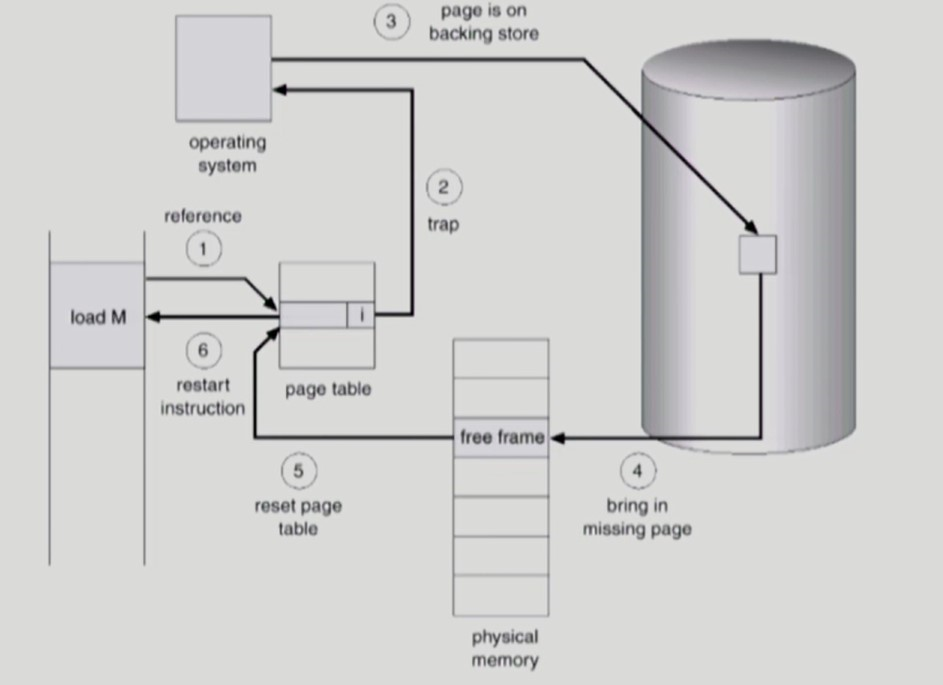
Page Replacment Algorithm
-
Page Replacement
-
물리 메모리의 frame 들이 모두 페이지로 가득 차 있는 상황에서
-
특정 frame의 페이지를 disk (backing store) 로 추방시키고 요청 페이지를 방금 비운 frame 에 넣어 페이지를 교체하는 것
-
-
어떤 페이지를 교체할 지 결정하는 알고리즘
-
page-fault rate 를 최소화하는 것이 좋은 알고리즘이다.
-
금방 다시 사용될 페이지를 내쫓는 것은 비효율적이다.
- pafe-fault rate ↑
-
-
Optimal Algorithm
-
가장 먼 미래에 참조되는 페이지를 교체한다.
-
가장 효율적인 알고리즘
-
미래를 알 수 없으므로 실제 구현할 수는 없고 다른 교체 알고리즘 성능에 대한 upper bound 를 제공한다.
-
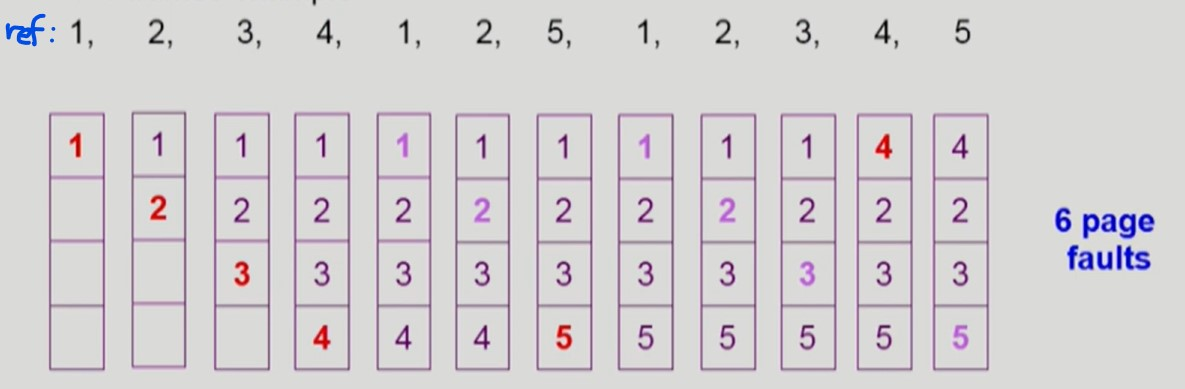
-
FIFO Algorithm
-
First In First Out
- 가장 먼저 들어온 페이지를 교체한다.
-
페이지 frame 을 늘렸을 때 성능이 더 나빠지는 이상현상이 발생할 수 있다.
-
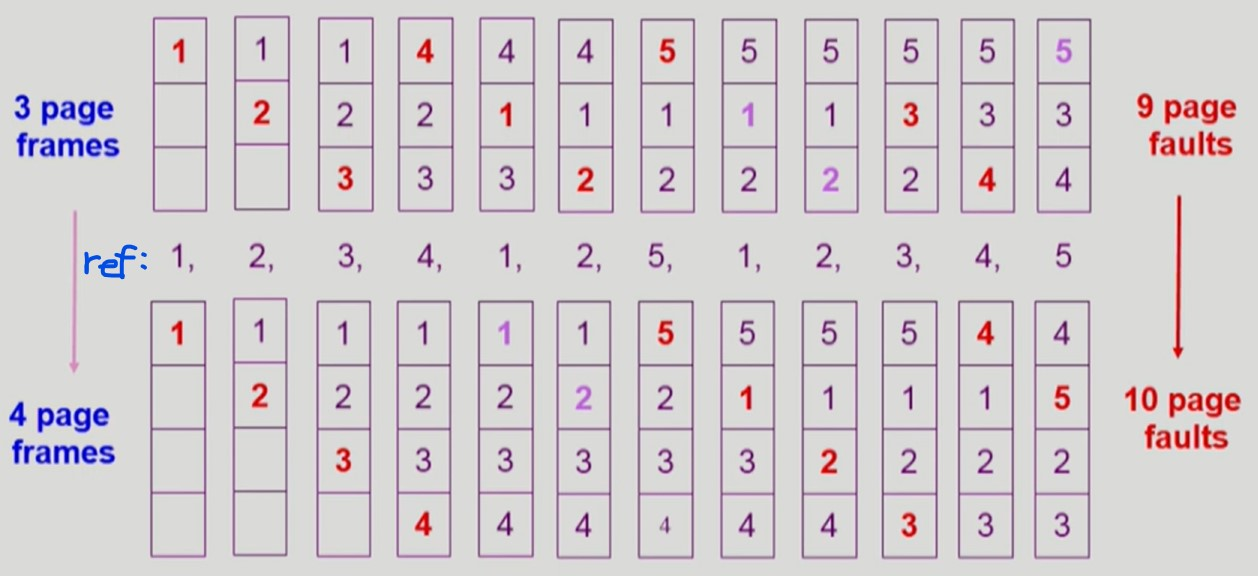
페이지 frame 을 늘렸는데 성능이 떨어지는 FIFO Anomaly 발생
-
LRU Algorithm
-
Least Recently Used
- 가장 오래전에 참조된 페이지를 교체한다.
-
최근에 참조된 페이지가 다시 참조될 확률이 높음을 이용
-
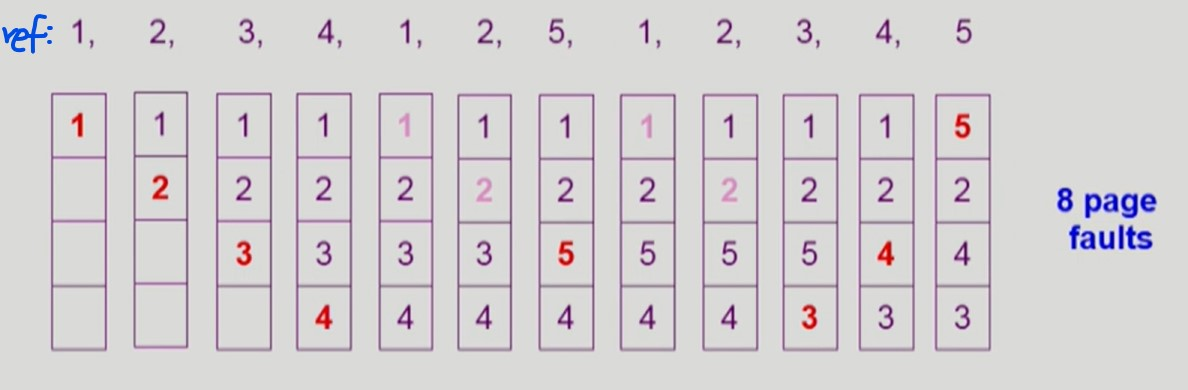
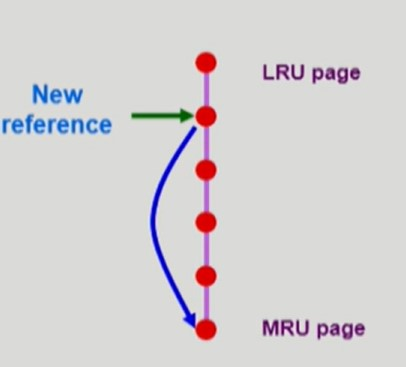
LRU 알고리즘의 구현
- Doubly Linked List 자료구조로 구현한다.
- 특정 페이지가 참조되면 해당 페이지를 자료구조의 맨 앞으로 옮긴다.
- 페이지 교체가 필요한 경우 자료구조의 맨 뒤에 위치한 페이지를 제거하고 새로운 페이지를 자료구조의 맨 앞에 넣는다.
O(1)시간 복잡도
-
LFU Algorithm
-
Least Frequently Used
- 참조 횟수가 가장 적은 페이지를 교체한다.
-
많이 참조된 페이지는 또다시 참조될 확률이 높음을 이용
-
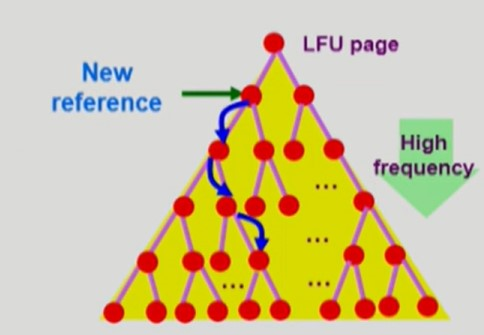
LFU 알고리즘의 구현
- Heap 자료구조로 구현한다.
부모의 참조 횟수<자식의 참조 횟수인 최소 Heap
- 특정 페이지가 참조되면 해당 페이지를 자료구조에서 자식들과 비교하여 아래로 내린다.
- 페이지 교체가 필요한 경우 자료구조의 루트 노드 페이지를 제거하고 새로운 페이지를 자료구조의 루트 노드에 넣는다.
O(logN)시간 복잡도
-
그러나 Paging System 에서 LRU, LFU 는 구현할 수 없다.
-
위 알고리즘들은 페이지가 참조될 경우, OS 가 자료구조내의 페이지들의 관계를 갱신해줘야 한다.
-
LRU의 경우 참조된 페이지를 자료구조의 맨 앞으로 옮기고, LFU의 경우 자료구조 (Heap) 를 재정렬 해주어야 한다.
-
하지만 OS는 page fault 가 발생했을때만 CPU 제어권을 가진다.
- page table 에 요청 페이지가 valid 인 경우, OS에게 CPU가 넘어가지 않고 하드웨어적으로 모두 처리한다.
-
따라서 page table 에 이미 존재하는 페이지들에 대해 적절한 갱신을 수행할 수 없다.
-
-
Clock Algorithm
-
Paging System 에서 실제로 적용할 수 있는 알고리즘
-
Second Chance Algorithm 이나 NRU (Not Recently Used) Algorithm 으로도 불린다.
-
Circular List 로 페이지들을 관리한다.
-
reference bit 을 사용해 교체 대상 페이지를 선정한다.
- 특정 페이지를 참조하면 하드웨어가 해당 페이지의 reference bit 을 1로 세팅한다.
-
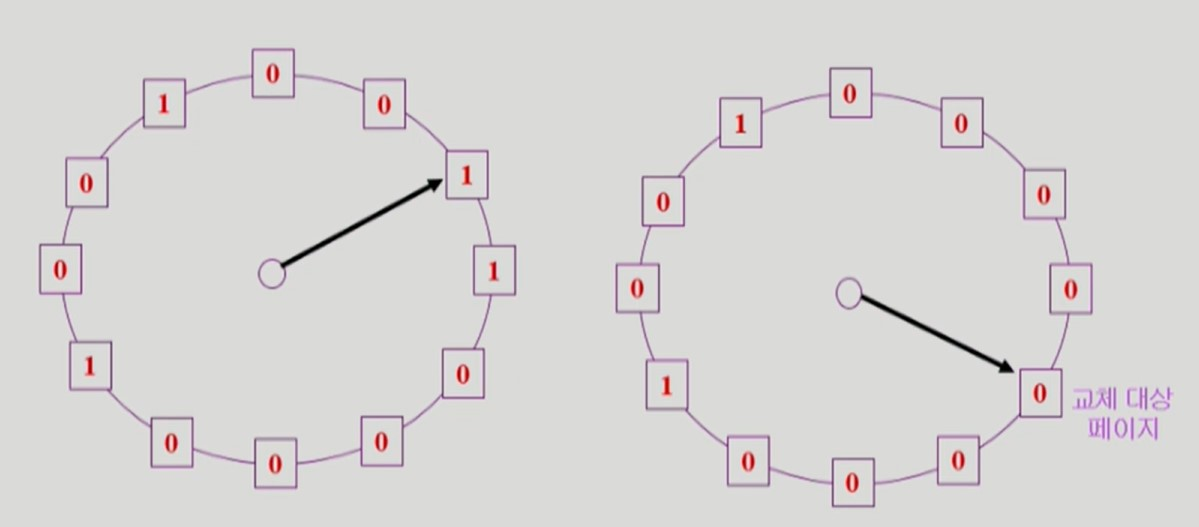
- reference bit 이 0인 페이지를 찾을 때까지 포인터가 이동한다.
- 포인터는 이동하면서 reference bit 1 을 모두 0으로 바꾼다.
- 포인터가 reference bit 이 0인 페이지를 찾으면 해당 페이지를 교체한다.
- LRU 처럼 정확하게 가장 오래전에 사용된 페이지를 교체하진 않지만 포인터가 한 바퀴 도는 동안에 사용되지 않은 페이지를 교체하므로, 결과적으로 오랫동안 사용되지 않은 페이지를 솎아낸다.
Page Frames per Process
각 프로세스에 얼마만큼의 page frame 을 할당해야 할까?
-
페이지 교체 알고리즘의 적용 범위
-
프로세스를 구별하지 않고 전역적으로 적용되거나 (global),
-
프로세스마다 사용할 수 있는 물리 메모리 frame 개수를 정해주고, 그 안에서 프로세스 내부적으로 페이지 교체 알고리즘을 적용한다. (local)
- 프로세스 A가 0 ~ 5 페이지로 이루어져 있고, 할당된 물리 메모리 frame 이 3개라면, 3개까지는 그냥 채워넣고 이를 초과하면 교체 알고리즘을 잘 적용해서 사용한다.
-
-
Allocation Scheme
-
Equal allocation: 모든 프로세스에 똑같은 개수의 frame 할당
-
Proportional allocation: 각 프로세스 크기에 비례하여 frame 할당
-
Priority allocation: 각 프로세스의 priority 에 비례하여 frame 할당
-
-
Thrashing
-
프로세스가 원활하게 수행되기 위한 최소한의 frame 수를 할당받지 못한 경우 발생한다.
-
page fault rate 이 매우 높아져
-
프로세스가 대부분의 시간을 페이지를 swapping 하는 Disk I/O 작업으로 보내고
-
CPU는 대부분의 시간을 놀게되는 현상
-
-
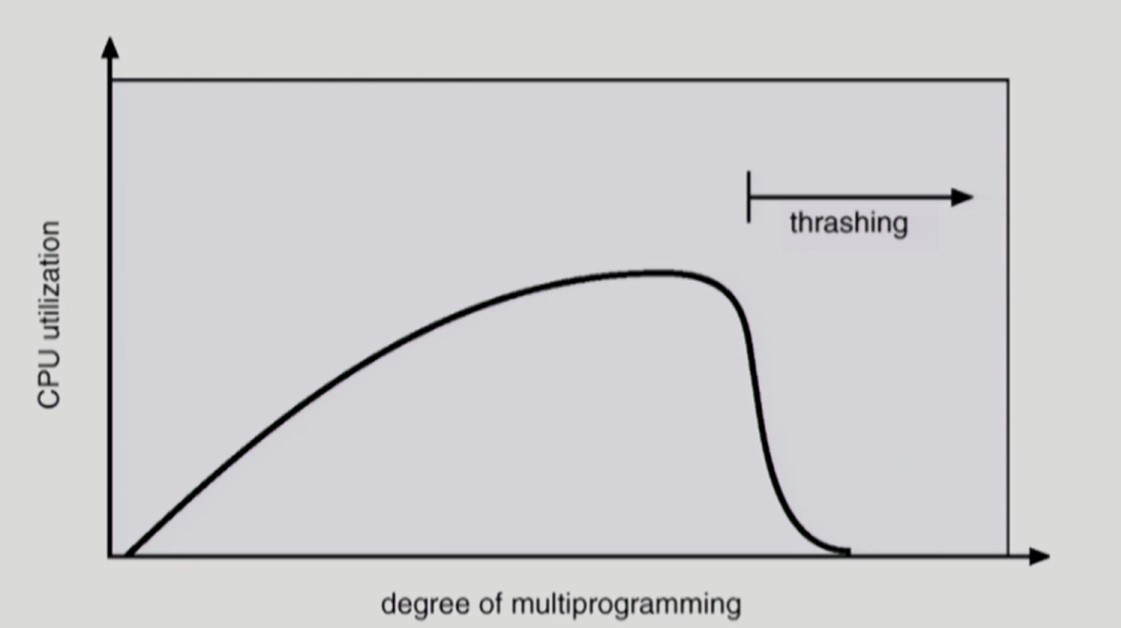
- 동시에 실행되는 프로세스가 너무 많으면 프로세스당 frame 이 적게 할당된다.
- degree of multiprogramming ↑↑
- 이 경우 빈번한 page fault 로 Disk I/O 작업 빈도가 증가한다.
- 어떤 프로세스가 CPU를 잡아도 page fault 가 발생한다.
- CPU 는 대부분의 시간을 놀게된다.
- CPU Utilization 감소
-
Working-Set Model
-
프로세스가 원활히 실행되기 위해선 어느정도의 frame 이 마련되어야 한다.
-
프로세스는 특정 시간동안 일정 장소만을 집중적으로 참조하는 경향이 있다.
- 집중적으로 참조되는 페이지들의 집합 = locality set = working set
-
Working Set 모델은 프로세스의 working set 전체가 물리 메모리에 있어야 프로세스를 실행한다.
- working set 전체를 물리 메모리에 올릴 수 없는 경우 해당 프로세스의 모든 page frame 을 반납하고 프로세스를 중지한다. (backing store 로 swap out)
-
이를 통해 Multiprogramming degree 를 결정하고 Thrashing 을 방지한다.
-
-
Working-Set Algorithm
-
현재시점부터 window 크기만큼의 과거의 참조된 모든 페이지들이 working set이 된다.
-
이는, 페이지가 처음 참조된 후 window 시간동안 해당 페이지를 물리 메모리에 유지한 후 swap out 하는 것과 동일한 의미이다.
- 만약 window 시간내에 재참조되면 유지시간을 window 크기만큼 다시 초기화한다.
-
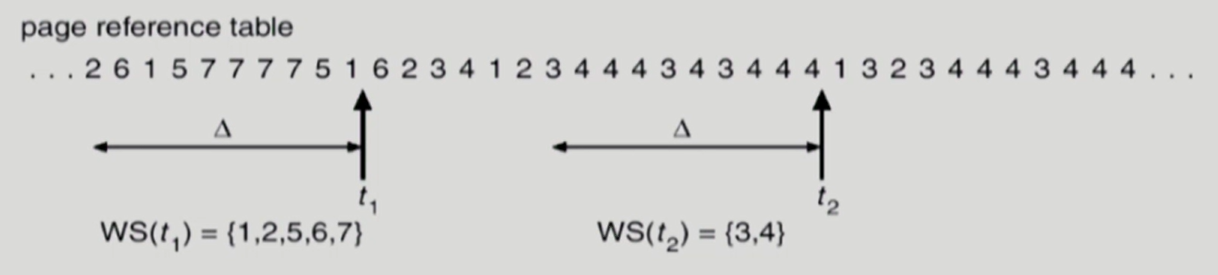
t1시점에서 해당 프로세스에게 1,2,5,6,7 번 페이지가 올라갈 5개의 frame 공간을 마련할 수 있다면, 1,2,5,6,7 번 페이지를 frame 에 올리고, 프로세스를 실행한다.
- 마련할 수 없다면 물리 메모리에 존재하는 해당 프로세스의 page frame 들을 모두 반납하고 해당 프로세스를 중지한다.
t2시점에서 해당 프로세스에게 3,4 번 페이지가 올라갈 2개의 frame 공간을 마련할 수 있다면, 3,4 번 페이지를 frame 에 올리고, 프로세스를 실행한다.
- 마련할 수 없다면 물리 메모리에 존재하는 해당 프로세스의 page frame 들을 모두 반납하고 해당 프로세스를 중지한다.
-
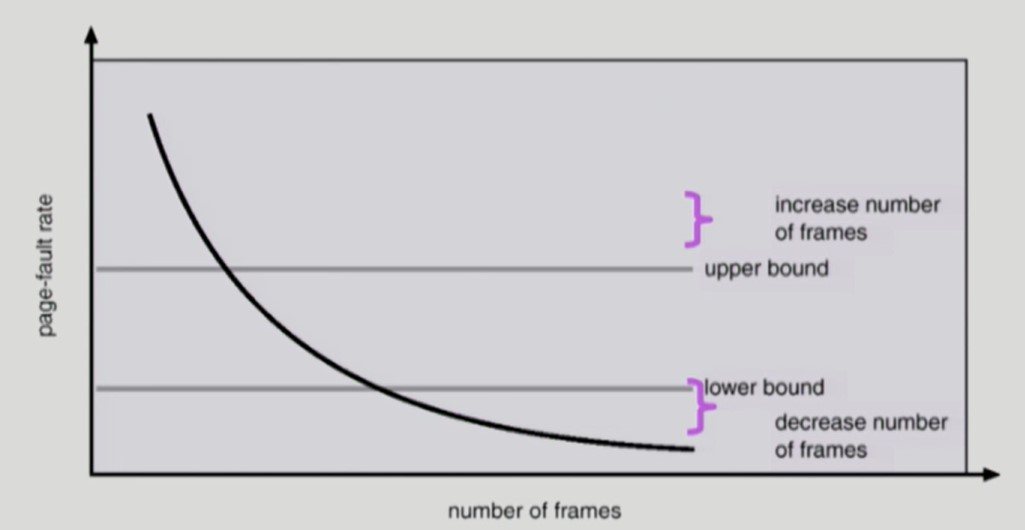
PFF Scheme
-
Page-Fault Frequency
-
특정 프로세스의 page-fault rate 이 상한값을 넘으면 frame 을 더 할당한다.
- 할당할 빈 frame 이 없으면 이미 할당된 해당 프로세스의 page frame 들을 모두 반납하고 프로세스 중지
-
특정 프로세스의 page-fault rate 이 하한값보다 작으면 할당 frame 수를 줄인다.
-
Page Size
-
페이지 크기가 작아지면
-
페이지 수 증가
-
page table 크기 증가
-
물리 메모리에서 페이지를 더 이상 할당할 수 없는 자투리 공간이 작아진다.
-
필요한 정보만 물리 메모리에 올라온다.
-
-
페이지 크기가 커지면
-
페이지 수 감소
-
page table 크기 감소
-
Locality 활용 ↑
-
Disk 에서 크게 크게 덩어리로 페이지를 찾아오기에 Disk I/O 작업 빈도를 줄일 수 있다.
-
오늘날 트렌드는 page 크기를 키우고 있다.
File Systems
용어정리
-
File
-
이름을 통해 접근할 수 있는 데이터 단위
-
일반적으로 비휘발성의 보조기억장치 (Disk) 에 저장
-
-
File metadata
-
파일 자체의 내용이 아니라 파일을 관리하기 위한 각종 정보들
-
파일 이름, 유형, 저장 위치, 파일 사이즈, 접근 권한 등
-
-
File System
-
OS 에서 파일을 관리하는 부분
-
파일을 어떻게 저장할지, 관리할지, 보호할지 정한다.
-
-
Directory
-
디렉토리에 속한 파일들의 메타데이터를 보관하는 특별한 파일
-
디렉토리 파일의 내용은 디렉토리에 속한 파일들의 메타데이터이다.
-
-
Partition
-
Logical Disk
-
하나의 물리적 디스크를 여러개의 논리적 디스크로 나눠 사용하거나
-
여러개의 물리적 디스크를 하나의 논리적 디스크로 합쳐 사용할 수 있다.
-
파일을 읽는 과정
-
파일 작업에 사용되는 명령어들은 모두 system call 명령어이다.
- 실질적인 작업은 커널모드에서 수행된다.
-
파일을 여는
open명령어는 원하는 파일의 메타데이터를 메모리로 가지고 온다. -
open한 파일들의 메타데이터는 open file table 에 저장된다.-
System wide 한 테이블로, 모든 프로세스가 이용 가능하다.
-
특정 프로세스가 파일의 어디까지 접근하였는지를 표시하기 위해 프로세스 별로 File offset 을 기록한다.
-
-
특정 프로세스에서 이용하려는 파일의 메타데이터가 open file table 의 어느 위치에 있는지는 file descriptor 에 저장한다.
- file descriptor 는 프로세스별로 PCB에서 보관한다.
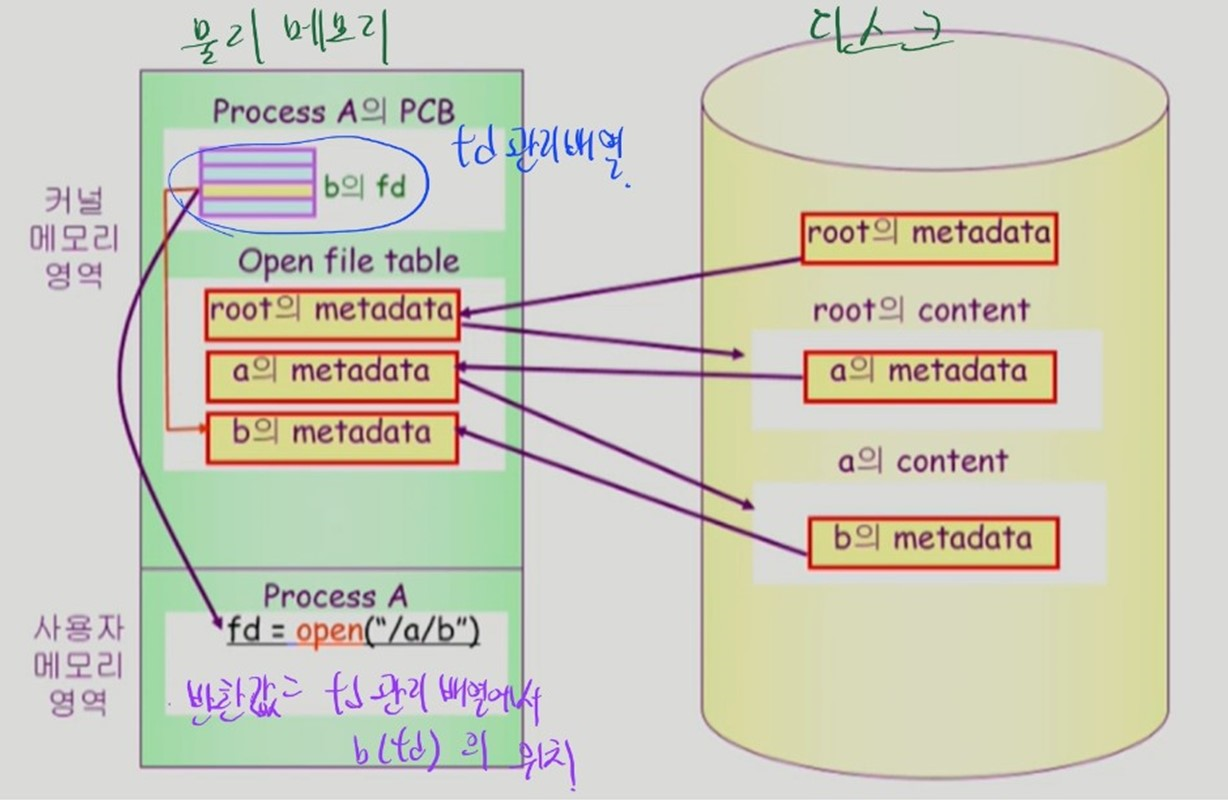
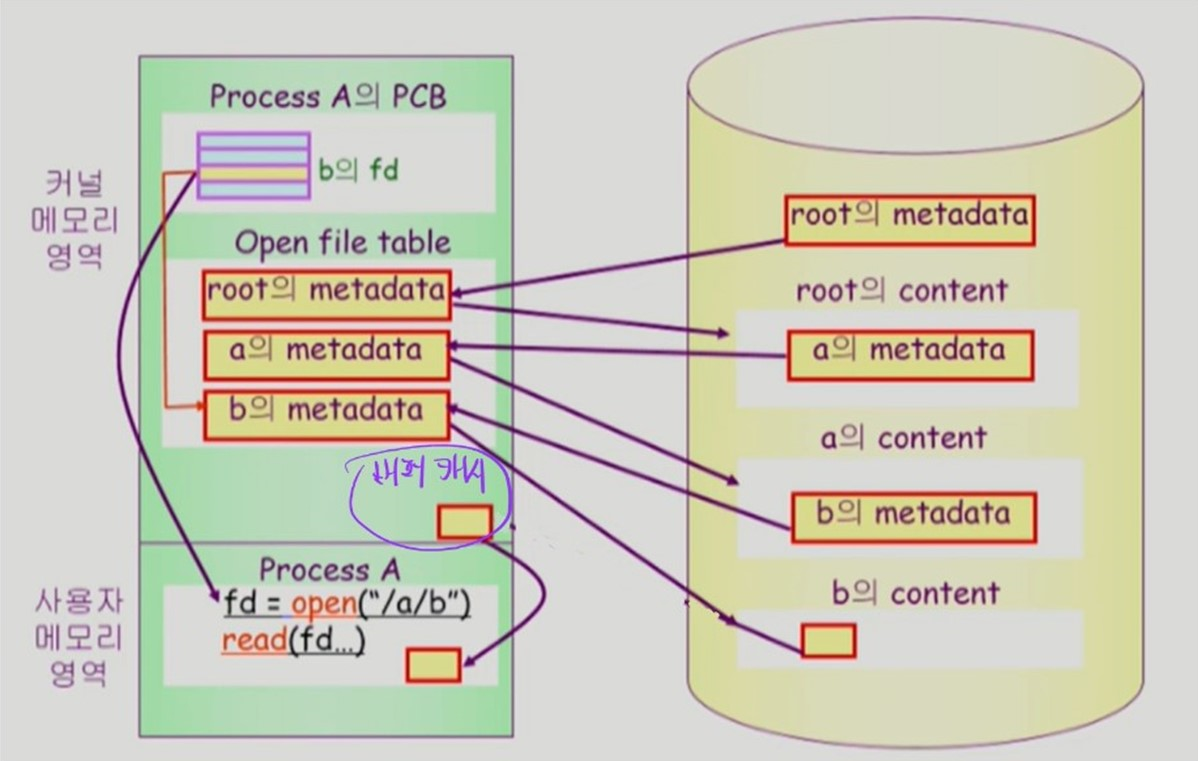
open("/a/b")명령어 실행 시,
- "/" (root) 의 메타데이터를 찾아 메모리에 올린다.
- "/" 의 메타데이터를 통해 "/" 의 content 에 접근하여 a의 메타데이터를 찾는다.
- a의 메타데이터를 통해 a의 content에 접근하여 b의 메타데이터를 찾는다.
- Process A 가 open 한 파일 b 의 메타데이터가 open file table의 어디에 위치하는지는 file descriptor (b의 fd) 에 저장한다.
- 이러한 file descriptor 들은 PCB에서 배열로 관리한다.
open명령어의 반환값은 PCB의 file descriptor 배열에서 b의 file descriptor 가 위치한 인덱스 값이다.
-
파일을 읽는
read(fd ...)명령어는 앞서 구한 파일의 메타데이터를 바탕으로 해당 파일의 content를 Disk에서 읽어온다.-
이때, content 는 OS의 버퍼 캐시에 저장된다.
-
이후, 버퍼 캐시의 content를 복사해 사용자 프로세스로 붙여넣는다.
-
만약, 읽어오려는 파일의 content가 OS의 버퍼 캐시에 이미 있다면, Disk 까지 가지 않고 버퍼 캐시에서 바로 읽어온다.
-
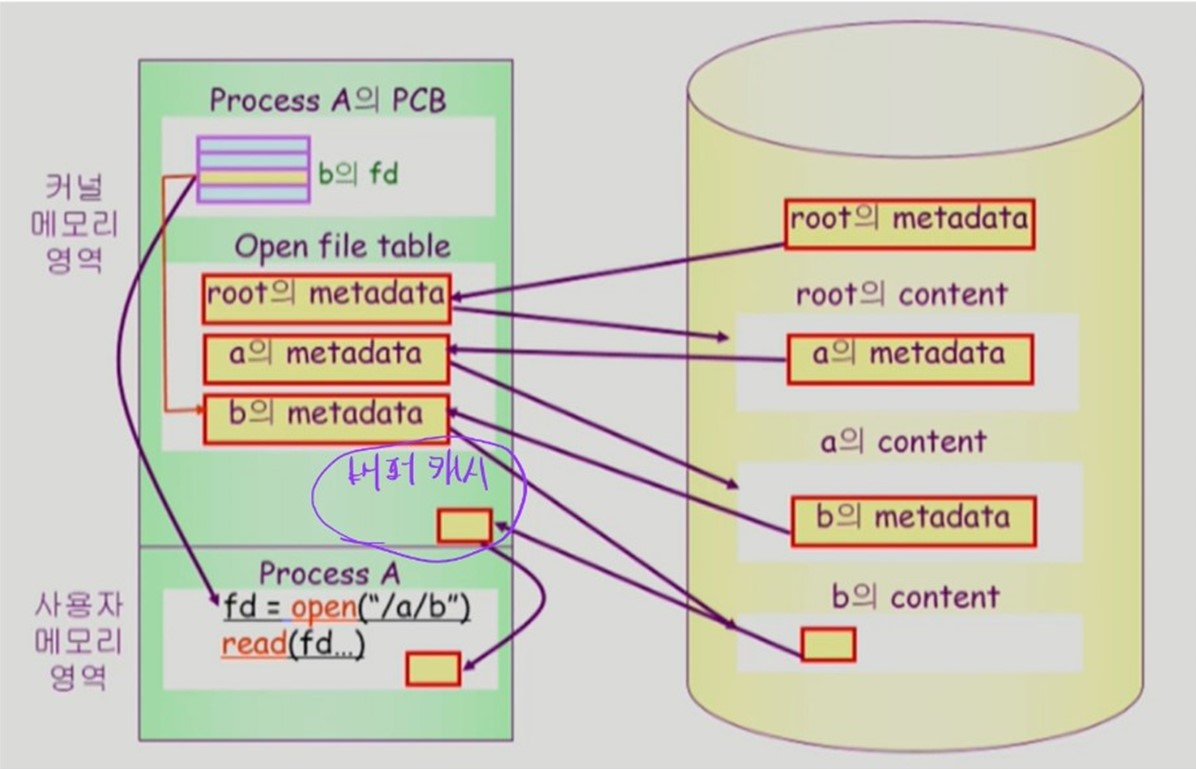
버퍼 캐시에 원하는 파일 content 가 없는 경우
- Disk 에서 파일 content를 읽어와 OS의 버퍼 캐시에 저장 후
- 버퍼 캐시의 content를 복사하여
read(fd ...)명령어의 반환값으로 전달한다.
버퍼 캐시에 원하는 파일 content가 있는 경우
- 버퍼 캐시의 content를 복사하여
read(fd ...)명령어의 반환값으로 전달한다.
- Disk 접근 x
File Protection
-
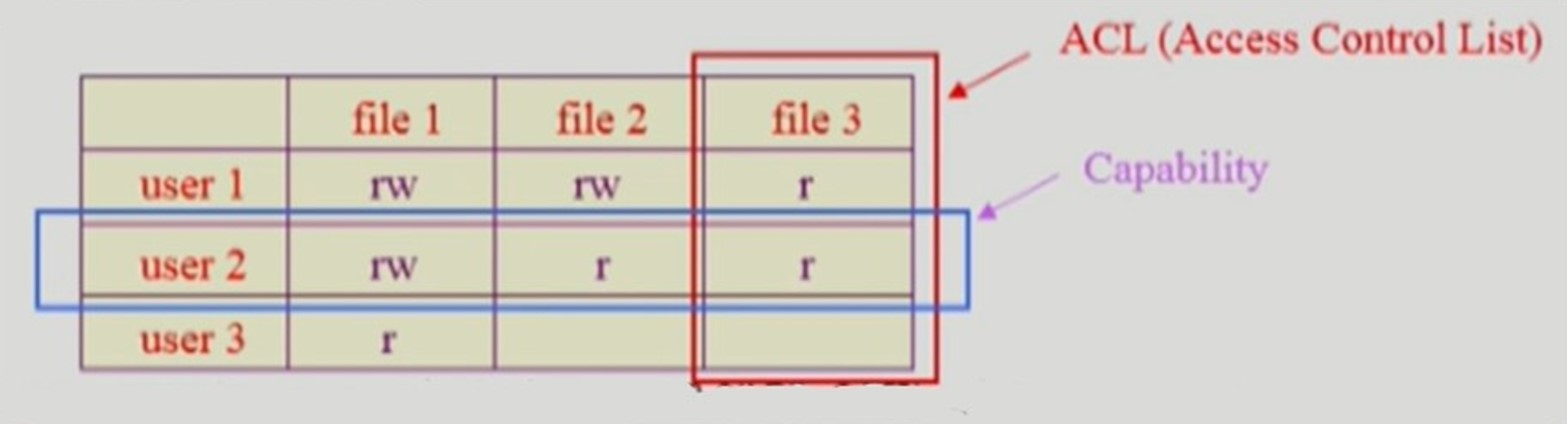
Access Control Matrix
-
특정 사용자가 특정 file에 대해 어떤 권한이 있는지를 matrix 형태로 기록하여 저장하는 것
-
특정 사용자가 자신만 사용하기 위해 만드는 특별한 파일은, 다른 사용자가 모두 접근할 수 없다.
-
그럼에도 다른 사용자들은 해당 파일 성분을 빈칸으로 갖고 있어야한다.
-
그렇기에 굉장히 sparse 한 행렬이 만들어져 공간이 낭비된다.
-
-
공간 낭비를 줄이기 위해
-
파일을 기준으로 접근 권하을 가진 사용자를 나타내는 ACL (Access Control List)
-
사용자를 기준으로 자신이 접근할 수 있는 파일과 해당 권한을 표시하는 Capability 방식을 사용할 수 있다.
-
-
-
Grouping
-
특정 파일의 접근 권한을 세 그룹으로 나눠 각각을 표현한다.
-
소유주 owner
-
소유주가 속한 그룹 group
-
이외의 모든 사용자 other
-
-
접근권한을 rwx 3bit로 표시한다.
-
r ➔ read
-
w ➔ write
-
x ➔ execute
-
-
파일별로 9개의 bit 만 있으면 접근권한을 표시할 수 있다.
-
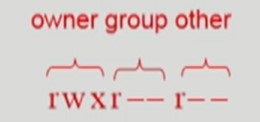
Disk의 파일 데이터를 저장하는 방식
-
Contiguous Allocation
-
하나의 파일이 Disk에 연속된 공간에 저장되는 방식
-
fragmentation 이 발생하여 공간이 낭비된다.
-
빠른 Disk I/O 작업이 가능하다.
-
Disk I/O 작업에서 가장 오랜시간이 걸리는 작업은 seek time 이다.
-
seek time >> transfer time
-
contiguous allocation 방식은 seek time 을 대폭 줄여 Disk I/O 시간을 줄여준다.
- 한번의 seek로 파일 데이터를 전부 가져온다.
-
-
파일 데이터의 특정 위치로 direct access 할 수 있다.
-
contiguous allocation 방식은 File System 보다는 프로세스의 Swapping 용도로 사용된다. (backing store)
-
swap out 된 프로세스는 장시간 저장되지 않고 금방 swap in 되기 때문에 공간 효율성이 아주 중요하진 않다.
-
swapping 영역은 시간 효율성이 더 중요하다.
-
-
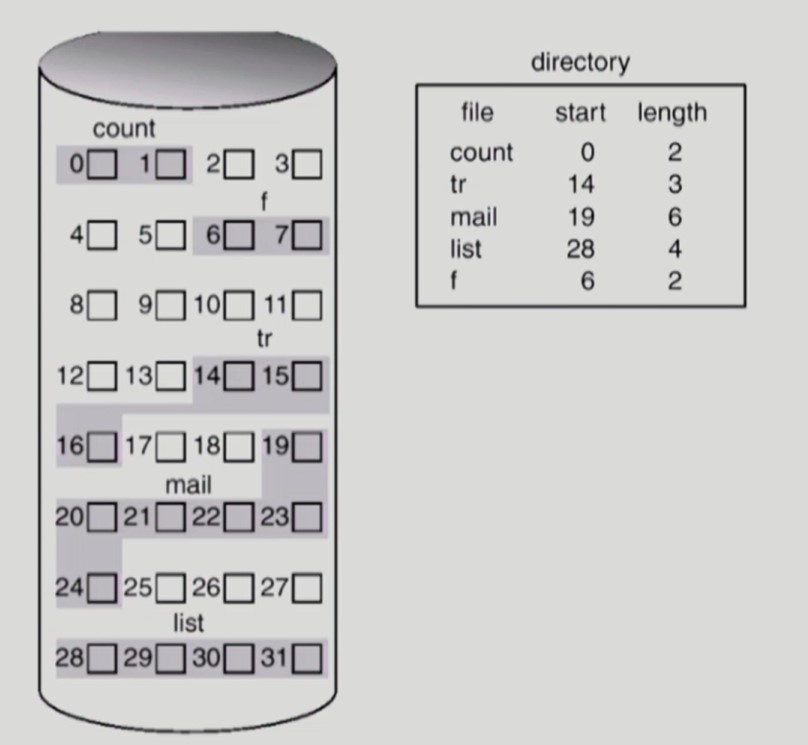
디렉토리는 파일 데이터의 시작 인덱스와 파일의 길이 정보를 갖고 있다.
-
Linked Allocation
-
하나의 파일이 링크드 리스트 형태로 분리되어 Disk에 불연속적으로 저장된다.
-
fragmentation 이 발생하지 않아 공간을 효율적으로 사용할 수 있다.
-
Disk I/O 작업이 상대적으로 느리다.
-
링크드 리스트를 타고 타고 이동하며 전체 파일을 구성해야 한다.
-
즉, 헤드가 각각의 위치로 반복해서 이동해야 한다.
-
seek time 이 늘어나 I/O 작업 시간이 늘어난다.
-
-
파일 데이터의 특정 위치로 direct access 할 수 없다.
-
특정 sector 가 고장나 포인터가 유실되면 파일 데이터의 유실된 포인터 이후 부분들을 찾을 수 없다. (reliability 문제)
-
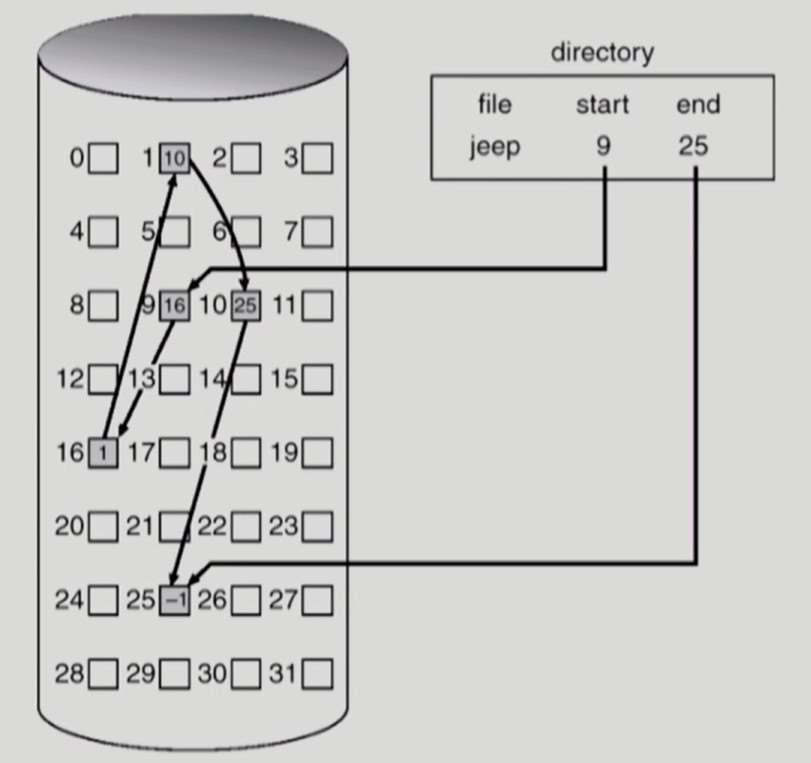
디렉토리는 파일 데이터의 시작 인덱스와 끝 인덱스 정보를 갖고 있다.
-
Indexed Allocation
-
하나의 파일이 Disk 내에서 불연속적으로 흩어져 저장된다.
- 흩어진 파일 조각들이 파일에서 몇 번째 조각이고, 디스크의 어느 위치에 존재하는지를 나타내는 인덱스 블록을 추가적으로 만들어 저장한다.
-
fragmentation 이 발생하지 않아 공간을 효율적으로 사용할 수 있다.
-
Disk I/O 작업이 상대적으로 느리다.
-
파일 데이터의 특정 위치로 direct access 할 수 있다.
-
파일이 아주 작은 경우에도 인덱스 블록이 하나 생기는 점은 공간 효율성면에서 단점이다.
-
파일이 아주 큰 경우 하나의 인덱스 블록으로 표현할 수 없다.
-
인덱스 블록이 더 필요하면 링크드 리스트로 인덱스 블록을 또 만들어 연결하는 linked scheme 방식이나
-
인덱스 블록의 인덱스 블록과 같이 계층을 주는 multi-level index 방식을 사용해야 한다.
-
-
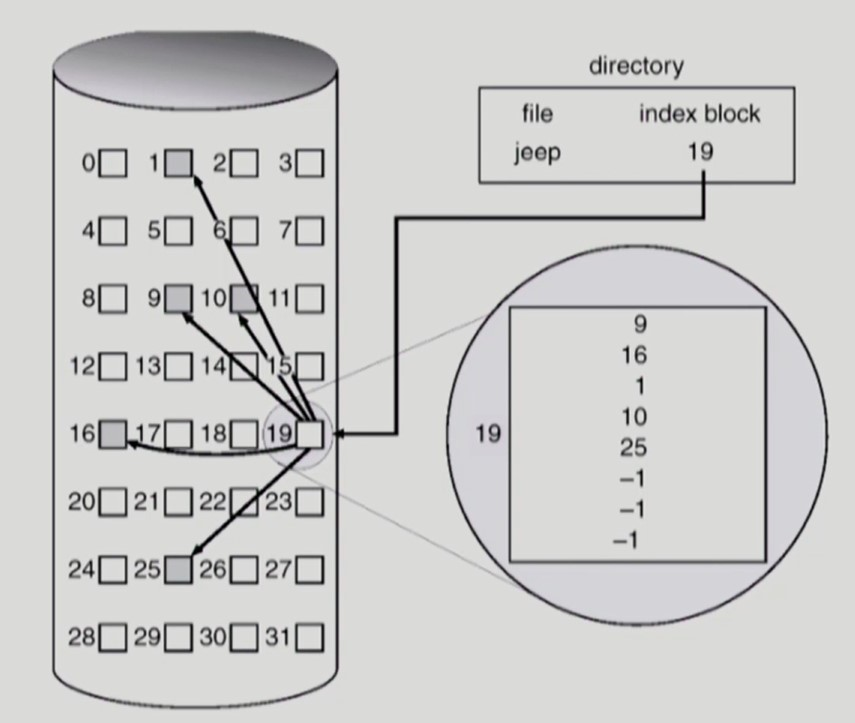
디렉토리는 파일 데이터의 인덱스 블록의 위치 정보를 갖고 있다.
UNIX 파일 시스템
-
Indexed Allocation 방식과 유사하다.
-
Boot block
- 부팅에 필요한 정보를 갖는다.
-
Super block
-
파일 시스템을 관리하기 위한 정보를 갖는다.
-
ex) Data block 의 범위, Inode list 의 범위 ...
-
-
Data block
- 실제 데이터가 저장되는 공간
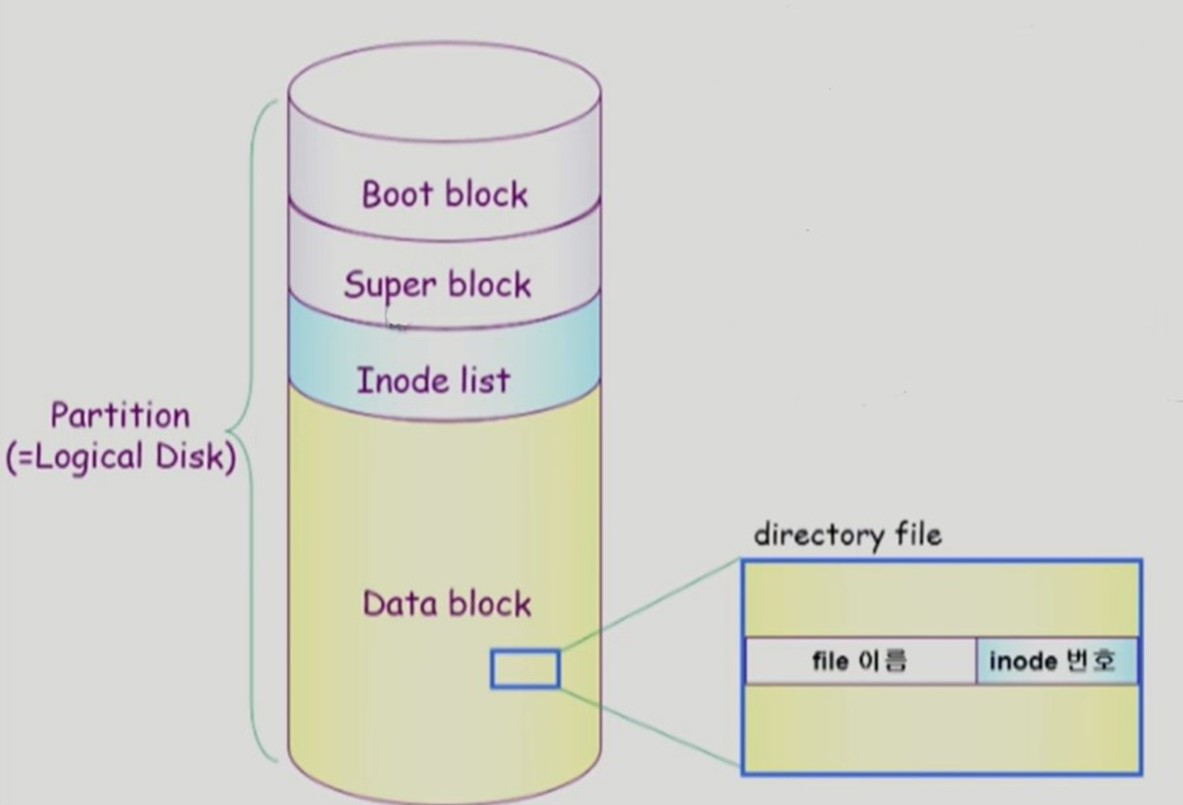
디렉토리 파일은 파일의 이름과 inode 번호 정보를 갖는다.
-
Inode list
- 파일이름을 제외한 파일의 모든 메타 데이터를 갖는다.
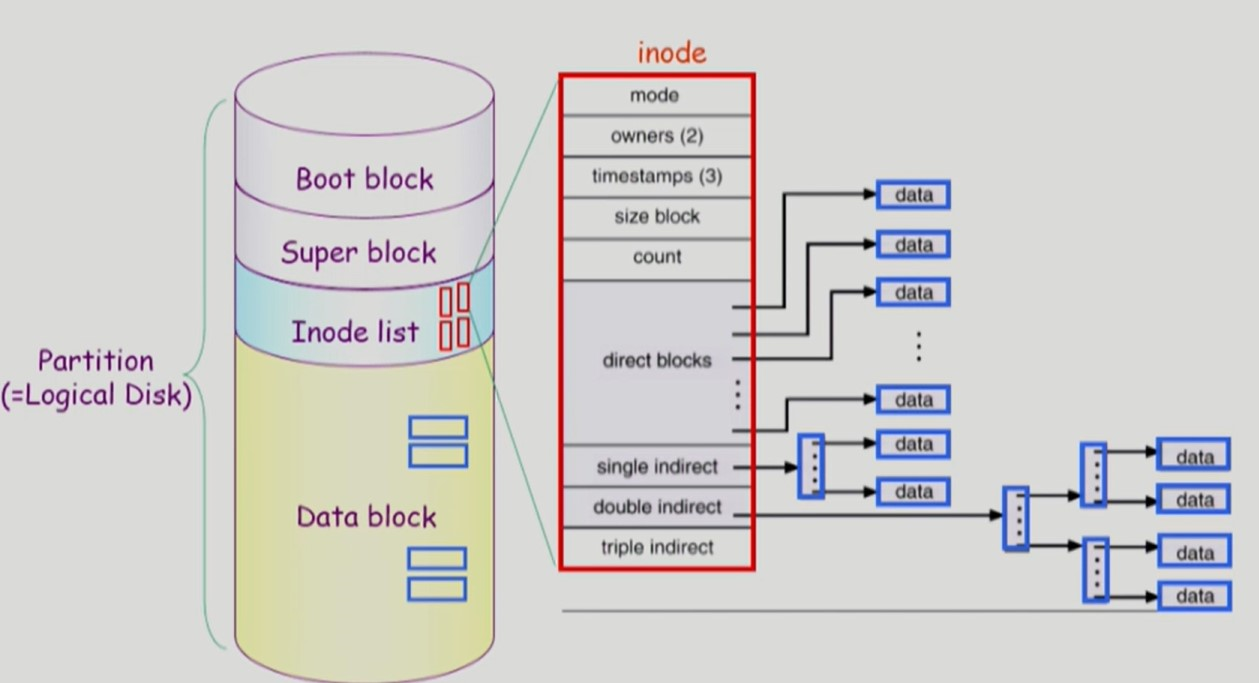
- 인덱스 블록이 필요없는 한 칸짜리 아주 작은 파일들은 direct blocks 영역에서
- 파일 데이터로 바로가는 포인터로 관리한다.
- 인덱스 블록이 1개면 되는 적당한 크기의 파일들은 single indirect 영역에서
- 파일 데이터의 인덱스 블록으로 가는 포인터로 관리한다.
- 인덱스 블록이 여러개 필요한 큰 파일들은 double indirect, triple indirect 영역에서
- 파일 데이터의 인덱스 블록의 인덱스 블록으로 가는 포인터로 관리한다.
FAT 파일 시스템
-
Linked Allocation 방식과 유사하다.
-
Boot block
- 부팅에 필요한 정보를 갖는다.
-
Data block
- 실제 데이터가 저장되는 공간
-
FAT
-
File Allocation Table
-
데이터 파일 조각의 다음 위치를 담아두는 테이블
-
Linked Allocation 방식에서의 포인터를 FAT 영역에서 따로 관리한다.
- Data block 의 특정 sector 가 유실되어도, FAT 에서 포인터를 관리하기 때문에 reliability 문제가 해결된다.
-
FAT은 중요한 정보이므로 여러 복제본을 만들어둔다.
-
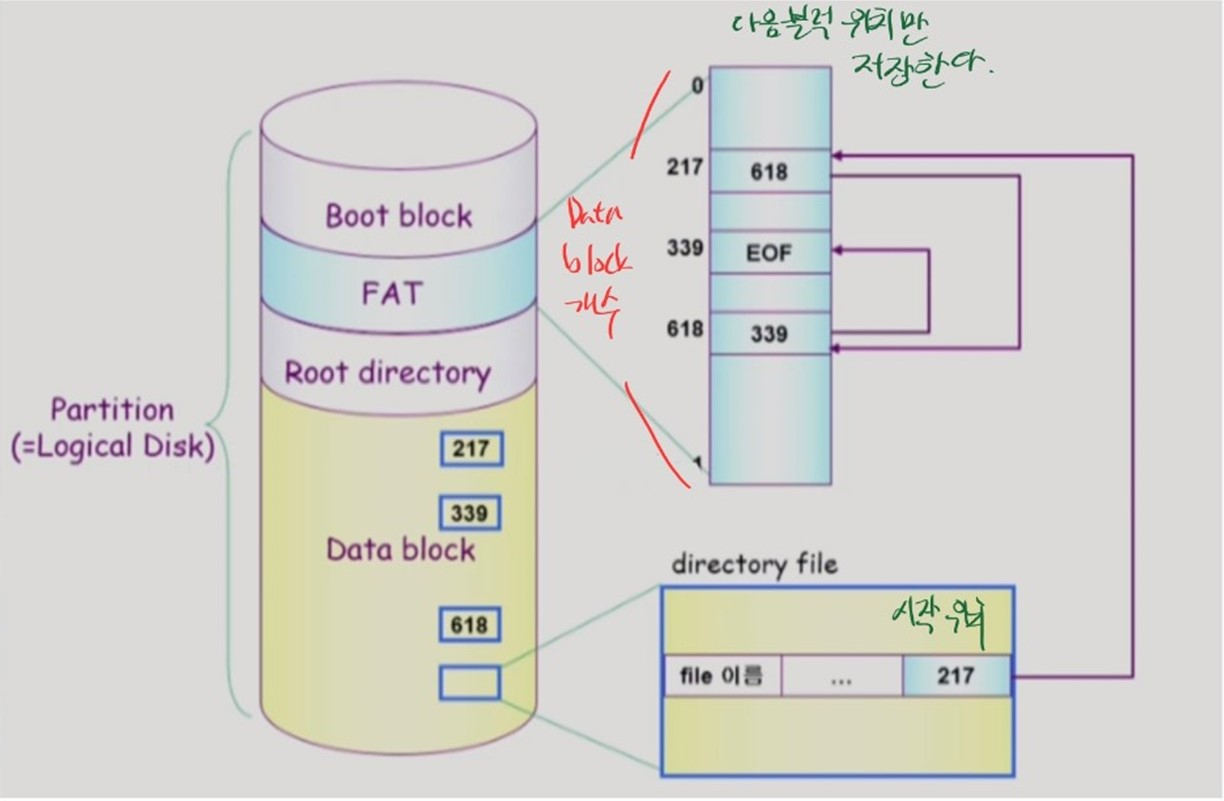
- 디렉토리 파일은 파일의 이름과 여러가지 메타 정보, 그리고 파일 데이터의 시작 인덱스를 갖는다.
- FAT은 작은 테이블이라 물리 메모리에 올려 캐싱할 수 있다.
- 따라서 파일 데이터의 특정 위치로도 빠르게 이동할 수 있다.
Page Cache & Buffer Cache
-
Page Cache
-
Paging System 에서 사용하는 물리 메모리의 page frame 들을 caching 관점에서 page cache 라 한다.
-
page fault 가 발생하지 않는다면 page cache 를 사용하는데 OS가 끼어들지 않는다.
- 따라서 LRU, LFU 교체 알고리즘은 사용할 수 없다.
-
-
Buffer Cache
-
파일을 조작하는 I/O 연산 (open, read .. ) 은 OS가 처리한다.
-
디스크에서 읽어온 파일 데이터는 물리 메모리의 OS 영역 안의 Buffer Cache 에 저장된다.
- 만약 Buffer Cache 에 존재하는 데이터를 재요청하면 Disk I/O 가 발생하지 않는다.
-
Buffer Cache 는 모든 프로세스가 공용으로 사용한다.
-
항상 OS가 담당한다.
- LRU, LFU 와 같은 교체 알고리즘을 사용할 수 있다.
-
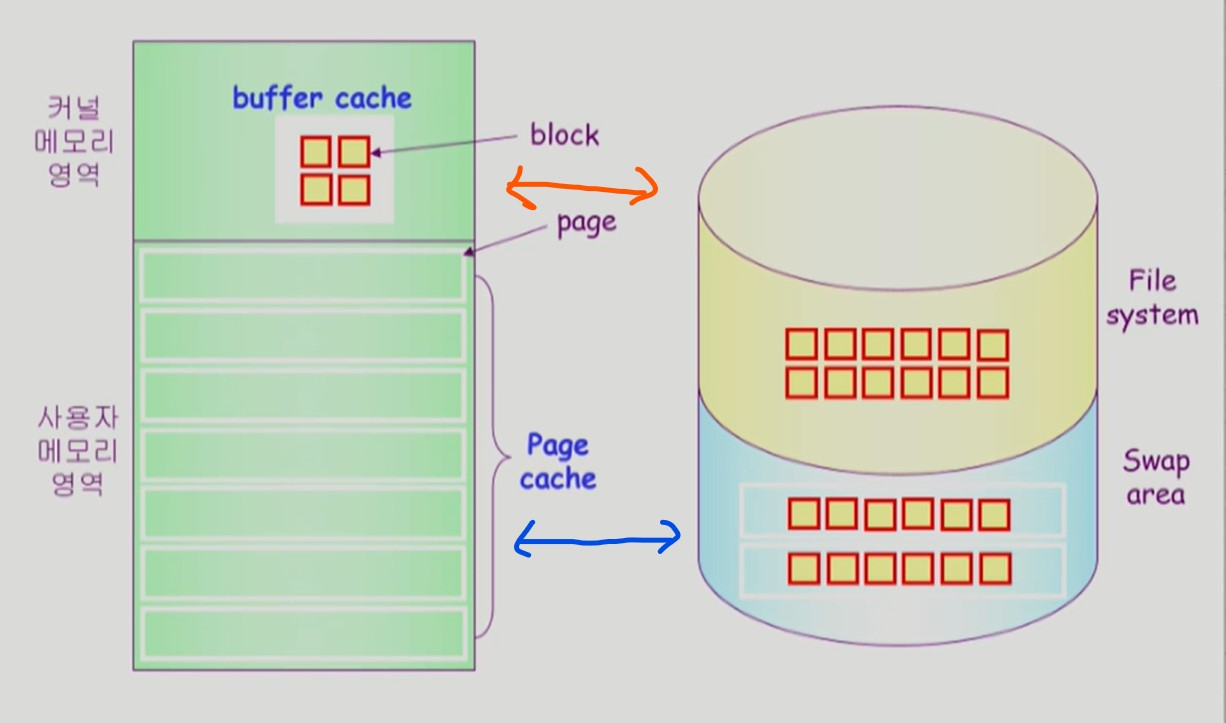
- 전통적인 방식에선 File System 의 파일 데이터 관련 작업은 반드시 OS 를 통해 buffer cache 를 거쳐야 하고
- Swap Area 의 swap out 된 프로세스 페이지들은 Page Cache (물리 메모리) 에 swap in 된 이후엔 OS를 거치지 않고 바로 접근할 수 있다.
-
Memory-Mapped I/O
-
파일의 일부를 페이지 단위로 프로세스의 가상 메모리에 올리는 것
-
가상 메모리에 올라간 파일 페이지에 대한 접근 · 조작 연산은 파일의 접근 · 조작 연산과 동일시된다.
-
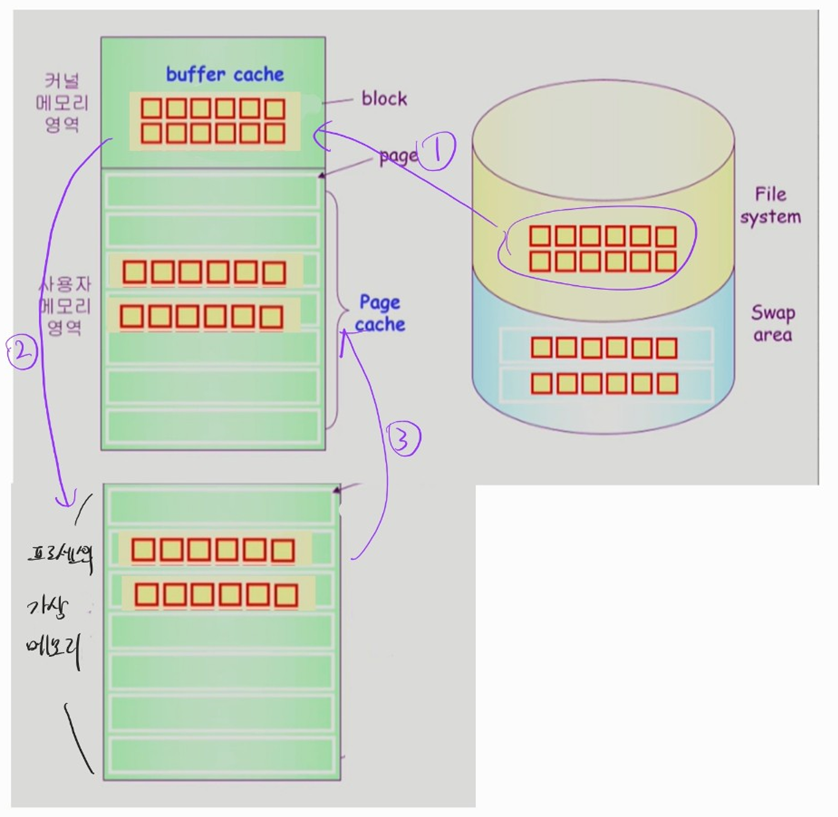
- 우선 파일 시스템에서 파일 데이터를 페이지 단위로 읽어와 buffer cache 에 저장한다.
- 그 다음, buffer cache 에 있는 파일 데이터 페이지를 특정 프로세스의 가상 메모리에 매핑한다.
- 매핑된 파일 데이터 페이지는 가상 메모리의 다른 페이지와 동일하게 관리된다.
- 물리 메모리 frame 에 올라간 파일 데이터 페이지를 접근 · 조작하는 것은 OS 없이 이루어진다.
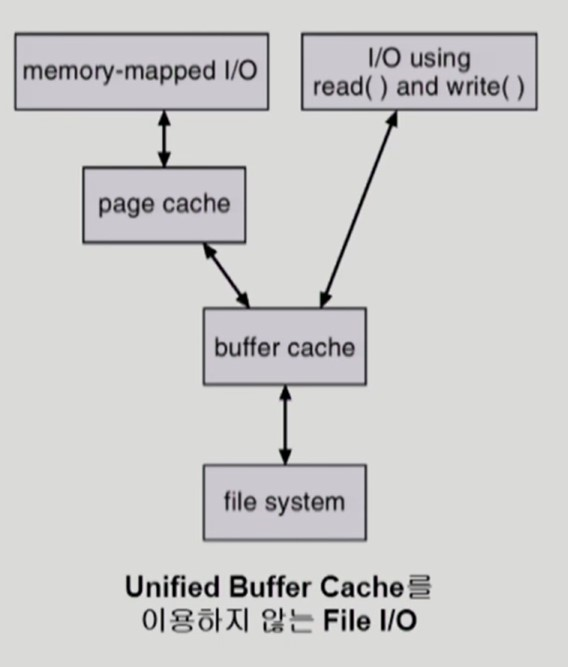
memory-mapped I/O 사용 여부에 따라 달라지는 File I/O 흐름도
-
Unified Buffer Cache
-
기존의 buffer cache 가 page cache 에 통합된 방식
-
page cache 만 사용한다.
-
최근의 OS에서 사용
-
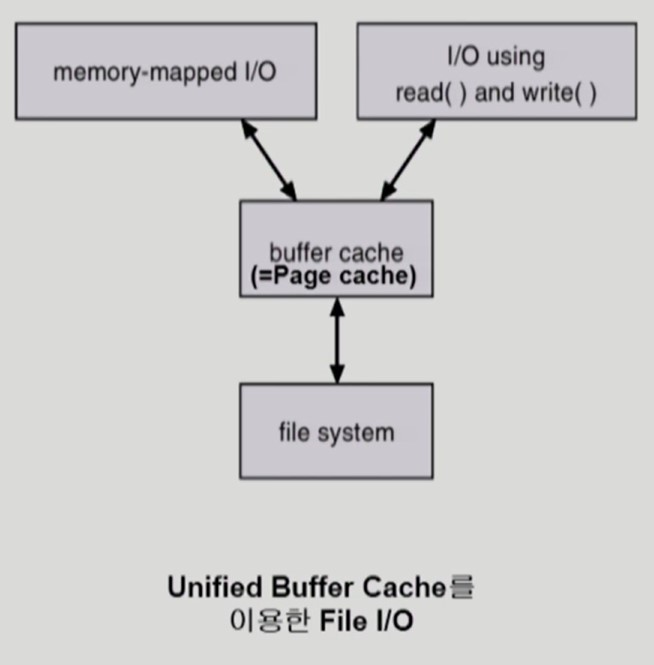
Unified Buffer Cache 방식에서 memory-mapped I/O 사용 여부에 따라 달라지는 File I/O 흐름도
Disk
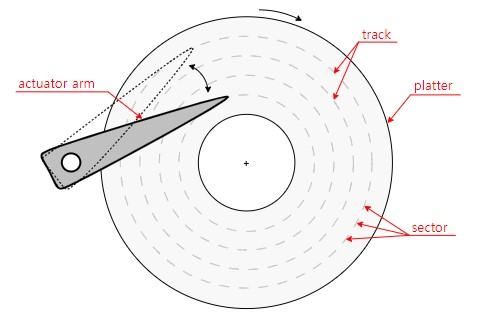
-
Disk 를 이루는 최소 단위는 sector 이다.
-
각 sector 는 header + 실제 data 저장공간 + trailer 로 이루어진다.
용어정리
-
physical formatting
- 디스크를 읽고 쓸 수 있는 sector 들로 나누는 과정
-
Logical formatting
-
파일 시스템을 만드는 과정
-
FAT, inode 등이 만들어진다.
-
-
Partitioning
- 디스크를 여러개의 논리적 디스크로 나누는 과정
-
Booting
-
시스템 전원이 꺼져도 휘발되지 않는 소량의 물리 메모리 공간인 ROM 에 있는 small bootstrap loader 를 실행한다.
-
loader 는 sector 0 의 bootblock 을 물리 메모리에 올린다.
- bootblock 에는 full bootstrap loader program 이 있다.
-
full bootstrap loader program 은 디스크에서 OS를 찾아 물리 메모리에 올린다.
-
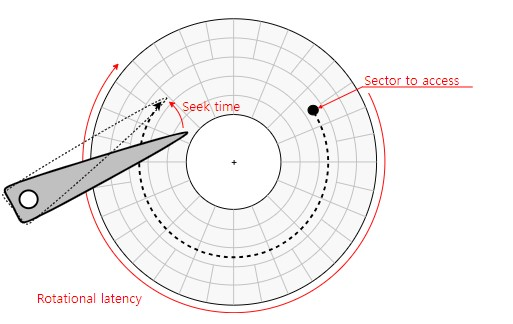
Access Time
-
Seek time
-
헤드를 특정 트랙으로 움직이는데 걸리는 시간
-
기계 장치가 직접 움직여야 하므로 시간이 많이 걸린다.
-
-
Rotational latency
- 헤드가 원하는 섹터에 도달하기까지 걸리는 회전지연시간
-
Transfer time
- (원하는 섹터에 도착하여) 실제 데이터를 전송하는 시간
Disk Scheduling Algorithm
단위시간 당 전송된 바이트 수 (Disk bandwidth) 를 늘리려면 seek time 을 최소화해야 한다.
- Disk Scheduling 의 목표는 seek time 을 줄이는 것, 즉 헤드의 이동거리를 줄이는 것이다.
-
FCFS
-
First Come First Service
-
queue 에 요청이 들어온 순서대로 헤드를 이동시킨다.
-
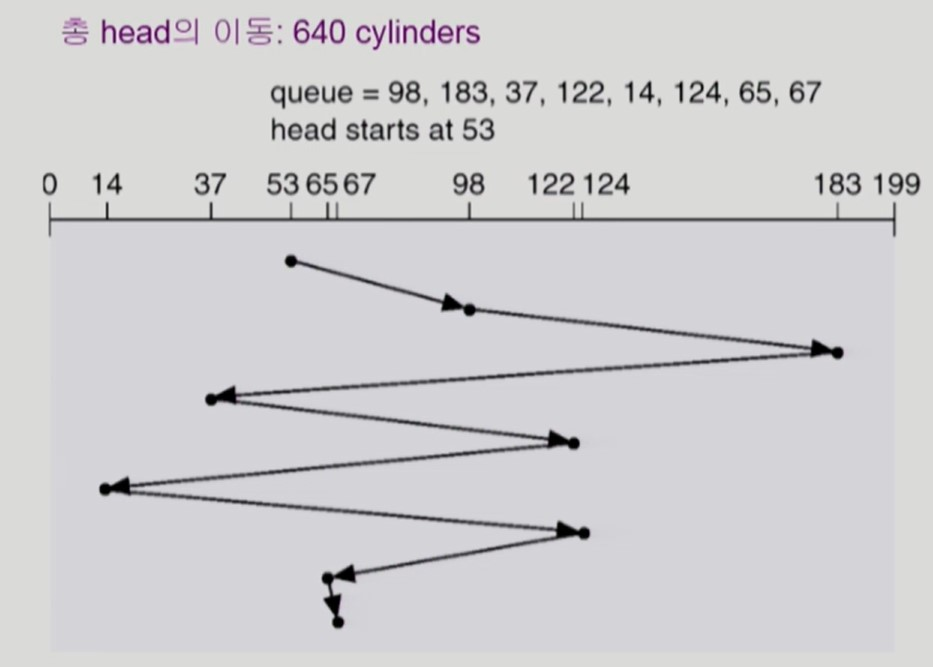
-
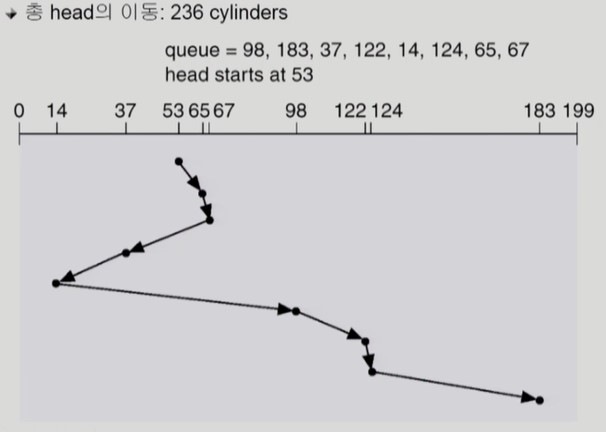
SSTF
-
Shortest Seek Time First
-
현재 헤드에서 가장 가까운 위치의 요청으로 헤드를 이동시킨다.
-
헤드의 이동거리는 줄지만 starvation 이 발생할 수 있다.
-
-
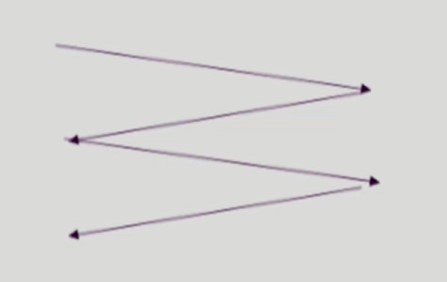
SCAN
-
헤드가 디스크의 한 쪽 끝에서 다른 쪽 끝으로 이동하며 가는 길목에 있는 모든 요청을 처리한다.
-
한 쪽 끝에 도달하면 역방향으로 이동하며 똑같은 동작을 반복한다.
-
헤드가 비효율적으로 왔다갔다하지 않으므로 이동거리가 짧아지고 starvation 도 발생하지 않는다.
-
가운데에 있는 트랙의 대기시간은 짧고, 가장자리에 잇는 트랙의 대기시간은 길어져 형평성 문제가 있다.
-
-
C-SCAN
-
헤드가 디스크의 한 쪽 끝에서 다른 쪽 끝으로 이동하며 가는 길목에 있는 모든 요청을 처리한다.
-
다른 쪽 끝에 도달했으면 요청을 처리하지 않고 다시 출발점으로 온다.
-
SCAN 대비 헤드의 이동거리는 더 길지만 트랙 위치와 상관없이 균일한 대기 시간을 제공한다.
-

-
LOOK, C-LOOK
-
SCAN 이나 C-SCAN 은 가장자리 위치의 요청이 있든 없든 헤드가 디스크 끝에서 끝으로 이동한다.
-
LOOK, C-LOOK 은 이를 개선하여 헤드 진행 방향에 더 이상 기다리는 요청이 없으면 헤드 이동방향을 즉시 반대로 돌린다.
-
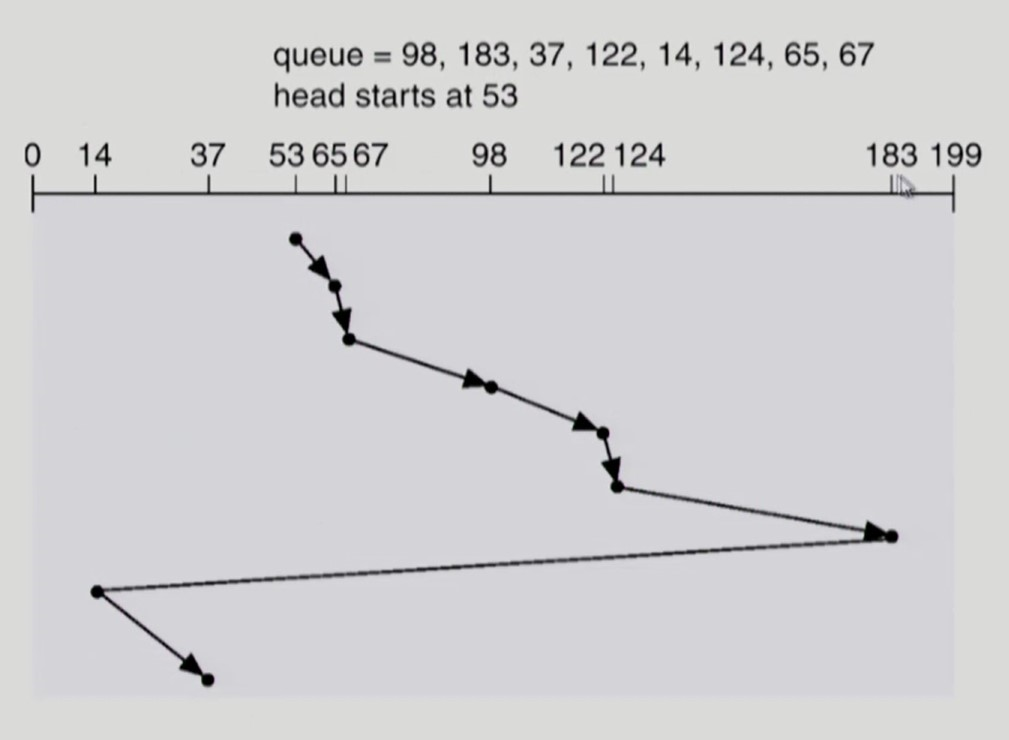
C-LOOK 방식
- 199까지 가지않고, 0으로 돌아가지 않는다.
- 183에서 14로 돌아간다.
출처
KOCW 운영체제 강의 (이화여자대학교 - 반효경 교수님)
http://www.kocw.net/home/cview.do?cid=3646706b4347ef09
프로세스 할당 시간 이미지 (Baeldung)
https://www.baeldung.com/cs/cpu-scheduling
valid/invalid bit 이미지 (junttang 님)
https://velog.io/@junttang/OS-2.6-MV-6-Multi-Level-Page-Tables
disk 이미지 (Andrei Gudkov 님)
https://gudok.xyz/sspar/
spin lock vs sleep lock (쉬운코드 님)
https://www.youtube.com/watch?v=gTkvX2Awj6g
