배열의 원소를 오름차순 또는 내림차순으로 정렬하는 다양한 알고리즘이 존재한다. 예를 들어
선택 정렬, 버블 정렬, 삽입 정렬, Merge Sort, Quick Sort, STL Sort 등등이 있는데 선택, 버블, 삽입 정렬은 시간 복잡도가 O(N^2)이라 배열의 길이가 큰 배열을 정렬할 때 비효율적이다. 그에 비해 Merge Sort, Quick Sort는 시간 복잡도가 O(NlogN)이다.
Merge Sort
- Merge Sort는 배열을 쪼개서 쪼개진 배열을 각각 정렬한 뒤 정렬된 두 배열을 합치는 정렬 알고리즘이다.
- Merge Sort는 대표적인 분할 정복(Divide and Conquer) 알고리즘으로, 길이가 N인 배열을 길이가 1이 될때까지 계속해서 쪼개나간다. 길이가 1인 배열은 정렬됨이 자명하기 때문에 길이가 1인 배열을 합쳐 길이가 2인 정렬된 배열을 만들고, 길이가 2인 정렬된 배열을 합쳐 길이가 4인 정렬된 배열을 만든다. 이러한 과정을 반복하면 길이가 N인 정렬된 배열을 만들 수 있다.

- Merge Sort가 진행되는 과정을 보여주는 그림이다.
- 배열의 길이 N = 2^k라고 가정하면, 배열을 나누는 과정은 1+2+2^2+....+2^k = 2*2^K - 1 = 2N - 1이므로 시간 복잡도는 O(N)이다. 배열을 합치는 과정의 시간 복잡도는 총 k개의 줄, 각 줄마다 N번씩 연산하므로 O(KN)이다. logN = k이므로 시간 복잡도는 O(NlogN)이다. O(N)보다 O(NlogN)이 더 크므로 최종 시간 복잡도는 O(NlogN)이 된다.
Merge Sort 구현
아래 코드는 재귀를 이용해서 Merge Sort를 구현한 것이다.
void merge(int st, int en) {
int mid = (st + en) / 2;
int lidx = st; // 왼쪽 배열의 시작 인덱스
int ridx = mid; // 오른쪽 배열의 시작 인덱스
for (int i = st; i < en; i++) {
if (lidx == mid) tmp[i] = arr[ridx++]; // 왼쪽 배열의 병합이 끝나서 오른쪽 배열만 남은 경우
else if (ridx == en) tmp[i] = arr[lidx++]; // 오른쪽 배열의 병합이 끝나서 왼쪽 배열만 남은 경우
else if (arr[lidx] <= arr[ridx]) tmp[i] = arr[lidx++]; // 왼쪽 배열 선택(stable sort)
else tmp[i] = arr[ridx++];
}
for (int i = st; i < en; i++)
arr[i] = tmp[i];
}
void merge_sort(int st, int en) { // [st,en) 구간으로 배열을 나눔
if (en == st + 1) return; // 배열의 길이가 1이면 반환, 배열의 길이가 1이면 정렬되어있음이 자명하다
int mid = (st + en) / 2;
merge_sort(st, mid);
merge_sort(mid, en);
merge(st, en);
}- 배열의 길이가 1이 될 때까지 merge_sort()를 재귀적으로 호출하고 merge()를 통해 두 배열을 합쳐준다.
- 합치는 과정에서는 각 배열의 맨 앞 원소를 가리키는 변수 혹은 포인터를 2개 둔다. 이때 두 배열은 이미 정렬되어 있으므로 각 배열의 맨 앞 원소가 가장 크기가 작은 원소임이 자명하다.
- 두 값을 비교하여 더 작은 값을 선택해 임시 배열에 저장하는 과정을 반복하고, 모든 과정이 끝나면 임시 배열의 값을 실제 배열에 옮겨준다.
Quick Sort
- Quick Sort도 Merge Sort와 같이 시간 복잡도가 O(NlogN)인 정렬 알고리즘이다.
- Quick Sort의 장점은 Merge Sort와 달리 추가적인 임시 배열을 선언하지 않아도 되서(In-place) cache hit rate가 높아서 속도가 빠르다.
- 단점은 최악의 경우 O(N^2)의 시간 복잡도를 가진다는 점이다.
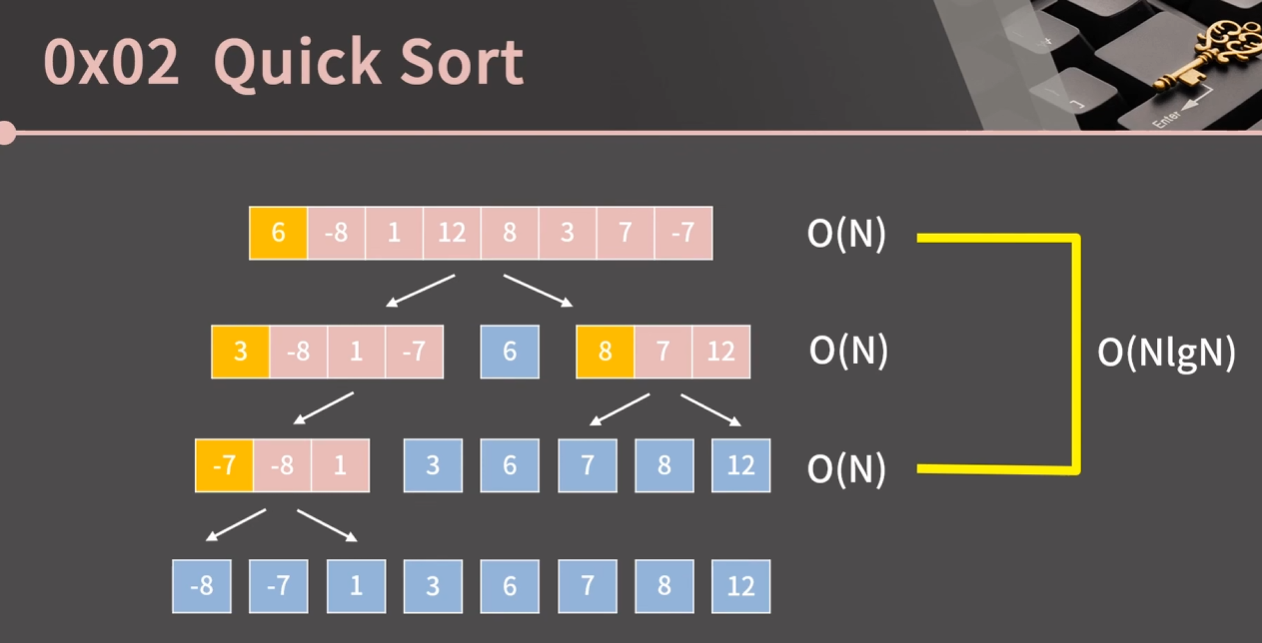
- pivot을 제자리로 보내는 시간 복잡도는 O(N)이고, 배열의 길이 N = 2^k인 경우 O(N)의 연산을 k번 반복해야 하므로 전체 시간 복잡도는 O(KN) = O(NlogN)이다.
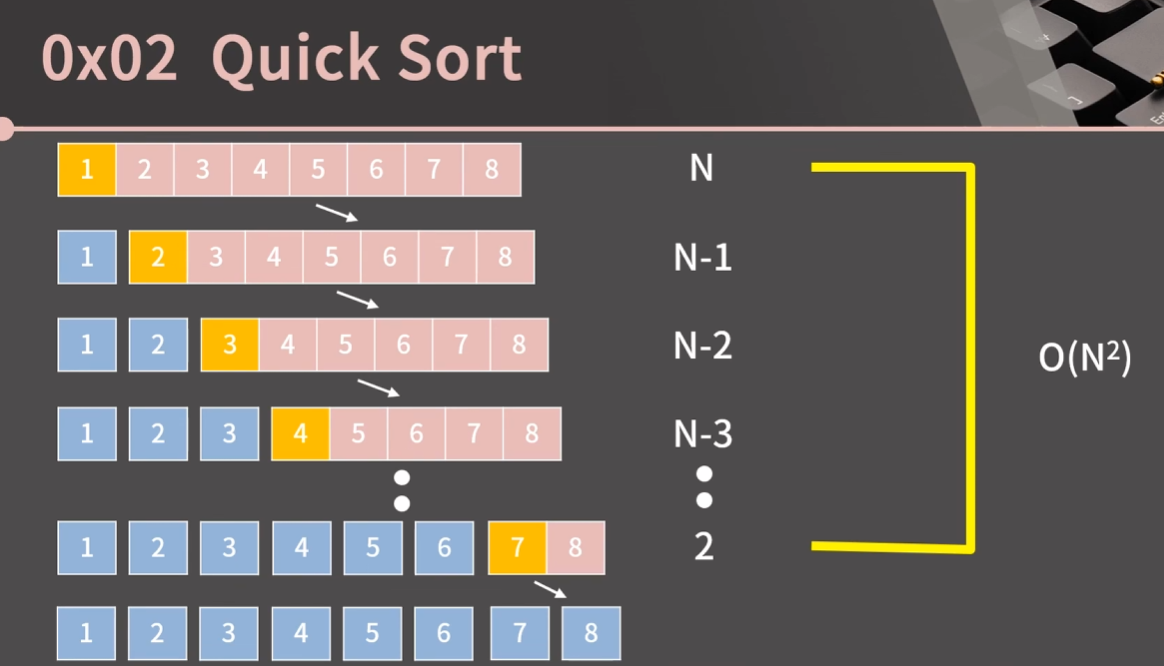
- pivot이 최대 혹은 최소 값으로만 잡힌다면 시간 복잡도가 O(N^2)이 나올 수 있다.
Quick Sort 구현
- pivot을 하나 선정하고 배열 양쪽 끝에서 시작하는 포인터를 2개 선언한다. 왼쪽 끝 포인터(l)는 pivot보다 큰 값을 만나는 순간 멈추고, 오른쪽 끝 포인터(r)는 pivot보다 작은 값을 만나는 순간 멈춘다.
- 두 포인터가 멈추면 두 값을 바꿔주고 다시 진행한다. 두 값을 바꿔주는 이유는 pivot보다 작은 값이 비교적 오른쪽, pivot보다 큰 값이 비교적 왼쪽에 있는게 모순이기 때문이다.
- 두 포인터가 교차하게 되면 pivot과 오른쪽 끝 포인터(r)를 바꾸고 알고리즘을 종료한다.
void quick_sort(int st, int en) {
if (en <= st + 1) return; // 배열의 길이가 1이하
int pivot = arr[st];
int l = st + 1;
int r = en - 1;
while (true) {
while (l <= r && arr[l] <= pivot) l++; // pivot보다 큰 값을 만날때 까지 전진
while (r >= l && arr[r] >= pivot) r--; // pivot보다 작은 값을 만날때 까지 후진
if (r < l) break;
swap(arr[l], arr[r]); // 두 값 교환
}
swap(arr[st], arr[r]); // pivot을 제자리로 보냄
quick_sort(st, r);
quick_sort(r + 1, en);
}- pivot을 제자리로 보내면 pivot을 기준으로 배열을 2개로 나눠서 각각 quick_sort를 재귀적으로 진행한다.
Merge Sort vs Quick Sort
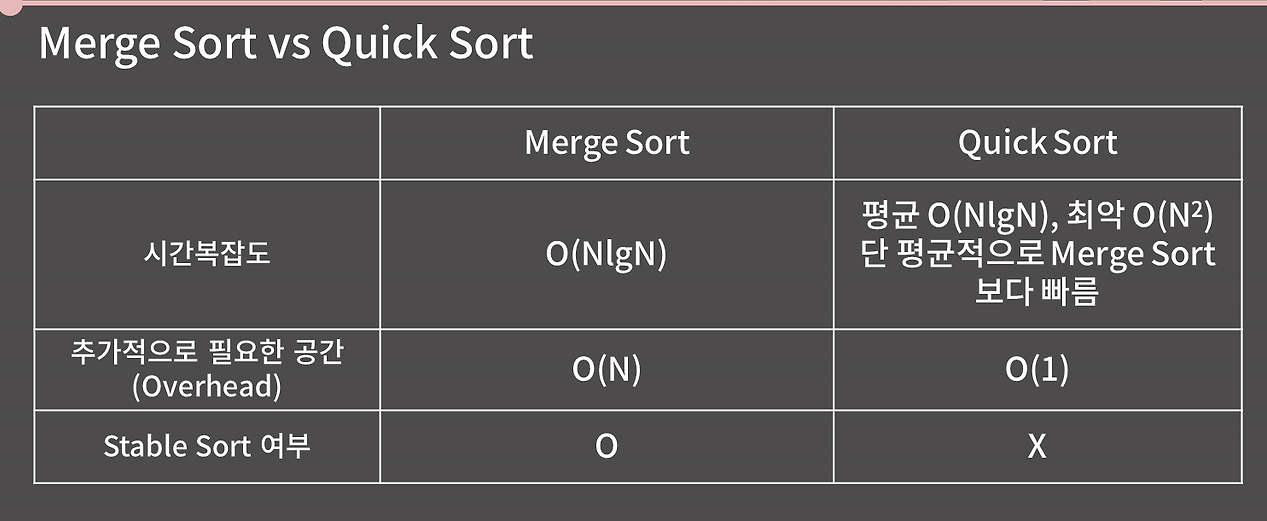
- Quick Sort는 Merge Sort에 비해 추가적으로 필요한 공간, 즉 메모리 복잡도가 낮아 더 빠른 속도로 정렬할 수 있다.
- Quick Sort는 최악의 경우 O(N^2)의 시간 복잡도를 가지기 때문에 주의해야 한다. 코딩 테스트에서는 Quick Sort를 구현하는 것을 지양하자.
