확률론 맛보기
중요개념
- 확률분포
- 조건부확률
- 기댓값
- 몬테카를로 샘플링
목표
데이터의 초상화로서 확률분포가 가지는 의미와 이에 따라 분류될 수 있는 이산확률변수, 연속확률변수의 차이점에 대해 공부합시다.
권고사항
확률변수, 조건부확률, 기댓값 등은 확률론의 매우 기초적인 내용이며 이를 정확히 이해해야 통계학을 잘 공부할 수 있습니다. 기댓값을 계산하는 방법, 특히 확률분포를 모를 때 몬테카를로 방법을 통해 기댓값을 계산하는 방법 등은 머신러닝에서 매우 빈번하게 사용되므로 충분히 공부합시다.
※ 고민합시다!
몬테카를로 방법을 활용하여 원주율에 대한 근삿값을 어떻게 구할 수 있을까요?
딥러닝에서 확률론이 필요한 이유
- 딥러닝은 확률론 기반의 기계학습 이론에 바탕을 두고 있습니다.
- 기계학습에서 사용되는 손실함수(loss function)들의 작동 원리는 데이터 공간을 통계적으로 해석해서 유도하게 됩니다.
- 예측이 틀릴 위험(risk)을 최소화하도록 데이터를 학습하는 원리는 통계적 기계학습의 기본 원리이다.
- 회귀 분석에서 손실함수로 사용되는 L2-노름은 예측오차의 분산을 가장 최소화하는 방향으로 학습하도록 유도합니다.
- 분류 문제에서 사용되는 교차 엔트로피(cross-entropy)는 모델 예측의 불확실성을 최소화하는 방향으로 학습하도록 유도합니다.
- 분산 및 불확실성을 최소화하기 위해서는 측정하는 방법을 알아야 합니다.
- 두 대상을 측정하는 방법을 통계학에서 제공하기 때문에 기계학습을 이해하려면 확률론의 기본 개념을 알아야 합니다.
확률 분포 & 확률 변수
- 확률분포는 데이터의 초상화라고 말할 수 있다.
- 데이터 공간에서 데이터를 추출하는 분포이다.
- 데이터만 가지고 확률분포를 아는 것은 불가능하기 때문에 기계학습 모형을 가지고 확률분포를 추론한다.
- 정답 레이블을 가진 지도학습을 예시로 들 때
- 데이터 공간을 x * y라 표기하고 D는 데이터공간에서 데이터를 추출하는 분포입니다.
- 데이터는 확률변수로 (x,y) ~ D라 표기합니다.
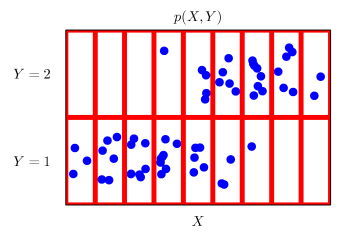
- 확률변수는 확률분포 D에 따라 이산형(discrete)과 연속형(continuous) 확률변수로 구분하게 됩니다.
- 이산형 혹은 연속형을 구분하는 것은 데이터 공간이 아니라 확률 분포의 종류에 따라 구분하게 됩니다.
- 이산형 확률변수는 확률변수가 가질 수 있는 경우의 수를 모두 고려하여 확률을 더해서 모델링합니다.
- 확률변수가 x값을 가질 확률로 해석할 수 있다.
- 연속형 확률변수는 데이터 공간에 정의된 확률변수의 밀도(density) 위에서의 적분을 통해 모델링한다.
- 밀도는 누적확률분포의 변화율을 모델링하기 때문에 확률로 해석해서는 안된다.
- 결합분포 P(x,y)는 D를 모델링합니다.
- D는 이론적으로 존재하는 확률분포이기 때문에 사전에 알 수 없습니다.
- P(x)는 입력 x에 대한 주변확률분포로 y에 대한 정보를 주지 않습니다.
- 주변확률분포는 결합분포에서 유도할 수 있습니다.
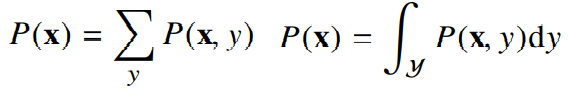
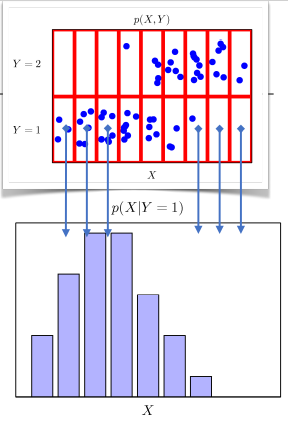
- 조건부확률분포 P(x|y)는 데이터 공간에서 입력 x와 출력 y 사이의 관계를 모델링합니다.
- P(x|y)는 특정 클래스가 주어진 조건에서 데이터의 확률분포를 보여줍니다.
- 조건부 확률 P(y|x)는 입력변수 x에 대해 정답이 y일 확률을 의미합니다.
- 연속확률분포의 경우 P(y|x)는 확률이 아니고 밀도로 해석한다.
조건부 확률
- 로지스틱 회귀에서 사용했던 선형모델과 소프트맥스 함수의 결합은 데이터에서 추출된 패턴을 기반으로 확률을 해석하는데 사용됩니다.
- 분류 문제에서 softmax(W*Phi+b)은 데이터 x로부터 추출된 특징패턴 Phi(x)과 가중치행렬 W을 통해 조건부확률 P(y|x)을 계산합니다.
- 회귀 문제의 경우 조건부기대값 E[y|x]를 추정합니다.
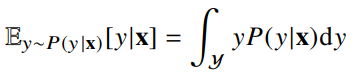
- 딥러닝은 다층신경망을 사용하여 데이터로부터 특징패턴을 추출합니다.
- 특징패턴을 학습하기 위해 어떤 손실함수를 사용할지는 기계학습 문제와 모델에 의해 결정된다.
기대값
- 확률분포가 주어지면 데이터를 분석하는데 사용 가능한 여러 종류의 통계적 범함수(statistical functional)를 계산할 수 있습니다.
- 기대값(expectation)은 데이터를 대표하는 통계량이면서 동시에 확률분포를 통해 다른 통계적 범함수를 계산하는데 사용됩니다.
- 기대값을 이용해 분산, 첨도, 공분산 등 여러 통계량을 계산할 수 있습니다.
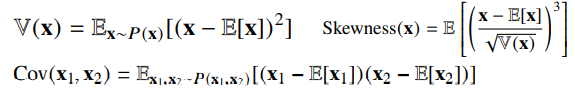
몬테카를로 샘플링
- 기계학습의 많은 문제들은 확률분포를 명시적으로 모를 때가 대부분이다.
- 확률분포를 모를 때 데이터를 이용하여 기대값을 계산하려면 몬테카를로(Monte Carlo) 샘플링 방법을 사용해야 한다.
- 몬테카를로는 이산형이든 연속형이든 상관없이 성립한다.
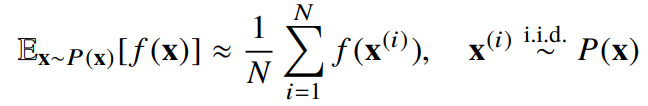
- 몬테카를로 샘플링은 독립추출만 보장된다면 대수의 법칙(law of large number)에 의해 수렴성을 보장한다.

꿈이 큰 새싹 개발자입니다.