ResNet(Residual Network)
딥러닝의 기초는 신경망으로 구성되어 있습니다.
신경망은 뉴런으로 구성되어 있으며, 각 뉴런은 입력값을 받아 가중치와 편향을 적용한 후, 활성화 함수를 통해 출력을 계산합니다.
이러한 뉴런들이 여러 층으로 구성되면 Multi Layer Perceptron, MLP라고 부릅니다.
다층 퍼셉트론이 발전하여 다층 신경망이 되고,
더 깊은(층이 더 많은) 다층 신경망이 될수록, 더 복잡한 과제를 수행할 수 있습니다.
딥러닝 연구가 지속되면서 더 깊은 네트워크가 오히려 성능이 떨어지는 문제를 발견하게 됩니다.
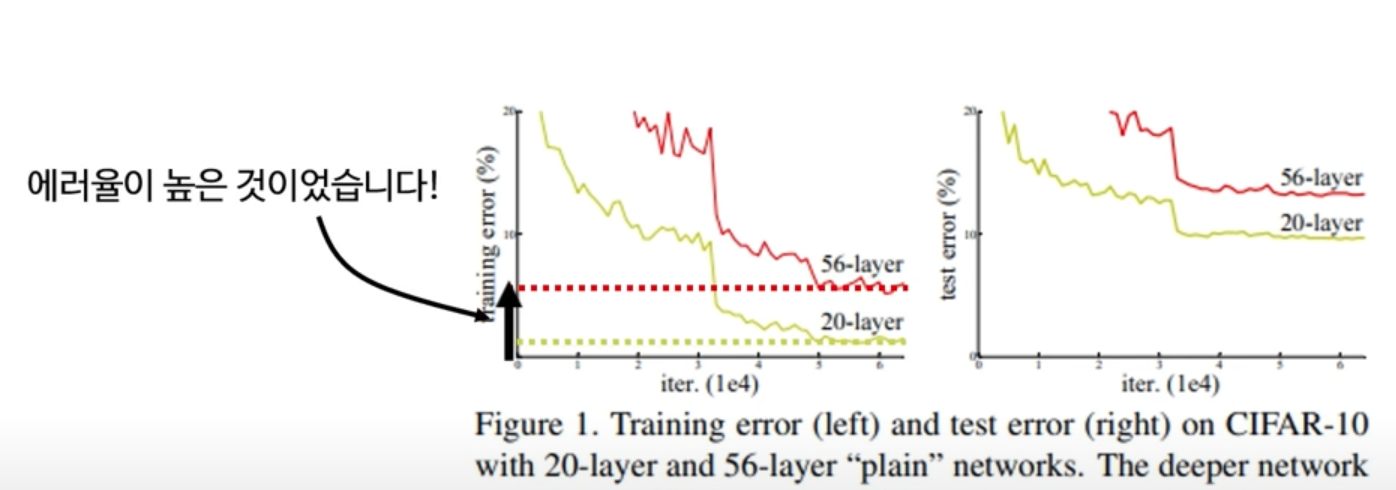
-> 이러한 깊은 모델의 성능 저하 degradation 문제는 여러 복합적인 요소들의 상호작용으로 발생합니다.
그 중 중요한 문제 중 하나인 기울기 소실 현상
Vanishing Gradient
을 살펴보겠습니다.
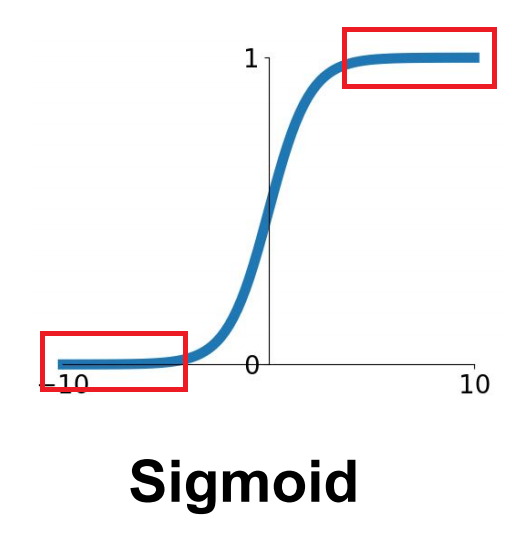
기울기 소실 현상은 주로 sigmoid나 tanh 계열의 active function을 쓸 때 나타나는 현상입니다.
Sigmoid 계열의 활성화 함수는 그 특성상 네트워크의 층이 깊을수록 출력값이 양극단(0 or 1)로 가는 경향이 있습니다
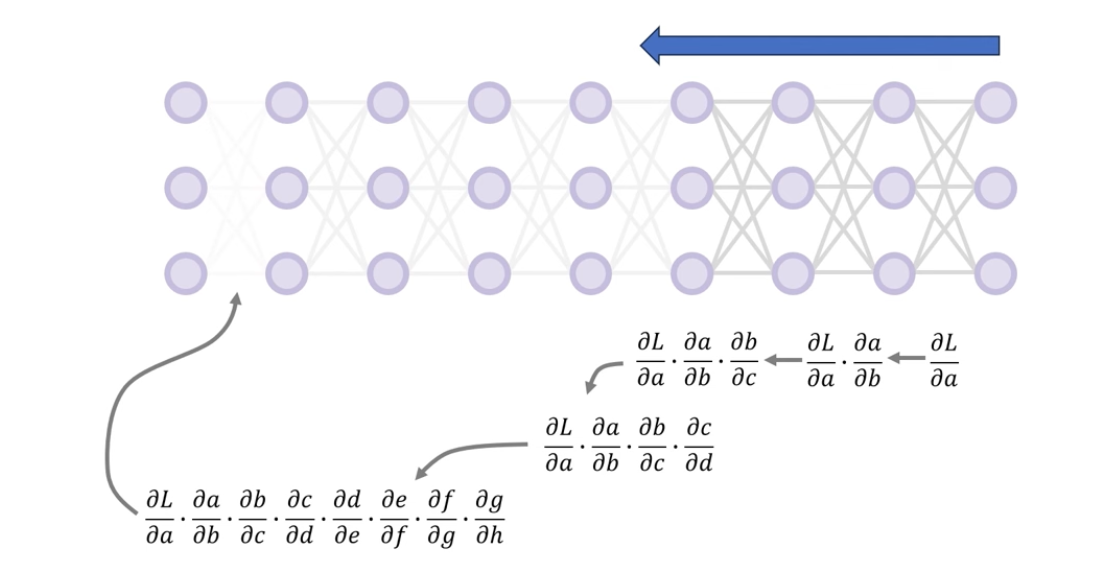
오차로 시작된 역전파의 gradient가 초기층으로 내려갈수록 체인룰에 의해 곱해져야할 항들이 점점 많아지게 되고, 층이 깊어질수록 초기층에 가까운 가중치들의 기울기가 거의 0에 가까워지는 현상이 발생하게 됩니다.
그러면 어떻게 해결할 수 있을까요?
Skip Connection & Residual Connection
| 용어 | 의미 | 특징 |
|---|---|---|
| Skip Connection | 입력을 다음 층으로 건너뛰어 전달 | 학습 안정화 목적, 구조적 연결 강조 |
| Residual Connection | Skip Connection을 이용해 잔차를 학습 | "잔차 학습" 목적, 수학적 의미 강조 |
Skip Connection 은 입력 데이터를 합성곱 계층을 건너뛰어 출력에 바로 더하는 구조를 말합니다.
다시 말해, 입력 데이터를 그대로 흘리는 기법으로, 역전파 때도 상류의 기울기를 그대로 하류로 보냅니다. 여기에서 핵심은 상류의 기울기에 아무런 수정을 하지 않고 그대로 보낸다는 것이죠.
이로 인해 기울기가 작아지거나 지나치게 커질 걱정 없이 앞 층에 '의미 있는 기울기'가 전해지리라 기대할 수 있습니다. 층을 깊게 할수록 기울기가 작아지는 vanishing gredient 문제를 skip connection이 줄여줍니다.
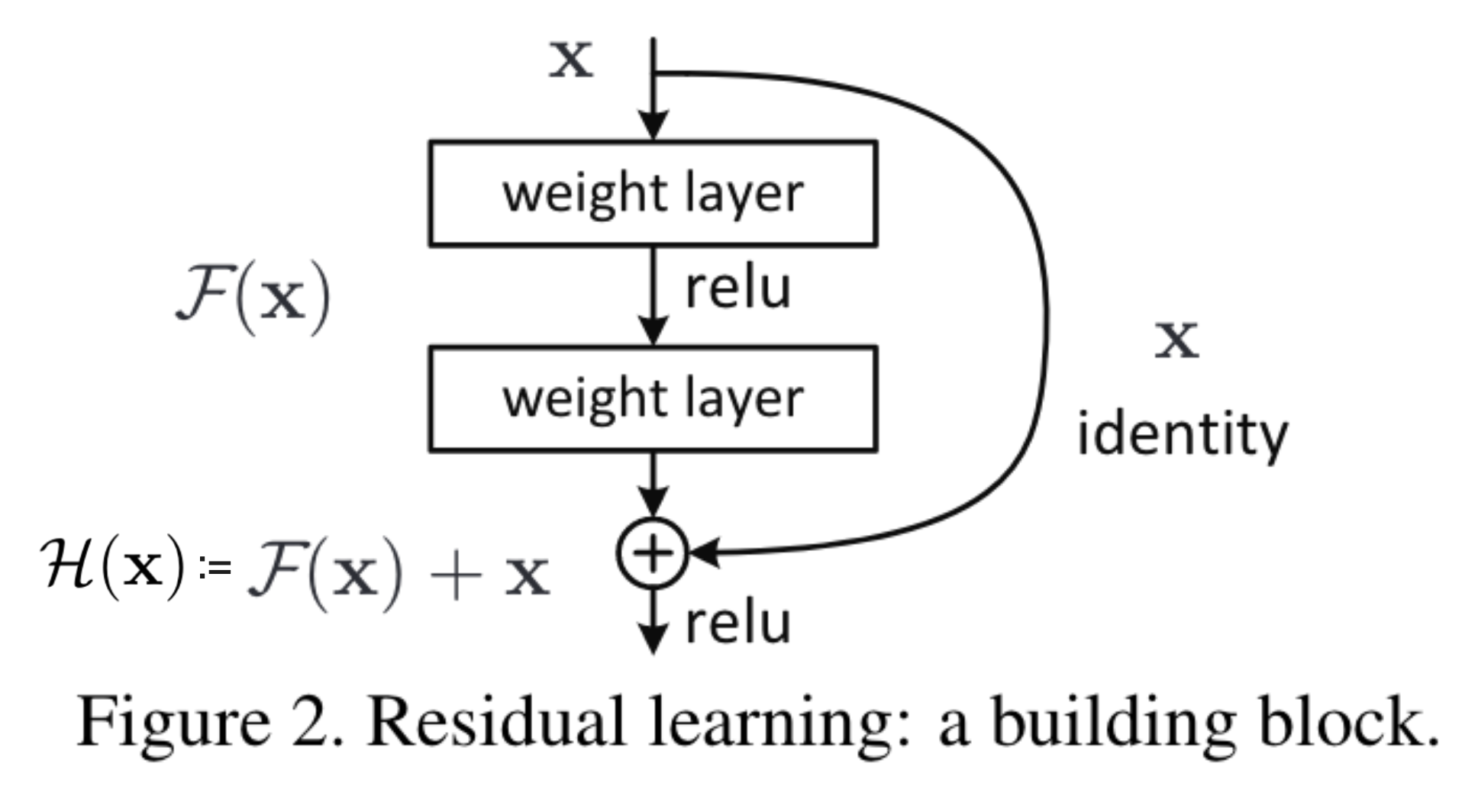
ResNet을 사용하면 레이어의 인풋이 다른 레이어로 곧바로 건너 뛰어 버립니다.(skip connection) 즉, 인풋 값들이 중간의 특정 레이어들을 모두 거치지 않고 한번에 건너 뛴다는 의미입니다. 이를 그림으로 나타내면 다음과 같습니다.
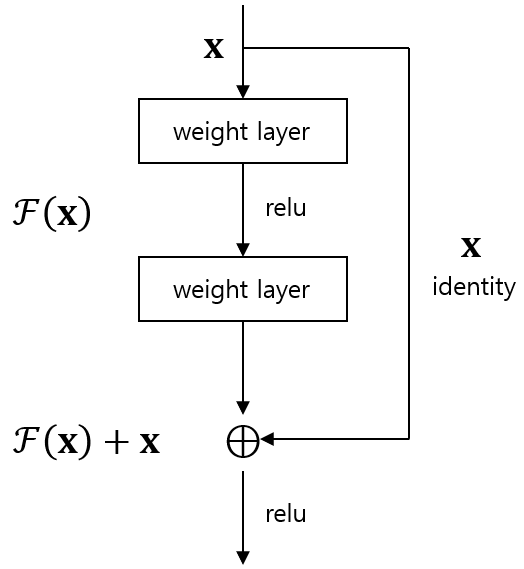
신경망의 입력값은 x인데 이 입력값 x가 가중치 레이어를 거쳐서 만들어지는 값이 F(x)입니다. 그리고 오른쪽을보면 그냥 입력값 x자체가 레이어를 거치지 않고 그대로 건너 뛰는데 이를 identity mapping이라고 합니다. identity mapping은 입력값과 출력값이 같은 매핑을 의미합니다. identity mapping은 skip connection 또는 identity shortcut connection이라고도 부릅니다. 따라서 x라는 입력값이 신경망을 거치고 난 결과는 가중치를 거친 값 F(x)와 identity mapping을 거쳐 만들어진 x 더한 F(x)+x가 됩니다.(residual connection) 따라서 최종 출력값이 y라고 하면 y는 다음과 같이 쓸 수 있습니다.
y = F(x)+x이것이 가장 간단한 형태의 ResNet입니다.
ResNet은 VGG신경망을 기반으로 skip connection을 도입하여 층을 깊게 했습니다.
VGG신경망 ResNet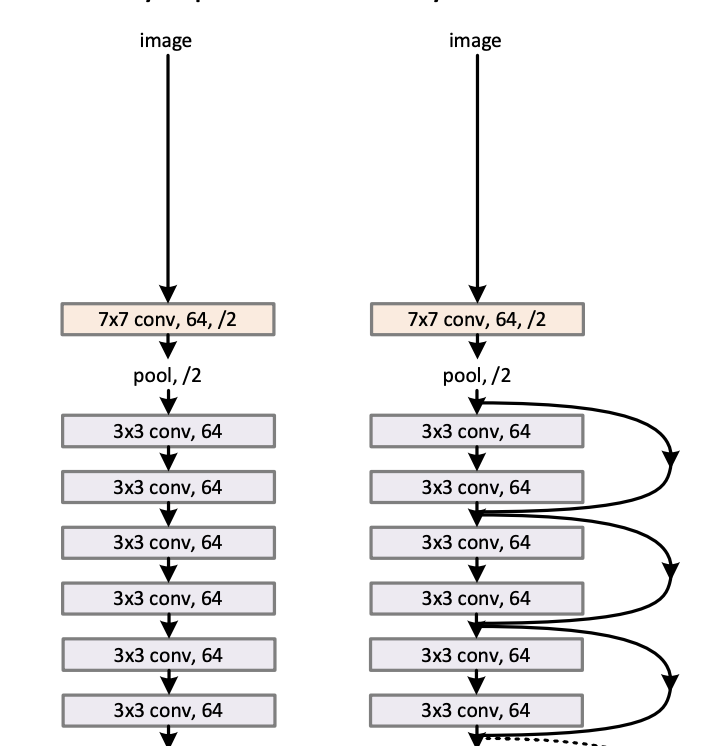
위의 그림과 같이 ResNet은 합성곱 계층을 2개 층마다 건너뛰면서 층을 깊게 합니다. 실험 결과 150층 이상으로 해도 정확도가 오르는 결과를 확인할 수 있습니다. (밑바닥부터 배우는 딥러닝 1권 p.273)
📌 VGG신경망
VGG는 3×3 컨볼루션을 반복해서 이미지를 처리하는 CNN
특징: 구조 단순, 깊게 쌓으면 성능이 좋아짐
문제: 너무 깊게 쌓으면 학습이 어려워지고 성능이 떨어짐ResNet은 VGG 같은 CNN 구조를 그대로 사용하면서, skip connection(지름길 연결)을 추가함.
즉, 입력이 다음 층으로 바로 전달되도록 통로를 만들어
모델이 깊어져도 기본 신호가 사라지지 않고, 필요한 변화(잔차)만 학습하게 만든 것
📌 전이학습
이미 학습된 모델의 가중치(weights) 일부 또는 전체를 새로운 모델로 옮김
옮긴 상태에서 새로운 데이터셋에 대해 재학습(fine-tuning) 수행
목표: 이미 학습된 지식을 활용하여 새로운 문제를 더 빠르고 정확하게 학습예시:
VGG나 ResNet 모델이 ImageNet 데이터셋으로 학습되어 있다면
이를 가져와 자체 데이터셋(예: 의료 이미지, 소규모 동물 사진)에 맞게 조금만 학습⁉️ 왜 데이터셋이 적을 때 유용한가?
학습 데이터가 적으면 처음부터 모델을 학습시키기 어렵습니다!
이유: 딥러닝 모델은 수백만~수천만 개의 파라미터가 있어, 충분한 데이터 없이는 과적합(overfitting)이 쉽게 발생하는데전이학습을 하면
-> 모델이 이미 일반적인 특징(feature)을 학습한 상태
예: 에지, 색상, 모양 등새로운 데이터셋에서 미세한 조정(fine-tuning)만 하면 되므로
1) 학습 속도가 빠름
2) 데이터가 적어도 어느 정도 성능 확보 가능
즉, 적은 데이터 + 이미 학습된 모델 → 빠르고 안정적인 학습 가능
