https://youtu.be/lDqn1UNwgrY?si=1FeARzHHabdo__kk
해당 포스트는 신박Ai youtube [Deep Learning 101] 합성곱신경망 CNN, Convolutional Neural Network 강의를 보고 정리하였습니다.
CNN이란?
Convolutional Neural Network. 이미지 처리와 패턴 인식에 탁월한 성능을 보여주는 신경망입니다.
image는 pixel로 이루어져있고, 각가의 픽셀은 각각의 rgb값을 가진 데이터입니다.
CNN은 이런 이미지 데이터의 공간적 특징을 추출하여 학습하고, 패턴을 추출해낼 수 있게 됩니다. 그러면 이렇게 다양한 패턴들과 비교해서 비슷한 패턴이 무엇인지 알아낼 수 있겠죠?

CNN 구조
Convolutional Layer(합성곱층)
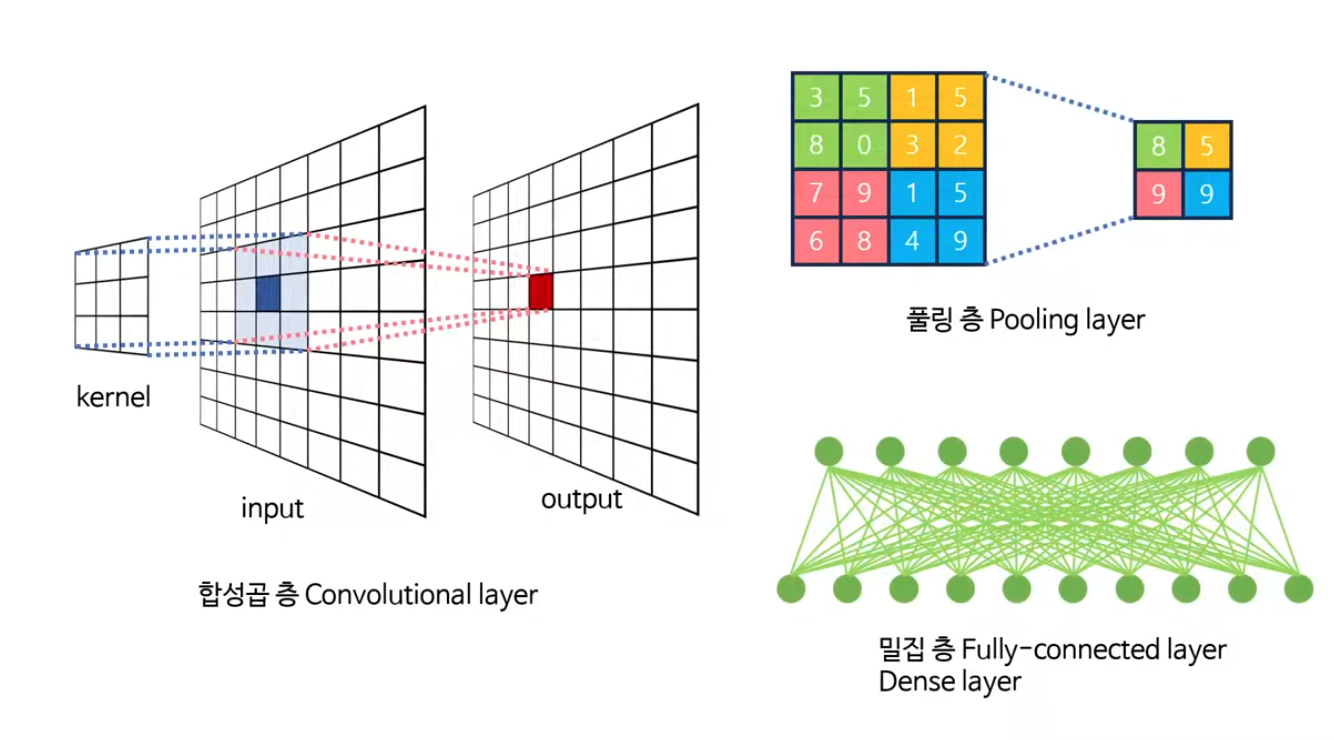
input image와 작은 크기의 필터(kernel) 간의 합성곱 연산을 통해 새로운 특성맵(feature map)을 생성합니다.
이를 통해 이미지의 지역적인 패턴을 감지하고 추출할 수 있습니다.
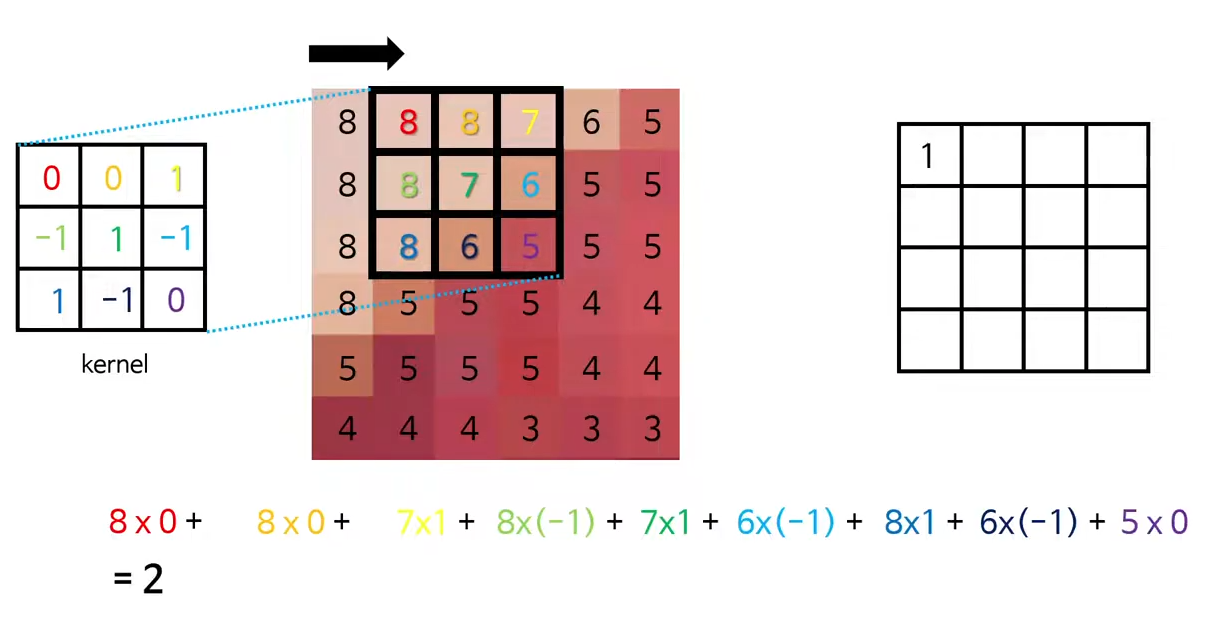
같은 방식으로 kernel을 이동해가면서 합성곱의 값을 구해줍니다.
그러면 이렇게 계산된 결과를 모아 새로운 feature map을 생성합니다.

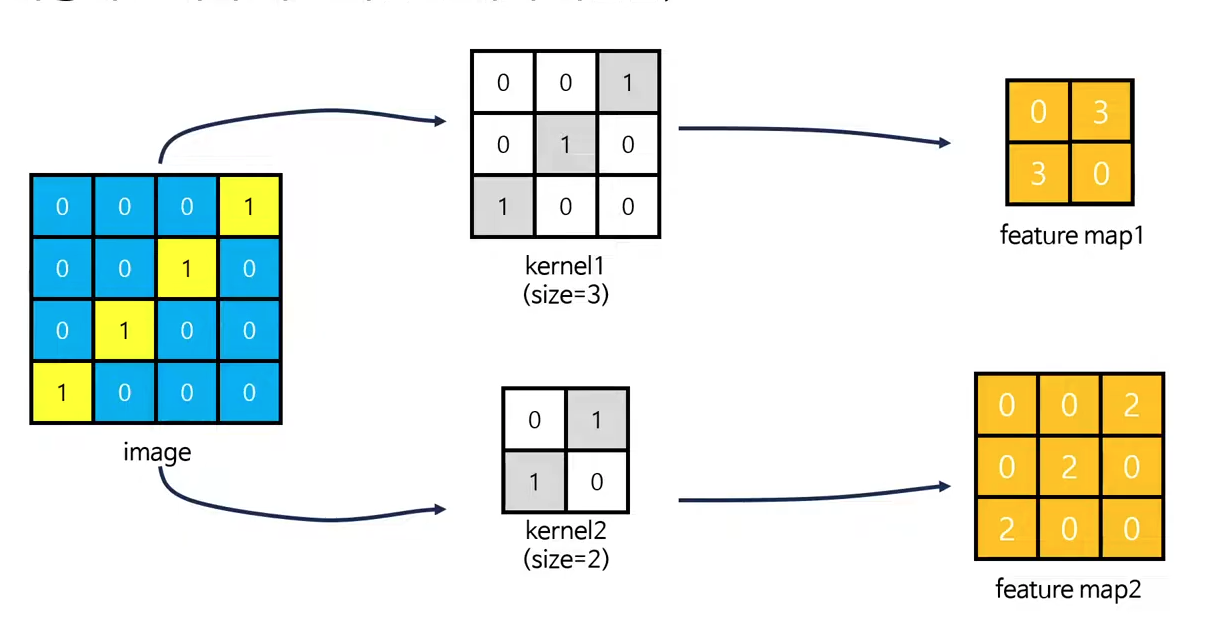
합성곱 연산이 갖는 의미?
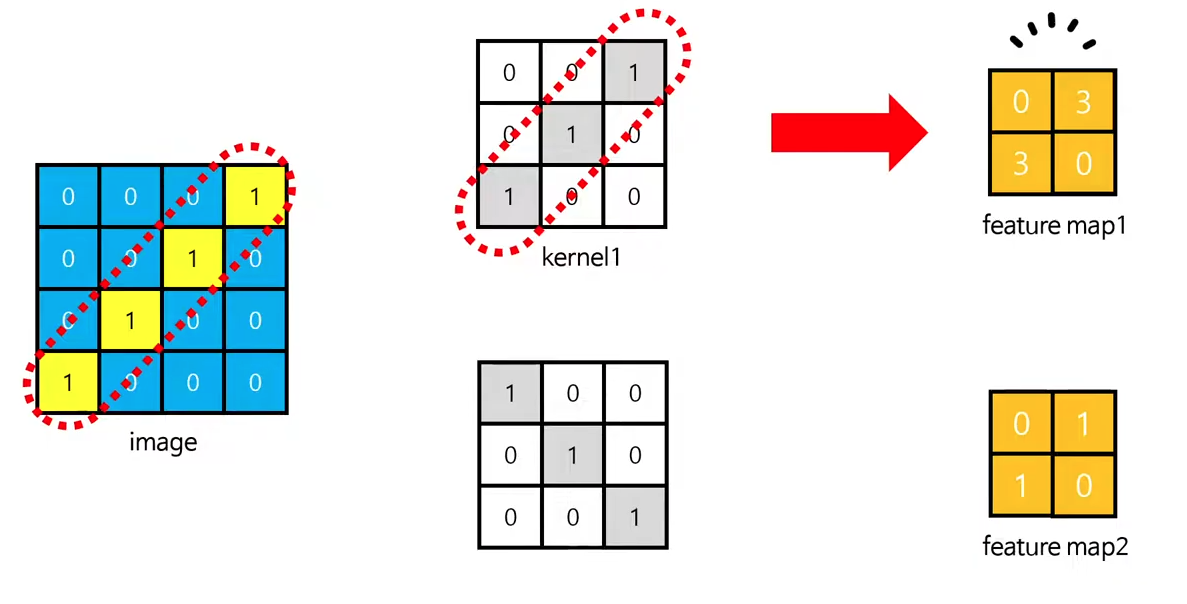
이미지의 특성과 유사한 kernel1을 활용해 합성곱한 [feature map1]은 결과값이 상대적으로 높고,
이미지의 특성과 다른 kernel2을 활용해 합성곱한 [feature map2]은 결과값이 상대적으로 낮다는 것을 알 수 있습니다.
이러한 방법을 통해 Classification을 할 수 있는 것이죠.
아래와 같이 1에 가까운 것은 직선적인 패턴 특징이 있는 것과 연결이 되고,
0에 가까운 것은 곡선형 패턴과 연결되어있다는 것을 볼 수 있습니다.
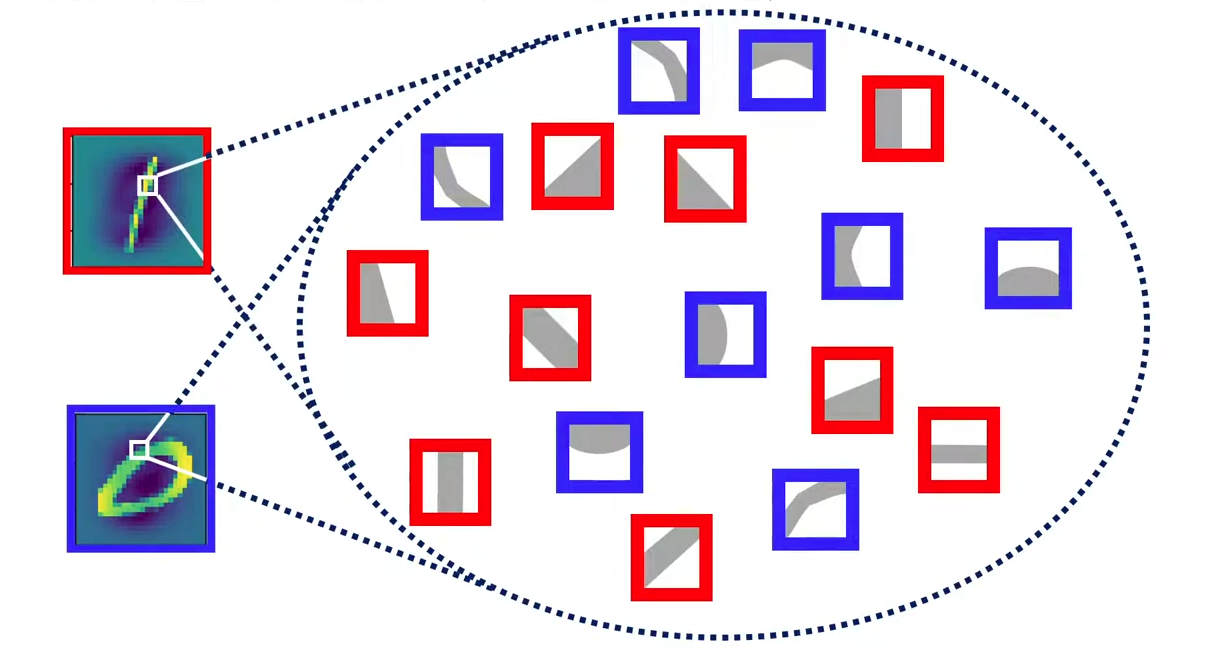
층이 깊어진다면 더욱 복잡한 형태의 패턴도 찾아낼 수 있게 됩니다
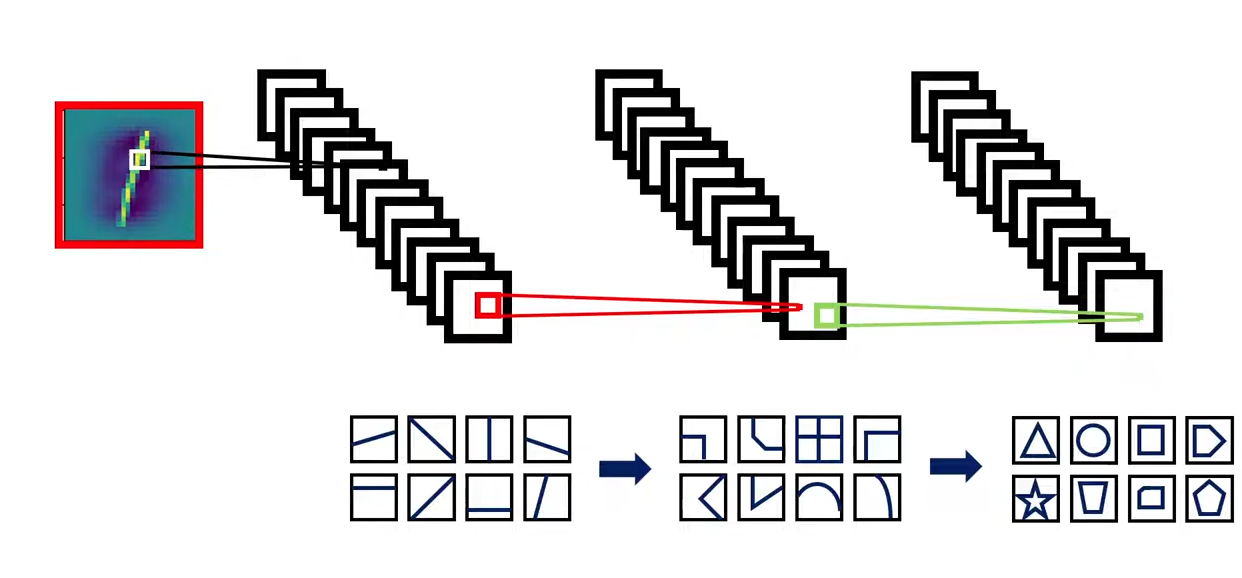
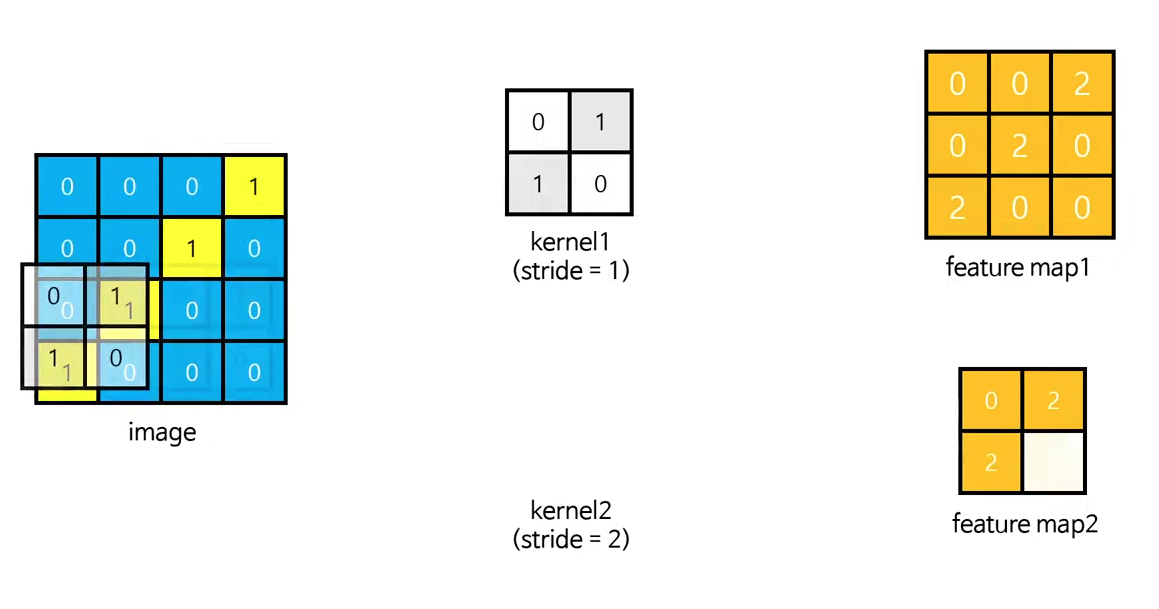
Kernel의 size와 stride(보폭)의 영향
Convolution의 출력층 크기를 조절하는 중요한 요소입니다.
Let's say
서로 크기가 다른 두 개의 kernel이 있다고 합시다
feature map의 크기가 다른 kernel을 통과하면 feature map의 크기가 클수도, 작을 수도 있습니다.
image의 픽셀수가 많을수록 feature map의 크키가 크면 더 디테일한 추출할 수 있겠지만, 연산량이 많아 시간이 많이 걸립니다.
좀 더 자세하게 정리해봅시다.
| 항목 | Kernel Size (커널 크기) | Stride Size (이동 간격) |
|---|---|---|
| 출력 크기 | 커널이 클수록 feature map 크기가 작아짐 (입력보다 더 크게 압축됨) | 스트라이드가 클수록 feature map 크기가 작아짐 |
| 수용 영역(Receptive Field) | 커널이 클수록 한 번에 더 넓은 입력 영역을 본다 → 더 큰 패턴을 학습 | 스트라이드는 receptive field 자체는 바꾸지 않지만, 건너뛰면서 샘플링하므로 특징의 세밀한 부분을 놓칠 수 있음 |
| 세부 정보 보존 | 작은 커널(예: 3×3)은 미세한 특징(엣지, 코너)을 잘 포착 | 큰 커널(예: 7×7)은 작은 디테일보다는 큰 구조에 집중 |
| 계산량(연산 비용) | 커널이 커질수록 연산량 ↑ | 스트라이드가 커질수록 feature map 크기가 작아져 연산량 ↓ |
| 대표적 사용 예 | 3×3 커널: 대부분의 CNN 기본 구조 (VGG, ResNet) 1×1 커널: 차원 축소, 채널 간 조합 (Inception, ResNet bottleneck) | Stride=1: 기본 convolution Stride=2: downsampling (Pooling 대체용) |
Kernel size는 "한 번에 얼마나 넓은 입력을 볼 것인가?" (패턴 크기)
Stride size는 "출력을 얼마나 촘촘히 뽑을 것인가?" (출력 크기 축소 비율)
⁉️ 그러면 kernel의 size와 stride size의 크기는 어떻게 설정하는 것이 적합할까?
1) Kernel Size 선택
| Kernel Size | 장점 | 단점 | 주로 쓰이는 경우 |
|---|---|---|---|
| 3×3 | - 세밀한 특징(엣지, 코너) 잘 포착 - 파라미터 수 적음 - 여러 층을 쌓아 더 큰 receptive field 형성 가능 | 한 층만으로는 넓은 문맥을 보지 못함 | VGG, ResNet 등 대부분의 현대 CNN |
| 1×1 | - 채널 간 조합/차원 축소 - 연산량 감소 | 공간적 특징 추출 불가 | Inception, ResNet bottleneck |
| 5×5, 7×7 이상 | - 넓은 영역 패턴(큰 객체) 인식 | - 연산량 큼 - 작은 특징을 놓칠 수 있음 | 초기 CNN (AlexNet 11×11, GoogleNet 일부 레이어) |
➡️ 실무적 권장:
- 대부분 3×3을 기본으로 사용
- 필요 시 여러 개의 3×3을 쌓아 5×5, 7×7 효과 대체 (연산량 줄이고 비선형성 확보)
- 채널 축소나 정보 혼합엔 1×1 활용
2) Stride Size 선택
| Stride | 장점 | 단점 | 주로 쓰이는 경우 |
|---|---|---|---|
| 1 | - 출력 feature map 크기 유지 - 세밀한 특징 보존 | 연산량 큼 | 대부분의 conv layer |
| 2 | - feature map 크기 절반 감소 (downsampling) - 연산량 절약 | 세밀한 정보 일부 손실 | pooling 대체 (ResNet, 일부 EfficientNet) |
| >2 | - feature map 급격히 축소, 속도 향상 | 정보 손실 심각 → 성능 저하 위험 | 거의 사용하지 않음 |
➡️ 실무적 권장:
- 일반 conv layer는 stride=1
- 차원 축소가 필요할 때만 stride=2
- 2 이상은 거의 쓰지 않음
정리,,
Kernel size = 3×3, stride=1 👉 가장 표준적이며 균형적 선택
Stride=2 (혹은 pooling) 👉 feature map 크기를 줄일 때만 사용
1×1 kernel 👉 채널 축소·정보 혼합
큰 kernel은 꼭 필요한 경우에만 제한적으로 사용 (예: 초반 넓은 시야 확보, 특정 대형 객체 검출)
합성곱 층은 보통 activation function을 사용하여 비선형성을 도입합니다.
Activation function-ReLU
입력 이미지/Feature map
↓
Convolution 연산 (커널 적용 + 합성곱)
↓
ReLU (비선형 활성화 함수)
↓
Pooling (선택적, downsampling)
↓
다음 Convolution Layer ...
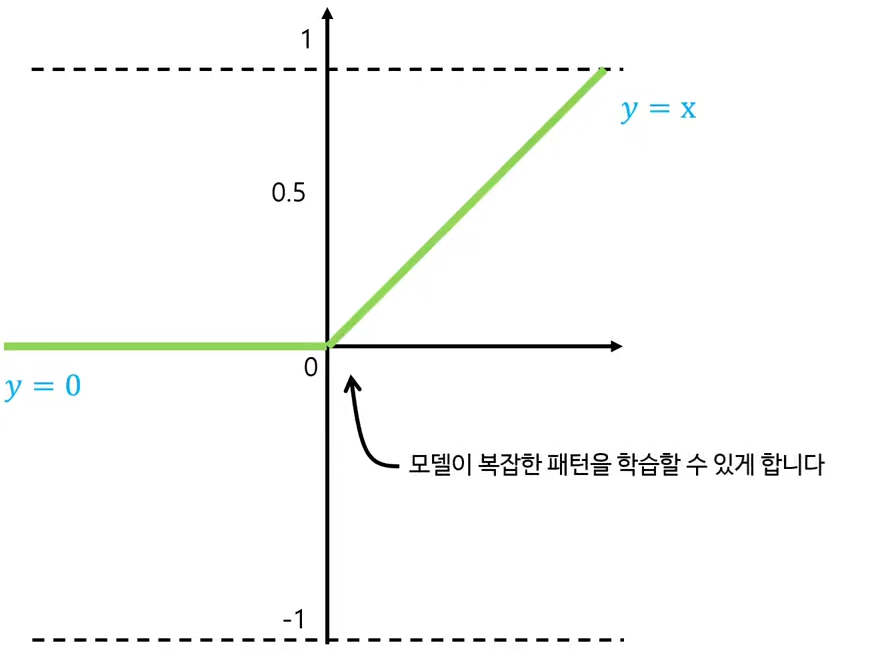
📌 왜 Convolution 뒤에 ReLU를 쓰는가?
Convolution 연산: 선형 연산 (입력×가중치 + bias)
→ 선형 변환만 반복하면 결국 하나의 큰 선형 변환과 같아져서 복잡한 패턴을 학습할 수 없습니다.
ReLU: 비선형성을 도입해 네트워크가 복잡한 함수(비선형 패턴)를 학습할 수 있게 합니다.
효과: 음수는 0으로 잘라내고, 양수는 그대로 전달 → 연산 간단, gradient 소실 문제 완화할 수 있습니다.
Pooling Layer

목적
1) Feature map 크기 축소 → 연산량 줄이고 속도 향상
2) Translation invariance(위치 변화에 둔감) 확보 → 물체가 조금 움직여도 같은 특징으로 인식 가능
3) Overfitting 완화 → 불필요한 세부 정보 제거
동작 방식: 입력 feature map을 일정한 영역(예: 2×2, stride=2)으로 나눠서, 각 영역을 대표하는 값으로 요약
| 항목 | Max Pooling | Average Pooling |
|---|---|---|
| 대표값 | 영역 내 최댓값 | 영역 내 평균 |
| 강조 효과 | 강한 특징(엣지, 패턴) 강조 | 전체적 특성 보존, 매끄러운 표현 |
| 장점 | 노이즈 제거, 중요한 특징 유지 | 전반적인 정보 유지, 부드러움 |
| 단점 | 작은 디테일 무시될 수 있음 | 뚜렷한 특징 희석됨 |
| 사용 추세 | 대부분의 현대 CNN (ResNet, VGG 등) | 초기 네트워크 (LeNet 등), Global Average Pooling은 여전히 사용 |
Max Pooling → "가장 강한 특징만 살려라" (현대 CNN 주류)
Average Pooling → "전체 평균적인 정보도 중요하다" (주로 Global Average Pooling으로 남음)
Fully connected layer
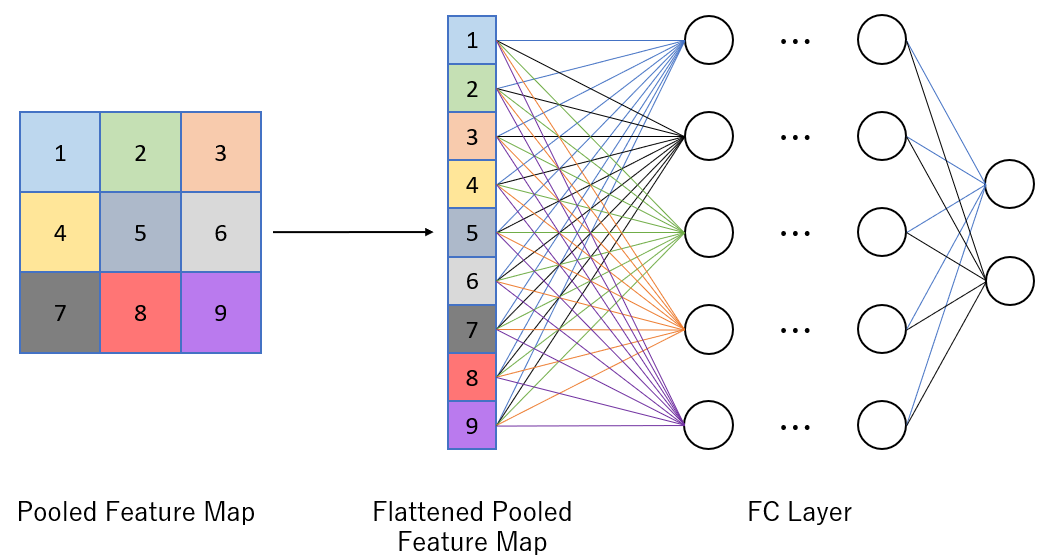
질문~~!
⁉️ Flatten을 하는 이유?
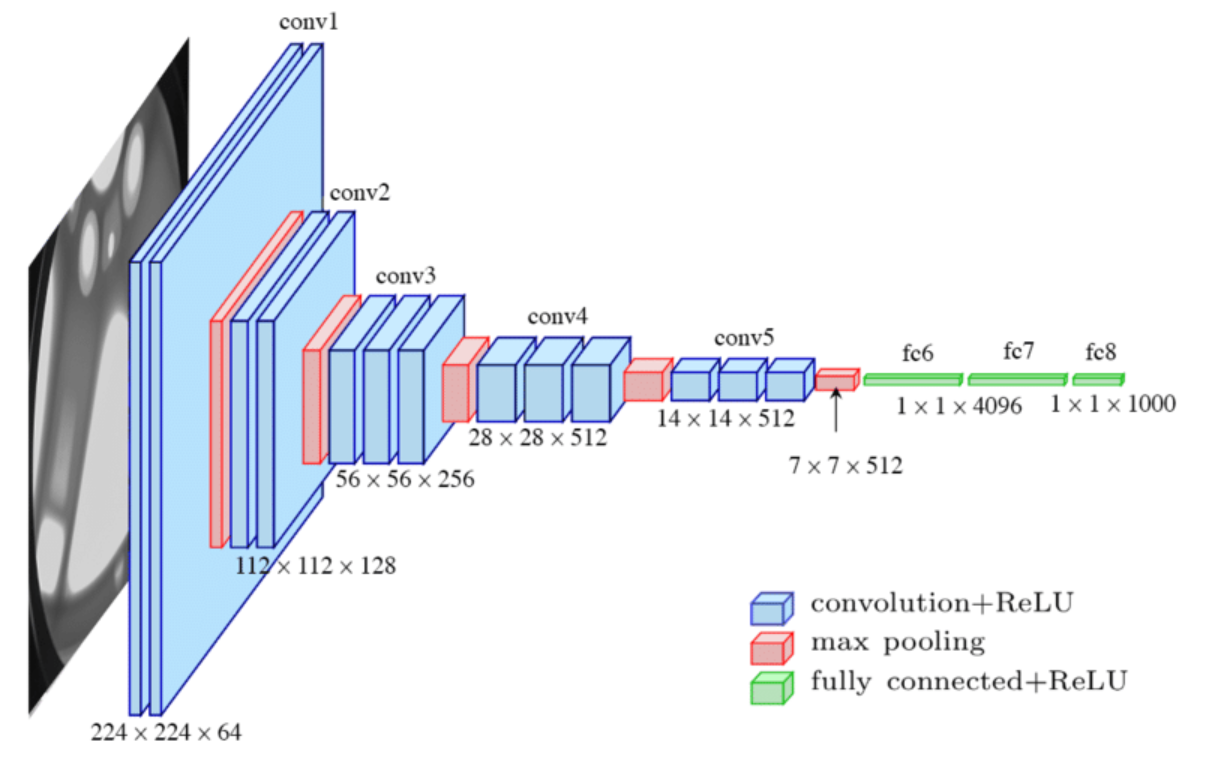
CNN(합성곱 신경망)은 이미지를 그대로 분류하는 대신, 여러 층의 합성곱(Convolution)과 풀링(Pooling)을 거치면서 이미지의 특징을 점점 추출해 나갑니다. 이 과정을 거치면 입력 이미지는 더 이상 원래의 픽셀 정보가 아니라, 중요한 패턴만을 담은 다차원 feature map으로 표현됩니다. 예를 들어, 224×224 크기의 이미지가 여러 층을 통과하면 7×7×512 같은 형태의 작은 feature map으로 바뀌죠.
문제는 Fully Connected(완전연결, FC) Layer입니다. FC Layer는 기본적으로 1차원 벡터를 입력으로 받습니다. 그런데 CNN의 앞단에서 나온 결과는 가로, 세로, 채널을 가진 3차원 구조예요. 따라서 이 상태로는 FC Layer에 직접 연결할 수 없습니다. 그래서 필요한 과정이 바로 Flatten입니다.
Flatten은 말 그대로 feature map을 한 줄로 “펼치는” 작업입니다. 예를 들어 (7×7×512)라면, 이걸 7×7×512 = 25088차원의 벡터로 바꿔줍니다. 이렇게 되면 FC Layer가 모든 노드와 연결될 수 있고, 최종적으로 분류나 회귀 같은 작업을 수행할 수 있습니다. 쉽게 말해, Flatten은 CNN에서 뽑아낸 특징들을 리스트처럼 나열해 최종 의사결정을 내리는 레이어에 넘겨주는 다리 역할을 한다고 보면 됩니다.
다만 최근의 최신 모델들은 Flatten 대신 Global Average Pooling(GAP)을 많이 씁니다. GAP은 각 채널의 평균값을 하나의 숫자로 요약해 벡터를 만들기 때문에 파라미터 수가 줄고 과적합을 막는 데 도움이 됩니다. 예를 들어 (7×7×512)라면 단순히 512차원 벡터로 압축되죠.
정리하자면, Flatten은 CNN이 추출한 다차원 특징을 FC Layer가 이해할 수 있는 벡터로 바꾸는 필수 과정입니다. 전통적인 CNN에서는 Flatten을 많이 쓰고, 최신 네트워크에서는 Global Average Pooling 같은 기법을 활용합니다.
⁉️ convolutional layer를 쓰면 크기가 줄어드는데 굳이pooling layer를 한 번 더 쓰는 이유가 뭐지?
Convolution layer도 stride로 크기를 줄일 수 있지만, Pooling은 "불필요한 세부 정보를 버리고 중요한 특징만 남기는" 별도의 역할을 하기 때문에 같이 쓰입니다.
