우아한테크코스 1기 히브리의 테코톡을 듣고 정리한 내용입니다 :)
세 아키텍처의 기본 개념에 대해서 비교하는 글입니다. 잘못된 내용이 있다면 댓글로 남겨주세요 :)
공통점: 데이터베이스를 여러개로 만든다.
데이터베이스 서버가 죽으면 어떻게 대응할까를 고민하면서 다양한 아키텍트가 나오게 되었습니다.
Clustering
데이터베이스 서버를 여러개로 만드는 방법입니다.
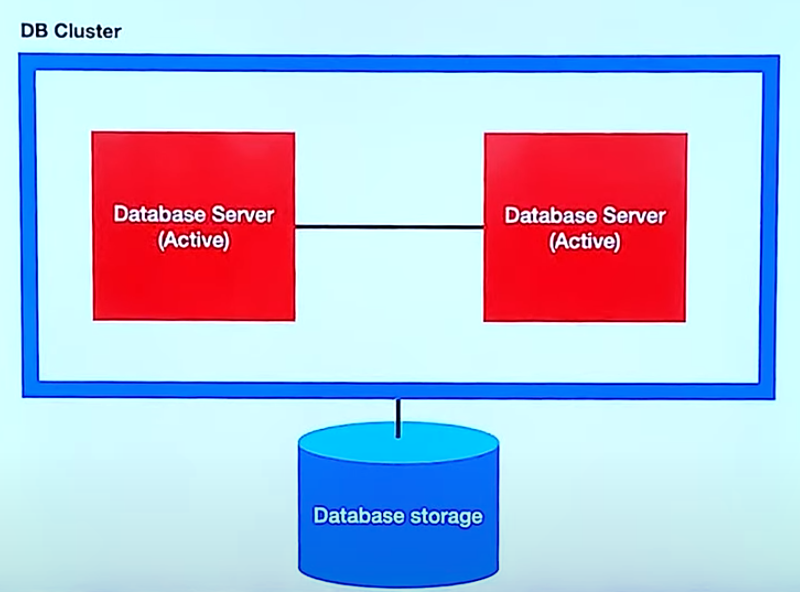
- Active - Active
실제로 동작하는 서버를 여러개 둡니다. cpu, memory 등을 더 많이 사용할 수 있습니다. 스토리지(데이터가 실제로 저장되는 저장소)는 하나를 공유하기 때문에 병목이 발생할 수 있습니다. 실제 동작하고 있는 서버가 2대이니 비용적으로 비쌉니다.
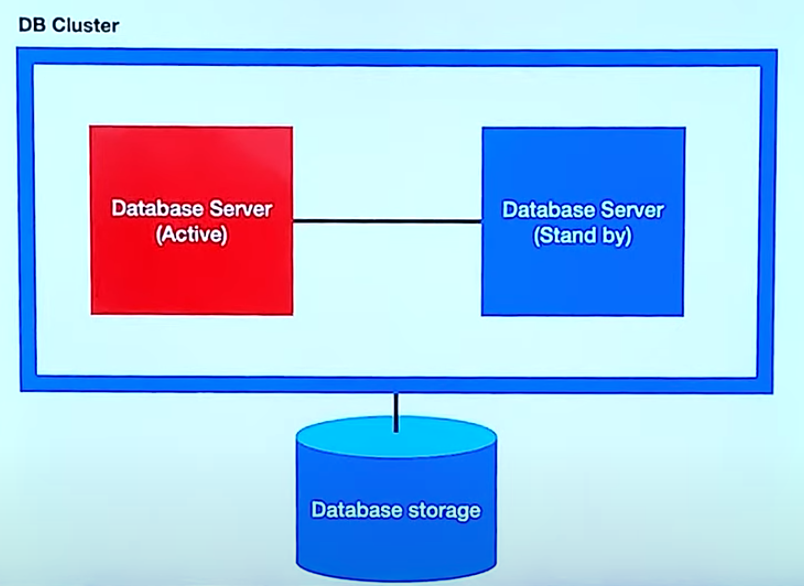
- Active - Standby
하나는 운영, 하나는 동작을 하지 않는 대기 상태의 서버를 운영합니다. 서버가 죽었을 때 대기 상태 서버가 실행됩니다. 대기 상태 서버는 실행 중이 아니기 때문에 동작 비용이 줄어듭니다. 하지만 운영 서버에 문제가 발생했을 때 동작시키는 비용이 발생합니다. -> 시간이 오래 걸릴 수 있다.
Replication
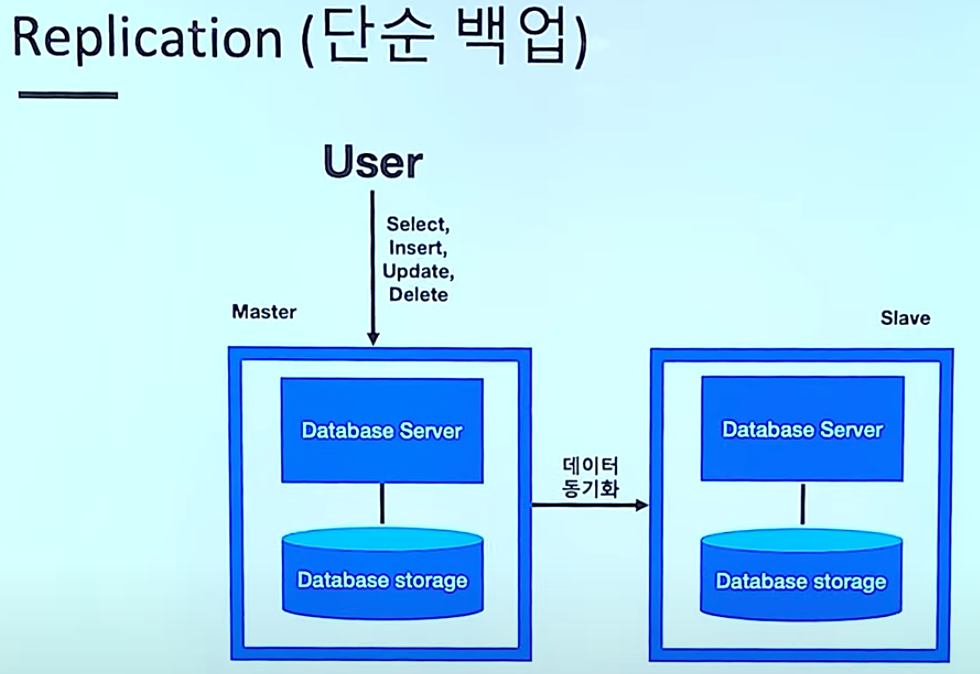
저장된 데이터가 손실되었을 때의 문제를 해결하기 위한 아키텍트입니다. 실제 저장소를 복제한 방식입니다.
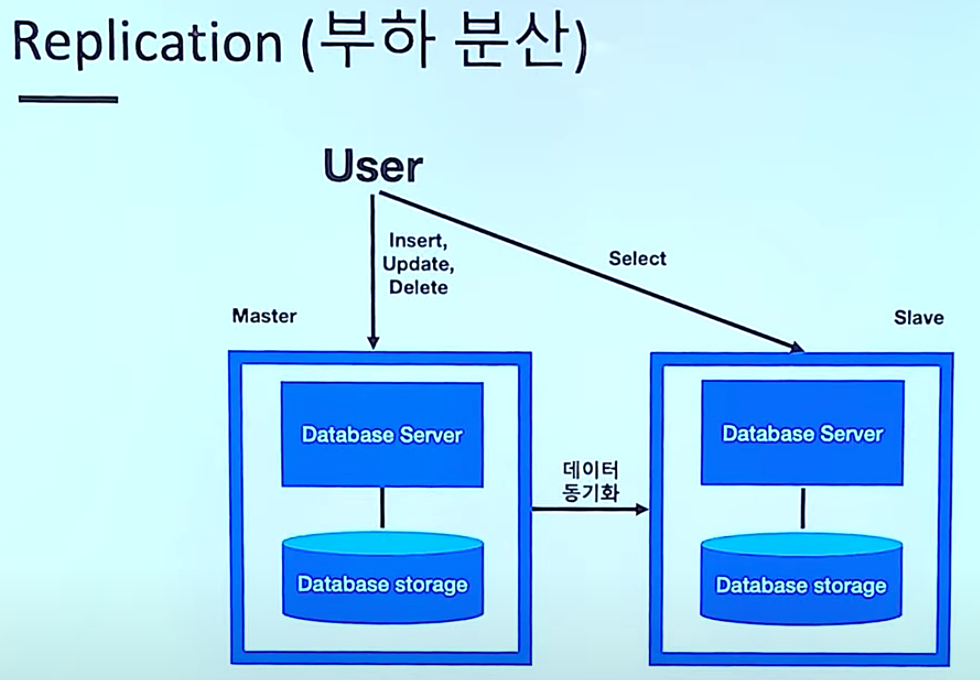
master - slave 구조: slave 구조를 읽기 전용 저장소로 사용해 부하를 분산시킵니다.
Sharding
데이터가 너무 많아서 검색이 느려졌을 때 더 빠르게 검색할 수 있는 방법입니다. 데이터베이스 테이블을 나눠서 저장한 후 검색을 하는 방법입니다.
고려해야 할 점
1. 분산된 데이터베이스에 데이터를 어떻게 저장할 것인가?
2. 분산된 데이터베이스에서 데이터를 어떻게 읽을 것인가?
Shard: 데이터베이스 또는 검색 엔진에 있는 데이터의 수평 파티션입니다.
Shared Key: 나눠진 Shard 중 어떤 Shard를 선택할지 결정하는 키 입니다.
Shared Key의 결정 방식에 따라 Sharding 방법이 나뉩니다.
Hash Sharding
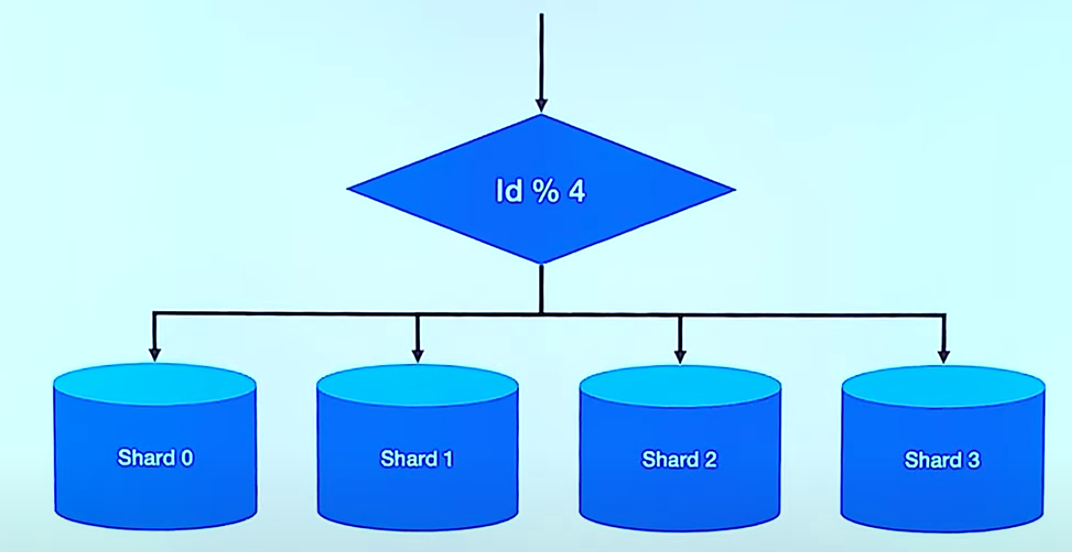
Shard의 수 만큼 해싱을 해주면 되니까 구현이 간단합니다. Shard가 늘어나면 해쉬 함수가 달라지니 데이터 정합성이 깨집니다. 저장 공간에 대한 효율성을 따지지 않고 구현한 방법입니다.
Dynamic Sharding
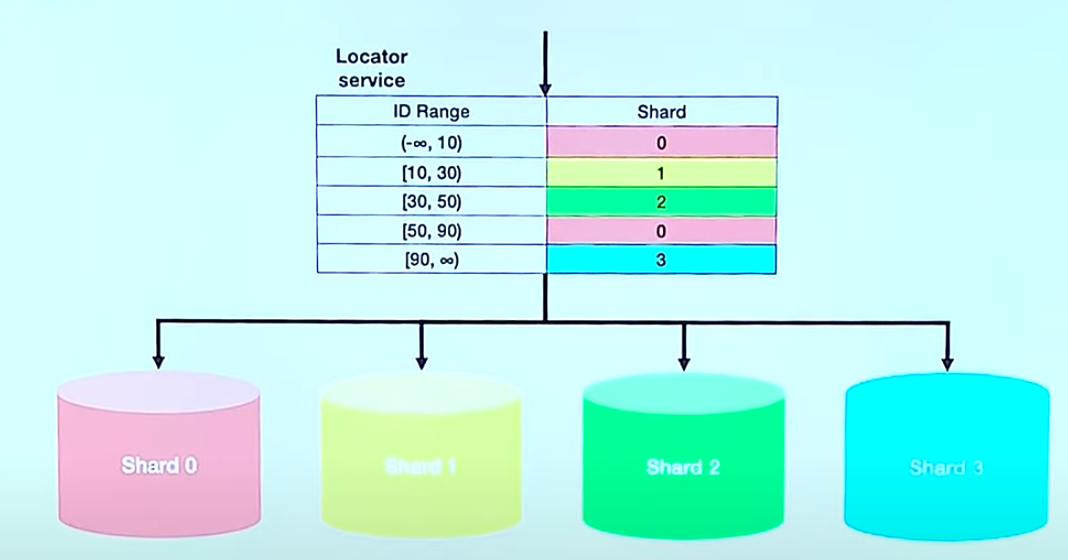
Locator Service를 이용해 Shard를 찾습니다. 확장에 유연한 구조입니다. 데이터를 재배치 할 때 Locator Service도 동기화 해야 합니다. Locator에 의존적이라 Locator에 문제가 생기면 db에도 문제가 생깁니다.
Entity Group
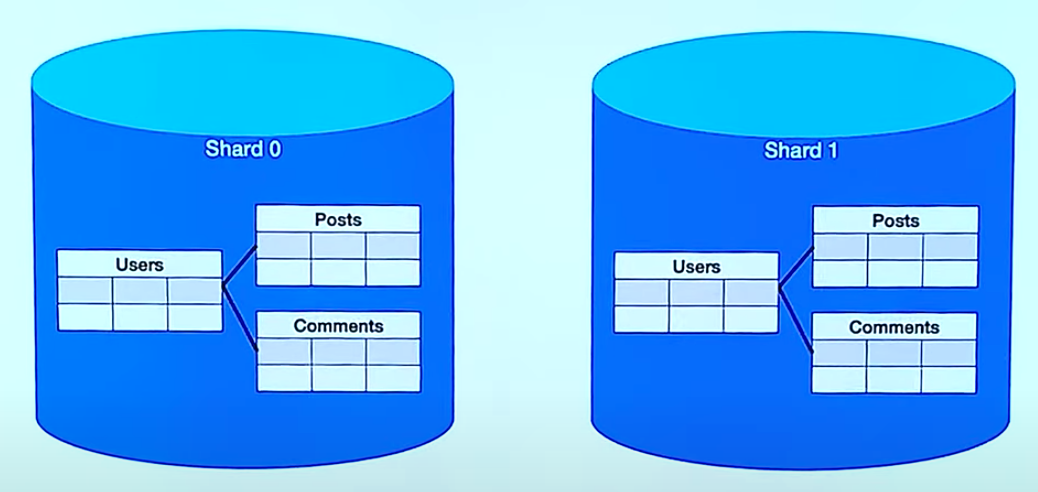
위의 Sharding 구조는 nosql에 더 적합한 구조입니다. RDB에 적합한 구조는 관계가 있는 엔티티끼리 같은 Shard에 존재하도록 구성하는 방식입니다. 단일 Shard 내에서 쿼리가 효율적입니다. 단일 Shard 내에서 강한 응집도를 갖습니다. 다른 Shard의 엔티티와 연관이 되는 경우 비효율적입니다.

좋은글 감사합니다 ^^