
MySQL의 실행 계획을 크루들과 스터디하면서 MySQL의 인덱스에 대해서 학습이 부족해 기본 개념을 정리합니다. 내용은 MySQL의 InnoDB 엔진을 기준으로 정리합니다. 이후에 Real MySQL에서 인덱스 부분을 읽은 후 내용을 더 추가하겠습니다. 잘못된 내용이 있다면 알려주세요 :)
기본 개념
인덱스란
데이터베이스에 저장된 데이터들을 위한 목차라고 생각하면 됩니다. 테이블의 특정 컬럼들을 인덱스로 등록해 데이터를 조회할 때 성능 향상을 기대할 수 있습니다. 데이터를 조회하는 쿼리를 작성할 때 WHERE, ORDER BY 절에 사용하는 컬럼이 인덱스로 등록되어있을 때 효율적인 검색을 할 수 있습니다.
인덱스가 효율적인 이유는
1. 인덱스로 지정한 컬럼은 full table scan을 하지 않는다.
2. 인덱스는 메모리에 저장되어 있어서 접근 속도가 빠르다.
입니다.
full table scan이란 테이블에서 데이터를 찾을 때 테이블 전체의 데이터를 순차적으로 읽으면서 원하는 값을 찾는 방법입니다. 인덱스를 이용하면 모든 데이터를 읽지 않고 원하는 데이터를 범위에 맞게 찾을 수 있습니다.
인덱스의 자료 구조
MySQL의 InnoDB엔진에서 인덱스를 설정하면 자동으로 B-Tree로 인덱스가 생성됩니다. B-Tree의 특징에 대해서 간략하게 알아보겠습니다.
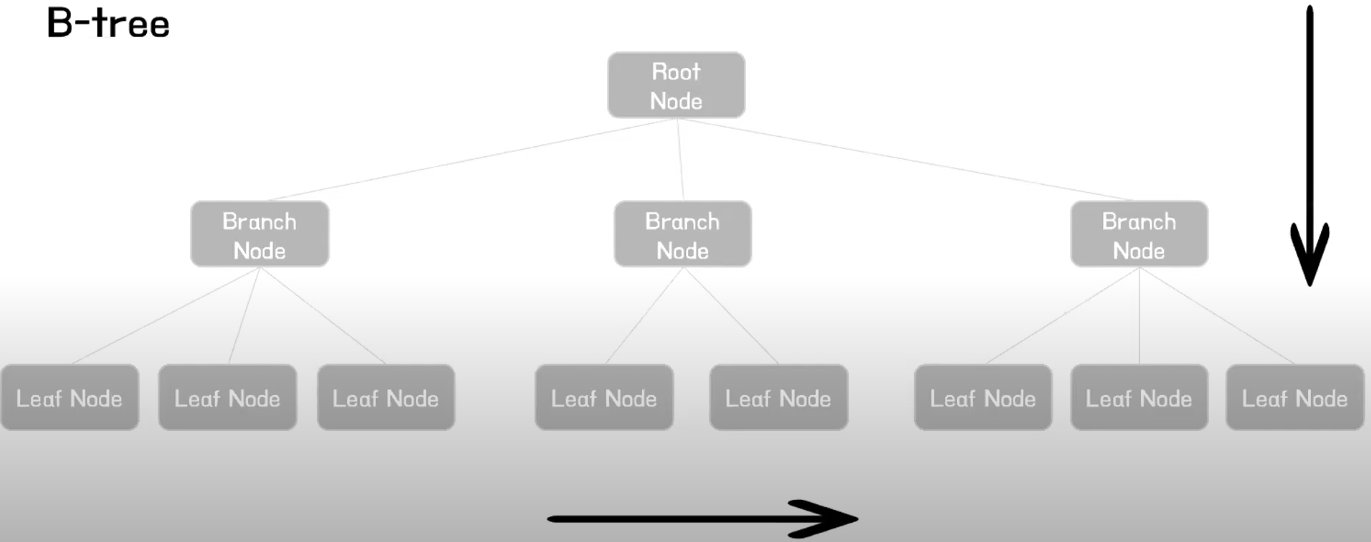
B-Tree는 이진 트리와 달리 자식 노드의 개수가 2개 이상인 트리입니다. 최상위 노드는 Root node, 중간 노드는 Branch node, 가장 마지막 노드는 Leaf node라고 합니다. 검색 방법은 수직 탐색과 수평 탐색이 있습니다. B-Tree로 인덱스를 생성하면 탐색할 때 수직 탐색과 수평 탐색을 진행합니다. 값이 있는 Leaf node까지 수직으로 탐색하고 Leaf node 내에서 원하는 값을 찾을 때 수평 탐색을 합니다.
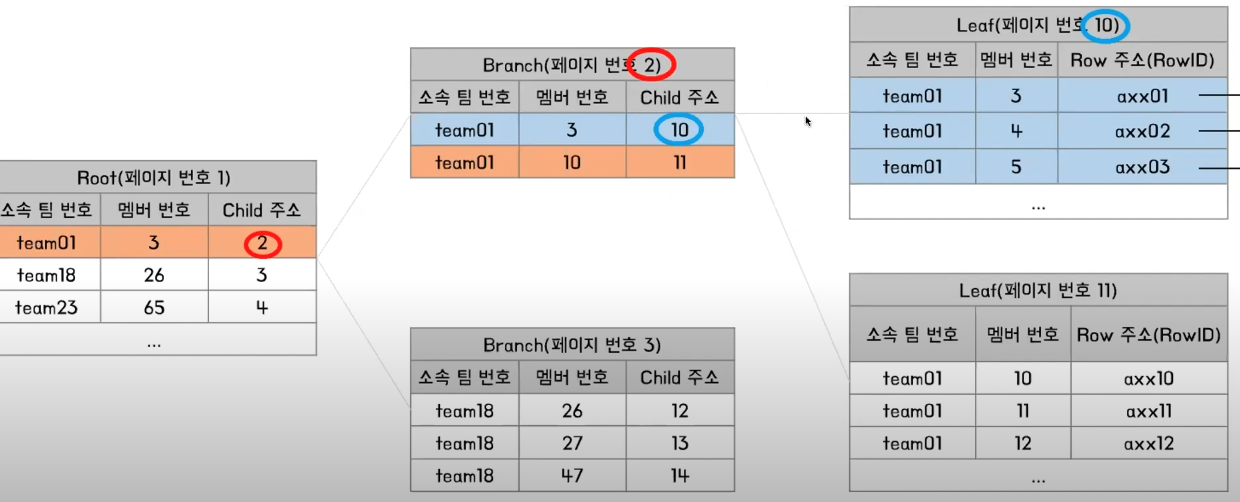
탐색 과정을 간단하게 나타내면 위와 같습니다. 인덱스를 이용해 멤버 번호 5 라는 값을 찾는 과정입니다. Root node에서 5라는 값이 포함된 범위의 Child 주소를 읽고 해당 Branch node로 이동합니다. Branch node에서도 동일한 과정을 거친 후 Leaf node에서 멤버 번호 5에 해당하는 row의 주소를 읽어서 데이터를 가져오는 것입니다. 이런 방법을 index range scan이라고 합니다. full table scan과 다르게 찾는 데이터가 범위에 있다면 탐색을 종료합니다.
위 내용은 레베카의 테코톡을 참고하였습니다 :)
해쉬 인덱스라는 자료구조도 사용하는데 여기에서는 다루지 않겠습니다 :)
인덱스의 종류
데이터베이스 테이블을 설계하고 인덱스를 등록할 때 MySQL에서는 클러스터링 인덱스와 논클러스터링 인덱스 두 가지를 사용할 수 있습니다. 두 인덱스의 특징에 대해서 알아보겠습니다.
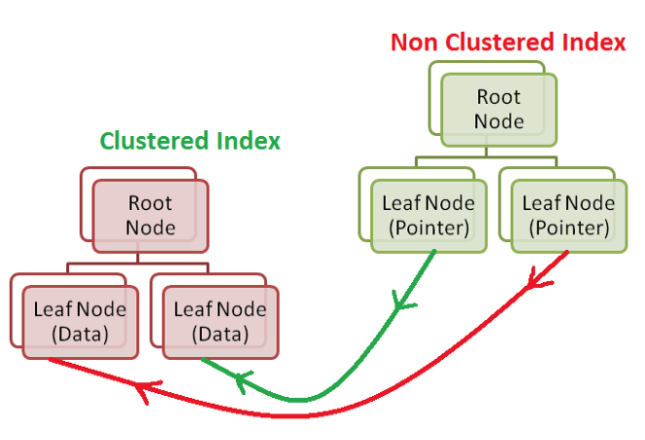
클러스터링 인덱스
클러스터링 인덱스란 테이블의 pk에 적용되는 인덱스입니다. 기본적으로 InnoDB엔진의 테이블에 pk를 등록하면 자동으로 해당 컬럼으로 클러스터링 인덱스를 생성합니다. 클러스터링 인덱스를 만들면 Leaf node에 인덱스로 지정한 컬럼의 값을 저장하고 있습니다.
클러스터링 인덱스의 특징은
- 데이터를 정렬된 상태로 유지
- 한 테이블에 하나만 생성 가능
- 클러스터 키로 검색 시 처리 성능이 매우 빠름
입니다.
여기서 데이터를 정렬된 상태로 유지하고있기 때문에 생기는 문제점이 있습니다. 만약 pk를 email, 주민등록번호와 같은 불규칙한 문자열의 집합으로 정했다고 가정하겠습니다. email의 경우 알파벳 순서대로 인덱스가 정렬되어있을 것입니다. 만약 giantim@naver.com이라는 email이 pk로 추가가 되었다면 인덱스의 중간에 삽입이 될 것이고 저장될 공간을 마련하기 위해 기존에 존재하는 인덱스들은 한 칸씩 뒤로 밀려나게 될 것입니다. 이런 작업이 추가로 필요해지기 때문에 보통 pk를 auto increment를 설정한 컬럼을 지정하는 것입니다. 따라서 email, 주민등록번호와 같은 값들은 pk로 설정하지 않고 유니크 키로 설정하는것이 더 좋습니다.
InnoDB엔진에서 클러스터링 인덱스 등록 순서는 다음과 같습니다.
- 프라이머리 키가 있으면 기본적으로 프라이머리 키를 클러스터 키로 선택합니다.
- NOT NULL 옵션의 유니크 인덱스(UNIQUE INDEX) 중에서 첫번째 인덱스를 클러스터 키로 선택합니다.
- 자동으로 유니크한 값을 가지도록 증가되는 컬럼을 내부적으로 추가한 후, 클러스터 키로 선택합니다.
만약 3번과 같은 경우로 클러스터링 인덱스가 생겼다면 사용자는 자동으로 추가된 컬럼이 무엇인지 알 수 없습니다. 그래서 위에서 말씀드린 문제점의 해결 방법과 마찬가지로 pk를 auto increment되는 값을 사용하는것을 권장하는 것입니다 :)
논클러스터링 인덱스
논클러스터링 인덱스는 클러스터링 인덱스와 다르게 노드 안에 컬럼의 값과 다음 노드로의 주소값을 가지고 있습니다. Leaf node의 경우에는 컬럼의 값과 데이터가 저장된 디스크의 주소값을 가지고 있습니다. 주소값으로 다음 노드의 위치를 알 수 있기 때문에 정렬되지 않은 상태로 유지하는 인덱스입니다.
논클러스터링 인덱스의 특징은
- 인덱스 키 값에는 해당 데이터에 대한 포인터가 존재
- 인덱스의 구조는 데이터 행과 독립적
- 한 테이블에 여러 개 생성 가능
입니다.
사용자가 등록하는 인덱스는 논클러스터링 인덱스로 등록이 됩니다.
주의사항
인덱스를 등록한다고 해서 CRUD 작업 전체의 성능이 빨라지는 것은 아닙니다. 클러스터링 인덱스의 주의점에서 말한 것 처럼 스트링 값을 pk로 설정했을 때 C의 과정에서 성능 이슈가 발생할 수 있습니다. 인덱스로 설정해야 하는 컬럼의 특징을 이해하고 주의해서 인덱스로 설정해야 합니다.
카디널리티
먼저 카디널리티를 고려해야 합니다. 카디널리티란 테이블에 해당 컬럼의 값들이 얼마나 유일하게 존재하는지를 나타내는 값입니다. 예를 들어 회원이라는 테이블에 성별을 저장한다고 할 때 성별은 남 / 여만 존재합니다. 핸드폰 번호를 저장한다고 할 때는 모든 회원이 유니크한 핸드폰 번호를 갖게 됩니다. 이런 경우 성별은 카디널리티가 낮다라고 표현하고 핸드폰 번호는 카디널리티가 높다라고 표현합니다.
인덱스로 설정하는 컬럼은 카디널리티가 높은 컬럼으로 설정해야 합니다. 카디널리티가 높은 컬럼으로 검색을 수행해야 더 많은 값들을 제외시키고 검색을 수행할 수 있기 때문입니다. 그렇기 때문에 만약 여러 컬럼으로 인덱스를 구성한다면 카디널리티가 높은 순서에서 낮은 순서대로 인덱스를 지정하는 것이 좋습니다.
인덱스도 비용이다
어떤 컬럼을 인덱스로 지정하고 검색을 할 때 효율성에 대한 손익 분기점이 존재한다고 합니다. 인덱스를 사용할 테이블의 데이터 수는 10만 ~ 100만 건 정도가 좋다고 합니다. 그리고 해당 데이터들 중 10% ~ 15%의 데이터들이 인덱스에 저장되도록 하는 것이 성능상 좋다고 합니다. 억 단위의 데이터에서는 인덱스 설계상 full table scan이 더 빠르게 동작한다고 합니다. 이 부분에 대해서는 아직 많은 데이터를 다뤄보지 못해서 체험해보지는 못했고 유튜브, 우아한테크코스 수업에서 들었던 내용입니다 :)
