
자연어 처리의 시작인 네이버 영화리뷰를 도전해 보았습니다.
1. load data
import urllib.request
import pandas as pd
from konlpy.tag import Mecab
import numpy as np
import matplotlib.pyplot as plt
from collections import Counter
import os
import reurllib.request.urlretrieve("https://raw.githubusercontent.com/e9t/nsmc/master/ratings_train.txt", filename="ratings_train.txt")
urllib.request.urlretrieve("https://raw.githubusercontent.com/e9t/nsmc/master/ratings_test.txt", filename="ratings_test.txt")training_set과 test_set에 해당하는 자료를 다운로드합니다. 문장과 각 문장에 대한 label이 0과 1로 저장된 데이터입니다. 이진 분류를 학습하는 것이 목표입니다.
데이터를 저장한 후, 저장한 상위폴더를 data_dir로 지정하여 pandas로 불러오도록 하겠습니다.
data_dir = '~/aiffel/sentiment_classification/data'
train_path = os.path.join(data_dir, 'ratings_train.txt')
test_path = os.path.join(data_dir, 'ratings_test.txt')
train_data = pd.read_csv(train_path, sep = "\t", engine='python')
test_data = pd.read_csv(test_path, sep = "\t", engine='python')이때, txt파일은 tab seperated values(tsv) 형식이므로 tab을 구분자로 하도록 sep="\t" 을 지정합니다.
데이터를 살펴보도록 합시다.
>>> train_data
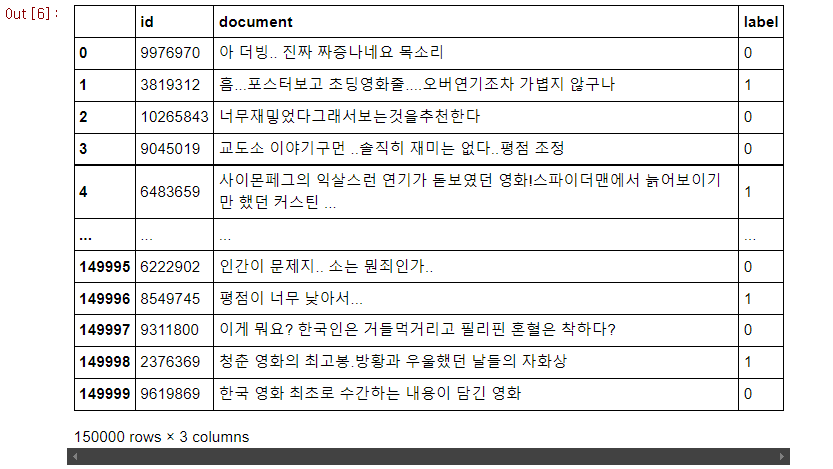 'document' column에는 내용이 있고, 'label' column에는 label이 있는 것을 확인할 수 있습니다. 'id' column은 별로 쓸모가 없을 것 같습니다. 또한, 연속한 점(.)과 오타(재밓었다), 그리고 의문스러운 label(너무재밓었다 -> 0)이 보입니다. 이러한 데이터 포인트는 모델 학습에 혼란을 주고, 모델이 학습이 잘 되더라도, 실제 세계에서의 성능이 뛰어나지 않을 것 같다는 생각이 듭니다.
'document' column에는 내용이 있고, 'label' column에는 label이 있는 것을 확인할 수 있습니다. 'id' column은 별로 쓸모가 없을 것 같습니다. 또한, 연속한 점(.)과 오타(재밓었다), 그리고 의문스러운 label(너무재밓었다 -> 0)이 보입니다. 이러한 데이터 포인트는 모델 학습에 혼란을 주고, 모델이 학습이 잘 되더라도, 실제 세계에서의 성능이 뛰어나지 않을 것 같다는 생각이 듭니다.
2. preprocess data
인공지능 모델에게 이 데이터를 먹이려면, 자연어 형태가 아닌 정수로 이루어진 numpy ndarray 형태로 바꾸어 주어야 합니다. ndarray는 모든 행의 차원(길이)가 같아야 하므로, 긴 문장이든 짧은 문장이든 특정한 길이로 바꿔주어야 한다는 점도 미리 생각할 수 있습니다.
만일 음절별로 분해하게 된다면, ("고민하다" -> "고", "민", "하", "다") 음절이 합쳐져서 어떤 의미를 만들어 내는지까지 모델이 학습해야 할 것이고, 이는 너무 큰 부담입니다. 따라서 형태소로 분해하는 것이("고민하다" -> "고민", "하", "다") 훨씬 좋은 선택일 것입니다.
다행히 문장을 형태소로 분해하는 모듈은 다양하게 존재하고, 빠른 처리를 해주는 것이 장점인 Mecab을 사용하겠습니다.
형태소 분해 후에는 각 형태소를 출현 빈도순으로 정리하여 {단어: 출현 빈도 순위} 인 딕셔너리와 {출현 빈도 순위: 단어}인 딕셔너리를 만듭니다. 이때 출현한 모든 형태소를 저장하는 대신, '사전'의 길이를 조정합니다. 이번에는 10000번째 자주 출현한 형태소까지 저장합니다. 이를 통해서 분해된 문장을 정수로 인코딩할 수 있습니다.
그 전에 생각해볼 처리로는, 현재 이 상태로 과연 문장을 형태소로 잘 분류하는지입니다.
tokenizer = Mecab()
tokenized_sentence = tokenizer.morphs(sentence) # 형태로소 분리Mecab 객체의 morphs 메소드를 사용하면 문장을 형태소로 분리 가능합니다. 이때, morphs는 영어로 형태소를 의미하는 morpheme에서 온 것 같습니다.
확인 결과:
- 'ㅋㅋ'와 'ㅋㅋㅋ', '..'와 '...'이 자주 나오고 이외에도 'ㅜㅜ'와 'ㅜㅜㅜ'등 역시 서로 다른 형태소로 인식된 채로 자주 나온다는 것을 확인했습니다. 'ㅜㅜ'와 'ㅜㅜㅜㅜㅜㅜㅜ'는 같은 것으로 인식해야 할 것 같습니다.
- ".?!,'"을 제외한 특수문자와 숫자는 모델 학습에 방해가 될 것 같습니다.('3류영화' -> '류영화')
- 괄호 안에 있는 내용은 그다지 필요 없을 것 같습니다
- 두개 이상의 공백은 하나로 변환하고 싶습니다.
이를 함수로 만들면 다음과 같습니다.
# 정규표현식을 통하여 형태소 분해 전의 전처리 방식을 설정합니다.
def preprocess_review(sentence):
sentence = re.sub(r'\([^)]*\)',r'',sentence) # 소괄호 내의 내용을 삭제합니다
sentence = re.sub(r'\[[^)]*\]',r'',sentence ) # 대괄호 내의 내용을 삭제합니다
sentence = re.sub(r'["."]{2,}', r" '..' ", sentence) # 연속한 .은 '..'로 변환합니다.
sentence = re.sub(r'["?"]{2,}', r" ?? ", sentence) # 2번 이상 연속한 기호, 자음을 2번 반복으로 변홥합니다
sentence = re.sub(r'["!"]{2,}', r" !! ", sentence)
sentence = re.sub(r'["ㅜ"]{2,}', r" ㅜㅜ ", sentence)
sentence = re.sub(r'["ㅠ"]{2,}', r" ㅠㅠ ", sentence)
sentence = re.sub(r'["ㅋ"]{2,}', r" ㅋㅋ ", sentence)
sentence = re.sub(r'["ㅎ"]{2,}', r" ㅎㅎ ", sentence)
sentence = re.sub(r'["ㄱ"]{2,}', r" ㄱㄱ ", sentence)
sentence = re.sub(r'["ㄷ"]{2,}', r" ㄷㄷ ", sentence)
sentence = re.sub(r'["ㅅ"]{2,}', r" ㅅㅅ ", sentence)
sentence = re.sub(r'["ㅊ"]{2,}', r" ㅊㅊ ", sentence)
sentence = re.sub(r'["ㅈㄴ"]+', "", sentence) # 비속어는 조금 삭제합니다.
sentence = re.sub(r'["ㅅㅂ"]+', "", sentence)
sentence = re.sub(r"[^ㄱ-ㅎ|ㅏ-ㅣ|가-힣.?!,' ]+", "", sentence) # 한글, 및 지정한 특수문자 이외의 글은 삭제합니다
sentence = re.sub(r'[" "]+', " ", sentence) # 연속된 공백은 공백 하나로 처리합니다
return sentence
- 불용어(stopwords)
특정 단어는 문맥에 관계없이 너무 자주 나와서 학습 시 사용하지 않는 것이 바람직합니다. 이번에는 직접 골라서 지정해주겠습니다.
stopwords = ['의','가','이','은', '을','들','는','좀','잘','걍','과','도','를','으로','자','에','와','한','하다', '겠', '음']
이상의 처리를 고려한 본격적인 load_data()는 다음과 같습니다
def load_data(train_data, test_data, num_words=10000):
train_data.drop_duplicates(subset=['document'], inplace=True)
train_data['document'] = train_data['document'].apply(lambda x: preprocess_review(str(x)))
train_data = train_data.dropna(how = 'any')
test_data.drop_duplicates(subset=['document'], inplace=True)
test_data['document'] = test_data['document'].apply(lambda x: preprocess_review(str(x)))
test_data = test_data.dropna(how = 'any')
X_train = []
for sentence in train_data['document']:
temp_X = tokenizer.morphs(sentence) # 토큰화
temp_X = [word for word in temp_X if not word in stopwords] # 불용어 제거
X_train.append(temp_X)
X_test = []
for sentence in test_data['document']:
temp_X = tokenizer.morphs(sentence) # 토큰화
temp_X = [word for word in temp_X if not word in stopwords] # 불용어 제거
X_test.append(temp_X)
words = np.concatenate(X_train).tolist()
counter = Counter(words)
counter = counter.most_common(num_words-4)
vocab = ['<PAD>', '<BOS>', '<UNK>', '<UNUSED>'] + [key for key, _ in counter] # 특수한 토큰은 미리 지정해 둡니다
word_to_index = {word:index for index, word in enumerate(vocab)}
def wordlist_to_indexlist(wordlist):
return [word_to_index[word] if word in word_to_index else word_to_index['<UNK>'] for word in wordlist] # '사전'에 없는 단어에는 <UNK> 토큰을 부여합니다.
X_train = list(map(wordlist_to_indexlist, X_train))
X_test = list(map(wordlist_to_indexlist, X_test))
return X_train, np.array(list(train_data['label'])), X_test, np.array(list(test_data['label'])), word_to_indexX_train, X_test는 각 문장이 형태소별 빈도수로 인코딩된 list,
train_set과 test_set의 label은 0과 1로 이루어진 np.array 입니다.
'사전'의 앞 부분은 다음과 같습니다.
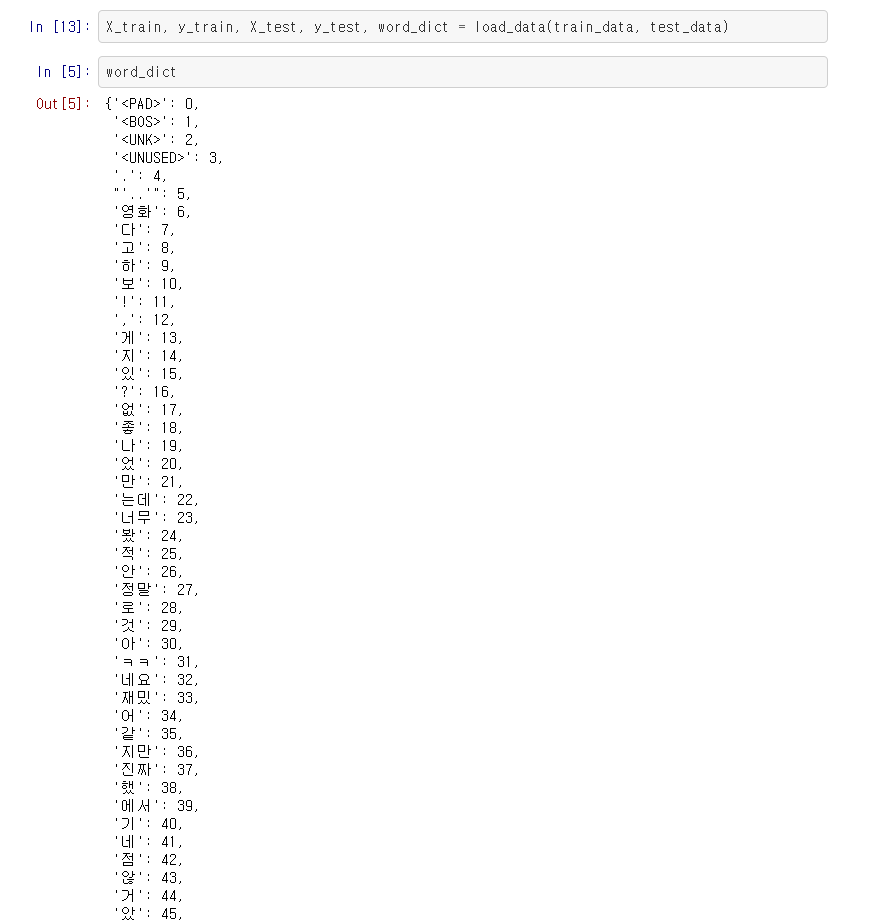
변환 예시
8892번 문장으로 변환이 제대로 되었는지 확인해 봅니다.

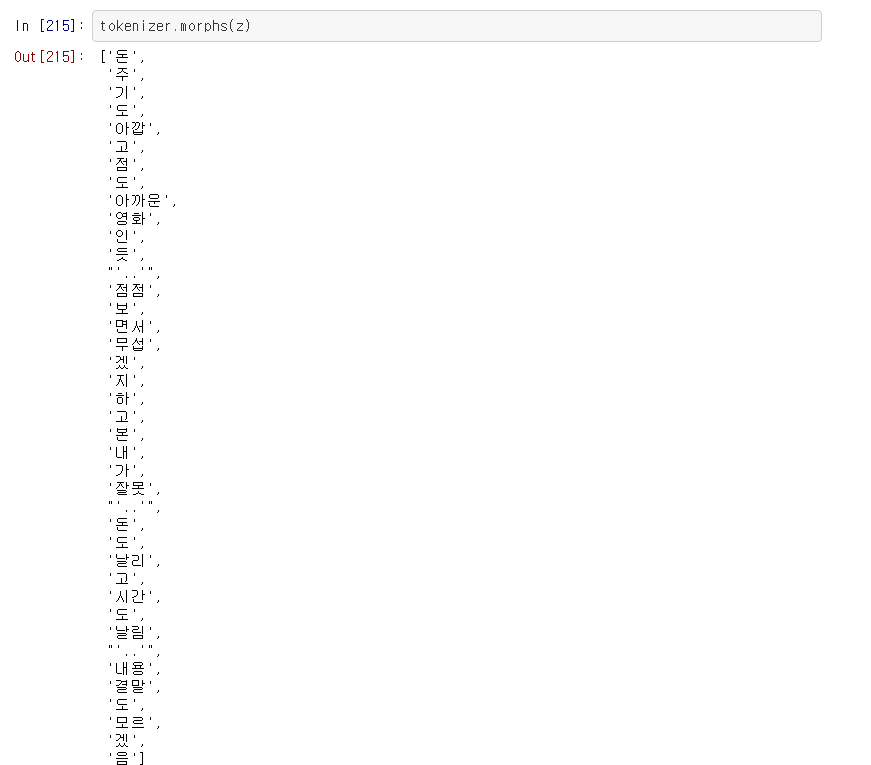

원하는대로 변환이 잘 된 것을 확인할 수 있습니다.
(자세히 보면 제일 앞의 형태소 '돈'이 삭제된 것을 볼 수 있습니다. get_decoded_sentence()는 제일 앞에 시작토큰 <BOS>가 포함된 문장을 기대하여, 이를 삭제하는 과정을 거치기 때문으로, 저는 <BOS> 토큰을 포함시키지 않아 생긴 문제입니다)
3. Padding & Modeling
현재 각 문장은 형태소별로 정수 인코딩이 된 상태입니다.
모델에게 데이터를 줄 때, 길이가 같은 형식으로 바꾸어 주어야 한다고 했습니다.
통계적 방법으로 적절한 길이를 정해, 더 긴 문장은 앞을 자르고, 더 짧은 문장은 앞에 PAD 토큰을 추가하겠습니다.
그 후 각 토큰을 256차원 dense matrix(각 행의 모든 값이 0이 아니고, 0~1사이의 실수이며, 각 행이 크기가 1인 벡터가 됨) 로 embedding합니다. 각 열은 특정한 feature를 나타내며, 이는 모델 학습을 통해 얻어지므로 learned feature라고 할 수 있습니다.

이제 본격적인 모델링을 시작합니다. 여러 시도를 통해 좋은 성능을 낸, 과적합이 되지 않도록 여러 장치를 추가한 LSTM을 사용하겠습니다.
from sklearn.model_selection import train_test_split
!pip install tensorflow-addons
import tensorflow_addons as tfa
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.initializers import Constant
from keras.regularizers import l2
# train_set을 train과 val으로 분해합니다
X_train, X_trainval, y_train, y_trainval = train_test_split(
X_train, y_train, test_size=0.25)vocab_size = 10000 # 어휘 사전의 크기입니다(10,000개의 단어)
word_vector_dim = 256 # 워드 벡터의 차원 수 (변경 가능한 하이퍼파라미터)
lnLSTMCell = tfa.rnn.LayerNormLSTMCell(20, recurrent_dropout=0.2, dropout=0.3, kernel_regularizer=l2(0.015), recurrent_regularizer=l2(0.015))
rnn = tf.keras.layers.RNN(lnLSTMCell, return_sequences=False, return_state=False)
# model 설계
model = keras.Sequential()
model.add(keras.layers.Embedding(vocab_size, word_vector_dim, input_shape=(None,)))
model.add(rnn)
model.add(keras.layers.Dense(15, activation='relu', kernel_regularizer=l2(0.01), bias_regularizer=l2(0.01)))
model.add(keras.layers.Dense(1, activation='sigmoid')) # 최종 출력은 긍정/부정을 나타내는 1dim 입니다.
>>> model.summary()
약 260만 개의 파라미터를 갖는 것을 확인할 수 있습니다.
# model 학습, validation_loss를 추적하여 validation_loss가 증가한다면 직전의 epoch에서 멈추고,
#그 상태를 bigger_model.h5 로 저장합니다.
callbacks = [tf.keras.callbacks.EarlyStopping(monitor='val_loss', mode='min'),
tf.keras.callbacks.ModelCheckpoint(filepath='bigger_model.h5',
monitor='val_loss',
save_best_only=True)]
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
epochs=15
history = model.fit(X_train,
y_train,
epochs=epochs,
batch_size=512,
validation_data=(X_trainval, y_trainval),
verbose=1,
callbacks=callbacks)
약 84%의 validation accuracy를 얻었습니다.
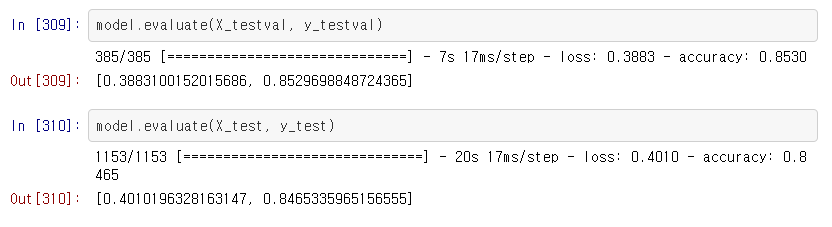
test_set에 대해서도 비슷한 성능을 얻어 일반화 성능이 좋은 모델인 것을 알 수 있습니다.
4. Visualization
cc = history_dict['accuracy']
val_acc = history_dict['val_accuracy']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(acc) + 1)
# "bo"는 "파란색 점"입니다
plt.plot(epochs, loss, 'bo', label='Training loss')
# b는 "파란 실선"입니다
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss-Bigger Model')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()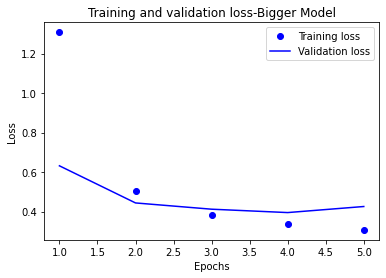
plt.clf() # 그림을 초기화합니다
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()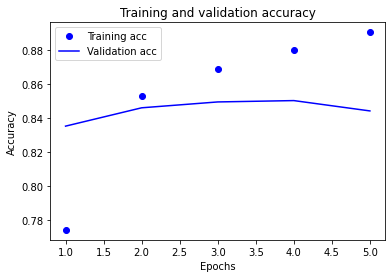
5. Check Embedding Layer
Embedding layer가 학습이 잘 되었는지 확인해 봅니다
# 학습한 Embedding 파라미터를 파일에 써서 저장합니다.
korword2vec_file_path = os.getenv('HOME')+'/aiffel/sentiment_classification/data/korword2vec.txt'
f = open(korword2vec_file_path, 'w')
f.write('{} {}\n'.format(vocab_size-4, word_vector_dim)) # 몇개의 벡터를 얼마 사이즈로 기재할지 타이틀을 씁니다.
# 단어 개수(에서 특수문자 4개는 제외하고)만큼의 워드 벡터를 파일에 기록합니다.
vectors = model.get_weights()[0]
for i in range(4,vocab_size):
f.write('{} {}\n'.format(index_dict[i], ' '.join(map(str, list(vectors[i, :])))))
f.close()!pip install python-Levenshtein
from gensim.models.keyedvectors import Word2VecKeyedVectors
word_vectors = Word2VecKeyedVectors.load_word2vec_format(korword2vec_file_path, binary=False)
"찡해"와 연관된 단어와, "환불"과 연관된 단어가 유의미하므로, Embedding이 잘 된 것을 확인할 수 있습니다.
번외 - 문장 예측해보기
- encode_sentence(): 문장 리스트를 입력으로 받아, train_set에 했던 처리를 동일하게 하고, 같은 '사전'을 사용하여 정수로 인코딩합니다.
def encode_sentence(sentence_list):
X=[]
for sentence in sentence_list:
sentence = preprocess_review(sentence) # 전처리
temp_X = tokenizer.morphs(sentence) # 형태소로 분리
temp_X = [word for word in temp_X if not word in stopwords] # 불용어 제거
X.append(temp_X) # 모으기
encoded_sentences = list(map(wordlist_to_indexlist, X)) # 정수로 인코딩
return encoded_sentences
def wordlist_to_indexlist(wordlist): # training에 사용한 '사전'을 word_dict 자리에 넣습니다.
return [word_dict[word] if word in word_dict else word_dict['<UNK>'] for word in wordlist]- predict_sentences(): 불러온 모델에 문장 리스트를 넣어 예측값을 이해하기 쉬운 형태로 출력합니다.
def predict_sentences(sentence_list):
encoded_list = encode_sentence(sentence_list)
padded_list = keras.preprocessing.sequence.pad_sequences(encoded_list,
value=word_dict["<PAD>"],
padding='pre', # 혹은 'post'
maxlen=maxlen)
score_list = loaded_model.predict(padded_list)
for sentence, score in zip(sentence_list, score_list):
if(score > 0.5):
print(f"문장: {sentence}\n {float(score) * 100:.2f}% 확률로 긍정 리뷰입니다.\n")
else:
print(f"문장: {sentence}\n {(1 - float(score)) * 100:.2f}% 확률로 부정 리뷰입니다.\n")
