Object Segmentation via Graph Cut
1. Overveiw

(a) 사람이 몇개의 pixel에 대해서 직접 라벨링을 진행 (Initial Seed)
(b) Graph의 Node, Edge, Source, Sink 정의 (두꺼운 선은 Initial Seed에 해당하는 pixel과 연결된 Edge)
(c) Max-Flow Algorithms을 이용하여 Graph cut을 수행
(d) cut한 Edge를 기반으로 Node를 분리하여 Segmentation 수행
2. Segmentation Energy
- 는 pixel의 집합
- Neighborgood system은 N개의 집합으로 표현될 수 있음. (상하좌우, 상하좌우+대각선 등등..)
- 는 '전경', '배경'으로 이루어진 집합이며, 이는 곧 Segmentation을 의미
3. Cost function
Cost function은 위와 같이 regional term인 와 boundary term인 로 이루어져 있다.
4. Assigning Costs
Regional cost와 Boundary Cost를 Minimize 하는 것이 목표
- Regional Cost
우선, 와 의 확률 분포는 Initial seed를 이용하여 정의되어 있다.
(a)는 pixel 가 obj일 때, 의 Intensity 값이 나올 확률에 를 취해준 것이고, (b)는 이와 반대로 pixel 가 bkg일 때, 의 Intensity 값이 나올 확률에 를 취해준 것이다.
만일, 가 obj에 가까운 color 정보를 가지고 있다면, 는 작아질 것이고, 는 커질 것이다.
- Boundary cost
Regional Cost는 p 한개만 가지고 Cost를 정의했다면, Boundary Cost는 p 주변의 픽셀 q와의 색깔, 거리 등을 이용하여 정의한다. 즉, p와 q 사이의 색이 매우 다르거나, 거리가 멀면 는 작아질 것이다.
- Experiment
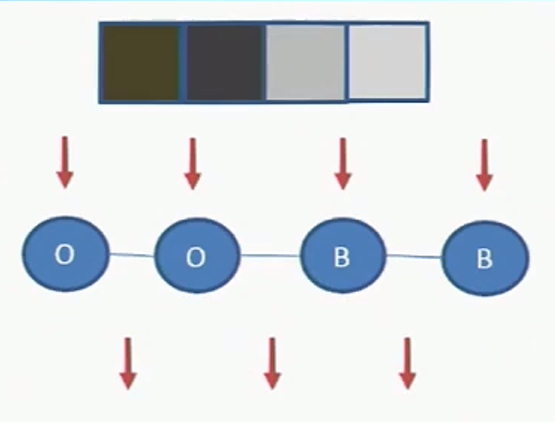
위 그림과 같이 4개의 pixel이 정의되어 있고 가 같은 case를 생각해보자. 빨간색 화살표의 상단은 Regional cost를 하단은 Boundary cost를 의미한다. 보시다시피 잘 매칭되어 있으므로 모든 cost가 낮은 것을 볼 수 있다.
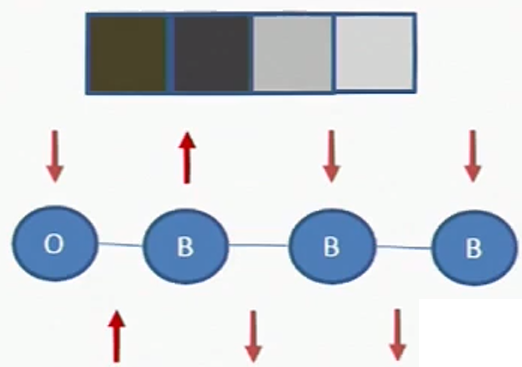
하지만, 위 그림과 같이 4개의 pixel이 정의되어 있고 가 같은 case를 생각해보자. Regional Cost는 2번째 pixel에서 검정색은 obj일 확률이 높기 때문에 Cost가 증가하게 된다. 다음으로 Regional Cost는 1번째와 2번째 pixel사이에서 이므로 를 고려해야하고 색이 거의 비슷하기 때문에 Cost가 증가하게 된다.
따라서, 첫 번째 그림에서 cost가 두 번째 그림에서의 Cost보다 낮게된다. 즉, 첫 번째 그림에서의 로 Segmentation해야한다. 하지만, 위 그림은 4개의 pixel로 이루어진 상황에서만 가능하며, 만일 100x100 이미지라면, 총 개의 상황의 cost를 모두 계산해야한다.
5. Object Segmentation via Graph Cuts
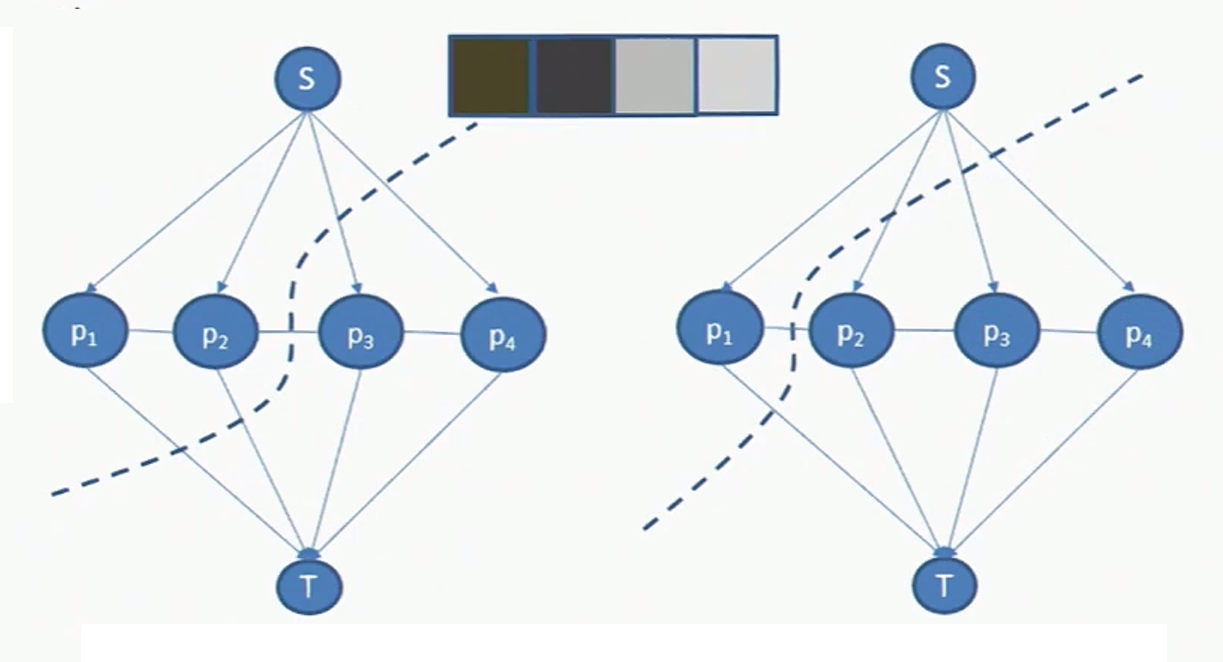
이미지의 크기가 커질수록 cost를 모두 비교하기 어렵기 때문에, 우리는 Graph cut이라는 알고리즘을 이용하여, Segmentation을 진행한다.
Graph cut을 수행하기 위해서는 Node, Edge, Sink, Source로 이루어지 Graph로 변환해야한다. 이 때, Edge의 가중치로 주는 식은 아래의 Table을 따른다.

6. Max-flow/Min-cut theorem
앞선 방식에 따라서 그래프를 생성했다면, 아래와 같은 방식으로 Segmentation을 진행한다.
- Source에서 Sink로 가는 path를 찾아낸다. (bfs, dfs)
- 최대 유량을 계산하여 지나간 path의 유량을 최대 유량만큼 빼준다.
- Source에서 Sink로 가는 길이 더 존재한다면, 1~2번을 반복해준다.
- 더이상 길이 존재하지 않는다면, 유량이 0인 edge를 기준으로 나뉘어진 node를 이용하여 Segmentation을 수행한다.
해당 원리는 크게 중요하지 않고, 궁금하다면 최대유량 알고리즘에 대해서 공부해보도록 하자.
KAIST 김창익 교수님의 강좌를 참고하였음.(https://www.youtube.com/watch?v=26QX41qajD0&t=1864s)