"가상 면접 사례로 배우는 대규모 시스템 설계 기초"를 읽고 정리한 글입니다 :)
키-값 저장소(Key-Value Store)는 키-값 데이터베이스라고도 불리는 비 관계형 데이터베이스이다. 이 저장소에 저장되는 값은 고유 식별자(Identifier)를 키로 가지는데, 키와 값 사이의 이런 연결 관계를 Key-Value Pair라고 지칭한다.
key-value pair에서 키는 유일해야 한다. 키는 일반 텍스트일 수도 있고 해시 값일 수도 있는데, 성능상의 이유로 키는 짧을수록 좋다.
단일 서버 키-값 저장소
키-값 저장소를 설계하는 가장 직관적인 방법은 key-value pair 모두를 메모리에 해시 테이블로 저장하는 것이다. 이 방법은 빠른 속도를 보장하지만, 모든 데이터를 메모리 안에 두는 것이 불가능할 수 있다는 단점이 있다. 그렇기 때문에 데이터를 압축하거나 자주 사용하는 데이터만 메모리에 두고 나머지는 디스크에 저장할 수 있다. 하지만 이 방법도 많은 데이터를 저장하기에는 부족하며, 결국 분산 키-값 저장소를 사용해야할 것이다.
분산 키-값 저장소
분산 키-값 저장소는 분산 해시 테이블이라고도 불리며, key-value Pair를 여러 서버에 분산시켜 저장한다. 분산 시스템을 설계할 때는 CAP 정리를 이해하고 있어야 한다.
CAP 정리
CAP 정리는 데이터 일관성(Consistency), 가용성(Availability), 파티션 감내(Partition Tolerance)라는 세가지 요구사항을 동시에 만족하는 분산 시스템을 설계하는 것은 불가능하다는 정리이다.
이 3가지 요구사항에 대해 조금더 설명하자면...
- 데이터 일관성: 분산 시스템에 접속하는 모든 클라이언트는 어떤 노드에 접속했느냐에 관계없이 언제나 같은 데이터를 보게 되어야 한다.
- 가용성: 분산 시스템에 접속하는 클라이언트는 일부 노드에 장애가 발생하더라도 항상 응답을 받을 수 있어야 한다.
- 파티션 감내: 파티션은 두 노드 사이에 통신 장애가 발생하였음을 의미한다. 파티션 감내는 네트워크에 파티션이 생기더라도 시스템은 계속 동작해야 한다는 것을 뜻한다.
CAP 정리는 이들 가운데 어떤 두 가지를 충족하려면 나머지 하나는 반드시 희생되어야 한다는 것을 의미한다.
키-값 저장소는 세 가지 요구사항 중 어떤 두 가지를 만족하냐에 따라 CP 시스템, AP 시스템, CA 시스템으로 분류할 수 있다. 이 중 CA 시스템은 파티션 감내를 희생하는데, 네트워크 장애는 피할 수 없는 일로 여겨지므로 분산 시스템은 반드시 파티션 문제를 감내할 수 있도록 설계되어야 한다. 그렇기에 실세계에 CA 시스템은 존재하지 않는다.
예시
분산 시스템은 파티션 문제를 피할 수 없다. 그리고 CAP 정리에 따라 파티션 문제가 발생하면 일관성과 가용성 사이에서 하나를 선택해야 한다.
n1, n2, n3 3개의 서버가 있고, n3 서버가 장애가 나 파티션 문제가 발생한 상황을 가정하자. 만약 n3에 기록되었으나 아직 n1 및 n2로 전달되지 않은 데이터가 있다면, n1과 n2는 오래된 사본을 가지고 있을 것이다.
여기서 가용성 대신 일관성을 선택한다면(CP 시스템) 세 서버 사이에 생길 수 있는 데이터 불일치 문제를 피하기 위해 n1과 n2에 대해 쓰기 및 읽기 연산을 중단시켜야 한다. 이 경우 가용성이 깨지게 된다. 은행권 시스템은 데이터 일관성을 양보할 수 없기에, 일반적으로 가용성을 포기하고 상황이 해결될 때까지 오류를 반환할 것이다.
하지만 일관성 대신 가용성을 선택한 시스템(AP 시스템)은 설사 낡은 데이터를 반환할 위험이 있더라도 읽기 연산을 계속 허용해야 한다. 마찬가지로 쓰기 연산 역시 계속 허용할 것이고, 파티션 문제가 해결된 뒤에 새 데이터를 n3에 전송할 것이다.
데이터 파티션
대규모 애플리케이션의 경우 전체 데이터를 한 대 서버에 모두 저장하는 것은 불가능하기에, 데이터를 작은 파티션으로 분할하여 여러 대의 서버에 저장할 수 있다. 데이터를 파티션으로 나눌 때는 다음 두가지 문제를 고려해야 한다.
- 데이터를 여러 서버에 고르게 분산할 수 있는가
- 노드가 추가되거나 삭제될 때 데이터의 이동을 최소화할 수 있는가
안정 해시가 이 문제를 해결하는데 적합한 기술이다. 안정해시를 사용하여 데이터를 파티션하면 다음과 같은 이점이 있다.
- 규모 확장 자동화(Automatic Scaling) : 시스템 부하에 따라 서버가 자동으로 추가되거나 삭제될 수 있다.
- 다양성(Heterogeneity) : 각 서버의 용량에 맞게 가상 노드의 수를 조정할 수 있다. 즉, 고성능 서버는 더 많은 가상 노드를 가질 수 있다.
데이터 다중화
높은 가용성과 안정성을 확보하기 위해 데이터를 N개 서버에 비동기적으로 다중화(Replication)할 필요가 있다. 이 N개 서버를 선정하는 방법은 해시 링에서 시계 방향으로 링을 순회할 때 만나는 첫 N개 서버에 데이터 사본을 보관하는 것이다.
가상 노드를 사용한다면 선택한 N개의 노드가 대응될 실제 물리 서버의 개수가 N보다 작아질 수 있다. 이 문제를 피하려면 노드를 선택할 때 같은 물리 서버를 중복 선택하지 않도록 해야한다.
같은 데이터 센터에 속한 노드는 정전, 네트워크 이슈 등의 문제를 동시에 겪을 가능성이 있다. 즉, 안정성을 담보하기 위해 데이터의 사본을 다른 센터의 서버에 보관해야 한다.
데이터 일관성
여러 노드에 다중화된 데이터는 적절히 동기화되어야 한다. 정족수 합의(Quorum Consensus) 프로토콜을 사용하면 읽기/쓰기 연산 모두에 일관성을 보장할 수 있다. 정족수 합의는 다음 3가지 정의를 통해 연산의 성공 여부를 판단한다.
- N : 사본 개수
- W : 쓰기 연산에 대한 정족수. 쓰기 연산이 성공하려면 적어도 W개의 서버로부터 성공 응답을 받아야 함
- R : 읽기 연산에 대한 정족수. 읽기 연산이 성공하려면 적어도 W개의 서버로부터 성공 응답을 받아야 함
정족수 합의에서는 중재자라는 개념이 있는데, 중재자(Coordinator)는 클라이언트와 노드 사이에서 프록시(Proxy) 역할을 하며, 읽기 및 쓰기 연산의 성공 여부를 판단한다.
만약 W가 1이라면, 중재자는 최소 한 대의 서버로부터 쓰기 성공 응답을 받아야 쓰기 연산이 성공했다고 판단한다. 이 W, R, N의 값을 정하는 것은 응답 지연가 데이터 일관성 사이의 타협접을 찾는 전형적인 과정이다. W = 1 혹은 R = 1인 구성은 응답 속도는 빠를 것이다. W나 R의 값이 1보다 큰 경우 데이터 일관성의 수준은 향상될 테지만, 응답 속도는 역으로 느려질 것이다.
W + R > N인 경우 강한 일관성(Strong Consistency)이 보장되는데, 일관성을 보증할 최신 데이터를 가진 노드가 최소 하나는 겹칠 것이기 때문이다.
일관성 모델
일관성 모델(Consistency Model)은 데이터 일관성의 수준을 결정한다. 그 종류는 아래와 같다.
- 강한 일관성(Strong Consistency) : 모든 읽기 연산은 가장 최근에 갱신된 결과를 반환한다.
- 다시 말해 클라이언트는 절대로 낡은(out-of-date) 데이터를 보지 못한다.
- 약한 일관성(Weak Consistency) : 읽기 연산은 가장 최근에 갱신된 결과를 반환하지 못할 수 있다.
- 최종 일관성(Eventual Consistency) : 약한 일관성의 한 형태로, 갱신 결과가 결국에는 모든 사본에 반영(즉, 동기화)되는 모델이다.
- Eventual Consistency의 번역에 대해서는 재미있는 글이 있어서 추가로 남긴다.
강한 일관성을 달성하는 일반적인 방법은, 모든 사본에 현재 쓰기 연산의 결과가 반영될 때까지 해당 데이터에 대한 읽기/쓰기를 금지하는 것이다. 하지만 이 방법은 고가용성 시스템에는 적합하지 않다. 그렇기 때문에 많은 저장소들에서 최종 일관성 모델을 택하고 있다. 최종 일관성 모델을 따를 경우, 쓰기 연산이 병렬적으로 발생하면 시스템에 저장된 값의 일관성이 깨질 수 있다. 이 문제는 클라이언트가 해결해야 하며, 클라이언트 측에서 데이터의 버전 정보를 활용해 일관성이 깨진 데이터를 읽지 않도록 할 수 있다.
비 일관성 해소 기법: 데이터 버저닝
데이터를 다중화하면 가용성은 높아지지만 사본 간 일관성이 깨질 가능성이 높아진다. 버저닝(Versioning)과 벡터 시계(Vector Clock)는 그 문제를 해소할 수 있다. 자세한 설명은 생략하겠다.
장애 감지
분산 시스템에서는 그저 한 대 서버가 특정 서버가 죽었다고 보고한다고, 해당 서버를 장애처리하지 않는다. 보통 2대 이상의 서버가 똑같이 특정 서버의 장애를 보고해야, 해당 서버에 실제 장애가 발생했다고 간주한다.
이것을 가장 쉽게 감지하는 방법은 모든 노드 사이에 멀티캐스팅(Multicasting) 채널을 구축하는 것이다. 하지만 이 방법은 서버가 많을 때는 분명히 비효율적이다.
보통 가십 프로토콜(Gossip Protocol)과 같은 분산형 장애 감지(Decentralized Failure Detection) 솔루션을 채택하는 편이 보다 효율적이다. 가십 프로토콜의 동작 원리는 다음과 같다.
- 각 노드는 멤버십 목록을 유지한다. 멤버십 목록은 각 멤버 ID와 그 박동 카운터(Heartbeat Counter) 쌍의 목록이다.
- 각 노드는 주기적으로 자신의 박동 카운터를 증가시킨다.
- 각 노드는 무작위로 선정된 노드들에게 주기적으로 자기 박동 카운터 목록을 보낸다.
- 박동 카운터 목록을 받은 노드는 멤버십 목록을 최신 값으로 갱신한다.
- 어떤 멤버의 박동 카운터 값이 지정된 시간동안 갱신되지 않으면, 해당 멤버는 장애(Offline) 상태로 간주한다.
시스템 아키텍쳐 다이어그램
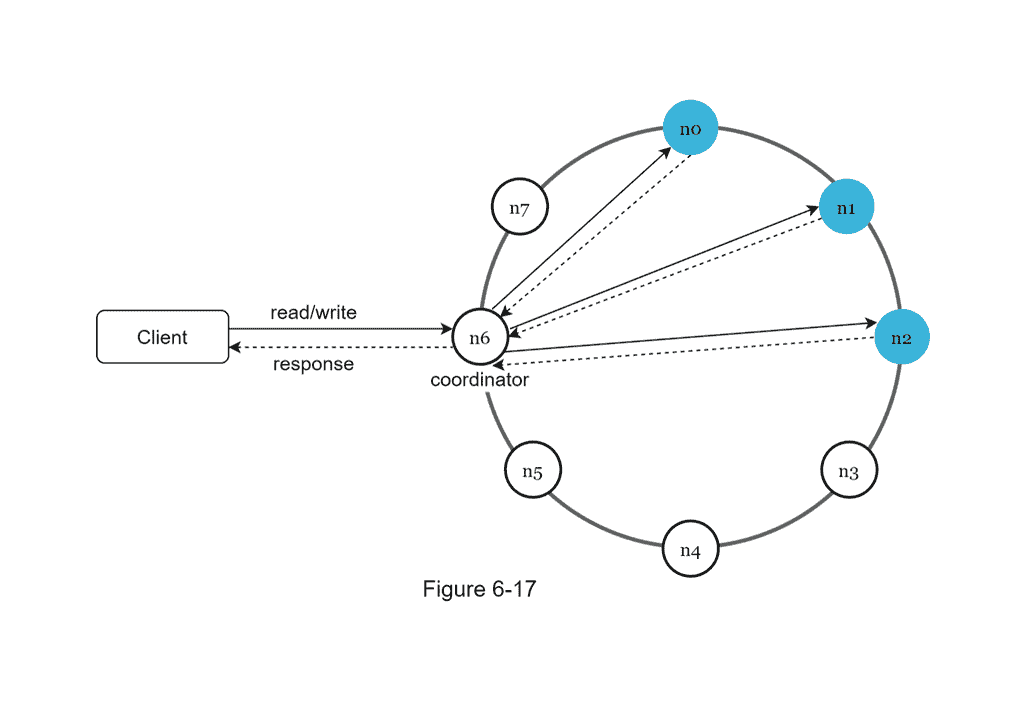
앞에서 설명한 내용들을 기반으로 위와 같은 다이어그램을 그릴 수 있다. 이 아키텍쳐의 주 기능은 다음과 같다.
- 클라이언트는 키-값 저장소의 Read/Write 연산을 사용한다.
- 중재자는 클라이언트에게 키-값 저장소에 대한 프록시 역할을 한다.
- 노드는 안정 해시의 해시 링 위에 분포한다.
- 노드를 자동으로 추가 또는 삭제할 수 있도록, 시스템은 완전히 분산된다. (Decentralized)
- 데이터는 여러 노드에 다중화된다.
- 모든 노드가 같은 책임을 지므로, SPOF(Single Point Of Failure)는 존재하지 않는다.
- SPOF : 시스템에서 동작하지 않으면 시스템 전체가 중단되는 요소
