이번 TIL은 인프런의 "모든 개발자를 위한 HTTP 웹 기본 지식"을 학습하고, 정리한 내용입니다.
만약, 제 글의 내용을 퍼갈 시에는 " 모든 개발자를 위한 HTTP 웹 기본 지식 "도 출처에 첨부하시기 바랍니다.
이제 "URI"와 "웹 브라우저의 요청 흐름"에 대해서 알아보자!!
먼저 URI , URL 등의 의미에 대해서 살펴보고, 그 다음에 웹 브라우져의 요청이 어떤 식으로 http 메세지로 만들어지는지 알아보자!
URI(Uniform Resource Identifier)
구지 번역하자면, " 리소스를 식별하는 통합된 방법 "
=> 여기서 "리소스를 식별한다" 라는 말은 "사람들을 주민번호로 식별한다" 이정도로 생각하면 이해가 쉽다.
=> 즉, 사람을 민증으로 식별하듯이 리소스를 식별하는 방법!!
URI vs URL vs URN
논란 거리가 있을 때, 찾아보는 표준 스펙 문서에 따르면,
URI는 로케이터(locator), 이름(name) 또는 둘다 추가로 분류될 수 있다.
그럼 로케이터(locator)는 뭐고 이름(name)은 뭐지??
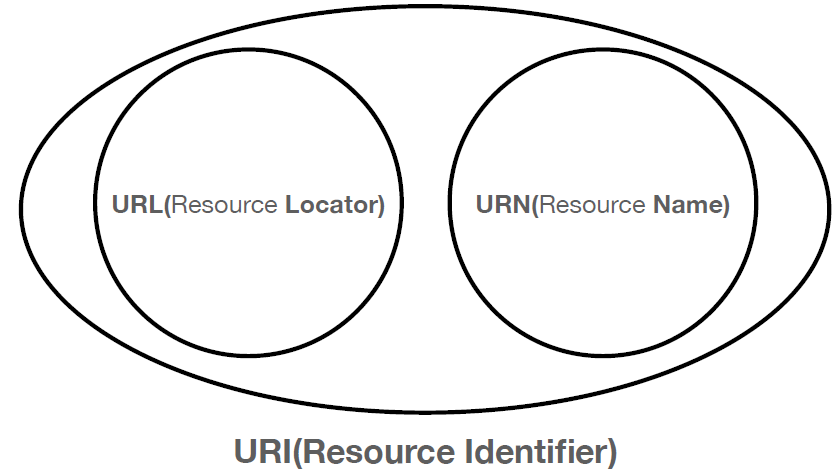
그림을 보면, URI 라는 가장 큰 개념이 있다. URI는 위에서 말했듯이 리소스를 식별하는 방법이다. 그리고 이 방법에는 크게 2가지가 있는데, URL 과 URN 이다.
예를 들어서, "잠실 사는 강개리"에서 "잠실"은 로케이터 이고, "강개리"는 네임이다. 즉, 잠실을 찾아가면 강개리가 있겠죠?? 아니면, 그냥 강개리 이름만 달랑 들고, 개리를 찾으러 다닐 수도 있을 거다.
- URL과 URN의 구조
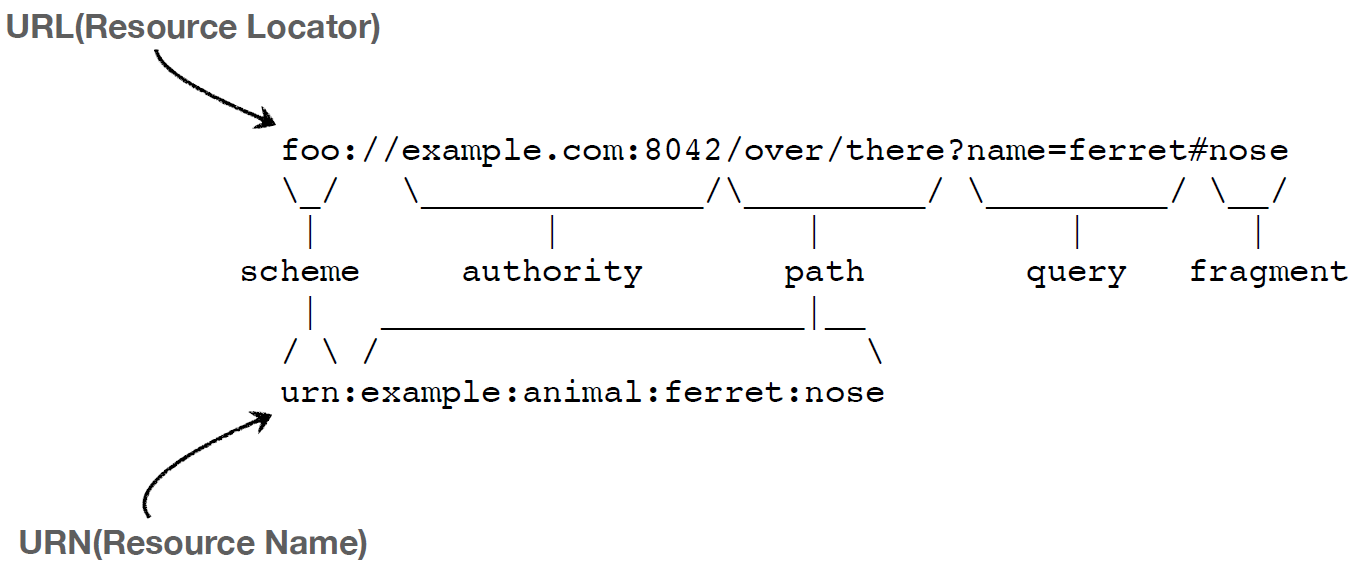
=> 문제는 이름을 부여하면, 거의 찾을 수가 없다. 중간에 어딘가 이름을 짚어넣으면, 해당 리소스가 나오는 게 맵핑이 되있어야 하는데, 그런 점이 어렵다. 그래서 거의 URL만 쓴다. URN은 이런 게 있다는 정도만 알아두자!!

=> 웹 브라우져의 HTML 파일만 리소스가 아니다. 실시간 교통정보나 URI를 통해 우리가 구분할 수 있는 모든 것이 다 리소스이다.
=> 식별자(아이덴티파이어)는 식별하는데 민증이 필요하다면, 민증이 식별자가 되는 것이다.

웹브라우져에서 URL을 치는 것은 리소스의 위치를 치는 거다.
URN은 해당 리소스의 이름 그 자체이다. 그런데, 이름은 안 변하니까 좋을 것같은데...
URN을 사용하는 대표적인 케이스가 책의 isbn이다.
하지만, 해당 책의 isbn을 검색한다고 정확하게 그 책으로 이동하지는 않다. 최선은 검색엔진을 통한 근접한 결과값을 나올 수 있지만, 실제 그 책으로 이동하는 것은 불가능하다.
다시 말하면, URN으로 해당 리소스를 찾을 수 있는 방법이 보편화 되지 않았다.
즉, 우리 입장에서는 URI와 URL만 알면 된다. => 단순화 시켜보면, URN은 필요없으니까, URI = URL 이라는 공식이 성립한다. 이런 이유로, 이 강의에서는 URI와 URL을 같은 의미로 받아들인다.
- URL 분석 (q는 쿼리를 의미한다)
https://www.google.com/search?q=hello&hl=ko

1. scheme (스키마)

=> http나 https를 쓰면, 포트는 생략 가능하다!!
=> https는 http에 강력한 보안이 추가된 업그레이드 버전이라고 생각하면 된다.
2. userinfo (유져인포)

3. host (호스트)

4. port (포트)

5. path (패스)
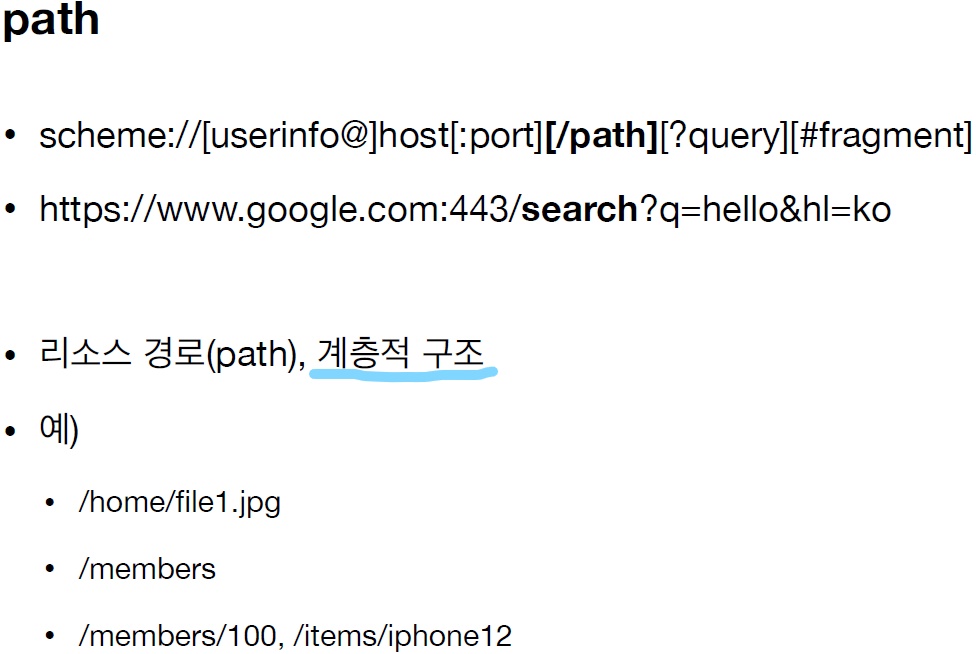
=> path는 해당 리소스 있는 경로이다. 보통 계층적 구조로 되있다.
=> 예를 들어, members/100는 members 디렉토리 하위에 있는 100 번의 정보를 의미한다.
6. query (쿼리)
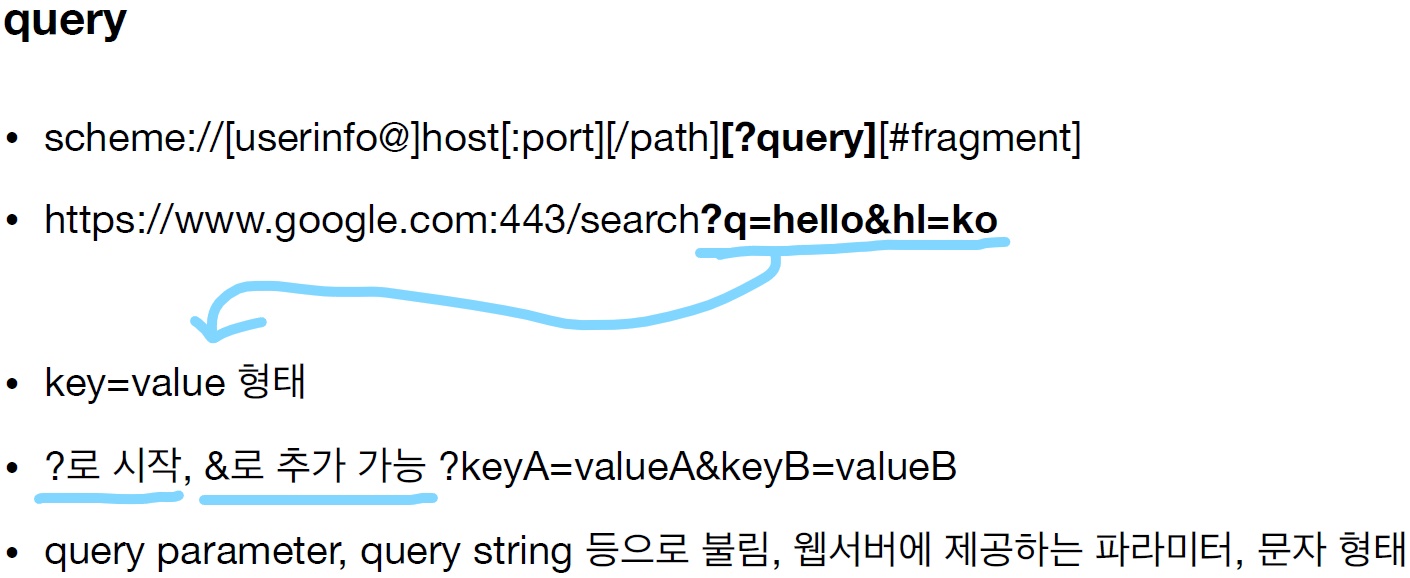
=> 공식 명칭은 "쿼리"인데, 쿼리 파라미터나 쿼리 스트링으로 불리기도 한다.
7. fragment (프레그먼트)

=> 보통, HTML 내부에서 갑자기 중간으로 이동하고 싶을 때, 사용한다.
=> fragment는 잘 사용하지는 않는다.
다음 시간에는 URL을 호출했을 때, 실제 웹 브라우져에서 네트워크를 어떻게 패킷으로 만드는지 그리고 어떻게 흘러가는 지에 대해서 알아보자!
