
원시 타입
자바스크립트에서 원시 타입의 데이터(primitive data types; 원시 자료형)는 객체가 아니면서 method를 가지지 않는 6가지의 타입
string, number, bigint, boolean, undefined, symbol, (null)
- 원시 타입들은 뭐가 특별해서 원시 타입이라고 부르는 걸까??
primitive는 원시, 초기의 라는 뜻이다. 다시 말해서, 초기 컴퓨터 언어에 쓰였던 데이터 타입들이라고 해서 원시 타입이라고 부른다.
출처 : The basics of BASIC, the programming language of the 1980s.
옛날 컴퓨터에서 사용되던 BASIC이라는 컴퓨터 언어인데, 우리가 알고 있는 string과 number는 쉽게 찾을 수 있지만, 배열에 상응하는 녀석은 찾기 어렵다. 이 당시만 해도 배열이 구현 가능했지만, 보통 사이즈가 제한되어 있었다. 그래서, 배열이 마치 원시 자료형 같다.

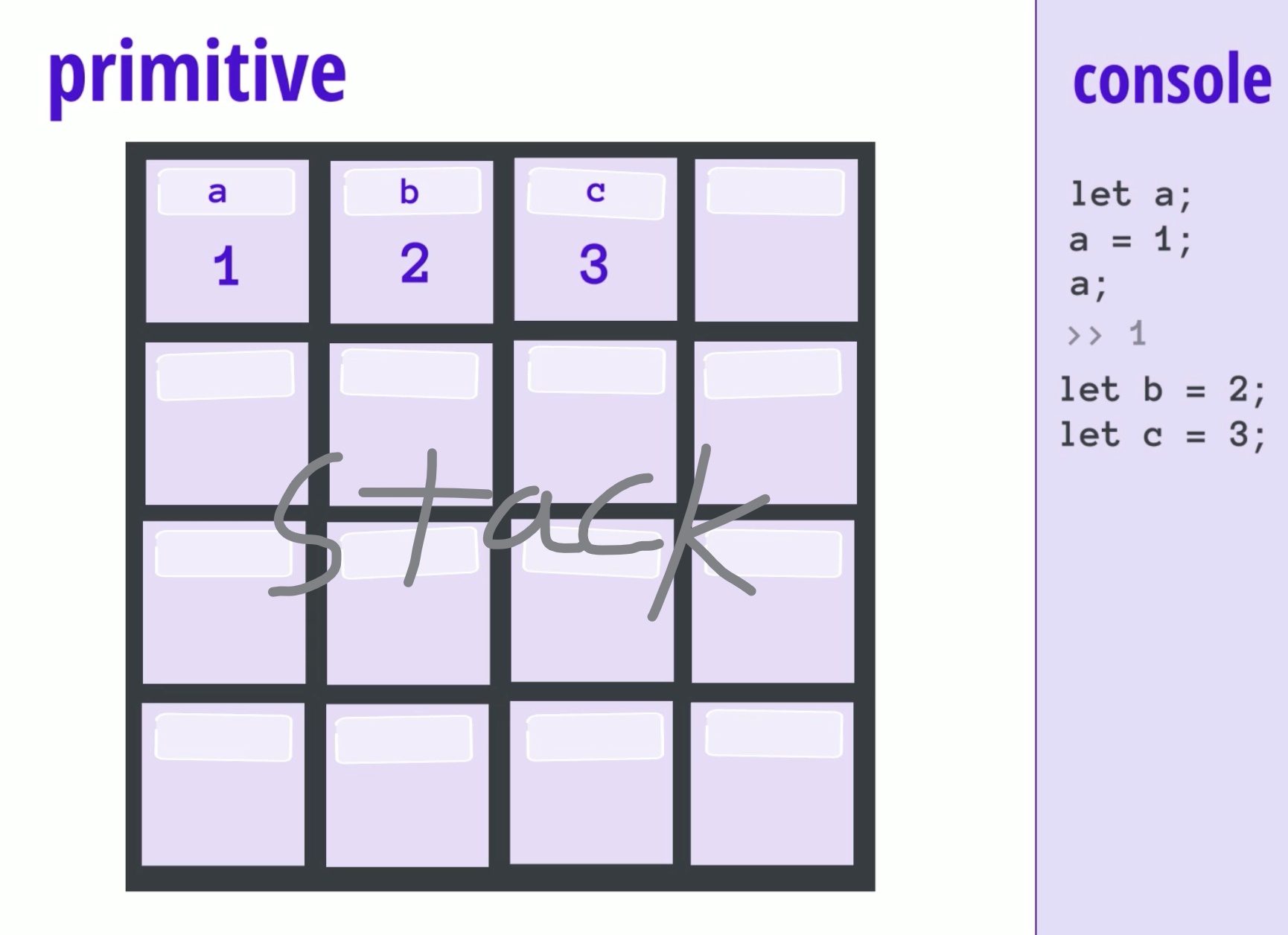
다시 말해서, 데이터 보관함 한 칸에 하나의 데이터만 넣을 수 있는 그 때의 "원시적인" 방식으로 저장되는 것들을 원시 타입이라고 부른다. 이때, 원시 타입이 저장되는 저장소를 stack이라고 부른다.
참조 타입
const colors = ['Blue', 'Green', 'Red', 'Pink']; // 사용될 수 있는 색의 종류를 담고 있다.
const archer = {
name: 'tyrande',
race: 'night elf',
str: 29,
dex: 49,
// ...
} // 특정 게임의 궁수(archer)의 정보를 담고 있다.참조 자료형은 딱 봐도 하나의 주제는 있지만 분명 서로 다르고, 여러 개의 데이터를 가지고 있는 것을 확인하실 수 있다.
자바스크립트에서 원시 자료형이 아닌 모든 것은 참조 자료형(=reference data type; 참조 타입)이다. 대표적으로, 배열([])과 객체({}), 함수(function(){})가 있다.
과거에 컴퓨터가 처음 사용되던 시절에는 배열, 즉 리스트라는 개념을 구현하기가 어려웠다. 그래서 띄어쓰기, 탭, 쉼표 등으로 데이터를 구분하여 배열과 비슷한 형태로 자료 구조를 구현하기 시작했다.
- 그런데, 왜 따로 자료 구조를 구현해야만 했을까?
바로, Stack에는 변수에 넣을 수 있는 데이터 크기가 제한되기 때문이다.

문자열의 길이가 100 이상인 경우 변수에 저장할 수 없다고 가정을 한다면, 위와 같은 배열의 요소는 34개 이상이 될 수 없다. 34개 이상인 경우 또 새로운 array를 만들고... 그 array의 맨 끝까지 찾으면 다시 다음 array를 찾고... 아주 번거로운 작업이 되버린다. 이런 이유로 "데이터의 크기가 동적으로 변하는" 특별한 데이터 보관함이 필요해졌다. 우리는 그 특별한 데이터 보관함을 Heap이라고 부른다.

다시말해서, 데이터가 언제 늘어나고 줄어들지 모르기 때문에 별도의 저장공간을 마련하여 따로 관리하는 것이다. Stack에 저장되는 변수에는 원시값 혹은 주소만 지정할 수 있고, 주소는 크기가 변하는 특별한 데이터 저장소를 참조(refer)하게 된다.

Achievement Goals
원시 자료형과 참조 자료형
- 원시 자료형(primitive type)과 참조 자료형(reference type)의 구분이 왜 필요한지에 대해서 이해할 수 있다.
- 원시 자료형과 참조 자료형의 차이를 이해하고, 각자 맞는 상황에서 사용할 수 있다.
- 원시 자료형이 할당될 때에는 변수에 값(value) 자체가 담기고, 참조 자료형이 할당될 때는 보관함의 주소(reference)가 담긴다는 개념을 코드로 설명할 수 있다.
- 참조 자료형은 기존에 고정된 크기의 보관함이 아니라, 동적으로 크기가 변하는 특별한 보관함을 사용한다는 것을 이해할 수 있다.
1. 원시 자료형(primitive type)과 참조 자료형(reference type)의 구분이 왜 필요한지에 대해서 이해할 수 있다.
Stack에 저장될 수 있는 데이터의 크기는 매우 제한적이고 정적이다. 원시 자료형과 달리, 참조 자료형은 사이즈가 크며, 동적으로 변하기 때문에, 동적인 크기를 충족시켜줄 수있는 특별한 보관함이 필요하다. 객체나 배열의 크기나 너무 크다면, 배열의 요소들을 쪼개서 arr1, arr2, arr3 등으로 상당히 번거로운 방법을 써야 하는데, 이러한 번거로움을 없애고자 Heap이라는 저장소가 등장했고, 하나의 주소값을 가진 arr에서 모든 동적인 작업이 가능해졌기 때문에, 두 자료형은 구분이 필요하다.
2. 원시 자료형과 참조 자료형의 차이를 이해하고, 각자 맞는 상황에서 사용할 수 있다.
참조 타입은 변수에 값을 직접 저장하지 않는다. 변수에 저장되는 것은 메모리 안에서 객체의 위치를 가리키는 "포인터"이다. 무엇이 저장되느냐, 이것이 원시 타입과 참조 타입의 가장 큰 차이이다.
데이터 사이즈가 크고, 하나의 주제 맞게 여러 자료형을 동적으로 저장해야 된다면, 참조 자료형을 사용해야지만, 하나의 데이터 타입으로만 모든 게 가능하다면, 원시 타입이 더 좋은 선택이다.
3. 원시 자료형이 할당될 때에는 변수에 값(value) 자체가 담기고, 참조 자료형이 할당될 때는 보관함의 주소(reference)가 담긴다는 개념을 코드로 설명할 수 있다.

참조 타입은 a라는 배열이 선언과 할당이 되면, stack에는 heap의 주소(reference)만 저장이 된다. 그리고 실질적으로, 배열의 요소들은 Heap의 1번이라는 주소에 할당되어 있다.
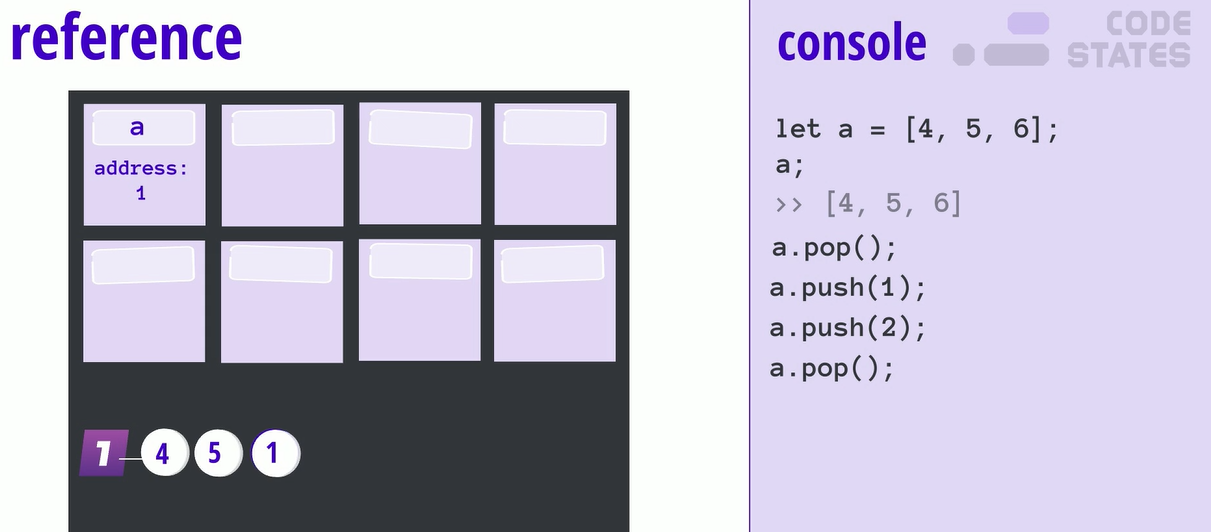
그렇기 때문에, 배열 요소를 삭제하거나 추가하는 거 역시 1번 주소에서 전부 일어난다.

원시 타입의 경우, 각 데이터에 원시 타입 데이터를 복사할 경우에 주소값이 아니라 데이터 그 자체의 값이 복사되기 때문에, b에서 데이터 값을 변경해도, a는 영향을 받지 않는다.
그러나, 참조 타입은 다르다.

참조 타입의 경우, 데이터 값이 아닌 주소 값을 복사는 것이기 때문에, 같은 주소를 복사한 f에서 어떤 변화가 일어나면, 같은 주소를 가진 e에서도 동일한 변화가 일어난다. 다시 말해서, e와 f는 전부 1번이라는 같은 주소지를 point하고 있다.
4. 참조 자료형은 기존에 고정된 크기의 보관함이 아니라, 동적으로 크기가 변하는 특별한 보관함을 사용한다는 것을 이해할 수 있다.
위에서 언급했듯이, 참조 자료형은 stack에 저장되는 a라는 변수에 Heap의 주소값만을 저장한다. 그리고 해당 주소를 가진 Heap은 stack처럼 저장하는 크기에 제한이 있지 않기 때문에 값은 곳에서 데이터가 추가됐다가 삭제됐다가 가능하다.

- 추가적으로 학습한 내용
레퍼런스(reference)=참조 이란
우리가 흔히 참고자료를 찾을 때, 레퍼런스(reference)를 찾는다고 종종 이야기한다. 이 레퍼런스라는 단어는 본래 참조할 만한 자료라는 영어 단어로 실생활에서 자주 쓰이지만, 컴퓨터 공학에서는 변수가 가리키고(refer)있는 데이터의 참조한다는 의미로 사용된다. 평소에 코딩을 배울 때, 우리는 쉽게 변수의 정보를 읽는다라고 이야기 하지만, 교육 엔지니어님은 종종 "참조"한다라는 표현을 사용하시는데, 이 이유가 바로 여기에서 온다. 읽는 것이 아니라, 그 변수의 주소를 "참조"하여 실제 변수가 있는 장소에 어떤 데이터가 있는지 도착하고 나서야 비로소 "읽을 수" 있기 때문이다.
Null에 관한 오류
Null에 대해서 신기한 사실을 알게 됐다.
typeof 라는 메서드를 사용하면, 원시값을 종류를 알려준다.

그런데, null은 타입이 object라고 뜬다. object는 참조타입이고, object인 null도 참조타입인가 하고, 혼란스러울 때, 해답을 찾았다.
정리해보자면, 이 부분은 JS를 개발하는 재단에서도 실수라는 것을 인정했다. null은 원시 타입과 거의 같게 사용된다. 작동 방식 또한 다른 원시 타입과 같다. 하지만, 엄밀하게 따지자면 원시 타입이라고 볼 수 없다.
어떤 값이 null인지 아닌지를 확인하기 위해서는 typeof가 아닌
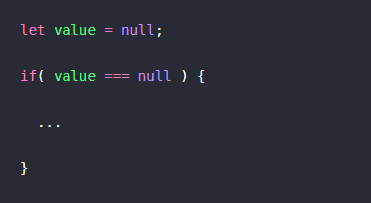
if절을 통해서 확인할 수 있다.
원시 래퍼 타입
과거에 이런 질문을 올린 적이 있었다.

그때는 그냥 그런가보다 하고 넘어갔지만, 이번 기회는 통해서 확실한 이유를 알게 됐다.
문자열은 원시 래퍼 타입이었던 것이다!!!!
원시 래퍼 타입은 원시 타입 중에서 일부는 마치 참조 타입처럼 사용할 수 있는 타입을 말한다. 다시 말해서, 원시 타입을 객체처럼 메소드를 사용하는 등 더 편리하게 사용할 수 있는 타입들을 말한다.
원시 타입 중 하나인 String을 예로 들어보자!!

분명 원시 타입인데, 객체처럼 메소드가 사용이 가능하다. 이렇게 사용가능한 메소드들을 우리는 원시 메소드라고 부른다. 그리고 이런 원시 메소드들을 사용할 수 있는 이유는 바로 이런 원시 래퍼 타입의 존재들 덕분이다.
- 원시 래퍼 타입의 종류
- String
- Number
- Boolean
=> 이들도 엄연한 원시 타입이다! 그냥 원시 래퍼 타입은 부분집합 정도로 생각하자!!
- 원시 래퍼 타입의 특징
원시 타입을 객체처럼 사용하는 순간, 자바스크립트 내부에서 사용하는 데이터의 인스턴스를 만들게 됩니다. 이렇게 만들어진 객체는 코드를 실행 후 바로 다음 줄에서 파괴됩니다.
이러한 과정을 오토박싱(autoboxing) 이라고 합니다.
말이 좀 어려워서 예시로 더 이해해보자!!
// ex1)
let name = "bit"
console.log(name.concat(" coin")); // => "bit coin"
// JS는 위의 코드를 내부적으로 이런 식으로 작동시킨다.
let name = "bit";
// 원시 타입을 객체처럼 사용하는 순간, JS는 임시변수(temp)를 만든다.
let temp = new String(name); // 임시변수의 메서드를 만들어준다
console.log(temp.concat("coin")); // 실행 후!
temp = null // 메모리 해제
// 바로 이런 이유로, concat이 원본을 수정하지 않는다는 것도 알 수있다.
/////////////////////////////////////////////////////////////
// ex2)
// 원시 래퍼 타입에 점 연산자를 써보자
let name = "bit";
name.coin = "coin";
console.log(name.coin); // => undefined
// JS는 위의 코드를 내부적으로 이런 식으로 작동시킨다.
let name = "bit";
let temp = new String(name);
temp.coin = "coin"; // 이 한 줄을 실행하면, 곧바로 JS는 temp를 지워버린다.
temp = null; // 파괴되었다.
// console.log 를 실행시키기 위해, 다시 임시변수를 만든다.
let temp = new String(name); // 다시 생성
// 할당을 해준 임시변수를 이미 앞에서 파괴가 됐다.
console.log(temp.coin); // => undefined
정리
- 원시 타입은 문자열, 숫자, 불리언, null, undefined가 있습니다.
- 참조 타입은 원시타입을 제외한 나머지 데이터 타입입니다.
- 원시 타입과 참조 타입의 가장 큰 차이는, 원시 타입은 값이, 참조 타입은 데이터의 주소가 저장된다는 것 이다.
- 원시 래퍼 타입은 String, Number, Boolean이다.
- 원시 래퍼 타입은 원시 타입을 객체 처럼 사용할 수 있도록 한다.
자료 출처
오늘 TIL은 코드스테이츠에서 학습한 내용과 개인적으로 보충 학습한 내용들을 바탕으로 작성됐다.
