서포트 벡터 머신(이하 SVM)은 Binary Classification을 위한 기계학습 알고리즘 중에 하나이다. 즉, 주어진 데이터 세트 혹은 샘플들을 두 가지로 분류하는 알고리즘 이다. Binary Classification 알고리즘에는 SVM 말고도 다양한 알고리즘들이 존재한다. 다른 알고리즘에 비해 분류 성능이 상당히 좋다는 것이 SVM의 강점이고 따라서 다양한 응용에서 사용되고 있다. SVM은 아래 그림과 같이 힌색점과 검정색 점으로 이루어진 데이터 세트를 나누는 결정 경계을 찾는 것이다. 아래 그림과 같이 입력 특징(x1, x2)이 2차원이면 경계선은 일차 직선이 되고 입력특징이 3차원이라면 결정 경계는 2차원 평면이 될 것이다. 결과적으로 결정경계를 찾는다는 것은 주어진 입력 특징보다 한 차원 아래인 초평면(Hyperplane)을 찾는 것이다.
hyperplane : a subspace of one dimension less than its ambient space
Support vector :
Margin :
Normal Vector :
핵심 아이디어
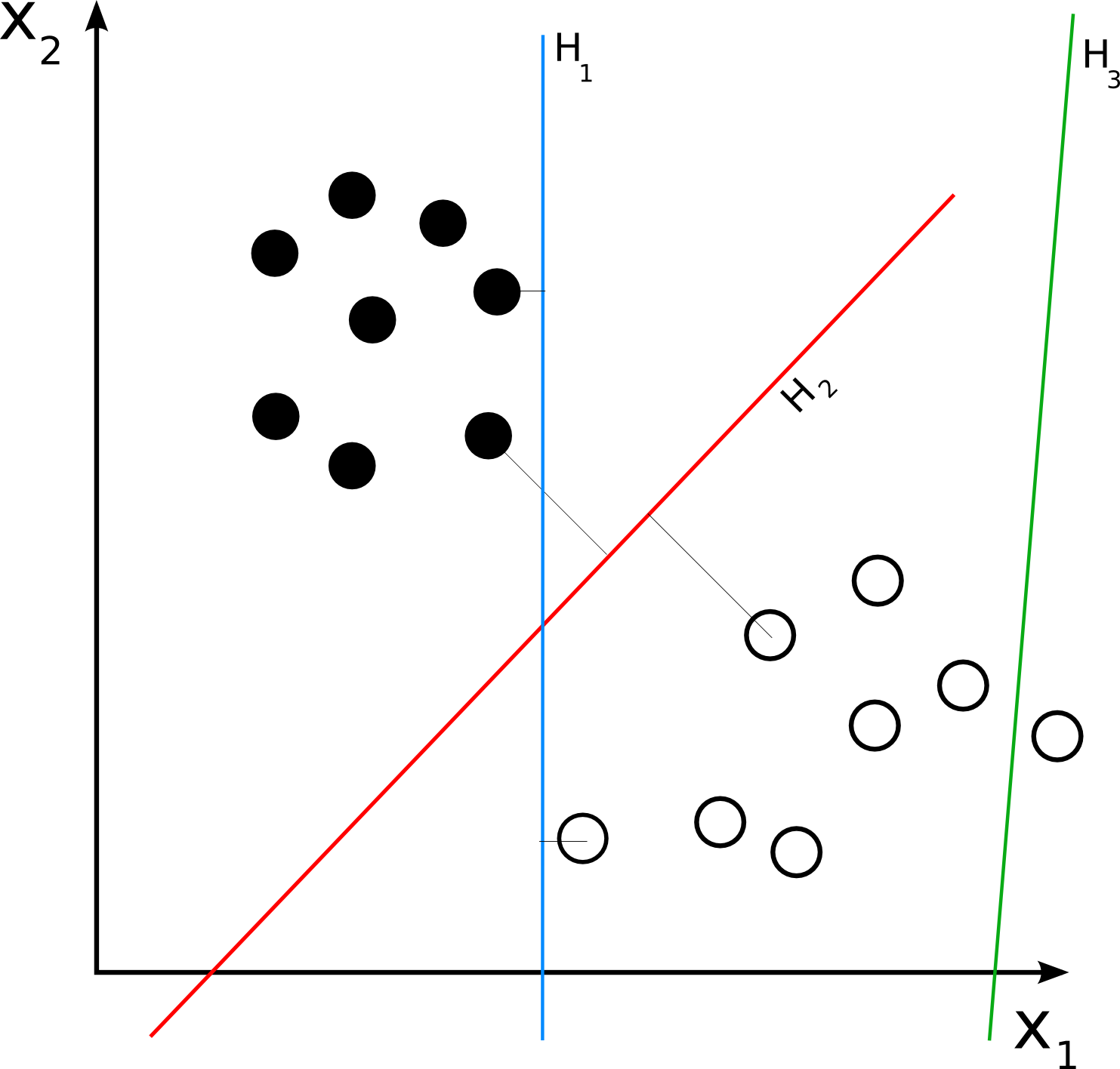
데이터 세트를 두 분류로 나눈는 가장 좋은 방법은 두 그룹 사이를 가장 잘 분류할 수 있는 경계선을 찾는 것이다. 아래 그림에서 H1, H2는 모두 흰색점들과 검정색 점들을 모두 두 분류로 나누는 것이 가능하다. 하지만 H1 보다는 H2가 더 적합하다는 것은 명확하다. H1은 경계선으로 사용가능하지만 H2 보다는 경계선에 가장 가깝게 있는 점들과의 거리가 가깝기 때문에 쉽게 가까운 점들이 경계를 침범할 수 있기 때문이다. 경계선과 가장 가깝게 존재하는 점들을 Support Vector라고 명명한다. SVM의 핵심 아이디어는 경계선과 Support Vector 사이의 간격을 최대로 하는 경계선을 찿는 것이다. Support Vector와 경계선 사이의 간격을 마진(Margin)이라고 명명한다. 그렇다면 마진을 최대로 하는 Support Vector와 경계선 혹은 초평면을 찾으면 된다.
데이터 집합
N개의 샘플로 이루어진 데이터 세트 D는 다음과 같이 정의된다.
D={(xi,yi)∣xi∈Rp,yi∈{−1,1}}i=1N
xi는 P차원의 특징을 가지는 i 번째 샘플 데이터, yi는 1과 -1중 하나의 값을 가지는 i번째 샘플 데이터의 타겟 값이다. 즉, D는 NxP 행렬로 표현될 수 있다.
결정 경계
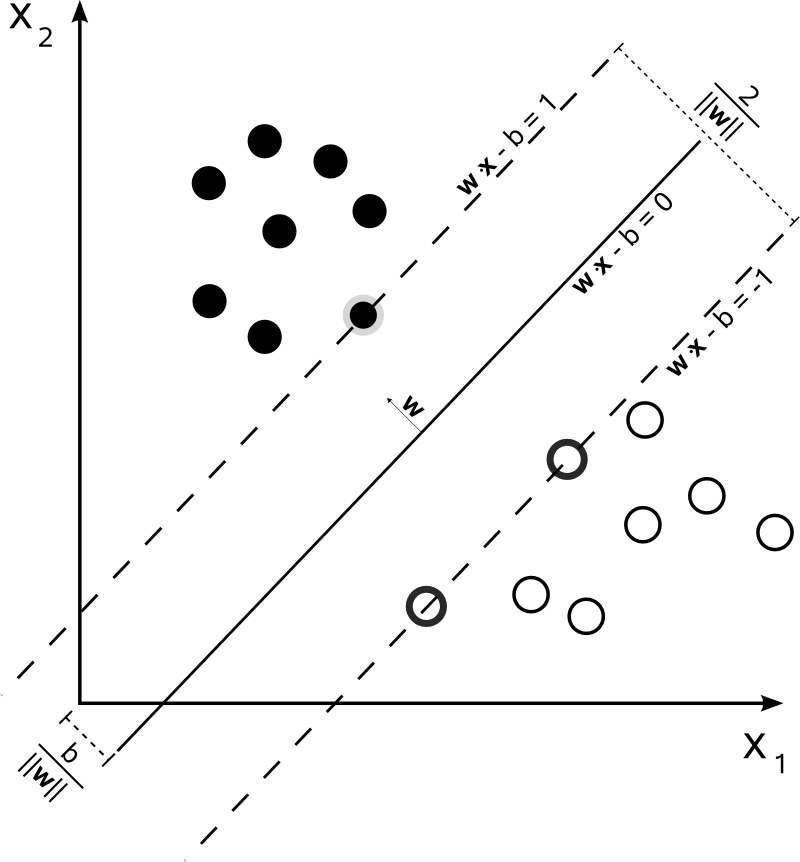
2차원에서 생각해보면 아래 그림과 같이 힌색점들과 검정색 점들 사이를 분류하는 방법은 두 그룹사이를 가로지르는 직선을 긋는 것이다. 그렇다면 이 직선은 어떻게 표현될까요? 일반적으로 어떤 직선(2차원) 혹은 평면(3차원)의 기울기나 경사각을 표현할 때, 해당 직선이나 평면에 수직인 벡터를 사용해서 표현하게 되는데 이러한 벡터를 법선벡터(normal vector)라고 합니다.
2 차원에서 직선의 방정식은 직선에 수직한 법선벡터 W에 대해 원점과의 거리가 d인 직선의 방정식이 될 것이다. 직선의 방정식은 아래와 같다.
w=[w1w2],xi=[x1x2]wTxi+d=0
그렇다면, Support Vector가 경계선과 동일한 거리인 δ 만큼 떨어져서 존재한다고 가정하면 Support Vector를 지나는 직선의 방정식을 생각해 볼 수 있다. Support Vector가 아닌 샘플들은 δ 보다 큰 값을 가지기 때문에 아래 식과 같이 두개의 Support Vector 를 구할 수 있다.
wTxi++d≥δwTxi−+d≤−δ
여기서, 기울기를 나타내는 W 벡터와 거리 d, δ 는 모두 결정된 상수가 아니기 때문에 δ로 양변을 나누고, 상수 b를 적용하면 아래 식과 같다.
wTxi++b≥1wTxi−+b≤−1
위 식을 타겟벡터에 대해 곱하면 아래와 같이 하나의 식으로 정리 할 수 있다.
yi(wTxi+b)≥1yi={+1−1 for xi+ for xi−
결과적으로 마진이 적어도 1보다 크고, 위식을 만족하는 최대 마진을 찾으면 된다. 그렇다면 최대 마진은 어떻게 구할 수 있을까?
최대 마진 구하기
$ \mathbf{x}^-$ 는 x+ 가 W방향으로 λ 만큼 평행이동한 것으로 표현할 수 있다.
결과적으로 마진은 입력 샘플들과는 무관하게 경계선의 법선벡터의 L2 norm으로 정의되고, 마진을 최대로 하는 것은 L2 norm을 최소화 하는 것과 같다. 위식은 제곱근을 포함하고 있기 때문에 풀기가 어렵다. 계산의 편의를 위해서 제곱을 해주고 2로 나누어 주어도 최적화를 만족하는 해는 변하지 않는다. 따라서, SVM의 목적식은 제약식을 가지는 최적화 문제로 정의된다.
라그랑주 승수법을 이용하면 위의 문제를 다음과 같은 안장점(영어: saddle point)을 찾는 문제로 나타낼 수 있다. Lagrangian multiplier method(라그랑주 승수법)을 이용하여 목적식과 제약식을 하나로 표현할 수 있습니다. 라그랑주 승수법은 제약식이 존재하는 문제를 제약이 없는 문제로 바꾸는 기법으로 제약식에 신경 쓰지 않을 수 있습니다.
Lp(w,b,αi)=21∣∣w∣∣2−i∑Nαi[yi(wTxi+b)−1]
KKT(Karush–Kuhn–Tucker) 조건에 따르면 부등식 제한 조건이 있는 경우에는 등식 제한조건을 가지는 라그랑주 승수 방법과 비슷하지만 𝑖i번째 부등식이 있으나 없으나 답이 같은 경우에는 라그랑지 승수의 값이 αi=0이 된다. 이 경우는 판별함수의 값 wTxi이 −1보다 작거나 1보다 큰 경우이다.
yi(wTxi−b)−1>0
학습 데이터 중에서 최전방 데이터인 서포트 벡터가 아닌 모든 데이터들에 대해서는 이 조건이 만족되므로 서포트 벡터가 아닌 데이터는 라그랑지 승수가 0이라는 것을 알 수 있다.