Tensor는 다차원 데이터를 표현하는 방법으로 딥러닝 개발에서 반드시 이해가 필요하다. 딥러닝 개발과정에서 필요에 따라 tensor의 형태를 다양한 형태로 변환해야 하는 경우가 자주 발생하게 된다. PyTorch에서도 tensor를 변환하는 다양한 방식을 제공한다. 자주 사용되는 함수가 view, reshape, permute, transpose등이 있다. 이러한 함수들은 비슷한 기능을 제공하지만 조금씩 다르기 때문에 정확한 활용을 위해서는 tensor의 형태와 실제 데이터가 메모리에 적제되어 있는 형식을 정확하게 이해하는 것이 중요하다.
Tensor and Memory
PyTorch와 Tenserflow와 같은 딥러닝 프레임워크에서 데이터를 생성하고 적제하는 과정은 모두 tensor를 기반으로 수행된다. Tensor는 다차원 데이터를 효과적으로 관리하기 위한 방법으로써 행렬에서 처럼 행(row)와 열(column)으로 구분하지 않고 0, 1, 2와 같은 index를 사용하게 된다. 2차원 tensor에서는 행렬에서 행에 대응되는 방향을 0, 열에 대응되는 방향은 1로 표현된다. 만약 3차원 tensor라고 하면 깊이(0), 행(1), 열(2) 로 표현된다.
View and Reshape
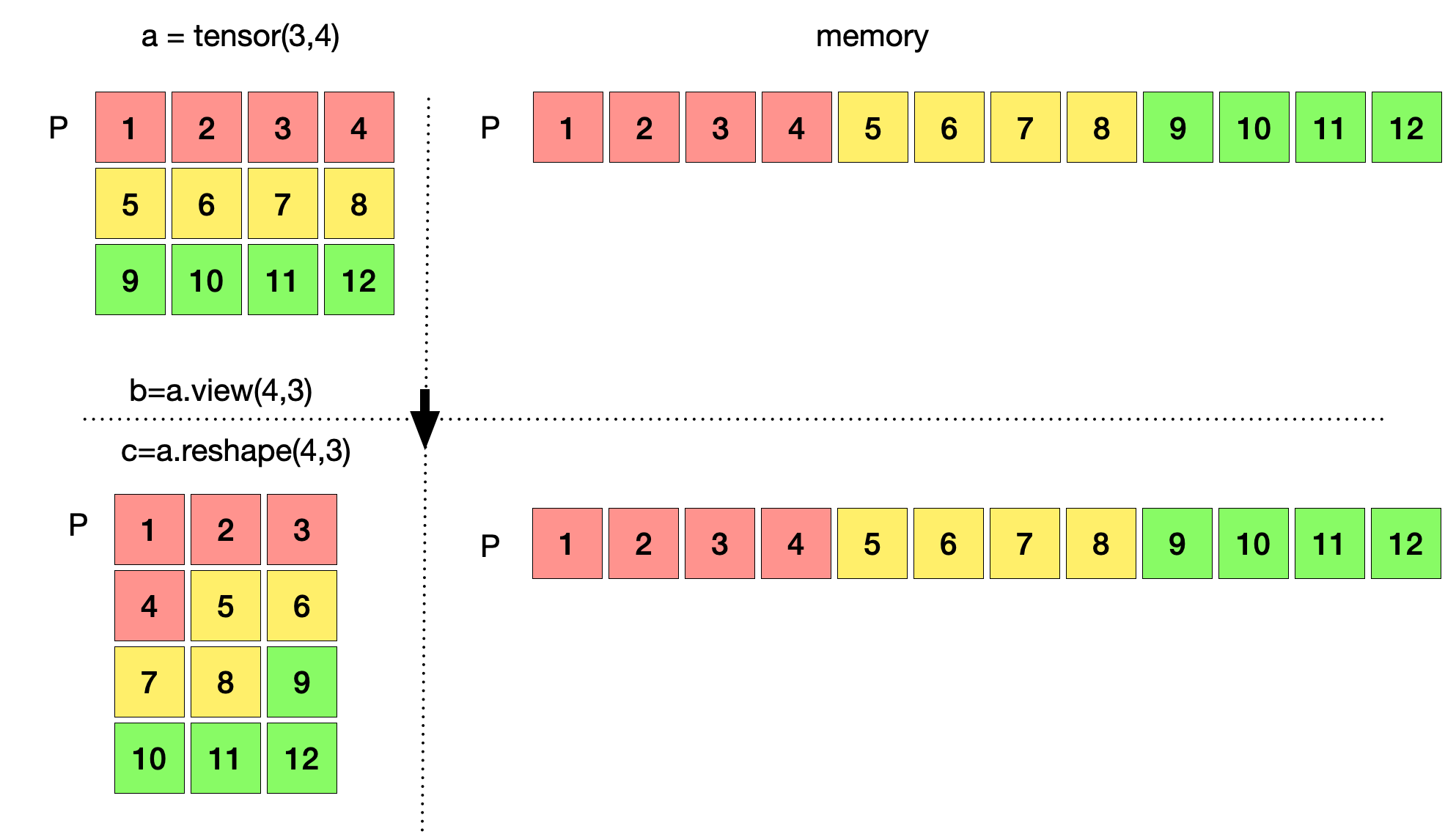
이러한 Tensor는 보여지는 형태와 실제 메모리 공간에 저장되는 형태는 다르다. 따라서, 이러한 현상을 정확하게 이해하기 위해 딥러닝 개발에 자주사용되는 Python에서 가지는 3x4 tensor 데이터를 생성하고 이것으로 부터 시작해 보자. 파이썬에서 배열 데이터를 생성하게 되면 실제 메모리 공간에서는 연속적으로 배열 데이터가 저장된다. 이는 연산 및 관리 등과 같은 많은 이유에서 유리하기 때문이다. 우리가 생성한 데이터 a는 아래와 같이 tensor 형태로는 3x4 형태로 표현되지만 실제 메모리에서는 P에 연속적으로 저장되게 된다. Tensor a는 P의 주소를 참조한다. 이 데이터 a 를 view 와 reshape을 이용해 4x3으로 변환해보면 아래 그림과 같이 4x3 형태로 변한 tensor b, c를 반환한다. 하지만 b, c는 여전히 메모리에 저장된 데이터 및 주소 P를 그대로 참조하고 있다. 즉, view와 reshape은 tensor의 형태만 변환시켜주기 원본 데이터에서는 어떠한 작업도 하지 않는다.
Permute and Transpose
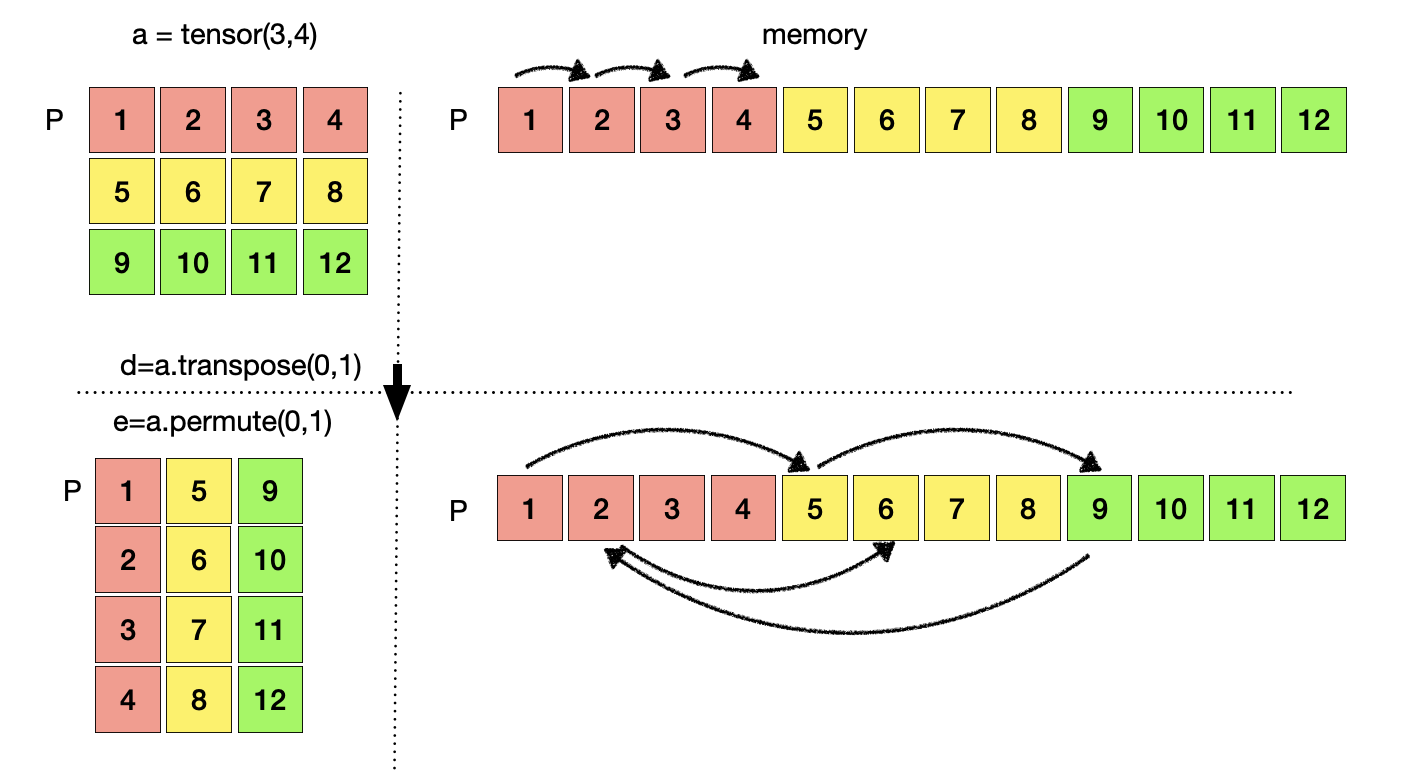
Permute와 transpose는 view와 reshape과는 조금 다른 연산을 진행한다. View와 reshape은 요소들의 순서를 유지한 채로 tensor의 형태를 변화 시키지만 permute와 transpose는 행렬 연산에서 처럼 행과 열을 맞바꾸기 때문에 요소들의 순서에 변화생긴다. 여전히 데이터가 저장된 주소는 P를 참조하고 있다.
Contiguous
딥러닝에서는 벡터 연산이 많이 이루어 진다. 벡터연산을 수행 할 때 데이터가 연속적으로 저장되어 있다면 매우 효율적으로 연산을 수행할 수 있다. 데이터가 연속적으로 저장되어 있다면 데이터의 시작주소에서 하나씩 증가 혹은 감소하면서 데이터를 읽어와서 연산을 수행하면 되기 때문이다. 만약 데이터가 연속적으로 저장되어 있지 않다면 연산을 수행하는 과정에서 데이터의 위치를 찾아서 이동한 후에 데이터를 읽어 올 수 있기 때문에 연산은 매우 비효율적으로 이루어 진다. 이러한 이유 때문에 딥러닝 프레임워크에서는 연속된 데이터 관리가 중요하다. View와 Reshape은 위에서 보았던 것처럼 tensor를 기준으로 모든 데이터가 연속적으로 유지 된다. 하지만, transpose와 permute 연산은 tonsor기준에서 바라보았을 때 데이터가 연속적으로 위치하고 있지 않다. 이러한 경우는 연산이 비 효율적으로 이루어 질 수 밖에 없다. 특히, GPU는 이렇게 연속적이지 않은 데이터를 싫어한다. 따라서, transpose나 purmute를 사용할 때는 contiguous를 같이 사용해서 데이터의 연속성을 유지하는 것이 좋다. 이렇게 연속성을 유지하기 위해 contiguous를 같이 사용하는 경우는 메모리의 P주소에 저장된 원본 데이터 복사해서 f tensor는 Q, g tensor는 R 주소로 새로운 데이터를 생성하고 연속성을 유지시킨다.
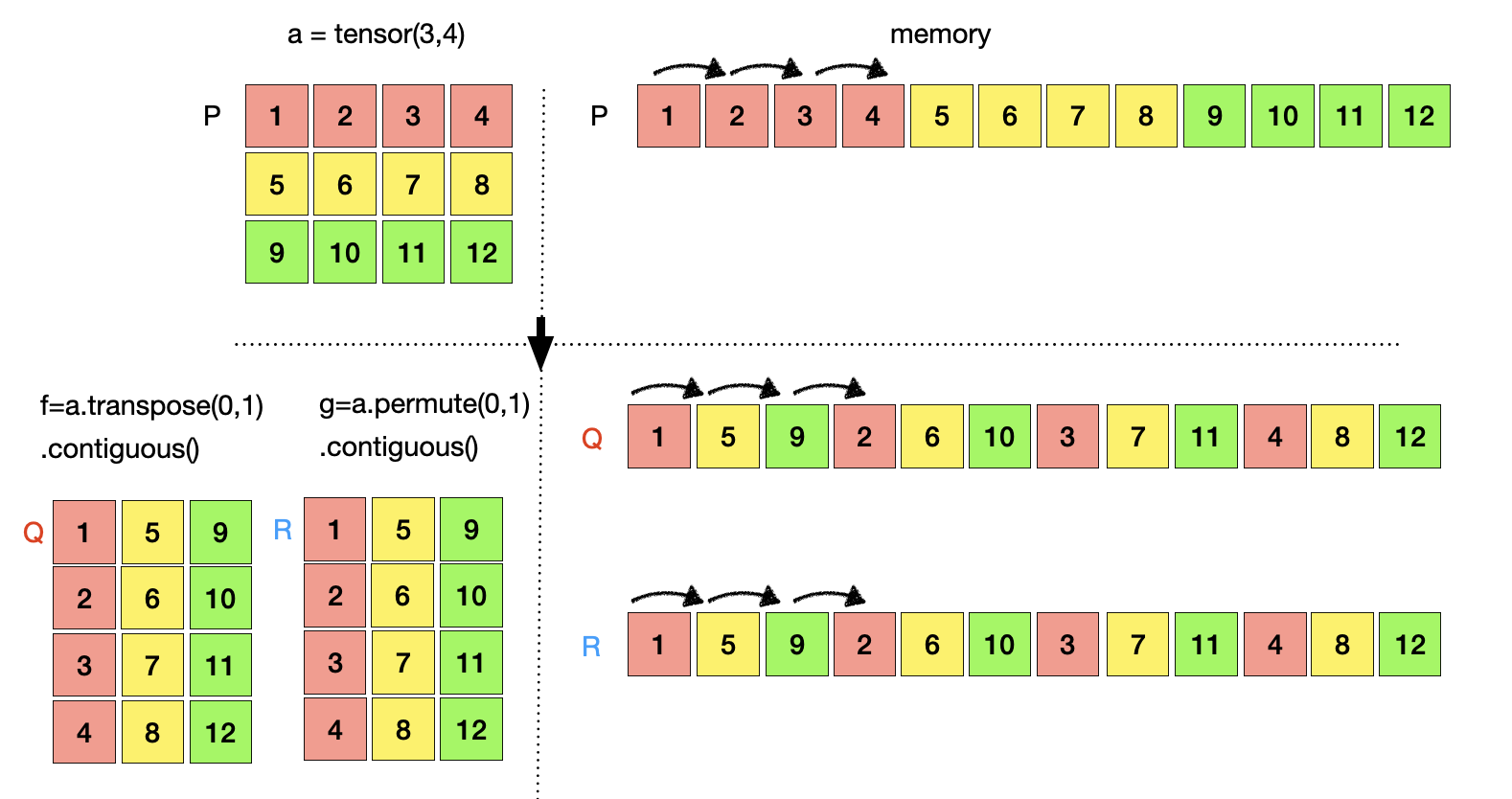
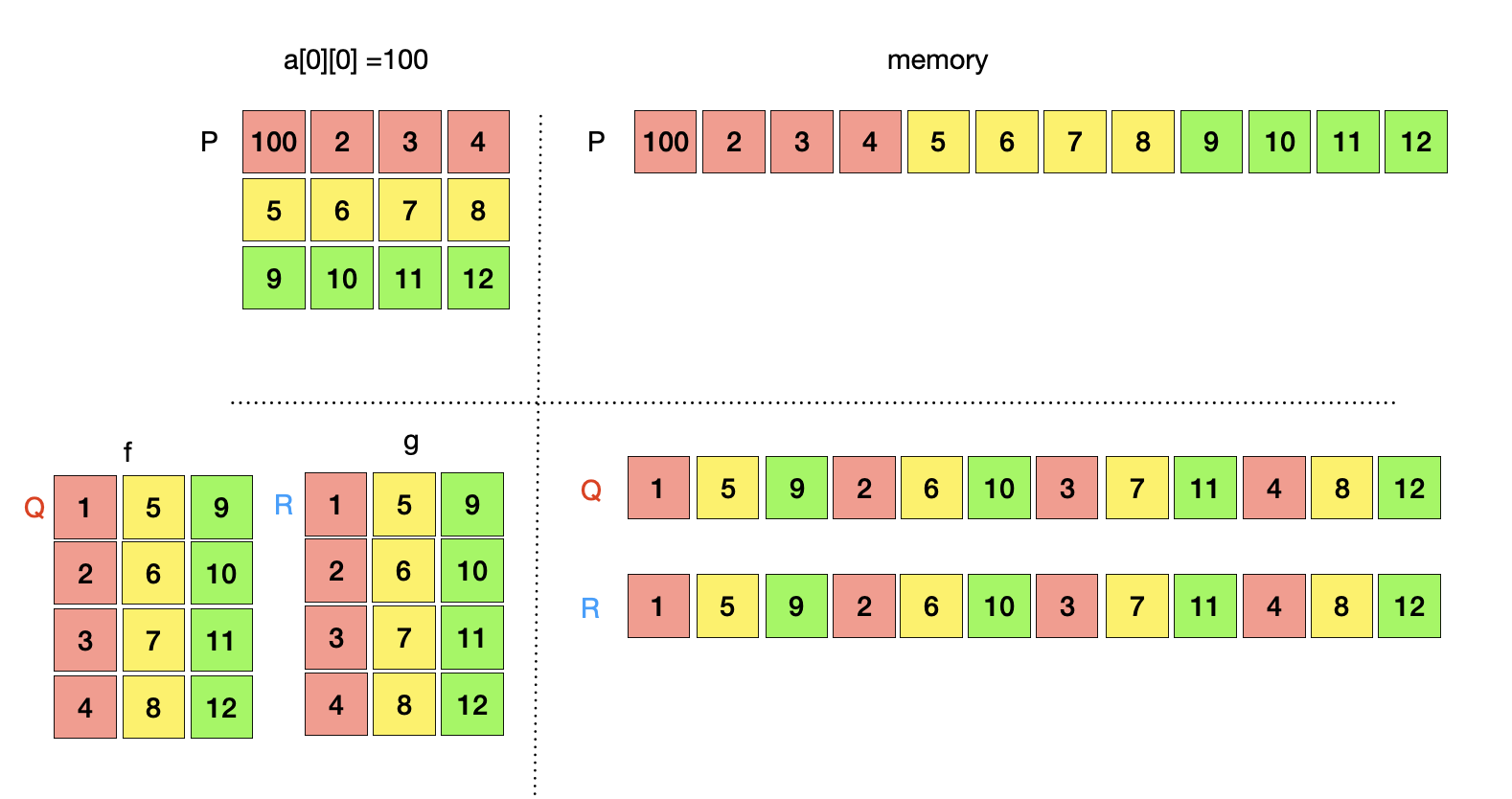
이제 부터는 P주소의 데이터와 R, Q 주소의 데이터가 독립적으로 저장되고, Tensor a는 P주소의 데이터를 참조하고, tensor f,g는 Q, R 주소의 데이터를 참조하게 된다. 따라서 P주소를 변경하면 Q, R주소의 데이터에는 영향을 미치지 않는다. 즉, tensor a의 값을 변경하면 tensor f, g의 값은 변경되지 않고 기존의 값이 유지된다. 예를 들어 을 대입하면 P주소의 데이터는 변경되지만 R, Q 주소의 데이터는 변경되지 않는다.
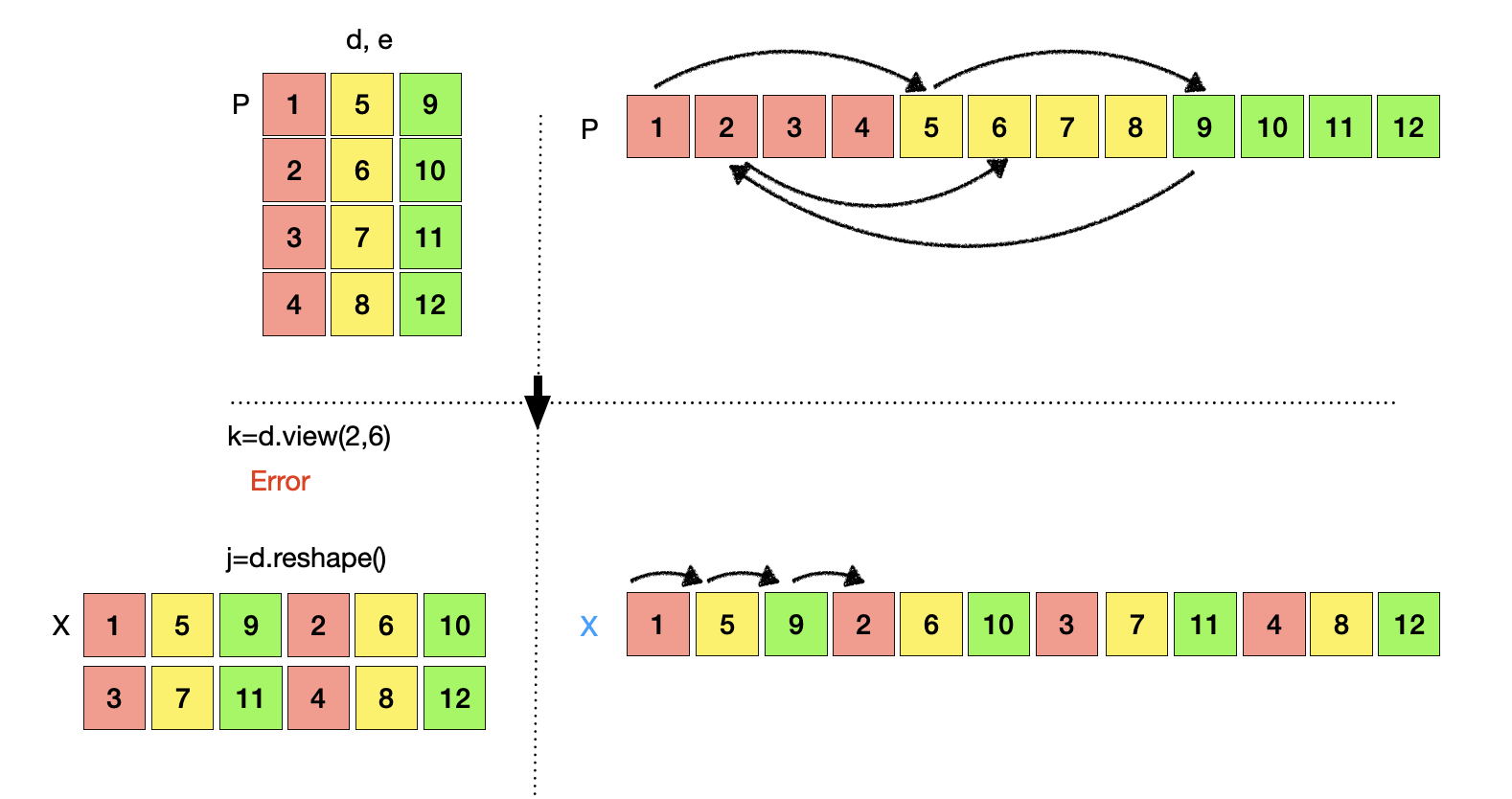
View vs Reshape
View와 Reshape은 무슨 차이가 있을까? 둘은 비슷한 일을 하지만 차이점이 있다. 둘의 차이점을 이해하기 위해 위에서 생성한 tensor d, e를 활용해보자. Tensor d, e는 tensor a를 transpose 혹은 purmute를 이용해서 생성한 tensor로서 연속적이지 않은 tensor이다. 연속적이지 않은 tensor에 view를 적용하면 연속적이지 않은 tensor라고 오류를 반환하지만 reshape을 적용하면 오류없이 동작하고 결과로서 연속적인 tensor를 반환한다. 즉, view는 연속적인 tensor를 연속적인 tensor로 모양을 변환시켜주는 동작을 하고, reshape은 입력 tensor가 연속적이든 연속적이지 않든 주어진 tensor의 모양을 변화시키고 연속적인 tensor을 반환한다.