Multivariate Time Series
시계열 데이터 표현
시계열 데이터는 다양한 것들이 있다. 주변 환경을 측정하기 위한 온도, 습도 등을 측정한 센서신호, 주식거래와 가격을 표시한 가격 데이터, 사람의 음성 혹은 음악을 나타내는 신호등과 같이 다양한 데이터들이 존재한다. 이러한 데이터는 시간의 흐름과 함께 생성된다는 공통점이 있다. 따라서, 시계열 데이터는 시간과 같이 순서가 중요한 데이터를 지칭한다.
Channel 혹은 Feature
시계열 데이터를 표현하는 방법을 설명하기 위해 온도와 습도 센서에서 매 시간 측정되 신호를 가정해보자. 이 시계열 데이터는 2개의 센서에서 취득되었기 때문에 채널 혹은 특징은 2개이고, 측정된 시간에 따라 기록이 될 것 이다. 아래 그림은 온도와 습도에서 측정된 데이터를 시간 순으로 표시한 것이라고 가정해보자. 이 시계열 데이터는 2개의 채널(온도, 습도)로 구성되고 측정된 시간에 따른 T0~T31까지 32개 타임스탬프(포인트, 시퀀스)로 표현된다. 아래 그림과 같이 전체 데이터를 한번에 처리할 수 있지만, 시계열 데이터는 시간 혹은 순서가 매우 중요한 요소이다. 따라서, 시간 혹은 순서에 따라 나누어서 분석 혹은 처리하는 것이 일반적이다.

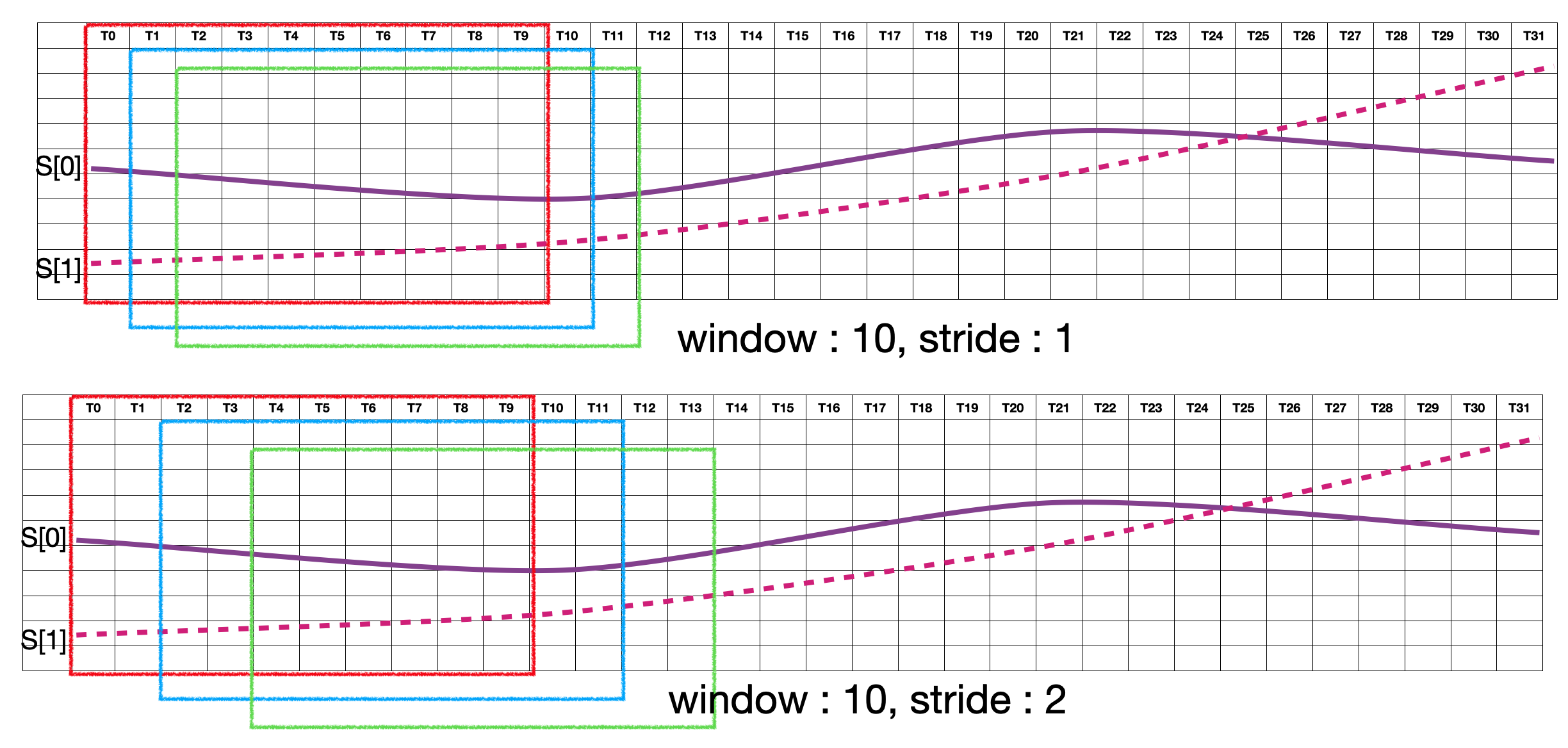
Winow(length, time_step) 및 Stride(Slide, Step)
시계열 데이터는 일정구간씩 선택해서 분석하게 되는데 이 구간의 길이을 일반적으로 윈도우라고 칭한다. 윈도우는 분석하고자 하는 데이터의 특성 및 방법에 따라 사용자가 선택 가능하다. 선택된 구간을 시간 축을 기준으로 이동하면서 분석을 하는데 이때 이동한 포인트 혹은 데이터를 stride 혹은 hopping, 스탭이라고 칭한다. 아래 그림은 window=10, stride=1과 window=10, stride=2를 도식한 것이다.
Batch 및 Shuffle
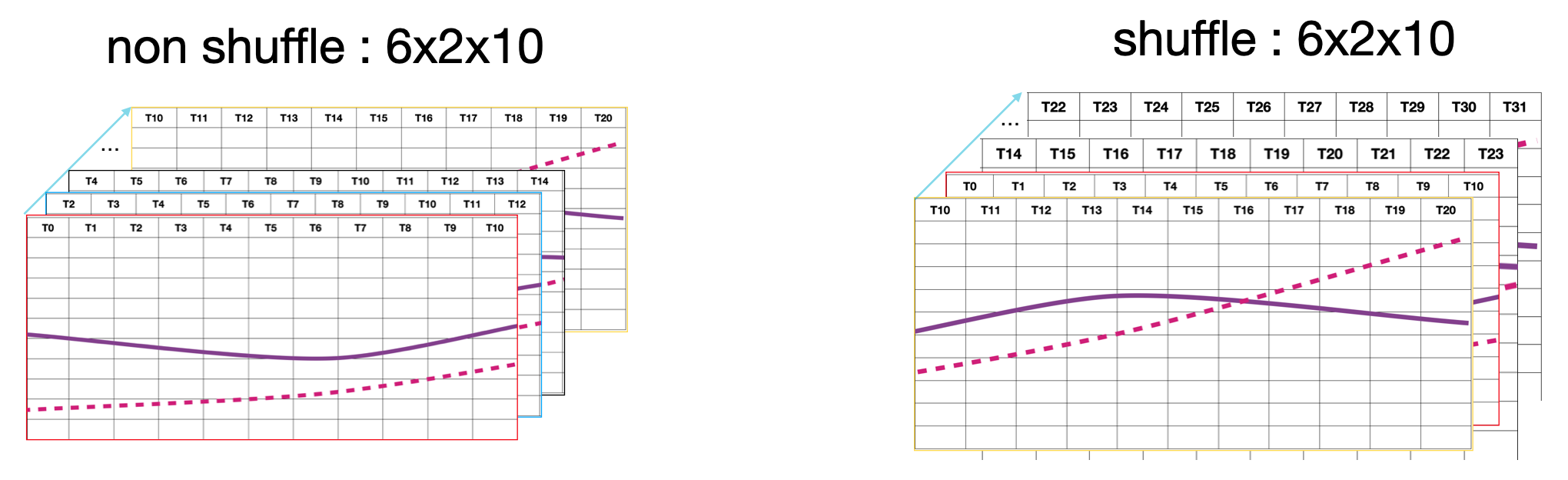
딥러닝이나 머신러닝은 데이터를 이용해 모델을 학습시키게 되는데 window와 stride를 설정하고 선택된 데이터를 하나의 묶음으로 처리하기 하는 것으로 배치라고 칭한다. 예를 들어서 위의 데이터는 전체 T0~T31까지 32 포인트 길이의 데이터이기 때문에 window=10, stride=2라고 하면 11개의 구간으로 나눌수 있다.
이렇게 구분된 데이터를 학습에 사용할 수 있지만 일반적으로 전체 데이터를 학습에 사용하지 않고 일부만 선택해서 반복적으로 학습을 시키게 된다. 이때 한번 학습할 때 사용하는 단위를 Batch라고 칭하고 하나의 배치를 구성하는 방식은 순차적으로 선택하는 방법과 랜덤하게 선택하는 방식이 있을 수 있는데 랜덤하게 선택하는 방식을 shuffle 이라고 한다. 아래 그림은 전체 11개의 데이터 중에 6개를 선태해서 하나의 배치를 구성한 것으로 도식한 것이다.
Dataloader
딥러닝이나 머신러닝에서는 이렇게 배치를 만들어 학습을 하게 되는데 학습과정에서 특정한 데이터를 가져오기 쉽게 많들어 주는 것을 dataloader라고 칭하고 학습과정에서 배치화된 데이터를 쉽게 접근하기 위해 dataloader를 사용한다.
