
데이터 웨어하우스(Data Warehouse)
- 데이터에 근거한 분석과 의사 결정을 내릴 수 있도록 데이터의 탐색 및 분석을 제공하는 저장소 혹은 서비스
- 작게는 특정 서비스의 분석에서 부터, 고객, 제품 및 기업에 이르기까지 기업의 가치를 높일 수 있는 분석과 의사결정에 필요한 모든 데이터를 수집, 변환 및 적재를 위한 데이터 기반 플랫폼 혹은 서비스
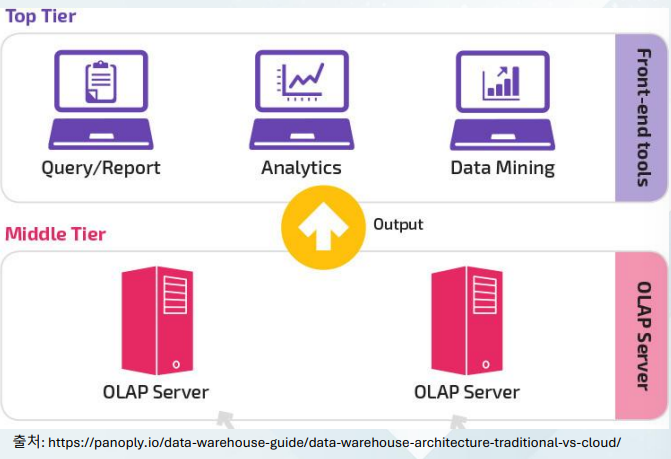
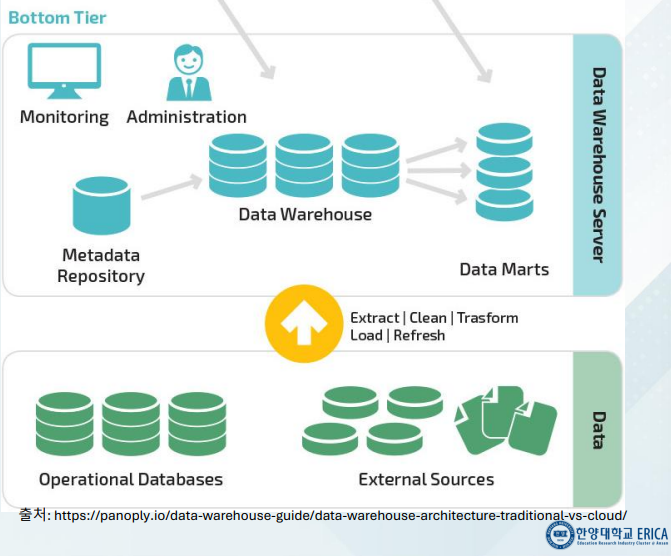
- 데이터웨어하우스 아키텍처는 3계층 구조를 채택
- Top Tier
- Middle Tier
- Bottom Tier
TopTier
- 데이터 분석, 리포트, 쿼리 및 데이터 마이닝에 사용되는 도구들이 포함
Middle Tier
- 데이터의 분석에 적합한 구조로 변환하는 OLAP 서버가 존재
- 직접 데이터 큐브를 생성하는 경우와 구성된 다차원 모델을 활용하는 방법 등을 통해
Bottom Tier
- 다양한 운영 및 기간계 서버로부터 데이터를 추출, 변환 등의 ETL 작업을 위한 데이터베이스 서버가 포함
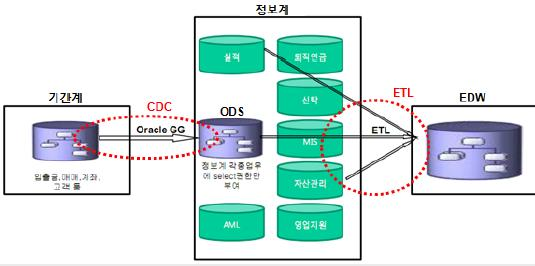
ETL
EXTRACT(추출)
- 여러 시스템(ERP, CRM)에서 필요한 데이터를 꺼냄
- 쇼핑몰 DB에서 주문 내역을 빼오는 등의 예시
Transform(변환)
- 데이터를 분석용으로 깨끗하게 가공
- 날짜 형식 맞추기, 통화 단위 통일, 중복 제거
Load(적재)
- 변환한 데이터를 분석용 저장소(데이터 웨어하우스 등)에 넣음
- OLAP 서버에 저장하는 등의 예시
Batch Vs Realtime(배치 Vs. 실시간)
데이터 웨어하우스 배치 처리
- 기간계 데이터베이스에 영향을 최소화 하기 위해 사용이 가장 적은 야간 배치 스케줄링
- OLTP: Snowflake-schema 통한 정규화, 중복을 제거한 운영에 최적화된 기간계 모델링
- OLAP: Star-schema 통한 비정규화 지표 추출과 분석에 용이한 웨어하우스 모델링
- 특정 주제 관점으로 데이터 마트 혹은 큐브를 통해 조회, 분석 성능 향상을 위해 최대한 미리 생성해 두는 방식
데이터 웨어하우스 실시간 처리
- 벤더 혹은 솔루션을 통한 실시간 처리가 가능하지만, 확장, 락인, 개발 운영 비용이 큼
- CDC(Change Data Capture) 방식을 통한 데이터 전송(Push, pull) 방식
- EAI(Enterprise Application Integration) 솔루션 등을 통한 실시간 통합 방식 특정 주제
- 마찬가지로 벤더에 락인되는 점과, 개발, 운영 비용이 크고 비지니스의 변화가 예상되는 불확실한 분야 통합의 단점이 있음
실시간 처리 예시
- 기간계
- 목적: 실시간 운영
- 주 용도: 거래 처리
- ODS(Operational Data Store)
- 목적: 중간 저장소
- 주 용도: 실시간 보고서 임시 집계
- EDW (Enterprise Data Warehouse)
- 분석 중심 저장소
- 주 용도: BI, 리포트, 머신러닝
OLTP Vs. OLAP
OLTP (Online Transaction Processing)
- 운영 중심 (주문, 결제, 회원가입 등)
- 정규화(Normalization)
→ 중복 없애고 빠른 저장 - 은행 입출금 시스템, 쇼핑몰 주문 시스템
- Snowflake Schema (눈꽃처럼 복잡한 구조)
OLAP (Online Analytical Processing)
- 분석 중심 (매출 추이 분석, 고객 세분화 등)
- 비정규화(Denormalization)
→ 분석을 위해 조회 빠르게 - 매출 분석 리포트 시스템, BI 대시보드
- Star Schema (별처럼 단순한 구조)
Snowflake Schema Vs. Star Schema
Snowflake Schema (스노우플레이크 스키마)
- 가지를 치듯 세분화된 복잡한 형태
- 거의 없음 (정규화)
- 데이터 무결성 유지, 저장공간 절약
- 조회 성능 느릴 수 있음
- OLTP 시스템 (운영 데이터베이스)
Star Schema (스타 스키마)
- 별 모양처럼 단순하게 중심(팩트) + 주변 (차원)
- 일부 있음 (비정규화)
- 조회 빠름, 분석 최적화
- 공간 더 사용, 업데이트 시 관리 필요
- OLAP 시스템 (분석 데이터베이스)
데이터 웨어하우스 특징
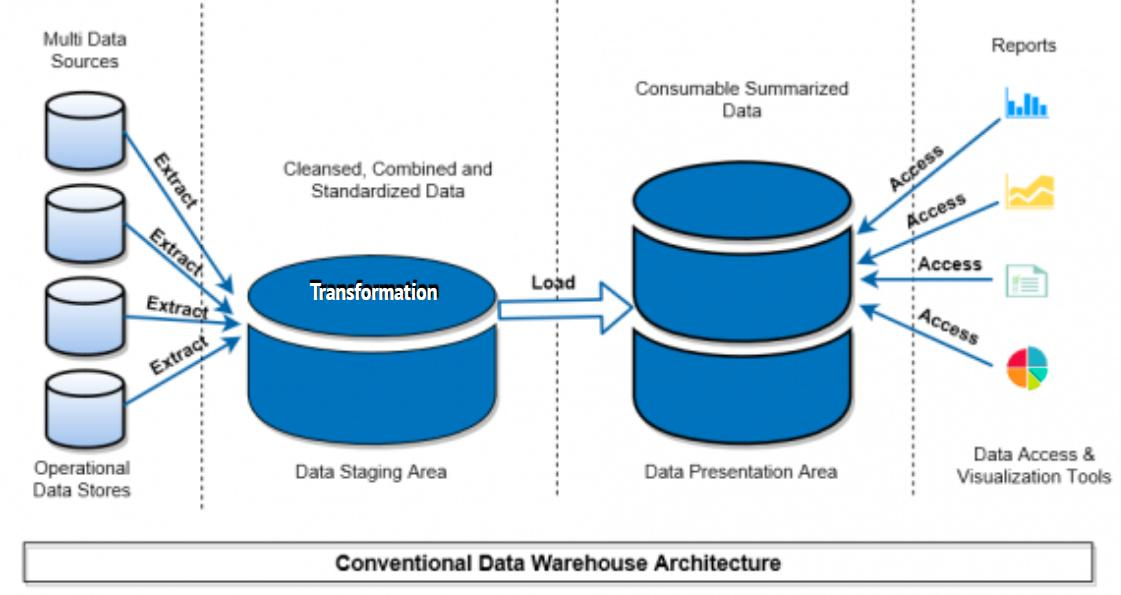
- SQL 기반 추출, 가공 및 적재
➔ 다양한 유형 관리 어려움 - 특정 벤더 최적화된 인원 구성
➔ 벤더 기술과 제품에 락인 - 저장소 분리 운영 기반 배치 작업
➔ 장애 처리 복구 비용 - Scale Up 방식의 규모 확장
➔ 확장의 어려움과 비용 문제
데이터 웨어하우스 한계
BI 영역 변화
- 전통적인 데이터 분석 과정인 BI영역은 관계형 데이터베이스 기반의 데이터 웨어하우스 구축을 통해 수행 해왔으나 데이터의 규모가 커지고, 다양화 되면서 더 빠르고 더 정확한 데이터 처리 필요
5V
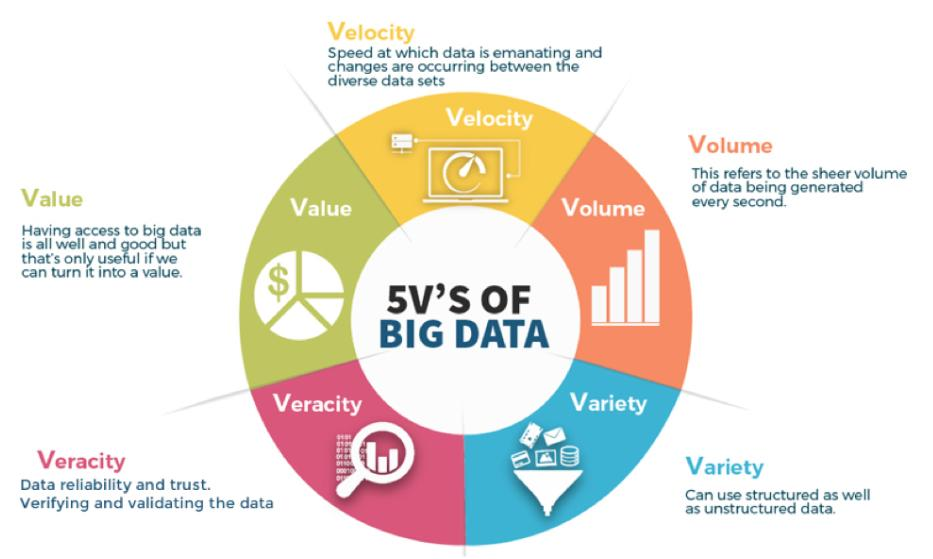
데이터 규모(Volume)
➔ 싱글 노드 환경에서 수행할 수 있는 처리 크기 혹은 확장성 제한
데이터 다양성(Variety)
➔ 관계형 데이터베이스 저장 및 처리 가능한 데이터 유형의 한계점
데이터 속도(Velocity)
➔ 실시간 혹은 스트리밍 처리를 위한 인프라의 유연성 및 성능 제한
데이터 레이크 (Data Lake)
- 모든 원본 데이터(raw data) 를 가공하지 않고 그대로 저장하는 저장소
- 조직의 모든 사람이 분석해야 하는 모든 raw data 에 대한 단일 저장소를 갖는 것
- 하둡의 저장소 개념 보다 더 광범위한 개념
- 데이터 소스가 제공하는 형식이나 스키마에 관계없이 원시 데이터를 저장
- 소비자는 해당 데이터를 스스로 이해하고 사용할 수 있어야 함.
데이터 레이크 특징
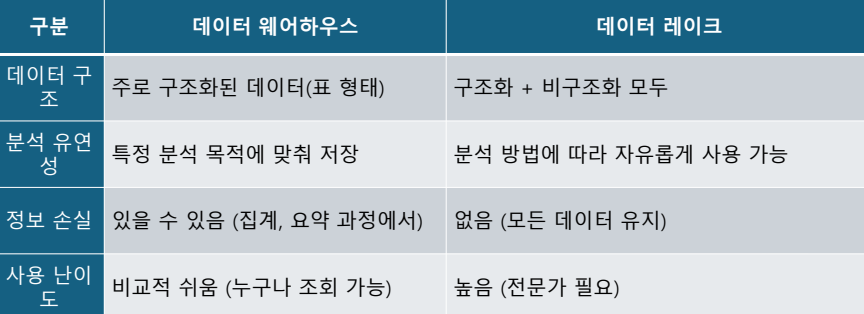
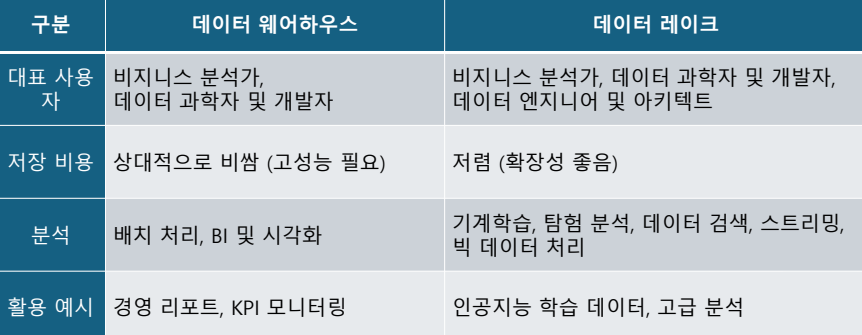
데이터웨어하우스 vs. 데이터 레이크
- 데이터웨어하우스는 일반적으로 데이터를 정제할 뿐만 아니라 분석하기 쉬운 형태로 집계
- 데이터 레이크는 데이터 소스가 제공하는 어떤 형태로든 raw data 저장
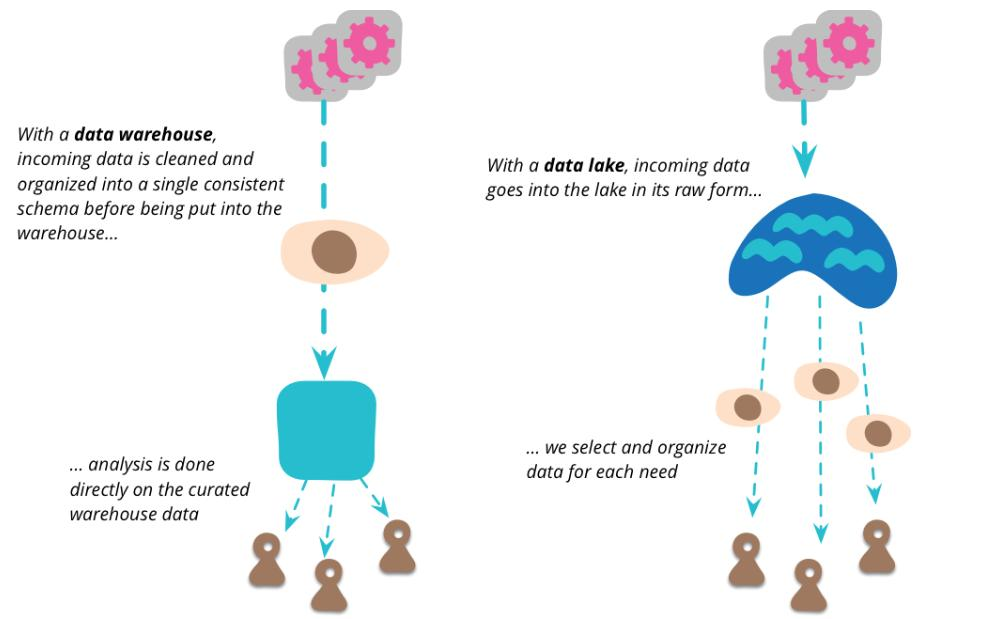
원본 데이터 유지
- 데이터를 분석하기 쉽도록 변형하거나 가공하지 않고,수집된 그대로 저장
➔ 필요할 때 언제든지 다양한 방법으로 재가공, 분석
정보 손실 최소화
- 데이터 웨어하우스 처럼 집계하거나 요약하는 과정이 없음 ➔ 정보량 손실 발생 없음
분석의 자유로움과 복잡성
- 다양한 관점에서 데이터 분석이 가능하지만 원시 데이터 자체는 복잡 ➔ 잘못 분석, 오해소지 있음
전문 지식 필요
- 통계 지식 도메인 이해 필수 ➔ 신뢰할 수 있는 데이터 마트 만들어 다수 사용자에게 제공
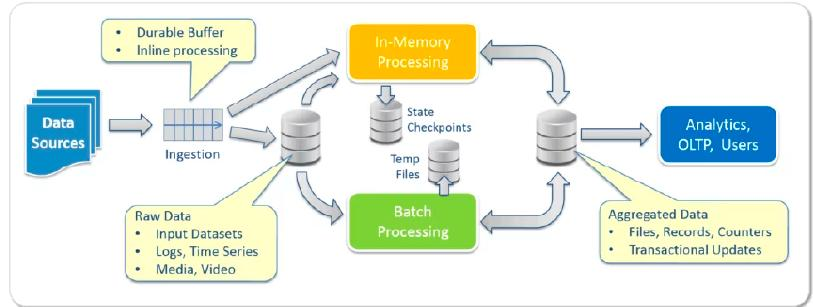
데이터 레이크의 배치 처리
ELT (Extract-Load-Transform)
- E (추출 Extract): 데이터를 다양한 소스에서 추출
- L (적재 Load): 추출한 데이터를 그대로 분산 저장소(HDFS 등)에 저장
- T (변환 Transform): 저장된 데이터에 대해 변환(정제, 가공) 작업을 나중에 수행 즉, 데이터를 먼저 저장한 후 필요한 시점에 변환하는 방식이 일반적
저장소: HDFS와 다양한 포맷
- HDFS 등 분산 저장소는 CSV, JSON, Parquet, ORC 등 다양한 포맷을 지원
- 다양한 데이터 유형(정형/비정형/반정형 데이터)을 유연하게 저장, 관리
NoSQL 웨어하우스와 OLAP 모델링
- NoSQL 기반의 데이터 웨어하우스를 구축할 때도 OLAP 모델 유지
- Star Schema를 사용하여 데이터 모델을 구성, 분석에 유리하도록
- 비정규화(Denormalization)
- 이를 통해 마트(Mart) 또는 요약 테이블 (Summary Table) 형태로 빠른 지표 추출이 가능
분산 배치 아키텍처: Scale-out
- 분산 환경에서는 서버를 Scale-out (서버 수를 수평적으로 확장)하여 선형적으로 성능 향상
- 다양한 오픈소스 툴(예: Apache Spark, Hadoop)을 활용해 대용량 데이터를 빠르고
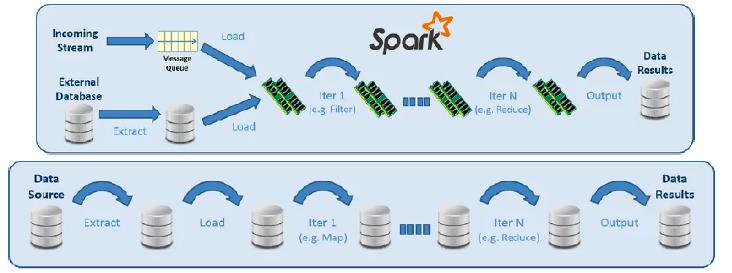
데이터 레이크(Data Lake) 실시간 처리(Realtime Processing)
실시간 데이터(Streaming Data) 처리
- 스트리밍 데이터란 실시간으로 지속적으로 생성되는 데이터를 의미
(예: 센서 데이터, 사용자 클릭, 거래 기록 등) - 데이터 레이크에서는 이런 스트리밍 데이터를 별도의 파이프라인을 통해 처리
분산 메시지 큐 : Kafka
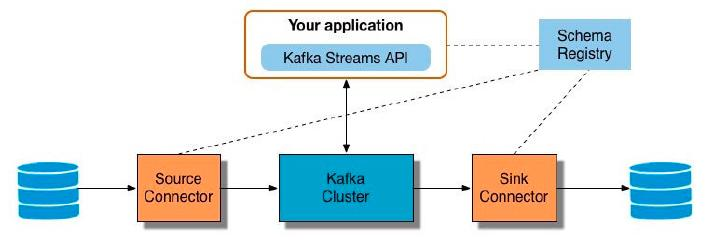
- Apache Kafka를 이용하면 데이터 저장과 데이터 처리를 디커플링(Decoupling) 할 수 있음
- 데이터를 저장하는 시스템과 데이터를 처리하는 시스템을 분리하여 유연성과 확장성 확보
Kafka 기반 디커플링 아키텍처
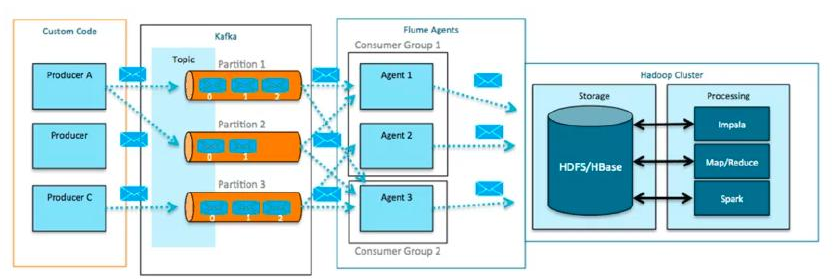
조직별 스트리밍 처리
- 사전에 통합된 방식으로 개발하지 않고, 개별 조직이 필요에 따라 스트리밍 지표를 별도로 개발
- 전체 시스템 통합보다는 조직별 요구사항에 맞춘 유연한 스트리밍 개발이 일반적
실시간 아키텍처의 특징
- Scale-out 기반으로 서버를 수평 확장하여 성능을 선형적으로 향상
- 오픈소스 도구 활용을 통해 특정 벤더 락인(lock-in)을 피할 수 있음
- 공용 인프라(클라우드) 를 활용하여 비용 효율적, 독립적인 서비스 구성도 가능
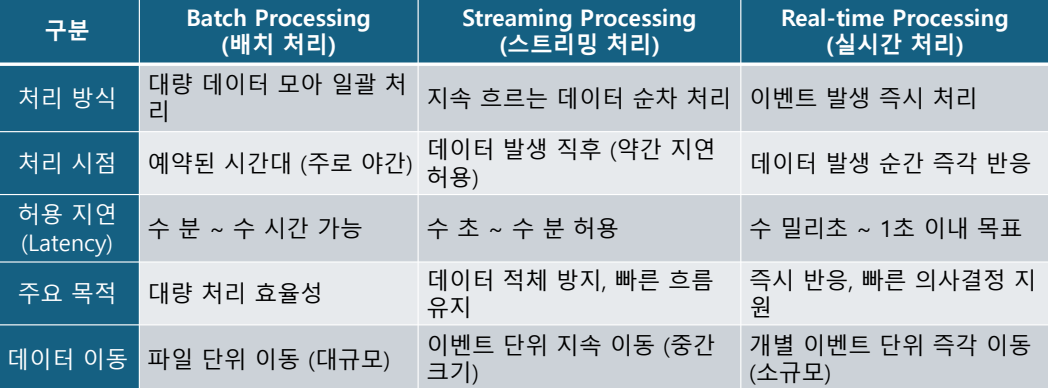
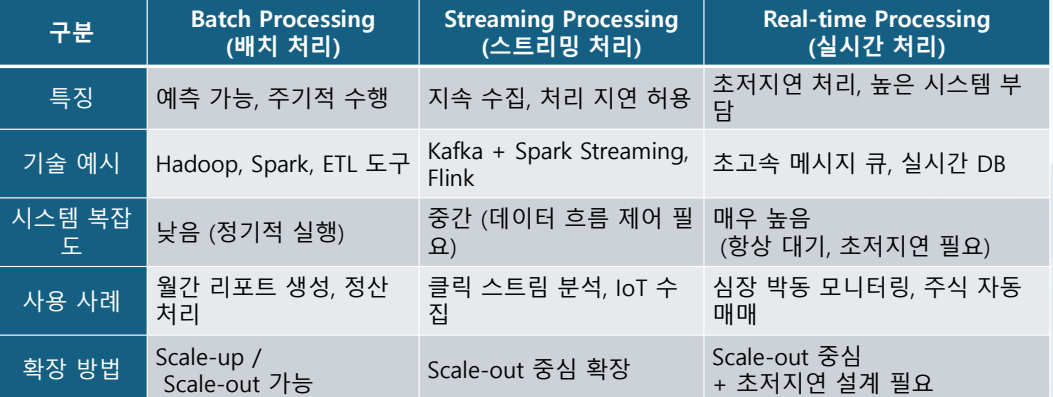
Streaming Processing VS Realtime Processing
Streaming Processing :
- 데이터를 계속 "흘려보내면서" 실시간에 가깝게 처리하는 것 (약간의 지연은 괜찮음)
- 사용자가 웹사이트에서 클릭할 때 클릭 로그를 모으는 경우
Real-time Processing :
- 지연 없이 "바로 반응해야 하는" 처리 (거의 즉각, 밀리초 수준 반응 필요)
- 심장 박동 센서가 이상 징후를 감지하는 경우
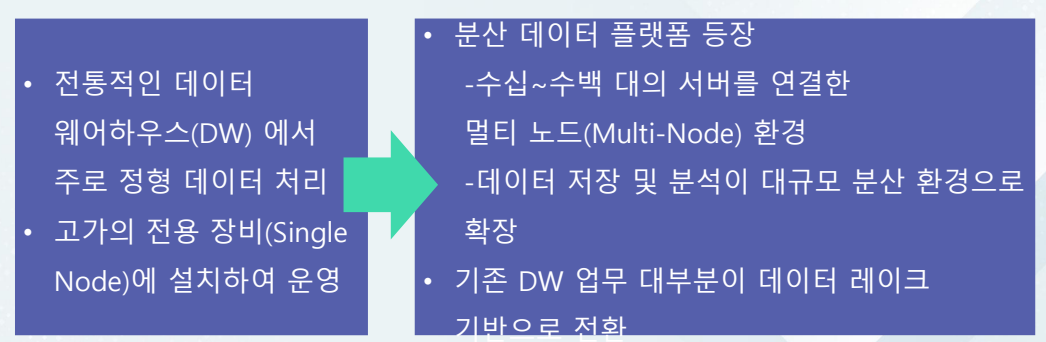
데이터 레이크(Data lake) 구축 방식
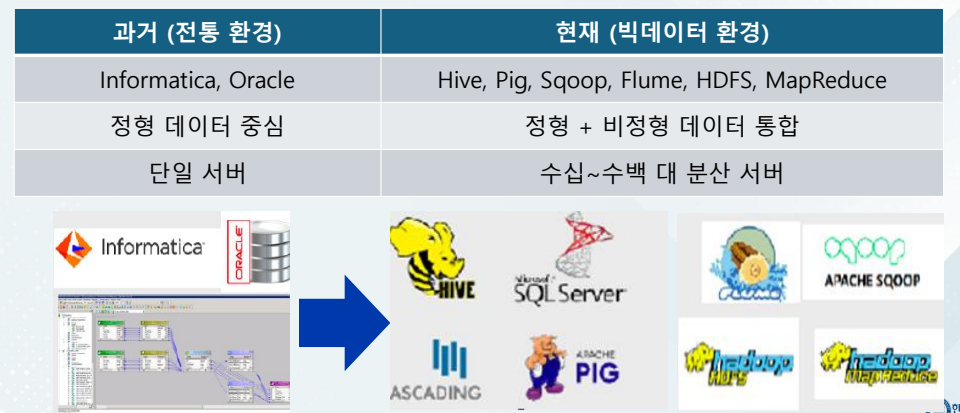
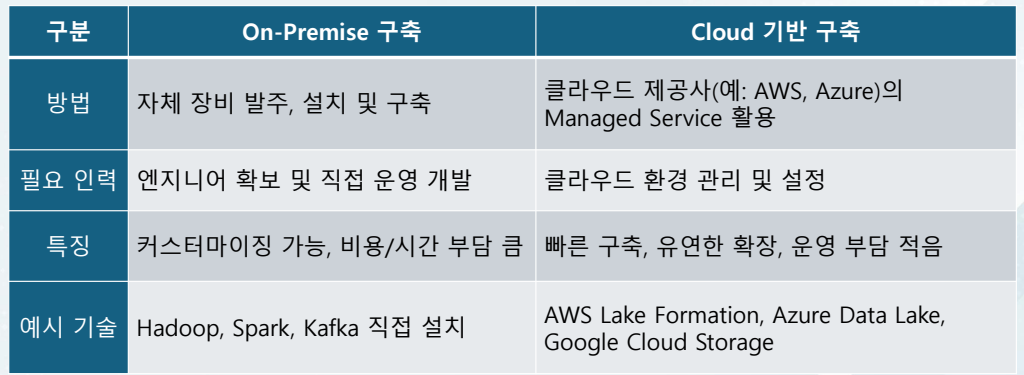
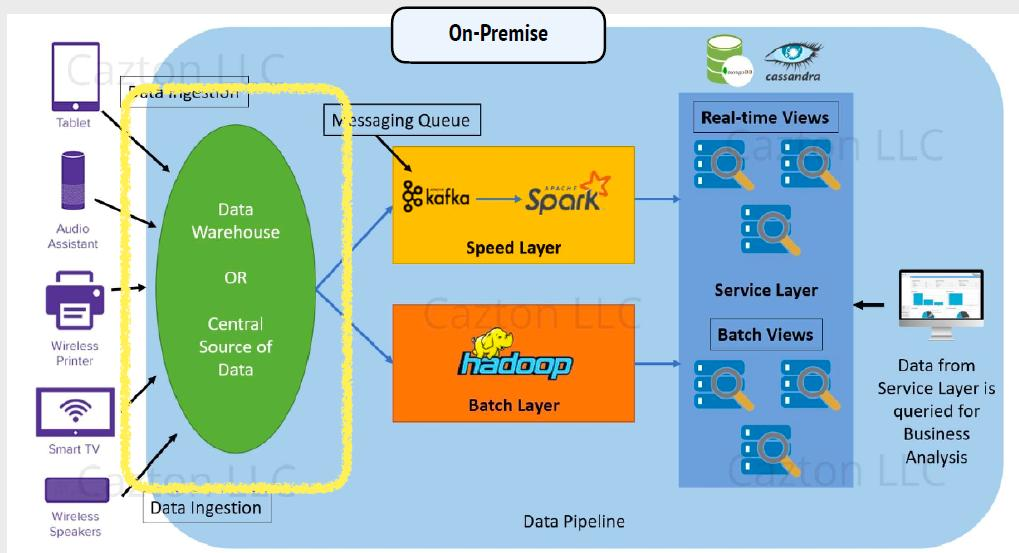
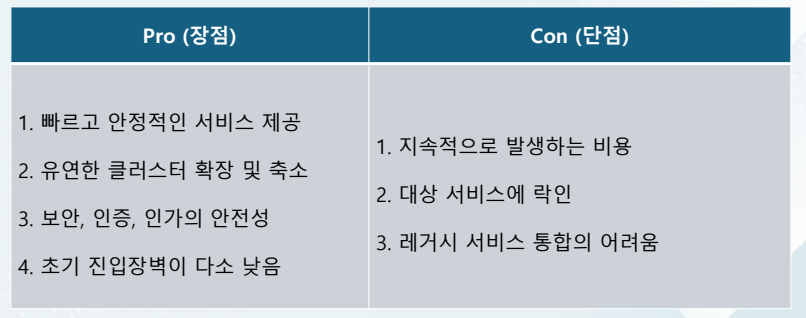
데이터 레이크(Data Lake) On-Premise
Lambda Architecture (람다 아키텍처)를 기반으로 한데이터 파이프라인
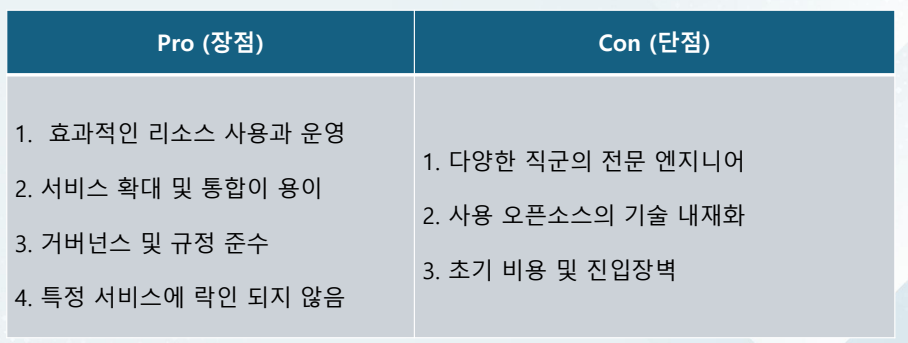
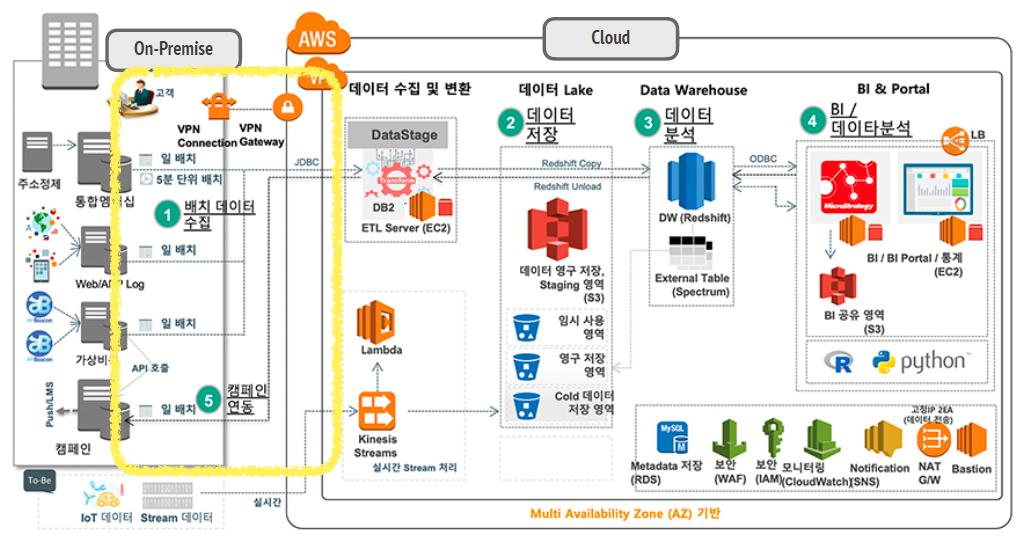
데이터 레이크(Data Lake) Cloud
- On-Premise + AWS Cloud 기반 데이터 파이프라인
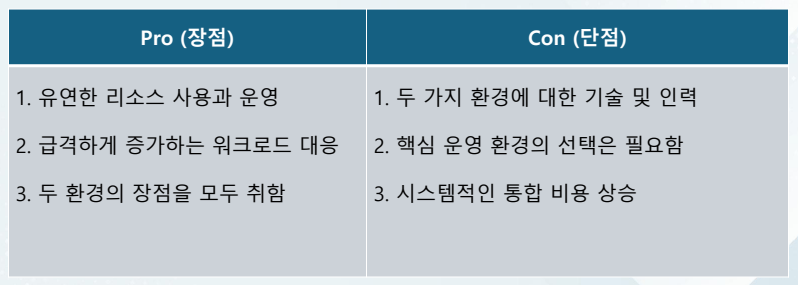
데이터 레이크(Data Lake) 하이브리드
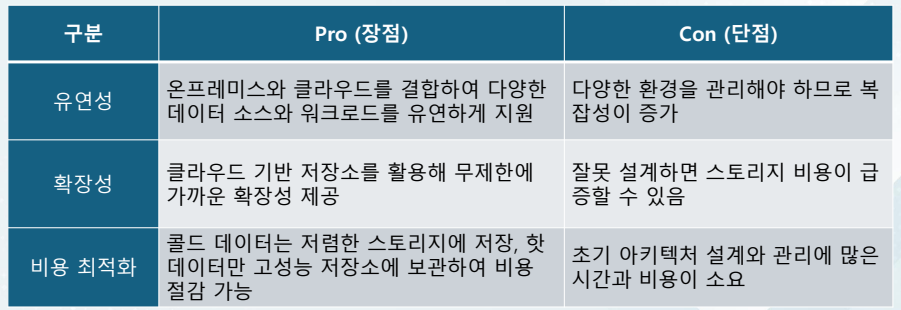
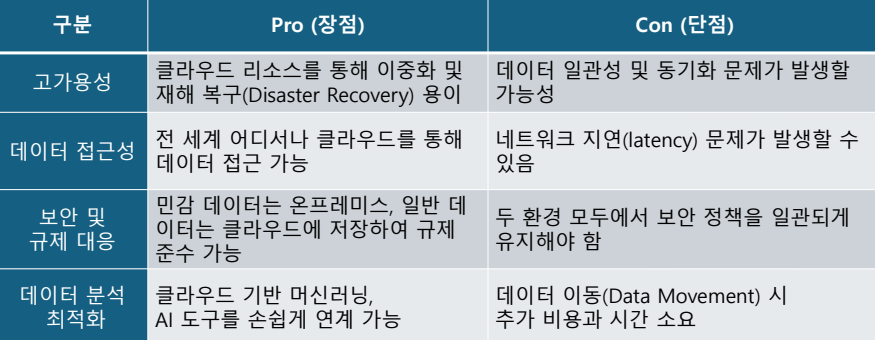
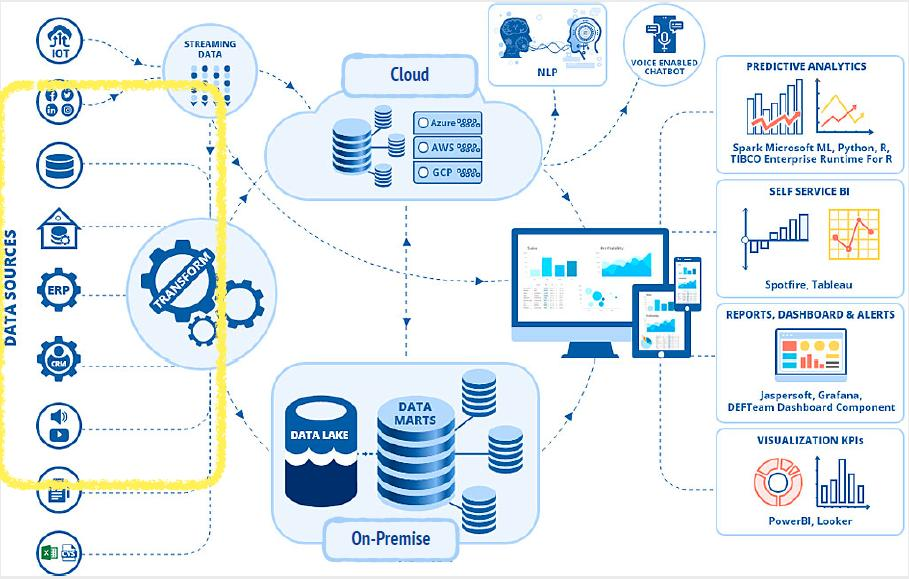
데이터 웨어하우스 VS 데이터 레이크 비교
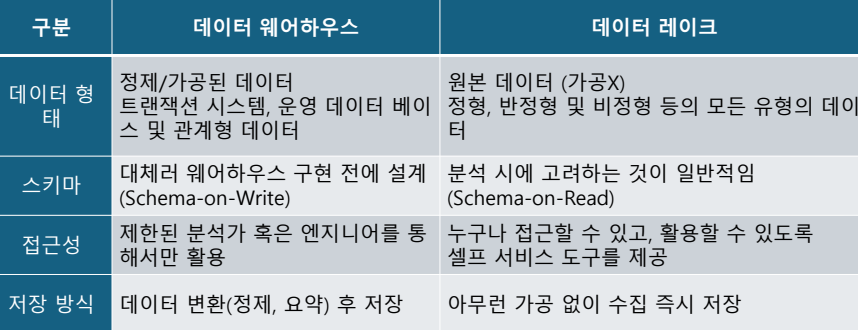

데이터 웨어하우스 구축
데이터 유형
보유하고 있는 데이터의 형태에 따라 어떻게 수집하고, 가공할 것인지 결정할 수 있기 때문에,
어떤 포맷의 데이터를 보유하고 있는지, 혹은 많이 활용해야 하는 데이터의 특징은 어떤지에 대해 파악
• 관계형 데이터베이스
• 시스템 혹은 애플리케이션 로그
• 이용자 활동 로그
• 인터넷 웹 페이지, 게시판 혹은 SNS
• 동영상 혹은 이미지
• 오픈 API 수집 데이터 https://levity.ai/blog/structured-vs-unstructured-data
데이터 규모
어느 정도 규모의 데이터를 다루어야 하는지 파악하는 것이 향후 클러스터 확장 혹은 애플리케이션 설계 및 개발시에 중요한 기준을 마련해준다
• 핵심 이벤트 로그 레코드의 평균 크기?
• 하루에 유입되는 데이터의 크기, 레코드 수?
• 피크 시 초당 유입 데이터 크기?
• 하루에 생산되는 데이터의 총 크기?
• 현재 보유한 데이터의 총 크기는?
• 현재 상태로 1, 5, 10년 후에 데이터의 크기는?
데이터 성능 Throughput
플랫폼의 처리 성능은 데이터의 크기나 형태 혹은 요구되는 요건의 수준에 따라 차이남
• 한 번에 처리되어야 하는 데이터의 크기는?
• 동시에 수행되어야 하는 작업의 수는?
• 서비스 수준 협약의 합의된 사항이 있는가?
데이터 성능 Latency
데이터 서비스의 조회 성능은 어떤 목적을 가진 서비스를 제공할 것인가
• 동시 접속 사용자 수는 어느 정도로 예상하는가?
• 하루에 접속하는 이용자수는 얼마나 되는가?
• '스캔 쿼리'가 많은지, '집계 쿼리'가 많은지?
• 허용 가능한 조회 '레이턴시' 수준은?
• 서비스 수준 협약의 합의된 사항이 있는가?
데이터 성능 품질
어느 정도 수준의 데이터의 품질을 요구하는 지 검토
• 정확성
• 완전성
• 일관성
• 적시성
데이터 성능 리소스 (Human & Machine)
현재 가용한 혹은 확보 가능한 인력과 장비의 수준을 파악
• 인력 풀 (BI 엔지니어, 개발자, 분석가, 시스템 엔지니어 등) 상세 비율
• 하둡 에코시스템 경험, 오픈소스 경험이 있는 엔지니어 구성 여부
• 활용 가능한 사내외의 관리 서비스 (Managed Service) 활용 여부
• 가용 인프라 (네트워크 등) 및 장비 (물리, 가상화) 스펙 확인
요약
- 데이터 웨어하우스는 다양한 출처의 정제된 데이터를 통합하여, 빠르 고 정확한 분석을 지원하는 구조화된 데이터 저장소이다.
- 정리된 데이터 분석 에 최적화한다
- 데이터 레이크는 크기와 형태에 상관없이 데이터를 수용하고, 분석과 머신러닝까지 지원하는 확장형 분산 데이터 플랫폼이다.
- 모든 데이터 저장과 유연한 활용을 지향한다.
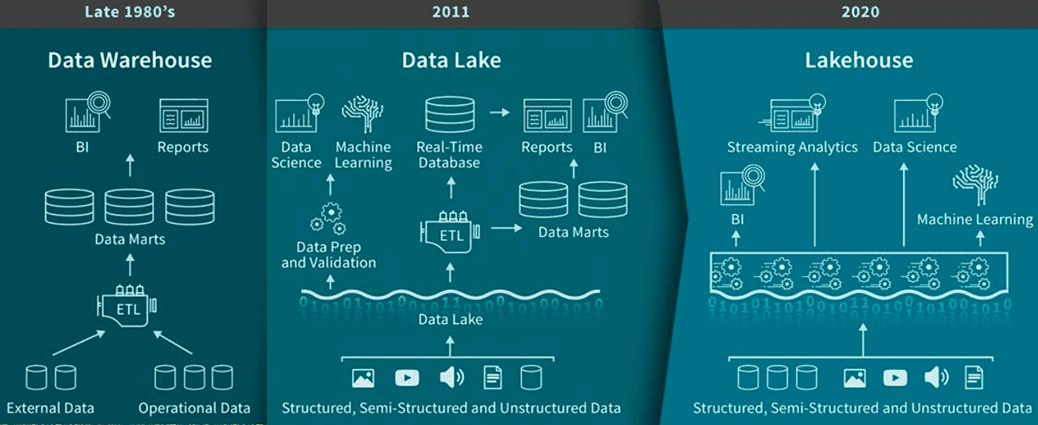
- 데이터 레이크하우스는 데이터 레이크와 데이터 웨어하우스의 장점을 결합, 하나의 저장소에 모든 형태의 데이터를 모두 저장하며 데이터 일관성(ACID 트랜잭션) 유지 가능하고 BI, 스트리밍 분석, 데이터 사이언스, 머신러닝 모두 지원한다.
