
Simple Processor
- 간단한 프로세서 구성 요소
- 메모리
프로그램(명령어)과 데이터 저장 - 레지스터 파일
명령어는 레지스터 파일에서 피연산자를 읽고 그 결과를 레지스터 파일에 등록 - 레지스터, ALU(산술 논리 장치) 및 가산기
- 디코딩 및 제어 로직
Simple (32-bit) Processor
- 모든 명령어가 32-bit로 encoding된 것으로 가정
- 레지스터와 데이터 경로(data path) 역시 32비트 폭(width(
- 메모리는 32비트 주소(address)로 액세스하고 32bit data 반환
- 프로세서에 32개의 레지스터가 있는 것으로 가정하면 특정 레지스터를 식별하는데 5비트를 사용(2^5 = 32)
Processor Datapath - Encoding Instructions
- 간단한 데이터 처리 명령어 형식
Instruction Rd, Rs, Operand2

-
Instruction: 데이터 처리 명령어의 종류
ex.ADD/SUB/AND/ORR(논리합) 등 -
R_d: 명령어가 결과를 저장할 레지스터(Register)의 번호
: 이 레지스터는 명령어의 실행 결과를 저장
: 여기서d는 목적지(Destination)를 나타냅니다. -
R_s: 연산에 사용될 두 번째 레지스터의 번호
: 이는 일반적으로 연산에 필요한 두 번째 피연산자를 나타내는 레지스터 -
Operand2: 연산에 필요한 두 번째 피연산자
: 이 피연산자는 레지스터 값과 상수 값을 가질 수 있음.
: 이러한 피연산자의 형식은 명령어에 따라 다름.
: ex. 레지스터 값을 직접 사용하거나 상수 값을 이동(shift)시키는 등의 방식
예를 들어, ADD R1, R2, #10은 R2의 값과 10을 더하여 그 결과를 R1에 저장하는 명령어
- 여기서
R_d는 R1
R_s는 R2
Operand2는 상수 값 10
만약, 명령어를 인코딩하는데 32비트가 주어진다면,
프로세서를 위한 두 가지 간단한 인코딩 형식을 만들 수 있음.
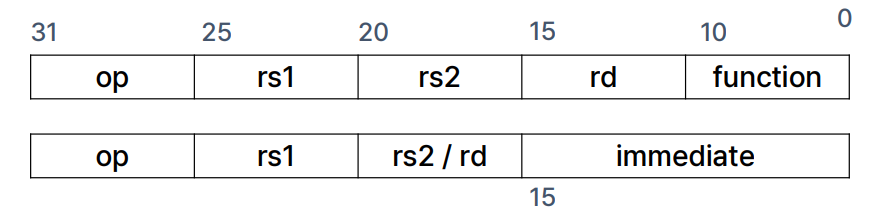
Processor Datapath - PC and Instruction Memory
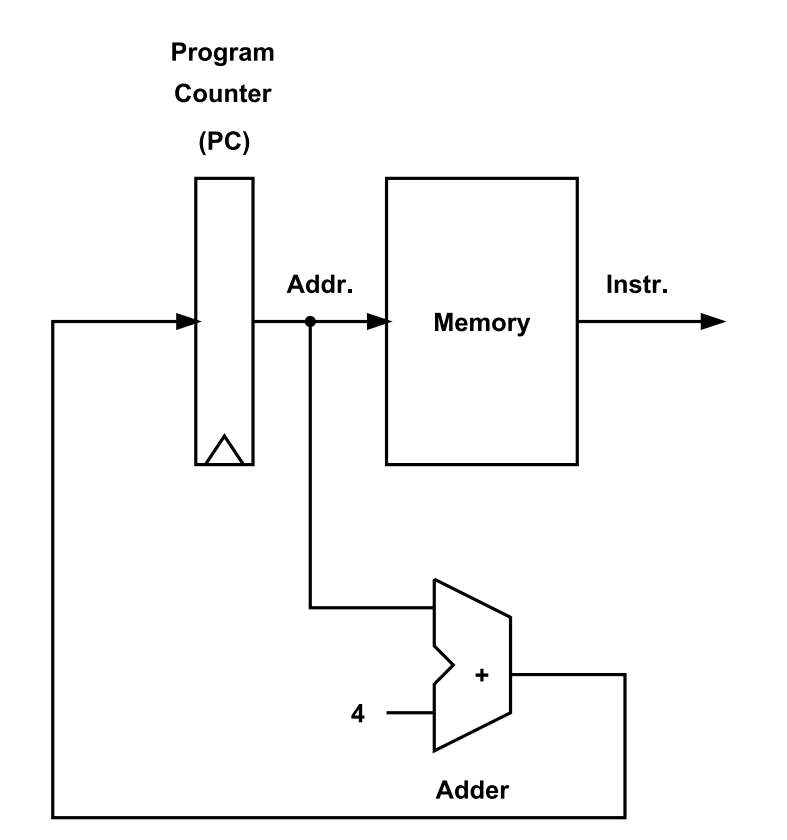
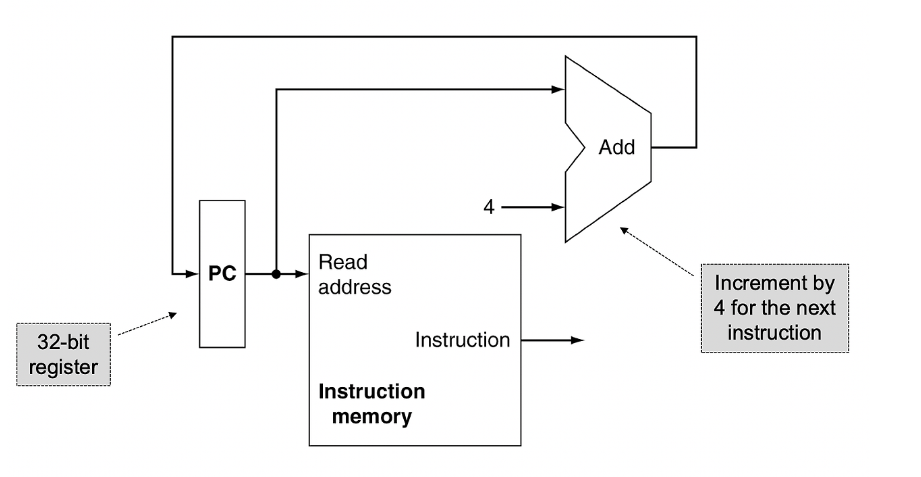
같은 의미의 사진 2개
1) PC(Program Counter)
: 실행해야 할 명령어의 주소를 가지고 있는 레지스터
2) Instruction Memory
: PC로 부터 주소를 읽어들이고 주소에 맞는 Instruction을 output으로 내보냄
3) Add
: PC 값을 4byte 씩 증가시키는 연산을 수행함.
: 즉, 다음 명령어의 주소값으로 pc를 업데이트
- 여기선 32bit의 간단한 프로세서를 가정했으므로
Add한 번에 32bit = 4Byte를 증가시킴.
8bit = 1Byte
즉, 4Byte = 32bit
- MUX(멀티플렉서)를 추가할 경우
MUX(Multiplexer)란?
: 복수 개의 입력 신호로부터 특정 조건에 의해 입력 신호를 한 개만 선택할 때 사용하는 것.
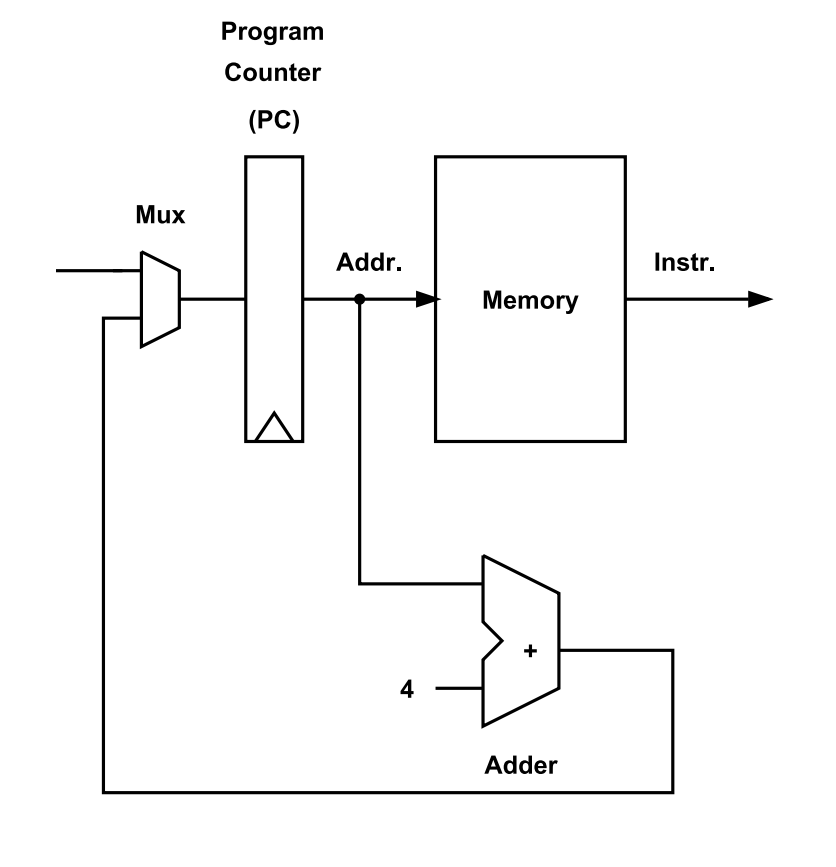
- 여기선
mux를 추가하여 브랜치 대상 주소(branch target adderess), 즉 가져온 브랜치 다음의 PC값을 제공할 수 있도록 함.
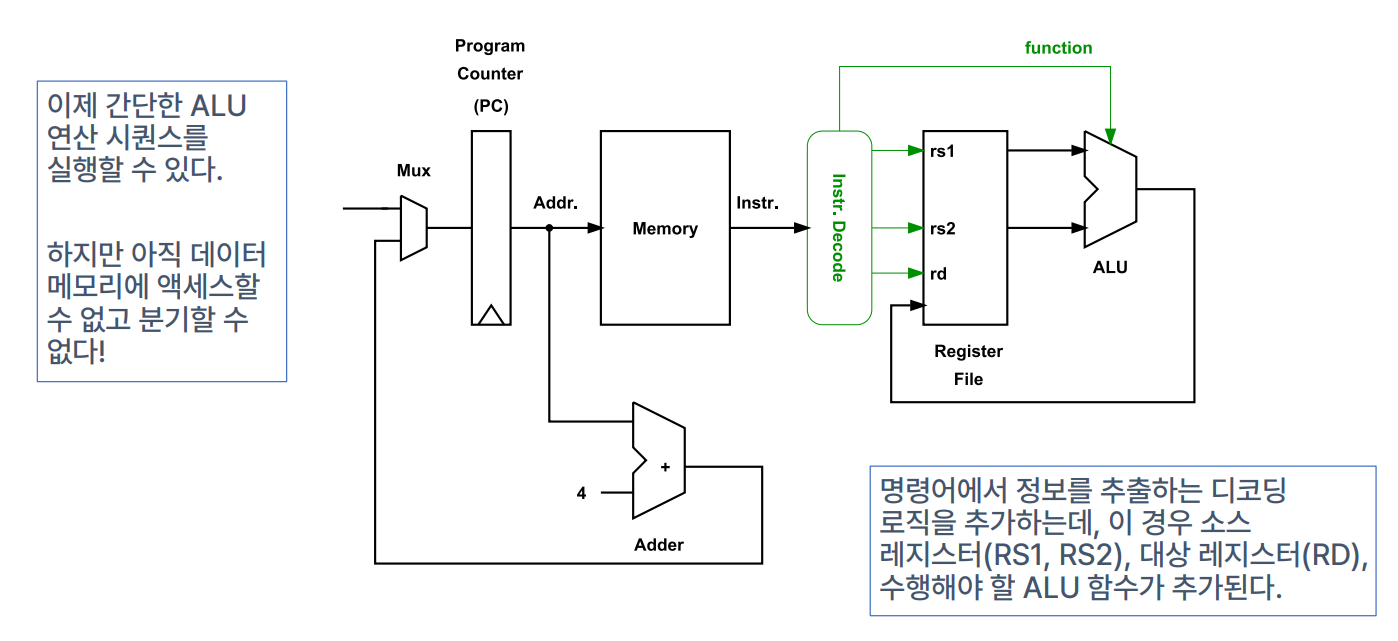
Processor Datapath - Add a Resgister File and ALU
- 간단한 ALU 연산 시퀀스를 실행할 수 있도록 디코딩 로직 추가
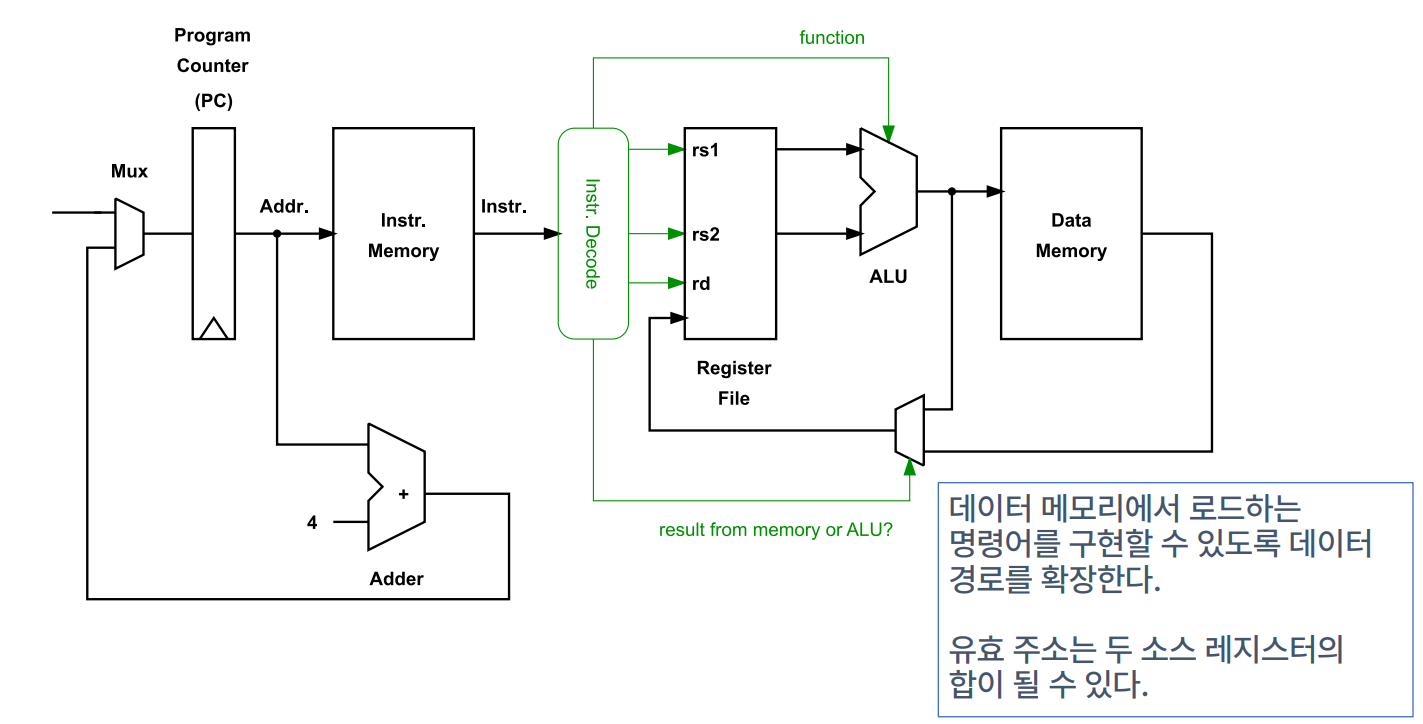
Processor Datapath - Loading from Data Memory
- 데이터 메모리에서 로드하는 명령어를 구현할 수 있도록 데이터 경로를 확장.
- 유효 주소는 두 소스 레지스터의 합이 될 수 있음
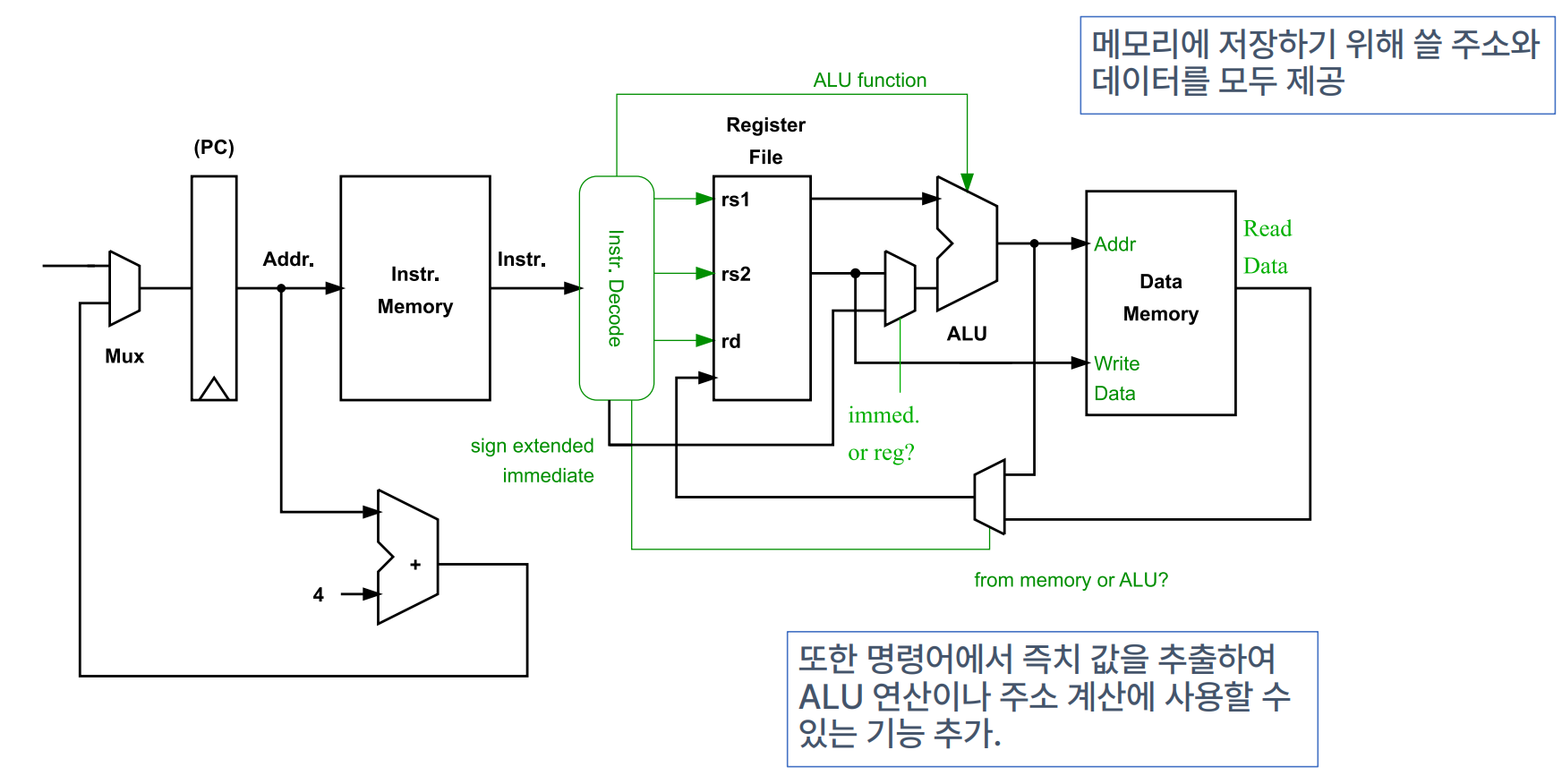
Processor Datapath - Storing to Data Memoery
- 메모리에 저장하기 위해 쓸 주소와 데이터를 모두 제공
- 명령어에서 즉치 값을 추출하여 ALU 연산이나 주소 계산에 사용할 수 있는 기능 추가
Processor Datapath - Supporting Branch Instructions
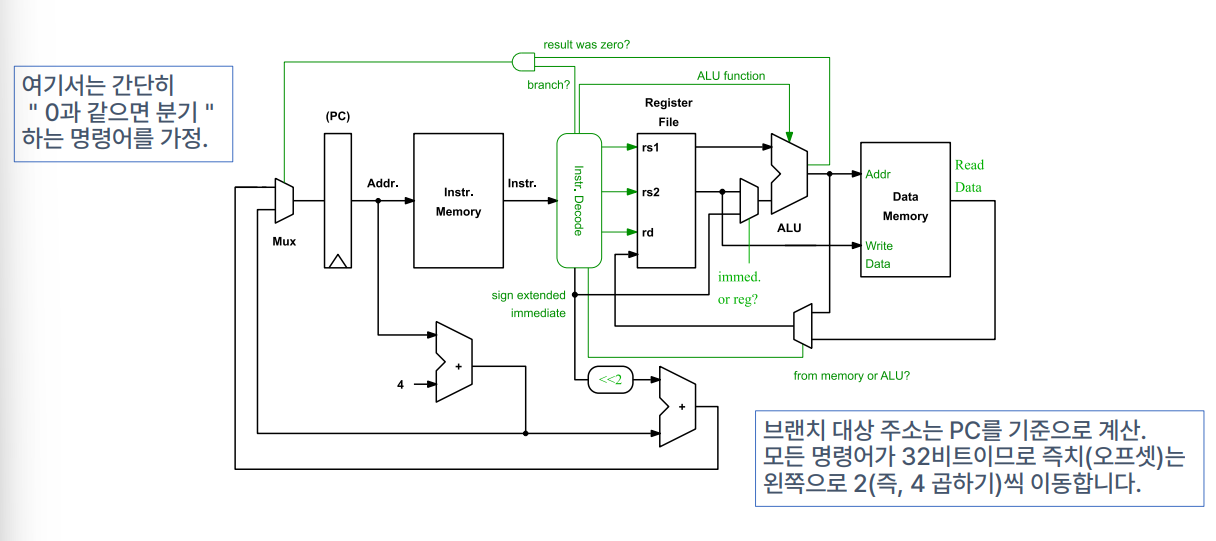
The Fundamentals of Computer Design
Architecture
: 개발자가 소프트웨어 및 펌웨엉를 작성할 수 있도록 하는 사양(specifications) 집합, 명령어 세트가 포함 되어 있음
Microarchitecture
컴퓨터 내부 구조의 논리적 구성
Hardware of Implementation
: 구현 또는 물리적 구조
: 로직 설계 및 칩 패키징
Amdahl's Law
- 리소스를 어떻게 할당할 수 있을까?
암달의 법칙
: 컴퓨터 시스템의 요소를 개선하여 얻을 수 있는 성능 향상을 계산하는 간단한 방법
: 즉, 컴퓨터 시스템의 일부를 개선할 때 전체적으로 얼마만큼의 최대 성능 향상이 있는지 계산하는데 사용되는 법칙.
: ex. 프로세서 개수에 따라 시스템 성능이 어느정도 향상되는가?

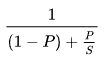
1-P병렬처리가 불가능한 부분
P병렬 처리가 가능한 부분
S프로세서 개수
EX. 병렬 처리가 가능한 부분이 95%, S가 무한대로 놓았을 경우. 임계점은 1/(1-0.95) = 20. 즉, 최대한 프로세서를 늘려도 20배가 최대 성능 향상의 마지노선
성능 개선의 한계
: 설계의 한 부분만 개선하여 얻을 수 있는 속도 향상은 개선이 이루어질 수록 점차 감소.
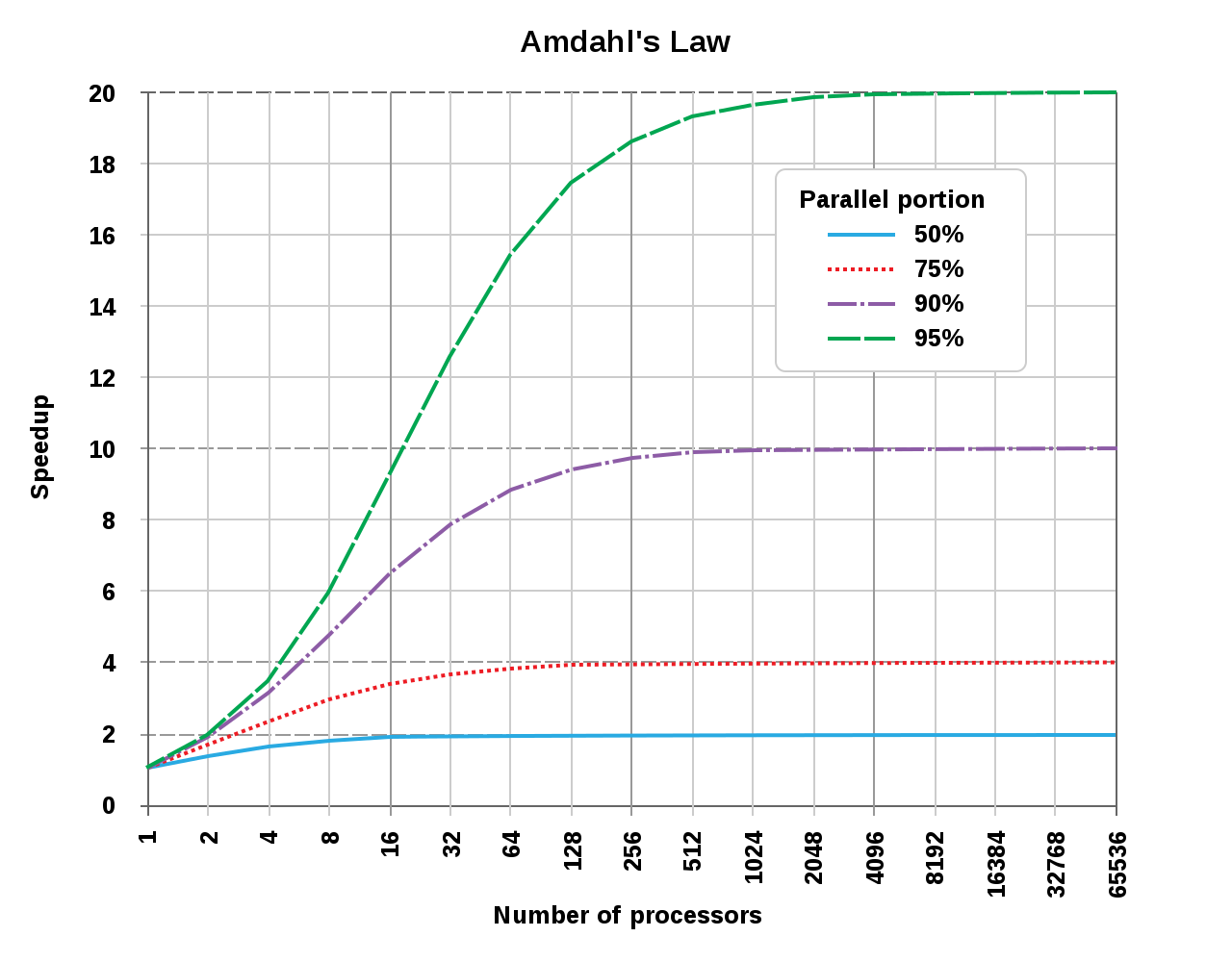
결론,
단일 최적화에 집중하면 하드웨어 투자에 따른 성능 개선이 줄어들게 된다. 이는 각 최적화를 적용한 후 개선할 부분을 신중하게 재평가하고 하드 웨어를 투자해야 함을 시사.
Complexity
엔지니어링에서는 다른 모든 것이 동일할 때, 단순한 것이 항상 더 좋으며 때로는 훨씬 더 좋다.
- 엔지니어링에서 복잡성은 설계 및 검증 비용을 증가시킴.
Benchmarks
벤치마크는 일반적인 사례(common cases)를 파악하고 디자인 프로세스를 안내하는 데 도움을 줌.
Instruction Set Architecture(ISA)
-
ISA: 소프트웨어와 하드웨어 간의 연결

-
명령어 집합은 컴파일러에서 하드웨어로 전달할 수 있는 정보, 즉 소프트웨어에 노출되는 하드웨어 세부 정보와 숨겨지는 하드웨어 세부 정보를 정의.
Q1. 이 HW/SW의 구분선 또는 인터페이스를 어느 수준에서 그릴 것인가? -
HW/SW의 구분선 또는 인터페이스를 그리는 수준은 시스템의 설계 목표와 요구사항에 따라 다를 수 있습니다. 일반적으로 이러한 구분선은 추상화 수준(Abstraction Level)에 따라 결정됩니다. 높은 추상화 수준에서는 소프트웨어가 하드웨어에 대해 일반적인 명령을 내리고, 하드웨어는 이러한 명령을 하드웨어 동작으로 변환하는 역할을 합니다. 낮은 추상화 수준에서는 소프트웨어는 직접 하드웨어 레지스터나 명령을 조작할 수 있습니다. 따라서 구분선은 소프트웨어와 하드웨어 간의 통신 및 상호작용을 정의하며, 이는 소프트웨어 개발자와 하드웨어 엔지니어 간의 협업을 지원합니다.(GPT)
Q2. 하드웨어를 단순화하기 위해 하드웨어에 전달하면 유용한 다른 정보는 무엇인가.
- 추상화된 명령어 집합(Instruction Set Architecture, ISA): 하드웨어에서 지원하는 명령어 집합을 정의하고, 소프트웨어가 하드웨어와 통신할 때 사용할 수 있도록 합니다.
- 입출력 인터페이스: 하드웨어와의 데이터 교환을 위한 표준화된 프로토콜 및 인터페이스를 제공합니다.
- 에러 및 예외 처리 메커니즘: 하드웨어에서 발생하는 에러나 예외 상황을 처리하기 위한 정보를 제공하여 소프트웨어가 이를 적절히 처리할 수 있도록 합니다.
(GPT)
Q3. 어떻게 하면 좋은 코드 밀도(CODE DENSITY)를 보장할 수 있을까?
- 효율적인 알고리즘 및 데이터 구조 선택: 코드가 더 짧고 간결하게 유지될 수 있도록 효율적인 알고리즘과 데이터 구조를 선택합니다.
- 불필요한 코드 제거: 사용되지 않는 코드를 제거하고, 중복 코드를 최소화하여 코드의 불필요한 부분을 줄입니다.
- 최적화된 컴파일러 및 라이브러리 사용: 최적화된 컴파일러를 사용하고, 효율적인 라이브러리를 활용하여 코드의 밀도를 개선합니다.
- 인라인 함수 및 코드 재배치: 인라인 함수를 사용하거나 코드를 재배치하여 함수 호출 오버헤드를 최소화하고 코드의 밀도를 향상시킵니다.
- 코드 크기 최적화: 컴파일러 옵션을 사용하여 코드 크기를 최적화하고, 불필요한 메모리 사용을 줄여 코드의 밀도를 높입니다.
(GPT)
Instruction Set Architecture
- High level 언어를 직접 실행
- 복잡한 명령어(CISC)를 실행
- 파이프라인 및 고성능 구현을 위해 명령어 세트를 맞춤 설정(tailor)함. 컴파일러에 명령어 파이프라인을 노출하여 코드를 최적화하고 하드웨어를 간소화 할 수 있도록 지원(RISC)
- 명령어 간의 종속성에 대한 추가 명시적 정보를 제공하세요. EX. VLIW
- 개별 데이터 전송 지정(EX. TTA(Transport Triggered Architectures))
