
Introduction
-
최신 마이크로프로세서는 우리가 소통하고 일하는 방식 엔진
-
통신, 연산, 스토리지가 거의 무료에 가까운 디지털 세상을 만드는 데 기여.
-
많은 과학적 혁신을 뒷받침하고 세계의 한정된 자원을 더 잘 활용할 수 있도록 지원

-
현대 컴퓨터의 역사는 100년 이하
-
1930년대와 1940년대에 최초의 전자 기계 및 밸브 기반 기계는 생산
-
오늘날의 컴퓨터는 훨씬 더 빠르고, 전력 소모가 적고, 안정적이며 저렴함.
추상화 수준(Levels of Abstraction)
Architecture
- 개발자가 소프트웨어 및 펌웨어를 작성할 수 있도록 하는 일련의 사양(Specifications)
- 여기에는 명령어 세트가 포함
Micoroarchitecture
- 컴퓨터 내부 구조의 논리적 구성
Hardware or Implementation
- 구현 또는 물리적 구조
ex. 로직 설계 및 칩 패키징
Computer Architecture vs. Organization
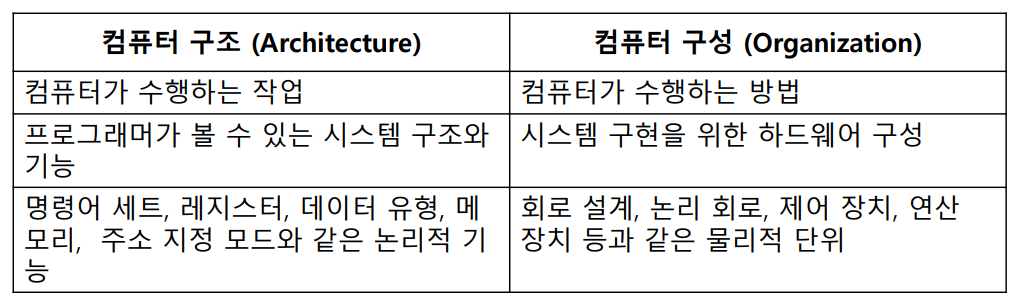
- Computer Organization은 Architecture를 결정한 후에 구현
- Computer Architecture는 하드웨어가 구현해야 하는 것을 결정
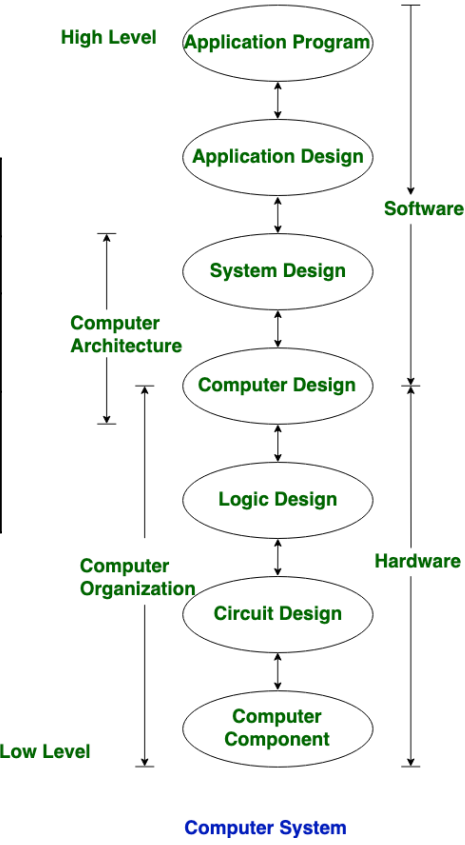
아키텍처 사양(Architecture Specification)
- 아키텍처는 하드웨어와 소프트웨어 간의 명확하고 잘 정의된 연결을 지정
- 예를 들어, 다양한 전력 소비, 비용, 면적, 성능 목표를 충족하기 위해 다양한 호환 프로세서를 구현 가능
- 소프트웨어가 아키텍처 사양을 준수하도록 작성된 경우 이식성을 가질 수 있음
Computer Architecture
- 명령어 집합이나 상위 수준의 아키텍처를 정의하는 그 이상의 작업
- Computer architect는 특정 애플리케이션과 목표 시장에 가장 적합한 설계를 제공하기 위해 모든 수준의 설계에 기여하고 이해해야 한다.
- 시장의 요구를 충족하기 위해 제조 기술을 가장 잘 활용하는 방법에 대한 고민이 필요
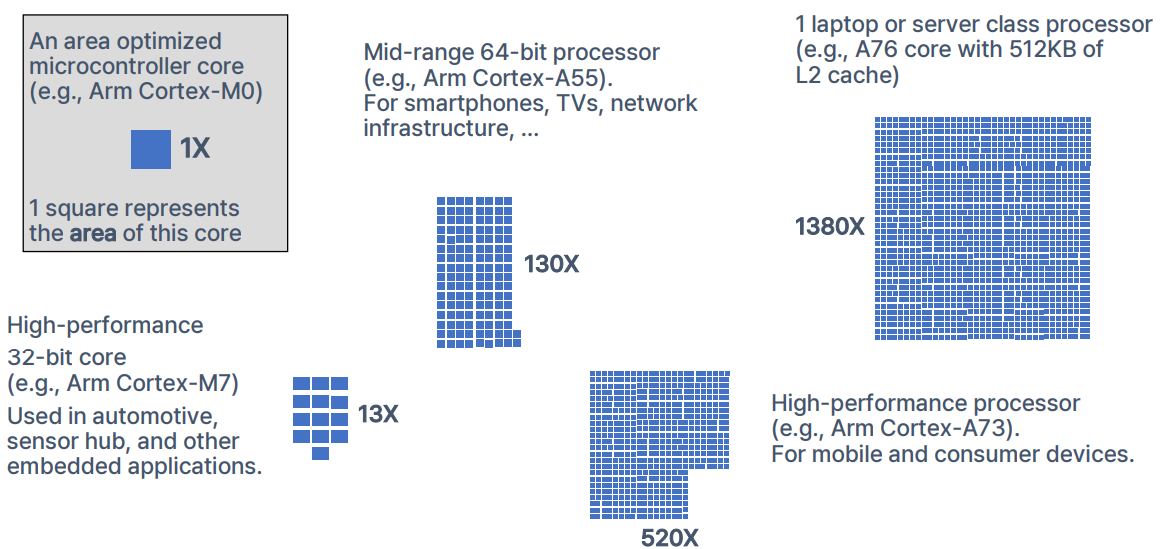
ex. 50억개의 트랜지스터와 2와트의 전력 예산으로 휴대폰의 핵심 칩을 설계하려면 어떻게 하면 가장 효율적으로 사용할 수 있을까? - 컴퓨터 아키텍처는 몇 가지 간단한 개념을 기반으로 구축되지만 끊임없이 새로운 솔루션을 찾아야 하기 때문에 도전적 작업임.
- "최상의 설계"는 시간이 지남에 따라 그리고 사용 사례에 따라 달라지므로 다양한 장단점을 고려해야 함.
- 각 디자인 수준은 시간이 지남에 따라 변화하는 다양한 요구사항과 제약 조건을 반영
- 역사 및 경제성
: 생태계(ex. 소프트웨어)에 대한 중단과 발생 가능한 비용을 최소화하는 방식으로 진화해야 한다는 상업적 압력이 존재 - 과거의 기술과 워크로드에 맞춰 설계하지 말고 미래를 내다봐야 할 필요성도 존재!
- 설계는 실험을 통해 신중하게 결정
Computer Architecture Arena
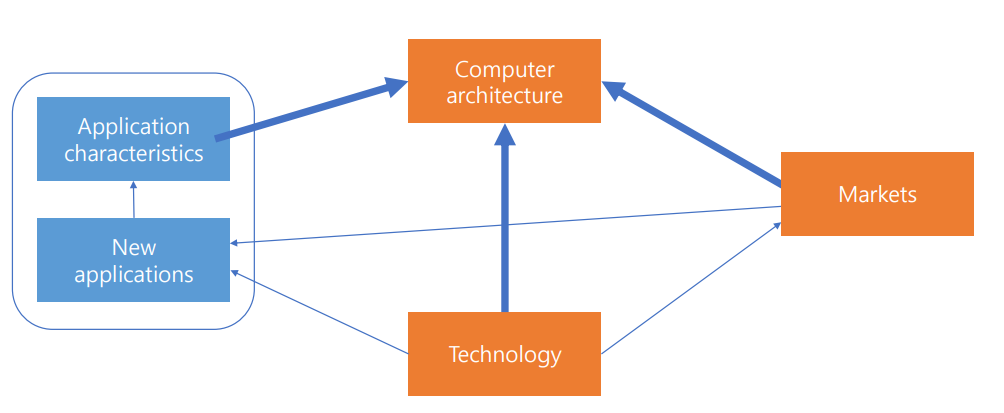
- 기술과 시장, 어플리케이션의 특징과 새로운 어플리케이션이 Computer Architecture에 영향을 주고 있는 모습이 보임.
Design Goal
- 디자인 프로세스에서 달성하고자 하는 목표나 목적
Functions(기능)
- 소프트웨어와 달리 수정이 어려우며, 검증은 설계 프로세스에서 가장 많은 비용이 듦.
- 칩이 제조된 후, 테스트에도 많은 비용이 들기 때문에 설계 단계에서 신중한 고려가 필요함
Performance(성능)
- 작업 부하에 따라 달라지기 때문에 정답은 없음
ex. 스포츠카와 오프로드 4x4는 어디서 쓰이냐에 따라 좋고 그름이 가려짐
Power(전력)
- 오늘날 대부분의 설계에서 가장 먼저 고려되는 설계 제약 조건으로 전력은 대부분의 시스템 성능을 제한
Security(보안)
- 민감한 데이터에 대한 액세스를 제어하거나 신중하게 조작된 악의적 입력이 프로세서의 제어권을 탈취하는 것을 방지
Cost(비용)
- 설계 비용(복잡성)
- 다이 비용(즉, 칩의 크기 또는 면적)
- 패키징
Reliability(신뢰성)
- 작동 중 오류를 감지 및/또는 허용해야 하는가?
Markets and Features
- 각 목표 시장마다 전력 소비, 비용, 면적, 성능, 보안, 신뢰성 등의 측면에서 서로 다른 절충안이 필요
- 다음은 Arm의 몇 가지 프로세서 클래스 예시
1. Cortex-A
: 고성능 애플리케이션 프로세서(ex. 휴대폰용)
2. Cortex-R
: 결정론적 실시간 성능(deterministic real time performance), 오류 감지(fault detection) 및 내성(tolerance)
3. Cortex-M
: 에너지 효율적인 임베디드 디바이스
(ex. 마이크로컨트롤러 클래스 코어)
4. Neoverse
: 단일 칩의 확장 가능한 프로세서 네트워크
: 즉, 단일 칩에 여러 개의 코어를 통합하여 확장 가능한 프로세서 네트워크를 구축
ex. 8, 16, 64 또는 128코어, 데이터센터, 엣지 서버 및 스토리지에 사용
Smartphone
- 하나의 스마트폰에는 다양한 프로세서 코어를 포함
- 왜 단일 프로세서를 사용하지 않을까?
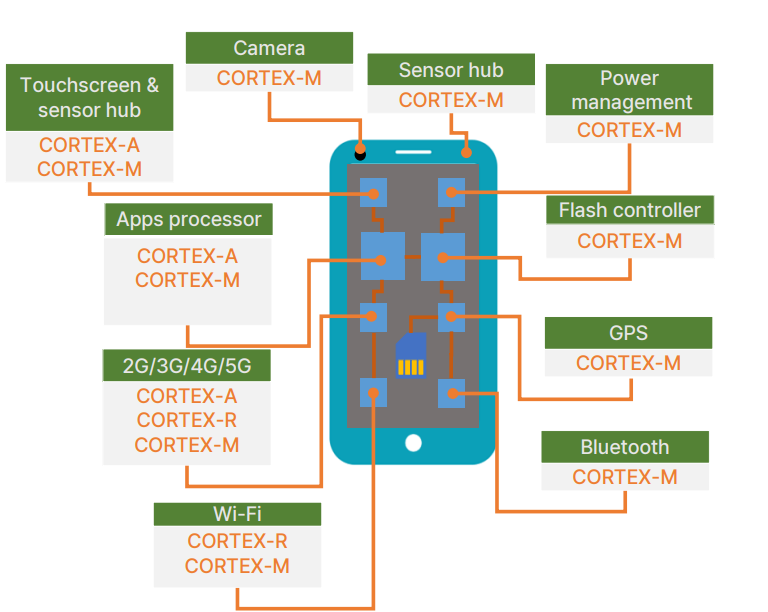
Cortex-M 사용
- 카메라
- 센서 허브
- 전력 관리
- 빛 컨드롤(손전등)
- GPS
- 블루투스
Cortex-A & M 사용
- 터치스크린과 센서허브
- 앱의 프로세서
Cortex-R & M 사용
- 와이파이
Cortex-A & R & M
- 2/3/4/5G
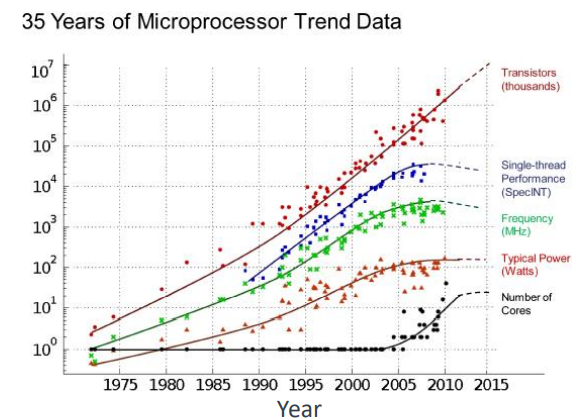
Historical Performance Gains
-
1985년에는 완전한 마이크로 프로세서를 하나의 die(다이) 또는 chip(칩)에 통합
die란
: 실리콘 웨이퍼의 작은 조각
: 즉, 한 개의 IC 칩을 만들기 위해 필요한 작은 부분 -
위 문장의 의미는 여러 개의 IC칩에 분산되어 있던 마이크로프로세서의 기능을 한 개의 다이 또는 칩에 모두 통합하여 제작한다는 것
-
즉 집적도(Integration Density)가 높아지고, 전력 효율성이 향상, 제조 및 설계 과정의 간소화
-
제조 기술이 향상되고 트랜지스터의 크기가 작아지면서 단일 코어의 성능이 빠르게 향상
-
거의 20년 동안 매년 52%의 비율로 성능이 향상
-
Clock period(클럭 주기)
: 디지털 시스템에서 사용되는 클럭 신호의 한 주기
: 1985~2002년 사이에 빠르게 개선
: 더 빨라진 트랜지스터로 인해 ~10배 그리고 파이프라이닝(pipelining) 및 회로 수준(circuit-level)의 발전으로 약 ~10배
: 즉, 전체적으로 총 800배의 성능 향상 중 약 100배는 클럭 주기 단축에서 비롯
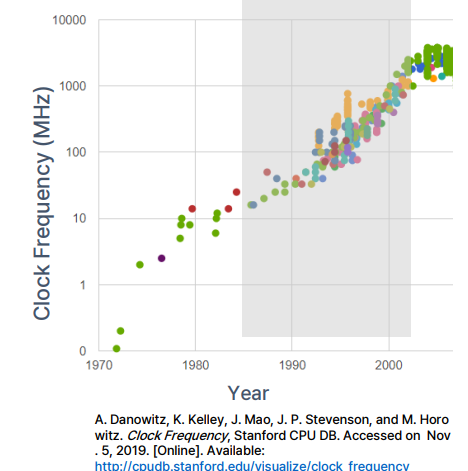
-
시간이 지남에 따라 기술 확장을 통해 훨씬 많은 수의 더 빠르고 저전력인 트랜지스터 제공
-
프로세서 성능의 철의 법칙(iron law)
시간 = 실행된 명령어 x 명령어당클럭(CPI) x 클럭 주기
-
명령어당 클럭(CPI)
: cycles per instruction
-
또한 사이클당 명령어(IPC, instruction per cycle)를 사용, 즉 1/CPI
Clocks Per Instruction(CPI)
- 초기 컴퓨터는 트랜지스터 수의 제한으로 각 명령을 실행하는 데 여러 클럭 사이클이 필요(CPI >> 1)
- 트랜지스터 예산이 개선되면서 CPI가 1에 가까워지는 것을 목표로 함
- 클럭 주파수에 전혀 신경 쓰지 않는다면 이는 쉬운 일
- 그러나 CPI가 좋은 고주파(high frequency) 설계가 훨씬 더 어려움. 고성능 프로세서를 계속 바쁘게 유지하면서 멈추는 것을 방지해야 CPI를 높일 수 있기 때문에 다양한 기술이 필요하고 트랜지스터(면적)와 전력 비용이 많이 든다.
- 결국 클럭 사이클 당 여러 개의 명령어를 가져와 실행할 수 있게 됨으로써 CPI는 1 이하로 감소
- 여러 명령어를 함께 가져와 실행할 때, 종종 1/CPI인 사이클 당 명령어(IPC)로 참조
- 명령어가 동시에 실행되려면 명령어가 독립적이어야 함.
- 트랜지스터 예산이 증가하면서 이 명령어 수준 병렬 처리(ILP)를 찾고 활용하는 데 도움.
Pipelining
여러 작업들을 병렬(pallerism)성을 이용해서 빠르게 작업하는 방법
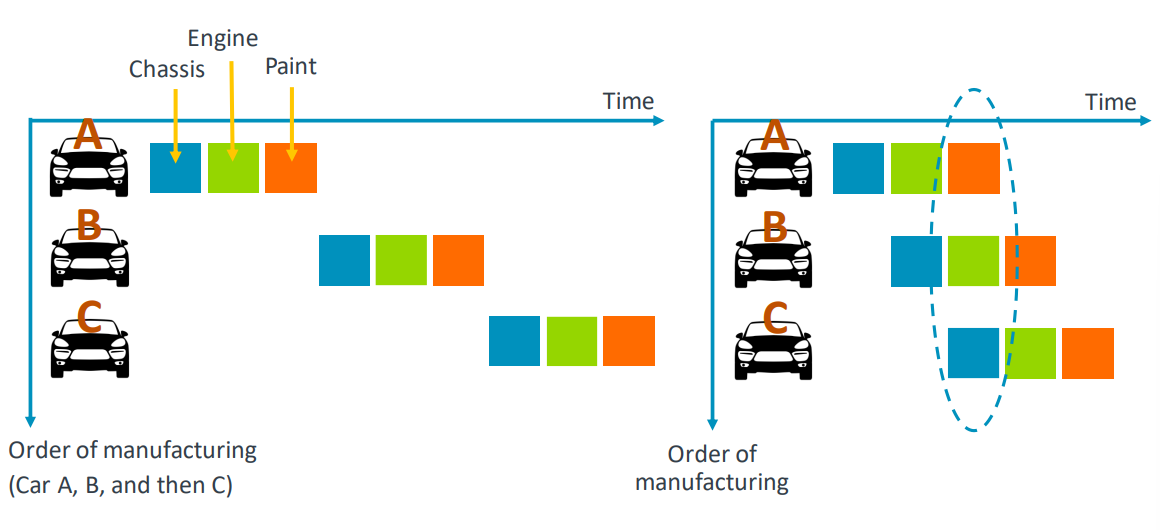
- 원래라면 9시간이 필요하지만, 병렬성을 이용하면 5시간만에 완료
IPC and Instruction Count
- 800배의 성능 향상 중 약 100배는 클럭 주파수 개선으로 인한 것
- 나머지 향상분(약 8배)는 명령어 수 감소, 컴파일러 최적화 개선, IPC 개선으로 인한 것임.
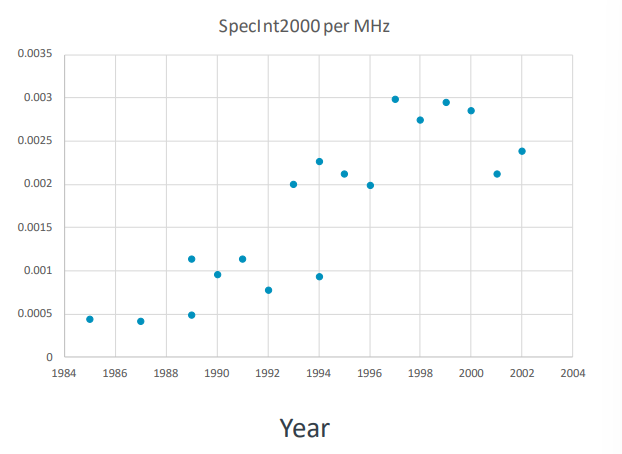
- 이 그래프는 성능(시간 대비 인텔 프로세서의 MHz당 Speclnt2000 벤치마크 성능)을 표시
Shorter Critical Path
- 임계 경로의 게이트 수를 줄이는 방법도 있음
- 이는 추가 레지스터를 삽입하여 복잡한 로직을 여러 '파이프라인'단계로 나누면 가능
- 회로 수준의 설계 기술도 발전
- 임계 경로의 길이가 약 10배(1985~2002)감소
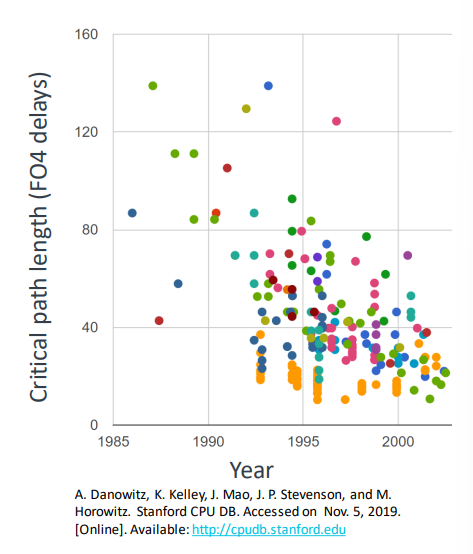
임계 경로(Critical Path)란?
시스템에서 가장 긴 지연을 갖는 경로
시스템의 전체 속도를 결정하는 핵심 요소
임계경로의 게이트 수 줄이기
: 임계 경로 상에 있는 논리 회로의 게이트 수를 감소
Moore's Law
- 동일한 비용으로 칩에 통합할 수 있는 트랜지스터의 수가 2년마다 두 배로 증가
- 마이크로 아키텍처가 더욱 복잡해지면서 프로세서 트랜지스터 예산은 빠르게 증가함
1985 - 인텔 386
- 275K 트랜지스터, 다이 크기 = 43mm^2
2002 - 인텔 펜티엄 4
- 42M 트랜지스터, 다이 크기 = 217mm^2
Better Performance and Lower Power
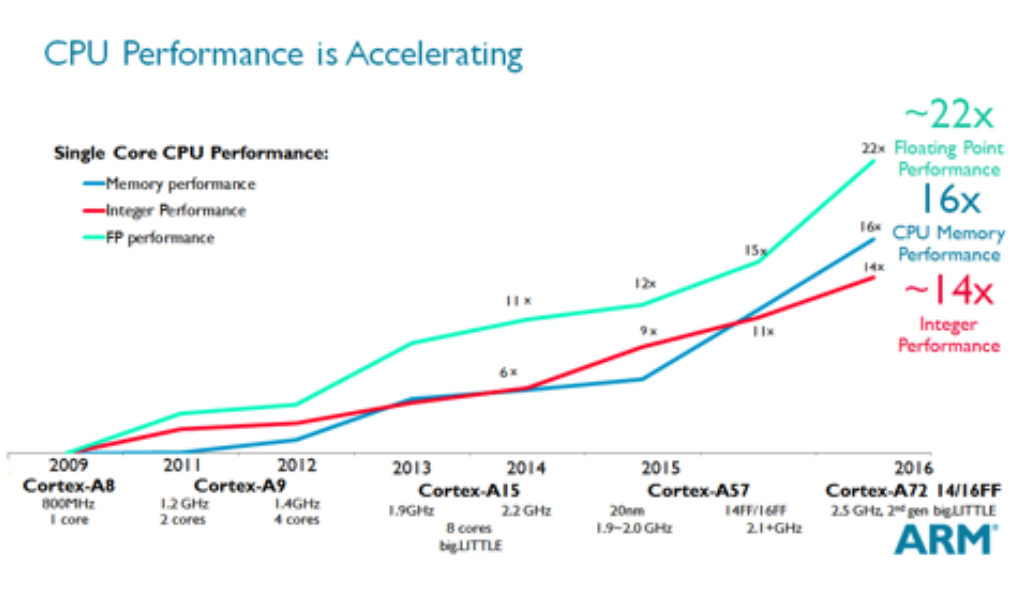
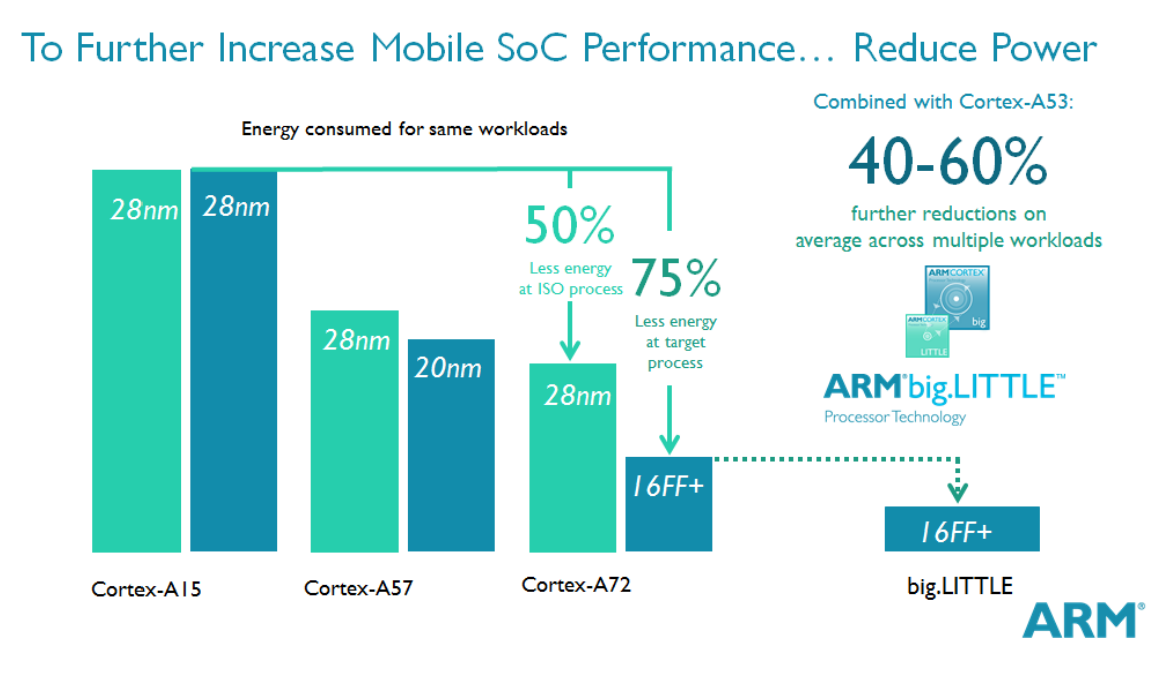
Slowing Single-core Performances Gains
-
요약하자면, 단일 코어 성능 향상을 지속하는 것은 어려워짐
: 파이프라이닝의 한계
: 명령어 수준 병렬 처리(ILP)의 한계
: 전력 소비
: 온칩 와이어의 성능 -
그 결과 최고 성능 프로세서의 경우 성능 향상이 연간 52%에서 21%로 둔화
Multicore Processors
-
결국 코어에서 멀티코어 설계로 전환 것이 합리적
-
2005년부터 멀티코어 설계가 대세
-
단일 칩의 코어 수는 시간이 지남에 따라 증가
-
클럭 주파수는 더 천천히 증가
-
개별 코어는 가능한 한 전력 효율을 높이도록 설계

-
다중 코어를 활용하는 데에는 여러가지 어려움과 한계가 존재
- 전력 소비로 인해 성능이 여전히 제한될 수 있음
- 이를 활용하려면 확장 가능하고 올바른 병렬 프로그램을 작성해야 함
- 코어를 활용하기에 충분한 병렬 스레드를 찾지 못할 수 있음
- 온칩 및 오프칩 통신은 성능 향상을 제한함.
: 오프칩 대역폭은 제한되어 있으며 많은 코어를 스로틀링 할 수 있음
: 또한 코어는 메모리에 대한 coherent view를 유지하기 위해 통신을 해야 함.
온칩 vs. 오프칩
: 반도체 디바이스에서의 두 가지 다른 위치를 가리키는 용어
1. 온칩(On chip)
반도체 칩(chip or die) 내부에 있는 것을 가리킴. 즉, 프로세서 칩 내부의 캐시 메모리, 레지스터, 논리회로 등은 온칩에 포함
2. 오프칩(Off chip)
오프칩은 반도체 칩 외부에 있는 것. 주 메모리(RAM), 그래픽 카드, 하드 디스크 드라이브 등과 같은 외부 디바이스를 가리킴
Core란?
멀티코어 프로세서에서 각각의 처리 유닛을 가리킴. 메모리에 대해 일괄된 coherent view를 유지하기 위해 서로 통신을 해야함.
- 멀티 코어 시스템에서 각 코어는 동시에 다양한 작업을 수행할 수 있지만 코어는 주로 하나의 메모리 공간을 공유하며, 서로 다른 코어들이 동시에 메모리에 접근하여 데이터를 읽거나 쓰는 경우가 발생하므로 메모리 일관성(memory coherent)를 유지해야 함.
Specialization
- 오늘날에는 설계 목표를 달성하기 위해 범용 프로그래머블 프로세서 이상의 것을 찾아야 하는 경우가 많음
- 이를 위해, 유연성과 효율성을 맞바꿈
- 모든 프로그램을 실행할 수 있는 기능을 제거하고 좁은 워크로드(narrow workload), 심지어 단일 알고리즘을 위한 설계
- 이러한 '가속기'는 전력과 성능 면에서 범용 솔루션보다 10~1000배 더 우수할 수 있다.
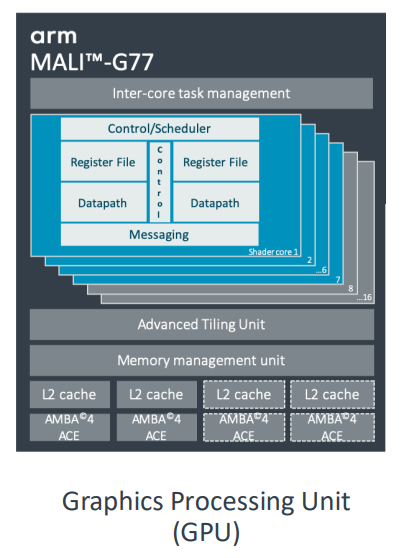
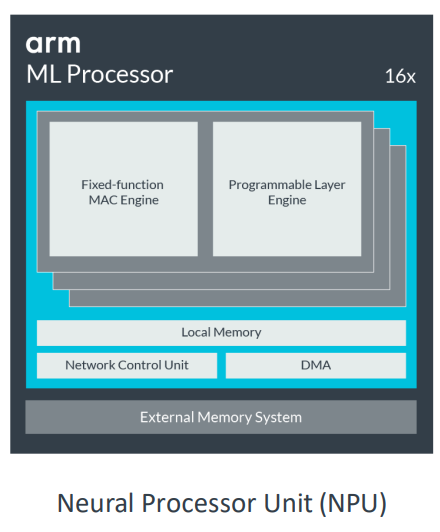
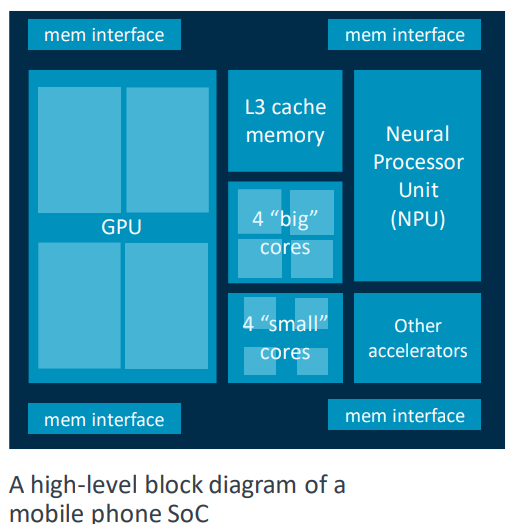
Today's SoC Designs
- 최신 휴대폰 SoC에는 70억 개 이상의 트랜지스터가 포함될 수 있다
: 여러 프로세서 코어
: GPU
: 다수의 특수 가속기
: 대량의 온칩 메모리
: 오프칩 메모리에 대한 고대역폭 인터페이스
Trends in Computer Architecture
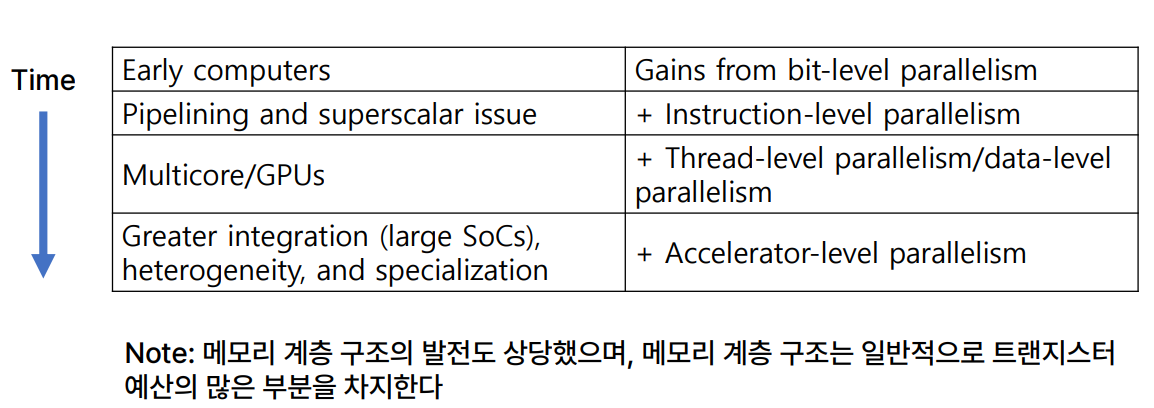
Note
: 메모리 계층 구조의 발전도 상당했으며, 메모리 계층 구조는 일반적으로 트랜지스터 예산의 많은 부분을 차지.
The Future - The End of Moore's Law?
- 무어의 법칙 종말은 여러 차례 예측되어 왔다.
- 최근 몇 년 동안 스케일링 속도가 느려졌지만 트랜지스터 밀도는 계속 향상
- 결국 2D 스케일링 속도도 느려질 수 박에 없다.
: 궁극적으로는 원자의 크기에 의해 제한될 수 밖에 없음! - 다음 단계?
: 3D로 가기 - 미래의 설계는 단일 칩에 여러 층의 트랜지스터를 활용할 수 있음
: 더 나은 패키징 및 통합 기술(ex. 칩 스태킹)
: 새로운 유형의 메모리
: 새로운 재료 및 장치
cf. 이득은 기하급수적으로 증가하는 것이 아니라 선형적으로 증가
From Sensors and Smartphones to Servers
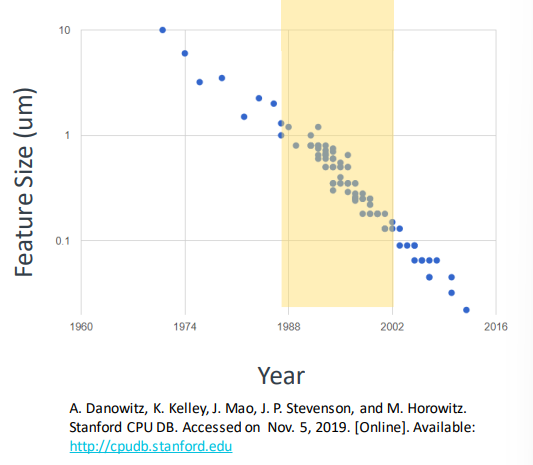
Technology Scaling : Faster Transistors
- 1985~2002까지 약 7세대에 걸쳐 새로운 공정이 탄생
- 스케일링은 더 작고 더 빠른 트랜지스터를 제공
- 성능은 세대 당 약 1.4배 향상
- 7세대 동안 약 10배 빠른 로직 게이트를 갖게 됨
Instruction Count
- 데이터 경로 폭 증가
: ex. 16bit -> 32bit -> 64bit - 더 커진 레지스터 파일(로드/저장 명령어 수 감소)
- 더 복잡한 명령어?
- SIMD 명령어
: 하나의 명령어가 여러 개의 데이터 요소를 동시에 처리할 수 있는 명령어 집합
Limits to Single Core Performance
파이프라이닝의 한계
- 캐시 미스 및 잘못된 브랜치 예측으로 인한 영향 등 중단(interruptions)으로 인한 비용 증가
- 궁극적으로 일부 구성 요소는 파이프라이닝하기 어렵거나 비용이 많이 듬
- 또한 매우 높은 주파수의 클럭을 배분하는 데는 현실적인 한계가 있고, 레지스터는 유한한 지연을 나타내며, 파이프라인 단계 간에 로직의 균형을 맞추는 데 어려움 존재.
명령어 수준 병렬 처리의 한계
- 대량의 ILP는 효율적으로 발견하고 활용하기가 매우 어려움
- 즉, 더 적은 양의 ILP를 노출하고 활용하기 위해 더 많은 전력과 더 많은 트랜지스터를 사용해야 하기 때문에 투자 대비 이득이 빠르게 감소함
Power consumption
- 역사적으로 성능 향상은 인상적이었지만 1980년대와 1990년대에는 전력 소비도 매우 빠르게 증가
- 이는 제조 기술이 개선되고 공급 전압이 감소했음에도 발생
- 전력은 모든 주요 시장에서 가장 중요한 설계 제약 조건이 되었으며, 지금도 마찬가지
On-chip wiring(온칩 와이어)
- 와이어 지연은 로직 지연에 비해 상대적으로 잘 확장되지 않음
- 따라서 한 클럭 사이클에서 도달할 수 있는 상태(state)의 양이 제한
- 이는 대규모이 복잡한 프로세서의 성능을 제한
와이어 지연 vs 로직 지연
1. 와이어 지연
: 전기 신호가 전선을 통해 전파되는 데 걸리는 시간
2. 로직 지연
: 디지털 논리 게이트에서 입력이 변경된 후 출력이 변경될 때까지 걸리는 시간
Specialization(전문화)
전문화를 통해 할 수 있는 것
- 프로세서에서 자주 사용되지 않는 부분을 제거
- 일반적인 작업을 위해 명령어 세트를 조정하거나 하드 와이어드 제어로 대체
- 애플리케이션에 풍부한 병렬 처리 형태를 활용
- 전용 메모리를 인스턴스화하고 폭과 크기를 조정
- 구성 요소 간에 특화된 상호 연결을 제공
- 데이터 사용 패턴을 최적화
Limits to Specialization
- 새로운 가속기를 설계할 때마다 비용이 발생
- 생산된 칩, 즉 ASIC는 소규모 목표 시장에서만 경쟁력이 있어 수익성이 떨어짐
- 전문화는 유연성을 떨어뜨림
: 전문화된 가속기에 투자된 로직은 더 이상 범용적이지 않음
: 알고리즘이 변경되면 전문화된 하드웨어가 쓸모 없어질 수 있음 - 한 번 전문화 하면 더 이상의 이득을 얻기가 어려움
: 전문화도 수익률 감소라는 개념에서 자유롭지 않음
ASIC란?
Application Specific Intergrated Circuit
: 특정 응용 프로그램이나 용도에 특화된 집적 회로를 의미
