
▶ Registers and Instruction Sets
Data sizes and Instruction sets
-
ARM 은 RISC(Reduced Instruction Set Computing) 구조 → 저전력 / 단순
-
간단한 만큼 컴파일러는 복잡해질 가능성 존재
-
ARM은 32bit의 load/store architecture 가짐
: 메모리에 접근할 때 load/store 명령어만 허용
: 시스템 내부 레지스터 중 대다수가 32bit 폭을 가짐(32 bit wide) -
Arm 아키텍처의 용어
1. Halfword
: 16비트(2byte) 데이터나 메모리 주소
2. Word
: 32bit(4byte)
3. Double Word
: 64bit(8byte)
즉, 데이터의 크기를 명확하게 정의하고 표현하는 데 사용
Arm 코어 대부분은 두 가지 명령어 세트 구현
1. 32비트 arm 명령어 세트
: 전통적인 arm 아키텍처 명령어 세트
: 32비트 데이터 및 주소를 처리하고 연산 수행
2. 혼합 16비트 및 32비트 Thumb 명령어 세트
: 더 작고 효율적인 명령어 제공하여 코드 크기를 줄이고 전력 소비를 줄임. 즉, 16비트와 32비트 명령어가 혼합. 상대적으로 간단한 작업을 수행할 때 사용.
위의 2가지 명령어 세트를 함께 구현함으로써 다양한 요구 사항에 대응 가능. 복잡한 작업에는 32비트 arm 명령어 세트를 사용. 코드 크기와 전력 소비를 최적화 해야 하는 경우에는 혼합 16비트 및 32비트 Thumb 명령어 세트를 사용
▶ Arm register set
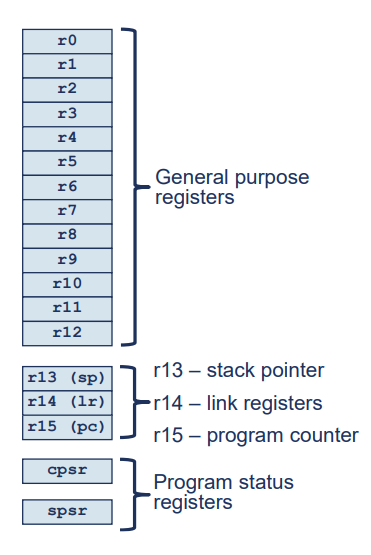
16개의 범용 레지스터(General Purpose Register)
특별한 의미를 가진 레지스터
r13(Stack Pointer, SP)
: 스택 프레임의 시작 위치를 가리키는데 사용r14(Link Register, LR)
: 서브 루틴 호출 시 다음 실행할 명령어의 주소 저장r15(Program Counter, PC)
: 다음에 실행할 명령어의 주소 저장
두 개의 상태 레지스터(Status Registers)
CPSR(Current Program Status Register_
: 현재 프로그램 상태 레지스터
: 현재 프로세서 상태 및 실행 조건을 나타냄SPSR(Saved Program Status Register)
: 저장된 프로그램 상태 레지스터
: 예외 모드에서만 존재
: 예외가 발생했을 때 현재 상태를 보존하는 데 사용
: 특정 명령어에 의해서만 접근 가능
Program status registers

control field
extended field
state field
flag field
- signed 연산: 부호 있는 연산
- unsigned 연산: 부호 없는 연산
- carry: 연산 결과가 해당 비트 크기를 초과하여 발생하는 자리 올림을 의미
- overflow: 주로 부호 있는 정수 연산에서 발생합니다. 연산 결과가 해당 자료형의 표현 범위를 초과할 때 발생. 예를 들어, 8비트 부호 있는 정수에서 127과 1을 더하면, 결과는 -128이 아닌 128. 이는 부호 있는 정수의 표현 범위를 벗어나는 것이므로 오버플로우가 발생함.
condition code flags
- N = Negative result from ALU
- Z = Zero result from ALU
- C = ALU operation Carried out
- V = ALU operation oVerflowed
sticky overflow flat - Q flag
- Architecture 5TE and later only
: 아키텍처 버전이 5TE 이상인 경우에만 해당 기능 지원 - Indicates if saturation has occurred
: 연산 중 overflow가 발생했는지 여부를 나타냄
J bit
- Architecture 5TEJ and later only
: 5TEJ 아키텍쳐 버전 이상에서만 지원 - J = 1: Processor in Jazelle state
: j bit가 1로 설정되면 프로세서는 Jazelle 상태에 있음.
Jazelle
: ARM 아키텍처의 하위 세트
: 프로세서가 네이티브 ARM 코드 뿐만 아니라 Thumb 코드와 Java bytecode도 실행할 수 있도록 함.
Mode bits
- Specify the processor mode
: 프로세서의 모드를 지정함
Interrupt Disable bits
- I = 1: Disables IRQ
: IRQ는 - F = 1: Disables FIQ
IRQ(Interrupt Request)
FIQ(Fast Interrupt Request)
T bit
- T = 0: Processor in ARM state
- T = 1: Processor in Thumb state

New bits in V6
GE[3:0] used by some SIMD instructions
: SIMD(Single Instruction Multiple Data)
: SIMD 명령어의 결과를 처리하는 데 필요한 데이터를 지정E bit controls load/store endianness
: load/store 명령어에서 데이터의 엔디안(Endianness)을 제어A bit disables imprecise data aborts
: 정밀하지 않은 데이터 중단을 비활성화
: 예외 상황이 발생하지 않도록 예방해줌IT [abcde] IF THEN conditional execution of Thumb2
instruction groups
: Thumb2명령어 그룹의 조건부 실행을 제어
Thumb instruction set
Thumb
- code density가 최적화 되어있음
: Arm ISA에 비해 65%가량을 차지. - ARM ISA의 일부 기능만 지원
: CPSR/SPSR, VEP/NEON 기능은 지원하지 않음
: 대부분의 data processing 명령어가 r0~r7까지의 레지스터만 사용. 즉 performance가 좀 떨어짐.
:Only branches can be conditional
Thumb-2
- Thumb instruction은 기능을 확장한 Thumb-2
- ARMv6T2에서 처음 도입되어 그 이후의 ARM에서는 Thumb-2 전부 사용 가능
- 16bit, 32bit ISA가 혼합되어 있음
- CPSR/SPSR, VEP/NEON 기능 지원
- Introduces IT (If-Then) instruction for conditional execution
- Provides the code density benefit of original Thumb instruction set, with flexibility of ARM instruction
set
메모리 면에서는 Thumb 가 Thumb-2보다 우수. 그러나 성능 면에서는 Thumb-2가 우수.
All Thumb and Thumb-2 instruction must be halfword aligned
C source code
if (r0 == 0)
{
r1 = r1 + 1;
}
else
{
r2 = r2 + 1;
}ARM instructions
unconditional
// unconditional
CMP r0, #0
BNE else // 같지 않을 경우 else로 이동
ADD r1, r1, #1 // 같을 경우 이 줄 실행
B end
else // 같지 않을 경우 이동하는 지점
ADD r2, r2, #1
end
...- 5개의 instructions(CMP/BNE/ADD/B/ADD)
- 5개의 words
: 하나의 명령어는 메모리 상에서 하나의 word를 차지 - 5 or 6 cycles
conditional
// conditional
CMP r0, #0
ADDEQ r1, r1, #1
ADDNE r2, r2, #1- 3개의 instructions(CMP/ADDEQ/ADDNE)
- 3개의 words
- 3개의 cycles
unconditional(분기가 없는) 코드
conditional(분기가 있는) 코드
Floating point and NEON
ARM processors have optional floating point support
: ARM 프로세서가 부동 소수점 지원을 선택적으로 지원함.
: VFPv3 Cortex-A8 and Cortex-A9, 32비트 ARM 프로세서의 부동 소수점 연산을 지원
: VFPv4 Cortex-A5 and Cortex-A15, VFPv3보다 더 많은 부동 소수점 연산 기능을 제공
NEON
: Single Instruction Multiple Data (SIMD) extension
: SIMD 의 확장이라고 생각하면 편함.
VFP and NEON instructions use a separate set of registers to standard data processing instructions
: VFP와 NEON 명령어는 표준 데이터 처리 명령어와 별도의 레지스터 세트를 사용함.
: 이유는 부동 소수점 연산 또는 SIMD 연산에 사용되는 데이터가 일반적인 정수 연산에 사용되는 데이터와 분리되어 있기 때문임.

: ARM 아키텍처에서 레지스터의 개수가 구현에 따라 정의. 일반적으로는 16개 또는 32개의 double precision(더블 정밀도) 레지스터를 사용한다는 것
★ AAPCS ★
참고 https://junorionblog.co.kr/aapcs-%EB%A0%88%EC%A7%80%EC%8A%A4%ED%84%B0-%EC%82%AC%EC%9A%A9/
- Procedure Call Standard for Arm Architecture
- AAPCS 기본 프로시저 호출 표준은 Arm 명령어 집합에 공통인 기계 수준의 코어 레지스터만 사용하는 호출 표준을 정의
- AAPCS는 ARM 아키텍처에서 사용되는 Application Binary Interface(ABI)의 한 부분
: 이는 컴파일된 코드와 어셈블러 코드 간 외부 인터페이스를 정의
: AAPCS를 따르는 것은 외부 인터페이스 호환성을 유지하는데 중요 - ABI
: ABI는 응용 프로그램 바이너리 인터페이스의 약자
: 컴파일된 코드와 라이브러리, 운영 체제 간의 상호 작용을 정의하는 규칙의 모음 - RWPI 옵션
: RWPI는 "Read Write Position Independent"의 약자로, ARM 아키텍처에서 사용되는 옵션 중 하나. 이 옵션을 선택하면R9레지스터가 정적 베이스로 사용
: 코드를 생성할 때 읽기 및 쓰기 명령의 위치 독립성을 보장하는 데 사용 - SP(스택포인터)가 항상 8바이트(2워드)로 정렬되어야 함을 나타냄.
- 레지스터 R14은 스택 내에서 일시적인 값으로 사용될 수 있음. 원래 R14는 함수 호출에서 현재 실행 중인 코드의 반환 주소를 저장하는 데 사용

ex.
func(int a, b, c, d, e)
가 있으면
a는 r0, b는 r1, c는 r2, d는 r3, e는 stack에 저장. r4는 인수(parameter)를 위해 할당되어 있지 않음. 그러므로 parameter e는 메인 메모리에 할당되어있는 stack 영역에 보관. 그 결과로 stack은 속도가 느림.
cf. stack은 메인 메모리에 스택 영역을 사용자가 할당해줄 수 있음
-
Scratch Register
R0-R3, R12 는 마음대로 훼손시켜도 되는 Scratch Register
가급적이면 함수는 이러한 레지스터를 이용해 설계 -
함수 내에서 손상된 Scratch Register들은 함수 호출 후 복귀한 뒤에 Caller가 복구(훼손되면 안되는 R0-R3, R12, LR)
-
Caller는 자체적으로 훼손시킨 R4-R11, R13에 대한 보존 책임 존재
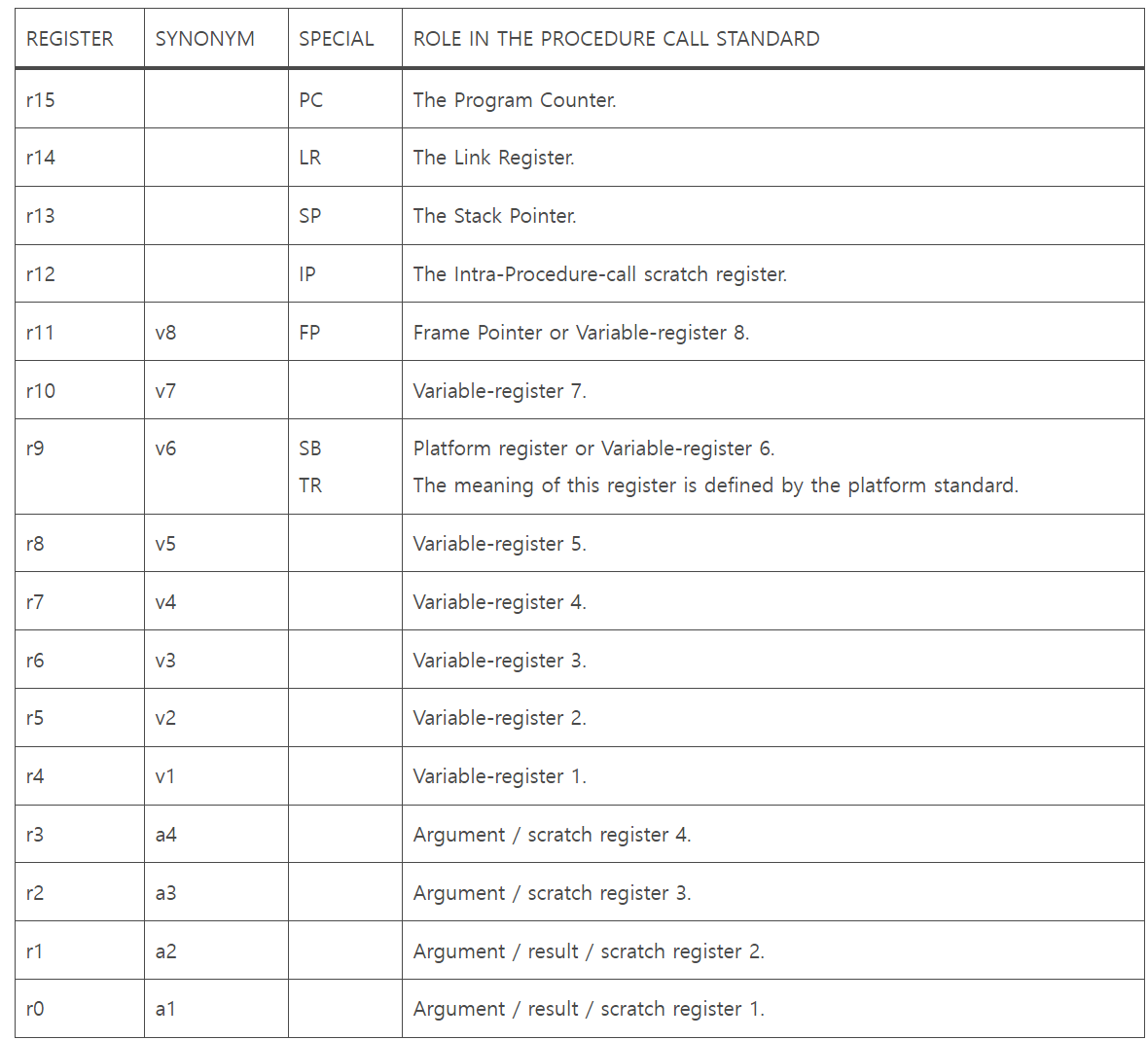
- r0~r3 (a1~a4) : 서브 루틴으로 인자 값을 전달하거나 함수에서 결과값을 반환하는데 사용된다.
- r12 (IP) : 루틴과 호출하는 모든 서브 루틴 사이의 링커의 스크레치 레지스터로 사용될 수 있다.
- r11 (FP) : 프레임 포인터로 사용될 수 있다.
- r9 (SB/TR) : 플랫폼에 따라 다른 역할을 한다. 정적 베이스(SB)로 지정하거나, 쓰레드 로컬 스토리지 환경에서 쓰레드 레지스터(TR)로 지정할 수 있다. 특별한 레지스터가 필요하지 않은 플랫폼에서는 callee-saved 변수 레지스터인 v6로 지정할 수 있다.
- r4~r8, r10, r11(v1-v5, v7, v8): 로컬 변수값을 저장하는데 사용된다.
- r13~r15(SP, LR, PC): 각각 특수한 역할을 수행한다.
- r13(SP) : 스택 포인터로 사용된다.
- r14(LR) : 링크드 레지스터로 사용된다.
- r15(PC) : 프로그램 카운터로 사용된다.
함수의 depth가 깊어지더라도(즉, sub function이 많이지더라도) stack에 저장 후 복구하면 됌.
- 하위 함수가 실행을 완료하면, 그 함수의 반환 주소가 r14에 저장되어 있음
- 이전 함수의 반환 주소를 r14에서 가져와야 함
- 이전 함수의 반환 주소를 사용하여 이전 함수로 복귀
function의 하위 함수 sub_func1의 하위 함수 sub_sunc2가 있고, function의 주소는 -x7000, sub_func1의 주소는 0x8000, sub_func2의 주소는 0x9000일 때
sub_func1에서 push(r4~r11, lr)해줌. 그리고 lr에는 0x8000을 넣음. 그 후 sub_func2 실행. sub_func2는 pc(0x9000 <- lr)를 사용해 lr의 값을 바꿈. 그 후 sub_func1에서 pop 사용하여 lr을 다시 stack에서 꺼내서 0x8000으로 바꿈. 그후 pc(0x7000 <- lr)하여 원래 함수 function으로 돌아감
Processor Modes
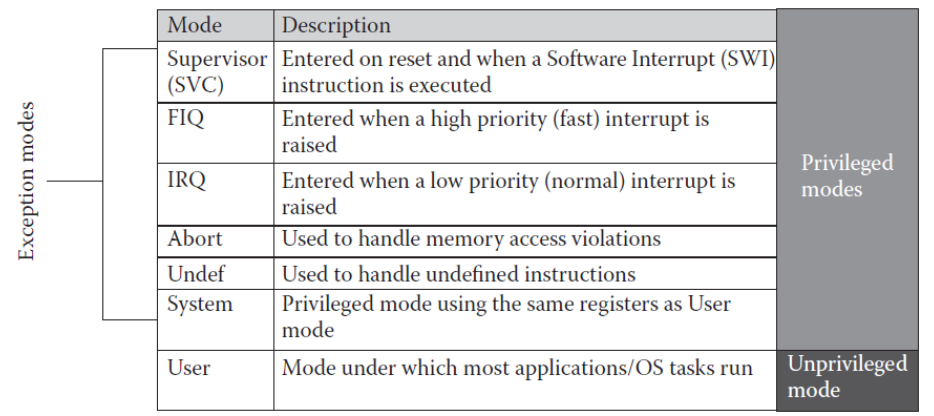
- ARM 아키텍처는 7가지 기본 운영 모드를 가짐
: 각 모드는 자체 스택 공간에 액세스
: 다른 레지스터의 하위 집합에 액세스 가능
: 특권 모드에서만 작업할 수 있는 특정 작업도 존재.
7가지 모드
User Mode(USR)
: 일반적인 사용자 프로세스의 실행 환경 제공
FIQ(Fast Interrupt Request) Mode
: 빠른 인터럽트 처리를 위한 모드
: 다른 인터럽트들보다 빠르게 처리되는 특별한 종류의 인터럽트를 나타냄
IRQ(Interrupt Request) Mode
: 일반적인 인터럽트 처리를 위한 모드
: 대부분의 하드웨어 인터럽트가 IRQ에서 처리
Supervisor Mode(SVC)
: 운영체제의 커널이 실행되는 모드
: 특권 명령어와 보호된 리소스에 접근 가능
Abort Moode
: 메모리 액세스 중에 발생한 예외를 처리하는 모드
: 일반적으로 메모리 관련 오류를 처리
: 가상 메모리 시스템에서 페이지 폴트를 처리
Undefined Mode
: 정의되지 않은 명령어나 예외를 처리하는 모드
System Mode
: 다양한 시스템 수준 작업을 수행하는 모드
: 부팅 및 초기화, 시스템 전원 관리 등의 작업이 여기서 처리
- 프로세스가 메모리에 access 할 때는?
ex. store명령어, 패치 명령어- system mode는 user모드와 유사. 그러나 privileged 얻고 싶을 때 사용?
Banking Registers
ex. 특정 interrupt가 발생하면 user mode에서 IRQ mode로 전환. 그러나 IRQ 의 r13, r14, spsr에 저장되어 있었던(banking) 레지스터의 값을 불러와서 사용.
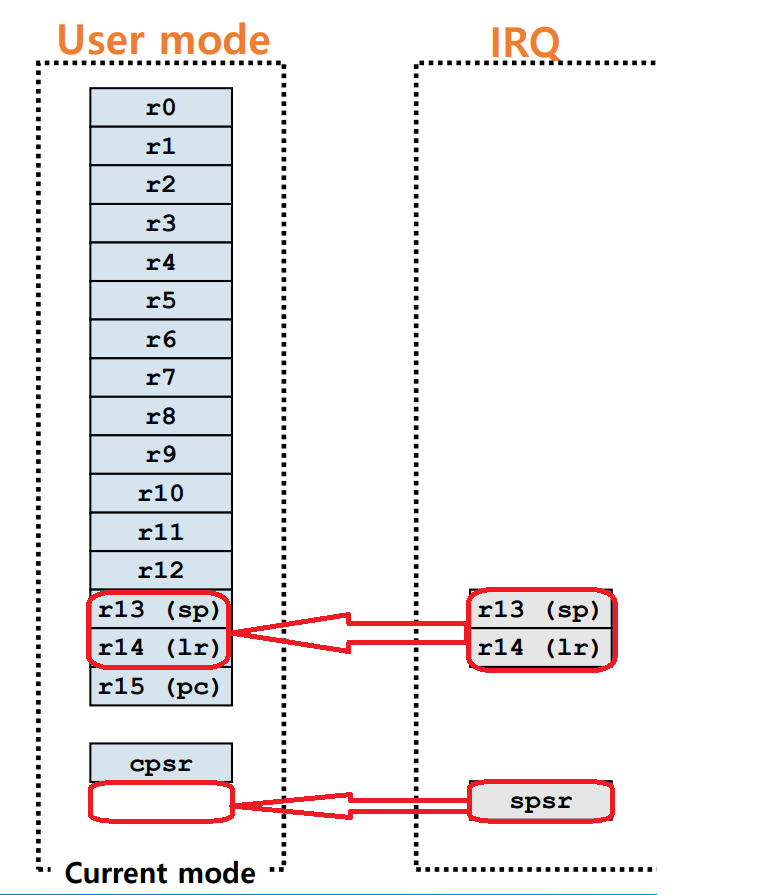
- 원본은 stack에 보관했다 복구함
- FIQ가 IRQ보다 빠름
: 왜냐하면 복구해야할 레지스터의 개수가 적기 때문. FIQ의 경우에는 r0~r7, r15까지만 복구하면 되지만, IRQ의 경우에는 r0~r12, r15를 복구해야함.
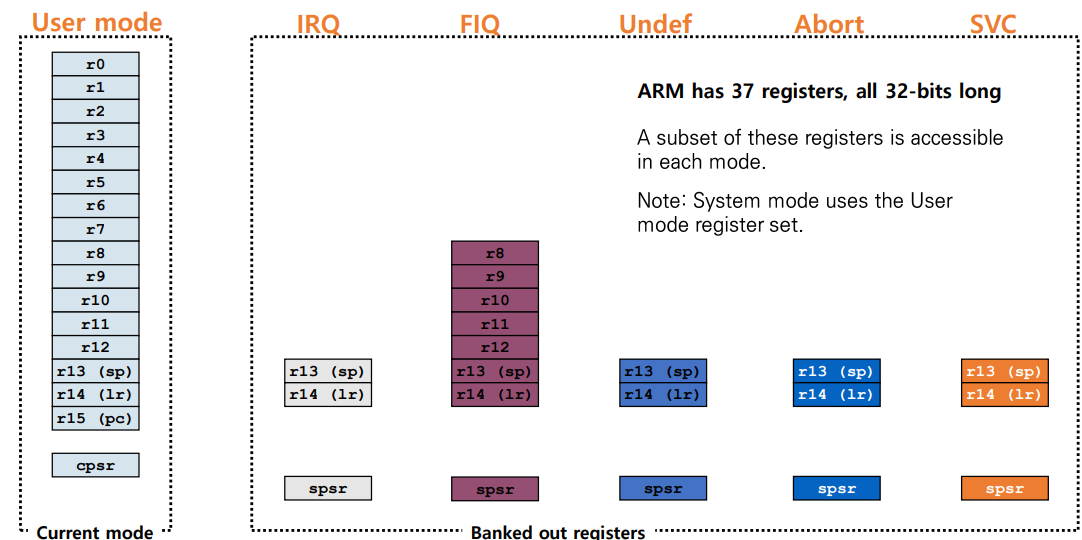
Note
: System mode는 User mode 레지스터 세트를 사용
Taking an exception
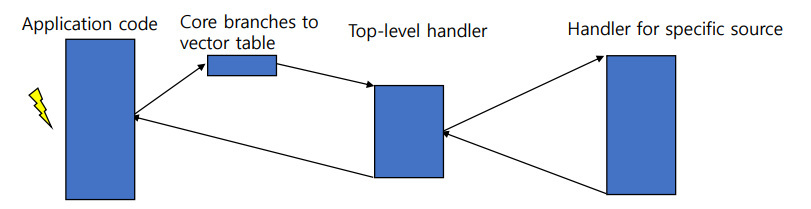
예외가 발생하면...
- CPSR을
SPSR_<mode>로 복사
: 즉, 현재 상태 레지스터의 값을 예외 상태 저장 레지스터 복사함. 현재 상태 보존을 위함. - 적절한 CPSR 비트를 설정
: 예외가 발생했을 때 프로세서 상태가 변경
ex. Arm또는 Thumb 모드로의 전환, 엔디안 설정 변경, 인터럽트 비활성화 등 - 미리 정의된 상태로 변경
: 예외 처리를 위해 미리 정의된 프로세서의 상태로 변경 LR_<mode>에 반환 주소 저장
: 예외가 발생할 때 현재 실행 중인 명령어의 반환 주소를 해당 모드의 링크 레지스터(LR_<mode>)에 저장.
: 이렇게 하면 예외 처리가 완료된 후에 원래의 실행 위치를 복귀할 수 있음- PC를 벡터 주소로 설정
: 예외가 발생했을 때 실행될 예외 처리 코드의 주소를 PC(Program Counter)에 설정
exception handler가 예외 처리를 완료 하고 복귀하기 위해...
- CPSR을
SPSR_<mode>에서 복원
: 예외 처리 동안 보존된 예외 상태 레지스터 - PC를
LR_<mode>에서 복원
: 예외 처리 동안 보존된 링크 레지스터의 값을 PC로 복원.
Armv7 core의 Arm/Thumb 상태에서 예외가 발생했을 때...

- Armv7 코어에선 Arm 또는 Thumb 상태에서 예외를 수용할 수 있음
: Thumb-2기술이 포함되지 않은 프로세서에서는 Arm 상태에서만 예외를 수용해야함.
: 그러나 Thumb-2 기술이 포함되어 있을 경우에는 Arm/Thumb 상태에서 모두 예외를 수용 가능
Thumb-2
: ARM의 16비트 명령어를 확장하여 32비트 명령어를 사용할 수있게 해주는 기술
- exception은 항상 32bit에서만 실행 가능.
즉, exception이 발생하면 ARM state로 변경하여 처리해줘야 함.
arm은 32bit고 thumb은 16bit이기 때문에...
thumb에서는 예외 처리가 제한되어 있기에, 대부분의 예외 처리는 arm 상태에서 실행
Vector table
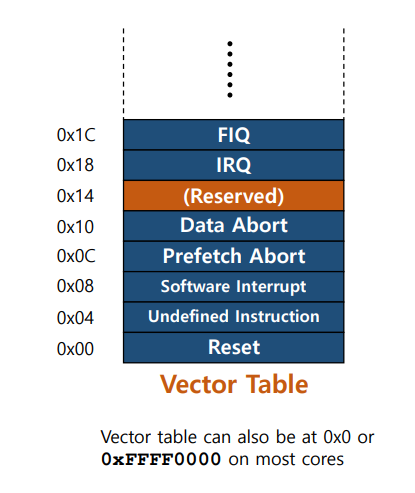
- 벡터 테이블은 예외 유형당 하나의 항목을 가짐
- 테이블 항목은 주소가 아니라 명령어를 포함
명령어 종류
- Arm 명령어 1개
- 16bit Thumb 명령어 2개
- 32bit Thumb 명령어 1개
- Arm 또는 Thumb는 SCTLR.TE bit에 의해 제어
- 벡터 테이블 주소는 구성 가능함.
: 일반적으로0x0혹은0xFFF0000으로 설정
: 디폴트 값은0x0이고 VINITHI signal 또는 SCTLR.V bit을 할 경우에만0xFFFF0000으로 위치함. - 보안 확장(Security extensions)은 다른 주소를 지원함
: Vector Base Address register(벡터 기준 주소 레지스터)를 추가로 제공해 다른 주소를 사용 가능
Memory Model
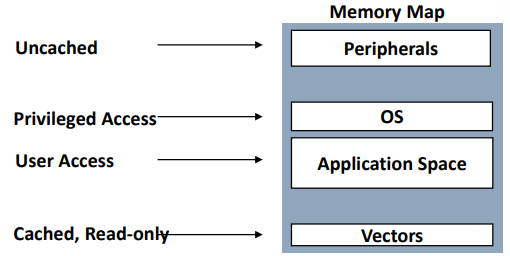
시스템은 여러 기억장치와 주변 장치(peripherals)를 포함
: 프로세서는 각 장치에 어떻게 접근해야 하는지 알려줘야 함
여기서 주변장치(Peripherals)란
시스템의 중앙 처리 장치(CPU)와 주기억장치(메인 메모리)를 제외한 모든 장치
- 각 주소 영역마다
- 접근 권한
: 사용자/특권 모드에 대한 읽기/쓰기 권한 - 메모리 유형
: 메모리 접근에 대한 캐싱/버퍼링 및 접근 규칙
Memory Types
Armv6/Armv7에서는 주소 위치를 유형에 따라 설명
: "유형(type)"은 프로세서에게 해당 위치에 액세스할 수 있는 대상을 알려줌
- 메모리 액세스 순서 규칙
- 캐싱 및 버퍼링 동작
- 추측
3가지 상호 배제적인(mutually exclusive) 메모리 유형
요약하자면 주소 영역은 Normal/Device/Strongly-ordered 중 하나의 메모리 영역에만 속할 수 있으며 동시에 여러 메모리 유형이 속할 수 없음.
Normal(일반)
: 데이터 및 명령어를 주로 저장Device(장치)
: 장치/주변장치를 주로 저장Strongly-ordered(강한 정렬)
: 장치/주변장치 또는 레거시 코드에서 사용되는 데이터
레거시 코드(legacy code)
: 과거에 개발되었고 현재 시스템에서 여전히 사용되고 있는 코드. 현재의 기술/표준과는 호환성이 낮을 수 있음
Normal 및 Device 메모리는 캐시 정책을 지정, 영역 공유 여부를 지정하는 추가 속성 허용
- 캐시 정책 지정
ex. 일반 메모리는 캐시를 사용할 수도 안 할수도 있음. 사용자의 설정에 따라 나뉨. - 영역 공유 여부 지정
ex. 메모리 영역을 공유할 것인지 여부 지정 가능. 일부 메모리 영역은 공유되어야 하며, 다른 메모리 영역은 개별 프로세스에 대해 격리되어야 할 수 있음.
- device는 Normal 보다 우선순위가 대체로 높음.
- Normal type은 메모리 영역 혼재 가능
: Normal 메모리 영역은 특정한 순서에 따라 배치될 필요가 없으며, 임의의 위치에 존재 가능 - Strongly ordered 는 device보다 더 우선순위가 높음
: 대체로 Strongly ordered 메모리가 device 메모리보다 시간적 제약이 더 강력하기에 Strongly Ordered 메모리가 우선 순위가 더 높음
일반적으로
Strongly ordered memory > Device > Normal 의 메모리 우선순위를 가짐
★ 소스코드에서 실행파일 만들어지는 과정
출처 https://dnf-lover.tistory.com/entry/%EC%BB%B4%ED%8C%8C%EC%9D%BC-%EC%96%B8%EC%96%B4%EC%97%90%EC%84%9C-%EC%86%8C%EC%8A%A4-%ED%8C%8C%EC%9D%BC%EC%97%90%EC%84%9C-%EC%8B%A4%ED%96%89%ED%8C%8C%EC%9D%BC%EC%9D%B4-%EB%90%98%EB%8A%94-%EA%B3%BC%EC%A0%95
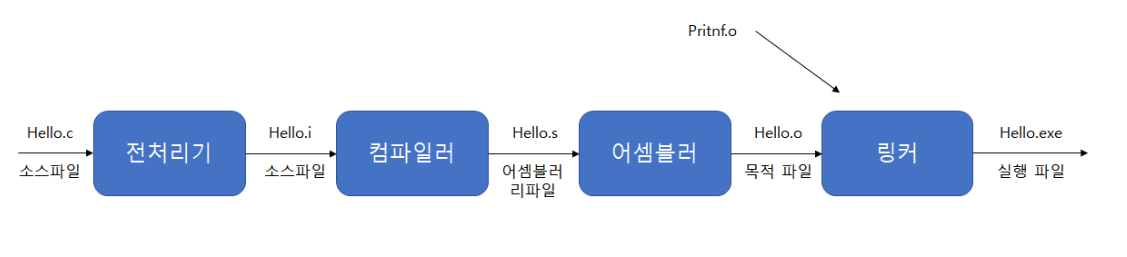
컴파일러
: 컴파일러는 C언어로 작성된 파일을 assembly language 프로그램으로 번역어셈블러
: Assembler는 assembly 코드의 pseudoinstruction을 cpu가 이해할 수 있는 instruction으로 번역링커
: assemble된 routine들(예를 들면 라이브러리 루틴)을 서로 연결
: Library routine이란 일반적으로 라이브러리 내에 정의된 함수
: Linker는 독립적으로 생성된 object file들을 연결하여 하나의 실행 파일을 만듦
Example Cached Arm macrocell
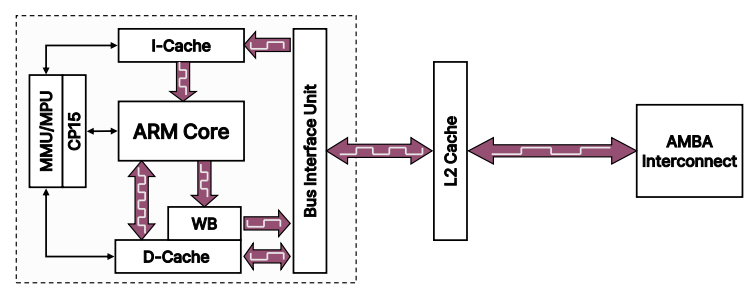
ARM 코어는 MMU(Memory Management Unit) 또는 MPU(Memory Protection Unit) 중 하나를 포함
1. MMU(Memory Management Unit)
: MMU는 가상 메모리 시스템 아키텍처(Virtual Memory System Architecture, VMSA) 구현
: MMU는 가상 주소를 실제 물리적 주소로 변환하여 메모리를 효율적으로 관리하고 가상 메모리를 지원
2. MPU(Memory Protection Unit)
: MPU는 물리 메모리 시스템 아키텍처(Physical Memory System Architecture, PMSA)를 구현
: 주소 범위를 설정하여 특정 메모리 영역에 대한 액세스 권한을 제어
- 일반적으로 MMU는 MPU의 모든 기능을 다 가지고 있음
- 프로세스가 사용하는 건 항상 Virtual Address
- i-cache(명령어 캐시) 는 instruction cache, instruction 영역에 해당
- d-cache 는 data cache, data 영역에 해당
- 이렇게 코어 내부에 있는 i/d cahce를 level 1 캐시라고 함.
Data Alignment(데이터 정렬)
Armv4/v5 데이터 정렬
- Armv6 이전에는 하드웨어 데이터 액세스가 크기에 맞게 정렬되어야 했음(ex. 워드는 워드 경계에 위치)
- 정렬되지 않은 액세스는 하드웨어에 의해 감지될 수 있음
- 소프트웨어에서의 정렬되지 않은 데이터는 일련의 정렬된 메모리 액세스에 의해 액세스될 수 있음
Armv6/v7 데이터 정렬
: 데이터 액세스가 정렬되지 않아도 되는 것이 특징
: 그러나 일부 load/store 명령어만 정렬되지 않은 액세스를 지원
: 정렬되지 않은 액세스는 Normal로 표시된 주소에 대해서만 허용
: load/store 유닛은 정렬된 메모리 액세스를 통해 메모리에 액세스하고 데이터를 CPU에 제공
Arm 프로세서는 little-endian
: Arm 프로세서는 주로 little endian 방식을 사용, 즉 낮은 바이트가 먼저 저장
: 그러나 Big Endiannes 메모리 시스템에 액세스할 수 있도록 구성도 가능
▶ Coprocessors
Coprocessors
CPU의 기능을 보충하기 위해 사용되는 컴퓨터 프로세서(보저처리기/보조프로세서)
이전 Arm 프로세서에서의 코프로세서 추가:
이전 Arm 프로세서에서는 Arm 명령어 집합을 확장하기 위해 추가적인 코프로세서를 추가할 수 있었습니다. 이는 프로세서의 기능을 확장하거나 특정한 작업을 수행하기 위해 사용될 수 있었습니다.
새로운 프로세서에서의 코프로세서 제한:
하지만 새로운 프로세서에서는 사용자 정의 코프로세서를 허용하지 않습니다. 대신 시스템 디자이너들이 메모리 맵핑된 페리페럴(memory mapped peripherals)을 사용하는 것이 더 좋습니다.
이것은 코프로세서를 코어 파이프라인에 연결해야 하기 때문에 구현이 더 쉽습니다.
Arm이 내부 기능을 위해 코프로세서 사용:
Arm은 특정한 메모리 맵핑을 강제하지 않기 위해 코프로세서를 "내부 기능"에 사용합니다.
예를 들어, 시스템 제어 코프로세서(cp15)는 프로세서 구성(시스템 ID, 캐시, MMU, TCM 등)을 위해 사용됩니다.
디버그 코프로세서(cp14)는 디버그 제어 레지스터에 액세스하기 위해 사용될 수 있습니다.
또한, VFP와 NEON과 같은 부동 소수점 및 SIMD(단일 명령어 다중 데이터) 기능을 위한 코프로세서(cp10 및 cp11)가 있습니다.
Example CP15 registers
ARM 아키텍처에서 사용되는 다양한 레지스터들
cf. CP15란?
: ARM 아키텍처에서 System Control Coprocessor
1. System Control Register (SCTLR):
- 예외 상태와 엔디안 설정
- 캐시와 메모리 관리와 관련된 설정을 포함
2. Auxiliary System Control Register (ACTLR):
- 아키텍처적 특징이 아닌 프로세서별(Processor-specific) 제어를 포함
3. Feature Registers:
- 프로세서의 기능, 캐시 크기 등을 발견
4. ID Registers:
- RTL(Release To License) 버전/리비전 정보를 포함하는 MIDR(MID Register)
- MPCore 시스템에서 CPU와 클러스터 ID를 식별하는 MPIDR(Multiprocessor Affinity Register) 등을 포함
5. Cache, TLB 및 분기 예측 유지 보수 작업:
- 캐시, TLB(Translation Lookaside Buffer) 및 분기 예측과 관련된 작업을 수행
PMU란?
Performance Monitoring Unit
: 시스템 내부에서 발생하는 하드웨어 관련 이벤트 발생을 측정하는 카운터 레지스터를 통해 성능 분석을 지원하는 컴포넌트
- Armv6 및 Armv7-A/R 프로세서에 포함된 성능 모니터링 유닛(PMU)
PMU의 역할
- PMU는 코어에서 실행 정보를 수집하는 비침입적인 방법을 제공
- PMU를 활성화해도 코어의 타이밍 변경X
PMU의 접근
- PMU는 CP15를 통해 접근
PMU가 제공하는 기능
- 사이클 카운터(Cycle Counter)
: 실행 사이클을 카운트.
: 선택적으로 1/64분 주기 사용 가능 - 프로그래밍 가능한 이벤트 카운터(Programmable event counters)
: 사용가능한 이벤트 수와 카운터 수는 코어 마다 다름
: 프로그래밍 가능한 이벤트에 대해 카운트를 제공 - 카운터가 오버 플로우하는 경우 인터럽트를 생성하도록 PMU 구성 가능
: 인터럽트 신호는 코어에서 출력
: 시스템의 인터럽트 컨트롤러에 연결되어야 함.
What can the PMU count?
PMU가 카운트 할 수 있는 이벤트는 프로세서마다 다름
-
PMU가 카운트 할 수 있는 이벤트의 다양성
: 각 프로세서마다 PMU가 카운트 할 수 있는 이벤트는 다를 수 있음
: 사용 중인 코어에 대한 기술 참조 메뉴얼(TRM)을 확인하여 이벤트 목록 확인 가능 -
일부 이벤트 예시
- 캐시 히트 또는 미스
- TLB 미스(MMU 코어의 경우)
- 분기 예측, 올바른/부정확한 예측
- 실행된 명령어의 수
- 분기 수(ex. BL, BLX)/함수 반환(ex. BX lr)
- 파이프라인 스톨
- 메모리 액세스
- 패리티 오류 / ECC (해당 기능을 지원하는 코어의 경우)
- 프로세서는 프로그램 가능한 카운터의 수에 제한이 존재
- 프로세서마다 프로그래밍 가능한 카운터의 수 제한
- 다양한 이벤트를 기록하기 윟 동일한 테스트를 여러 번 실행해야 할 수 있음
PMU를 사용하여 다양한 이벤트를 모니터링함으로써 프로그램의 동작과 성능을 분석 가능
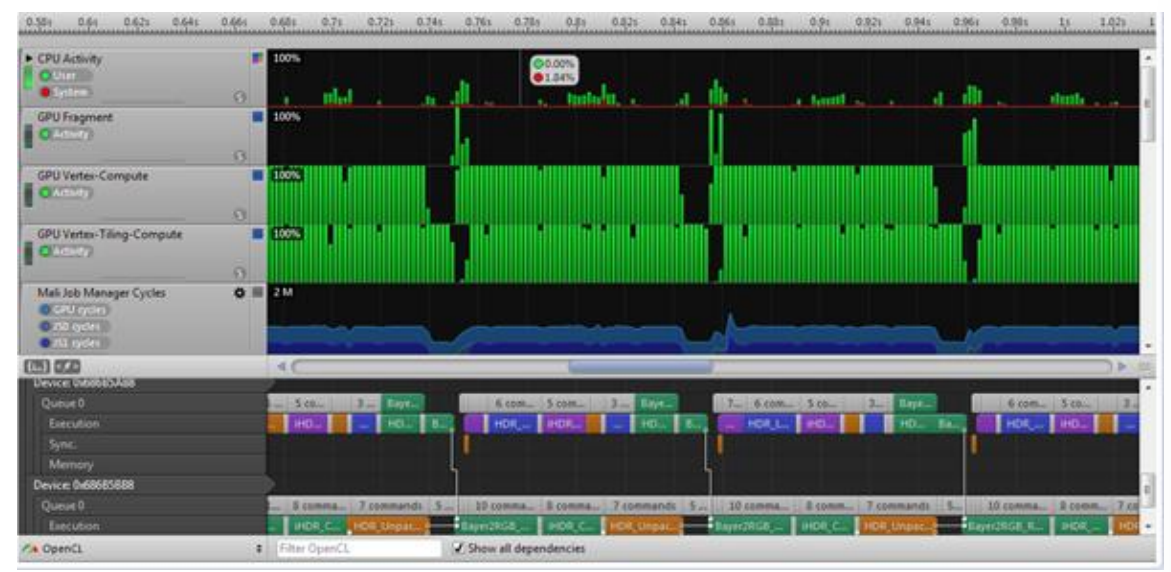
Profiling(Streamline 사용 예)
▶ Architecture extensions
Floating point and NEON

Large Physical Address Extensions(LPAE)
페이지 테이블에 대한 롱 디스크립터(long descriptor) 형식이 추가
1. 롱 디스크립터 형식 추가:
- 32비트 가상 주소가 40비트 물리 주소 공간으로 매핑
- 64비트 변환 테이블 디스크립터를 사용하는 새로운 변환 테이블 형식이 도입
- 총 1TB의 메모리 공간에 접근할 수 있습니다.
2. 32비트 쇼트 디스크립터 형식 지원:
- 32비트 쇼트 디스크립터 형식은 여전히 지원
- 변환 테이블 베이스 컨트롤 레지스터(TTBCR)의 EAE 비트(bit 31)를 사용하여 구
- 16MB 메모리 슈퍼섹션을 사용하여 40비트 주소 공간에 매핑
이러한 변경으로 인해 가상 주소 공간을 40비트로 확장하여 더 많은 메모리를 접근 가능
기존의 32비트 쇼트 디스크립터 형식도 여전히 지원되므로 호환성이 유지
롱디스크립터란?
롱 디스크립터(long-descriptor)는 ARM 아키텍처에서 가상 주소를 물리 주소로 변환하기 위해 사용되는 페이지 테이블의 한 형식입니다. 이전에 사용되던 쇼트 디스크립터(short-descriptor) 형식보다 더 많은 비트를 사용하여 더 큰 물리 메모리 공간을 매핑 가능
- ARM 프로세서에서 메모리 관리에 사용되는 확장 기술
- 주로 32bit ARM 아키텍처에서 메모리 주소 공간의 확장을 위해 사용
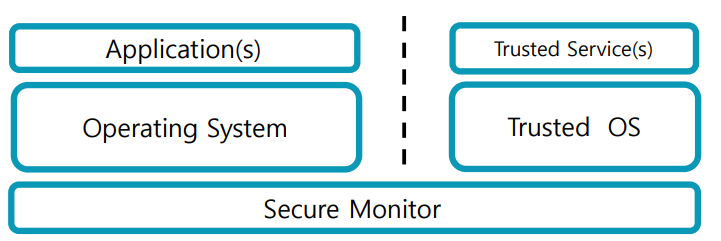
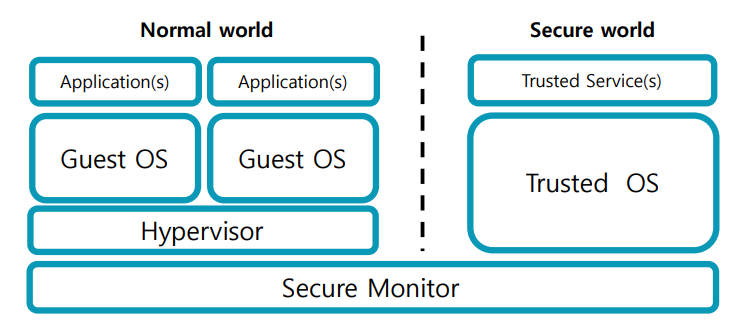
TrustZone
- 안전한 컴퓨팅 환경을 제공하는 기술
- ARM 프로세서에 통합되어 있음
- 시스템을 하드웨어 적으로 두 개의 영역으로 나눔.(안전영역/일반영역)
1. 두 개의 월드:
"Secure"와 "Normal"이라는 두 개의 월드가 있습니다.
각각의 월드는 자체 벡터 테이블과 페이지 테이블을 가지고 있습니다.
2. "Monitor" 모드:
"Monitor" 모드는 월드 간 이동을 관리하는 게이트키퍼 역할
이 모드는 보안 상태를 변경하거나 다른 월드로 전환할 때 사용
-
두 개의 물리 주소 공간:
프로세서는 "Secure"와 "Non-Secure" 두 개의 물리 주소 공간을 제공
각각의 월드는 독립적인 물리 주소 공간을 가지며, NS(Non-Secure) 속성으로 제어
예를 들어, "Secure" 월드에서의 주소 0x8000은 "Non-Secure" 월드에서의 주소 0x8000과는 다른 물리적인 위치로 처리 -
보안 월드 코드 및 데이터의 디버그 제한:
"Secure" 월드 코드 및 데이터의 디버깅은 제한될 수 있음.
Virtualization
- "Normal world"에서 여러 개의 게스트 운영체제를 실행하는 기능 지원
: Normal world(일반적인 os 환경)에서 여러 가상화된 os를 실행할 수 있음 - "Hypervisor"모드
: 가상화 소프트웨어가 동작하는 모드
: 여러 게스트 운영 체제 간의 전환을 관리 및 제어 수행 - "Hypervisor" 모드는 예외를 잡아내어 어느 게스트로 전달할지 선택 가능
: 가상화 소프트웨어의 hypervisior모드는 시스템에서 발생하는 예외(ex. 오류)를 감지 및 적절한 게스트 os로 라우팅 해줌.
Jazelle
1. Jazelle DBX(Direct Bytecode Execution)
: 자발 DBX는 자바와 같은 대부분의 일반적인 바이트 코드를 하드웨어에서 직접 실행하는 기술
: ARM JTEK(JAVA Technology Enabling Kit)은 이를 지원하기 위한 지원 코드 제공
: ARM 기반 JVM에 비해 더 나은 성능 제공.
: 그러나 약간의 크기 패널티 발생 가능
2. Jazelle RCT(Runtime Compilation Targe)/Thumb-2EE
: 자발 RCT(런타임 컴파일 타켓) 또는 Thumb-2EE는 미리 컴파일(AOT) 및 실시간 컴파일(JIT)을 지원
: 이는 자바뿐만이 아닌 어떤 인터프리티드 언어에도 사용 가능
▶ Pipelines
Early Pipelines
- 초기 ARM 코어는 3단계 파이프라인을 사용했음
: 파이프라인은 CPU(중앙처리장치)의 작업을 단계별로 나누어 처리하는 방식
: 각 단계는 다음 단계로의 전달을 위해 뎅이터를 준비, 연속적인 명령어를 병렬적으로 처리함으로써 전체적인 처리 속도를 향상 시킴.
FETCH/DECODE/EXECUTE

- 위 파이프라인은 ARM7TDMI를 포함한 모든 코어에서 사용
- ARM 아키텍처는 여전히 위 파이프라인의 일부 특성을 반영
e.g) 예를 들어 명령어는 PC(Program Counter)가 두 개의 명령어 앞으로 이동한 것 처럼 동작
이는 명령어 실행과 함께 다음 명령어를 미리 로드하여 파이프 라인의 지연을 줄이는 방식임. - ARM9TDMI부터는 몇 가지 중요한 변경 사항이 소개
: 하버드 메모리 아키텍처는 명령어 메모리와 데이터 메모리가 별도로 구성되는 아키텍처, 캐시 일관성을 향상, 성능 향상
: 5단계 파이프라인을 통해 명령어의 처리 효율성을 높임

Pipeline length
- 전송률의 증가로 인하여 파이프라인 길이가 깊어짐.
- 이로 인하여...
1. 파이프라인 길이 증가
: ARM10 코어에서는 6단계의 파이프라인 사용
: ARM11 코어에서는 8~9단계의 파이프라인 사용
: CortexA 및 CortexR 프로필 코어에서는 8~14단계의 파이프 라인 사용
2. 긴 파이프라인으로 인한 여러 효과
: 더 긴 파이프라인은 분기에 대한 패널티(파이프라인 플러시로 인한)을 증가
: 명령 복잡도 증가
파이프라인 플러시란?
: CPU의 파이프라인에 저장된 모든 명령어를 제거하는 프로세스
: 일반적으로 파이프라인에서 예기치 않은 상태가 발생할 때 발생
3. 분기 예측을 사용하여 파이프라인 플러시 회피
: 최신 코어들은 파이프라인을 플러시하는 것을 피하기 위해 분기 예측 사용
: 정적 및 동적 분기 예측이 존재
: 동적 분기 예측은 분기 이력에 따라 업데이트되는 상태 머신 사용
: 분기 예측은 파이프라인의 초기 단계에서 발생
: 일부 코어에서는 최근의 분기 및 결과를 포함하는 Branch Target Address Cache(BTAC) 존재
: 코어에서는 서브루틴 반환 주소를 위한 반환 스택 존재
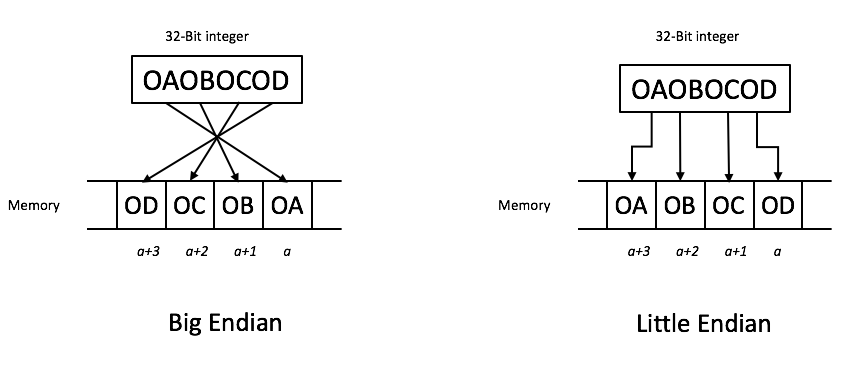
Endiannes
1. 엔디안은 레지스터 내용이 메모리 내용과 어떻게 관련되는지 결정
: ARM 레지스터는 워드(4B) 폭을 가짐
: ARM은 메모리를 바이트의 시퀀스로 주소화
2. ARM 프로세서는 리틀 앤디안 사용
: 그러나 빅 엔디안 메모리 시스템에 액세스할 수 있도록 구성 가능
3. 리틀 엔디안 메모리 시스템
: 최상위 유효 바이트가 가장 낮은 주소에 존재
4. 빅 엔디안 메모리 시스템
: 최상위 유효 바이트가 가장 낮은 주소에 존재
5. ARM은 3가지 엔디안 모델을 지원
: LE(Little Endian)
: BE-32(Word Invariant Big-Endian) - 워드 불변 빅 엔디안(v7에서 도입)
: BE-8(Byte Invariant Big-Endian) - 바이트 불변 빅 엔디안(v6에서 도입)
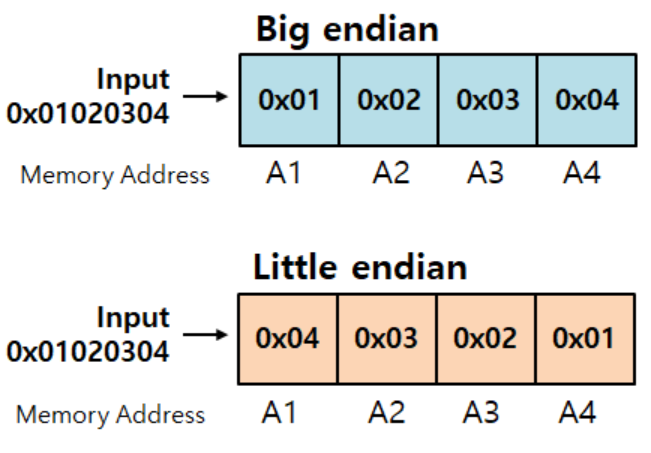
- Big Endian
ex. Sparc - Little Endian
ex. Intel
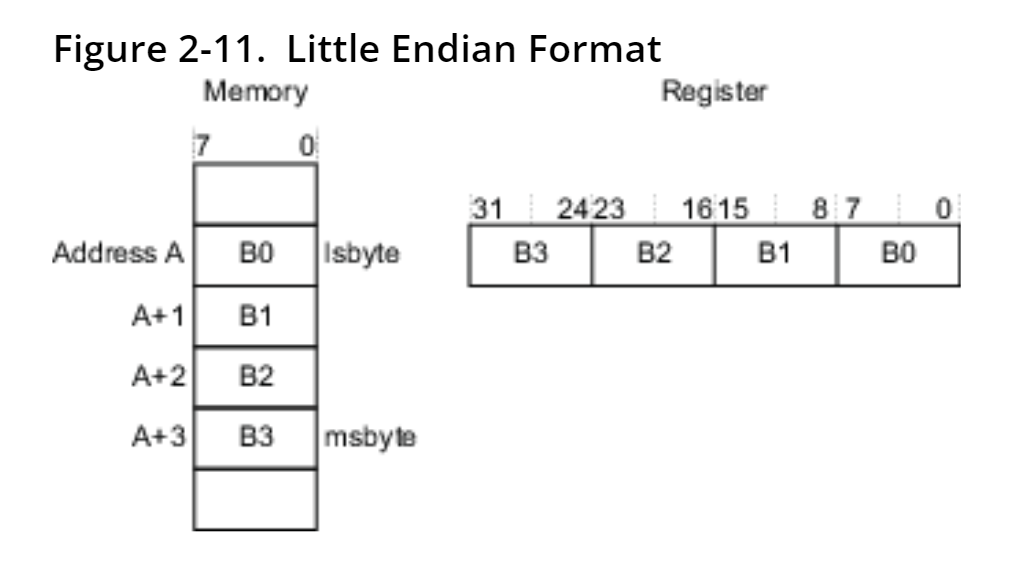
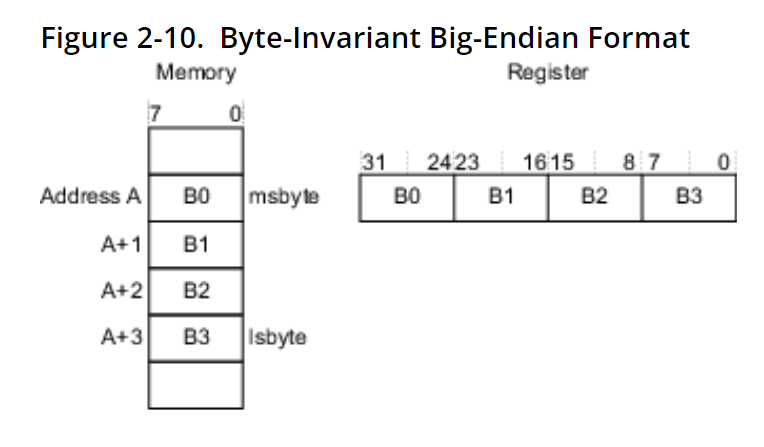
Arm support three models of endianness
- LE(Little Endian)
- BE-32
: word invariant Big-Endian - BE-8
: Byte invariant Big Endian
What's new in Armv8-A?
- AArch32
- Armv7-A의 진화 버전
- A32(Arm)와 T32(Thumb) 명령어 세트 사용
- Armv8-A는 몇 가지 새로운 명령어를 추가
- 전통적인 Arm 예외 모델 사용
- 가상 주소는 32bit 레지스터에 저장
- AArch64
- 새로운 64bit 일반 목적 레지스터(X0~X30) 존재
- 새로운 명령어인 A64가 추가, 고정 길이 32bit 명령어 세트
- SIMD, 부동 소수점 및 암호화 명령어를 포함
- 새로운 예외 모델을 사용
- 가상 주소는 이제 64bit 레지스터에 저장
