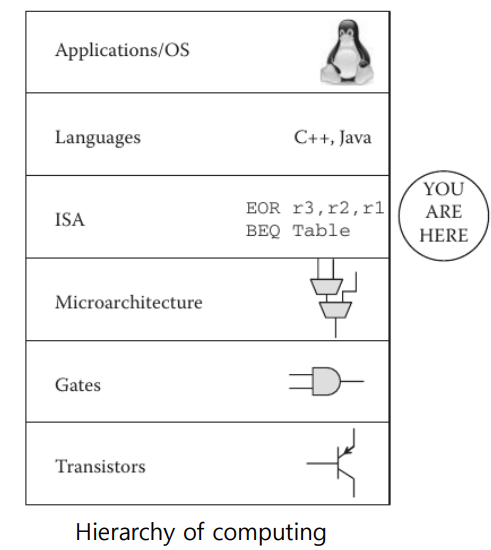
Where we are
Why do we need to know the instruction set
- Arm/Thumb의 ISA는 컴파일러로부터 최적의 OUTPUT을 낼 수 있도록 디자인
: 특히, THUMB ISA! - 대부분의 시스템을 위한 디자인적 노력은 컴파일 된 코드에 집중.
- ISA에 대한 지식이 필요없음.
- 그러나....
- 많은 시스템은 초기화 코드와 인터럽트 루틴이 필요
- 모든 시스템은 디버깅이 필요(아마, 명령어 수준에서...)
- 어셈블러 루틴을 작성하여 성능 향상을 이룰 수 있음
- 몇 가지 ARM 아키텍처의 기능은 컴파일러로는 사용할 수 없음
Aims & Objectives
- 목표
: ARM 명령어 집합 소개 - 학습 목표
- ARM 명령어 집합의 기본 기능을 인식
- 명령어의 일반 구문을 알기
- ARM 명령어 집합의 이점에 대해 알기
▶ 조건부 실행(Conditional Execution)
Conditional Execution and Flags(1)

- Conditional execution enables faster and smaller code
: 조건부 실행은 더 빠르고 작은 코드를 가능하게 함 - Can eliminate short forward branches
: 짧은 앞쪽 분기를 제거 가능
즉, 파이프라인에서 fetch, decode, execute에서 execute에 branch가 있으면 fetch와 decode에 적힌 명령어가 실행되더라도 branch(분기)해야 하기때문에 쓸모가 없음. 즉 분기 이후 새로운 명령어 1, 2를 받아야 함. Conditional Execution and Flag를 사용하면 이러한 짧은 앞쪽 분기를 제거 가능.
- Condition specified in top four bits of instruction word
: 명령어 워드의 상위 네 비트에 조건이 지정(N/Z/C/V) - 'S' suffix and allows control over which instructions set condition co
:s접미사를 사용하여 어떤 명령어가 조건을 설정하는지 제어 가능
: 즉, 's' 접미사는 해당 명령어가 조건 코드(condition code)를 설정하는지의 여부 나타냄
e.g) ADD 명령어는 두 개의 레지스터를 더하고 결과를 저장하는 명령어. 일반적으로 이 명령어는 항상 실행. 그러나 ADD 명령어에 S 접미사가 추가되면(ADDS), 해당 명령어는 조건 코드에 따라 실행될 수 있음.
조건부의 Negative/Zero/Carry/Overflow bit
- ARM 프로세서의 상태 레지스터(PSR, Program Status Register)에서 사용되는 비트
- 이 비트는 명령어의 실행 결과를 나타냄
1. N(Negative) bit
: 명령어가 실행된 결과가 음수일 경우 즉, 최상위 비트가 1일 경우 N비트는 1
2. Z(Zero) bit
: 명령어가 실행된 결과가 0인지를 나타냄.
: 즉, 명령어가 실행된 후 결과 값이 0일 경우 Z bit는 1
3. C(Carry) bit
: 명령어에서 발생한 Carry또는 Carry-out(빌로)를 나타냄. 주로 덧셈 또는 뺄셈에서 발생한 캐리를 검사하는데 사용
4. V(Overflow) bit
: 명령어가 실행된 결과에 Overflow가 발생했는지를 나타냄. 즉, 부호있는 연산에서 발생한 결과의 오버플로우를 검사하는데 사용
이러한 비트들은 조건부 분기 명령어(ex. BNE, BEQ)등에서 사용. 이들을 통해 프로그램의 제어 흐름 결정 가능.
e.g) BEQ 명령어는 Z bit가 1일 때 실행. BNE 명령어는 Z 비트가 0일 때 실행
BEQ (Branch if Equal) 명령어:
BEQ 명령어는 Z(Zero) 비트가 1일 때 실행됩니다.
Z 비트는 이전 명령어의 실행 결과가 0인지를 나타냅니다. 즉, 이전 명령어의 실행 결과가 0이면 Z 비트가 1이 됩니다.
BEQ 명령어는 Z 비트가 1일 때, 즉, 이전 명령어의 실행 결과가 0인 경우에 실행됩니다.
이는 주로 두 값이 동일한 경우 분기해야 할 때 사용됩니다. 즉, 두 값이 같으면 분기하고, 다르면 분기하지 않습니다.
BNE (Branch if Not Equal) 명령어:
BNE 명령어는 Z(Zero) 비트가 0일 때 실행됩니다.
Z 비트는 이전 명령어의 실행 결과가 0인지를 나타냅니다. 즉, 이전 명령어의 실행 결과가 0이 아니면 Z 비트가 0이 됩니다.
BNE 명령어는 Z 비트가 0일 때, 즉, 이전 명령어의 실행 결과가 0이 아닌 경우에 실행됩니다.
이는 주로 두 값이 다른 경우 분기해야 할 때 사용됩니다. 즉, 두 값이 다르면 분기하고, 같으면 분기하지 않습니다.
cf. 양수 + 양수를 했는데 음수가 나옴.
즉, (overflow) 될 경우v bit를 통해 알 수 있음.
Conditional Execution and Flags(2)
-
ARM 명령어는 적절한 조건 코드를 접미사로 추가함으로써 조건적으로 실행 가능
: 이는 코드 밀도를 높이고, 앞쪽 분기의 수를 줄임으로써 성능 향상 가능
: 밑의 코드에서는 branch가 나오지 않기 때문에 분기가 발생하지 않아 파이프라인이 깨지지 않음 -
GT : Greater Than 큼
-
LE: Least Equal 작거나 같음

- 기본적으로 데이터 처리 명령어는 조건 플래그에 영향을 주지 않지만, 's'를 접미사로 붙여서 영향을 줄 수 있음
ADDS 명령어는 덧셈을 수행하고, 그 결과에 따라 조건 플래그를 업데이트
ADDS R1, R2, #10
: 레지스터 R2의 값에 10을 더하고, 그 결과를 레지스터 R1에 저장
ADDS R1, R2, #10
: 덧셈을 수행하고, 그 결과를 레지스터 R1에 저장. 동시에 덧셈 결과에 따라 조건 플래그를 업데이트
/
즉, S는 명령어가 실행된 후에 조건 코드를 나타내는 상태 비트들을 업데이트
SUB'S' 를 함으로써 SET FLAGS도 진행
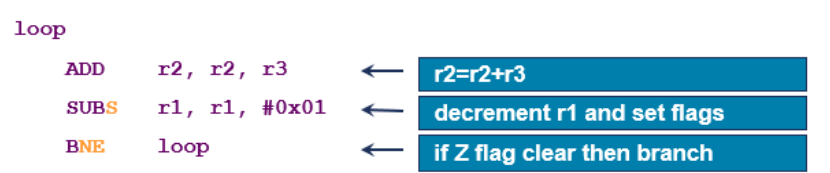
SUB R1 R1 #0X01
레지스터 R1에서 0x01을 빼고 그 결과를 다시 레지스터 R1에 저장#0x01: 16진수 값인 0x01을 나타내며, 이 값이 레지스터 R1에서 뺄셈됩니다.BNE loop
:Branch if Not Equal의 약어
: Z(Zero) 플래그가 0이 아닌 경우에 분기
: 즉, Z플래그가 0이 아니면 loop로 분기
: 이전 명령어의 실행 결과가 0이 아니라면, Z플래그가 clear 된 경우에만 분기가 이루어짐.
1. Z 플래그가 0인 경우
=이전 결과값이 0이 아닌 경우
= BNE 명령어 실행
= 즉, LOOP 실행2. Z플래그가 0이 아닌 경우
= 이전 결과값이 0인 경우
= BNE 명령어 건너 뛰고 다음 명령어 실행
Conditional Execution and Flags(3)
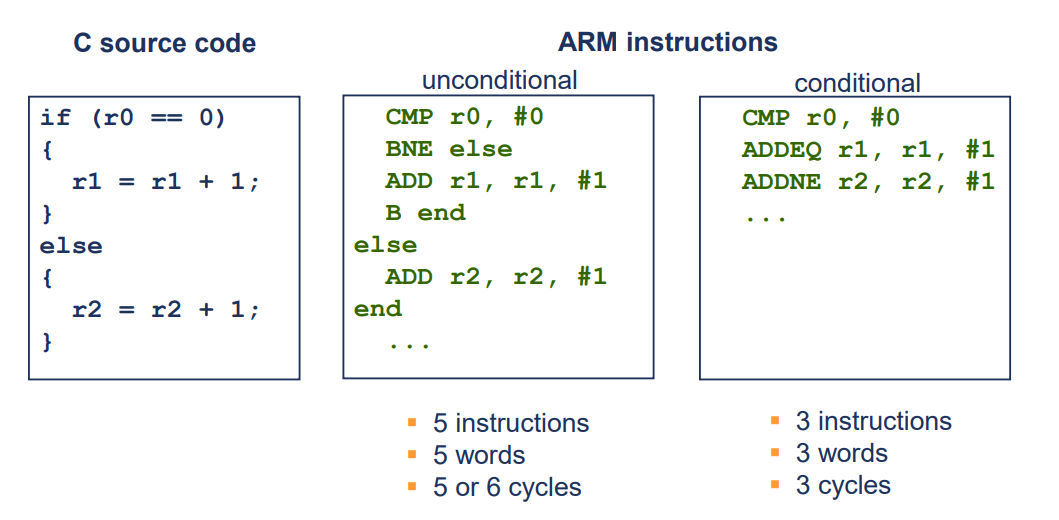
- arm isa는 32bit즉 1워드(4바이트)
- conditional 하게 진행되면 코드의 효율, 사이즈, 성능에서 차이가 발생하는 모습을 볼 수 있음
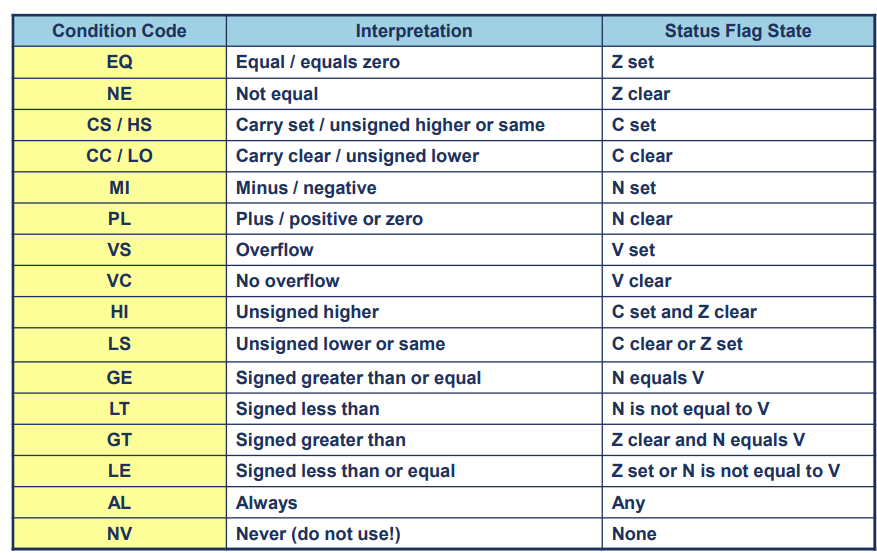
Condition Codes
Data processing Instruction: 데이터 처리 명령어
Data Processing Instruction

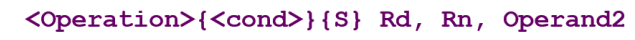
-
ADD
: 첫 번째 및 두 번째 피연산자를 더하고 결과를 목적지 레지스터에 저장합니다. -
ADC
: 덧셈에 대한 캐리 플래그를 포함하여 두 피연산자를 더합니다. -
SUB
: 첫 번째 피연산자에서 두 번째 피연산자를 뺀 결과를 목적지 레지스터에 저장합니다. -
SBC
: 뺄셈에 대한 캐리 플래그를 포함하여 두 피연산자를 빼고, 결과를 목적지 레지스터에 저장합니다. -
RSB
: 두 번째 피연산자에서 첫 번째 피연산자를 뺀 결과를 목적지 레지스터에 저장합니다. -
RSC
: 두 번째 피연산자에서 첫 번째 피연산자와 캐리 플래그를 빼고 결과를 목적지 레지스터에 저장합니다. -
AND
: 두 피연산자의 비트 단위 AND 연산을 수행하고 결과를 목적지 레지스터에 저장합니다. -
ORR
: 두 피연산자의 비트 단위 OR 연산을 수행하고 결과를 목적지 레지스터에 저장합니다. -
EOR
: 두 피연산자의 비트 단위 XOR (배타적 OR) 연산을 수행하고 결과를 목적지 레지스터에 저장합니다. -
BIC
: 첫 번째 피연산자에서 두 번째 피연산자의 비트를 클리어하고 결과를 목적지 레지스터에 저장합니다. -
CMP
: 두 피연산자를 비교하여 결과에 대한 플래그를 설정하지만 실제로 결과를 목적지에 저장하지 않습니다. -
CMN
: 두 피연산자의 부호 없는 덧셈을 수행하고 결과에 대한 플래그를 설정하지만 결과를 목적지에 저장하지 않습니다. -
TST
: 두 피연산자의 비트 단위 AND 연산을 수행하여 결과에 대한 플래그를 설정하지만 결과를 목적지에 저장하지 않습니다. -
TEQ
: 두 피연산자의 비트 단위 XOR 연산을 수행하여 결과에 대한 플래그를 설정하지만 결과를 목적지에 저장하지 않습니다. -
MOV
: 소스 피연산자의 값을 목적지 레지스터로 이동합니다. -
MVN
: 소스 피연산자의 비트를 반전하여 결과를 목적지 레지스터에 저장합니다.
- ADC: ADD CARRY, 캐리도 같이
- SBC: Subtract CARRY, 캐리도 같이
- RSB: Reverse Subtract
SUB R0 R1 R2의 경우: R1 - R2
RSB R0 R1 R2의 경우: R2 - R1
EX.
A = B - 10
A = 10 - B 일 때
Operand2는 레지스터 또는 value값이 가능
그러나 R1의 경우 레지스터만 가능
그러므로 OP Rd Rn Op2의 형태를 유지하기 위해선 RSB도 필요함!
-
RSC: Reverse Subtract Carry
-
이러한 명령어는 레지스터에만 작도앟며 메모리에는 적용되지 않음
syntax

-
Operand 2는 레지스터 또는 즉시 값
: SUB r0, r1, r2
: AND r1, r4, #0xFF -
비교는 플래그만 설정 가능 Rd를 지정하지 않음
: CMP R0 R3 -
데이터 이동은 Rn을 지정하지 않음
: MOV R0 R1(R1 레지스터의 값을 R0으로 복사) -
OP2는 barrel shifter를 통해 ALU로 전송
The Second Operand(두 번째 피연산자) - Barrel shifter(배럴 쉬프터)
Barrel shifter(배럴 쉬프터)
: 프로세서 내부의 회로
: 주로 ALU(산술 논리 연산 장치)와 함께 사용.
: ALU로 전달되는 두 번째 피연산자(Op2)를 반환하고 수정함.
선택적 shift 연산을 적용
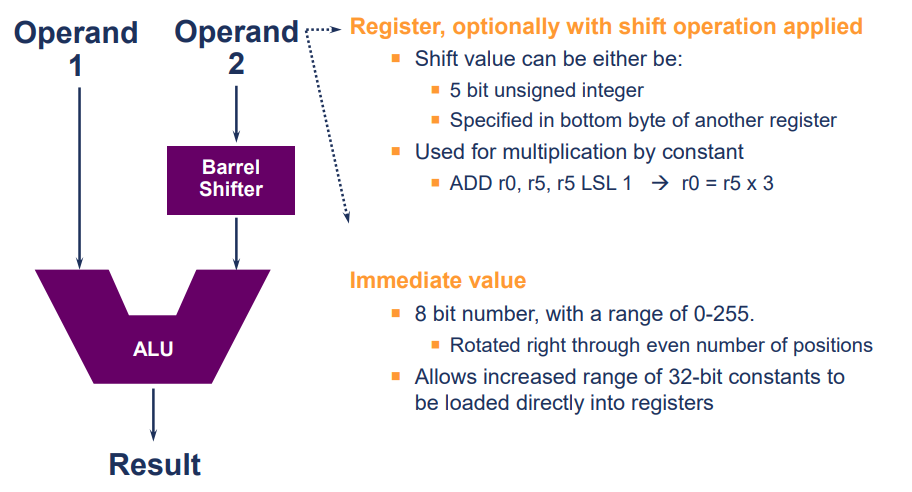
- 레지스터에 시프트 연산을 적용하여 결과를 다른 레지스터에 저장
shift value
-
5비트의 부호 없는 정수
-
다른 레지스터의 하위 바이트에 지정된 값
즉, 시프트 연산에 사용되는 값은 5비트의 부호 없는 정수일 수도 있고, 다른 레지스터의 하위 바이트에서 가져올 수도 있음. -
앞의 shift operation(시프트 연산)은 상수를 곱셈하는 데 사용
ex.
ADD r0, r5, r5 LSL1 → r0 = r5 x 3
: 시프트 연산을 사용하여 곱셈을 수행하는 방법
: r5를 1비트 왼쪽으로 shift하여 값을 2배로 만들고, 그 결과를 r0에 더함. 결과적으로, r0은 r5의 값에 3을 곱한 값.
Shift Operations
-
shift 연산은 데이터 처리 명령어의 일부로 사용
-
비트는 일반적으로 성능 페널티 없이 0에서 31까지 위치 이동 가능.
-
LSL(Logical Left Shift)
: Multiplication by a power of 2
: 2를 곱하기 -
ASR(Arithmetic Right Shift)
: Division by power of 2
: preserving the sign bit
: 2로 나누기 + 부호 비트 보존o
(부호 비트: +인 경우 0, -인 경우 1) -
LSR(Logical Shift Right)
: 2로 나누기, 부호 비트 보존x -
ROR(Rotate Right)
: 비트를 오른쪽으로 회전.
:wrap around가장 왼쪽 비트(MSB, Most Significant Bit)를 가장 오른쪽 비트(LSB, Least Significant Bit)로 이동
예를 들어, 8비트 이진수 10101100을 왼쪽으로 1비트 회전시키면, 비트는 01011001
1이 LSB에서 MSB로 회전하여 MSB로 이동하고, 나머지 비트는 한 자리씩 왼쪽으로 이동하며, 가장 오른쪽 비트는 가장 왼쪽 비트로 감싸짐
ROR R0, R1, #2
이 명령어는 R1 레지스터의 값을 오른쪽으로 2비트 회전하고, 그 결과를 R0 레지스터에 저장합니다. 즉, R1의 값을 오른쪽으로 2비트 회전시킨 후 그 값을 R0에 저장합니다.
R0: 00101011 (회전된 값)
예를 들어, 초기에 R1 레지스터에 10101100이 저장되어 있다고 가정해 봅시다. 이 때 ROR 명령어를 실행하면 LSB가 MSB로 이동하면서 회전됩니다. 따라서 회전 후의 결과는 다음과 같이 될 것입니다:
R0: 00101011 (회전된 값)
RRX(Rotate Right Extended)
: CF(Carry Flag)부터 MSB(최상위비트)까지 비트를 한 번 회전
: 즉, CF bit가 가장 오른쪽 bit, 나머지 bit는 한 자리씩 왼쪽으로 이동. MSB bit는 가장 왼쪽 bit로 감싸지는 회전.예를 들어, 8비트 이진수 10101100을 CF에서 MSB까지 한 번 회전시키면, 비트는 01010110. 즉, 가장 오른쪽 비트인 LSB를 MSB로 이동함.
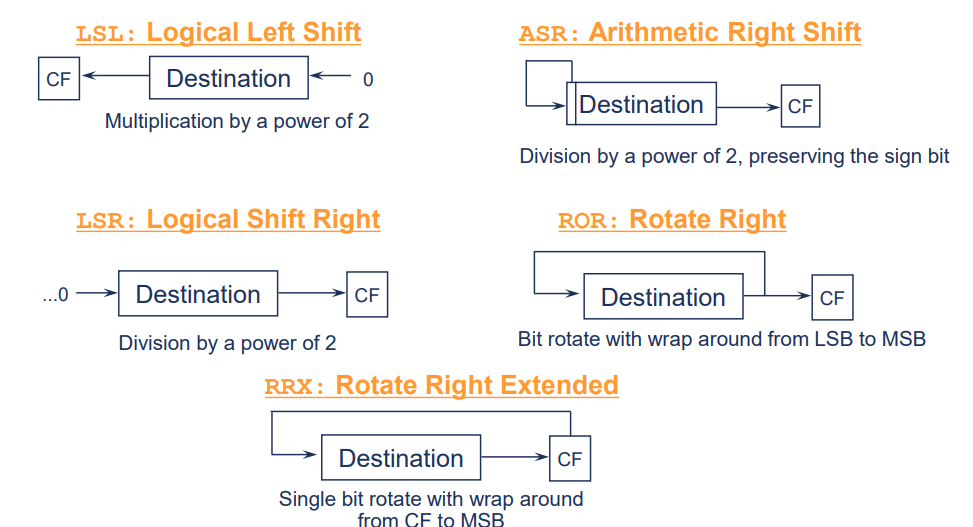
-
3단 파이프라인의 경우 fetch하는데 한 사이클, decode하는데 한 사이클, execute하는데 한 사이클
-
LSL(logical shift left, 왼쪽으로 1만큼 shift)
: 즉, x2의 의미를 가짐.
: ex. 3만큼 움직이면 2^3해서 8만큼
ADD R0 R5 R5 LSL 1
의 경우 R5를 1만큼 왼쪽 이동해서 R52 한 후에 ADD R5 해서 2R5 + R5 = 3R5 즉, 결과 레지스터(r0)에는 r53
- logical은 부호를 생각하지 않음
- ASR의 경우 맨 앞을 비워두고 거기에 부호에 따라 1, 0을 넣음
- ROR으로 ROL까지 표현이 가능하기에 ROL은 따로 존재하지 않음.
Immediate constants
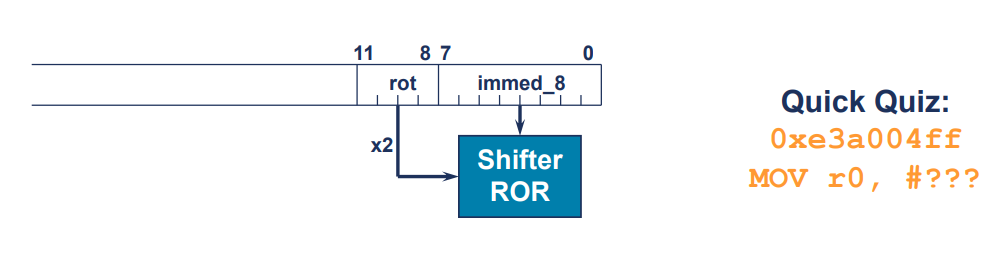
- arm 명령어는 32bit 길이로 고정
: 32비트 내에서 immediate constatnt를 포함할 수 없음.
0xe3a004ff
e3a0: MOV 명령어
04ff: operand 값
- r0 레지스터에 즉시 값 0xff를 이동하는 MOV 명령어
"MOV r0, #0xff"
: r0 레지스터에 255라는 값을 할당하는 명령어- ff가 immed
- 오른쪽으로 8bit 로테이트
cf. "MOV r0, #10"는 r0 레지스터에 상수 값 10을 이동하는 명령어
cf. 8비트 이진수 11001100을 오른쪽으로 8비트 로테이트하면, 비트는 다음과 같이 회전됩니다
: 00110011
- ARM 명령어는 32bit로 고정
- 32bit 즉시 상수를 포함하는 ARM 명령어는 없음. 따라서 모든 상수는 12bit의 op2에 포함되어야 함.
- 데이터 처리 명령어 형식에서는 op2에 12bit 사용. op2에는 즉시 상수 또는 즉시 이동이 포함 가능
- 즉시 이동에는 4bit 회전값(0-15) 사용. 이 회전 값은 2배가 되어서 범위가 0-30의 2의 단위로 증가. 이것은 회전 값이 짝수로 고정된다는 것을 의미
- 8bit rotated by an even number of bit positions규칙 존재
: 회전된 값이 짝수 비트 위치에 회전되었음을 의미.
: 즉시 상수를 조작할 때 사용
Loading 32 bit constants
- 어셈블리어에서 상수 값을 레지스터에 로드하는 방법
- 상수값을 로드하기 위해 어셈블러는 가짜 명령어인 LDR rd, =const 제공
- 여기서 rd는 대상 레지스터, const는 로드하려는 상수 값
- 이 가짜 명령어는 두 가지 방식 중 하나로 동작
- 가능하다면 상수 값을 생성하는 MOV 또는 MVN 명령어 사용 생성
- 불가능한 경우 PC 상대 주소를 사용하여 리터럴 풀(literal pool)에서 상수를 읽어오는 LDR 명령어 생성. 리터럴 풀은 코드에 포함된 상수 데이터 영역을 가리킴
a pseudo-instruction

-
0xFF라는 상수 값을 r0 레지스터에 로드함
-
mov가 불가능한 경우 LDR을 사용하여 레지스터에서 직접 읽어옴.
-
LDR r0, [PC, #Imm12]
"[PC, #Imm12]": 로드할 데이터가 저장된 메모리의 주소를 계산하기 위한 표현식
: PC 레지스터 값을 기준으로 한 상대적인 주소를 지정합니다. 여기서 "#Imm12"는 12비트 즉시 상수 값을 나타내며, 이 값은 0부터 4095(0xfff)까지의 값을 가질 수 있습니다. -
DCD 0x55555555
: "DCD"는 "Define Constant Doubleword"의 약어
: 메모리에 32비트 데이터로서 모든 비트가 1로 설정된 값을 정의
Multiply and Divide
- 레지스터는 32bit, 그러면 레지스터 2개를 곱하면 어떻게 될까? → 64bit가 된다. 그러면 64bit를 하나의 레지스터에 전부 담을 수는 없으니까 적당히 잘라서 넣음!
-
곱셈에는 2가지 종류가 존재
: 32bit 결과를 생성
: 64bit 결과를 생성 -
32bit 버전은 ARM7TDMI와 같은 이전 버전에서 2~5 사이클 내에 실행
ex.
1. MUL R0, R1, R2 => R0 = R1 * R2
2. MLA R0, R1, R2, R3 : R0 => (R1*R2)+R3
- MLA(곱셈을 수행하고 그 결과에 누적값을 더하기)
- 64비트 곱셈 명령어는 부호 있는(signed) 및 부호 없는(unsigned) 버전이 있으며, 두 개의 목적지 레지스터 사용
ex.
1. [U|S]MULL R4, R5, R2, R3 => R5:R4 = R2*R3
: "r2 * r3"의 결과를 64비트 값으로 계산하고, 그 결과를 r4와 r5 레지스터에 저장
2. [U|S]MLAL R4, R5, R2, R3 => R5:R4 = (R2*R3) + R5:R4
: "r2 * r3"의 결과를 64비트 값으로 계산하고, 이 결과에 r5:r4 레지스터에 저장된 값을 더함.
- MULL(Multiply Long)
: 32비트 레지스터 2개를 곱하고 그 결과를 64bit 레지스터 하나에 저장. 부호가 있거나 혹은 없는 32bit 곱셈을 수행할 때 사용.- [U|S] 의 U는 Unsigned, S는 Signed
- MLAL(Multiply Accumulate Long)
: 곱셉과 덧셈을 결합하여 수행
: 두 개의 32bit 레지스터 값을 곱한 후, 그 겨로가에 다른 64bit 레지스터에 저장된 값을 더함.
-
MULL은MUL에다가L을 붙인거, L을 붙였다는 뜻은 64bit라는 의미임. 즉, 64비트 곱하기
: 즉, r5:r4 = r2*r3임 -
ARM 코어 대부분이 정수 나눗셈 명령어를 제공하지 않음.
: 정수 나눗셈 연산은 대부분 C라이브러리 루틴이나 인라인 쉬프트를 사용하여 수행
▶ Branch instruction: 분기 명령어
Branch Instruction(1)

- perform PC relative branch to label "start"
:start라벨로의 PC 상대 분기를 수행. - continue execution from here
: 그곳에서부터 실행
분기 명령어의 형식
-
B{L}{<condition>} label
:B분기
:label분기 목표 지점을 나타내는 주소
:condbranch condition, 즉 조건을 검. 특정 조건을 만족할 때만 분기 수행
:{L}서브루틴 호출을 나타내는 옵션. 명령어를 수행한 후에 돌아올 주소를 저장하는 레지스터에 현재 명령어의 다음 주소를 저장 -
명령어 인코딩에는 24bit 주소 오프셋 필드 포함. 실행 시 이 오프셋은 2비트 왼쪽으로 이동되어야 함.(ARM 명령어는 항상 워드 정렬되어 있기 때문에) 이로써 상대적인 분기 범위가 32MB
-
분기 명령어의 실행은 파이프라인 플러시(Pipeline flush)를 발생. 파이프라인 플러시는 프로세서 파이프라인을 지우고 새로운 명령어를 가져오는 작업 수행
절대 분기(Absolute branches)는 PC를 직접 수정하여 구현 가능.
LDR pcMOV pc, ...SUBS pc, ...
위 명령어를 사용해 절대 분기 수행 가능. 이러한 절대 분기의 범위는 4GB의 주소 공간 내에서 제한되지 않음. 목적지의 주소는 절대적. 주소 공간 내의 어떠한 위치로도 이동 가능.
절대 분기(Absolute Branch)
- 절대 분기는 목적지 주소를 직접 명시하여 분기하는 방식입니다.
- 주로 점프 명령어(LDR pc, MOV pc, SUBS pc 등)를 사용하여 구현됩니다.
- 목적지 주소는 절대적이며, 전체 주소 공간 내의 특정 위치를 가리킵니다.
- 예를 들어, 주소 0x1000에 있는 코드로 분기할 수 있습니다.
- ex.
MOV pc, r1: r1에 저장된 값이 PC로 이동하여 분기 수행- ex.
LDR pc, [r2]: r2가 가리키는 주소에 있는 데이터를 로드 후 해당 데이터를 프로그램 카운터로 설정하여 분기 수행- ex.
SUBS pc, r3, #4: r3에 저장된 값에서 4를 뺀 결과를 PC 값으로 설정
상대 분기(PC Relative Branch)
- 상대 분기는 현재 명령어의 위치를 기준으로 한 상대적인 오프셋을 사용하여 분기합니다.
- PC 상대적 분기 명령어를 사용하여 구현됩니다.
- 목적지 주소는 현재 PC 값과 상대적으로 계산되며, 일반적으로 몇 바이트만큼 떨어진 곳으로 분기합니다.
- 예를 들어, 현재 위치에서 10바이트 떨어진 곳으로 분기할 수 있습니다.
- 상대 분기는 목적지 주소가 현재 위치와의 상대적 위치로 계산되므로 코드의 이동이나 재배치에 유리
- 절대 분기는 목적지 주소를 직접 지정하므로 코드가 이동하면 목적지 주소를 변경해야 하지만, 상대 분기는 현재 위치를 기준으로 하므로 코드 이동에 유연
position independent vs position dependent
- 절대주소값이 딱 정해지는 것이 position dependent
- pc의 index count값으로 정해주는 것이 position independent
이진수로 표현된 수의 최하위 2bit는 항상 00
ex. 8 = 1000, 4 = 100
Branch and Exchange
Branch and Exchange 명령어(BX)는 실행 중인 코드의 상태를 전환하고 다른 상태에서의 분기를 수행
BX Rn: Thumb 상태 분기 교환
- 레지스터 Rn에 저장된 값이 가리키는 주소로 Thumb 상태에서의 분기 수행. 즉, Thumb 상태에서 ARM 상태로 전환하여 해당 주소로 분기
BX <condition> Rn: ARM 상태 분기 교환
- ARM 상태에서 특정 조건이 충족될 때 레지스터 Rn에 저장된 값이 가리키는 주소로 분기를 수행. 분기 조건은 조건 코드(condition)에 따라 결정. 조건 코드는 분기가 수행될지 여부를 제어
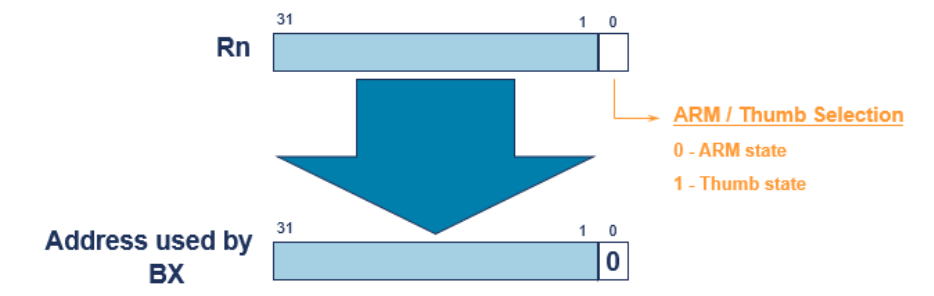
-
ARM/Thumb Selection은
0일 때ARM 상태,1일 때Thumb 상태. -
분기 교환 명령어(BX)는 상태 변경 없이도 절대 분기로 사용 가능.
Subroutines(서브루틴)
- 전통적인 서브루틴 호출 구현
- 반환 주소 저장
- 필요한 서브루틴의 주소로 분기
- 위 단계를 한 번에 수행하는 명령어 BL
- BL은 반환 주소를 링크 레지스터(LR, R14)에 저장하고, 필요한 서브루틴의 주소로 분기
- 반환주소는 LR 레지스터에 저장
- +-32MB 범위 내에서 어느 곳이든 분기 가능
- 반환은 프로그램 카운터(PC)를 LR레지스터의 값으로 복원하여 수행
- 서브루틴이 실행을 마치고 반환하면, 프로그램 카운터는 LR 레지스터의 값으로 복원
BL(Branch with Link)
BL subroutine_address
1. 현재의 프로그램 카운터(PC)의 다음 주소가 링크 레지스터(LR)에 저장됩니다. 이는 서브루틴이 실행을 마치고 반환할 주소를 저장하는 데 사용됩니다.
2. 명령어는 "subroutine_address"로 분기합니다. 따라서 프로그램은 지정된 서브루틴으로 분기하게 됩니다.
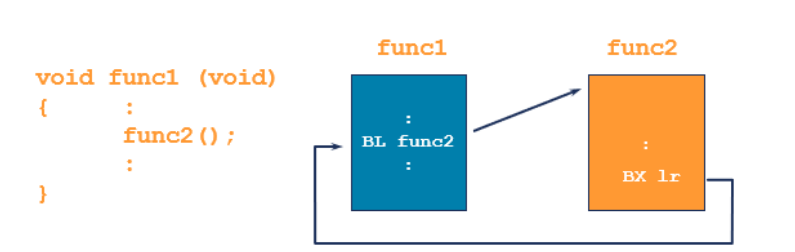
Generating Branches with LDR
- ARM 아키텍처에서의 범위는 +-32MB로 제한.
- 그러나 분기는 직접적으로 주소 값을 PC 레지스터 R15에 로드함으로써 수행 가능.
즉, 분기 명령어를 사용하여 특정 주소로 분기하는 것이 아니라, 직접 PC레지스터에 주소 값을 로드하여 분기 가능. 이렇게 하면 분기의 범위가 제한되지 않음.
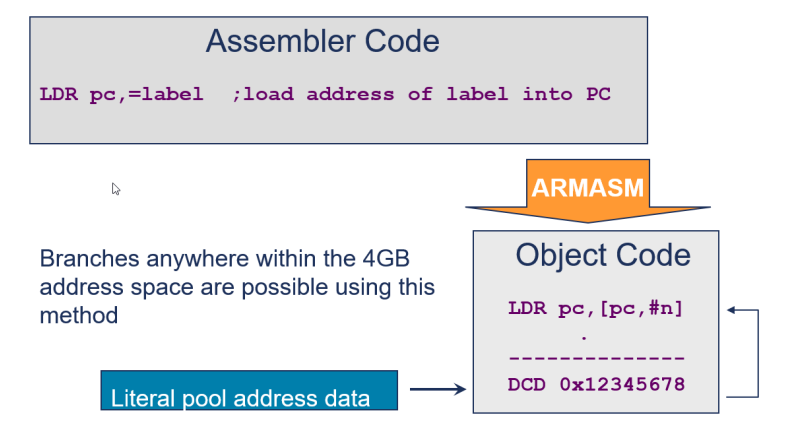
Literal Pool
: 데이터를 담아두는 공간
: 즉 명령어 공간 안에 데이터를 집어넣음, 그러므로 fetch 되지 않을 위치에다가 담아두어야 함.
상수나 리터럴 값이 반복해서 사용되는 경우, 이러한 값들은 메모리의 특정 영역에 저장. 이렇게 상수나 리터럴 값이 저장된 메모리 영역을 "Literal Pool"
▶ Status Register Instruction: 상태 레지스터 명령어
PSR Transfer Instruction

- MRS(Move to Register from Special Register) 및 MSR(Move to Special Register from Register) 명령어는 CPSR(현재 프로세서 상태 레지스터) 및 SPSR(이전 프로세서 상태 레지스터)의 내용을 일반 목적 레지스터로 전송하거나, 그 반대로 전송하는 데 사용.
문법(Syntax)
-
MRS{<cond>} Rd, <psr>: = <psr>
: Rd 레지스터에 <psr>의 내용을 전송 -
MSR{<cond>} <psr[_fileds]>, Rm: <psr[_fields]> =
: Rm 레지스터의 내용을 <psr[_fileds]>에 전송
: 여기서 <psr[_fields]>는 CPSR 또는 SPSR이며, 필드 중 하나인 'fsxc' 중 선택적으로 조합 -
MSR{<cond>} <psr_fields>,#Immediate
: 직접적인 형태로 <psr_fields>에 즉시 값을 전송 -
<psr> 및 <psr[_fileds]>
: <psr>은 CPSR또는 SPSR을 나타냄
: <psr[_fields]>는 CPSR 또는 SPSR에 있는 특정 필드 가리키기.
psr(program status register)이란?
: ARM 아키텍처에서 사용되는 특수 레지스터
: 현재 프로그램의 상태와 관련된 정보 저장.
CF. 사용자 모드에서는 모든 버튼을 읽을 수 있지만, 조건 플래그만 새울 수 있음.
PSR modification

이 설명은 CPSR(Current Program Status Register)를 수정하여 IRQ(Interrupt Request) 인터럽트를 활성화하는 예시를 제시하고 있습니다.
-
일반적으로는 읽기/수정/쓰기 전략이 사용됩니다:
- CPSR과 같은 레지스터를 수정할 때에는 일반적으로 현재 값에서 원하는 변경을 수행한 후, 변경된 값을 다시 레지스터에 기록하는 방식을 사용합니다.
-
아래 예시는 CPSR을 수정하여 IRQ 인터럽트를 활성화하는 방법을 보여줍니다:
- 먼저 CPSR의 값을 읽어서 r0 레지스터에 저장합니다.
- 다음으로 r0 레지스터에서 비트 7을 지워서 IRQ 비트를 0으로 설정합니다. 이는 IRQ 인터럽트를 활성화하기 위해 해당 비트를 클리어하는 작업입니다.
- 수정된 값을 다시 CPSR 레지스터에 쓰기 위해 MSR 명령어를 사용합니다. 여기서 "CPSR_c"는 CPSR 레지스터의 "current" 부분을 나타냅니다.
-
코드는 조심스럽게 'c' 바이트만 쓰기 때문에 다른 비트가 의도치 않게 변경되지 않도록 주의합니다:
- 다른 비트를 변경하지 않도록 하기 위해 코드는 "CPSR_c" 부분만 수정합니다.
-
CPSR을 상수 값으로 설정하는 것은 가능하지만 주의해서 사용해야 합니다:
- CPSR을 상수 값으로 설정하는 것은 프로세서 상태를 변경하는 중요한 작업이므로 주의해서 사용해야 합니다. 변경된 상태가 프로그램의 실행에 영향을 미칠 수 있으므로 신중하게 고려해야 합니다.
Load & Store Instruction: 로드 및 저장 명령어
Single register data transfer

- 메모리 시스템은 모든 접근 크기를 지원해야 함.
- 명령어 구문
LDR{<cond>}{<size>} Rd, <address>
: 메모리에서 데이터를 로드하여 레지스터에 저장STR{<cond>}{<size>}Rd, <address>
: 레지스터의 데이터를 메모리에 저장.
CF. LDR(Load Register), STR(Store Register)
CF. LDREQB
: LDR + EQUAL + BYTE
: 조건이 EQUAL 인 경우 BYTE 크기의 데이터를 로드
Address accessed

CF. OFFSET
: 어떤 위치나 값을 참조하기 위해 기준점으로부터의 상대적인 거리나 위치를 나타냄.
- LDR/STR로 접근하는 주소는 베이스 레지스터와 오프셋(offset)으로 지정
- 주소는 베이스 레지스터와 오프셋을 결합하여 계산
- 워드(word) 및 부호 없는 바이트(unsigned byte) 접근의 경우, 오프셋은 다음과 같음
- 부호 없는 12비트 즉시값(즉, 0에서 4095바이트)
LDR r0, [r1, #8] - 레지스터 및 선택적으로 즉시값으로 시프트된 값
LDR r0, [r1, r2]
LDR r0, [r1, r2, LSL#2] - 베이스 레지스터에서 더하거나 빼는 오프셋
LDR r0, [r1, #-8]
LDR r0, [r1, -r2, LSL#2]
- 반워드(halfword) 및 부호 있는 반워드/바이트의 경우, 오프셋은 다음과 같음
- 부호 없는 8비트 즉시값(즉, 0에서 255바이트)
- 레지스터 (시프트되지 않음)
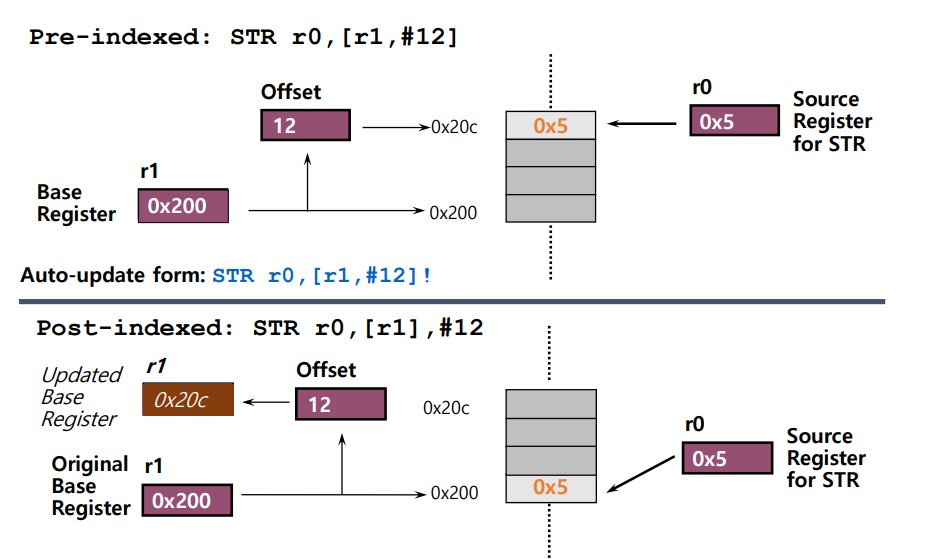
- 전위 증가(pre-indexed) 또는 후위 증가(post-indexed) 주소 지정 방법 선택:
- 베이스 포인터 업데이트 여부 선택 가능 (전위 증가(pre-indexed) 방식에서만 가능)
LDR r0, [r1, #-8]!
LDR r0, [r1, #8]
: r1이 가리키는 메모리 주소에서 8바이트(offset)만큼 이동한 위치의 데이터를 로드하여 r0 레지스터에 저장합니다.LDR r0, [r1, r2]
: r1이 가리키는 메모리 주소에서 r2 레지스터가 가리키는 오프셋(offset)만큼 이동한 위치의 데이터를 로드하여 r0 레지스터에 저장.LDR r0, [r1, r2, LSL#2]
: r1이 가리키는 메모리 주소에서 r2 레지스터가 가리키는 오프셋(offset)에 4를 곱한 값만큼 이동한 위치의 데이터를 로드하여 r0 레지스터에 저장. 이 때, LSL#2는 r2의 값을 왼쪽으로 2비트 시프트하는 것을 의미LDR r0, [r1, #-8]
: r1이 가리키는 메모리 주소에서 8바이트(offset)만큼 반대 방향으로 이동한 위치의 데이터를 로드하여 r0 레지스터에 저장LDR r0, [r1, -r2, LSL#2]
: r1이 가리키는 메모리 주소에서 r2 레지스터가 가리키는 값을 왼쪽으로 2비트 시프트한 값을 반대 방향으로 이동한 위치의 데이터를 로드하여 r0 레지스터에 저장LDR r0, [r1, #-8]!
: r1이 가리키는 메모리 주소에서 8바이트(offset)만큼 반대 방향으로 이동한 위치의 데이터를 로드하여 r0 레지스터에 저장하고, r1에 -8을 더한 새로운 주소를 저장
Pre or Post Indexed Addressing? (기억하자★★★)
인덱싱
메모리 주소에 상대적인 OFFSET을 적용하여 데이터에 접근하는 방법.
- 상대적인 오프셋은 인덱스 레지스터 값과 조합하여 사용
인덱싱하는 3가지 방식
1. PRE INDEXED(전위 인덱싱)★★★
- 주소 계산이 레지스터에 저장된 오프셋을 사용하여 수행
- 주소 계산 후에는 인덱스 레지스터가 업데이트
- 예를 들어,
[r1, #8]!와 같이 사용될 수 있으며, 이 경우 r1이 가리키는 주소에 8바이트를 더한 주소로 데이터를 접근하고, 그 후 r1이 8만큼 증가
2. AUTO UPDATE(자동 업데이트)★★★
- 주소 계산 후에는 인덱스 레지스터가 자동으로 업데이트
- 인덱스 레지스터의 값이 변하지만, 실제로 새로운 주소로 접근하는 것은 아니며, 이전에 계산된 주소로 데이터에 접근
3. POST INDEXED(후위 인덱싱)★★★
- 주소 계산에는 인덱스 레지스터의 현재 값을 사용
- 주소 계산 후에는 인덱스 레지스터가 업데이트
[r1], #8와 같이 사용될 수 있으며, 이 경우 r1이 가리키는 주소로 데이터에 접근한 후에 r1이 8만큼 증가.
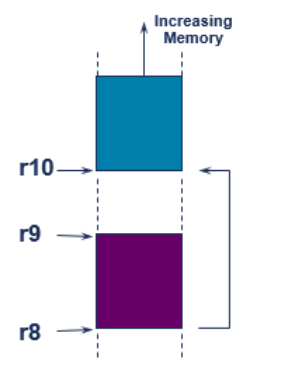
Memory Block Copying(1) ★ 코드 이해 필요 ★
- r8~r9까지의 memory block을 r10으로 copying하고 싶음.
- 베이스 레지스터 업데이트를 사용하면 간단한 복사 루틴 작성 가능.
EX. 후위 인덱싱은 메모리 블록을 복사하는데 사용 가능.

loop LDR r0, [r8], #4 // load 4 bytes
STR r0, [r10], #4 // and store them
CMP r8, r9 // check for the end
BLT loop // else loopSTR 명령어에서 r10 레지스터의 값을 4만큼 증가시키는 이유는 메모리에서 데이터를 읽고 저장하는 동안 다음 데이터를 저장할 위치를 나타내기 위해서
r8이 r9보다 작으면 아직 복사할 데이터가 남아 있음을 의미하므로 루프를 계속하여 더 많은 데이터를 복사
이 예제에서는 각 반복마다 1 워드가 복사
Load and Store Multiples
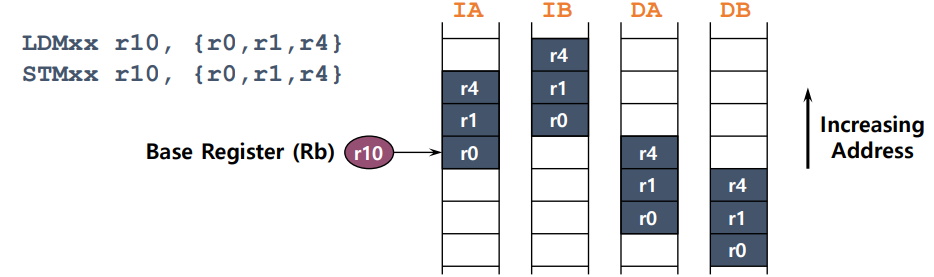
<LDM|STM>{<cond>}<addressing_mode> Rb{!}, <register list>
4 addressing modes
-
LDMIA(Load Multiple Increment After) / STMIA(Store Multiple Increment After)
: increment after -
LDMIB / STMIB
: increment before -
LDMDA / STMDA
: decrement after -
LDMDB / STMDB
: decrement before
-
after와 before 차이 기억하기
-
increament와 decrease 차이 기억하기
-
LDMIA R10, {R0, R1, R4}
: R10이 가리키는 메모리 위치에서 R0, R1, R4 레지스터로 데이터를 로드합니다.
이후에 R10 레지스터 값을 증가시킵니다. (Increment After) -
LDMIB R10, {R0, R1, R4}
: R10이 가리키는 메모리 위치에서 R0, R1, R4 레지스터로 데이터를 로드합니다.
로드 작업 이전에 R10 레지스터 값을 증가시킵니다. (Increment Before) -
LDMDA R10, {R0, R1, R4}
: R10이 가리키는 메모리 위치에서 R0, R1, R4 레지스터로 데이터를 로드합니다.
이후에 R10 레지스터 값을 감소시킵니다. (Decrement After) -
LDMDB R10, {R0, R1, R4}
: R10이 가리키는 메모리 위치에서 R0, R1, R4 레지스터로 데이터를 로드합니다.
로드 작업 이전에 R10 레지스터 값을 감소시킵니다. (Decrement Before)
증가(increment) 방식:
증가 방식에서는 데이터를 읽거나 저장한 후에 레지스터 값을 증가시킵니다.
이렇게 하면 다음 데이터가 저장될 위치를 지정하기가 편리합니다.
메모리의 연속적인 데이터를 로드하거나 저장하는 데 특히 유용합니다.감소(decrement) 방식:
감소 방식에서는 데이터를 읽거나 저장하기 전에 레지스터 값을 감소시킵니다.
이렇게 하면 이전 데이터의 위치를 지정할 수 있습니다.
주로 스택과 같이 메모리의 역순으로 데이터를 처리할 때 유용합니다.
Memory Block Copying(2)
- STM와 LDM 명령어는 스택 작업 뿐만 아니라메모리 블록 복사에도 사용 가능
loop LDMIA r8!, {r0-r8}
STMIA r10!, {r0-47}
CMP r8, r9
BLT loop
LDMIA r8!, {r0-r8}:
r8이 가리키는 메모리 위치에서 데이터를 읽어와 r0부터 r8까지의 레지스터에 저장합니다.
읽기 작업 이후에 r8 레지스터 값을 증가시킵니다.STMIA r10!, {r0-47}:
r0부터 r7까지의 레지스터에 있는 데이터를 r10이 가리키는 메모리 위치에 저장합니다.
쓰기 작업 이후에 r10 레지스터 값을 증가시킵니다.CMP r8, r9:
r8과 r9 레지스터의 값을 비교합니다. 이 명령어는 루프 종료 조건을 검사하기 위해 사용됩니다.
BLT loop:
r8이 r9보다 작으면 루프로 이동하여 작업을 계속합니다. 이렇게 함으로써, r8이 r9보다 작은 동안 루프를 반복하여 메모리 블록을 계속 복사합니다.
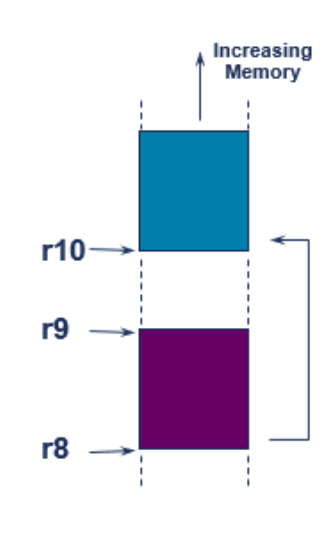
Stacks
- ARM 스택 작업은 블록 전송 명령어를 사용하여 구현
1. STMFD(Push)
Store Multiple - Full Descending stack [STMDB]
: 스택에 여러 레지스터를 저장하는데 사용되며, Full Descending stack 방식
이는 STMDB(Store Multiple Decrement Before)와 동등한 동작을 함.
2. LDMFD(Pop)
Load Multiple - Full Descending stack [LDMIA]
: 스택에서 여러 레지스터를 로드하는데 사용되며, Full Descending stack 방식. 이는 LDMIA(Load Multiple Increment After)와 동등한 동작을 함. 이 명령어는 스택에서 레지스터를 로드하기 위해 사용
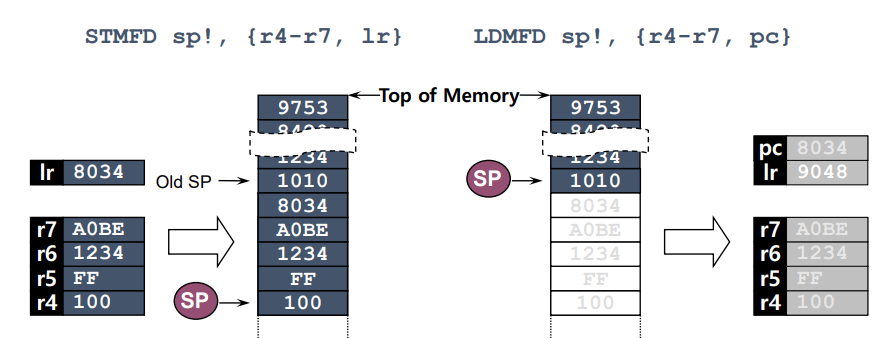
- 높은 쪽 주소값에 높은 레지스터 들어감
Full Descending 이란?
- 스택이 내림차순으로 꽉 차 있는 상태
- 스택이 메모리의 높은 주소에서 낮은 주소로 증가하는 방식으로 구현되어 있음
- 스택의 가장 최근에 저장된 값은 메모리의 가장 낮은 주소에 위치
SWP
- 메모리 읽기(Memory Read)가 이루어진 후 메모리 쓰기(Memory Write)가 진행되는 원자적(Atomic) 작업
- 즉, 레지스터와 메모리 간에 바이트 또는 워드를 이동하는 것
SWP{<cond>}{B} Rd, Rm, [Rn]
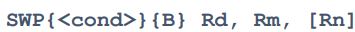
SWP: Swap을 의미합니다.
<cond\>: 조건 코드(Conditional Code)가 선택적으로 사용됩니다.
{B}: 바이트(Byte) 크기로의 이동을 나타냅니다. 이 부분은 선택적입니다.
Rd: 이동할 데이터를 담을 레지스터입니다.
Rm: 이동할 데이터를 담고 있는 레지스터입니다.
[Rn]: 데이터를 읽거나 쓸 메모리 위치를 가리키는 베이스 레지스터입니다.
- 레지스터 Rm의 값을 읽어와 메모리 주소 [Rn]에 있는 데이터와 교환(Swap)한 후, 이전의 메모리 데이터를 레지스터 Rd에 저장
- 작업은 원자적으로 실행되어, 다른 스레드 또는 프로세스가 중간에 메모리를 수정하는 경우에도 안전하게 작동
▶ Coprocessor Instruction: 코프로세서 명령어
Coprocessor Instructions
- ARM 아키텍처는 16개의 코프로세서를 지원
- 각 코프로세서에 대한 명령어는 ARM 명령어 세트의 고정된 부분 차지
- 시스템에 적절한 코프로세서가 없는 경우에는 정의되지 않는 명령어 예외(Undefined Instruction Exception) 발생
코프로세서 명령어의 세 가지 유형
- 코프로세서 데이터 처리(Coprocessor data processing)
- CDP: 코프로세서 데이터 처리 작업을 시작합니다.
- 코프로세서 레지스터 전송(Coprocessor register transfers):
- MRC: 코프로세서 레지스터에서 ARM 레지스터로 이동합니다.
- MCR: ARM 레지스터에서 코프로세서 레지스터로 이동합니다.
- 코프로세서 메모리 전송(Coprocessor memory transfers):
- LDC: 메모리에서 코프로세서 레지스터로 로드합니다.
- STC: 코프로세서 레지스터에서 메모리로 저장합니다
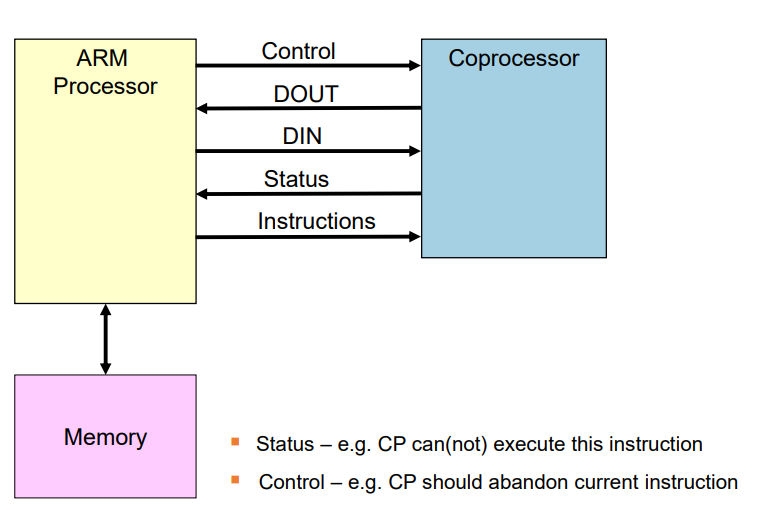
Coprocessor Connections
▶ Exception Generating Instruction: 예외 발생 명령어
Software Interrupts(SWI)
- SWI(Software Interrupt) 하드웨어 벡터로 예외(trap)를 발생
- SWI 핸들러는 SWI 번호를 검사하여 요청된 작업이 무엇인지 결정
- SWI 메커니즘을 사용하면 운영 체제는 사용자 모드에서 요청할 수 있는 일련의 특권 작업을 구현
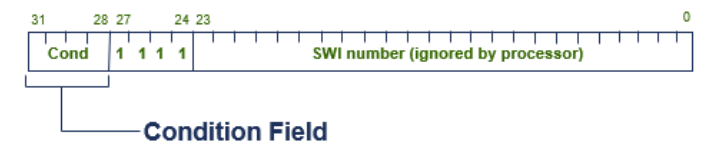
SWI: Software Interrupt를 의미합니다.<cond>: 조건 코드(Conditional Code)가 선택적으로 사용됩니다.<SWI number>: SWI 번호로, 핸들러가 어떤 작업을 수행해야 하는지를 식별
- 예외가 발생하면 vector table에 감.
- 이 명령은 일반적으로 운영 체제 내에서 특정 시스템 호출 또는 특권 작업을 수행하기 위해 사용
- SWI 명령은 사용자 프로그램이 특정한 운영 체제 서비스를 요청할 때 운영 체제로 제어를 양도하는 데 사용
Undefined Instructions
- 코프로세서에 대응되는 명령어가 없거나, 코프로세서에 접근할 권한이 없는 경우 발생하는 명령어들
1. 존재하지 않는 코프로세서 동작 (Non-existent coprocessor operation)
: 시스템에 해당 코프로세서가 없는 경우 해당 명령어가 발생합니다.
2. 코프로세서에 대한 권한 부족 (Lack of privilege to access coprocessor)
: 사용자 모드에서 특권 명령을 수행하려고 시도할 때 해당 명령어가 발생합니다.
3. 정의되지 않은 명령어 (Undefined instruction)
: ARM 아키텍처에서 정의되지 않은 명령어 또는 해당하는 명령어가 없는 비어 있는 비트 패턴이 포함된 명령어가 발생합니다.
- 또한, 정의되지 않은 명령어 공간이 존재
정의되지 않은 명령어 공간 (Undefined instruction space)
: 이 공간은 opcode의 일부 비트 패턴으로서 명령어가 정의되어 있지 않은 영역
: 이 공간은 새로운 명령어를 추가하기 위해 예약되어 있을 수 있음.
: 예를 들어, opcode의 27~25번째 비트가 0b011이고, 4번째 비트가 1인 경우를 예로 들 수 있음.
: 이 공간에서는 opcode의 일부 비트 패턴이 정의되어 있지 않으므로, 해당 명령어들은 ARM 아키텍처에서 정의되어 있지 않은 것으로 간주
