
Why do you need to know assembler?
- 많은 시스템의 대부분 디자인 작업은 고수준 프로그래밍에 집중
: 명령어 집합에 대한 지식은 필요하지 않음 - 그러나 임베디드 시스템의 경우
: 초기화 코드와 인터럽트 루틴이 필요 - 드라이버 작성의 경우
: 프로그램 추상화의 가장 낮은 수준에 대한 지식 필요 - 모든 시스템은 디버깅이 필요
: 때론 명령어 수준에서도 발생 - 성능 향상
: 어셈블러 루틴을 작성하여 얻을 수 있음 - 또한, Arm 아케텍처의 일부 기능은 고수준 언어로 표현 불가능.
▶ Load/Store
Single/Double register data transfer
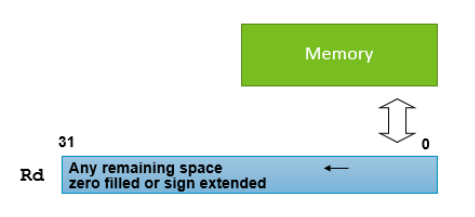
레지스터와 메모리 간 데이터 이동에 사용

LDRD STRD 더블워드
LDR STR 워드
LDRB STRB 바이트
LDRH STRH 하프워드
LDRSB 부호 있는 바이트 로드
LDRSH 부호 있는 하프워드 로드
LDR {<size>}{<cond>} Rd, <address>
STR {<size>}{<cond>} Rd, <address>
LDRB r0, [r1]
; load bottom byte of r0 from the byte of memory at address in r1
; r1에 저장된 주소가 가리키는 메모리 위치에서 바이트를 읽어와 r0 레지스터에 저장Addressing memory
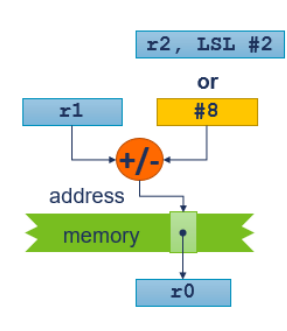
- LDR/STR에 의해 접근되는 주소는 선택적 오프셋을 가진 베이스 레지스터에 의해 지정
Base register only (no offset)
LDR r0, [r1]
Base register + 상수
LDR r0, [r1, #8]
Base register + 옵션으로 즉시값에 의해 shift된 register
LDR r0, [r1, r2]
LDR r0, [r1, r2, LSL #2]
오프셋은 베이스 레지스터에 더하거나 뺄 수 있음
LDR r0, [r1, #-8]
: offset은 '-8'
: 이스 레지스터 r1의 주소로부터 8바이트 떨어진 곳
LDR r0, [r1, -r2]
: offset은 '-r2'
: r1의 주소에서 r2 레지스터의 값만큼 뺀 위치
LDR r0, [r1, -r2, LSL #2]
: offset은 '-r2, LSL #2'
: r2 레지스터의 값에 4를 곱한 후(왼쪽 시프트) 베이스 레지스터 r1의 주소에서 뺀 위치
offset(오프셋)?
- 오프셋(offset)은 주소 계산에서 사용되는 상대적인 값
- 일반적으로 오프셋은 메모리 주소를 계산하기 위해 베이스 주소에 더하거나 빼는 값
Pre- and Post-Indexed Addressing
Pre-indexed(add offset before memory access)
LDR r0, [r1, #12]{!}
- r1의 값에 상대적인 오프셋으로 12를 더한 주소에서 데이터를 로드하여 r0에 저장.
- 이후에 r1은 변경되지 않음.
- 그러나,
!를 이용하면..
:!는 오프셋이 적용된 주소로 메모리에서 데이터를 로드한 후에, r1에 오프셋을 추가한 값을 사용하여 r1을 갱신하라는 의미
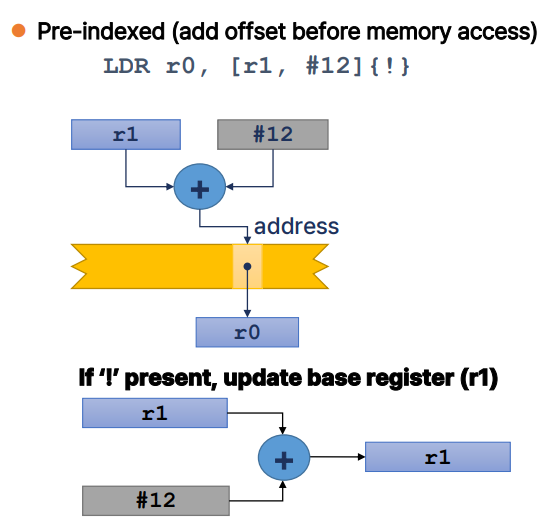
Post-indexed(add offset after memoery access)
LDR r0, [r1], #12
- r1이 가리키는 메모리 주소에서 데이터를 로드하여 r0에 저장한 후에, r1의 값을 12만큼 증가.
- 이는 자동으로 r1을 다음 데이터의 위치로 이동시키는 효과 존재.

Multiple register data transfer
<LDM|STM>{<addressing_mode>}{<cond>} Rb{!}, <register list>
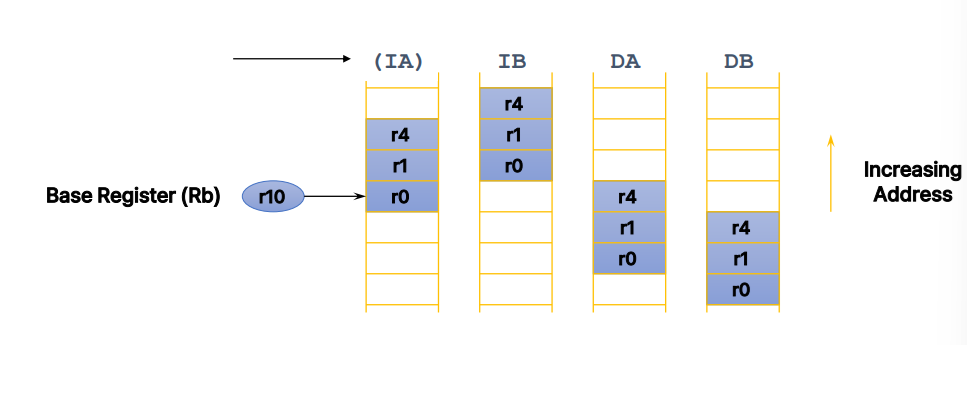
4가지 주소 지정 모드
- Increment after(IA)
: 데이터가 저장된 후에 베이스 레지스터가 증가 - Increment before(IB)
: 베이스 레지스터가 증가된 후에 데이터가 저장 - Decrement after(DA)
: 데이터가 저장된 후에 베이스 레지스터가 감소 - Decrement before(DB)
: 베이스 레지스터가 감소된 후에 데이터가 저장
- 여러 레지스터와 메모리 간의 데이터 이동을 수행
PUSH/POP(선입선출), SP를 베이스 레지스터로 사용하면STMDB/LDMIA와 동등
STMDB (Store Multiple Decrement Before)는 SP를 감소 시킨 후 레지스터의 값을 메모리에 저장.
LDMIA (Load Multiple Increment After)는 메모리에서 레지스터로 값을 로드한 후에 SP를 증가시킴.
LDM r10, {r0,r1,r4}
r10을 베이스로하여 레지스터를 로드
PUSH {r4-r6,pc}
SP를 베이스로하여 레지스터를 저장.
PUSH {r4, r5, lr} 명령은 STMDB sp!, {r4, r5, lr}와 동일한 동작을 수행
: 레지스터 r4, r5 및 lr을 스택에 저장
1. 스택 포인터(SP)를 4바이트씩 감소시킵니다.
2. 레지스터 r4의 값을 SP가 가리키는 메모리 위치에 저장합니다.
3. SP를 다시 4바이트씩 감소시킵니다.
4. 레지스터 r5의 값을 SP가 가리키는 메모리 위치에 저장합니다.
5. SP를 다시 4바이트씩 감소시킵니다.
6. 레지스터 lr의 값을 SP가 가리키는 메모리 위치에 저장합니다.
POP {r4, r5, pc} 명령은 LDMIA sp!, {r4, r5, pc}와 동일한 동작을 수행
- 스택 포인터(SP)가 가리키는 메모리 위치의 값을 레지스터 pc에 복원합니다.
- SP를 4바이트씩 증가시킵니다.
- 스택 포인터(SP)가 가리키는 메모리 위치의 값을 레지스터 r5에 복원합니다.
- SP를 4바이트씩 증가시킵니다.
- 스택 포인터(SP)가 가리키는 메모리 위치의 값을 레지스터 r4에 복원합니다.
- SP를 4바이트씩 증가시킵니다.
▶ Data Processing
Data processing instructions
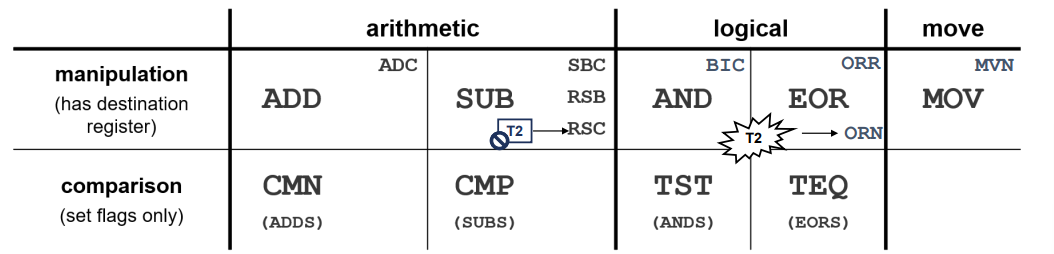
- 레지스터의 내용을 조작하는 명령어들
: 메모리에 영향을 미치지 않음
<Operation>{S}{<cond>} {Rd,} Rn, Operand2
ADD r0, r1, r2
; r0 = r1 + r2
TEQ r0, r1
; 만일 r0 = r1이면, Z 플래그가 설정됩니다.
SUBS r2, r4, #1
; r2 = r4 - 1 및 ALU 플래그를 업데이트합니다.
The flexible second operand
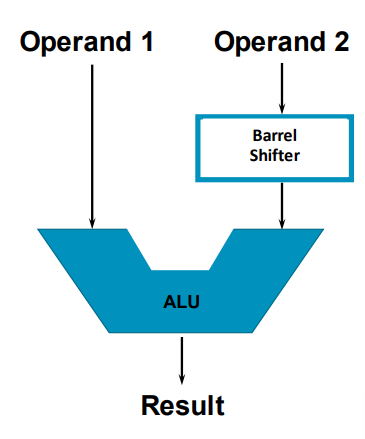
2번째 피연산자(Operation2)는 유연
<Op> Rd, Rn, Operand2- 레지스터, 선택적 시프트에서 시프트값
: 5bit의 부호 없는 정수
: 다른 레지스터의 하위 바이트에 지정됨(ARM 전용)
: 상수를 곱하는 데 사용
ADD r0, r5, r5, LSL #1
; r0 = r5 * 3
: 유연한 두 번째 피연산자는 즉시 값도 가능
: 0부터 255까지의 8비트 숫자
:ARM- 짝수만큼 오른쪽으로 회전
:Thumb- 어떤 양만큼이든 왼쪽으로 시프트됨
:Thumb은 또한 다음과 같은 형태의 상수를 허용
0x00XY00XY0xXY00XY000xXYXYXYXY
Instructions for loading constants
어셈블러는 레지스터에 값을 로드하는 명령어 제공
- 레지스터에 상수를 로드하도록 권장되는 메커니즘
Absolute constants
LDR Rn, =<constant>
LDR Rn, =label
- 가상 명령어(pseudo instruction)
: 어셈블러는 상수를 지정된 레지스터로 로드하기 위해 최적의 시퀀스를 생성 (MOV, MVN 또는 리터럴 풀로부터의 LDR 중 하나)
: 분기를 발생시켜 PC로 로드할 수 있음
: 절대 주소 지정 및 현재 섹션 외부의 참조에 사용 (위치 종속 코드로 결과)
: 어셈블리 또는 링크 시간에 결정된 상수
LDR R0, =42
: 레지스터 R0에 상수 42를 로드
LDR R1, =my_label
: my_label이라는 레이블의 주소를 R1에 로드PC- or register-relative constants(레지스터 상대적인 상수)
ADR - 레이블의 상대적인 주소를 계산하여 레지스터에 로드
ADR Rn, label
: 지정된 레지스터로 레이블의 주소를 생성하기 위해 한 명령어를 사용하여 PC에 즉시 값이 더해지거나 뺌.
: ADRL 가상 명령어는 두 개의 명령어를 사용하여 더 나은 범위를 제공
: 즉, 더 멀리 떨어진 레이블의 주소를 더 넓은 범위로 다룰 수 있음
: 위치 독립적인 코드의 주소를 생성하는 데 사용 가능(하지만, 동일한 코드 섹션에 있어야 함.)
: 실행 시간에 결정된 상수
ADR R2, some_label
: some_label 레이블의 주소를 R2에 로드.
: 이때, 주소는 PC에 즉시 값이 더해져 계산
ADRL R3, another_label
: another_label 레이블의 주소를 R3에 로드
: ADRL은 두 개의 명령어를 사용하여 더 나은 범위를 제공함.
- ADR 명령어는 현재 명령어의 주소(PC)를 기준으로 지정된 레이블까지의 상대적인 오프셋을 계산.
- 이러한 상대적인 오프셋을 해당 레이블까지의 바이트 수로 계산.
- 계산된 상대적인 오프셋은 명령어의 형식에 따라 해당 레지스터에 저장
- 즉, 명령어의 실행 위치와 지정된 레이블 사이의 상대적인 거리를 계산하여 레이블의 주소를 로드하는 데 사용
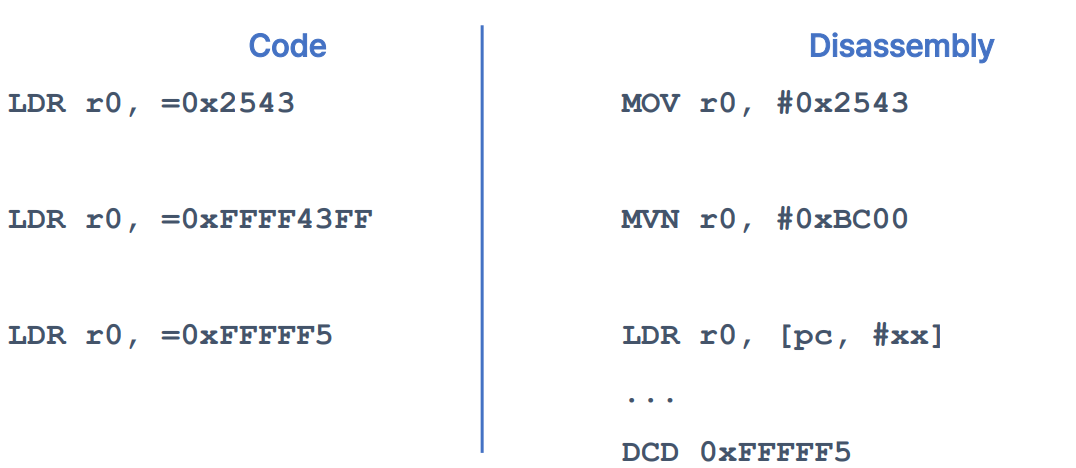
LDR=Examples
- LDR=를 사용하면 상수나 레이블이 변경되어도 코드를 수정하지 않고도 유연하게 대응 가능
Multiply / Divide
Multiplication
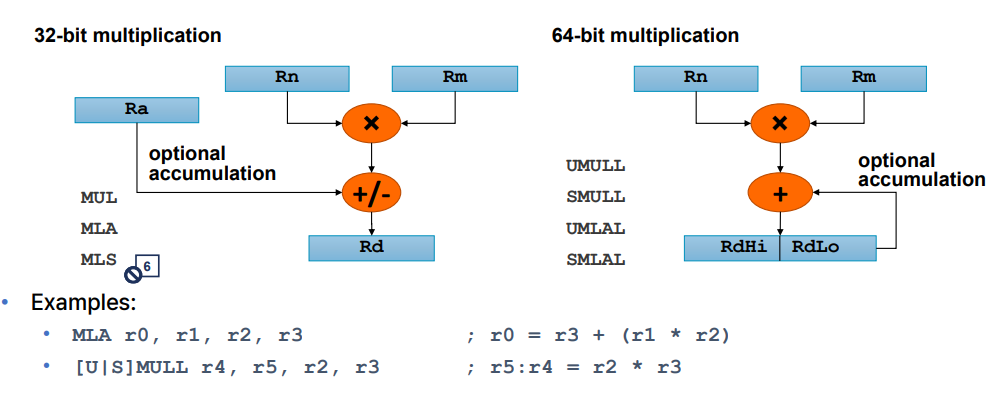
32bit 곱
MLA r0, r1, r2, r3
: r0 = r3 + (r1 * r2)
64bit 곱
[U|S]MULL r4, r5, r2, r3
: r5:r4 = r2 * r3
Division

부호 있는 division(SDIV)
SDIV r0, r1, r2
: signed: r0 = r1 / r2
부호 없는 division(UDIV)
UDIV r0, r1, r2
: unsigned: r0 = r1 / r2
Bit manipulation instructions
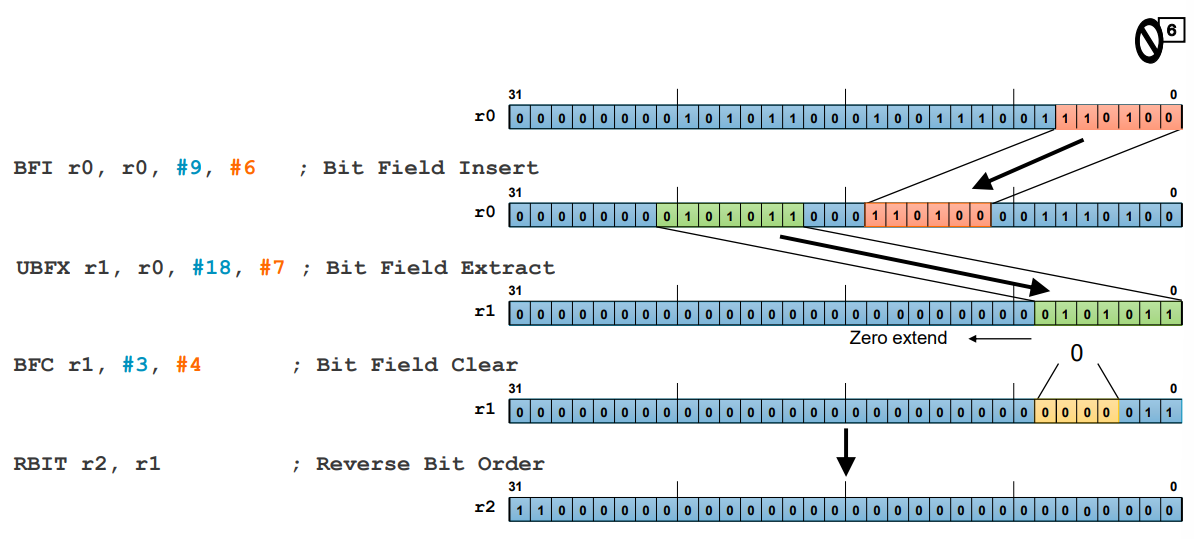
BFI r0, r0, #9, #6
; Bit Field Insert
: 레지스터 r0의 비트 필드를 조작하여 다른 값을 삽입
: r0의 9번째 비트부터 6비트를 가져와서 r0의 해당 비트 위치에 삽입
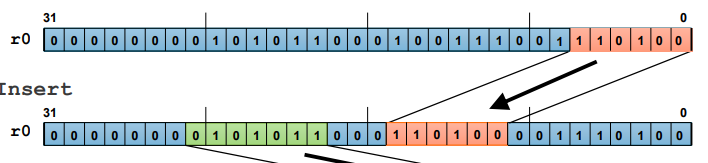
-
UBFX r1, r0, #18, #7
; Unsigned Bit Field Extract
: 레지스터 r0에서 비트 필드를 추출하여 다른 레지스터인 r1에 저장
: r0의 18번째 비트부터 7비트를 추출하여 r1에 저장
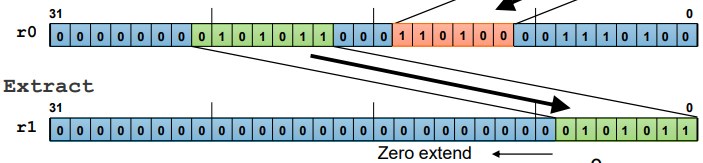
-
BFC r1, #3, #4
; Bit Field Clear 0
: 레지스터 r1의 비트 필드를 지움
: r1의 3번째 비트부터 4비트를 지움
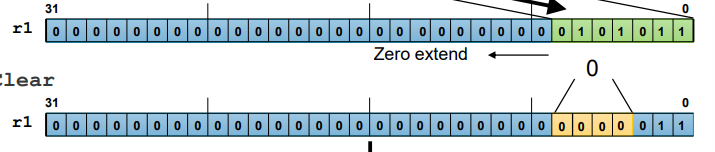
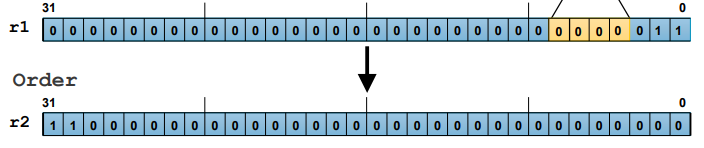
RBIT r2, r1
; Reverse Bit Order
: 레지스터 r1의 비트 순서를 역순으로 변경하여 r2에 저장
: r1의 가장 오른쪽 비트가 r2의 가장 왼쪽 비트로 이동
Byte reversal
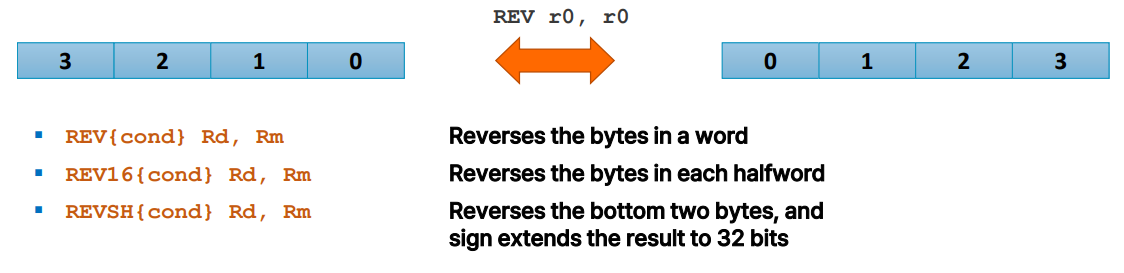
REV{cond} Rd, Rm
- 해당 명령어는 단어(word) 내의 바이트(byte) 순서를 뒤집음.
- 즉, 32비트 단어의 모든 4바이트에 대해 바이트의 순서를 뒤집어 새로운 레지스터에 저장
MOV r0, #0x12345678
; r0 레지스터에 0x12345678 값을 로드
REV r1, r0
; r0의 바이트 순서를 뒤집어서 r1에 저장
; r1: 0x78563412REV16{cond} Rd, Rm
- 반단어(halfword) 내의 바이트(byte) 순서를 뒤집음.
- 16비트 반단어의 각각의 2바이트에 대해 바이트의 순서를 뒤집어 새로운 레지스터에 저장
MOV r0, #0xABCD
; r0 레지스터에 0xABCD 값을 로드합니다.
REV16 r1, r0
; r0의 반단어 내의 바이트 순서를 뒤집어서 r1에 저장합니다.
; r1: 0xCDABREVSH{cond} Rd, Rm
- 하위 두 바이트(byte)의 순서를 뒤집고, 결과를 32비트로 sign-extend
- 즉, 16비트 반단어의 바이트 순서를 뒤집은 후, 이를 32비트로 확장하여 새로운 레지스터에 저장
MOV r0, #0xFF7F
; r0 레지스터에 0xFF7F 값을 로드
REVSH r1, r0
; r0의 하위 두 바이트의 순서를 뒤집고, 결과를 32비트로 확장하여 r1에 저장
; 여기서, r0의 하위 두 바이트는 0x7F와 0xFF
; 0XFF = 1111 1111 → 역순 0X00 = 0000 0000
; 0X7F = 0111 1111 → 역순 0XFE = 1000 0000
; r1: 0x0000FE
▶ Flow Control
Branch instructions
B{<cond>} label
- 조건부로 실행되는 Branch 명령어의 경우
{<cond>}포함 가능 - 이는 조건이 충족될 때만 분기가 실행됨을 나타냄
- 이 명령어는 주어진 label로 분기를 수행
- 이 때, 분기는 파이프라인 플러시를 발생시키지 않을 수 있음
- 즉, 브랜치 예측(branch prediction)이 이뤄질 수 있음
- 분기의 범위는 명령어 세트와 너비에 따라 다름.
- 하드웨어의 아키텍처에 따라 달라짐.

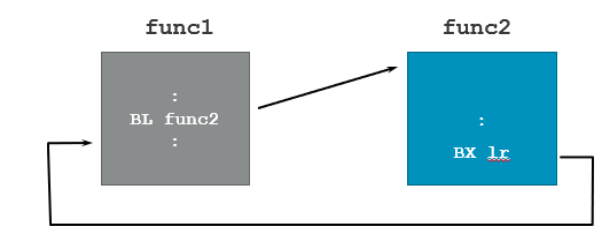
BL(Branch with Link) 명령어
BL{<cond>} label
- BL 명령어는 분기를 수행하는 동시에 리턴 주소(return address)를 레지스터 r14(일반적으로 lr)에 저장
- 함수 호출 시 사용되며, 함수의 반환은 프로그램 카운터(pc)를 lr의 값으로 복원하는 것으로 이뤄짐.
Interworking
BX(Branch eXchange) 명령어
- Interworking을 수행할 때 BX 명령어 사용 가능
BX Rn - Rn 레지스터의 0번째 비트는 교환 행동(exchange behavior)을 결정
- 비트가 설정되지 않은 경우: Arm 상태로 변경하거나 유지
- 비트가 설정된 경우: Thumb 상태로 변경하거나 유지
Branch and Link with Exchange (BLX) 명령어
BLX Rn
- 반대의 명령어 세트에 있는 서브루틴으로 분기하는 데 사용
- Arm와 Thumb 간의 상호작용을 수행할 때 사용
- 가져온 레이블로 분기할 때는 BL 명령어를 사용하고, 링커(linker)가 필요한 경우 BLX를 대체
BLX offset
; 항상 상태를 변경하는 Arm/Thumb 명령어 (LR도 설정됨)
PC를 수정하는 모든 명령어는 상태 변경을 유발
- PC를 수정하는 모든 명령어는 결과의 0번째 비트에 따라 상태 변경을 유발
- 데이터 처리 명령어의 경우, S(save flag) 변형을 사용하지 않은 경우에만 상태가 변경
- S 옵션을 사용하지 않으면, 데이터 처리 명령어는 단순히 주어진 레지스터들 간의 연산을 수행하고 그 결과를 다른 레지스터에 저장
Compare and Branch if Zero
- CBZ 및 CBNZ 명령어는 CMP 명령어를 사용한 후에 분기하는 것을 대체
- 두 명령어는 조건 코드 플래그를 변경하지 않음.
CB{N}Z <Rn>, <label>
CBZ(Compare Branch if Zero)
: 만약 Rn이 0과 같으면, 지정된 레이블로 분기
CBNZ(Compare Branch if Not Zero)
: 만약 Rn이 0과 같지 않으면, 지정된 레이블로 분기
분기 범위
4바이트에서 130바이트 사이에서만 전방으로 분기 가능

If-Then
IT{T|E}{T|E}{T|E} <cond>
- IT 블록은 다음 1-4개의 명령어를 조건적으로 실행
- IT 블록은 T(Then) 또는 E(Else) 상태를 설정하여 다음 명령어가 조건적으로 실행되는지 여부를 결정
<cond>는 임의의 조건 코드- 조건 코드 플래그에 영향을 주지 않음(CMP, CMN 및 TST 제외)
- 32비트 명령어는 조건 코드 플래그에 영향을 줌
- 필요한 경우 이 명령어를 직접 작성할 필요는 없습니다. 어셈블러가 필요한 곳에 자동으로 삽입
- 현재의 "if-then" 상태는 CPSR에 저장
- 이로써 조건 블록은 안전하게 중단되고 되돌아갈 수 있음.
- "if-then" 블록으로 분기하거나 이를 빠져나가는 것은 권장되지 않음.
; if (r0 == 0)
; r0 = *r1 + 2;
; else
; r0 = *r2 + 4;
; if
CMP r0, #0
ITTEE EQ
; then
LDREQ r0, [r1]
ADDEQ r0, #2
; else
LDRNE r0, [r2]
ADDNE r0, #4- r0가 0인지를 비교한 후에 ITTEE EQ 명령어로 조건 블록을 설정
- 이후 LDREQ 명령어가 실행되어 r1이 가리키는 메모리 위치의 값을 r0에 로드
- ADDEQ 명령어가 실행되어 r0에 2를 더함
- 그렇지 않은 경우, LDRNE 명령어가 실행되어 r2가 가리키는 메모리 위치의 값을 r0에 로드하고, ADDNE 명령어가 실행되어 r0에 4를 더함.
Example: Conditional Execution
pseudo code
if (r0 == 0)
{
r1 = r1 + 1;
}
else
{
r2 = r2 + 1;
}- r0가 0인지를 확인하고, 그에 따라 r1 또는 r2 값을 증가시키는 조건문
inefficient branching
CMP r0, #0
IT NE
BNE else
ADD r1, r1, #1
B end
else
ADD r2, r2, #1
end- CMP로 r0와 0을 비교하고, 이후 NE 조건에 따라 IT 블록을 설정
- NE 상태인 경우, else 레이블로 분기하여 r2를 증가시키고, 분기 후에는 end 레이블로 분기
- 그렇지 않은 경우, r1을 증가시키고, 분기 없이 end 레이블로 분기
no brancing
CMP r0, #0
ITE EQ
ADDEQ r1, r1, #1
ADDNE r2, r2, #1- 주어진 코드는 CMP로 r0와 0을 비교하고, EQ 또는 NE 조건에 따라 IT 블록을 설정
- EQ 상태인 경우, ADDEQ 명령어를 사용하여 r1을 1만큼 증가
- NE 상태인 경우, ADDNE 명령어를 사용하여 r2를 1만큼 증가
▶ Misc
Coprocessor instructions
- coprocessor에 대한 명령어는 Arm 명령어 집합의 고정된 부분을 차지
Coprocessor의 3가지 유형
Data processing(데이터 처리)
CDP
: coprocessor data processing operation을 시작
Register transfer(레지스터 전송)
MRC
: coprocessor 레지스터에서 Arm 레지스터로 이동
MCR
: Arm 레지스터에서 coprocessor 레지스터로 이동
Memory transfers(메모리 전송)
LDC
: 메모리에서 coprocessor 레지스터로 로드합니다.
STC
: coprocessor 레지스터에서 메모리로 저장
- 다중 레지스터 및 이러한 명령어의 다중 레지스터 및 기타 변형도 있음.
PSR access
MRS 및 MSR
- MRS 및 MSR 명령어는 CPSR, SPSR의 내용을 일반 목적 레지스터로 전송하거나, 일반 목적 레지스터 또는 즉시값을 CPSR, SPSR에 전송하는데 사용
- MSR 명령어는 전체 상태 레지스터 또는 그 일부 업데이트 가능
MRS r0,CPSR
: 현재 프로그램 상태 레지스터(CPSR)의 내용을 일반 목적 레지스터인 r0에 읽어옴.
: CPSR은 ARM 프로세서에서 현재 실행 중인 프로그램의 상태를 나타내는 레지스터
BIC r0,r0,#0x80
: r0 레지스터의 7번째 비트를 지워줌.
: IRQ(Interrupt Request)를 활성화시키는데, 이는 인터럽트를 처리할 수 있도록 함.
MSR CPSR_c,r0
: 수정된 값이 포함된 r0 레지스터를 CPSR의 'c' 바이트에 쓰는데, 'c' 바이트는 CPSR의 제어 비트를 포함
: 이 명령은 IRQ를 활성화시키기 위해 수정된 CPSR 값을 사용
CPS
- CPSR의 일부 비트를 직접 수정하는 데 사용
SETEND 명령어
- 데이터 접근의 엔디안을 선택하는 데 사용
- 혼합된 엔디안 데이터를 사용하는 시스템에 사용
SETEND BE
LDR r0, [r7], #4 ; big-endian
SETEND LE
LDR r1, [r7], #4 ; little-endianMiscellaneous instructions
- Breakpoint Instruction (BKPT):
- BKPT 명령어는 디버그 에이전트(Debug Agent)에 의해 사용되며, BKPT 번호를 사용하여 지정.
- 즉시 값은 프로세서에 의해 무시.
- 이 명령어의 실행은 프리페치 어보트(Prefetch Abort)를 유발하거나 프로세서를 디버그 상태로 전환시킴. 이는 코어 디자인 및 구성에 따라 다름
- Wait For Interrupt (WFI):
- WFI 명령어는 코어를 대기 모드(Standby Mode)로 전환.
- 인터럽트 또는 디버그 이벤트에 의해 깨어남.
- 이전에는 CP15(Coprocesor 15) 연산으로 구현.
- No Operation (NOP):
- NOP 명령어는 다음 명령어를 정렬하기 위한 패딩으로 사용 가능.
- 실행하는 데 시간이 걸릴 수도 있고, 걸리지 않을 수도 있음.
- Wait for Event (WFE) & Send Event (SEV):
- 이 명령어들은 별도의 모듈에서 다루어짐.
▶ DSP
DSP instructions overview
-
SIMD (Single Instruction Multiple Data) DSP Instructions:
- 이 DSP(Digital Signal Processing) 명령어들은 SIMD(Single Instruction Multiple Data) 구조를 가지고 있습니다.
- 이들은 단어(word)에 패킹된 8 또는 16비트의 데이터에 작용합니다.
- 패킹된 구조체 유형에 대한 더 효율적인 액세스를 허용합니다.
-
명령어 그룹:
- 데이터 패킹/언패킹(Data Packing/Unpacking): 데이터를 패킹하거나 언패킹하는 명령어들의 그룹입니다.
- 데이터 처리(Data Processing):
- Saturated Maths: 포화된 연산을 수행하는 명령어들의 그룹입니다.
- 덧셈 / 뺄셈(Addition/Subtraction): 덧셈이나 뺄셈을 수행하는 명령어들의 그룹입니다.
- 곱셈(Multiplication): 곱셈을 수행하는 명령어들의 그룹입니다.
- Sum of Absolute Differences: 절대 차이의 합을 계산하는 명령어들의 그룹입니다.
이러한 명령어들은 디지털 신호 처리에 특화되어 있으며, SIMD 구조를 활용하여 여러 데이터를 동시 처리 가능.
Saturated Maths and CLZ
- 포화된 수학(Saturated Mathematics) 지원:
- 포화된 수학은 DSP 및 제어 응용 프로그램을 대상으로 합니다.
- 오버플로우가 발생하면 V(오버플로우) 플래그가 아니라 Q(스티키) 플래그를 설정하고 결과를 최대값 또는 최소값으로 설정합니다.
- 포화된 수학 명령어:
- QSUB{cond} Rd, Rm, Rn: Rd에 (Rm - Rn) 값을 포화하여 설정합니다.
- QADD{cond} Rd, Rm, Rn: Rd에 (Rm + Rn) 값을 포화하여 설정합니다.
- QDSUB{cond} Rd, Rm, Rn: Rd에 (Rm - (Rn×2)) 값을 포화하여 설정합니다.
- QDADD{cond} Rd, Rm, Rn: Rd에 (Rm + (Rn×2)) 값을 포화하여 설정합니다.

3. 선행 0의 개수 세기:
- CLZ{cond} Rd, Rm: 가장 유의미한 비트 앞의 설정되지 않은 비트의 개수를 반환합니다.
포화된 수학 명령어들은 DSP 및 제어 응용 프로그램에서 사용되며, 오버플로우를 방지하고 안정성을 향상시키는 데 도움이 됩니다. 또한, CLZ 명령어는 주어진 레지스터에 대해 가장 유의미한 비트 앞의 설정되지 않은 비트의 개수를 계산합니다.
Saturation(포화)
USAT Rd, #sat, Rm {shift}
: Rd = Saturate(Shift(Rm), #sat)
- USAT 명령어는 값이 특정 비트 위치로 포화되도록 함.
- 사실상 임의의 2의 거듭제곱으로 포화되는 것을 의미
- USAT는 부호 없는 32비트 값에 대해 포화를 수행
Unsigned Saturate 32-bit (USAT)
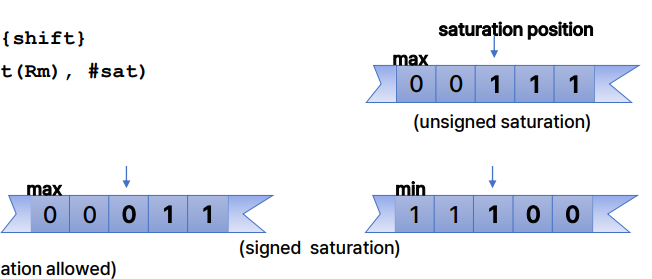
- SSAT: 부호 있는 포화
- USAT16: 두 개의 16비트 부호 없는 하프워드를 포화시킵니다. (회전(rotation)은 허용되지 않음)
- SSAT16: 두 개의 16비트 부호 있는 하프워드를 포화시킵니다. (회전은 허용되지 않음)
- #sat은 1에서 32까지의 범위 내에서 즉시값으로 지정됩니다.
- {shift}는 선택적이며 LSL 또는 ASR로 제한됩니다.
- 포화가 발생하면 Q 플래그가 설정됩니다.
USAT 명령어를 사용하여 특정 비트 위치로 값을 포화시키면 값이 특정 범위 내에서 제한되며, 부호 있는 경우 포화되는 방식도 다르게 설정할 수 있습니다.
SIMD
Armv6에서 추가된 SIMD 명령어
- Armv6 아키텍처는 Arm 레지스터를 사용하여 - SIMD(Single Instruction Multiple Data) 연산을 수행하는 여러 명령어를 추가했습니다.
- 이 명령어들은 덧셈, 뺄셈, 곱셈 및 절대값의 합과 같은 연산을 수행합니다.
- 이 명령어들은 8비트 묶음 4개 또는 16비트 묶음 2개에서 작동할 수 있습니다.
- 많은 명령어에는 부호 있는/부호 없는 및 포화 버전이 제공됩니다.
- 일반 ALU(산술 논리 장치) 플래그 대신 CPSR(현재 프로그램 상태 레지스터)의 GE(상태 등급) 비트가 사용됩니다.
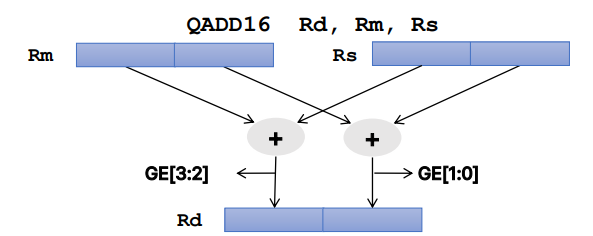
레지스터의 패킹 및 언패킹을 위한 명령어
- SIMD 연산 중 패킹(PKHBT, PKHTB) 및 언패킹(UXTH 및 UXTB) 레지스터를 위한 명령어가 있습니다.
QADD16 Rd, Rm, Rs는 레지스터 Rm과 Rs의 각각의 16비트 묶음에 대해 포화된 16비트 덧셈을 수행하고 그 결과를 Rd에 저장하는 명령어
Appendix: Encoding choice
-
Thumb-2 프로세서를 대상으로 어셈블하는 경우 16비트와 32비트 명령어 인코딩을 선택할 수 있습니다:
- 일반적으로 어셈블러는 16비트 명령어를 생성합니다.
-
Thumb-2 명령어 폭 지정자:
- 이를 통해 어셈블러가 사용할 명령어 폭을 결정할 수 있습니다.
- 명령어 목록 바로 뒤에 배치될 수 있습니다.
- .W: 32비트 명령어 인코딩을 강제합니다.
- .N: 16비트 명령어 인코딩을 강제합니다.
- 선택된 인코딩이 불가능한 경우 어셈블러는 오류를 발생시킵니다.
-
해제 규칙:
- 올바른 재조립을 보장하기 위해 1:1 매핑이 정의됩니다.
- 위의 규칙을 따르지 않는 비트 패턴이 해제되는 경우 .W 또는 .N 접미사가 사용됩니다.
이것은 Thumb-2 프로세서를 대상으로 하는 어셈블리 작업에서 사용되는 인스트럭션 인코딩 폭을 결정하고 관리하는 방법에 관한 지침을 제공합니다.
