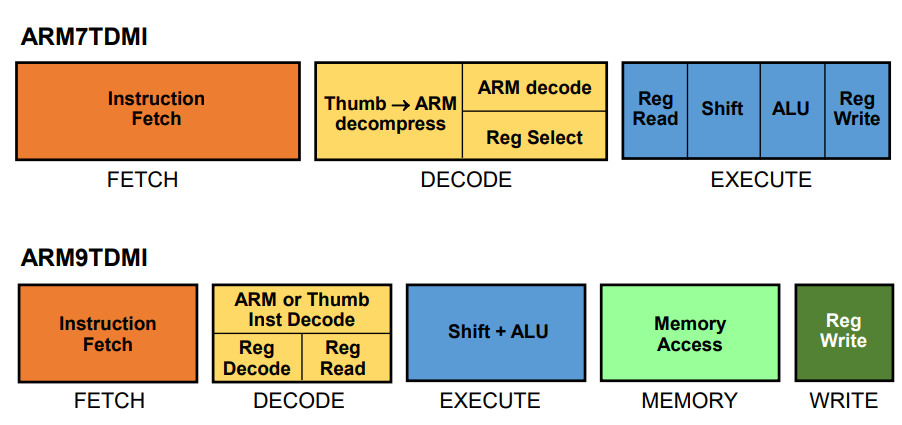
▶ Arm7 Family
Arm7TDMI Processor Core
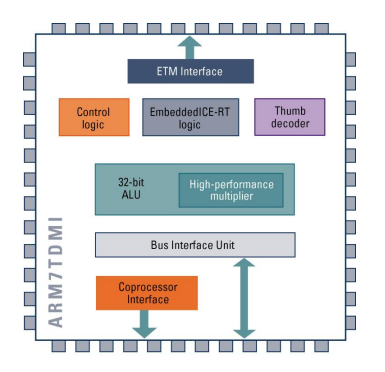
- 아키텍쳐 v4T
- 3 단계 파이프라인
CPI ~ 1.9 - 폰 노이만 아키텍처
: 하나의 외부 메모리 인터페이스 - ARM7TDMI-S(synthesizable version, 합성 가능한 버전)도 제공
T
- Thumb 명령어 집합 지원
: 32bit ARM 명령어
: 16bit Thumb 명령어
DI
- JTAG를 통한 디버그를 위한 "EmbeddedICE Logic" 지원
M
- 64bit 결과를 위한 명령어와 32x8 개선된 곱셈기
Von Neumann Memory Interface(폰 노이만 메모리 인터페이스)
One interface for Instruction & data
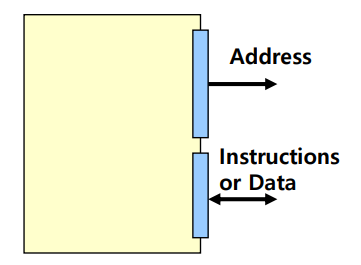
- 컴퓨터 시스템에서 프로그램 명령어와 데이터를 같은 메모리 공간에 저장
- 즉, 단일 메모리 공간 내에서 명령어와 데이터가 동일한 메모리 공간을 공유함.
- 메모리와 CPU 사이에 단일 버스가 존재하여 명령어와 데이터를 전송
1. 주소 버스(Address Bus)
: cpu가 메모리 주소를 지정하는 데 사용
: cpu는 명령어를 읽거나 데이터를 읽고 쓰기 위해 메모리의 특정 주소를 지정
2. 데이터 버스(Data Bus)
: 메모리에서 명령어나 데이터를 읽고 쓰는 데 사용
: 데이터 버스를 통해 명령어가 CPU로 전달되고, CPU에서 처리된 데이터가 다시 메모리로 전달
The Instruction Pipeline(명령어 파이프라인)
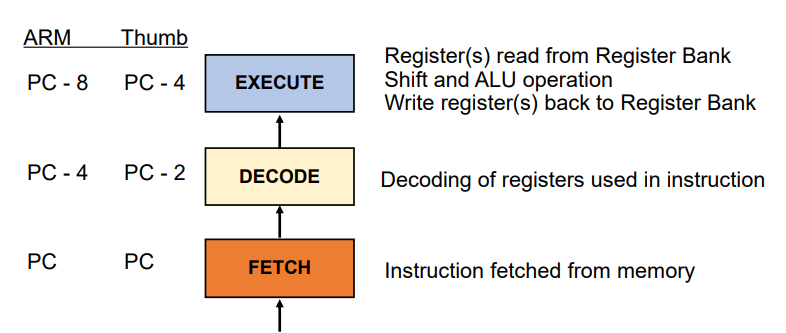
- ARM7 계열은 3단계 파이프라인을 사용
: 여러 작업을 동시에 수행 가능 - PC(프로그램 카운터)는 실행 중(EXECUTE)인 명령어가 아닌, 가져오고(FETCH) 있는 명령어를 가리킴.
1. FETCH(가져오기)
- 메모리에서 명령어를 가져옴
- PC는 이 단계의 명령어를 가리킴
2. DECODE(해독)
- 명령어에 사용된 레지스터를 해독
- ARM 명령어의 경우 PC보다 4바이트 앞서 있음(PC+4)
- Thumb 명령어의 경우 PC보다 2바이트 앞서 있음(PC+2)
3. EXECUTE(실행)
- 레지스터 뱅크에서 레지스터를 읽어옴
- Shift와 ALU연산을 수행
- 레지스터를 레지스터 뱅크에 다시 사용
- ARM 명령어의 경우 PC보다 8바이트 앞서 있음(PC+8)
- Thumb 명령어의 경우 PC보다 4바이트 앞서 있음(PC+4)
The Arm 7TDM Core
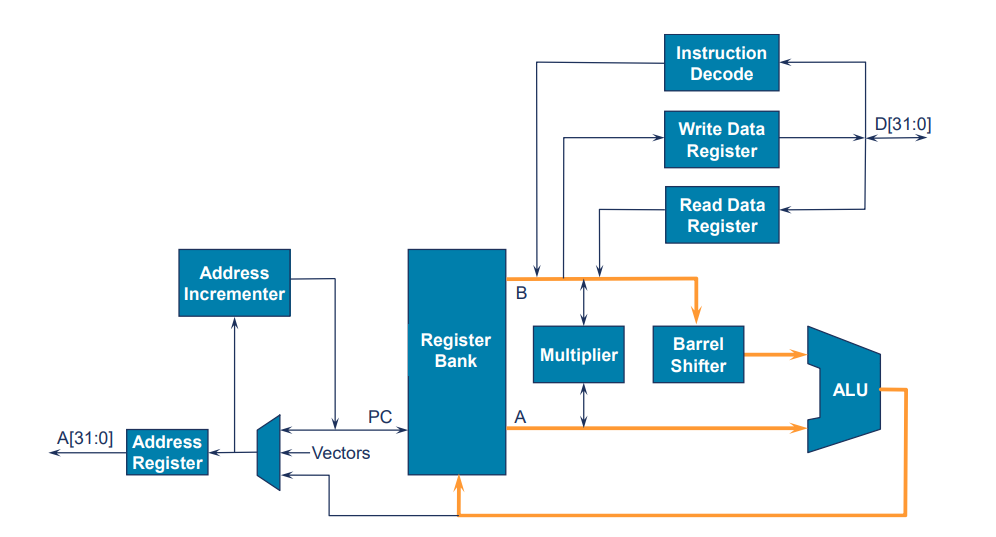
Optimal Pipeline
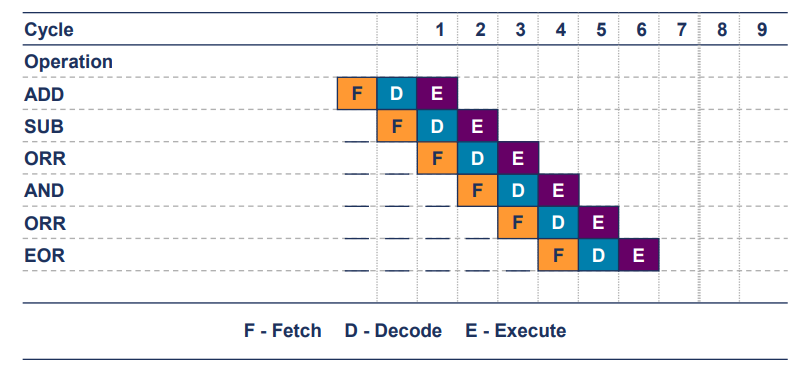
- 모든 연산은 레지스터에서 수행(단일 사이클 실행)
- 위 예에서는 6개의 명령어를 실행하는 데 6 clock cycle 소요
- 명령어 당 클록 사이클(CPI) = 1
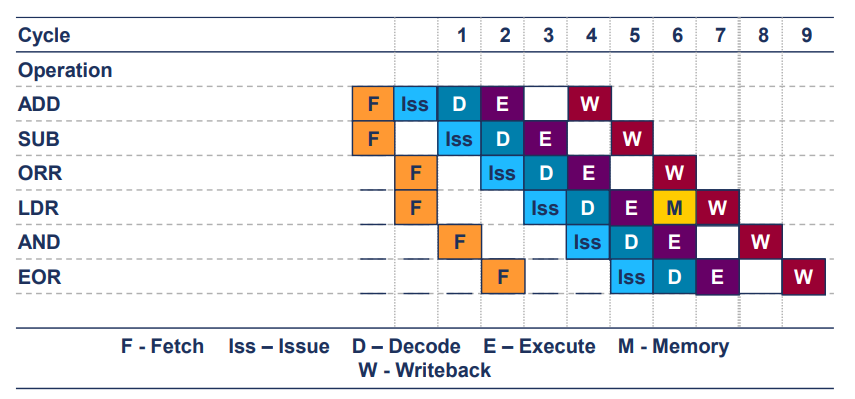
LDR Pipeline Example
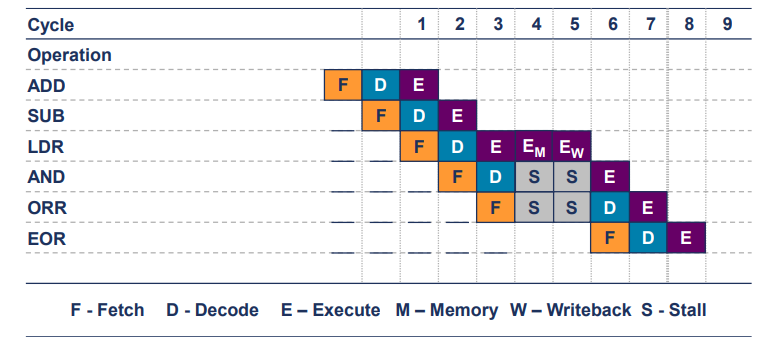
- 첫 번째 명령어(ADD)가 사이클1에서 시작, 네 번째 명령어(ADD)가 사이클 6에서 execute할 때까지 6개의 clock cycle 필요
- 즉, 4개의 명령어를 실행하는데 6개의 clock cycle소요
- CPI = 1.5
- 여기서 LDR명령어는
- FETCH(F)
- DECODE(D)
- EXECUTE(E): 주소 계산
- MEMORY(M): 메모리에서 데이터 로드
- WRITEBACK(W): 레지스터에 데이터 쓰기
해서 일반적으로 5사이클이 필요함.
추가로, STR 명령어의 경우에는
FETCH, DECODE, EXECUTE, MEMORY해서 4개의 사이클이 일반적으로 필요함.
파이프라인 단계
- F: Fetch (명령어 가져오기)
- D: Decode (명령어 해독)
- E: Execute (명령어 실행)
- M: Memory (메모리 접근)
- W: Writeback (결과 기록)
- S: Stall (정지)
- 여기서, Stall이 발생한 이유
데이터 의존성
1. AND 명령어의 STALL
: LDR 명령어가 EXECUTE단계가 아직 끝나지 않은 상태이고, AND 명령어는 LDR 결과값을 필요로 하기에, 스톨 상태에서 대기함.
2. ORR 명령어의 STALL
: ORR 또한 AND의 EXECUTE단계가 아직 끝나지 않은 상태이기에, 대기함.
Pipeline Flushing
파이프라인 플러싱이란?
- 프로세서의 파이프라인에서 잘못된 예측 분기나 다른 제어 흐름 변경으로 인해 필요하지 않게 된 명령어들을 제거하는 과정
- 주로 분기 명령어(branch)가 실행되었을 때 발생
- 밑 이미지는 분기 명령어(
B <destination>)이 실행되는 상황 - 이 명령어는 특정 조건이 충족되면 다른 주소로 점프하는 명령어
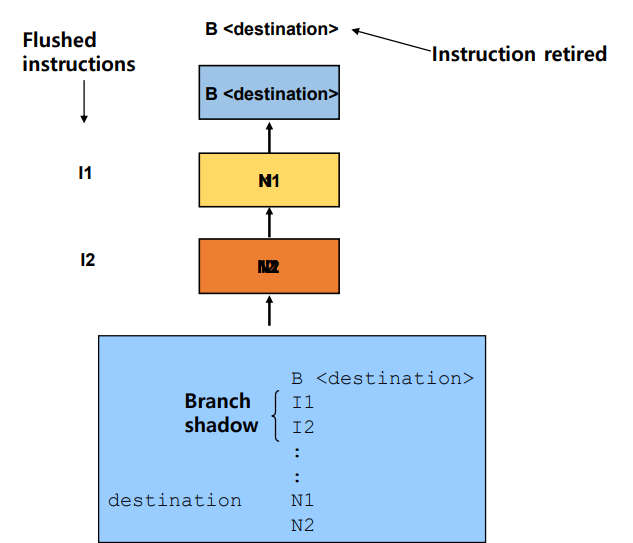
1. 분기 명령어 실행 (
B <destination>):
- 분기 명령어가 실행되면서, 프로세서는 조건에 따라 특정 주소로 점프
2. 플러싱된 명령어 (Flushed Instructions):
- I1, I2와 같은 명령어들이 분기 명령어 이후에 파이프라인에 로드되었으나, 분기 명령어가 실행되면서 이 명령어들은 더 이상 유효하지 않음.
이러한 명령어들은 파이프라인에서 제거.
이를 "플러싱"이라고 함.3. 분기 그림자 (Branch Shadow):
- 분기 명령어 이후에 파이프라인에 존재하는 명령어들(I1, I2 등)은 분기 그림자(Branch Shadow)라고 불림.
분기 명령어가 실행되면, 이 분기 그림자 내의 모든 명령어는 무효화되며 제거됨.4. 목적지(destination):
- 분기 명령어가 점프하는 주소로, 여기서부터 새로운 명령어(N1, N2 등)가 파이프라인에 로드되고 실행됨.
Branch Pipeline Example
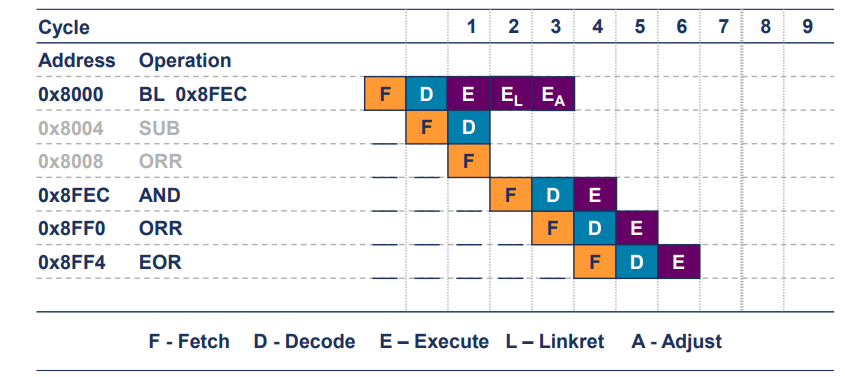
- 파이프라인 깨짐(Breaking the Pipeline) 발생
- 코어는 ARM 상태에서 명령어를 실행하고 있음.
F (Fetch): 명령어 가져오기
D (Decode): 명령어 해독
E (Execute): 명령어 실행
L (Linkret): 복귀 주소를 링크 레지스터에 저장
A (Adjust): 분기 주소로 이동
- 0x8000에서 branch 실행
- 0x8FEC 주소로 branch하기 때문에
- 그 다음 주소인 SUB과 ORR은 붕괴
- 그 후 0X8FEC부터 AND명령어 실행..
Interrupt Pipeline Example

DI(디코드 IRQ)
: 인터럽트 요청(IRQ)이 디코딩
EI(Execute IRQ)
: 인터럽트 요청이 실행 중
- IRQ 인터럽트의 최소 지연은 7cycle임.
- IRQ 발생할 경우 인터럽트 서비스 루틴(ISR)로 분기
- 이 과정에서 파이프라인 플러싱 발생
- 인터럽트가 처리된 후에 지정된 인터럽트 핸들러 주소로 분기
▶ Arm9 Family
Arm9E(J) Processor Core
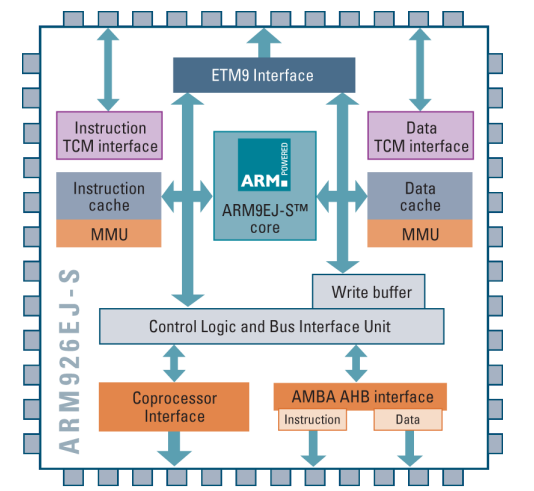
ARM926EJ-S (pictured)
- ARM9TDMI 코어 기반
- v5TE 아키텍처를 따른다.
- 5단계 파이프라인을 가짐 (ARM9TDMI와 동일).
- 단일 사이클 32x16 곱셈기를 가짐.
- 메모리 관리 유닛(MMU)을 포함
- Jazelle 기술을 지원
- 구성 가능한 캐시와 TCM(태스크 캐시 메모리)를 가짐.
- 2개의 AHB 메모리 인터페이스를 제공
- 개선된 디버깅을 위한 EmbeddedICE-RT를 지원
ARM946E-S
- ARM9TDMI 코어를 기반
- 구성 가능한 캐시와 TCM을 가짐.
- 메모리 보호 유닛(MPU)을 포함
- 단일 AHB 메모리 인터페이스를 가짐.
ARM966E-S / ARM968E-S
- ARM9TDMI 코어를 기반
- ARM968E-S는 DMA(Direct Memory Access)를 TCM으로 지원
- ARM968E-S는 캐시나 MPU/MMU를 가지지 않으며, TCM은 구성 가능.
- ARM966E-S는 캐시나 MPU/MMU를 가지지 않고, TCM은 구성 가능하며, 단일 AHB 메모리 인터페이스를 제공함.
Harvard Memory Interface
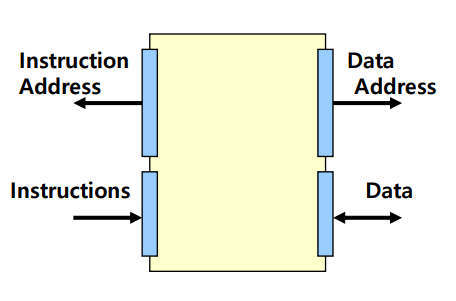
- 데이터와 명령어를 별도의 인터페이스로 처리하는 구조
- 데이터와 명령어 접근을 병렬로 처리하여 성능을 향상 시킴.
- 기존 폰 노이만 구조와 달리, 데이터와 명령어가 별도의 경로에서 동시에 접근할 수 있어 처리 속도가 빠름.
- 하버드 메모리 인터페이스는 임베디드 시스템과 같은 성능 요구가 높은 환경에서 특히 유용하게 사용됨.
Arm9
Harvard Architecture
- 하버드 아키텍처는 메모리 대역폭을 증가시킴
- 명령어 메모리 인터페이스와 데이터 메모리 인터페이스가 별도로 존재
- 명령어와 데이터 메모리에 동시 접근이 가능하도록 설계되어 있어 병렬 처리를 통해 성능을 향상 시킬 수 있음
5단계 파이프라인 사용
- 파이프라인은 명령어를 처리하는 단계를 여러 단계로 분리하여 작업을 동시에 처리할 수 있도록 함.
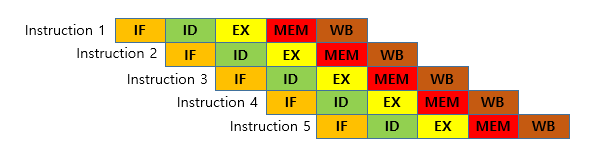
5단계 파이프라인
- Instruction Fetch (IF): 메모리에서 명령어를 가져옴.
- Instruction Decode (ID): 명령어를 해석하고 필요한 데이터를 준비함.
- Execution (EX): 명령어를 실행하고 필요한 계산을 수행함.
- Memory Access (MEM): 데이터 메모리 접근이 필요한 경우 데이터를 읽거나 쓰기를 수행함.
- Write Back (WB): 실행 결과를 레지스터에 저장하거나 필요한 경우 메모리에 쓰기를 완료함.
개선 사항
- CPI(Cycles Per Instruction)을 약 1.5로 개선하도록 변경 사항이 구현됨.
- 이는 명령어를 수행하는 데 필요한 평균 사이클 수를 줄이는 것을 의미함
- 최대 클럭 주파수를 개선하여 처리 속도를 더욱 높일 수 있도록 변경 사항이 이뤄짐.
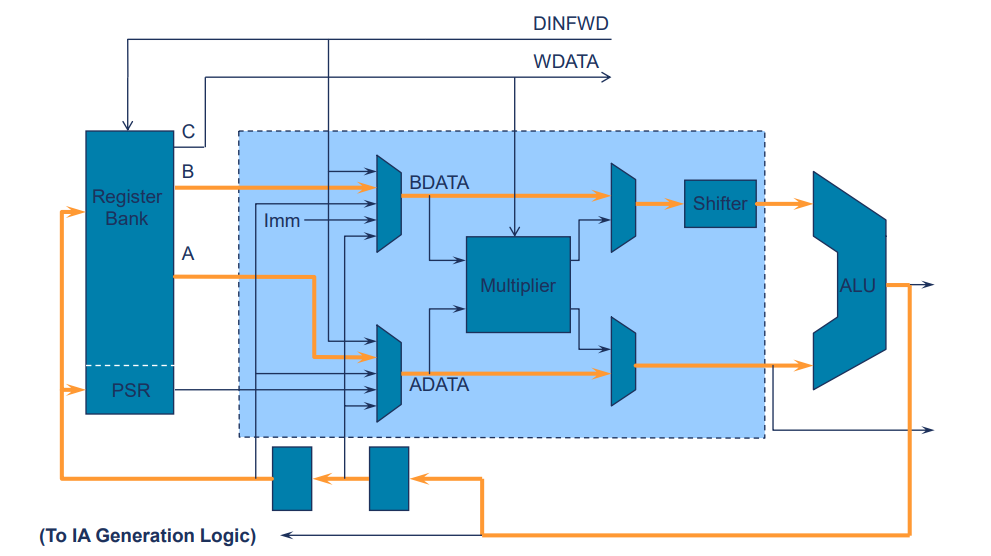
Arm9E-S Datapath
Optimal Pipelining
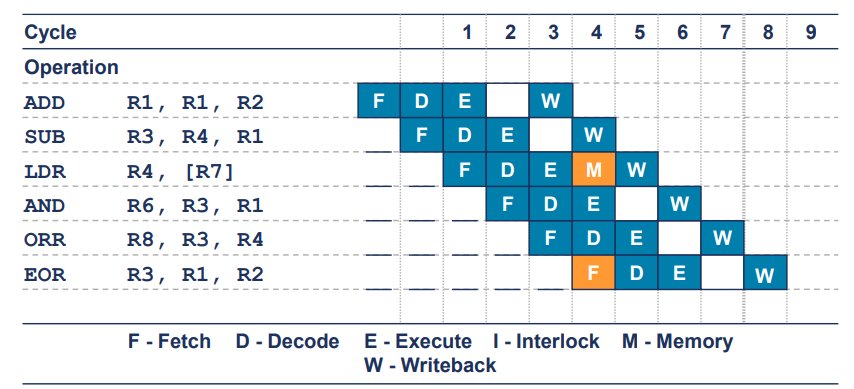
- 이 예시에는 총 6개의 명령어가 6개의 사이클 동안 실행
- 즉, CPI가 1임.
- 4번째 사이클에서는 명령어와 데이터 메모리가 동시에 접근. 이는 하버드 아키텍처에서의 특징으로, 명령어와 데이터가 별도의 경로를 통해 동시에 접근될 수 있음을 의미함.
- 5번째 사이클에서는 레지스터 R4의 데이터가 ORR 명령어에서 사용될 수 있음
- 이 데이터는 레지스터에 쓰이기 전에 ORR 명령어에서 이미 사용 가능한 상태
- 내부 전달 경로가 사용됨.
- 이는 처리기 내부에서 데이터가 필요한 곳으로 직접 전달되어 성능을 향상시키는 기술
- 데이터를 레지스터나 명령어 실행 단계로부터 직접적으로 전달함으로써 파이프라인의 지연을 줄이고 처리 속도를 최적화함.
LDR Interlock
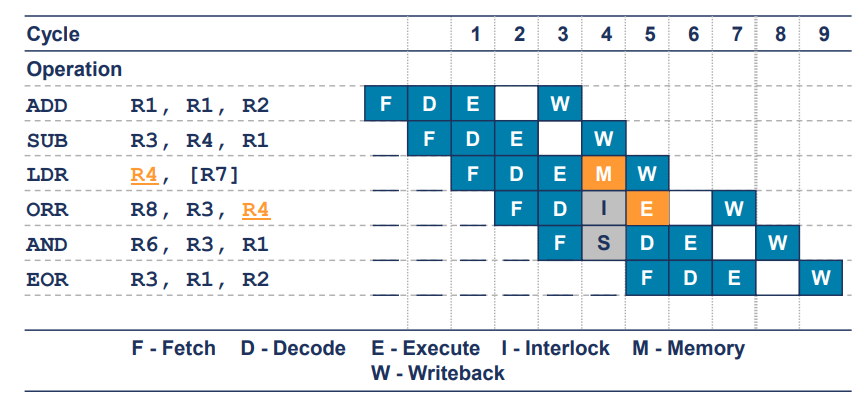
- 이 예시에는 6개의 명령어를 실행하는데 7개의 클럭 사이클이 소요
- 이는 cpi가 1.2임을 의미
- LDR 명령어 바로 뒤에 동일한 레지스터를 사용하는 데이터 연산이 오는 경우 인터록(interlock)이 발생
- 인터록은 앞선 명령어의 결과가 필요한 후속 명령어가 기다려야 하는 상황을 의미
- 즉, LDR 명령어가 데이터를 메모리에서 로드하는 동안, 그 데이터를 사용하는 다음 명령어는 해당 데이터가 준비될 때까지 대기해야 하므로 사이클이 추가로 필요하게 됨.
LDM Stall
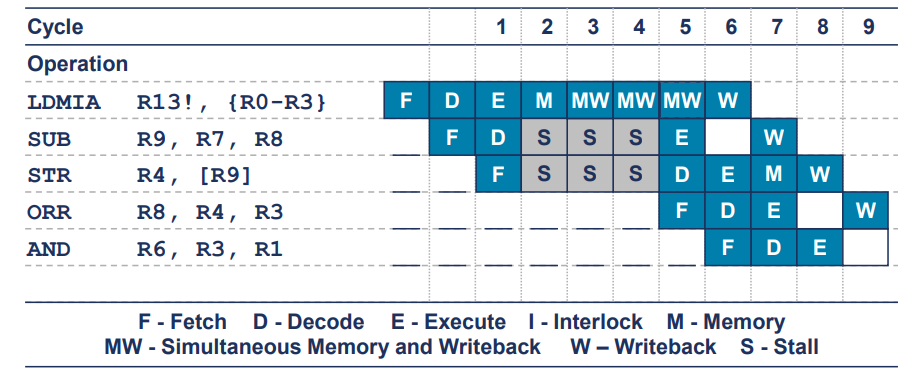
- 5개의 명령어를 실행하는 데 8개의 클럭 사이클이 소요
- CPI가 1.6임을 의미
- LDM(Load Multiple)명령어 실행 중에는 메모리 접근과 레지스터에 값을 쓰는 과정이 병렬로 이뤄짐
- 이는 메모리에서 여러 데이터를 읽어오는 동안 동시에 그 데이터를 레지스터에 쓰는 작업이 진행됨을 의미
- 이렇게 병렬로 작업을 처리함으로써 성능을 최적화하려고 함.
Branching
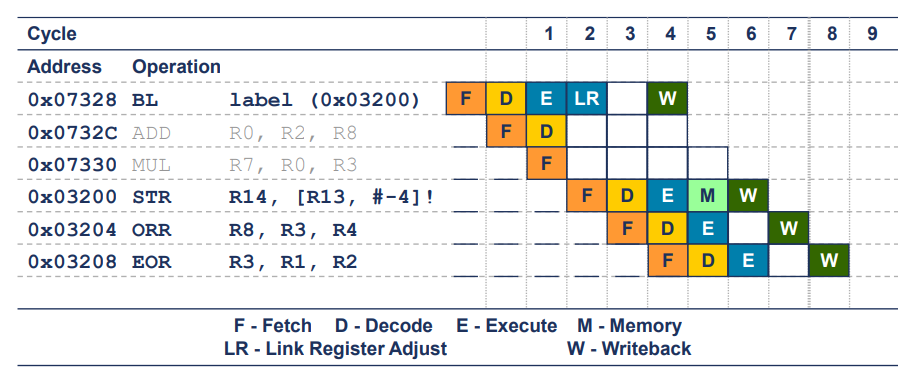
- 분기 명령어는 3개의 사이클 동안 실행
- 파이프라인의 명령어 가져오기(fetch)단계와 해독(decode)단계만이 flush(플러시) 됨.
- 이는 분기 명령어가 실행될 때, 잘못된 경로로 가져온 명령어들을 제거하기 위해 파이프라인의 초기 두 단계를 비우는 작업이 이루어짐을 의미
- 그러나 실행(execute)단계 이후의 단계는 영향을 받지 않음.
Interrupts
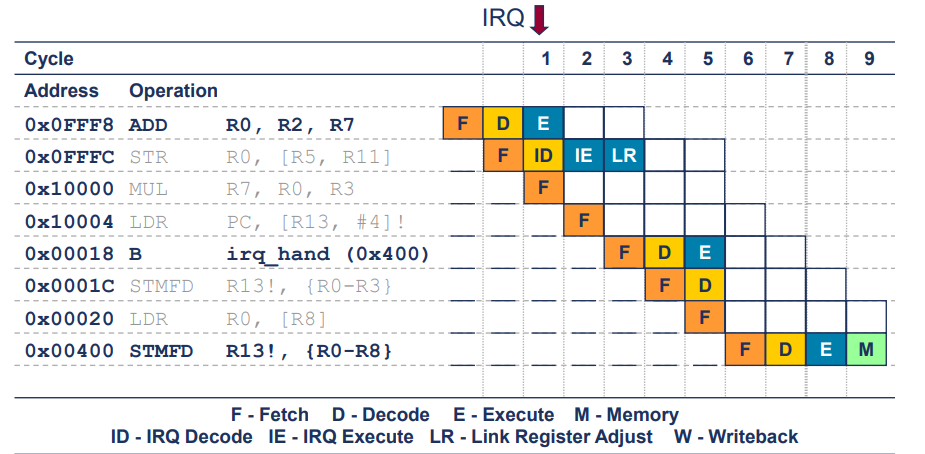
- 코어는 사이클 1에서 인터럽트 진입 시퀀스를 시작함
- 현재 실행 중인 명령어는 실행을 완료
▶ Arm10 Family
Arm10E Processor Core
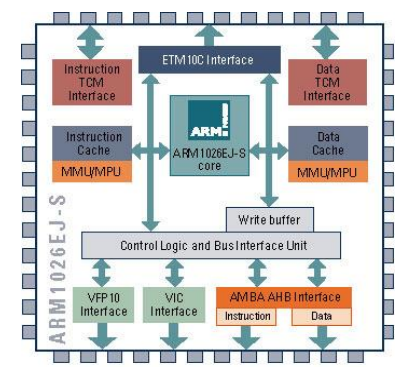
ARM1026EJ-S
- 구성 가능한 캐시와 TCM (태스크 캐시 메모리)를 지원
- MMU (메모리 관리 유닛)와 MPU (메모리 보호 유닛)를 지원
- 64비트 AHB 메모리 인터페이스 2개를 가짐
- Jazelle 기술을 포함함.
Architecture v5TE
- ARM 아키텍처 버전 v5TE를 따름
6-stage pipeline
- 6단계 파이프라인을 사용
- CPI (Cycles Per Instruction)는 약 1.3
64-bit memory interfaces
- 64비트 메모리 인터페이스를 가짐
Static branch prediction
- 정적 분기 예측을 지원
“Hit under miss” support in caches
- 캐시에서 "Hit under miss"를 지원
- 이는 캐시 미스가 발생해도 캐시 히트를 처리할 수 있는 기능을 의미
Non-blocking execution unit
- 비차단 실행 유닛을 가짐
- 하나의 명령어가 완료될 때까지 다른 명령어가 대기하지 않고 실행될 수 있음을 의미
64 bits per cycle LDM / STM operations
- LDM (Load Multiple) 및 STM (Store Multiple) 명령어가 사이클당 64비트를 처리
EmbeddedICE Logic RT-II
- EmbeddedICE Logic RT-II를 지원
- 디버깅을 위한 하드웨어 로직
Arm10 vs Arm9 Pipeline
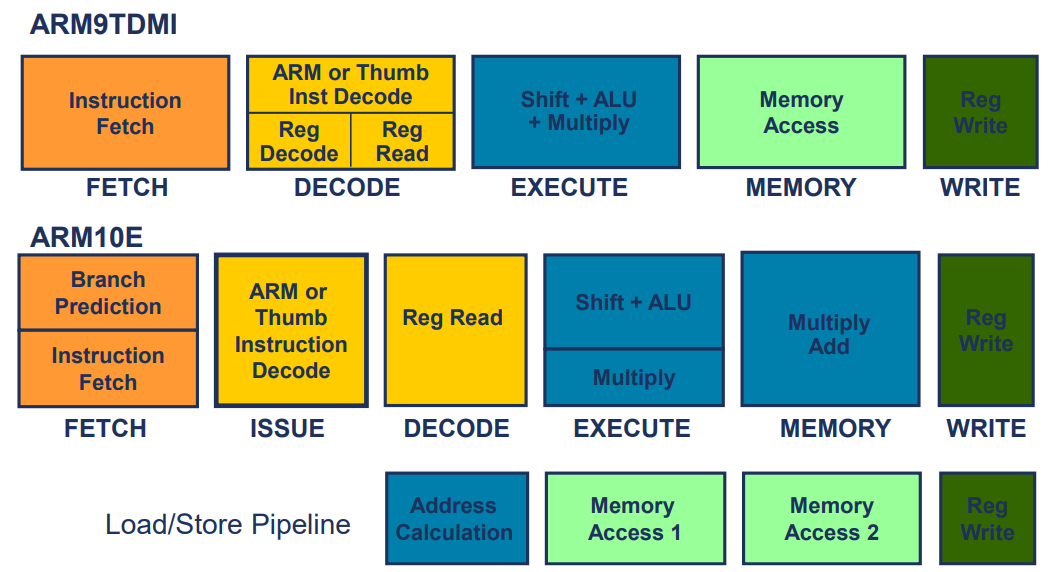
Branching
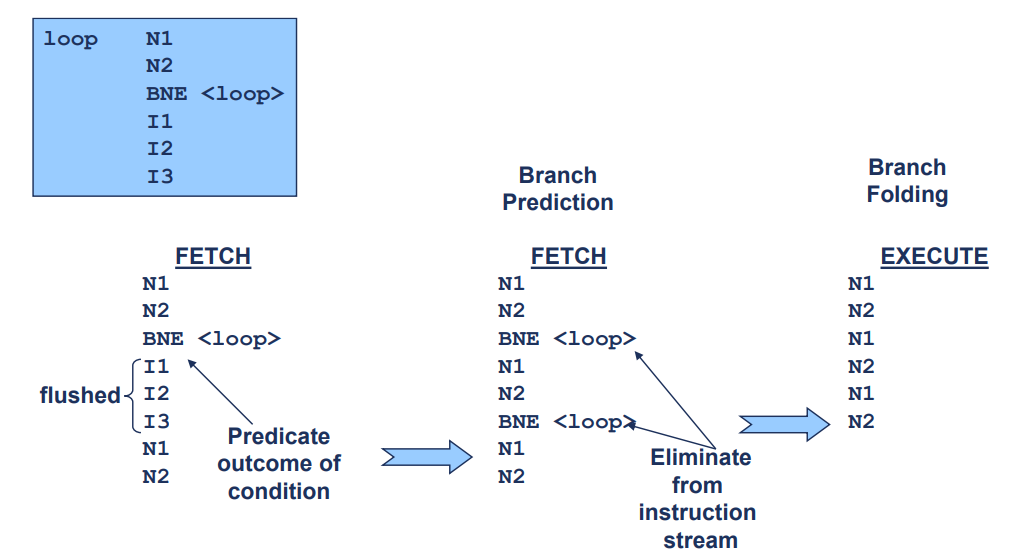
Static Branch Prediction(정적 분기 예측)
- 프로그램 실행 중 분기 명령어의 결과를 예측하여 다음 실행할 명령어를 미리 결정하는 기술
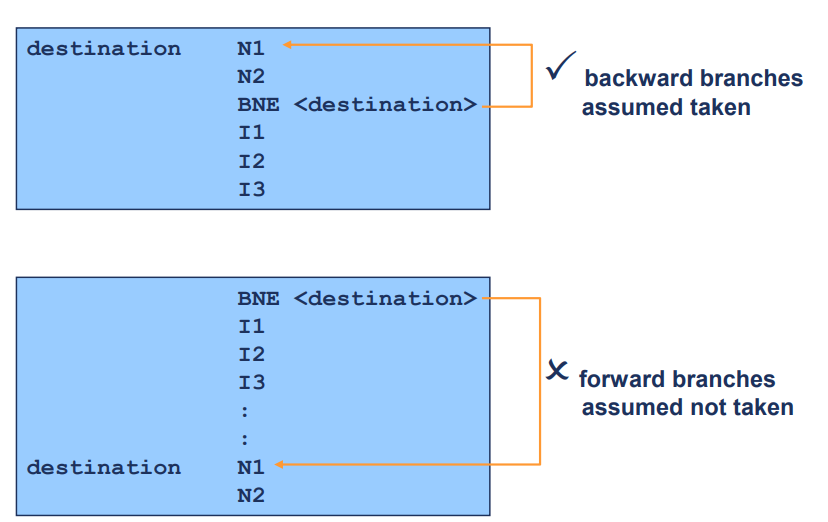
뒤로 가는 분기(Backward Branches)
Assumed taken (실행될 것으로 가정)
- 뒤로 가는 분기는 주로 루프에서 사용
- 프로그램 흐름이 반복적으로 동일한 코드 블록을 여러 번 실행할 때 발생
- 정적 분기 예측에서는 이러한 뒤로 가는 분기를 실행될 것으로 가정하여 예측
예를 들어, 루프의 끝에서 처음으로 돌아가는 분기 명령어는 계속 실행될 것으로 가정되어 루프가 끝날 때까지 계속 반복
Forward Branches (앞으로 가는 분기)
Assumed not taken (실행되지 않을 것으로 가정)
- 앞으로 가는 분기는 주로 조건문에서 사용
- 특정 조건이 만족될 때 프로그램 흐름을 다른 코드 블록으로 이동시킴.
- 정적 분기 예측에서는 이러한 앞으로 가는 분기를 실행되지 않을 것으로 가정하여 예측
- 예를 들어, 조건문에서 특정 조건이 만족되지 않는 경우 다음 명령어를 계속 실행하는 것으로 가정
- 이러한 정적 분기 예측 방식은 간단하고 하드웨어 구현이 용이하지만, 분기 예측이 항상 정확한 것은 아님.
- 분기 예측이 틀릴 경우 파이프라인 플러시와 같은 오버헤드가 발생할 수 있음
- 그럼에도 불구하고, 많은 경우에서 유용하게 사용되어 프로그램의 실행 성능을 향상시킬 수 있음.
- 분기 명령어의 실행 시간은 파이프라인이 길어짐에 따라 증가함.
: ARM 10코어에서 분기 명령어는 4사이클이 소요(분기 예측이 없는 경우)
: 이는 실행 단계 이전에 3개의 파이프라인 단계가 존재하기 때문
정적 분기 예측
-
PC-상대 분기만 예측 가능
-
이는 실행 단계 이전에 대상 주소를 미리 계산할 수 있기 때문
-
조건부 앞으로 가는 분기는 실행되지 않음으로 예측됨.
일반적으로 앞으로 가는 분기는 조건문에서 사용됩니다. 조건이 충족되지 않으면 현재 실행 중인 코드의 다음 명령어로 계속 진행하게 됩니다. 따라서, 정적 분기 예측에서는 이런 분기 명령어가 조건을 만족하지 않을 것으로 예상하고, 분기하지 않고 다음 명령어를 계속 실행하는 것으로 가정합니다.
-
조건부 뒤로 가는 분기는 실행됨으로 예측
: 프리페치 버퍼에 충분한 명령어가 있는 경우, 예측된 분기 명령어는 명령어 스트림에서 완전히 접혀질(folded) 수 있음.뒤로 가는 분기는 주로 반복문에서 사용됩니다. 루프의 끝에서 루프의 처음으로 돌아가는 형태입니다. 대부분의 경우, 반복문은 여러 번 실행되므로, 정적 분기 예측에서는 이런 분기 명령어가 조건을 만족할 것으로 예상하고, 분기하여 루프의 처음으로 돌아가는 것으로 가정합니다.
Sequential Code Execution
fetch단계는 매 사이클마다 명령어 캐시에서 두 개의 32bit 명령어를 가져올 수 있음- 이는 명령어 가져오기(fetch)단계가 한 사이클 동안 두 개의 32bit 명령어를 동시에 가져올 수 있는 능력을 가지고 있음을 의미
- 이는 명령어 처리 속도를 높여 파이프 라인의 효율성을 증가시킬 수 있음.
앞으로 가는 분기
올바르게 "실행되지 않음"으로 예측됨
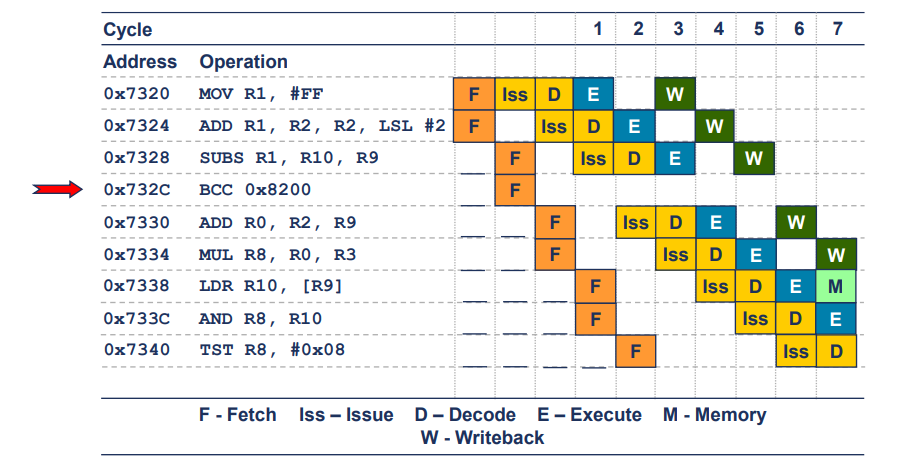
- 앞으로 가는 분기가 완전히 해결되어 파이프라인에서 제거됨.
- 이 예시에서는 8개의 명령어를 실행하는 데 7개의 사이클이 소요
- 즉, 정적 분기 예측이 앞으로 가는 분기를 실행되지 않음으로 올바르게 예측했기 떄문에, 해당 분기가 파이프라인에서 효율적으로 제거되어 성능이 최적화된 상태를 설명
bbc(branch if carry clear)
: 조건 분기 명령어
: cpu의 상태 레지스터에서 특정 비트가 설정되지 않은 상태를 충족하지 않으면 분기를 수행하지 않음.
Branch Misprediction

- 앞으로 가는 분기가 예측된대로 "실행되지 않음"으로 예측되었지만, 실제로는 실행되었음
: 이 경우 앞으로 가는 분기 명령어가 정적 분기 예측에서 "실행되지 않음"으로 예측되었지만, 프로그램 실행 중 실제로는 해당 조건이 만족되어 분기가 발생함 - 이러한 잘못된 에측으로 5cycle이 발생함.
- 분기 예측이 잘못되었을 경우, cpu는 예측이 틀렸음을 인식하고 실제 분기 목적지로의 점프를 조정해야 함.
- 이 과정에서 추가적인 시간이 소요되며, 이 경우에는 5cycle의 패널티가 발생하게 됨.
Return Stack
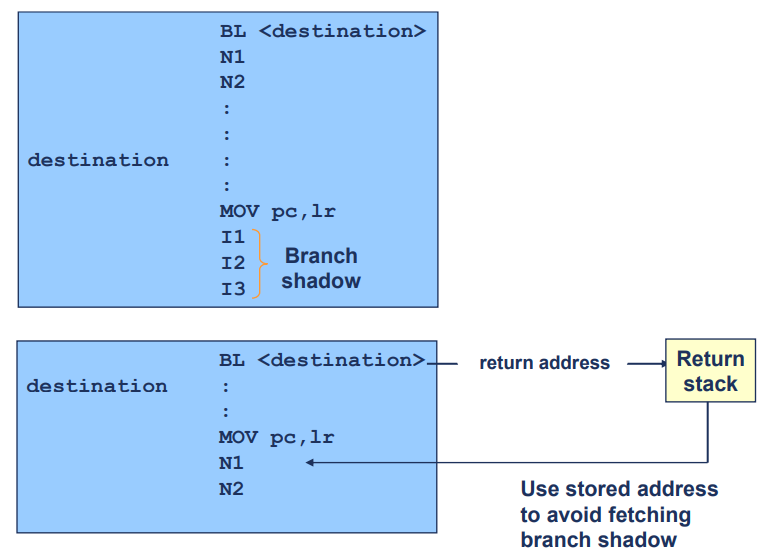
- 주로 프로세서의 분기 예측 매커니즘에서 사용
- 함수 호출과 같은 분기 명령어의 예측 정확성을 높이기 위해 사용
- Return Stack의 주요 목적은 함수 호출 후 복귀 주소를 효율적으로 관리하여 분기 예측 오류를 줄이고, 성능을 향상 시키는 것
BL<destination>
: 함수 호출 명령어
: 현재 명령어의 다음 주소가 반환 주소로 LR(링크 레지스터)에 저장
: 동시에, 이 반환 주소는 Return Stack에 푸시- 함수 본문 실행
: 함수의 본문이 실행되며 명령어 순차 처리 시작
: 이 과정에서 branch shadow(브랜치 섀도우) 영역에 해당하는 명령어들은 예측의 어려움으로 인해 성능에 영향을 줄 수 있음 - 함수 종료
: 함수가 끝나면MOV pc, lr명령어를 통해 링크 레지스터(LR)에 저장된 반환 주소로 복귀
: 이때, Return Stack에 저장된 반환 주소를 사용하여 복귀.
: 이를 통해 브랜치 섀도우 영역을 피하고 정확한 반환 주소로 복귀하게 됨. - Return Stack의 장점
- 함수 호출과 복귀 시, Return Stack을 사용하면 링크 레지스터(LR)에 저장된 반환 주소를 예측 없이 바로 사용할 수 있음
- 이는 브랜치 섀도우에서 발생할 수 있는 성능 저하를 방지하고, 보다 빠르고 정확한 함수 복귀를 가능하게 함.
Arm10 Return Stack
- 프로시저에서의 복귀 속도를 높이기 위해 사용됨
: 프리페치 유닛은 최근의 반환 주소를 '기억'함
: 반환 스택은 깊이가 하나임
: 즉, 반환 스택은 단 하나의 반환 주소를 저장 가능
: 반환 상태(arm/thumb)도 저장 - bl및 blx 명령어는 반환 주소를 반환 스택에 저장하게 함.
- bx lr및 mov pc, lr 반환 명령어는 저장된 반환 주소를 사용하여 예측됨.
: 예측된 반환 주소나 상태가 실제 사용된 것과 일치하지 않으면 파이프라인이 플러시됨.
▶ Arm11 Family
Arm Architecture v6 Overview
-
멀티미디어 성능 개선
- 미디어 처리 확장 (Media processing extensions): 새로운 SIMD(Single Instruction, Multiple Data) 명령어들을 포함하여 멀티미디어 처리 성능을 향상시킴.
- 2배 빠른 MPEG4 인코딩/디코딩: MPEG4 비디오 인코딩 및 디코딩 속도를 2배 빠르게 함.
- 더 빠른 오디오 DSP: 오디오 디지털 신호 처리(DSP) 성능을 향상시킴.
-
실시간 성능 개선
- 예외/인터럽트 처리 속도 개선: 예외 및 인터럽트 처리 속도를 빠르게 함.
- 벡터 인터럽트 컨트롤러 지원: 벡터화된 인터럽트 컨트롤러를 지원함.
- 줄어든 인터럽트 지연 모드: 인터럽트 지연을 줄이기 위한 새로운 스택 및 모드 변경 명령어 제공.
- 핸들러 진입/진출 오버헤드 감소를 위한 새로운 스택 및 모드 변경 명령어: 핸들러(예: 인터럽트 핸들러) 진입 및 진출 시 오버헤드를 줄이기 위한 새로운 명령어를 제공함.
-
기타 개선 사항
- 비-ARM 프로세서와의 데이터 공유 개선: ARM 프로세서와 다른 프로세서 간의 데이터 공유 기능을 향상시킴.
- 비-ARM 프로세서에서의 응용 프로그램 이식성 개선: ARM이 아닌 다른 프로세서에서 개발된 응용 프로그램의 이식성을 개선함.
- 혼합 엔디언 시스템 지원: 믹스 엔디언 시스템에서의 지원을 추가함.
- 비정렬 데이터 접근 지원: 정렬되지 않은 데이터 접근을 지원함.
Arm1136J(F)-S Processor Core
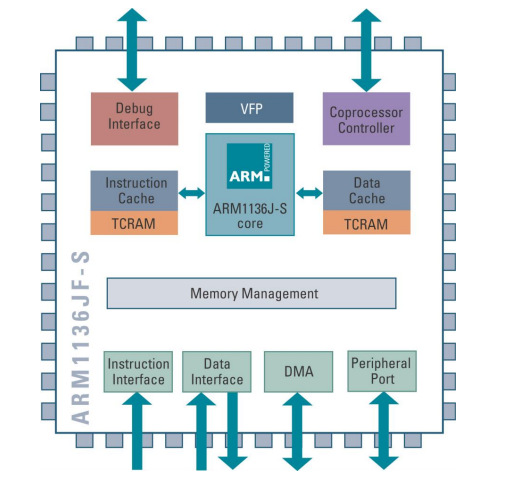
ARM1136JF-S (pictured)
- 아키텍처 v6: ARM v6 아키텍처를 따름.
- 8단계 파이프라인: 명령어를 처리하는 파이프라인이 8개의 단계로 구성됨.
- 정적 및 동적 분기 예측 (Static and dynamic branch prediction): 분기 명령어를 예측하여 성능을 최적화함.
- 리턴 스택 (Return stack): 서브루틴 호출과 복귀를 효율적으로 관리하기 위한 스택 제공.
- 물리적으로 태깅된 4-64k 캐시 (Physically-tagged 4-64k caches): 캐시 메모리가 물리적인 주소로 태깅되어 있음.
- 내부 구성 가능한 TCMs (Internal configurable TCMs): 프로세서 내부에 구성 가능한 Tightly Coupled Memory를 지원함.
- 메모리 관리 유닛 (Memory management unit, MMU): 메모리 접근을 관리하고 가상 주소를 물리 주소로 변환하는 기능 제공.
- 네 개의 AHB 메모리 포트 (Four AHB memory ports): 다중 메모리 접근을 지원하기 위한 AHB 버스 기반의 메모리 포트가 네 개 제공됨.
- 자젤 기술 (Jazelle technology): 자바 바이트코드를 직접 실행할 수 있는 기술 지원.
- 통합 VFP 코프로세서 (Integrated VFP coprocessor): 부동 소수점 연산을 가속화하기 위한 VFP(Virtual Floating Point) 코프로세서 통합.
ARM1136J-S
- ARM1136JF-S와 유사하지만 VFP가 없음: ARM1136JF-S와 비교하여 VFP 부동 소수점 코프로세서가 통합되어 있지 않음을 의미함.
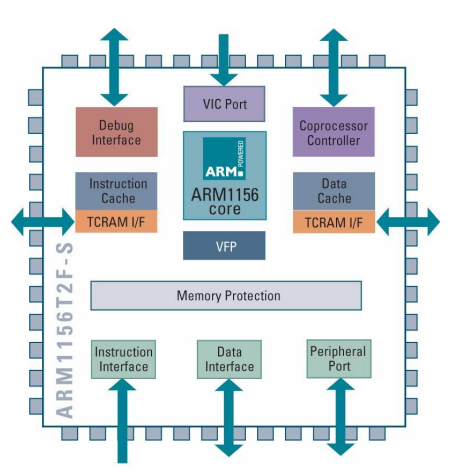
Arm1156T2(F)-S Processor Core
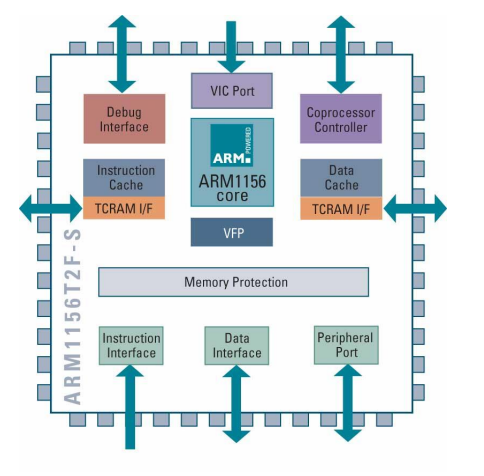
ARM1156T2F-S
- 아키텍처 v6T2: ARM v6T2 아키텍처를 따름.
- Thumb-2 전용 동작 지원 (Supports Thumb-2 only operation): Thumb-2 명령어 세트만을 지원함.
- 9단계 파이프라인: 명령어 처리를 위한 9개의 파이프라인 단계를 가짐.
- 정적 및 동적 분기 예측 (Static and dynamic branch prediction): 분기 명령어를 예측하여 처리 속도를 향상시킴.
- 리턴 스택 (Return stack): 서브루틴 호출과 복귀를 효율적으로 관리하기 위한 스택을 지원.
- 물리적으로 태깅된 4-64k 캐시 (Physically-tagged 4-64k caches): 캐시 메모리가 물리적인 주소로 태깅되어 있음.
- 구성 가능한 TCMs (Configurable TCMs): 프로세서 내부에 구성 가능한 Tightly Coupled Memory를 지원함.
- 메모리 보호 유닛 (Memory protection unit, MPU): 메모리 보호를 위한 유닛을 포함하여 시스템 보안을 강화함.
- 세 개의 AXI 메모리 포트 (Three AXI memory ports): 다중 메모리 접근을 지원하기 위한 AXI 버스 기반의 메모리 포트가 세 개 제공됨.
- 통합 VFP 코프로세서 (Integrated VFP coprocessor): 부동 소수점 연산을 가속화하기 위한 VFP(Virtual Floating Point) 코프로세서가 통합되어 있음.
ARM1156T2-S
- ARM1156T2F-S와 유사하지만 VFP가 없음: ARM1156T2F-S와 비교하여 VFP 부동 소수점 코프로세서가 통합되어 있지 않음을 의미함.
Arm1176JZ(F)-S Processor Core
ARM1176JF-S
- 아키텍처 v6Z: ARM v6Z 아키텍처를 따름.
- TrustZone 기술 (TrustZone technology): 보안 관리를 위한 TrustZone 기술을 지원함.
- 8단계 파이프라인: 명령어 처리를 위한 8개의 파이프라인 단계를 가짐.
- 정적 및 동적 분기 예측 (Static and dynamic branch prediction): 분기 명령어를 예측하여 처리 속도를 향상시킴.
- 리턴 스택 (Return stack): 서브루틴 호출과 복귀를 효율적으로 관리하기 위한 스택을 지원.
- 물리적으로 태깅된 4-64k 캐시 (Physically-tagged 4-64k caches): 캐시 메모리가 물리적인 주소로 태깅되어 있음.
- 내부 구성 가능한 TCMs (Internal configurable TCMs): 프로세서 내부에 구성 가능한 Tightly Coupled Memory를 지원함.
- 듀얼 TCMs 사용 가능 (Dual TCMs available): 두 개의 TCM을 동시에 사용할 수 있음.
- 메모리 관리 유닛 (Memory management unit, MMU): 메모리 접근을 관리하고 가상 주소를 물리 주소로 변환하는 기능 제공.
- 네 개의 AXI 메모리 포트 (Four AXI memory ports): 다중 메모리 접근을 지원하기 위한 AXI 버스 기반의 메모리 포트가 네 개 제공됨.
- 자젤 기술 (Jazelle technology): 자바 바이트코드를 직접 실행할 수 있는 기술 지원.
- 지능형 에너지 관리 (Intelligent Energy Management, IEM): 에너지 효율성을 높이기 위한 지능형 에너지 관리 기능 제공.
- 통합 VFP 코프로세서 (Integrated VFP coprocessor): 부동 소수점 연산을 가속화하기 위한 VFP(Virtual Floating Point) 코프로세서가 통합되어 있음.
ARM1176JZ-S
- ARM1176JF-S와 유사하지만 VFP가 없음: ARM1176JF-S와 비교하여 VFP 부동 소수점 코프로세서가 통합되어 있지 않음을 의미함.
TrustZone Computing
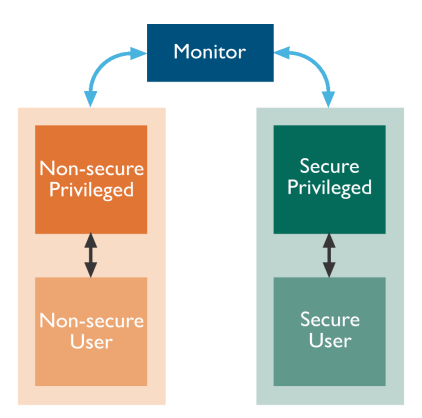
- Trust Zone 기술은 ARM 프로세서에서 안전하게 신뢰할 수 있는 프로그램과 데이터를 운영체제와 애플리케이션들로부터 격리시키기 위한 "병렬 세계(Pararell world)"를 추가함.
새로운 안전 모니터 모드(Secure Monitor Mode)
: 안전한 상태를 유지하기 위한 게이트 키퍼 역할을 수행하는 모니터 모드를 도입
: 이 모드는 안전한 코드와 데이터에 대한 접근을 관리
: 안전하지 않은 영역으로의 접근을 제한함CP15의 새로운 S비트
: 프로세서가 안전한 상태에서 실행 중인지를 나타내기 위해 CP15(System Control Coprocessor)에 새로운 S비트를 도입함.
: 이 비트는 현재 프로세서가 보안 상태인지를 외부에 알리는 데 사용외부 버스 접근 시 보안 상태 노출
: 메모리와 주변 장치들이 보안 관련 메모리 및 장치에 접근할 수 있도록 외부 버스 접근에서 보안 상태를 노출함.
: 이는 안전한 데이터와 코드에 대한 접근 제어를 강화하는 데 도움이 됨.비-안전 상태에서 디버깅 제한 기능
: 디버깅 접근을 비-안전한 상태에서만 가능하도록 제한할 수 있는 능력을 제공
: 이는 안전한 상태에서 실행 중인 코드와 데이터가 노출되지 않도록 보호하는 데 도움이 됨.
MPCore
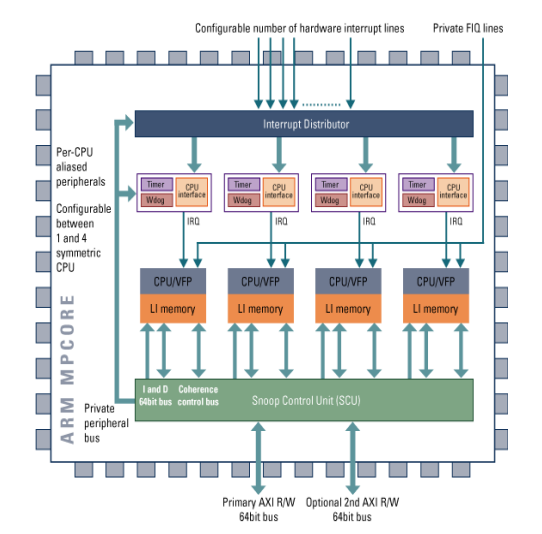
- 아키텍처 v6K
: ARM v6K 아키텍처를 기반으로 함. - 1 - 4 MP11 프로세서
: 최대 4개의 MP11 프로세서를 지원합니다. 각각의 프로세서는 관련된 타이머와 인터페이스를 포함할 수 있습니다. - VFP11 코프로세서 포함 여부 선택 가능
: VFP11 부동 소수점 코프로세서를 함께 사용할지 여부를 선택할 수 있습니다. - 구성 가능한 인터럽트 입력
: 0에서 244까지의 인터럽트 입력을 32씩의 스텝으로 구성할 수 있으며, 프로그래밍 가능한 방식으로 MP11 프로세서들에게 분배할 수 있습니다. - SMP 또는 AMP 지원
: SMP(대칭적 다중 처리) 또는 AMP(비대칭적 다중 처리) 구성을 지원합니다. - MESI 기반 데이터 캐시 일관성
: MESI 프로토콜을 기반으로 한 데이터 캐시 일관성을 제공하여 다중 코어 간 데이터 일관성을 유지합니다. - 레벨 2에 대한 1 또는 2개의 AXI 인터페이스: 레벨 2 캐시에 접근하기 위한 64비트 데이터 버스를 사용하는 1개 또는 2개의 AXI 인터페이스를 지원합니다.
- IEM 준비: 지능형 에너지 관리(IEM) 기능을 준비하여 에너지 효율성을 최적화할 수 있습니다.
- ETM을 사용한 프로그램 추적 (r1만 해당): 프로그램 추적을 위해 ETM(Embedded Trace Macrocell)을 사용할 수 있습니다 (r1 버전에서만 해당).
MPCore는 다중 코어 시스템에서의 성능 및 효율성을 높이기 위해 설계된 ARM 프로세서
Arm11 Pipeline Architecture
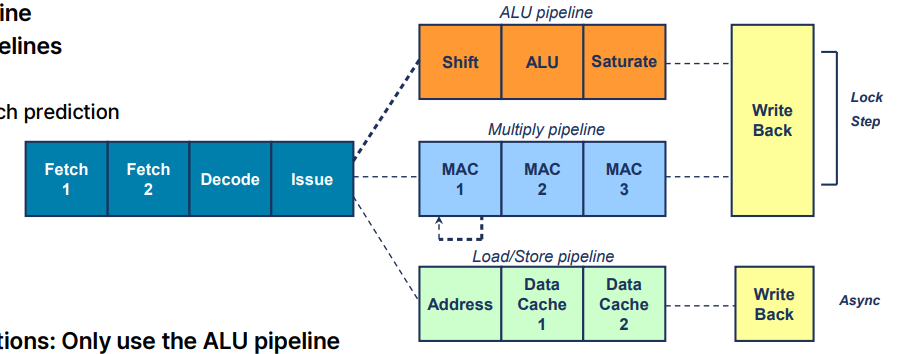
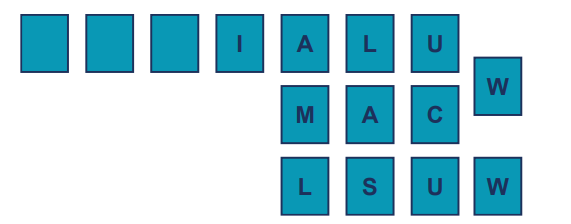
공통 프론트엔드 파이프라인 (Common front end pipeline)
: 명령어를 가져오고 초기 단계를 처리하는 파이프라인 부분.세 개의 별도 백엔드 파이프라인 (3 separate back end pipelines)
: 명령어의 실행과 결과 처리를 담당하는 별도의 세 개의 파이프라인 존재.페치 단계 (Fetch Stage):
1. 정적 및 동적 분기 예측 (Static and dynamic branch prediction)
: 분기 명령어를 예측하여 처리 성능을 최적화.
2. 분기 접기 (Branch folding)
: 분기 명령어를 최적화하여 불필요한 분기 명령어를 줄임.데이터 처리 명령어(Data processing instructions)
ALU 파이프라인만 사용
: 산술 논리 장치(ALU) 파이프라인만을 사용하여 데이터 처리를 수행곱셈 명령어 (Multiply instructions)
: 곱셈 파이프라인은 ALU 파이프라인과 함께 동작: ALU 파이프라인과 동시에 동작하여 곱셈 명령어를 처리
MAC1에서 여러 사이클 동안 부분 결과 생성
: 부분 곱셈 결과를 생성하기 위해 여러 사이클 동안 MAC1 단계에서 작업 가능
MAC2에서 부분 결과 누적
MAC3는 파이프라인과 동기화하여 결과를 처리로드/스토어 명령어(Load/Store instructions)
ALU 및 로드/스토어 파이프라인 사용
: 로드 및 스토어 명령어 처리에 ALU와 로드/스토어 파이프라인을 모두 사용
ALU 파이프라인을 사용해 결과 기본 레지스터 값 업데이트
: 결과 기본 레지스터 값을 업데이트하고 레지스터 뱅크에 기록하는 데 ALU 파이프라인을 사용
1 사이클당 2개의 레지스터 전송
: 로드/스토어 명령어는 각 사이클마다 2개의 레지스터를 전송 가능.
Dynamic Branch Prediction(동적 분기 예측)
정적 분기 예측(Static Branch Prediction)
- 예측 결정이 고정
- ARM10 및 ARM11에서 분기 방향에 기반함.
: ARM 10과 ARM 11 프로세서에서는 분기 방향을 기준으로 정적으로 예측을 수행 - 분기 방향에 따라 결정
: 분기 명령어의 방향(분기를 취할지 말지)를 기준으로 하여 예측을 수행
동적 분기 예측(Dynamic Branch Prediction)
- 최근 분기 활동의 기록을 기반으로 예측
: 분기 예측은 최근의 분기 활동 기록을 바탕으로 수행 - 네 가지 상태로 예측
- 약하게 취해짐(Weakly taken)
: 분기가 잘못 예측될 가능성이 있는 상태로, 대개 분기가 발생할 가능성이 낮은 상황에서 발생 - 강하게 취해짐(Strongly taken)
: 분기가 발생할 가능성이 높은 상태로, 대개 분기가 발생할 가능성이 높은 상황에서 발생 - 약하게 취하지 않음(Weakly not taken)
: 분기가 발생하지 않을 가능성이 높은 상태로, 대개 분기가 발생하지 않을 상황에서 발생 - 강하게 취하지 않음(Strongly not taken)
: 분기가 발생하지 않을 가능성이 높은 상태로, 대개 분기가 발생하지 않을 가능서잉 높은 상황에서 발생.
- 정적 예측은 단순하고 빠르지만 정확도가 낮을 수 있음
- 동적 예측은 분기 활동의 패턴을 분석하여 더 높은 정확도로 예측을 수행할 수 있지만, 추가적인 하드웨어 지원이 필요할 수 있음.
Prediction History State Machine
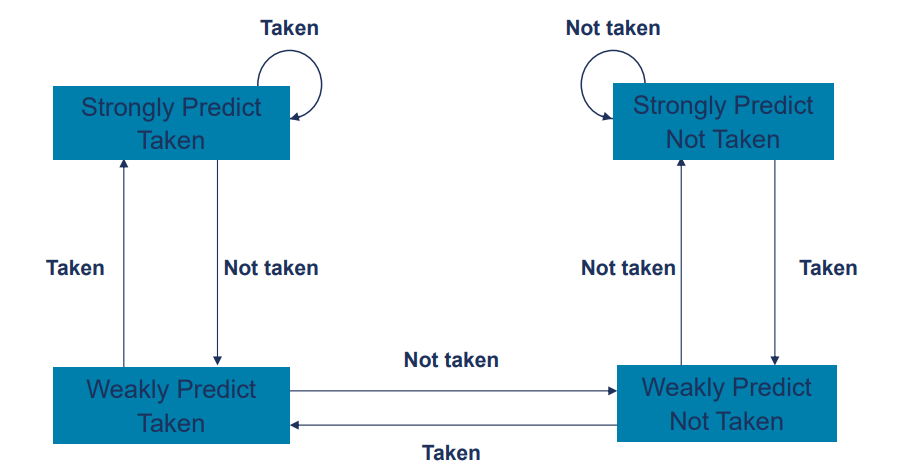
- 4 상태 예측 기록은 중첩된 루프를 더 효율적으로 처리할 수 있게 함.
: 중첩된 루프는 하나의 루프가 다른 루프 내부에 포함되어 있는 구조를 말하며, 프로그램에서 자주 발생하는 패턴 중 하나임.
Branch History
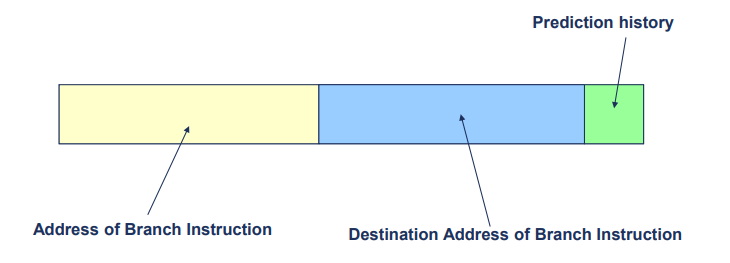
- 저장 분기 명령어는 두 가지 주소를 기록함
1. 분기 명령어 주소(Branch instruction address)
: 분기 명령어가 실행된 메모리 상의 주소를 저장
2. 목적지 주소(Destination address)
: 분기가 이동하려는 목적지 주소를 저장
- 예측 기록 상태(prediction history state)는 다음 실행될 주소가 분기에서의 연속된 주소인지 아니면 분기 목적지에서의 주소인지를 결정
1. 연속된 주소(Sequential address)
: 분기 명령어 다음에 실행될 주소가 분기 명령어의 다음 주소일 경우
2. 목적지 주소(Destination address)
: 분기 명령어가 분기한 목적지 주소로 실행될
Arm11 Return Stack
- 리턴 스택은 최대 3개의 항목을 저장할 수 있음
: 이는 함수 호출 시 사용되는 리턴 주소를 저장하는 데 사용됨. - BL(Branch with Link) 및 BLX(Branch with Link and Exchange) 명령어는 리턴 주소를 리턴 스택에 저장
: 이는 함수가 실행을 마친 후 복귀할 주소를 기록하는 역할을 함. - BX LR, LDM sp1,{...,pc}, LDR pc,[sp...] 반환 명령어는 저장된 리턴 주소를 사용하여 예측됨.
: 이는 프로세서가 다음에 실행될 명령어의 주소를 예측하는 데 중요한 역할을 함. - 예측된 리턴 주소나 상태가 실제 사용된 것과 일치하지 않으면 파이프라인이 비워짐.
: 이는 잘못된 예측이 파이프라인에서 발생할 경우 실행 흐름의 일관성을 유지하기 위해 필요한 조치
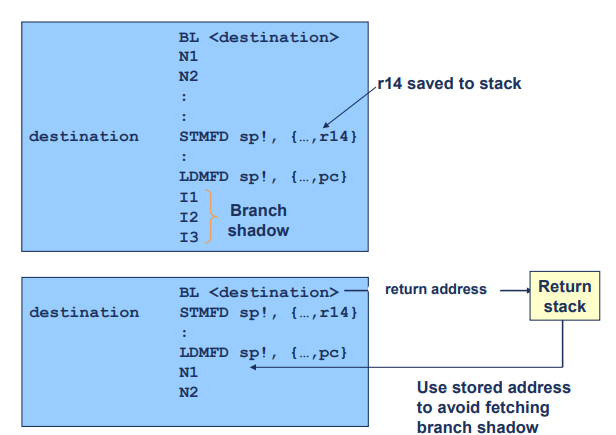
- 위쪽 그림:
BL <destination>명령어가 실행됩니다. 이 명령어는 함수 호출을 의미하며, 현재 주소를 링크 레지스터(r14)에 저장합니다.- 이후
STMFD sp!, {..., r14}명령어가 실행되면서 링크 레지스터(r14)의 값이 스택에 저장됩니다.- 함수 본문이 실행되면서 여러 명령어가 수행됩니다. 여기서
I1, I2, I3는 브랜치 섀도우(Branch Shadow) 영역으로, 이 명령어들은 분기 예측이 어려워 성능에 영향을 미칠 수 있습니다.- 함수가 끝나면
LDMFD sp!, {..., pc}명령어가 실행되어 스택에서 반환 주소를 로드하여 프로그램 카운터(pc)에 저장, 원래 호출 위치로 복귀합니다.
- 아래쪽 그림:
BL <destination>명령어가 실행되면서 반환 주소가 Return Stack에 저장됩니다.- 이후
STMFD sp!, {..., r14}명령어가 실행되면서 링크 레지스터(r14)의 값이 스택에 저장됩니다.- 함수 본문이 실행되고, 함수가 종료되면
LDMFD sp!, {..., pc}명령어가 실행되어 Return Stack에서 반환 주소를 사용하여 원래 호출 위치로 복귀합니다. 이를 통해 브랜치 섀도우 영역을 피하고 성능을 향상시킵니다.
Program Order Execution(프로그램 명령어 실행)
- ALU(산술 논리 장치)와 MAC(곱셈 누산 장치) 파이프라인은 'lockstep' 방식으로 동작
- 이는 이들 파이프라인이 한 번에 하나의 명령어만을 처리하며, 명령어가 한 번에 하나씩 순차적으로 실행된다는 것을 의미
- LSU(로드 및 저장 유닛) 파이프라인은 'out-of-order' 실행을 허용
- 이는 메모리 접근 명령어들이 다른 명령어들보다 먼저 실행될 수 있다는 것을 의미
- LSU 파이프라인은 다음과 같은 경우에 out-of-order 실행을 지원
: 메모리 접근 명령어와 ALU/MAC 작업 사이에서
: 메모리 접근 사이에서 (캐시의 Hit-Under-Miss 동작 때문에)
예시
LDM {r6-r10}, ... ADD r2, r2, #1
- 여기서 LDM 명령어는 메모리에서 데이터를 로드하는 명령어
- ADD 명령어는 ALU를 사용하여 레지스터 값에 1을 더하는 명령어
- LSU 파이프라인의 특성 때문에 ADD 명령어는 LDM 명령어보다 먼저 완료될 수 있음.
EX.
Out-of-order Execution
: CPU가 LSU(로드 및 저장 유닛) 파이프라인에서 메모리 접근 명령어(LDM)를 받았지만, 이 명령어가 메모리 접근을 기다리는 동안 ALU 파이프라인에서 ADD 명령어를 실행할 수 있습니다. 이 경우 ADD 명령어는 LDM 명령어보다 먼저 ALU 연산을 완료할 수 있습니다.
Pipeline Stalls 및 예측 실패
: 예를 들어, LDM 명령어의 메모리 접근이 예상보다 오래 걸릴 경우 LSU 파이프라인에서 stall이 발생할 수 있습니다. 이러한 상황에서 ALU 파이프라인은 LDM 명령어의 완료를 기다리지 않고 다른 명령어(예를 들어 ADD)를 처리할 수 있습니다.
Cache Miss 처리
: 만약 LDM 명령어가 메모리 캐시에서 데이터를 가져오는 중에 Cache Miss가 발생하여 실제 메모리에서 데이터를 로드해야 할 경우, LSU 파이프라인은 해당 데이터를 기다리는 동안 ALU 파이프라인에서 다음 명령어(예를 들어 ADD)를 먼저 실행할 수 있습니다.
▶ Cortex Family
Arm Cortex-A8 Processor Core
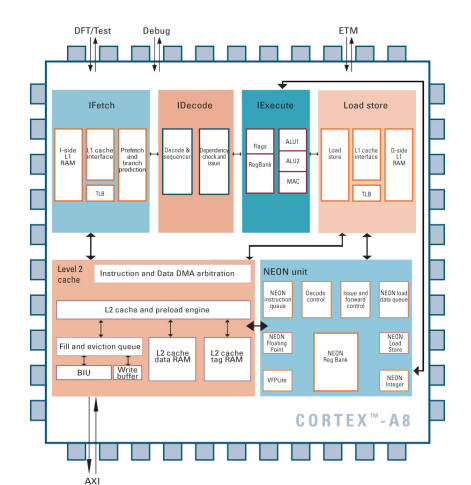
아키텍처 v7-A
: Arm의 Cortex-A8 프로세서는 ARMv7-A 아키텍처를 기반으로 함.더 긴 파이프라인(최대 14 단계)
: Cortex-A8는 최대 14 단계의 파이프라인을 가지고 있음.
: 이는 명령어를 처리하는 데 필요한 여러 단계의 과정을 의미함.듀얼 이슈, 슈퍼스칼라 실행
: 이 프로세서는 두 개의 명령어를 동시에 실행할 수 있는 슈퍼스칼라 구조를 가지고 있음.고급 동적 분기 예측
: Cortex-A8는 분기 명령어를 예측하여 성능을 향상시키는 고급 동적 분기 예측 기능을 제공함.NEON을 위한 별도 파이프라인
: Cortex-A8에는 NEON 미디어 프로세싱을 위한 별도의 파이프라인이 있음.
: NEON은 SIMD(Single Instruction, Multiple Data) 명령어를 지원하여 멀티미디어와 디지털 신호 처리 작업을 가속화함.설정 가능한 레벨 1 캐시
: Cortex-A8는 L1 캐시를 사용하여 데이터와 명령어를 빠르게 액세스할 수 있으며, 이는 설정 가능한 구조를 가지고 있음.통합된 레벨 2 캐시
: L2 캐시는 통합된 구조를 가지고 있어 전체 시스템의 성능을 향상시키는 데 기여함.메모리 관리 장치 (MMU)
: MMU는 가상 주소를 물리 주소로 매핑하여 프로세스 간의 메모리 공간을 격리하고 메모리 보호를 제공함.AXI 인터페이스
: Cortex-A8는 AMBA AXI(Advanced eXtensible Interface) 버스 프로토콜을 지원하는 인터페이스를 가지고 있음.
: 이는 고성능 시스템에서 데이터 통신을 효율적으로 처리하는 데 도움을 줌.- 커스텀/합성 가능한 디자인
: Cortex-A8는 사용자가 필요에 따라 커스터마이징하거나 합성할 수 있는 디자인을 제공
: 이는 다양한 응용 분야에 맞춰 유연하게 사용할 수 있도록 함.
Neon Media Processor 특징
-
Single Instruction Multiple Data (SIMD) Media Processor
- SIMD 미디어 프로세서는 한 번의 명령어로 여러 데이터를 동시에 처리할 수 있는 구조
- 이는 동일한 연산을 여러 데이터에 대해 병렬로 수행하여 처리 속도를 향상시키는 데 유용
-
타겟
- NEON은 오디오 및 비디오 코덱, 이미지 및 음성 처리, 그래픽, 기저대역 처리 및 일반 신호 처리를 대상으로 함.
- 다양한 멀티미디어 및 신호 처리 응용에 적합
-
3개의 처리 파이프라인
- NEON은 세 가지 주요 처리 파이프라인을 가지고 있음.
- 정수/고정소수점 처리 파이프라인
- 단정밀도 부동소수점 처리 파이프라인
- IEEE 벡터 부동소수점 처리 파이프라인
- NEON은 세 가지 주요 처리 파이프라인을 가지고 있음.
-
간소화된 프로그래밍 모델
- NEON은 단일 명령어 스트림, 메모리의 한 뷰, 디버깅 및 추적을 간소화한 프로그래밍 모델을 제공함.
- ARM 프로세서는 제어 평면을 처리하고, NEON은 데이터 평면을 처리함.
-
효율적인 데이터 처리
- NEON은 사용 가능한 메모리 대역폭을 최대한 활용하여 효율적인 데이터 처리를 지원함.
- 데이터 배열 오버헤드를 제거하여 처리 속도를 향상시킴.
- 별도의 레지스터 파일에서 작업하여 데이터 처리 성능을 최적화함.
- SIMD 프레임워크는 컴파일러가 최적화하기에 용이하며, 효율적인 코드 생성을 지원함.
→ NEON 미디어 프로세서는 다양한 멀티미디어 및 신호 처리 작업을 위한 고성능 SIMD 기능을 제공하며, 이는 ARM 프로세서와 통합하여 복잡성을 줄이고 프로그래밍과 성능 최적화를 용이하게 함.
Cortex-A8 Integer Pipeline
- NEON 미디어 프로세서가 ARM Cortex-A 시리즈 프로세서와 별도로 독립적인 실행 파이프라인을 가지고 있음.
- 이는 NEON 명령어들이 ARM 코어의 다른 명령어들과는 별도의 경로를 통해 처리되며, NEON이 병렬로 작동할 수 있도록 설계되었다는 것
Arm Cortex-M3 Processor Core
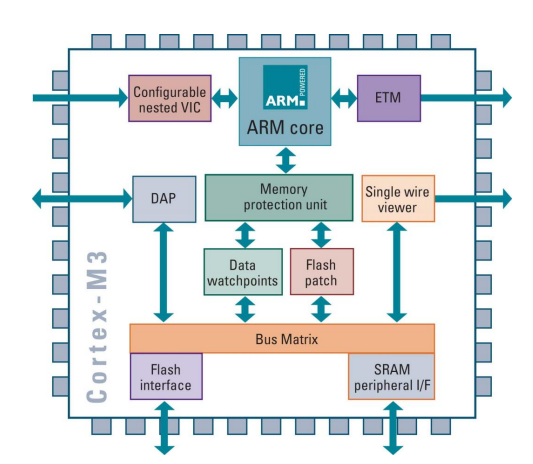
- 저전력 마이크로컨트롤러와 같은 임베디드 시스템에서 사용되며, 다른 ARM 아키텍처들과는 매우 다른 특성을 가짐.
-
Thumb-2만 지원
- ARM 아키텍처 v7-M은 Thumb-2 명령어 세트만 지원하며, 기존의 ARM 명령어를 지원하지 않음
- Thumb-2는 16비트와 32비트의 명령어를 혼합하여 사용하여 코드의 밀도를 높이고 성능을 향상시키는 데 기여함.
-
3단계 파이프라인
- 이 아키텍처는 3단계 파이프라인을 가지고 있음.
- 이는 명령어를 처리하기 위해 CPU가 거치는 단계들을 의미
- 비교적 간단한 파이프라인 구조로 빠른 명령어 실행을 가능하게 함.
-
정적 분기 예측
- 정적 분기 예측을 사용하여 명령어의 분기 실행 경로를 예측함.
- 이는 동적 분기 예측보다 단순하지만, 임베디드 시스템에서 신뢰할 수 있는 성능을 제공
-
고정된 메모리 맵
- 메모리 맵이 고정되어 있어, 임베디드 시스템 개발자가 메모리와 주변장치를 설계할 때 예측 가능한 환경을 제공
-
AHB-Lite 외부 메모리 인터페이스
- AHB-Lite는 ARM의 Advanced High-performance Bus Lite 인터페이스로, 외부 메모리와의 데이터 교환을 담당함.
- 이 인터페이스는 저전력 임베디드 시스템에서 효율적인 데이터 전송을 지원
-
통합 인터럽트 컨트롤러
- 내장된 인터럽트 컨트롤러는 프로그래머가 설정 가능한 인터럽트 우선순위를 지원하여 시스템의 반응성을 개선
- 또한, 비마스킹 가능한 인터럽트도 지원
-
시리얼 와이어 디버그 또는 JTAG
- 디버깅을 위한 시리얼 와이어 디버그나 JTAG 인터페이스를 선택적으로 지원
- 이를 통해 개발자는 소프트웨어 및 하드웨어 디버깅을 수행할 수 있음.
-
플래시 패치 지원
- 플래시 패치 기능을 지원하여 소프트웨어 업데이트나 수정을 효율적으로 관리하고 적용할 수 있음.
-
옵션 메모리 보호 장치 (MPU)
- 선택적으로 사용할 수 있는 메모리 보호 장치(MPU)가 포함되어 있어, 메모리 접근 권한을 관리하고 시스템의 안정성을 높이는 데 도움을 줌.
-
코프로세서 인터페이스 없음
- 이 아키텍처는 별도의 코프로세서 인터페이스를 지원하지 않음
- 이는 일반적인 임베디드 시스템에서는 필요하지 않을 수 있음.
ARM 아키텍처 v7-M은 저전력 및 리소스 제한 환경에서 동작하는 임베디드 시스템용으로 설계되었으며, 간결한 구조와 효율적인 기능을 제공하여 여러 산업 분야에서 널리 사용.
M profile cores are different from other Arm Cores
- ARM의 저전력 임베디드 시스템을 위해 설계되어 다른 ARM 코어들과는 매우 다른 특성을 가짐.
Thumb-2 명령어 세트만 지원
ARMv7M 아키텍처는 Thumb-2 명령어 세트만을 지원하며, 기존의 ARM 명령어 세트를 지원하지 않습니다. Thumb-2는 16비트와 32비트의 명령어를 혼합하여 코드의 밀도를 높이고 성능을 개선하는 데 기여합니다.
CPSR 없음 - 다른 상태 레지스터 세트 사용
ARMv7M에서는 CPSR(현재 프로그램 상태 레지스터) 대신 다른 종류의 상태 레지스터 세트를 사용합니다. 이는 프로세서 상태와 관련된 정보를 다르게 저장하고 관리합니다.
다른 모드
ARMv7M 아키텍처는 Thread 모드와 Handler 모드만 지원합니다. 이는 저전력 임베디드 시스템에서의 다양한 실행 환경을 처리하기 위한 목적으로 설계되었습니다.
다른 예외 처리 모델
예외 처리 모델이 다르며, 벡터 테이블이 주소를 가리키는 형태로 구성됩니다. 이는 인터럽트가 발생할 때 자동으로 상태를 저장하고 복원하여 처리의 효율성을 높입니다.
예외 처리기(exception handler)는 완전히 C 언어로 프로그래밍할 수 있습니다. 이는 소프트웨어 개발의 편의성을 증가시키고, 복잡성을 줄입니다.
코프로세서 15 없음 (시스템 제어 코프로세서)
ARMv7M 아키텍처에서는 코프로세서 15인 시스템 제어 코프로세서가 없습니다. 모든 제어 레지스터는 메모리 매핑되어 있어 접근할 수 있습니다.
외부 메모리를 위한 고정된 메모리 맵
외부 메모리에 대한 메모리 맵이 고정되어 있으며, 이는 시스템 설계 시 예측 가능성을 제공합니다.
캐시와 MMU(Memory Management Unit)가 없습니다. 이는 저전력 임베디드 시스템에서 메모리 액세스와 관리의 간소화를 목적으로 합니다.
Appendix

- 반도체 설계에서 다른 유형의 IP(Core) 제공 방식
-
하드 매크로셀 (Hard Macrocell)
- Hard Macrocell은 라이선스를 받은 디자인의 레이아웃 레벨로 제공됩니다.
- GDSII로 제공됩니다: 디자인의 최종 레이아웃 데이터 포맷으로, 반도체 제조 공정에서 직접 사용됩니다.
- 라이선스 받은 자는 변경할 수 없습니다: 라이선스를 받은 사용자는 하드 매크로셀의 내부 구조나 기능을 변경할 수 없습니다. 이는 이미 완성된 물리적 레이아웃을 의미합니다.
-
소프트 코어 (Synthesizable Core)
- Synthesizable (Soft) Cores는 RTL(Register Transfer Level)로 제공됩니다.
- 라이선스 받은 자가 구성하고 합성합니다: 라이선스를 받은 사용자는 소프트 코어를 구성하고, 합성하여 자신의 디자인에 통합할 수 있습니다.
- 기능을 변경할 수 없습니다: 소프트 코어의 기본 기능은 라이브러리 제공자가 정의하며, 라이선스를 받은 사용자는 이 기능을 변경할 수 없습니다.
하드 매크로셀은 더 높은 성능을 제공하지만 변경이 어렵고 비용이 더 들 수 있습니다.
반면 소프트 코어는 유연성이 있으며, 사용자가 설계 요구 사항에 맞춰 구성할 수 있지만 일반적으로 하드 매크로셀보다 성능이 낮을 수 있습니다.
Soft Core Overview