
▶ Introduction to Caches (Basics)
Example: Cached Arm Macrocell
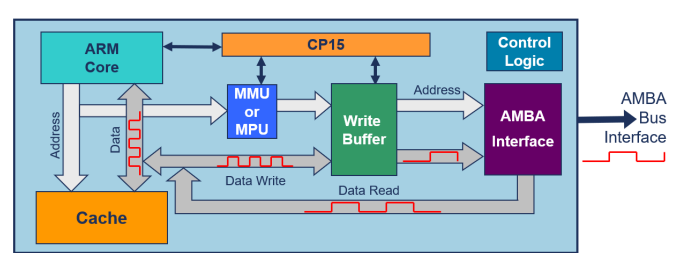
-
MPU – 메모리 보호 장치 (Memory Protection Unit)
- 메모리 접근 권한을 제어
- 메모리 영역의 캐시 가능 및 버퍼 가능 속성을 제어
-
MMU – 메모리 관리 장치 (Memory Management Unit)
- MPU의 모든 기능을 가짐.
- 또한 가상 주소를 물리 주소로 변환하는 기능을 제공
-
캐시 (Cache)
- 빠른 로컬 메모리
- 최근에 접근한 메모리 위치의 복사본을 보유
-
쓰기 버퍼 (Write Buffer)
- 외부 메모리로의 쓰기를 분리
-
CP15 - 시스템 제어 보조 프로세서 (System Control Coprocessor)
- 코어와 캐시 구성 설정을 제어
- MPU는 메모리 접근 권한과 속성을 제어
- MMU는 MPU의 기능에 더해 가상 주소를 물리 주소로 변환
- 캐시는 빠른 접근을 위해 최근 메모리 데이터를 저장
- 쓰기 버퍼는 외부 메모리로의 쓰기 작업을 효율적으로 처리.
- CP15는 시스템 제어와 캐시 설정을 관리
What is a cache?
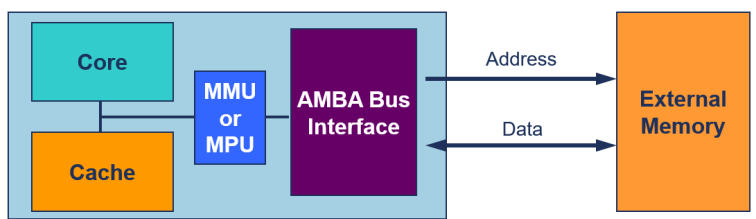
- 작고 빠른 메모리, 프로세서에 지역적인(local)
- RAM이나 TCM이 아니며, 직접적으로 주소 지정되지 않음.
- 최근에 액세스한 메모리 위치의 복사본을 자동으로 보유
- 캐시에 어떤 메모리 위치가 캐시될지는 MMU 또는 MPU를 통해 제어
- 성능 향상을 위해 메모리 재사용에 의존
- 성능을 향상시키기 위해 메모리를 재사용합니다.
- 느린 메모리나 좁은 메모리에 대해서만 성능을 향상
- 느린 메모리나 좁은 메모리에 대해서만 성능을 향상시킴.
- 버스 대역폭 요구사항을 줄이고, 그로 인해 전력 소모를 감소시킴
- 버스 대역폭 요구사항을 줄이고, 이로 인해 전력 소모를 줄임.
Cache Operation #1
캐시 사용 전의 소프트웨어 설정
- 캐시를 사용하기 전에는 몇 가지 소프트웨어 설정이 필요
메모리 액세스 시 캐시 확인
- 코어가 메모리에 대한 모든 액세스는 먼저 캐시에서 확인
- 캐시에 위치하는 경우(캐시 히트), 코어로 빠르게 반환
- 보통 한 사이클 내에 처리되어, 완벽한 메모리 시스템과 같이 작동
- 캐시에 위치하지 않는 경우(캐시 미스), 상황이 더 복잡해짐...
- 결정론적이지 않은 동작
ARM 캐시의 채움
- ARM 캐시는 캐시 미스가 발생한 후에 메모리 읽기를 통해 채워짐.
- 옵코드 페치 또는 데이터 로드 (LDR/LDM)
- 그렇다면, 새 데이터는 캐시에 어디에 배치?
- ARM 프로세서는 다음과 같은 전략을 지원
: 랜덤, 순환 (라운드 로빈) - 이러한 로직은 다음에 채워질 캐시 라인을 가리키는 희생자 카운터를 제어함.
- ARM 프로세서는 다음과 같은 전략을 지원
Cache Operation #2
How is a cache accessed by the core?
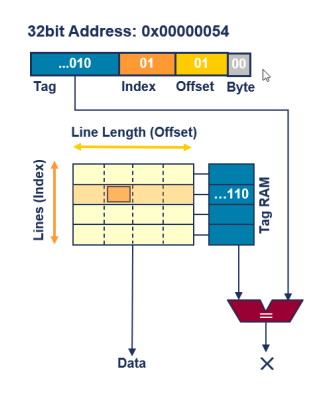
- Cache Miss(캐시미스)가 발생하면 Cache Linefill(캐시 라인필)과정을 거침
Cache Miss (캐시 미스):
프로세서가 메모리에 접근할 때, 필요한 데이터가 캐시에 없는 상황
Cache Linefill (캐시 라인필):
캐시 미스가 발생했을 때, 필요한 데이터를 주기억장치(메인 메모리)에서 캐시로 불러오는 과정
- 캐시의 특정 라인(일반적으로 캐시는 여러 개의 라인으로 구성)에 데이터를 채움.
How is a cache populated?(캐시는 어떻게 채워질까?)
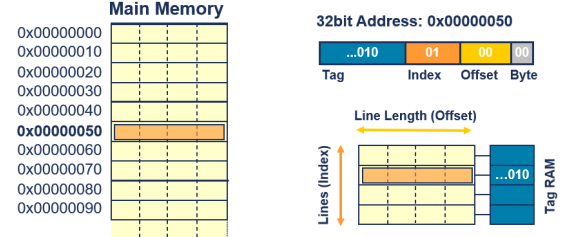
-
데이터는 한 번에 한 라인씩 캐시에 복사 (Cache Linefill)
- 캐시 라인필 과정에서 데이터가 캐시로 복사
-
캐시 라인은 항상 캐시 라인 크기에 맞춰 정렬(Offset이 0)
- 캐시 라인은 특정 크기를 가지며, 이 크기에 맞춰 정렬
-
캐시 라인필은 캐시 미스에 의해 트리거
- 캐시 미스가 발생하면, 필요한 데이터를 캐시에 불러오는 과정이 시작
- 이전에 요청된 데이터는 이제 외부 메모리에서 캐시 라인으로 로드(Index로 선택된 캐시 라인에)
- 필요한 데이터가 외부 메모리(주기억장치)에서 캐시로 불러와져서, 특정 인덱스로 선택된 캐시 라인에 채워짐.
- 연관된 캐시 태그가 업데이트
- 캐시 라인에 데이터가 채워지면, 그 라인과 연관된 태그 정보도 함께 업데이트.
-
각 필드에 할당된 비트 수는 캐시의 구조와 크기에 따라 다름
- 캐시의 구조(예: 직접 사상, 세트 연관, 완전 연관)와 캐시 크기에 따라 각 필드(인덱스, 태그, 오프셋)에 할당된 비트 수가 달라짐.
-
위 과정을 통해 캐시는 점차적으로 필요한 데이터를 저장함.
Direct Mapped Cache
-
가장 심플한 캐시 구조
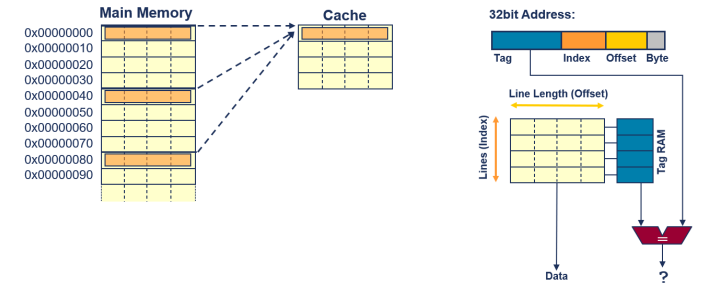
-
메모리 공간은 캐시의 단일 블록(웨이, Way)과 매핑
- 여러 메모리 위치가 동일한 캐시 라인(동일한 인덱스)을 두고 경쟁
- 저장된 태그는 해당 라인이 포함하고 있는 메모리 위치를 식별
-
데이터는 재사용되기 전에 쉽게 대체될 수 있음 (축출, Eviction)
- 예를 들어, 캐시 크기의 두 배인 처리 루프의 경우...
-
메모리의 여러 주소가 캐시의 동일한 인덱스에 해당하면, 캐시 라인이 어느 메모리 주소의 데이터를 포함하는지를 태그를 통해 확인할 수 있음
-
그러나 캐시 크기보다 큰 데이터 세트를 반복적으로 처리할 경우, 캐시 라인에 있는 데이터가 재사용되기 전에 새로운 데이터로 대체되어(축출되어) 캐시 효율이 떨어질 수 있다는 것
cf. 캐시 재사용 (Re-use)와 축출 (Eviction)의 개념
- 캐시 재사용 (Re-use):
- 캐시 재사용은 한 번 캐시에 로드된 데이터가 이후에 다시 필요할 때, 이미 캐시에 존재하기 때문에 메모리 접근 시간을 줄일 수 있는 상황
- 이는 캐시 히트(Cache Hit)로 이어져 성능 향상에 기여
- 예를 들어, 반복적인 루프나 자주 접근하는 데이터가 캐시에 남아 있는 경우 재사용이 잘 이루어짐.
- 캐시 축출 (Eviction):
- 캐시 축출은 새로운 데이터를 캐시에 로드하기 위해 기존의 데이터를 제거해야 하는 상황
- 캐시가 한정된 크기를 가지기 때문에 발생합니다.
- 캐시 축출은 캐시 미스(Cache Miss)를 초래
- 이는 메모리 접근 시간이 증가하여 성능 저하를 유발
Associativity(연관성)
Associativity (연관성)
-
단순 캐시는 직접 매핑 전략을 사용
- 특정 메모리 항목은 캐시 내의 고유한 위치에 저장
- 동일한 캐시 주소 필드(인덱스)를 가진 항목들은 그 위치를 두고 경쟁
- 구현이 간단하고 실행이 빠름.
-
세트 연관 캐시는 경쟁 문제를 줄이는 것을 목표로 함
- 특정 메모리 항목은 캐시 내의 여러 위치에 저장될 수 있음
- 캐시가 특정 메모리 항목을 캐시 내의 'n'개의 위치에 저장할 수 있으면, 그 캐시는 'n'웨이 세트 연관임.
- 구현이 더 복잡하며 더 많은 비교 하드웨어를 필요로 함.
-
직접 매핑은 구현이 단순하고 빠르지만, 동일한 인덱스를 가진 메모리 항목들이 한 위치를 두고 경쟁
-
반면, 세트 연관 캐시는 이러한 경쟁 문제를 줄이기 위해 항목을 여러 위치에 저장할 수 있도록 하지만, 그만큼 구현이 복잡하고 더 많은 하드웨어 자원이 필요
Set Associative Cache
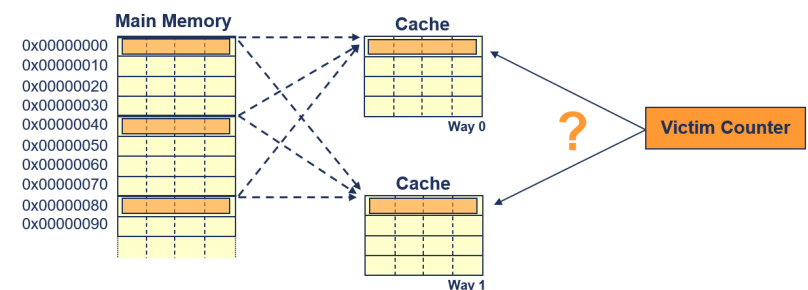
- 여러 캐시 웨이가 병렬로 작동
- 이제 주어진 주소에 대해 여러 가능한 캐시 위치가 있음
- 각 캐시 웨이에 하나씩 존재합니다.
- 희생자 카운터(Victim counter)는 라인필(Linefill)을 위해 어느 캐시 웨이가 사용될지를 결정
- 선택된 캐시 라인에서 이전 데이터는 축출
- 축출된 데이터는 외부 메모리를 업데이트해야 할 수도 있음 (더티 데이터).
2-Way Set Associative Cache
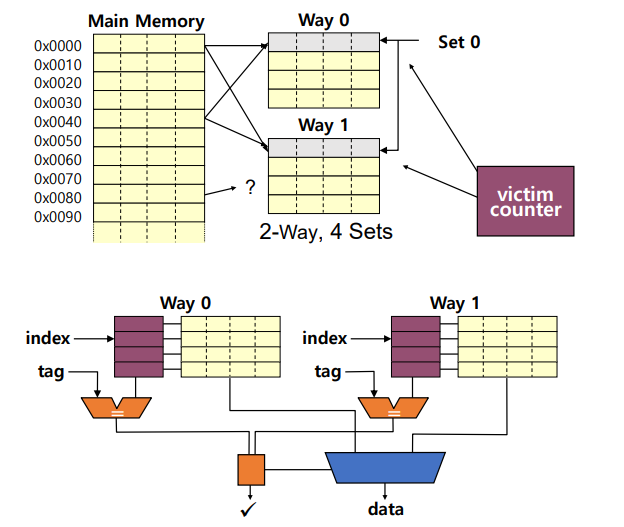
- 현재 ARM 프로세서에선 사용X
Replacement Strategies(교체 전략)
- 랜덤 (Random)
: 교체할 캐시 라인을 임의로 선택 - 순환 (Cyclic, round robin)
: 교체할 캐시 라인을 순차적으로 선택 - 가장 최근에 사용되지 않은 (Least Recently Used, LRU)
: 가장 오랫동안 사용되지 않은 캐시 라인을 교체
Example Memory Access
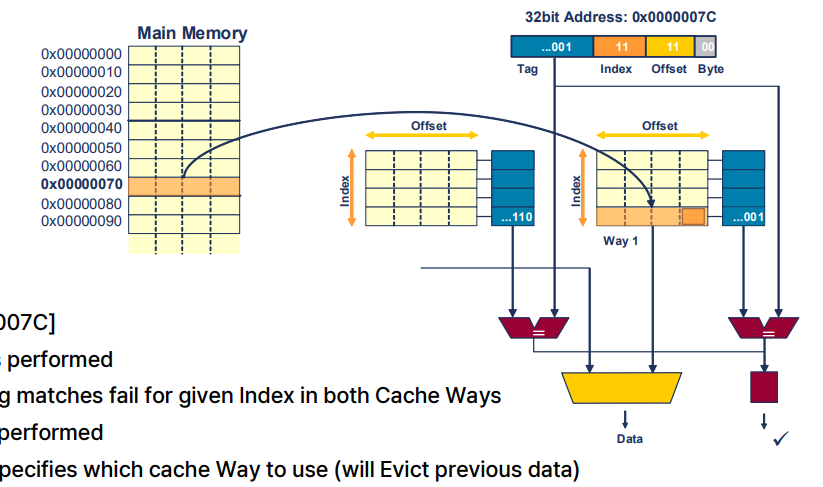
메모리 읽기(Memory Read):
- 명령어:
LDR r1, [0x0000007C]- 레지스터 r1에 메모리 주소 0x0000007C의 값을 로드
- 캐시 조회가 수행
- 캐시 미스(miss)
- 주어진 인덱스에 대한 태그 일치가 캐시 웨이 모두 실패
- 캐시 라인필(linefill) 수행
- 희생자 카운터가 이전 데이터를 제거할 캐시 웨이를 지정 (이전 데이터는 Evict).
- 캐시는 요청된 워드를 코어에 반환
Terminology
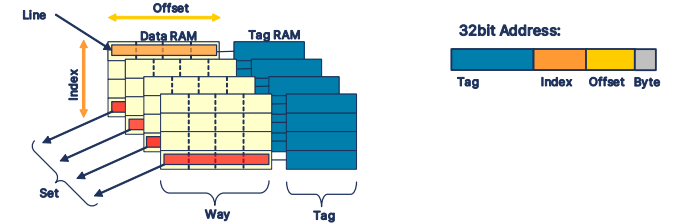
- 라인 (Line)
: 캐시의 가장 작은 로드 가능 단위
: 항상 메모리의 연속된 워드 블록임. - 웨이 (Way)
: 특정 캐시 '페이지'를 가리킵니다
: 위의 예에서는 4개의 웨이가 존재 - 세트 (Set)
: 각 캐시 웨이에서 동일한 라인이 모여 하나의 세트를 형성 - 태그 (Tag)
: 캐시에 저장된 특정 물리 주소를 식별하는 데 사용되는 메모리 주소의 일부분 - 인덱스 (Index)
: 캐시 라인이 저장될 수 있는 세트를 결정하는 메모리 주소의 일부분
▶ Caches on Arm processors
Arm Cache Features
- 하버드 구현 (Harvard Implementation)의 L1 캐시
- 명령어와 데이터를 각각 분리하여 저장하는 캐시
- 명령어 캐시와 데이터 캐시가 별도로 존재
- 캐시 락다운 (Cache Lockdown)
- 지정된 캐시 웨이에서 라인 축출을 방지(이후에 설명됨)
- 의사랜덤과 라운드 로빈 교체 전략(Pseudo-random and Round-robin replacement strategies)
- 교체 전에 사용되지 않은 라인들이 할당 가능
- 비차단(Non-blocking) 데이터 캐시
- 캐시 조회가 라인필이 완료되기 전에도 발생 가능 (라인필 버퍼도 확인함)
- 스트리밍, 중요 워드 우선 (Streaming, Critical-Word-First)
- 요청된 워드가 라인필 버퍼에서 수신되는 즉시 캐시 데이터가 코어로 전달
- 버스 상에서 'WRAP' 버스트를 사용하여 캐시 라인의 어떤 워드든 먼저 요청 가능
- ECC 또는 패리티 체크 (ECC or parity checking)
- 오류 검출 및 수정을 위한 ECC 또는 패리티 체크가 적용
Cache Operation
-
캐시는 일반적으로 물리적으로 태그 지정되고 가상적으로 인덱싱
- 캐시 태그는 물리 주소(Physical Address, PA)를 기반으로 함.
- 세트/인덱스 선택은 가상 주소(Virtual Address, VA)를 사용
- 가상 주소 지원이 없는 코어는 VA = PA
• 예: Cortex-R4
-
ARM 캐시는 캐시 미스(Cache Miss) 이후에 채워짐.
- 지원하는 할당 방식에 따라 달라짐.
- Read-allocate
: 읽기 미스 시 캐시 라인필(Cache Linefill)- 모든 캐시 프로세서에서 지원
- Write-allocate - 읽기와 쓰기 미스 시 캐시 라인필
• 일부 v6 및 v7 코어에서 지원 (예: Cortex-A8)
Non-Deterministic Cache behavior
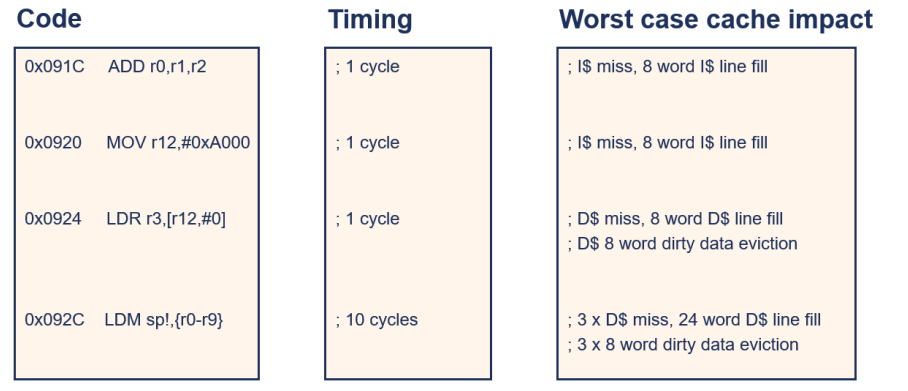
-
ISR 루틴이 Foreground 작업의 캐시된 데이터를 축출할 수 있음
- 인터럽트 서비스 루틴(ISR)이 실행되면, 캐시에 새로운 데이터를 로드하기 위해 필요한 캐시 라인을 확보하기 위해 기존에 캐시된 데이터가 축출될 수 있음.
- 이는 전경 작업(foreground task)의 성능에 영향을 줄 수 있습니다.
-
다중 마스터 시스템에서는 핵심이 버스를 획득하기 위해 대기할 수 있음
- 다중 마스터 시스템에서는 여러 핵심이 버스를 공유하고 경쟁할 수 있음.
- 따라서 한 핵심이 버스를 획득하기 위해 대기해야 하는 경우가 발생 가능
- 이는 핵심의 동작을 지연시킴.
4-Way Set Associative Cache
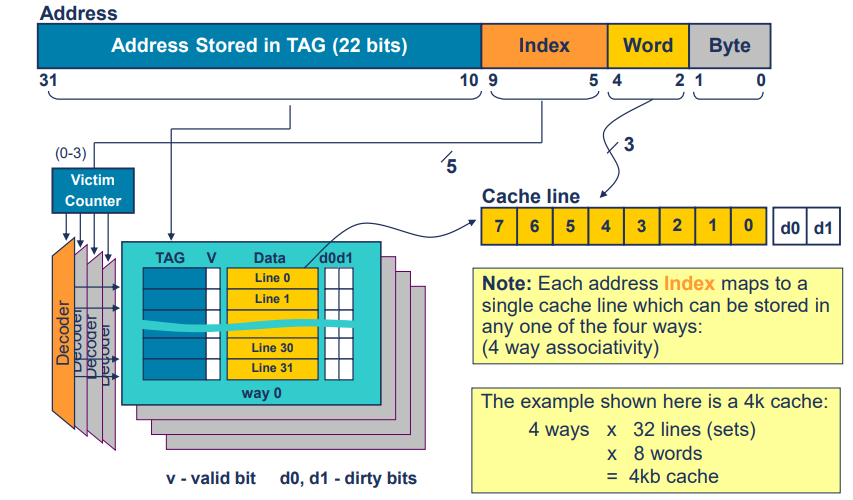
쓰기 방식 (Write Policies)
1. Write-Back
2. Write-Through
-
Write-Back (WB):
- Write-Back 방식은 캐시에 쓰기 작업이 발생할 때, 해당 데이터를 캐시에만 업데이트하고 메인 메모리에는 즉시 반영하지 않음.
- 변경된 데이터는 캐시에만 저장되고, 해당 블록이 캐시에서 쓰기를 요청할 때 메모리로 비동기적으로 쓰여짐.
- 이 방식은 쓰기의 효율성을 높이고 버스 대역폭을 절약. 하지만 메모리와의 일관성 관리가 필요함.
-
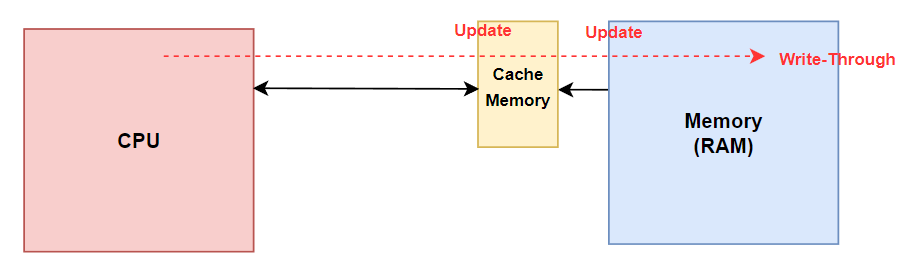
Write-Through (WT):
- Write-Through 방식은 쓰기 작업이 발생할 때 동시에 캐시와 메모리 양쪽에 모두 업데이트.
- 변경된 데이터가 캐시에 기록되는 동시에 메모리에도 즉시 기록됨.
- 이 방식은 메모리와 캐시 간의 데이터 일관성을 유지할 수 있지만, 쓰기 지연이 발생할 수 있고 쓰기 대역폭을 증가시킬 수 있음.
- Write-Back은 쓰기 작업이 자주 발생하는 시스템에서 성능을 향상시킬 수 있지만, Write-Through는 데이터 일관성이 매우 중요한 시스템에서 더 나은 선택
Cache Lockdown
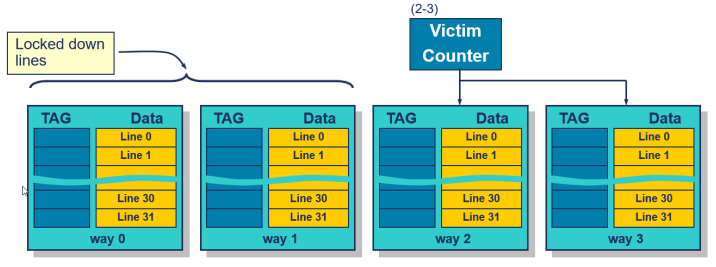
- 이는 4-way 연관 캐시
- 각각에는 4개의 웨이가 있으며, 각 웨이는 32개의 라인(세트)을 포함함.
- 단일 희생자 카운터가 교체가 발생하는 방식을 선택.
- Lockdown은 희생자 카운터의 기본 값을 고정하여 해당 값 아래의 방식은 교체에서 면제됨.
- 4-way 캐시의 경우, lockdown은 한 웨이의 정밀도를 가짐 (캐시 크기의 1/4)
Lockdown은 TCM을 사용하는 것으로 대체 가능. TCM 사용하는 게 더 나음.
-
이것은 보장된 실시간 성능을 제공하기 위해 필요함.
- 디버그 도구와의 상호 작용을 이해하는 것이 중요
- Lockdown 데이터는 축출될 수 있음.
- 가능하다면 Onchip SRAM (TCM)이 더 나은 솔루션
-
캐시 라인필을 제어하기 위해 짧은 소프트웨어 루틴이 필요
- 코어 기술 참조 매뉴얼(core Technical Reference Manuals)에 예제 루틴이 제공
- 그런 다음 희생자 카운터 범위가 제한됨 (CP15 레지스터 9).
-
잠긴 라인은 교체에서 면제됩니다.
- 그러나 여전히 'flushed'될 수 있음.
- 잠금 메커니즘을 해제해야 함.
-
나중에 TLB 잠금도 고려해야 함.
Cache Flushing
- 캐시 플러싱이 주로 사용되는 상황
- 캐시의 정보를 메모리보다 우선 사용하는 경우
- 일반적으로 CPU는 데이터나 명령어를 빠르게 액세스하기 위해 캐시에 저장된 정보를 사용
- 이는 메모리보다 접근 속도가 빠르기 때문에 성능을 향상시킴.
- 그러나 항상 바람직 하지 않은 경우도 있음.
- 코드가 자기 수정(self-modifying)될 때
: 일부 시스템은 코드가 실행 중에 자신을 수정할 수 있습니다. 이 경우 캐시에 저장된 이전 버전의 코드가 낡아 있을 수 있으므로 새로운 코드를 메모리에서 다시 로드해야 할 수 있음 - 메모리 속성이 변경될 때
: 메모리 영역의 접근 권한이 변경될 경우, 캐시에 있는 이전 버전의 데이터가 더 이상 유효하지 않을 수 있음 - MPU 또는 MMU 재프로그래밍 시
: 메모리 보호 장치(MPU)나 메모리 관리 장치(MMU)를 재프로그래밍할 때, 캐시에 있는 정보가 새로운 메모리 매핑과 충돌할 수 있음
→ 캐시 플러싱은 이러한 문제를 해결하기 위한 매커니즘
-
시스템 제어 코프로세서 CP15를 통해
: 캐시를 플러시할 때는 시스템 제어 코프로세서(CP15)를 사용.
: 이를 통해 캐시 라인들이 무효(invalid)로 표시되고, 다시 재사용할 수 있게 됨. -
캐시 플러싱은 단순히 캐시 유효 비트를 지우는 것
: 캐시를 플러시하면 캐시 라인들의 유효(valid) 비트가 지워지며, 이후 새로운 데이터나 명령어를 다시 메모리에서 로드할 때 캐시에 새로운 데이터가 채워질 수 있음. -
몇 사이클 내에 전체 캐시를 플러시할 수 있음
: 캐시 전체를 플러시하는 작업은 몇 개의 CPU 클럭 사이클 안에 완료될 수 있음.
L1 and L2 Caches
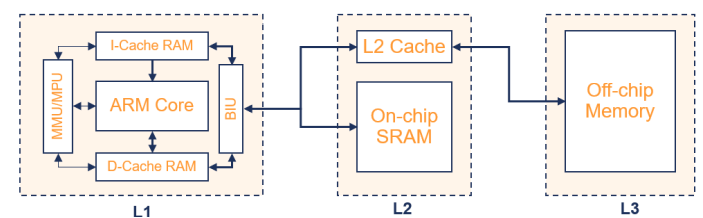
- 그림이 제일 이해하기 쉬움
- Inner cache, Outer cache
- 숫자가 작을수록 프로세스에 가까움.
1. 다중 레벨 캐시 시스템
- 전형적인 메모리 시스템은 여러 레벨의 캐시를 가질 수 있음.
- Level 1 메모리 시스템은 일반적으로 L1 캐시, MMU/MPU(메모리 관리 장치/메모리 보호 장치) 및 TCMs(태스크 특정 메모리)로 구성
- Level 2 메모리 시스템 및 그 이상의 레벨은 시스템 설계에 따라 다름
2. 메모리 속성이 캐시 동작을 결정
- 각 레벨에서의 캐시 동작은 메모리 속성에 의해 결정
- MMU/MPU에 의해 제어됨
: 메모리 관리 장치(MMU)나 메모리 보호 장치(MPU)가 메모리 접근에 대한 동작을 제어 - Inner Cacheable 속성
: L1 메모리 시스템에서의 메모리 접근 동작을 정의 - Outer Cacheable 속성
: L2 메모리 시스템 및 이후의 레벨에서의 메모리 접근 동작을 정의 (버스 상의 신호로 표시됨).
3. 캐시 사용 전에 소프트웨어 설정 필요
- 캐시를 사용하기 위해선 소프트웨어 설정이 필요
- 이 설정은 캐시의 동작 방식을 결정하며, 메모리 시스템의 전체적인 성능과 안정성에 중요한 역할을 함.
Write Buffer
일반적으로 코어는 다음과 같은 경우에 쓰기를 시도할 때 실행을 멈출 수 있음
-
쓰기 버퍼가 가득 찬 경우
쓰기 버퍼가 채워진 상태에서 추가적인 쓰기를 시도할 때 코어는 실행을 멈출 수 있습니다. 쓰기 버퍼가 가득 차 있으면 코어는 더 이상 새로운 데이터를 쓸 공간이 없기 때문에 기다려야 합니다.
-
쓰기 버퍼가 비활성화된 경우
쓰기 버퍼가 비활성화되어 있는 경우, 즉 쓰기 버퍼가 사용되지 않도록 설정된 상태에서 쓰기를 시도하면 코어는 멈출 수 있습니다. 쓰기 버퍼는 메모리 쓰기 성능을 향상시키기 위해 사용되므로, 비활성화 상태에서는 코어가 쓰기를 진행할 수 없습니다.
-
버퍼할 수 없는 메모리 영역에 쓰기가 수행된 경우
버퍼할 수 없는 메모리 영역에 쓰기를 시도하면 코어가 멈출 수 있습니다. 일부 메모리 영역은 쓰기 버퍼링을 지원하지 않을 수 있습니다. 이런 경우에는 쓰기가 직접적으로 메모리에 기록되어야 하며, 이 과정에서 코어는 기다려야 할 수 있습니다.
쓰기 버퍼가 비워지기 전에는 버퍼링되지 않은 쓰기가 발생하지 않을 것입니다.
프로세서는 소프트웨어 제어( CP15를 통해)로 쓰기 버퍼가 비워질 때 실행을 멈출 것
소프트웨어 제어를 통해: 프로세서는 CP15(시스템 제어 코프로세서)를 통해 소프트웨어에 의해 쓰기 버퍼가 비워질 때까지 실행을 멈출 수 있습니다. 이는 쓰기 버퍼가 처리되는 동안 다른 명령어들이 실행되지 않고 대기하는 상황을 의미
버퍼링된 쓰기는 중단을 발생시키지 않아야 함.
외부 메모리 컨트롤러에서의 중단은 무시됩니다: 외부 메모리 컨트롤러로부터 발생하는 중단은 무시됩니다. 이는 메모리 컨트롤러의 동작이나 외부 환경의 변화가 프로세서 동작에 직접적인 영향을 미치지 않도록 합니다.
Memory Properties


메모리 속성은 전역 설정과 지역 설정의 조합에 의해 설정
-
전역 설정은 Coprocessor CP15를 통해 설정된 속성을 제어.
- EX. MMU/MPU 활성화
- EX. 캐시 활성화
-
지역 설정은 MPU 영역 또는 MMU 페이지 테이블에 저장
- EX. 캐시 속성, 버퍼링 속성
- EX. 접근 권한
특정 주소 범위에 대해 속성은 다음과 같이 파생
-
GCd/i
: MMU 페이지의 캐시 속성 AND 캐시 활성화 AND MMU 활성화 -
Bd
: MMU 페이지의 버퍼링 속성 AND MMU 활성화 -
메모리 속성이 설정되는 방식과, 특정 주소 범위에 대해 속성이 파생되는 방식을 설명
-
전역 설정과 지역 설정을 결합하여 최종 메모리 속성이 결정됨.
Cache Write Strategy
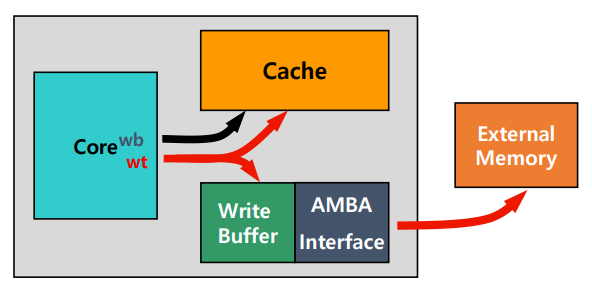
Write Through (쓰기 즉시 전달):
- Write를 할 때, Cache Memory와 Main Memory 모두에 업데이트를 하는 방식
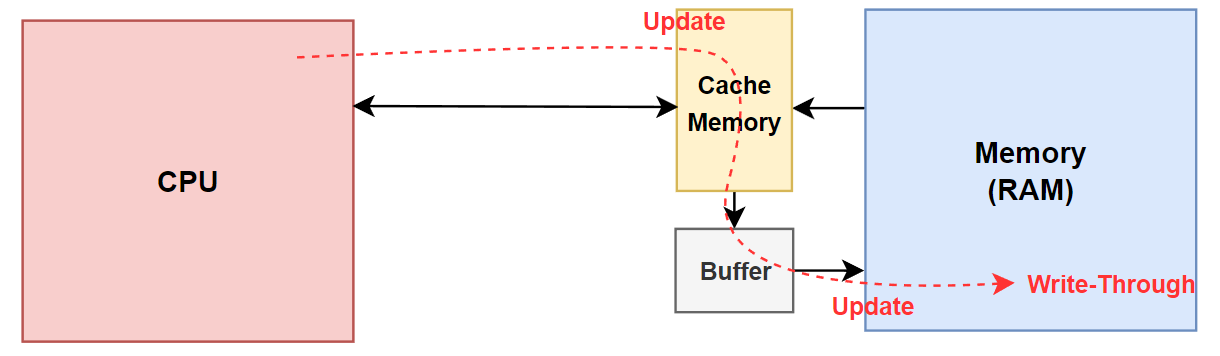
- CPU가 Cache Memory에 Write를 함과 동시에 Main Memory에도 Data를 Update를 하기 위해서 Buffer가 존재
- Buffer를 두면 CPU가 직접 Main Memory에 Write를 하지 않고 Cache Memory에만 Write하면 되기 때문에 CPU가 대기하는 시간을 줄일 수 있음.
Write Back (쓰기 지연):
- Write-Through와 반대로 Write-Back은 Cache Memory에만 Data를 Write
- Cache Memory가 새로운 Data block으로 교체되는 때에 Main Memory에 업데이트
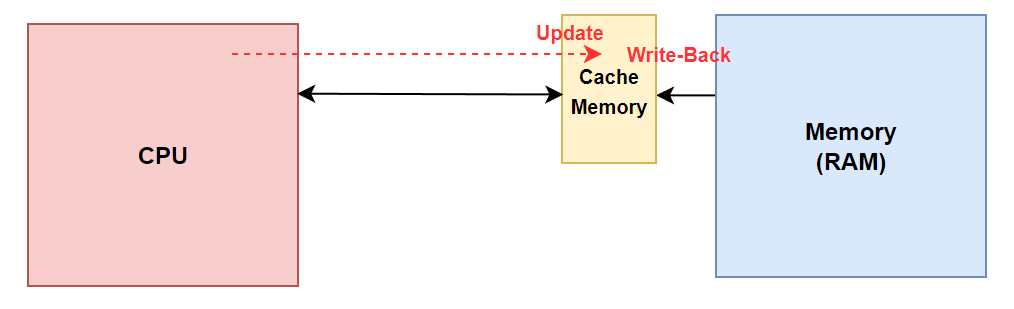
- Write-Back에서는 Data Block이 교체되지 않는 한, Main Memory에 Data는 업데이트 되지 않고 Cache Memory만 계속 수정, Overwrite
Write Through
- 데이터의 위치가 캐시 내에 있는 경우
: 캐시+데이터가 업데이트- 데이터의 위치가 캐시 내에 없는 경우
: 쓰기 버퍼를 통해 메모리로 전송
Write Back
- 데이터 위치가 캐시 내에 있는 경우
: 오직, 캐시만 업데이트- 데이터 위치가 캐시 내에 없는 경우
: 데이터는 직접 메모리에 기록- 해당 영역이 버퍼링되거나 캐시 가능한 경우, 쓰기 버퍼가 사용
WB and WT caching modes : Write Through
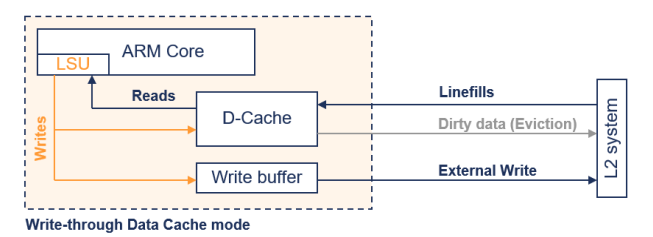
ARM 코어: 중앙에 위치하고 있으며, LSU (Load Store Unit)가 포함되어 있습니다.
- D-캐시: 데이터 캐시를 나타내며, 코어에서 읽기와 쓰기를 처리합니다.
- 쓰기 버퍼: 캐시와 외부 메모리 시스템 사이의 데이터를 중계합니다.
- L2 시스템: 더 큰 레벨의 캐시 또는 외부 메모리 시스템을 나타냅니다.
- Linefills: 캐시에 데이터가 없을 때 L2 시스템에서 데이터를 가져오는 작업입니다.
- Dirty data (Eviction): 캐시에서 변경된 데이터가 L2 시스템으로 퇴출되는 경우를 나타냅니다.
- External Write: 쓰기 버퍼를 통해 외부 메모리 시스템으로의 쓰기를 나타냅니다
- v6및 v7 코어의 캐싱 모드
- Write through, Read allocate
- Write back, Read allocate
- Write back, Write allocate
- 캐시 타입/사이즈 레지스터를 읽어 구현 지원
- Write through 모드
: 쓰기 업데이트는 캐시와 외부 메모리 시스템 모두를 갱신 - Write through 접근은 Dirty data를 생성하지 않음.
WB and WT caching modes #2
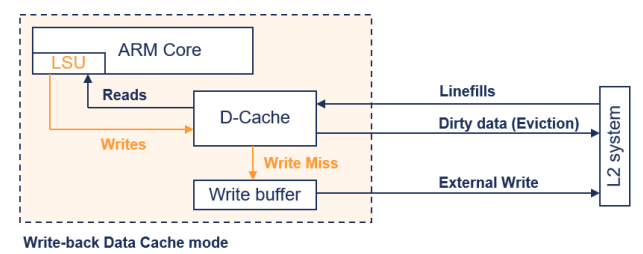
ARM 코어: 중앙에 위치하고 있으며, LSU (Load Store Unit)가 포함되어 있습니다.
- D-캐시: 데이터 캐시를 나타내며, 코어에서 읽기와 쓰기를 처리합니다.
- 쓰기 버퍼: 캐시와 외부 메모리 시스템 사이의 데이터를 중계합니다.
- L2 시스템: 더 큰 레벨의 캐시 또는 외부 메모리 시스템을 나타냅니다.
- Linefills: 캐시에 데이터가 없을 때 L2 시스템에서 데이터를 가져오는 작업입니다.
- Dirty data (Eviction): 캐시에서 변경된 데이터가 L2 시스템으로 퇴출되는 경우를 나타냅니다.
- External Write: 쓰기 버퍼를 통해 외부 메모리 시스템으로의 쓰기를 나타냅니다.
Write back 모드
- 쓰기 캐시 히트(Write Cache Hit)
: 캐시 히트 시 캐시만 업데이트되며, 데이터가 Dirty로 표시 - 쓰기 캐시 미스
: 쓰기 버퍼를 통해 외부 메모리에 쓰기 작업이 전파 - 쓰기 할당(Write-allocate)
: 캐시 라인필(linefill)이 발생하여 쓰기 캐시 히트가 발생
: 쓰기 버퍼를 통한 외부 쓰기가 더 이상 필요하지 않음
Dirty data를 포함한 캐시 라인의 Eviction은 외부 메모리에 쓰기 작업을 발생시킴
여기서, 데이터 캐시 읽기는 WT, WB 모드에서 동일하게 작동
Summary: Cache Policy
Cache Replace Policy(캐시 교체 정책)
- Round-Robin(라운드 로빈)
- Pseudo Random(의사 랜덤)
- Least Recently Used (LRU) - not used in current ARM processors(가장 최근에 사용되지 않은 것)
Cache Write Policy
- Write-through
- Write-back
Cache Allocate Policy
- Read
- Write (Read + Write)
Cache Policy Usage(시험나옴)

WT와 Read allocate
- 읽기 미스
: 캐시 라인필(linefill) 발생 - 쓰기 히트
: 캐시에 쓰기 + WT 버퍼를 통해 메모리에 쓰기 - 쓰기 미스
: WT 버퍼를 통해 메모리에쓰기
WB와 Read allocate
- 읽기 미스
: 캐시 라인필(linefill) 발생 - 쓰기 히트
: 캐시 라인만 쓰기, 더티 비트(dirty bit) 설정 - 쓰기 미스
: WT 버퍼를 통해 메모리에쓰기
Write-back과 Write allocate
- 읽기 미스
: 캐시 라인필(Linefill) 발생 - 쓰기 히트
: 캐시 라인만 쓰기, 더티 비트(dirty bit) 설정 - 쓰기 미스:
: 메모리 위치가 캐시 라인으로 가져와짐
: 캐시 라인에 쓰기
: 더티 비트(dirty bit) 설정
WB Caching – Cleaning Dirty Data
-
캐시 내의 비일관된 데이터는 'dirty' 비트를 사용하여 표시
- 캐시에 있는 데이터가 메모리와 일치하지 않는 경우, 해당 데이터에 대한
dirty비트가 설정. - 이는 해당 데이터가 수정된 상태임을 나타냄.
- 캐시에 있는 데이터가 메모리와 일치하지 않는 경우, 해당 데이터에 대한
-
가끔은 캐시의 전체 내용을 비워야 함
- 때로는 캐시에 있는 모든 데이터를 비워야 할 필요가 존재.
- 이는 주로 시스템이나 프로세서의 특정 조건에서 필요한 작업임..
WB Caching - Cleaning Dirty Data
데이터 캐시 내용이 외부 메모리와 비일관성 상태가 될 수 있습니다:
- 비일관성 데이터는 캐시 내에서 '더티(dirty)' 비트를 사용하여 표시됩니다.
더티 데이터를 포함한 캐시 라인이 퇴출될 때, 그 내용은 쓰기 버퍼를 통해 메인 메모리에 다시 쓰여집니다:
- 이는 CP15를 통해 소프트웨어 제어 하에 수행될 수도 있습니다.
- 예를 들어, 소프트웨어 브레이크포인트 설정, 자기 수정 코드 등에 사용됩니다.
때때로 캐시의 전체 내용을 플러시해야 할 필요가 있습니다:
- 예를 들어, 작업 전환 시
- 이 작업이 발생하기 전에, 캐시 전체를 먼저 클린해야 합니다.
- 이는 상당한 시간이 걸릴 수 있으며 쓰기 버퍼를 포화시킬 수 있습니다.
Write Back 캐시의 성능 이점은 캐시 클리닝의 시간적 페널티와 균형을 이루어야 합니다.
Write/Read Buffers
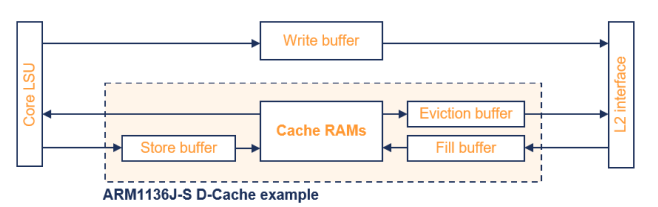
Core LSU: 로드/스토어 유닛
Store buffer: 데이터를 캐시에 저장하기 전에 임시로 보관하는 버퍼
Cache RAMs: 캐시 메모리
Eviction buffer: 쓰기 백 모드에서 데이터를 외부 메모리로 퇴출시키는 버퍼
Fill buffer: 캐시 라인필 데이터를 보관하는 버퍼
Write buffer: 데이터를 외부 메모리로 쓰기 전 임시로 보관하는 버퍼
L2 Interface: 레벨 2 캐시 또는 외부 메모리와의 인터페이스
ARM 코어는 다양한 버퍼를 구현하여 다른 클록 도메인 간의 접근을 디커플링
- 메모리 접근 버퍼링은 메모리 유형에 따라 결정
: Write Buffer는 Write-through 접근을 처리
: 때로는 Write-through Buffer라고도 함.
: Eviction Buffer는 Write-back 모드에서 사용.
: 내부 캐시 버퍼는 프로그래머에게 투명하게 동작.
: 메모리 접근은 프로그램 순서대로 완료되지 않을 수 있음.
CP15 또는 명시적인 메모리 배리어 연산을 사용하여 수동으로 플러시할 수 있음.
Write buffer
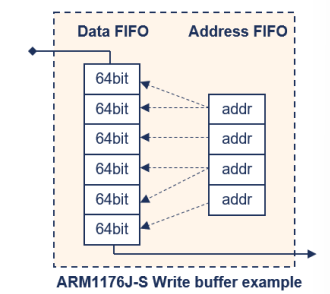
-
메모리 쓰기 버퍼링이 허용된 메모리 유형에서 사용됩니다. 이는 일반 메모리와 장치 메모리 등 여러 유형의 메모리에서 적용됩니다.
-
코어(Core)가 쓰기를 시도할 때 다음과 같은 상황에서 코어가 정지될 수 있습니다:
: 쓰기 버퍼가 가득 차 있어서 먼저 비워져야 할 때
: 쓰기 버퍼가 비활성화되어 있고 L2 캐시에 직접 액세스해야 할 때
: 메모리가 버퍼링할 수 없는 상태로 표시된 경우 (예: 강력 순서대로 메모리) -
만약 쓰기 버퍼에 이미 존재하는 주소에서 읽기를 시도하면, 쓰기 버퍼를 먼저 비워야 합니다.
-
쓰기 버퍼를 비울 때는 소프트웨어 제어 하에 프로세서 실행이 멈출 수 있습니다:
: Cortex-A8에서는 DSB(데이터 동기화 버퍼 플러시) 명령어를 사용하여 쓰기 버퍼를 비웁니다.
: ARM1176J-S에서는 CP15(시스템 제어 프로세서) 연산을 사용합니다. -
버퍼링된 쓰기는 중단을 생성해서는 안 됩니다:
: 이는 부정확한 중단(Imprecise Abort)을 발생시킬 수 있으며, 이는 복구할 수 없는 상태입니다.
Cached Core Problems
해당 문장들은 캐시를 사용하는 코어와 캐시를 사용하지 않는 코어의 성능과 관련된 주제
- 캐시를 사용하는 코어는 일반적으로 메모리 시스템 비용과 어플리케이션 성능 사이에서 훌륭한 절충안을 제공합니다.
▪ 그러나... - 실시간 시스템은 예측 가능한 실시간 성능이 필요합니다.
▪ 캐시를 사용하는 코어는 결정론적인 실시간 행동을 보이지 않습니다.
▪ 캐시 미스는 쉽게 예측할 수 없으며, 시간적인 패널티가 큽니다.
▪ 이러한 상황을 처리하기 위해 시스템 설계에서 허용해야 할 여지가 있어야 합니다.
• 한 가지 해결책은 중요한 실시간 루틴을 위해 온칩 SRAM(TCM)을 사용하는 것입니다.
• 또는 대안으로, 캐시 락다운 전략을 사용할 수 있지만 이는 두 번째 선택입니다. - 캐시를 사용하지 않는 코어의 성능은 빠르지 않을 수 있습니다.
▪ 외부 메모리 속도의 1/5 수준일 수 있습니다.
이 문장들은 캐시를 사용하는 코어와 캐시를 사용하지 않는 코어 간의 성능 차이와 실시간 시스템에서의 고려 사항을 설명
캐시를 사용하는 코어는 일반적으로 어플리케이션 성능을 높이지만, 실시간 시스템에서는 예측할 수 있는 실시간 성능을 보장하기 어려울 수 있으며, 이를 해결하기 위해 특별한 설계 고려가 필요
Cached Core Optimizations(★)

해당 문장들은 ARM 아키텍처에서 지원하는 다양한 캐시 관련 기술들을 설명
-
Critical Word First
▪ 캐시 미스가 발생할 때, 첫 번째로 가져오는 단어는 요청된 단어입니다.
▪ ARM926EJ-S 이후 버전에서 지원됩니다. -
Prefetch buffer
▪ 캐시가 비활성화되었거나 메모리가 캐시할 수 없는 상태일 때, 일부 코어는 명령어 페치를 위해 명세적인(예측적인) 버스트 메모리 읽기를 수행할 수 있습니다.
▪ ARM926EJ-S 이후 버전에서 지원됩니다. -
Non-blocking data cache
▪ 데이터 캐시 라인 채우기 작업 중에도 데이터 캐시 히트가 발생할 수 있습니다.
▪ ARM926EJ-S, ARM1136JF-S 등에서 지원됩니다. -
Hit-Under-Miss
▪ 데이터 읽기 미스가 발생하면, 코어는 명령어 실행을 계속하고 데이터 캐시 히트를 반환할 수 있습니다.
▪ 원래 데이터 값이 후속 명령어에서 연산자로 필요할 때만 코어가 정지합니다.
• 두 개 이상의 데이터 캐시 미스가 발생할 때도 실행을 계속할 수 있습니다.
▪ ARM1136JF-S 등에서 지원됩니다. -
ARM 아키텍처의 다양한 캐시 관련 기술들에 대해 설명
-
이러한 기술들은 캐시 효율성을 높이고, 성능을 최적화하며, 명령어와 데이터 액세스의 지연을 줄이는 데 기여
What should I cache?
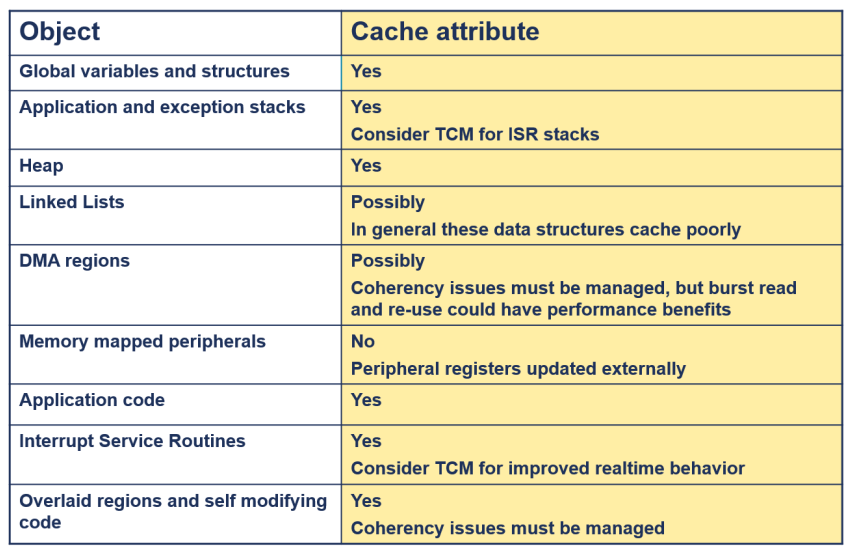
Memory Management
ARM 아키텍처에서 사용되는 메모리 보호 장치인 MPU(Memory Protection Units)와 메모리 관리 장치인 MMU(Memory Management Units)
⚫ Memory Protection Units (MPU)는 메모리를 프로그래머블한 권한을 가진 별도의 영역으로 나누어 제공합니다.
▪ 설정이 간단합니다.
▪ MMU에 비해 전력과 면적을 절감할 수 있습니다.
• 가상 메모리 지원이 없습니다.
✓ 페이지 테이블을 사용하지 않습니다.
▪ ARM946E-S는 MPU를 포함한 ARM 코어의 한 예입니다.
⚫ Memory Management Units (MMU)는 훨씬 더 유연하고 동적인 메모리 제어를 제공하며 더 강력한 권한 체계를 가지고 있습니다.
▪ 설정이 복잡합니다.
• 페이지 테이블을 통해 가상 메모리 지원을 제공합니다.
▪ ARM926EJ-S는 MMU를 포함한 ARM 코어의 한 예입니다.
이 문장들은 MPU와 MMU의 차이점과 각각의 장점 및 사용 사례에 대해 설명하고 있습니다. MPU는 간단하게 설정할 수 있지만 가상 메모리를 지원하지 않고, MMU는 보다 유연한 메모리 제어와 가상 메모리 지원을 제공하지만 설정이 더 복잡함.
Programmer’s Model
- ARM 아키텍처에서 코어를 구성하는 데 사용되는 CP15 코프로세서 내의 레지스터들
- 코어는 CP15 코프로세서 내의 레지스터에 데이터를 쓰는 방식으로 구성
: 이는 캐시, 보호 유닛 및 엔디언 구성과 같은 시스템 작업을 포함 - CP15에 정의된 레지스터들은 MCR(또는 MRC) 명령어를 통해서만 접근할 수 있음.
▪ MCR/MRC{cond} p15, opcode_1, rd, cn, cm, opcode_2
• p15 - 코프로세서 15를 식별합니다.
• opcode_1 - 캐시 작업에서는 항상 0입니다.
• rd - ARM 소스 또는 목적 레지스터
• cn - 주 CP15 레지스터
• cm - 일부 주 CP15 레지스터에 대한 추가 정보를 지정하기 위해 사용되는 추가 레지스터 이름 (버전/접근 유형)
• opcode_2 - 선택적으로 추가 정보를 지정하는 3비트 숫자
- 다른 코프로세서 명령어 (CDP, LDC, STC)나 비특권 모드에서 CP15에 대한 MCR/MRC 사용은 정의되지 않은 명령어 예외를 발생시킴.
- CP15의 레지스터는 MCR 또는 MRC 명령어를 사용하여 접근할 수 있으며, 이를 통해 캐시 설정, 보호 설정 등 다양한 시스템 작업을 수행가능.
▶ Tightly Coupled Memory(TCM)
What is Tightly Coupled Memory?
- 캐시 대안인 TCM (Tightly-Coupled Memory)
⚫ 캐시 대안 접근 방식
▪ 외부 메모리가 느릴 때도 높은 성능을 제공합니다.
▪ 동일한 양의 캐시에 비해 더 작은 다이 크기의 페널티가 있습니다.
⚫ 프로세서에 로컬한 빠른 메모리
▪ 시스템 버스 접근 없이 고속 성능을 제공합니다.
▪ 동등한 캐시 양과 비교했을 때 더 작은 다이 크기 페널티가 있습니다.
⚫ 물리적 메모리 맵 내에서 고정된 위치에 나타납니다.
▪ 응용 프로그램이나 라이브러리 코드에 의해 코드와 데이터가 TCM으로 복사될 수 있습니다.
▪ 일부 프로세서에는 DMA 액세스나 외부 AXI 인터페이스를 통해 TCM에 접근할 수 있는 기능이 포함되어 있습니다.
• TCM 사전로드에 사용될 수 있습니다.
• Cortex-R4는 TCM에 접근하기 위한 외부 AXI 슬레이브 포트를 제공합니다.
• ARM1136J-S에는 DMA 컨트롤러가 포함되어 있습니다.
⚫ MPU 기반 코어에서 정밀한 실시간 성능을 예측할 수 있습니다.
▪ MMU 활성화된 코어는 TCM 접근을 위해 주소 변환을 수행해야 합니다.
• TLB(Terminal Lookup Buffer) 검사가 이루어지고 테이블 워크(table walk)가 발생할 수 있습니다.
이 문장들은 TCM을 사용하여 캐시 대안으로 빠른 메모리 접근을 가능하게 하고, 이로 인해 다이 크기와 성능이 어떻게 변화하는지를 설명하고 있습니다. 또한 TCM이 물리적 메모리 맵의 고정된 위치에 있으며, 응용 프로그램이나 라이브러리 코드에 의해 데이터와 코드가 TCM으로 복사될 수 있음을 언급하고 있습니다.
TCM Configuration
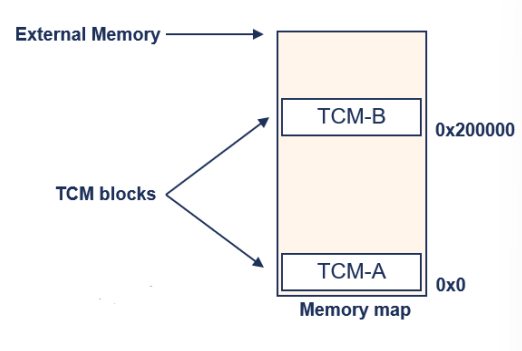
해당 문장들은 TCM (Tightly-Coupled Memory)을 지원하는 코어들의 구성과 관련된 내용을 설명하고 있습니다:
⚫ TCM을 지원하는 코어들은 두 개의 인터페이스를 제공합니다.
▪ 전통적으로 I-TCM과 D-TCM으로 알려져 있습니다.
▪ 예를 들어 Cortex-R4에서는 TCM-A와 TCM-B로도 불립니다.
⚫ 각 TCM 인터페이스는 CP15 연산을 사용하여 개별적으로 구성할 수 있습니다.
▪ 물리적 기본 주소 (크기의 배수)
• 외부 메모리와 중첩할 수 있습니다.
▪ 메모리 크기 (코어 및 구현에 따라 다름)
▪ 활성화/비활성화
⚫ 외부 핀은 리셋 후 구성을 결정합니다.
▪ 시스템을 TCM 메모리에서 부팅할 수 있습니다.
▪ INITRAM 핀은 코어 리셋 동안 TCM을 활성화합니다.
▪ LOCZRAM 핀은 리셋 전에 TCM 주소 선택을 허용합니다.
• Cortex-R4에서 지원됩니다.
⚫ TCM이 활성화된 경우에는 서로 겹치지 않아야 합니다.
이 문장들은 TCM을 구성하고 제어하는 방법에 대한 세부 사항을 설명하고 있습니다. TCM 인터페이스는 각각의 물리적 주소와 메모리 크기를 설정할 수 있으며, 외부 핀을 통해 리셋 후에 TCM의 동작을 결정할 수 있습니다.
Arm966E-S Memory Map
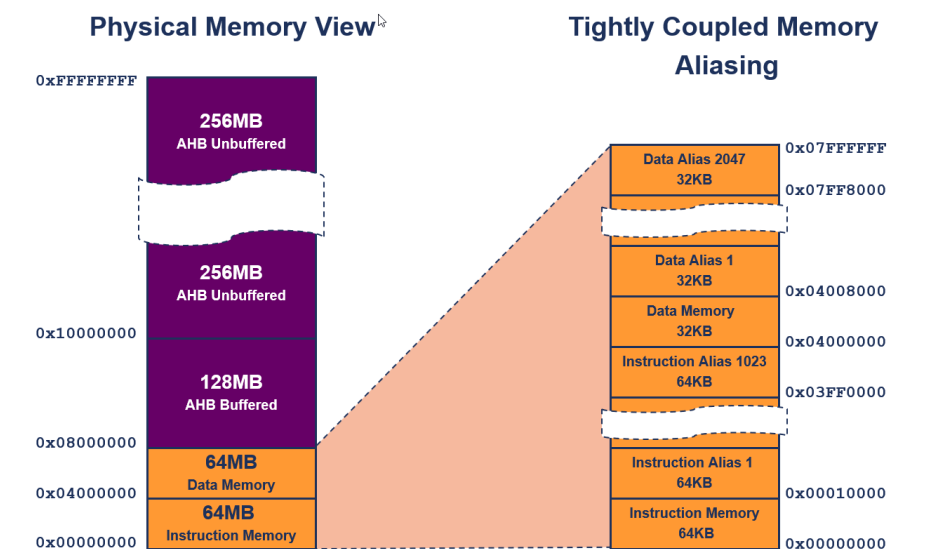
Arm946E-S Memory Map
해당 문장들은 TCM (Tightly-Coupled Memory)의 설정과 관련된 중요한 규칙들을 설명하고 있습니다:
⚫ 명령어 TCM의 기본 주소는 항상 0x0입니다.
- 즉, 명령어 TCM은 항상 메모리의 시작 부분에서 시작합니다.
⚫ 데이터 TCM의 기본 주소는 해당 영역의 크기의 배수여야 합니다.
- 예를 들어, 데이터 TCM 영역의 크기가 64KB라면 데이터 TCM의 기본 주소는 64KB의 배수여야 합니다.
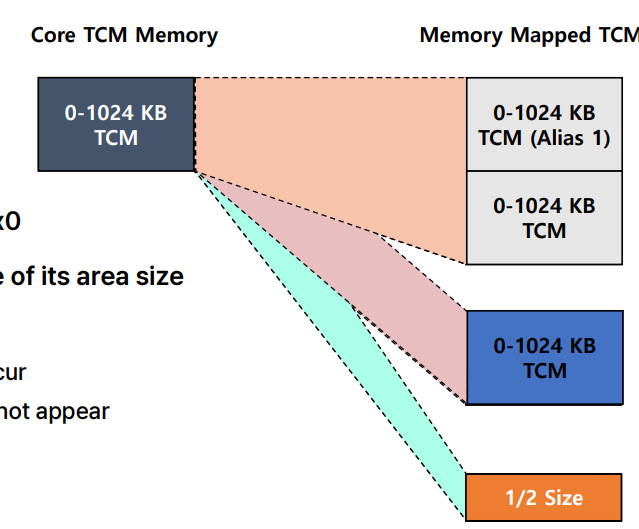
⚫ TCM 영역의 크기는 명시할 수 있습니다.
- 실제 크기보다 큰 경우 TCM 에일리어싱(aliasing)이 발생할 수 있습니다. 즉, 여러 주소가 같은 실제 메모리 위치를 가리키게 됩니다.
- 실제 크기보다 작은 경우 일부 메모리가 나타나지 않을 수 있습니다. 이 경우 메모리를 더 세밀한 주소에 배치할 수 있습니다.
⚫ TCM이 활성화된 경우 서로 겹치지 않아야 합니다.
- 즉, 명령어 TCM과 데이터 TCM은 서로 겹치지 않아야 합니다.
이러한 규칙들은 TCM을 올바르게 설정하고 사용하기 위한 중요한 사항들을 포함하고 있습니다. TCM은 성능을 향상시키기 위해 사용되는데, 이러한 설정들이 TCM의 효과적인 활용을 가능하게 합니다.
Arm926EJ-S
해당 문장들은 TCM (Tightly-Coupled Memory)에 대한 추가적인 설명과 설정 관련 규칙을 다루고 있습니다:
⚫ 명령어 TCM과 데이터 TCM은 주소 공간에서 독립적으로 어디든 위치시킬 수 있습니다.
▪ 그러나 겹쳐서는 안 됩니다.
⚫ 리셋 시 활성화된 경우, 명령어 TCM은 주소 0x0에 위치합니다.
▪ 이후 위치를 변경할 수 있습니다.
▪ 보통 TCM은 초기화되지 않은 RAM이며, 전원이 켜질 때 부트되어서는 안 됩니다.
⚫ 데이터 TCM은 리셋 시 항상 비활성화됩니다.
⚫ TCM은 물리적 주소를 가집니다.
▪ 접근은 MMU에 의해 번역되어야 하며, 이 과정에는 페이지 테이블 워크가 포함될 수 있습니다.
▪ 관련된 페이지 테이블 항목을 TLB에서 잠금 처리하려 할 수 있습니다.
▪ TLB에는 잠금 처리용으로 8개의 항목이 할당되어 있습니다.
⚫ TCM 영역은 반드시 캐시를 사용할 수 없도록 표시되어야 합니다.
이러한 문장들은 TCM의 설정과 관련된 중요한 사항들을 설명하고 있습니다. TCM은 명령어와 데이터 모두를 독립적으로 주소 공간에서 설정할 수 있으며, 리셋 시 초기 위치 설정에 대한 규칙과 초기화되지 않은 상태에서 부팅이 필요하지 않다는 점을 강조합니다. 또한 TCM은 물리적 주소를 사용하며, MMU를 통해 접근이 번역되어야 하며, 캐시를 사용할 수 없도록 설정되어야 한다는 점이 중요합니다.
