Conditional Diffusion model을 기반으로 개발된 image-to-image translation 프레임워크에 관한 논문이다.
Image-to-image translation tasks: Colorization, Inpainting, Uncropping, JPEG Restoration
Conditional Diffusion Model ?
기존 Diffusion model + 특정 조건에 따라 데이터를 생성할 수 있는 것
- Keywords: Generative models, Diffusion models, DL, GAN, L1 Loss, L2 Loss, self-attention, multi task learning(MTL) (논문 키워드 + 내가 뽑은 키워드)
🍞 1. Introduction
vision / image processing의 많은 문제는 image-to-image translation으로 공식화될 수 있다.
super-resolution, colorization, inpainting과 같은 restoration tasks / instance segmentation, depth estimation과 같은 pixel-level image understanding tasks가 이에 해당한다.

그림처럼 이러한 task들은 여러 출력 이미지가 단일 입력과 일치하는 복잡한 inverse problem이다.
Image-to-image translation에 대한 자연스러운 접근 방식은 이미지의 고차원 multi-modal 분포를 포착할 수 있는 심층 생성모델을 사용하여, input이 주어진 output 이미지의 conditional distribution을 학습하는 것이다.
GAN은 많은 image-to-image task를 위한 모델이지만, 학습이 어렵고 종종 output distribution에서 모드를 drop하는 문제가 있다.
Autoregressive model, VAE, Normalizing Flows는 특정 애플리케이션에서는 성공적이었지만 GAN과 같은 quality와 generality를 갖지 못했다.
최근(논문 상) 연속 데이터 모델링에서 Diffusion과 score-based model이 주요 진전이 있었다.
음성 합성에서 diffusion model이 human evaluation score에서 SoTA autoregressive model과 동등한 성능을 달성했고, class-conditional ImageNet generation challenge에서는 GAN을 FID 점수에서 능가했으며, super-resolution에서는 인상적인 향상된 결과를 냈다.
이러한 결과에도 불구하고, diffusion 모델이 image manipulation에서 GAN과 겨룰 정도의 다양하고 일반적인 프레임워크를 제공하는지는 불분명하다.
(-> 그런 프레임워크 Pallete를 우리가 제공할거다? 라는 내용이 나오려나 라는 생각함)
이 논문에서는 Palette 의 general applicability를 colorization, inpainting, uncropping, JPEG restoration과 같은 distinct & challenging한 태스크에 대해 조사한다.
- Palette는 task-specific 구조에 대한 customization, hyper-parameters, loss 변경 없이 high-fidelity output을 제공한다.
Palette의 핵심 구성 요소: denoising loss function / neural architecture
L2, L1 loss가 유사한 sample-quality score를 산출했지만, L2가 좀더 샘플에 대해 높은 다양성인 반면, L1은 conservative한 output을 산출했다.
Fully convolutional model을 위해 Palette의 U-Net 구조에서 self-attention 레이어를 제거하면 성능이 저하된다.
🍞 2. Related Work
- Pix2Pix
- GAN 기반 image-to-image translation task - GAN-based techiques(때때로 일관된 structural/textural regularity 변환에 실패)
- unpaired translation
- unsupervised cross-domain generation
- multi-domain translation
- few-shot translation - Diffusion model
- Multi-task training
관련 연구들에 대해 소개하는 내용. task들에 대한 추가 설명은 논문 레퍼런스 보는게 나을듯
🍞 3. PALETTE
(Diffusion model / Conditional Diffusion model 에 대한 설명 / 아키텍처 소개 섹션)
- Diffusion model
- Diffusion model은 가우시안 분포에서 반복적인 denoising을 통해 실제 데이터 분포로부터의 샘플을 생성한다.
- Conditional Diffusion model
- Denoising + conditional on input signal -> 특정 입력에 기반한 결과 생성 가능
- Loss function
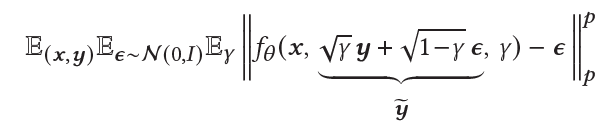
y = output image, y_tilda = noisy version, f_theta = neural network
- L1은 일부 경우에 hallucination(학습 데이터에 기반하지 않은 비현실적 결과물)을 줄일 수 있지만, L2가 출력 분포를 더 faithfully하게 포착한다.
- Architecture
- U-Net 구조 사용(아래는 Palette / U-Net 주요 차이점)
- class-conditioning이 없다.
- source image concatenation을 통해 additional conditioning
🍞 4. Evaluation Protocol
- scale, diversity, public availability 때문에 ImageNet 기반으로 평가
- 평가 측정은 Inception Score(IS), Frechet Inception Distance(FID), Classification Accuracy(CA) of a pre-trained ResNet-50 classifier, Perceptual Distance(PD) 사용
- Human evalutation: 모델 출력과 natural 이미지를 구별할 수 있는지 -> fool rate로 결과 출력
- fool rate: 어떤 이미지가 카메라로 촬영한 것일까? -> natural 이미지보다 model output을 답하는 사람 비율(
바보보다 진짜 속았을지도)
🍞 5. Experiments
🌿Colorization: grayscale image -> color image
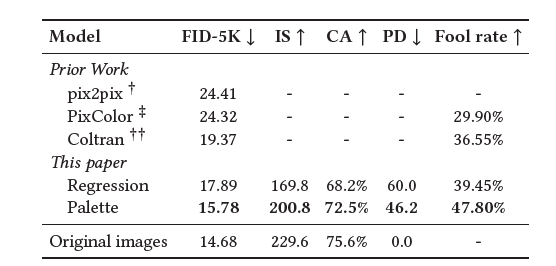
SoTA 달성이용ㅋ
🌿Inpainting: user-specified masked region을 realistic한 content로 채우기

기존 모델 능가!
🌿Uncropping: extends input image to enlarge
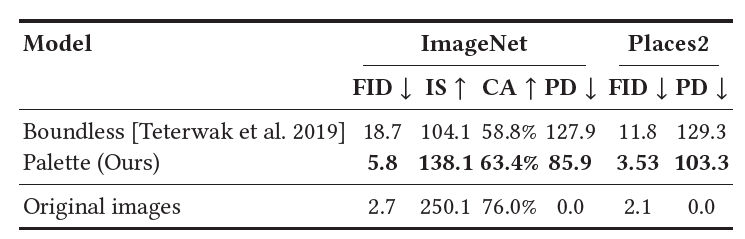
얘도 잘나왔어용
🌿JPEG Restoration: corrects JPEG compression artifacts
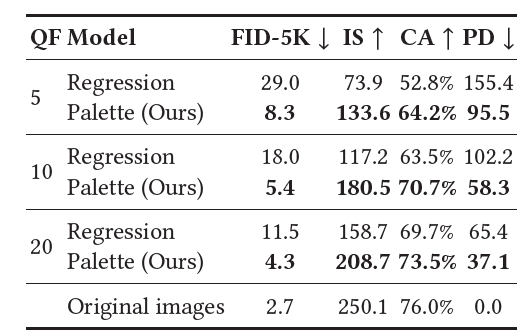
암튼 여기서도 결과 잘나왔단 뜻임
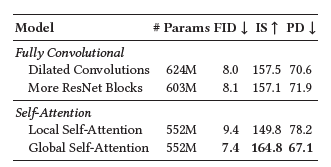
🌿 Self-attention in Diffusion model architectures
- self-attention 레이어는 Diffusion model을 위한 U-Net에서 중요 구성 요소
- global dependency 제공 unseen image resolution에 대한 generalization 방지
- 본 논문에서는 4 configurations 에서 실험진행
- Global Self-Attention: Baseline(32x32, 16x16, 8x8 resolution에서)
- Local Self-Attention: 피처맵이 겹치지 않는 4개의 query block으로 분할
- More ResNet Blocks without Self-Attention: 2 residual blocks -> receptive field size 증가로 깊은 컨볼루션
- Dilated convolutions without Self-Attention: 위랑 비슷하게 dilation rate 증가로 receptive field 기하급수적으로 증가
🌿 Sample Diversity
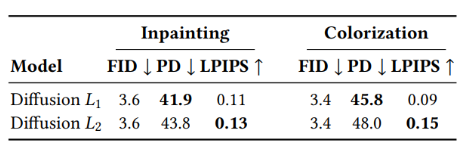
L2 loss 사용한 모델이 L1 loss 사용한 모델보다 더 큰 Sample Diversity 제공.
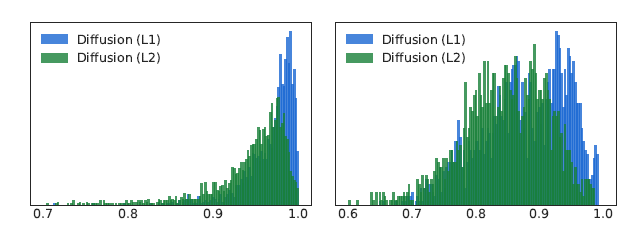
좌측은 Colorization, 우측은 Inpainting에 대해 측정한 출력 이미지들의 histogram이다.
🌿 Multi-Task Learning(MTL)
MTL: 여러 task들을 동시에 해결하기 위해 단일 모델을 훈련시키는 머신러닝 방식
-> 서로 다른 task 간의 공유 지식들을 학습하여 개별 task에 대한 모델의 일반화 능력을 향상시키는 것

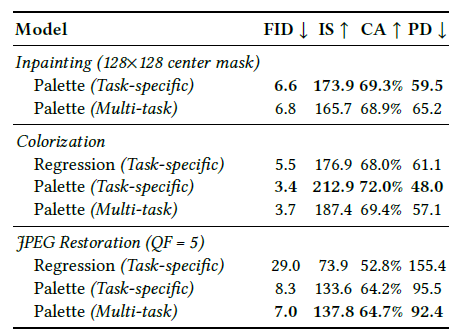
JPEG restoration에서는 MTL이 task-specific 모델보다 성능이 우수하지만, Inpainting과 Colorization에서는 task-specific이 더 성능이 좋음
왜? (개인적 생각) -> JPEG restoration은 compression artifact를 제거하는 것인데, 타 task로부터 얻은 general한 이미지 representation과 feature들을 활용할 수 있어서 일반화가 좋지 않을까 싶다.
반면 Inpainting / Colorization은 semantic한 ? (창의적인?) 일반화보다는 좀더 task 자체 specific한게 필요할 것 같다.
재밌는 논문이었다. 뭔가 내가 하는 일에 좀 응용해서 적용해보면 재밌을듯한..
일단 다음에는 코드구현으로 돌아오겠당
