본 글은 Stanford CS224N Winter 2021의 강의를 듣고 정리하는 내용입니다.
Youtube : Stanford CS224N
Website : Stanford CS224n : Natural Language Processing with Deep Learning
1. Optimization : Gradient Descent
Good Word vector를 어떻게 학습시킬 것인가?
⇒ parameters에 대한 loss function의 Gradient(기울기) 계산
1) Gradient Descent (경사 하강법)
- θ를 변화시키면서 J(θ)를 최소화하고자 함
- 현재 θ에 대한 기울기를 구하고, 기울기의 반대 방향으로 조금씩 움직임(small step in the direction of negative gradient)
- 이를 반복함
→ 현재 예시 사진에서는 기울기가 음수이므로 x를 양의 방향으로 조금씩 움직이는 것!
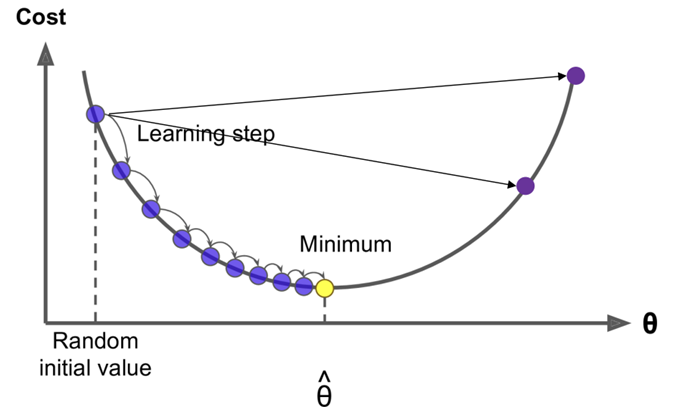
- Step size를 매개변수로서 조절할 수 있음
- step size가 너무 작으면 너무 오랜 시간이 걸리고 불필요한 계산이 증가함
- step size가 너무 크면 한 번에 너무 많은 이동이 발생해 최저점을 지나칠 수 있음
❗ 관련 공식
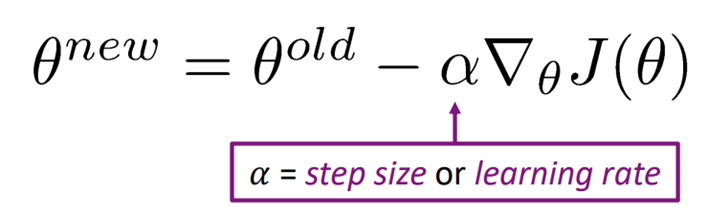

→ 가 step size이고, 가 θ일 때 loss function의 기울기
→ 현재 세타에서, 기울기의 반대방향으로 알파의 가중치만큼 이동시키기 위해 위와 같은 공식을 사용하는 듯함
그런데 이건 Simple Gradient Descent Algorithm으로, 문제가 많아서 쓰지 않음!
2) Stochastic Gradient Descent (확률적 경사 하강법 : SGD)
Simple Gradient Descent의 문제
- corpus에는 무수히 많은 word가 있음
- 는 corpus 내의 모든 window에 대한 함수임 → 전체 corpus에 대해 계산을 반복하기 때문에 계산량이 엄청남!
- 최적화 또한 매우 느릴 것임(한 번 업데이트를 위해 오래 기다려야 하니까)
⇒ 그래서 이건 안 씀
SGD : Stochastic Gradient Descent
- Very simple modification of Simple Gradient Descent
- 전체 corpus에 대해 기울기를 예측하는 대신 one center나 small batch(32개 정도의 center word)에 대해서만 기울기를 예측함
- one center나 small batch : Noisy and bad- 일부만 보는 것이기 때문에 noisy and bad지만, 파라미터인 세타를 업데이트 하는데는 똑같이 쓰이기 때문에 훨씬 빠르게 계산할 수 있음
💣 장단점
- Window에 포함되지 않는 단어들은 업데이트에 대한 정보를 못 받음
- 실제로 가진 단어는 2m+1개인 것에 비해 컴퓨터는 전체 word vector인 2dv의 matrix를 주고받아야 함(Sparse gradient update : 그 matrix에서 몇개만 업데이트되는 드문 업데이트)
→ 효율성 문제 - 하지만 계산량이 적기에 학습이 빠름
다음으로 넘어아기 전에! Word2vec에 대한 이야기
- 왜 한 단어에 대해 두 개의 벡터(center일 때와 context일 때)를 사용하는가?
- 하나로만 하려면 할 수도 있지만 center word가 outside에도 있으면 처리하기가 더 복잡해져서..이렇게 함! - Word2Vec model 두가지
- Skip-grams (SG)
- center word를 input으로 넣어서 context word를 추측하는 방식
- Continuous Bag of Words (CBOW)
- context word를 input으로 넣어서 center word를 추측하는 방식
- Skip-grams (SG)
⇒ 우리가 여태 한 건 Skip Gram 방식임!
3) Negative Sampling
- 지금까지 우리는 순수한 softmax 방정식을 사용함
- 단순하지만 비싼 훈련 방식
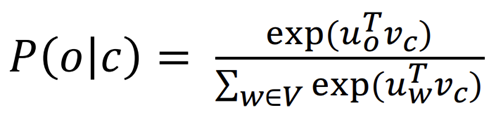
- 분모를 계산할 때 vocabulary에 있는 모든 단어에 대해 dot product를 하기 때문에 계산이 비쌈
- 단순하지만 비싼 훈련 방식
⇒ 그래서 Negative Sampling이 등장함
- Binary logistic regressions for a true pair VS serval noise pairs
- true pair : center word and a word in its context window
- noise pair : center word paired with a random word
- true pair와 noise pair에 대해 binary logistic regression을 학습시킴!
SGNS : Skip-Grams Negative Sampling
- Skip-grams model을 사용하는 word2vec에서 효율성을 높이기 위해 사용하는 기법
Overall objective function (maximize)
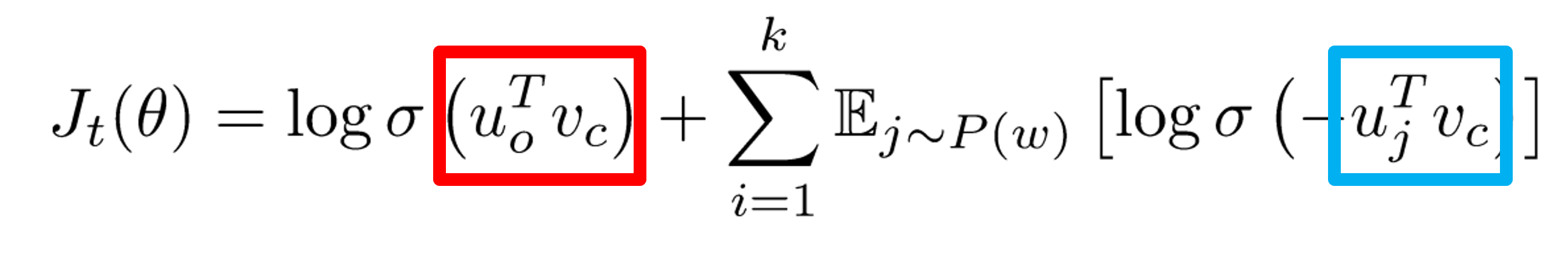
** 주의할 점 : 최소화하던 기존의 손실함수와는 달리 최대화된 상태임(여기에 마이너스를 곱해서 최소화시키려고!)
- 빨간 박스 : Dot product between true pair
- center word의 실제 context word로 이루어져 있으니, 이는 값이 크게 나와야 함
- 이를 logistic(sigmoid) function(=σ)에 넣으면 1에 가까운 값이 나옴
- 파란 박스 : Dot product between noise pair
- center word의 context에 존재하지 않는 단어들과의 내적이니 값이 음수로 나옴(서로 동떨어져있는 값이니까)
- 우리는 지금 최대화를 하고 있으니 음수는 곤란함. 그래서 앞에 마이너스를 곱하고 sigmoid에 넣어줌
- 음수와 음수가 곱해져 양수가 되었으니 sigmoid 에 넣은 결과 역시 1에 가까운 수가 나옴
(서로 아주 다른 벡터를 지녀 그 내적은 절대값이 큰 음수였으니 이젠 큰 양수가 되었으므로, 이를 sigmoid에 넣으면 1에 가까운 수가 나옴)
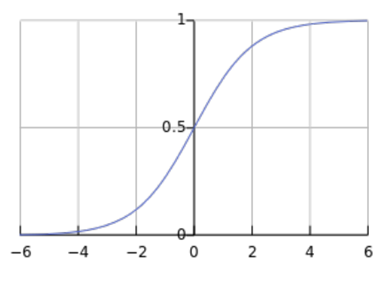
❓ Logistic(Sigmoid) function
- 임의의 실수를 0과 1사이의 확률로 매핑해줌
- dot product 값이 크다면 1에 가까운 값이 될 것
Objective function (minimize)
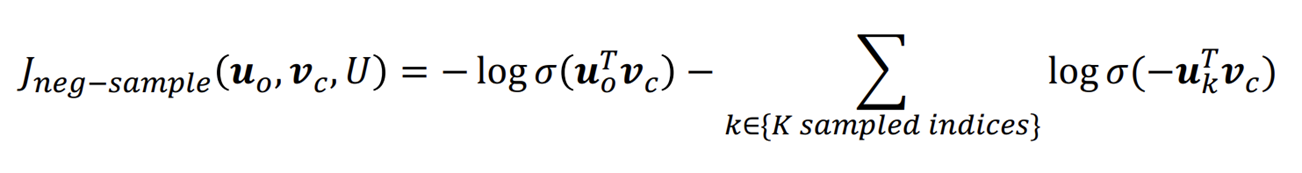 **이게 우리가 아는 그 최소화된 손실함수!
- 앞에서 본 Maximize 손실함수에 마이너스를 곱한 것과 같음
- K 개의 negative sample을 사용함
**이게 우리가 아는 그 최소화된 손실함수!
- 앞에서 본 Maximize 손실함수에 마이너스를 곱한 것과 같음
- K 개의 negative sample을 사용함
Random words
- 윈도우 내에 등장하지 않은 어떤 단어 가 negative sample로 뽑힐 확률
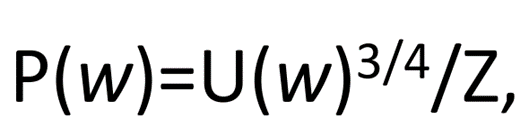
- U : 유니그램, Corpus에 등장한 각 단어 빈도 수를 전체 단어 수로 나눈 것 (해당 corpus에서 단어 w가 등장할 확률)
- 여기에 3/4 제곱을 함으로써 자주 나오는 단어와 그러지 못한 단어의 차이를 감소시킴
- and, a와 같은 단어보다 더 유용한 단어가 나올 수 있도록 확률을 높이기 위함
2. Co-occurence matrix
이 부분은 이해를 잘 못했다. 일단은 이해한 정도만 정리하는데, 어째서 co-occurence가 필요한지는 모르겠다.
co-occurence matrix?
- corpus에 많은 word가 있을 때, 단어들이 서로 어떻게 발생하는지를 count하고 matrix of counts를 만드는 것!
- co-occurence를 만드는 방법
- Window : 각 단어에 대해 window를 사용하여 window 내에 있는 단어들 카운트
- Word2vec과 유사한 방식
- Word-document : Window size가 전체 문서인 것과 같음
- 한 문서를 기준으로 각 단어가 몇 번 등장하는지를 카운트함
- 문서에 있는 많은 단어들 중 빈번하게 등장하는 특정 단어가 존재한다는 것을 전제함
- General topics 파악 가능
- Window : 각 단어에 대해 window를 사용하여 window 내에 있는 단어들 카운트
Example : Window based co-occurence matrix
- 윈도우 길이가 1일 때, 세 문장에 대한 매트릭스
- I like deep learning
- I like NLP
- I enjoy flying
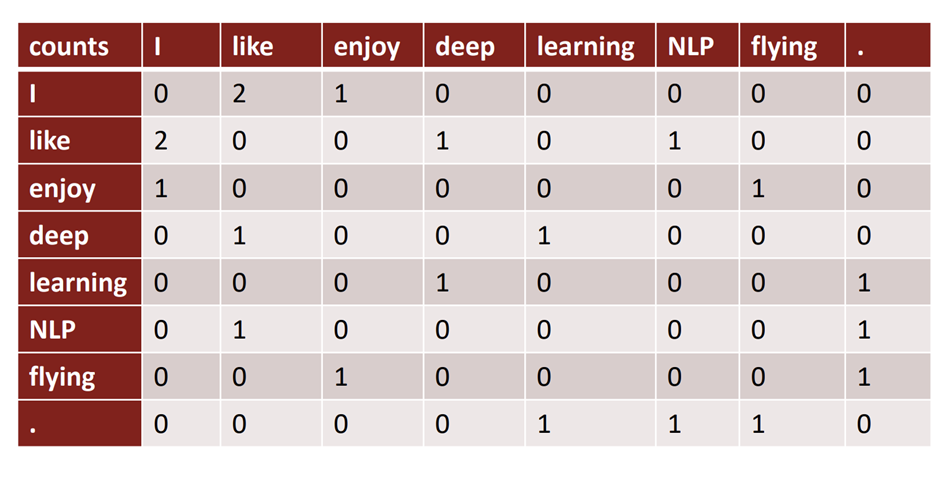
- 특징
- 단어의 수만큼 벡터 사이즈가 증가함
- 대부분의 셀이 0을 가짐
⇒ Low dimmensional vector가 되어야 함- 유의미한 정보를 고정된 적은 수의 차원에 저장시켜 dense vector가 될 수 있도록
→ 어떻게 차원을 줄일 것인가?
- 유의미한 정보를 고정된 적은 수의 차원에 저장시켜 dense vector가 될 수 있도록
차원 축소 기법 : SVD
Singular Value Decomposition : SVD (특이값 분해)
-
어떠한 matrix라도 가능하고, 3개의 matrix로 분해됨

-
그런데 Raw counts (위에서 본 것 같은 태초의 count based matrix)에 적용하는 건 잘 작동하지 않음
- "a", "the" 같은 단어들의 카운팅이 너무 커서 스케일링이 필요함
- 카운팅 횟수에 log 씌우기
- 최대값 정하기
- 해당 단어 무시하기
- "a", "the" 같은 단어들의 카운팅이 너무 커서 스케일링이 필요함
⇒ COALS라는 model은 이러한 방법을 사용하여 co-occurence matrix 개선에 성공함
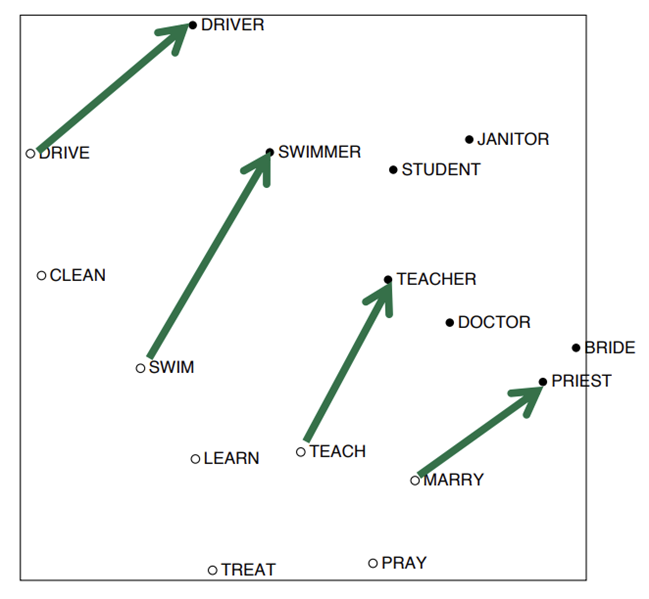
- 완전히 일치하지는 않지만, DRIVE -> DRIVER, SWIM -> SWIMMER 와 같이 같은 관계로 이루어진 단어들이 대략 평행하고 비슷한 크기의 화살표로 이어짐을 알 수 있음
3. GloVe algorithm
1) Towards GloVe : Count based vs Direct predict
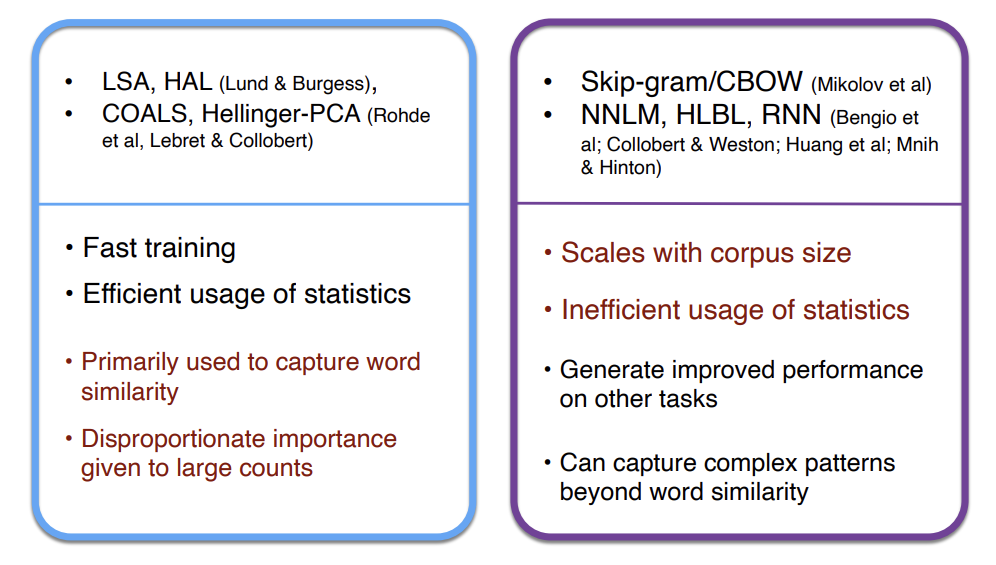
- Count based
- 수학적 카운트를 기반으로 COUNT BASED MATRIX를 만든 뒤 SVD 등을 사용해 차원을 축소한 후 사용함(COALS 등)
- 장점
- 훈련 속도가 빠름
- 전체적인 통계정보 파악에 유리함 -> 효율적인 통계정보 사용
- 단점
- 단어의 유사성만을 파악할 수 있음(단어 간 관계 등은 파악 불가)
- 빈도수가 클수록 중요하다고 판단함 (the, a와 같은 것들도 중요하다고 판단함)
- Direct Prediction
- Skip gram, CBOW와 같이 벡터를 사용해 바로 확률 예측
- 장점
- 단어 유사성뿐만 아닌 그 이상의 패턴 등을 파악할 수 있음
- 높은 수준의 성능을 보임
- 단점
- Corpus size만큼의 크기를 가짐(너무 커질 수 있음)
- 통계정보 사용이 효율적이지 못함
이 뒤에도 meaning component 등 내용이 더 있는데, 여기부터는 진짜 이해를 못하겠어서 아직 정리하지 못할 것 같다. meaning component를 계산할 때 왜 저런 계산식이 나오는지부터 GloVe 는 왜 저런 방식이 되는지를 차차 이해한 후에 본 블로그를 이어서 쓰고자 한다.


잘봤습니다.