SwingNet의 입력 영상은 CNN 기반의 MobileNet V2를 통과한다. 그렇다면 MobileNetV2가 뭔지부터...
MobileNetV2
Manifold of Interest
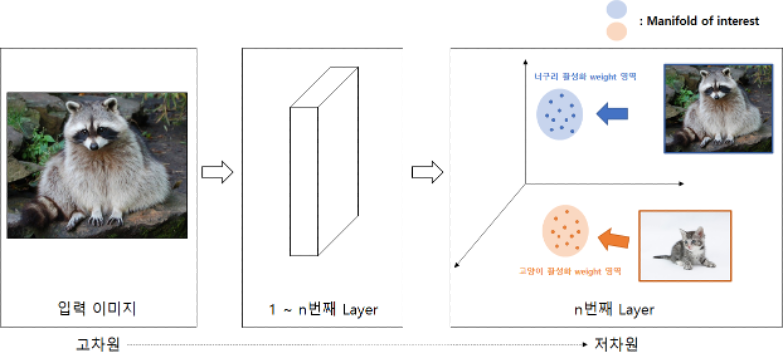
- 고차원의 정보는 저차원(subspace)에 mapping하여 표현 가능
- 이 때 Layer를 거쳐가며 저차원영역으로 전달되는 과정에서, Layer가 linear transformation이면 정보 보존
Linear Transformation
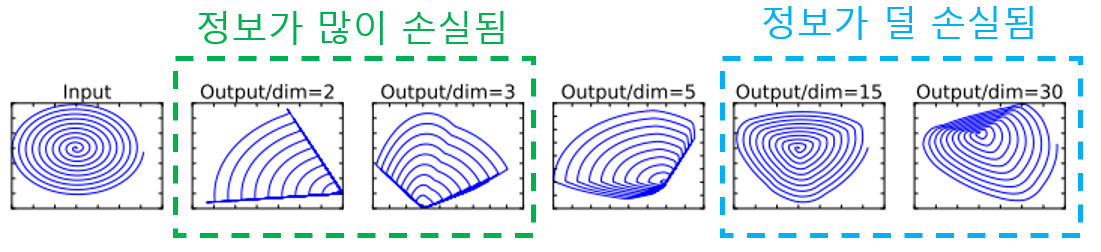
manifold of interest 양수이면 ReLU를 통과할 때 자기 자신을 반환한다 (정보 보존)
하지만 이 과정에서 필연적으로 정보의 손실이 발생하는데, 많은 채널을 사용할수록 정보가 더 보존된다.
Linear Bottlenecks
MobileNet V2에서는 이 저차원 mapping을 위한 linear transformation을 위해 bottleneck 구조를 활용한다.
Bottleneck 안에 있는 ReLU(비선형성)는 너무 많은 정보 손실이 일어나므로, 이것을 제거한 Linear Bottleneck 구조가 더 좋은 성능
→ 차원은 줄이되 manifold of interest(중요 정보)는 그대로 유지
= 네트워크 크기는 줄어들지만, 정확도는 그대로!
Inverted Residual Block
일반적인 Residual Bottleneck Block의 구조
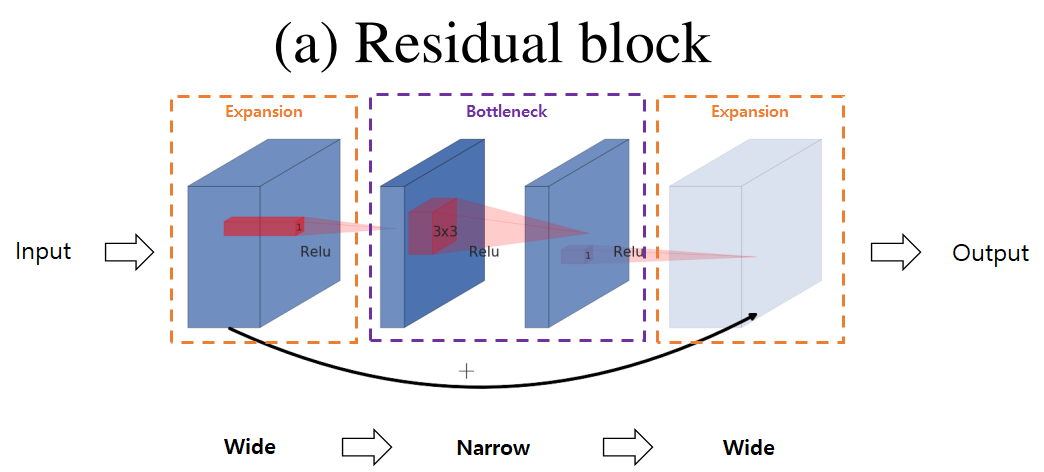
- 1x1 Conv layer로 적은 수의 채널의 bottleneck block 생성
- 3x3 Conv layer 통과 후 Residual Connection 연결을 위해 다시 1x1 Conv layer를 활용하여 많은 수의 채널의 expansion block 사용
- 저차원의 bottleneck block에 이미 manifold of interst가 보존됨
Inverted Residual Block
MobileNet V2는 Shortcut connection을 bottleneck block끼리 연결
Narrow → Wide → Narrow
형태의 Inverted Residual Block을 사용
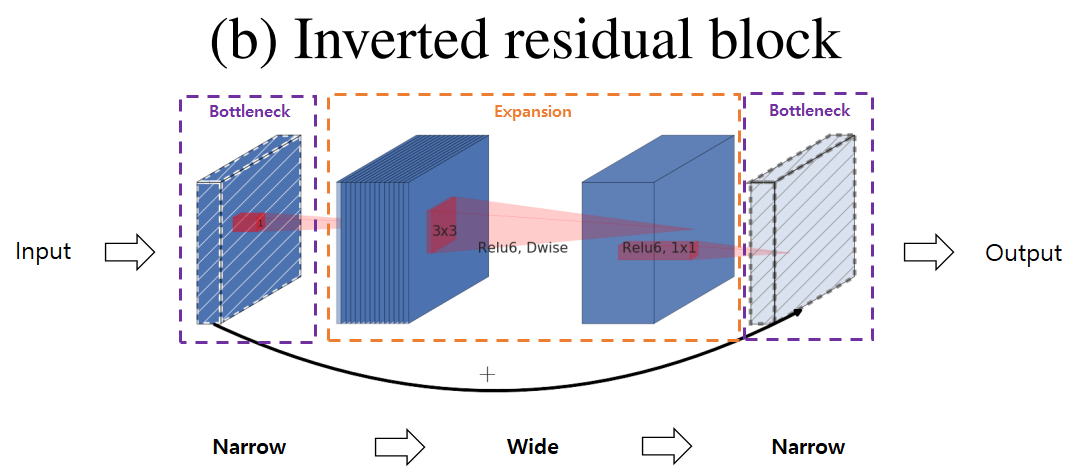
-
빗금 block: ReLU 등의 비선형 함수를 제거한 block
-
입/출력의 채널수가 낮기 때문에 Residual Block에 비해 연산량이 적고 메모리 효율이 좋음
아무튼 MobileNetV2는 Lightweight Depthwise Convolution을 자유롭게 사용할 수 있어서 모바일 어플에 잘 맞다는 장점이 있다!
SwingNet의 구조
본론으로 돌아와서, input 영상이 MobileNetV2를 통과하여 얻어진 feature가 bi-LSTM layer를 거치면 시간 정보가 입력된다.
bi-LSTM
- 정방향으로만 학습을 진행하는 대신, 마지막 노트에서 뒤에서 앞으로 (역방향) 실행되는 다른 LSTM을 추가하는 것
- 일반 LSTM 대비 역방향으로 정보 전달하는 Hidden Layer가 추가되므로 정보 처리가 유연하다!
근데.. LSTM이 무엇인고
LSTM = Long Short Time Memory
그 이전에 RNN (Recurrent Neural Network)가 있었다. 얘는 이전의 입력 데이터를 기억해서 다음 출력을 결정하는 모델인데, 입력 데이터가 길어지면 Gradient Vanishing Problem 때문에 이전의 정보를 제대로 기억하는 데에 문제가 있다.
그 래 서!
LSTM은 이 RNN의 그래디언트 소실 문제 해결을 위해 등장한 모델인데,
- 이전 정보를 오랫동안 기억할 수 있는 메모리 셀 가짐
- 긴 시퀀스 데이터 처리 가능
이라는 장점을 가진다.
근데 RNN이랑 그래서 뭐가 다르냐 하면...
메모리 셀의 값을 얼마나 기억할지 결정이 가능한 "게이트"가 있어서 필요한 정보만 기억하도록 제어가 가능하다.

(메모리 셀 안에 상태 정보를 변경하는 게이트가 있다!: Input Gate, Forget Gate, Output Gate와 함께 Cell State가 있다)

이건 SwingNet 안에서 LSTM이 작동하는 구조다. 골프 스윙과 같은 스포츠 동작은 시간에 따라 변하는 연속적인 데이터 이다. 각 순간의 동작이 이전의 동작과 연관되기 때문에, 단일 프레임을 사용해 골프의 swing event를 감지하는 것은 어려운 작업이다. 따라서 시간적 context가 중요한 요소가 되는데,
하지만 LSTM을 사용해 이러한 시간적 의존성을 잘 처리할 수 있다!
이렇게 시간 정보를 입력하고 나서, 최종적으로 softmax 함수를 적용하면 최종 결과값으로는 각 event 별로 Confidence 값(Event Probabilities)이 얻어진다.
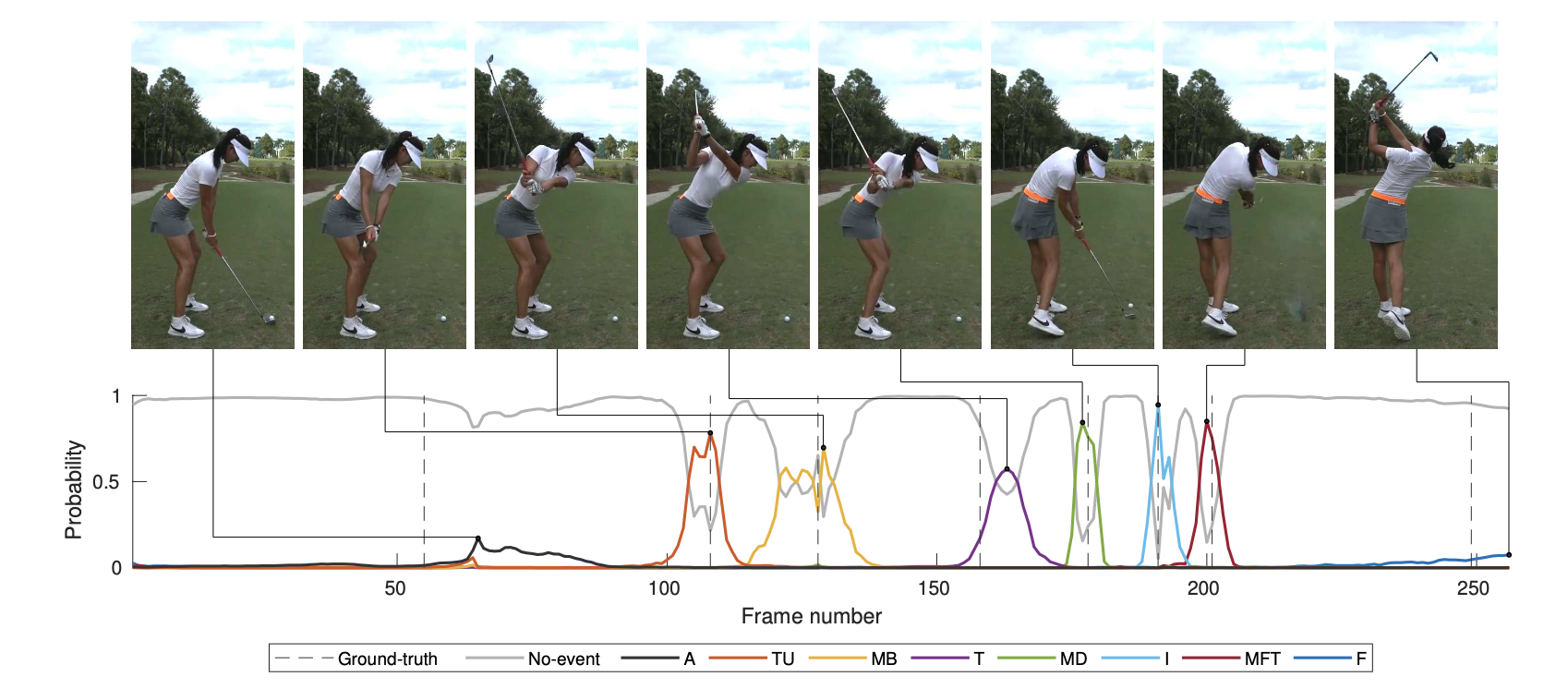
실제 Michelle Wie 선수의 스윙 동작을 input으로 넣었을 때 얻은 확률값들이다.
근데 Address(처음)와 Finish(끝) 단계의 확률이... 좋지 않다.
이제 우리의 프로젝트인 '손동작 인식을 통한 메시지 전송'을 위한 Human Pose Estimation에 대해 알아보고자 한다.
Human Pose Estimation (HPE)
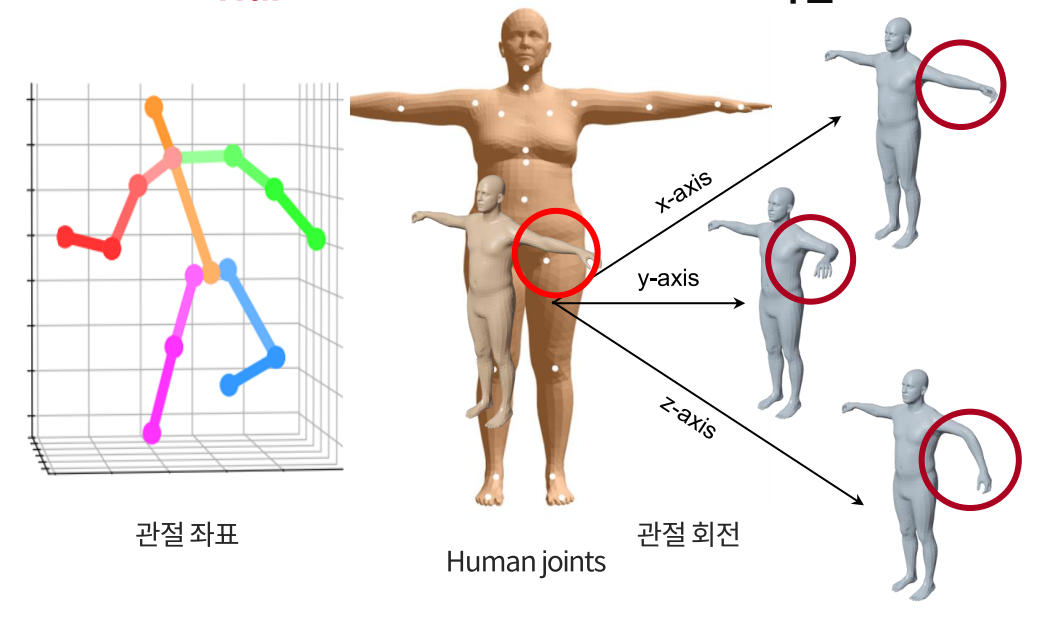
컴퓨터 비전을 통해 사람을 이해하는 것은 매우 중요하다. 이러한 분야를 Human Understanding Computer Vision (HUCV)라고 하는데, HPE는 이 HUCV의 아주 핵심 분야이다. 여기서 'Human Pose'라 함은, 사람 관절의 좌표, 회전을 의미한다. Pose Estimation(이하 P.E)은 대상 이미지나 영상 속 인체 부위가 갖는 방향성이나 위치를 감지(Detecting) + 연결(Associating) + 추적(Tracking)하는 것을 포함한다. 그 대상은 Semantic Key Point인데, 인간의 경우 예를 들어 "right shoulders", "left knees" 등이 있다. 사물이 경우 자동차라면 "left brake lights of vehicles"가 있다.
real-time 영상에서 semantic keypoint를 추적하는 것은 매우 큰 컴퓨팅 리소스를 필요로 하지만 최근 하드웨어와 모델 효율성이 크게 발전해서 구현이 가능해지고 있는 추세다.
Multi-Person HPE의 접근법
Bottom-up methods
- 신체의 모든 관절(joints)을 먼저 추정한 다음, joint들의 상관 관계를 분석해 특정 포즈나 사람 객체로 연결하여 그룹화하는 방식
- Ex. DeepCut 모델
- 관절을 모두 찾은 다음 연결을 하는 과정에서, 다른 사람 간의 관절을 한 사람으로 잇는 문제점이 발생할 수 있어 적절하게 매칭하는 데에 많은 시간이 걸림
- 정확도 낮음
- crop-resize 과정이 없어서 저해상도의 이미지가 입력되면 손목, 발목 등의 edge 검출이 힘듦
- 사람 Detection이 필요 없어서 속도가 빠르고 Real-time에 적용 가능하다는 장점이 있음!!
- 하나의 네트워크에서 진행하기에 효율적
Top-down
- 사람을 먼저 Detection(ex. mask R-CNN, YOLO)하고, Bounding Box 안에 있는 신체 관절을 추정
- 일반적으로 더 정확도 높음
- Detect된 사람들을 순회하며 joint를 찾기 때문에 속도가 느리고, 사람 수가 많아지면 계산량이 늘어남
문제점
Occlusion (폐색 현상)
- 사람이 사람에 의해 가려지거나, 다른 객체에 의해 가려져서 관절이 보이지 않는 경우
- 올바른 keypoint 추정이 어려워짐
- 각 keypoint가 낮은 Confidence 값을 얻게 됨
- 현존하는 데이터셋 (COCO, MPII) 등은 Occlusion을 고려하지 않음
→ 참고: Occluded Human Dataset API로 해결하고자 함
https://github.com/liruilong940607/OCHumanApi
Depth Ambiguity
- 3D 공간 상에서 카메라-사람 사이의 거리가 모호한 경우
- 사람의 크기, 관절 위치 추정이 어려움
- 3D 카메라 (RGB-D 카메라) 사용 또는 Multi-View 방법 필요
Truncation
- 이미지에서 사람의 일부가 잘려서, 해당 부분의 정보가 부족한 경우
2D Human Pose Estimation
- 인체의 keypoint의 2D 위치 / 공간 위치 추정
- 대표적 기법: OpenPose, CPN, AlphaPose, HRNet
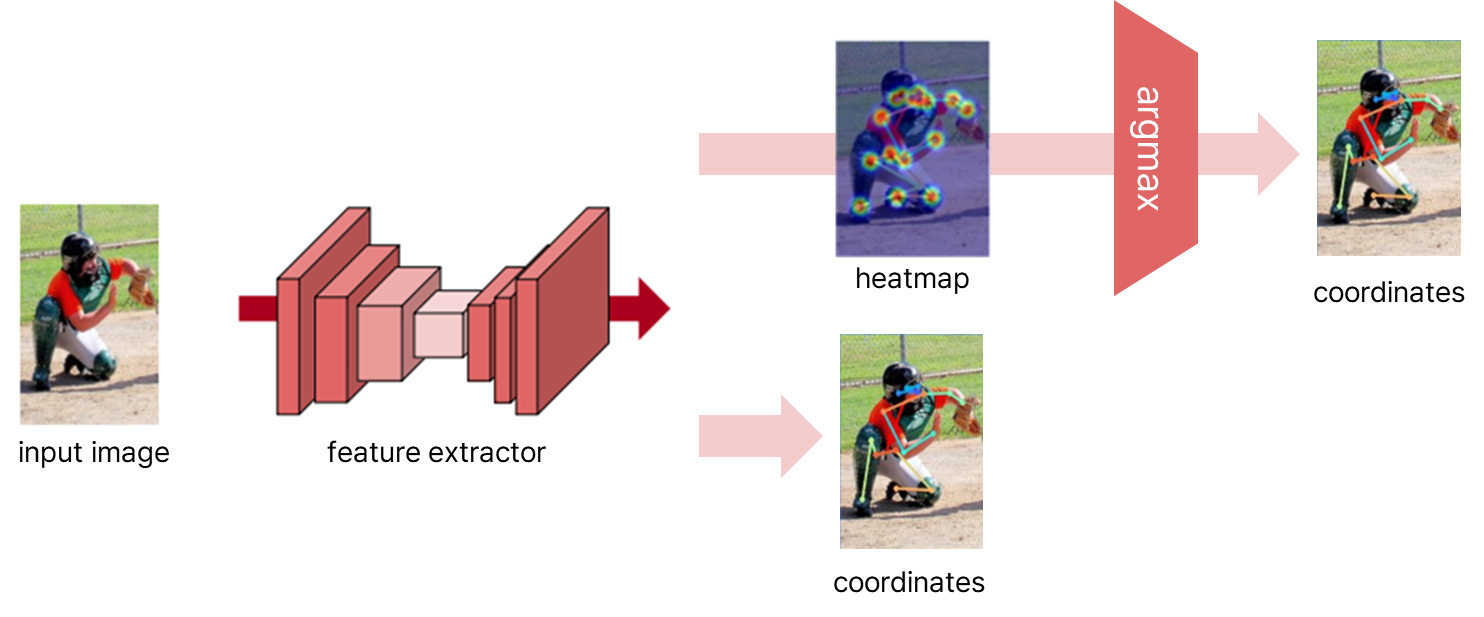
입력으로 이미지를 받고, Feature Extractor(ex. ResNet, Hourglass)가 입력 이미지에서 강하게 드러나는 feature를 Feature Map으로 추출한다.
- 바로 관절의 좌표 추정하거나
- Feature Map에서 각 관절의 위치에 대한 Gaussian blob을 모델링하는 heatmap을 예측
보편적인 MS COCO 데이터셋의 경우 서로 다른 17개의 keypoint(class)를 감지할 수 있는데, 이 때 세 개의 숫자 (x,y,v)가 annotated 된다.
x,y: target point의 좌표
v: keypoint인지 아닌지 여부 (key면 v=1, non-key면 v=0)
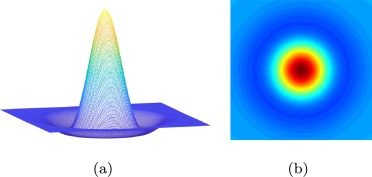
Gaussian Blob
- 2D 이미지에서 특정 위치를 중심으로 평균, 분산을 갖는 확률 분포를 나타냄
- HPE에서는 특정 관절의 위치를 표현
- 생성된 Gaussian Blob들을 연결하여 전체 자세를 추정
3D Human Pose Estimation
- 3D 공간 상에서 신체 관절의 위치 예측
- 3D 데이터셋을 얻는 게 상대적으로 어렵고, 정확한 image annotation에 많은 시간이 소요되며, manual labeling에 비용이 많이 듬..
- 입력 이미지에서 Feature Extractor를 통해 바로 3D 좌표 추정
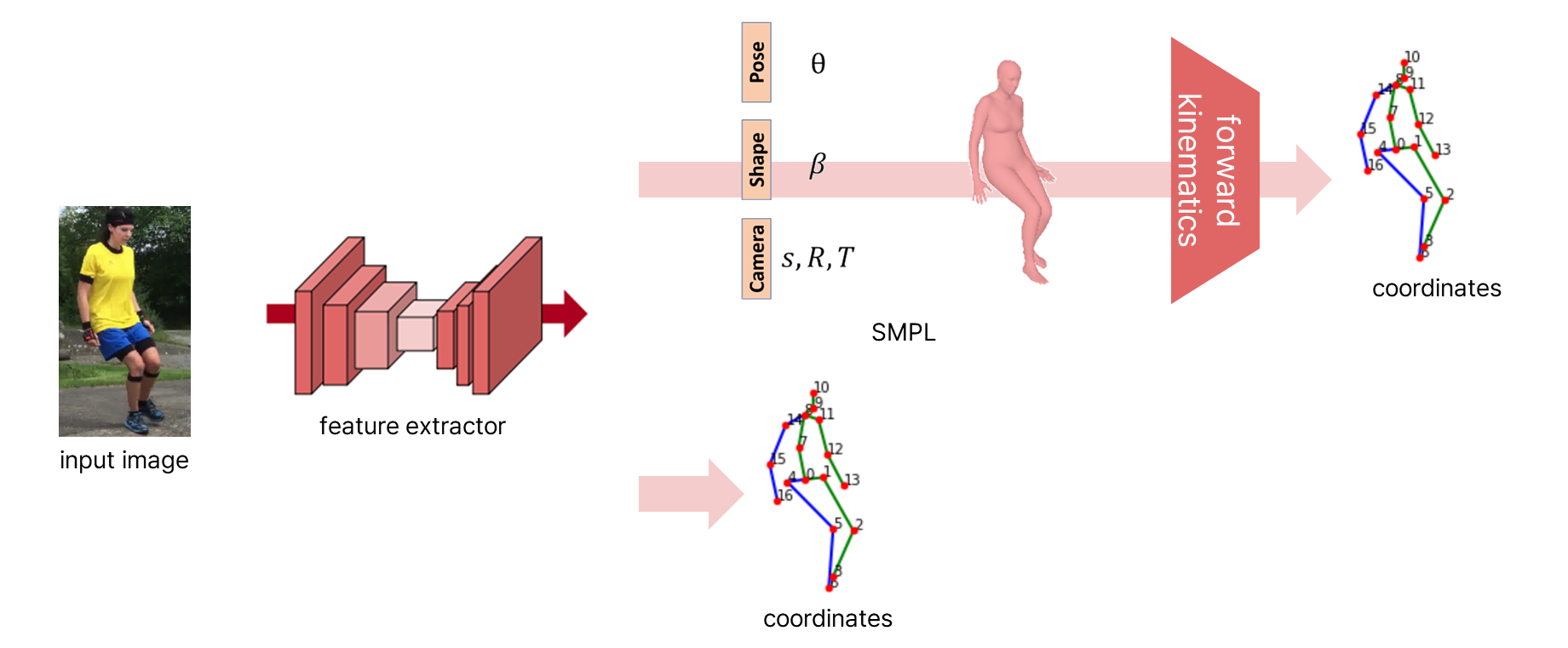
→ 입력 이미지와 3D 좌표의 매핑 관계를 직접 학습 - 입력 이미지에서 Feature 추출 후 SMPL 등의 3D 모델 예측
- 관절 회전에 관한 다양한 파라미터
- 예측된 모델, 입력 이미지 사용해서 Forward Kinematics 수행하여 3D 좌표 추정
- 높은 정확도와 안정성
Metric이란?
- 하드웨어/소프트웨어의 성능 측정을 위한 수치 값
- '어떤 기준으로 평가할 것인가?'에서의 그 기준!
