
개요
운영 중인 프로젝트를 내부 인프라에서 클라우드 환경으로 이전 계획이 있어 기존 아키텍처와 코드를 분석 중에 있었다. 팀 이동이 되어 본 프로젝트를 맡은 지 한달정도 되었던 상황이라 아직까지 완벽히 구조를 이해하지 못하고 있었고 사용해보지 않은 SCDF와 RabbitMQ를 사용하고 있어 해당 내용을 학습해보았다.
당장 SCDF 환경을 구축해야하는 상황이기에 개념적인 학습을 간단히 마친 뒤 로컬에서 환경을 구축해보았다.
RabbitMQ
우선 SCDF 환경을 구축하기 위해 어플리케이션을 개발해야하고 세가지 어플리케이션(Source, Processor, Sink)에서 사용 중인 RabbitMQ를 알아야 했다.
사실 메세지 처리와 관련된 기술로는 Kafka라는 것이 있다는 것 정도만 들어봤었고 학습 계획에만 넣어두고 미루다 보니 RabbitMQ라는 것이 있다는 것은 이번 프로젝트를 통해 처음 알게 되었다.
Kafka와 RabbitMQ를 비교하며 찾아보니 둘은 차이점이 분명했다.
먼저 Kafka는 분산 메시징 시스템으로, 하나의 topic(메세지)을 여러개의 partition으로 분산시켜 병렬로 처리한다. 때문에 주로 대용량 데이터 처리에 사용된다.
RabbitMQ는, AMQP 프로토콜(Client와 Middleware broker간의 메시지를 주고받기 위한 프로토콜) 구현을 위한 메세지 브로커이다. 메세지를 주고받기 위해 Producer는 Exchange로 메세지를 보내는데 Exchange는 4가지 타입(Direct, Topic, Headers, Fanour)이 있다. 각각 queue를 찾는 방법이 달라진다. Exchange는 Consumer의 queue를 찾아 메세지를 전달하고 Consumer는 queue에 있는 메세지를 소비한다.
정리하자만, Producer -> exchange -> queue -> consumer 순으로 메세지가 흐른다.
https://velog.io/@sdb016/RabbitMQ-%EA%B8%B0%EC%B4%88-%EA%B0%9C%EB%85%90
https://velog.io/@cho876/%EC%B9%B4%ED%94%84%EC%B9%B4kafka-vs-RabbitMQ
rabbitmq 설치 - brew
- https://velog.io/@ychxexn/MacOS-M1%EC%B9%A9%EC%97%90%EC%84%9C-RabbitMQ-%EC%84%A4%EC%B9%98%ED%95%98%EA%B8%B0
- https://primayy.tistory.com/74
Spring Application 개발
- https://dataflow.spring.io/docs/stream-developer-guides/streams/standalone-stream-sample/
- https://ppaksang.tistory.com/38
- https://tech.nexr.kr/9abeff57-79a1-405c-a8a6-ad6288883832
공식 문서와 여러 블로그를 참조하여 RebbitMQ를 활용한 간단한 메세지 처리 어플리케이션을 개발하였다.
Source에서 메세지를 생성하여 Processor에서 가공하고 Sink에서 DB(MongoDB)에 적재한다.
Source -> RabbitMQ -> Processor -> RabbitMQ -> Sink -> MongoDB
Source
public class MessageScheduler {
private final MessageProducer producer;
@Scheduled(fixedRate = 5000)
public void scheduleMessageProduction() {
Supplier<Message<String>> messageSupplier = producer.produceMessage();
log.info("Sent message: Hello, SCDF!, {}", messageSupplier.get());
}
}
public class MessageProducer {
@Bean
public Supplier<Message<String>> produceMessage() {
return () -> MessageBuilder.withPayload("Hello, SCDF!").build();
}
}- Scheduled를 통해 5초 마다 메세지를 생성하도록 하였다.
Processor
public class MessageProcessor {
@Bean
public Function<Message<String>, Message<String>> processMessage() {
return message -> {
String processedMessage = "Processed message: " + message.getPayload().toUpperCase();
log.info(processedMessage);
return MessageBuilder.withPayload(processedMessage).build();
};
}
}- 기존 메세지에 임의의 메세지를 추가하는 로직을 추가하였다.
Sink
public class MessageHandler {
private final MessageRepository messageRepository;
@Bean
public Consumer<Message<String>> handleMessage() {
return message -> {
String messagePayload = message.getPayload();
MessageEntity messageEntity = MessageEntity.builder()
.message(messagePayload)
.build();
log.info("Received message: {}", messagePayload);
messageRepository.save(messageEntity);
};
}
}- 메세지를 MongoDB document에 저장해주었다.
SCDF(Spring Cloud Data Flow)
이제 SCDF를 설치하고 Source, Processor, Sink를 배포하면 SCDF를 통한 Stream 관리가 가능해진다.
SCDF 설치
dataflow server의 경우 전용 데이터베이스가 필요한데 기본 h2로 설정되어 있고 대부분의 RDBMS를 지원한다.
간단히 설치페이지에서 설치한 뒤 실행해보자
nohup java -jar /Users/joon-yeonglee/Projects/scdf-test/spring-cloud-skipper-server-2.11.5.jar \
> /Projects/scdf-test/skipper-server.log 2>&1 &
# postgresql
nohup java -jar /Users/joon-yeonglee/Projects/scdf-test/spring-cloud-dataflow-server-2.11.5.jar \
--spring.datasource.url=jdbc:postgresql://localhost:5432/dataflow \
--spring.datasource.username=admin_ljy \
--spring.datasource.password=password \
--spring.datasource.driver-class-name=org.postgresql.Driver \
--spring.rabbitmq.host=localhost \
--spring.rabbitmq.port=5672 \
--spring.rabbitmq.username=username \
--spring.rabbitmq.password=password \
> /Projects/scdf-test/dataflow-server.log 2>&1 &- skipper 서버와 dataflow 서버가 있고 각각의 서버는 다음과 같은 역할을 한다.
- dataflow server : 대쉬보드를 제공하는 서버로, Stream, task의 등록과 deploy, undeploy를 담당한다. 관련 메타데이터를 db에 저장하는데 기본적으로 h2를 사용하여, 데이터를 활용하기 위해서 다른 관계형 데이터베이스를 연동해주는 것이 좋다. Stream, Task 등을 생성하여 배포를 실행하게 되면 직접 진행하지 않고 skipper sever로 위임하게 된다.
- skipper server : dataflow server에서 위임 받아 실제 배포를 실행하는 역할을 한다.
- https://programmer-chocho.tistory.com/13#SCDF%EB%A-%-C%--Spring%--Batch%--%EB%AA%A-%EB%-B%--%ED%--%B-%EB%A-%--%ED%--%--%EA%B-%B-
위 과정에서 dataflow server의 DB를 설정하는 단계에서 겪은 시행착오를 적어보았다.
- postgresql로 시도
- 바로 성공
- mysql 시도 (회사 프로젝트에서 mysql을 사용하여 시도해봄)
- 실패
- 공식문서를 보니 driver-call-name이 mysql이 아닌 mariadb로 된 것을 확인
https://docs.spring.io/spring-cloud-dataflow/docs/current/reference/htmlsingle/#configuration-local-rdbms - sh 파일에서 &기호를 제대로 인식하지 못함 -> \로 이스케이프 해줘야 함
- 실패 시 flyway_schema_history_dataflow 테이블 데이터가 생성된다. 다시 실행하기 전 삭제해주어야한다.
- 공식문서를 보니 driver-call-name이 mysql이 아닌 mariadb로 된 것을 확인
추가로 rabbitmq 4.0 버전부터 spring application.yml의 group속성을 활용하여 queue name을 지정할 수 있는 기능이 deprecated 되어 사용 시 rabbitmq 페이지에서 경고 문구가 뜬다. queue name은 자동으로 생성되니 굳이 사용하지 않아도 될 것 같지만 추후 재시도 기능을 적용해볼 때 추가로 알아봐야겠다.

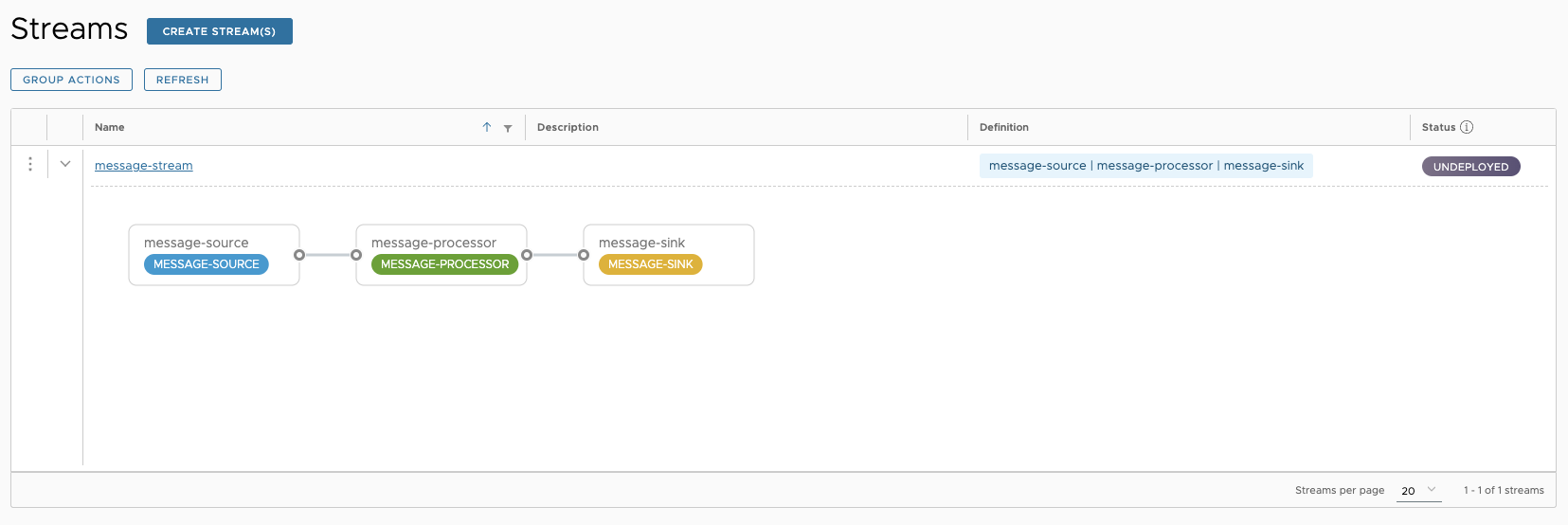
- Application과 Stream 등록은 아래 글을 참조하였고 추후 업데이트 시 활용 가능하도록 스크립트를 작성하였다.
- https://rhgustmfrh.tistory.com/47
# Define the version and the app names
version="1.0-SNAPSHOT"
apps=("message-source" "message-processor" "message-sink")
for app_name in "${apps[@]}"; do
project_dir="/Projects/JHome/${app_name}"
file_path="${project_dir}/build/libs/${app_name}-${version}.jar"
echo "Building ${app_name}..."
cd "$project_dir" && ./gradlew build
# Check if the file of specified version exists
if [ -f "$file_path" ]; then
echo "Installing $app_name version $version..."
mvn install:install-file -U \
-Dfile="$file_path" \
-DgroupId="com.jhome" \
-DartifactId="${app_name}" \
-Dversion="${version}" \
-Dpackaging=jar \
-DlocalRepositoryPath="/.m2/repository"
else
echo "File $file_path does not exist. Skipping $app_name."
fi
done마치며
회사 프로젝트를 통해 Spring Cloud를 활용한 Micro Service 구현과 Spring Cloud Data Flow를 접하게 되었고 실제 동일한 환경을 구축해보려고 시도하였다.
로컬 환경에서 비슷하게 구현은 완료 하였고 시스템 배포와 관리적인 면에서 유용한 점을 발견하였다.
이제 구축된 환경에 유의미한 기능을 추가해보려고 한다.
