
범주형 변수와 연속형 변수 사이의 관계를 파악할 시에 범주형 변수가 가지고 있는 level에 따른 각 그룹 별 연속형 변수의 분포, 그 중 특히 평균을 파악하는 것은 매우 중요한 일입니다.
예를 들어 독립표본 t 평균 검정, 일원분산분석, 이원분산분석(factorial design)을 하기 전에 각 그룹 별 연속형 변수의 평균 차이를 시각화하는 것이 필요하며, R에서는 gplots 패키지에서 plotmeans() 함수라는 아주 유용한 함수를 제공하고 있습니다.
먼저 두 그룹에 따른 연속형 변수의 평균 차이를 plotmeans() 함수를 통해 시각화해보겠습니다. smoker 변수는 범주형 변수로써 2개의 level을 가지고 있으며 bmi 변수는 연속형 변수입니다.
plotmeans(bmi ~ smoker, ins, mean.labels = T)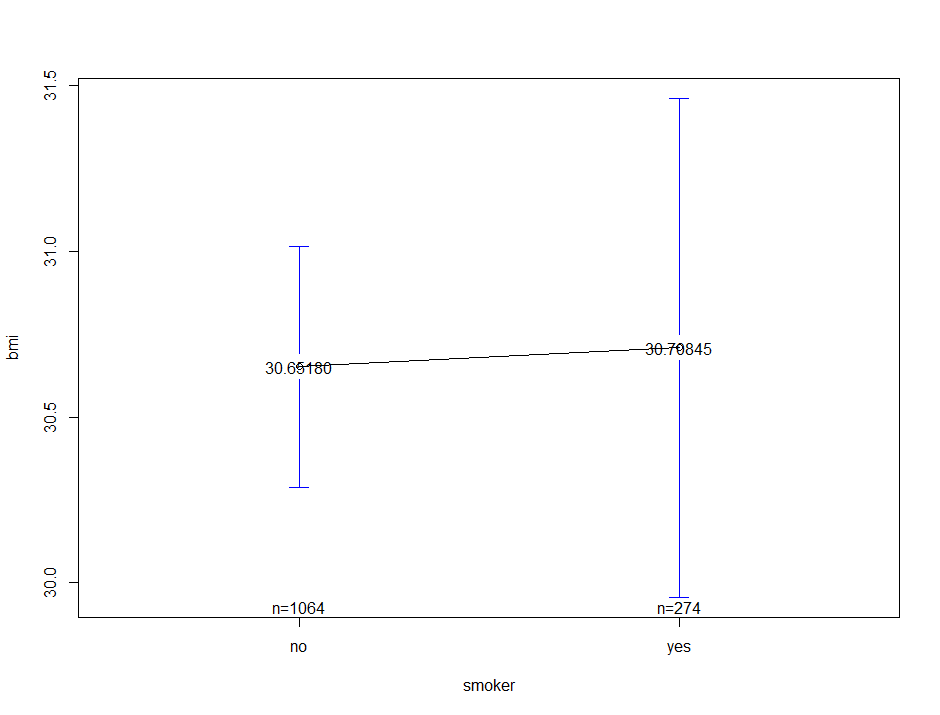
smoker 변수가 가지고 있는 2개의 level, 즉 비흡연 그룹과 흡연 그룹에 따른 bmi 평균의 차이를 시각화했습니다. plotmeans() 함수에 formula 형식으로 값을 넣어준 다음 mean.labels 인자를 T로 설정하게 되면 각 그룹 별 평균값 또한 나타낼 수 있게 됩니다.
물론 plotmeans() 함수를 사용할 수 없을 경우에는 ggplot2를 활용해 충분히 시각화할 수 있습니다.
이번에는 ggplot2의 geom_line() 함수를 활용해 앞서 만들었던 그래프를 똑같이 따라해보겠습니다.
ins %>% group_by(smoker) %>% summarise(mean = mean(bmi)) %>%
ggplot(aes(x=smoker, y=mean, group = 1)) + geom_line(size=2) + geom_text(aes(label = round(mean,2)), size = 10, color = "black")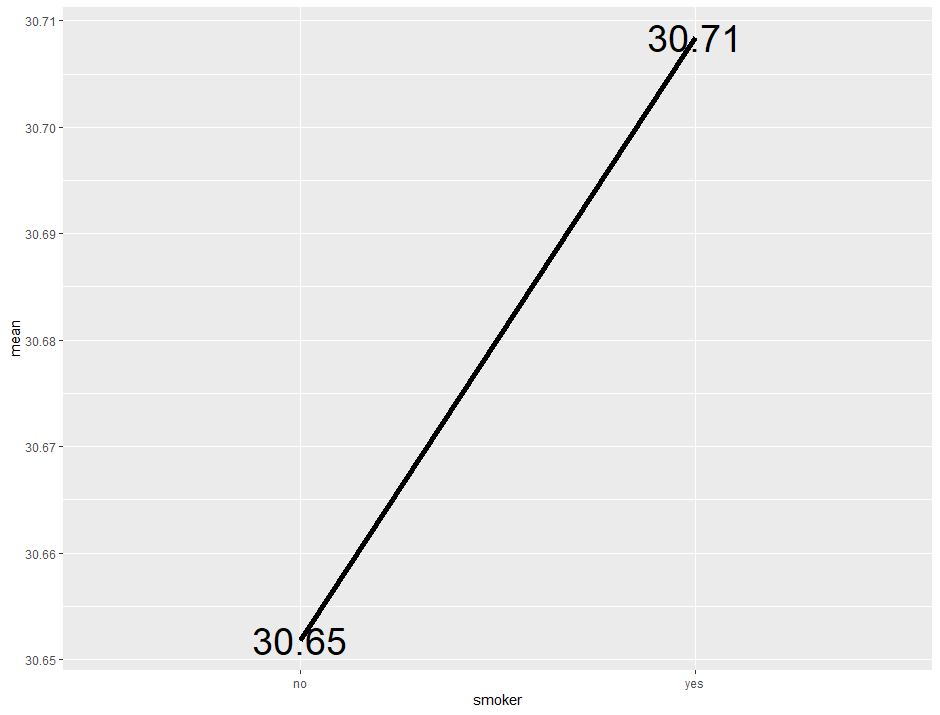
smoker 변수를 기준으로 그룹화한 다음, 각 그룹의 bmi 평균을 구한 데이터프레임을 바탕으로 geom_line() 함수와 geom_text() 함수를 사용해 시각화했습니다.
plotmeans() 함수를 사용하게 되면 이렇게 코드가 길어질 필요가 없이 단 한줄의 간단한 코드로 같은 시각화 결과를 얻을 수 있게 됩니다.
이번에는 여러 개의 그룹 별 bmi 평균 차이를 시각화해보겠습니다. 과정은 앞선 코드와 유사하며, region 변수는 총 4개의 level을 갖는 범주형 변수입니다.
plotmeans(bmi ~ region, ins, mean.labels = T)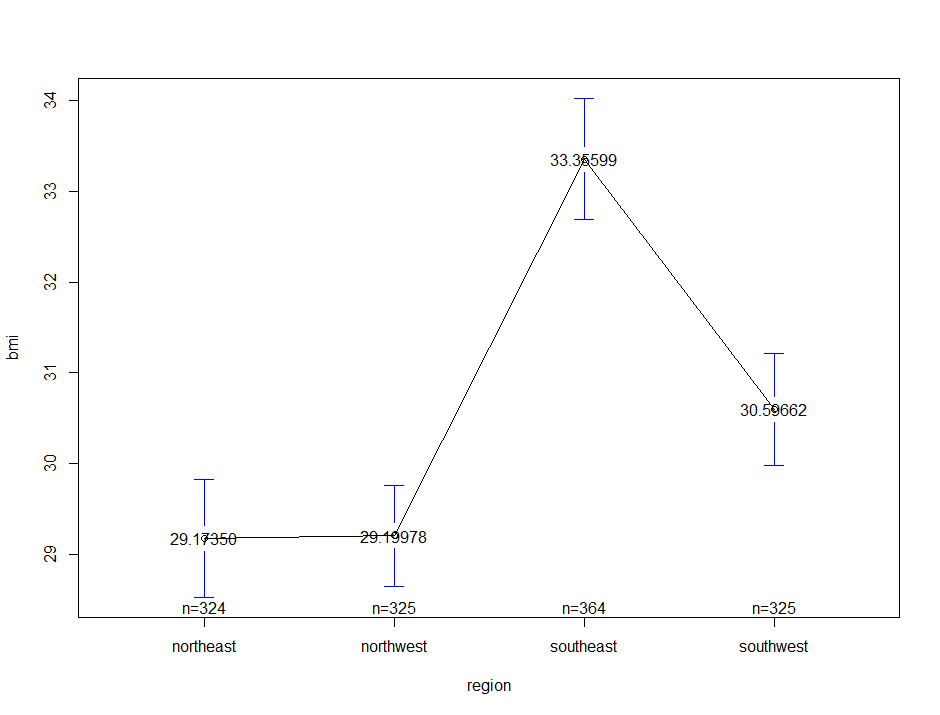
ins %>% group_by(region) %>% summarise(mean = mean(bmi)) %>%
ggplot(aes(x=region, y=mean, group = 1)) + geom_line(size=2, color = "tomato") + geom_text(aes(label = round(mean,2)), size = 10, color = "black")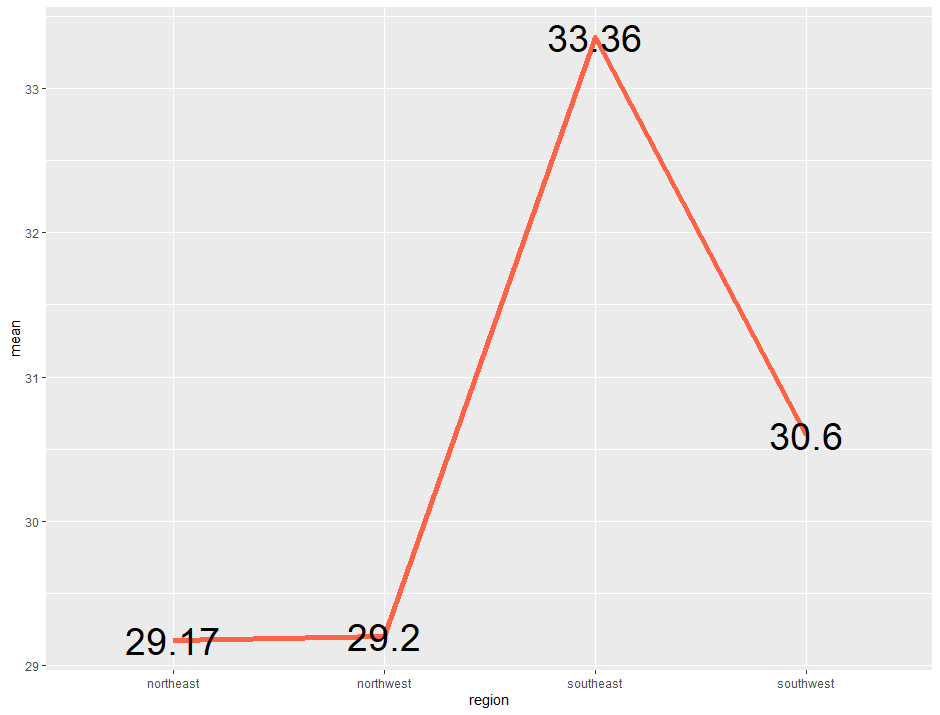
이처럼 plotmeans() 함수와 ggplot2를 활용하여 여러 개의 그룹 별 평균 비교 그래프 또한 그려보았습니다.
보시다 싶이 plotmeans() 함수를 활용하게 되면 코드의 길이를 대폭 줄일 수 있기 때문에 여건이 되신다면 plotmeans() 함수를 사용하시는 것을 추천드립니다.
