[논문리뷰] Deep Reinforcement Learning with Double Q-learning
Deep Reinforcement Learning with Double Q-learning
Abstract
-
Q learning의 overestimation problem: max Q값 사용 -> overestimation of Q values
1) common하게 발생하는가?
2) 성능을 저하시키는가?
3) 해결방법? -
ANSWERS
1) DQN은 일부 게임에서 상당한 overestimation을 겪음.
2) 이를 줄이면 성능이 향상됨.
(if overestimation is not uniform, not concentrated at important states, then it can lead to negative effects)
3) Double Q learning을 large function approx까지 확장해서 적용.
-
이전 연구에서 지목되었던 overestimation의 원인: asymptotic error + noise
-
DQN은 low asymptotic error + prevent effects of noise로 해결했음에도 불구하고, overestimation이 발생
Double Q learning
-
DQN에서는 action selection, evaluation에 같은 network(online Q)을 사용함.
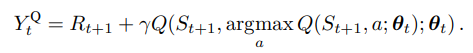
-
DDQN에서는 두 개의 network로 각각 action selection()과 evaluation()을 담당, 번갈아가면서 하나씩 update
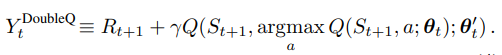
Overoptimism
-
overestimation lower bound
even if (평균 error=0), 즉
원인에 무관하게 error가 있으면 다음과 같이 overestimation이 발생
-
action의 수 m이 증가할수록 overestimation lower bound는 감소할 것 같지만, 실제로는 action이 늘어날수록 overestimation error은 증가
overestimation generality
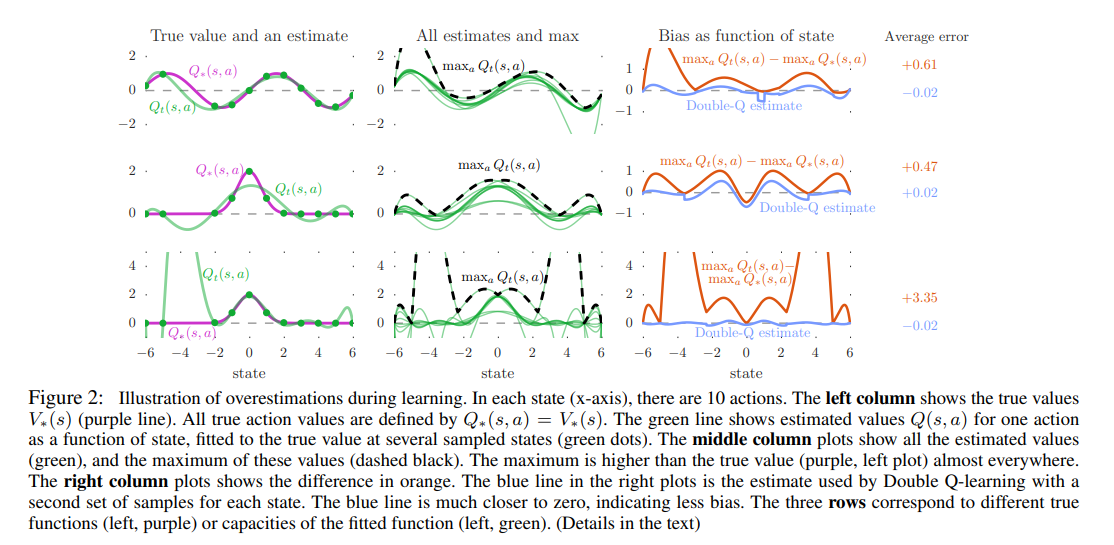
left column : 특정 action a에 대한 estimate
-
초록색 점에서 sample된 estimated 는 true 에 대해 error 발생.
-
또한 sample된 점도 정확히 맞추지 못하는데,
1,2번: function approx is not flexible enough
3번: flexible to match all samples, but overestimation is higher
=> 오히려 nerual net과 같은 flexible func approx을 사용하면 overestimation 발생할 수 있다. overestimation은 general한 현상이다.
middle column : 모든 action a에 대한 estimate & max
right column : max - true = error
결론
실제로는 true Q value sample이 아닌 sample error가 있을 뿐더러, 부정확한 Q value에 대해 bootstrap을 하면 overestimation이 심해짐. 또한 overestimation은 실제로는 uniform하지 않은 error를 발생시킴. 즉, 어떤 state가 중요한지 잘못된 정보를 흘림.
+ uncertain value에 대한 exploration bonus와는 다름. update 후에 certain한 값에 대한 overestimation임.
Double DQN

DQN의 target network 로 evaluation
action selection에는 똑같이 사용
Results
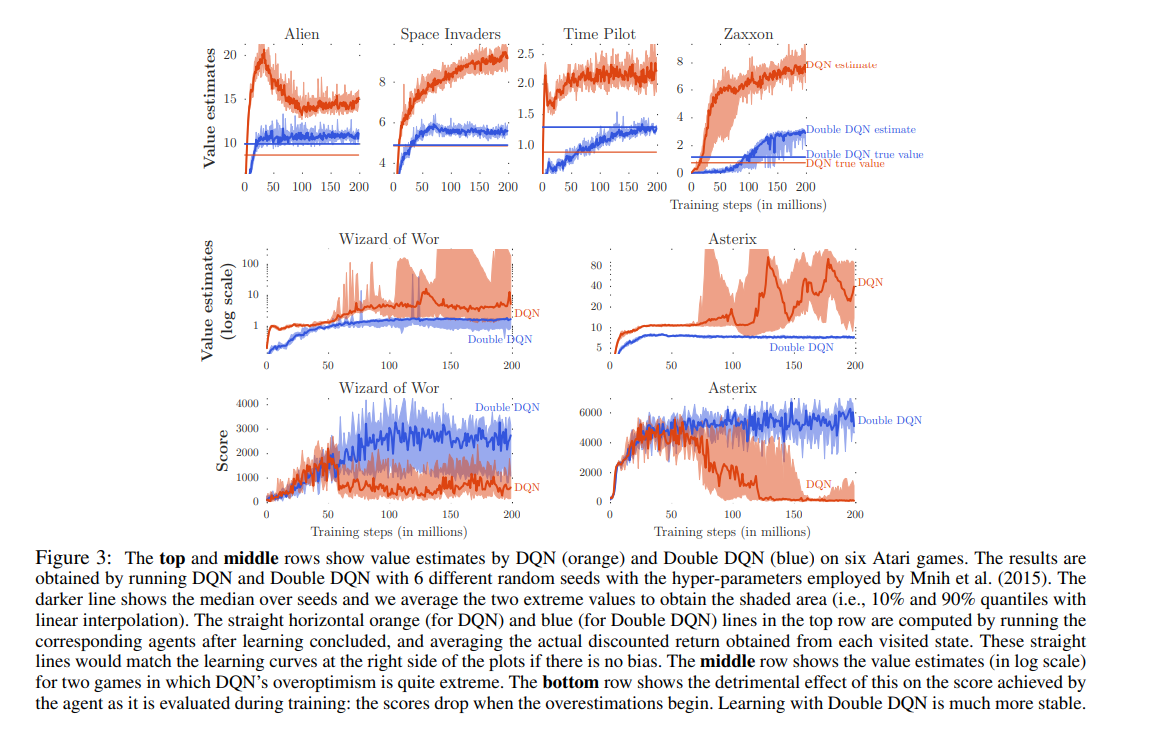
DQN True Q val average vs DQN Q val average vs DDQN Q val average, True val average
-
DDQN은 true Q val에 훨씬 가깝게 학습, overestimation이 적음.
-
True Q val은 best learned policy로 실제 reward를 계산하여 평균냄. true DDQN(파란선) > true DQN(주황선)이라는 것은 reward값이 높은 더 좋은 policy를 학습했다는 것임.
-
DDQN은 overestimation을 줄여서 learning stability를 향상(마지막 줄)
-
DDQN은 다양한 위치의 (human play에서 sample된) start point에서도 robust하게 잘함. DQN보다 generalization을 잘했기 때문이다.
