텐서플로 공부 - 2
❤️ 모델 정의
- 모델을 정의하는데 방법은 총 3가지로
sequential API,Functional API,Model subclassing API가 있다
(1)Sequential API를 이용하는 법
- 직관적이고 간결해 딥러닝을 처음 접하는 사람에게 적합
- 텐서플로 2에서 케라스를 이용한 sequential API 는 아래 그림과 같은 구조로 동작한다.
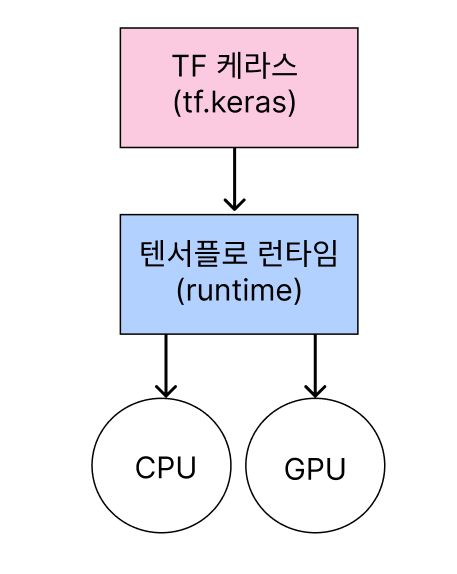
#텐서플로우에서 케라스를 사용하는 코드
from tensorflow.keras import models, Dense
model = tf.keras.sequential()- 텐서플로우 안에 있는 케라스 라이브러리를 가져온 뒤 라이브러리 안 api 는 tf.keras로 패ㅣ지로 제공된다.
- 모델을 정의하는 방법을 선택한 후
계층(layer)을 만든다.
 - 계층은 x를 입력받아 y로 출력하는 형태의 계산을 표현
- ex)
y=wx+b의 계산을 하기 위해서는 딥러닝 기본층인밀집층(은닉층을 사용한다.밀집층은 입력과 츨력을 연결해주고, 입력과 출력을 각각 연결하는 가중치를 포함하고 있다. - 밀집층은 add라는 메서드 4를 사용해 모형에 계층을 추가.
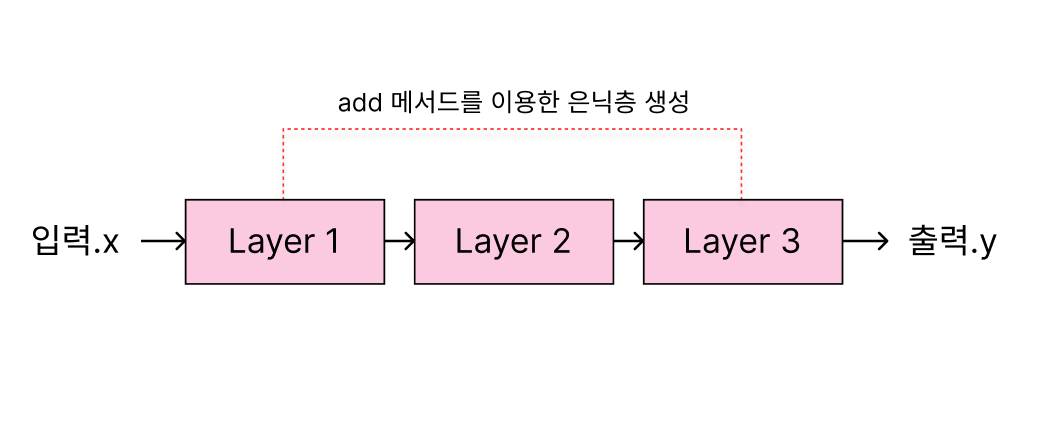{kind=link}
model.add(Dense(4,activation="sigmoid", input_shape(4,), weights=(w,b), name="dense1"))
❗ 한계
- sequential API는 대중적으로 많이 사용하나 단순하게 층을 여러개 쌓는 형태이므로 복잡한 연산을 하는 모델을 생성할 때는 한계
(2) Functional API를 이용하는 방법
Functional API는 앞서 말한Sequential API의 한계를 극복할 수 있다.- 입력과 출력을 사용자가 정의해서 모델 전체를 규정할 수 있기에 다중 입력과 다중 출력등 복잡한 모델을 정의할 수 있다.
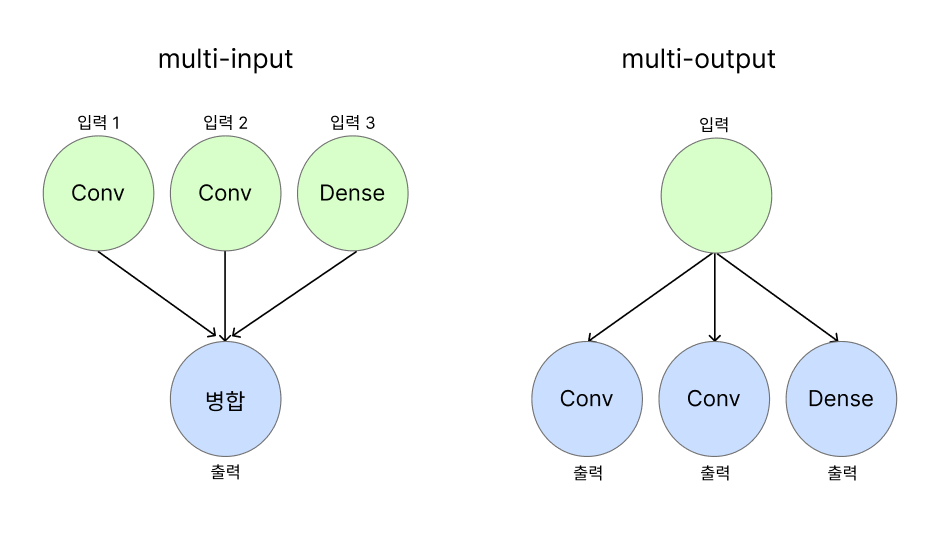
1) Functional API와 Sequential API 차이
- Functional API는 입력 데이터 형태를 input()의 파라미터로 사용해 입력층을 정의해줘야 한다.
- 이전 층을 다음 층의 입력으로 사용한다.
- model()에 입력과 출력을 정의한다.
from tensorflow.keras.layers import Input, Dense
from tensorflow.keras.models import model
inputs = Input(shape=(5,)
x = Dense(8, activation="relu")(inputs)
x = Dense(4, activation="relu")(x)
x = Dense(1, activation="softmax")(x)
model = Model(inputs, x)- 위의 코드는 functional API를 이용한 예시 코드이다.
- 간단한 구조 모델을 만들 때는 sequential API를 사용하고 직관적이며 빠르고 복잡한 구조의 모델을 만들땐 Functional API를 사용하는게 대체적이다.
(3) Model Subclassing API를 이용하는 방법
- Functional API와 별 차이 없지만 자유롭게 모델을 구축할 수 있다.
💙모델 컴파일
옵티마이저 (optimaizer): 데이터와 손실함수를 바탕으로 모델의 업데이트 방법을 결정한다.
손실함수(loss function): 훈련하는 동안 출력과 실제 값 사이의 오차를 측정한다지표(metrics): 훈련과 테스트 단계를 모니터링하여 모델의 성능을 측정
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy',metrics = ['accuracy'])optimizer='adam': 아담 옵티마이저 사용loss='sparse_categorical_crossentropy': sparse_categorical_crossentropy는 다중 분류에서 사용되는 손실함수metrics = ['accuracy']: accuracy는 훈련에 대한 정확도를 나타내는 것. 1에 수렴할수록 좋은 모델.
💜 모델 훈련
- 모델 훈련은 만들어둔 데이터로 모형을 학습시킨다.
- 학습시킨다란 y=wx+b라는 매핑 함수에서 w와 b의 적절한 값을 찾는다는 의미
- w와 b의 임의값을 적용해 모델에 데이터를 입력하면서 오차를 구한다.
모델훈련 예시코드
model.fix(x_train, y_train, epochs=10, batch_size=100, validation_data=(x_test,y_test), verbose=2)x_train': 입력데이터y_train': 정답 데이터셋epochs=10: 학습데이터 10번 반복batch_size=100: 한번에 학습할 때 사용하는 데이터 개수(100개)validation_data=(x_test,y_test): 테스트 데이터를 나타내는 것. 데스트 데이터를 사용하면 각 에포크마다 정확도도 함께 출력. 이 정확도는 훈련이 잘되는지 확인할 수 있을 뿐 실제로 모델이 테스트 데이터를 학습시키진 않음verbose=2: 학습 진행상황을 보여줄지 지정하는 것으로 1값을 설정하면 학습 진행 상황을 볼 수 있음
💚 모델 평가
- 주어진 데이터셋을 사용해 모델 평가
- 평가가 끝나면 테스트 데이터셋에 대한 오차, 정확도가 결과로 표시
모델평가 예시코드
model.evaluate(x_test,y_test, batch_size=40)x_test: 검증데이터y_test': 정답 데이터셋batch_size=100: 한번에 학습할 때 사용하는 데이터 개수(32개)
🧡 훈련과정 모니터링
- 텐서보드를 이용하면 학습에 사용되는 각종 파라미터값이 어떻게 변화하는 지 시각화해 볼 수 있다.
예시코드
log_dir="logs/fit/"
tensorboard_callback = tf.keras.calback.TensorBoard(log_dir, histogram_freq=1)
model.fit(x=x_train,
y=y_train,
epochs=5,
validation_data=(x_test, y_test),
callbacks=[tensorboard_callback]}-
tensorboard_callback의 각 파라미터는 아래와 같다
tf.keras.calback.TensorBoard(log_dir, histogram_freq=1)
-log_dir: 로그가 저장될 디렉토리 위치 지정
-histogram_freq=1: 모든 에포크마다 히스토그램 계산을 활성화한다. 기본값은 0으로 히스토그램 계산이 비활성화 돼 있음 -
텐서보드 사용을 위해서는 콜백함수를 만들고 앞서 만든 log_dir변수를 넣어준다. 마지막으로 model.fit메서드의 마지막 파라미터로 callback에 tensorboard_callback을 넣은 후 cmd 창에 아래 명령어를 입력하면 텐서보드가 실행된다.
tensorboard --logdir=./logs/fit/
🧡 모델 사용
예시코드
model.predict(y_test)
먀먀먐