AIOps를 단순히 “이상 탐지 도구”로 이해하면 마케팅 카피는 될 수 있어도 실제 시스템을 설계하기 어렵습니다.
1주차는 AIOps가 무엇인지를 정확히 정의하는 것에서 시작합니다.
Observability·SRE·DevOps와의 관계를 정리하고, AIOps가 소비하는 Telemetry 데이터의 유형과 수집 과정에서 발생하는 현실적 제약까지 살펴봅니다.
1. AIOps 정의 — 무엇이 아니고 무엇인가
1.1 “AIOps = 이상 탐지”는 왜 틀렸나
이 오해는 도입 범위와 기대치를 잘못 설정하게 만드는 원인입니다.
실제로 어떤 판단 오류가 생기는지 아래 표를 통해 확인합니다.
| 오해 | 실제 |
|---|---|
| 이상 탐지 도구 | 이상 탐지는 AIOps의 입력 처리 단계 중 하나일 뿐 |
| 알림을 더 잘 울리는 시스템 | 알림 노이즈를 줄이고 의사결정을 가속하는 계층 |
| ML 모델 = AIOps | ML은 AIOps 안에서 사용하는 수단 |
| 단일 플랫폼 | Observability → AIOps → 자동화 파이프라인의 중간 계층 |
1.2 정확한 정의
AIOps = Observability 위에 위치하는 운영 의사결정 보조 계층다양한 운영 데이터를 AI/ML로 처리하여 아래 기능을 수행합니다.
- 원인 추정 (Root Cause Analysis)
- 우선순위화 (Alert Prioritization & Noise Reduction)
- 상황 요약 (Context Summarization)
- 조치 추천 및 자동화 (Remediation Suggestion / Automation)
입력 범위: AIOps의 입력은 Observability 데이터(Logs/Metrics/Traces)만이 아닙니다.
alerts/events,deployment·change events,topology/CMDB,incident·ticket데이터까지 포함합니다.
[업계 동향 — Gartner 2025]
Gartner는 2025년 Market Guide에서 AIOps 플랫폼 시장을 이벤트 인텔리전스 use case 중심으로 재프레이밍하며 “Event Intelligence Solutions(EIS)” 를 핵심 범주로 제시했습니다.
주요 벤더(Datadog, Dynatrace, IBM, ServiceNow)는 여전히 AIOps 용어를 사용 중이며, EIS는 업계 전반에서 완전히 정착된 표준 용어는 아닙니다.[EIS 5가지 핵심 Capability]
Gartner EIS의 5가지는 엄격한 순차 파이프라인이 아니라 상호 작용하는 핵심 역량(capability) 집합입니다.
특히 Pattern Recognition과 Correlation은 병렬 실행되거나 반복적으로 상호작용합니다.
# Capability 역할 1 Cross-domain Event Ingestion Logs·Metrics·Traces·CMDB·변경 이벤트·티켓 등 이종 소스에서 이벤트를 수집 — 실시간 스트리밍과 과거 데이터 분석을 모두 지원 2 Topology Assembly 서비스·인프라 의존성 그래프를 구성·갱신 (CMDB 정적 데이터 + 서비스 디스커버리·Trace 기반 동적 업데이트) 3 Event Correlation & Enrichment 관련 이벤트를 단일 인시던트로 그룹화하고 CMDB·배포 이력·SLO 데이터 등으로 컨텍스트 보강 4 Pattern Recognition & Clustering ML로 반복 이벤트 패턴 인식·군집화 → 알림 노이즈 감소, 이상 탐지 (Anomaly Detection은 이 안의 일부) 5 Remediation & Automation 조치 추천(Runbook 제안) 또는 승인된 범위 내 자동 실행 — 대부분은 추천 단계에 머뭄 (→ #13 참조) 이 5가지 Capability가 “AIOps = 이상 탐지”라는 오해를 차단하는 구조적 근거입니다.
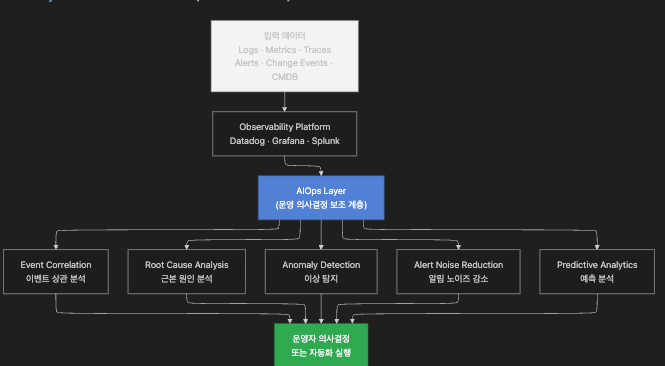
다이어그램에서 Anomaly Detection(이상 탐지)은 AIOps 기능 중 하나로 표시됩니다.
Event Correlation, RCA, Noise Reduction, Predictive Analytics와 동등한 위치에 있으며,
AIOps 전체를 대표하지 않습니다.
1.3 EIS 5개 컴포넌트 심화 — 각 단계가 하는 일
앞의 표에서 나열한 5개 Capability를 하나씩 풀어봅니다.
① Cross-domain Event Ingestion (이종 소스 이벤트 수집)
AIOps의 첫 번째 전제: 단일 도메인 데이터만으로는 전체 그림을 볼 수 없다.
| 소스 도메인 | 데이터 유형 | 예시 |
|---|---|---|
| Application | Logs, Traces, Metrics | OTel SDK 계측 데이터 |
| Infrastructure | Host metrics, K8s events | CPU, Memory, Pod 상태 |
| Network | Flow logs, Latency metrics | VPC Flow Logs, BGP 이벤트 |
| Change | Deployment, Config 변경 이벤트 | ArgoCD, Terraform 적용 로그 |
| Business | Ticket, Incident 이력 | ServiceNow, PagerDuty 이력 |
| Topology | CMDB, 서비스 의존성 맵 | 서비스 간 호출 관계 |
핵심 과제 — 정규화(Normalization):
소스마다 시간 형식, 필드명, 심각도 레이블이 다릅니다. (예:severity: "ERROR"vslevel: 3vsalert_level: "critical")
AIOps 파이프라인의 첫 번째 작업은 이 이종 데이터를 공통 스키마로 변환하는 것입니다.
정규화가 실패하면 이후 모든 단계(Correlation, RCA)가 오작동합니다.
② Topology Assembly (토폴로지 조립)
AIOps가 “어느 서비스가 원인인가”를 판단하려면 서비스 간 의존성 그래프가 필요합니다.
Topology Assembly는 이 그래프를 자동으로 구성하고 실시간으로 갱신하는 단계입니다.
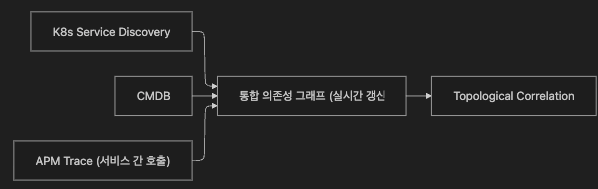
| 항목 | 설명 |
|---|---|
| 정적 토폴로지 | CMDB에 등록된 고정 의존성 (변경 느림, 정확도 높음) |
| 동적 토폴로지 | K8s 서비스 디스커버리, OTel Trace의 실제 호출 패턴으로 실시간 갱신 |
| 핵심 위험 | Stale Topology — K8s Pod는 수분 단위로 교체되는데 그래프가 갱신되지 않으면 엉뚱한 서비스가 원인으로 지목됨 |
AIOps와 CMDB의 관계:
전형적인 AIOps 분석은 CMDB·Topology를 입력으로 소비합니다. (→ #14 개념 경계 참조)
일부 플랫폼은 Discovery·Service Mapping과 결합해 토폴로지 정보를 보강·갱신하기도 합니다.
Topology Assembly의 품질은 CMDB 정확도에 직접 의존합니다.
③ Event Correlation & Enrichment (이벤트 상관 및 보강)
→ #12에서 상세 설명 (Temporal / Topological / Semantic 3가지 유형)
Enrichment(보강)는 Correlation 과정에서 이벤트에 추가 컨텍스트를 붙이는 과정입니다.
| 보강 데이터 | 효과 |
|---|---|
| CMDB 정보 (담당팀, 서비스 등급) | 인시던트 자동 라우팅, 우선순위 설정 |
| 배포 이력 | “이 오류 직전에 배포가 있었는가?” 자동 확인 |
| 과거 유사 인시던트 | “이전에 같은 패턴이 있었고 해결 방법은 X였다” |
| SLO Burn Rate | 현재 오류가 Error Budget에 미치는 영향 즉시 계산 |
④ Pattern Recognition & Clustering (패턴 인식 및 군집화)
이 단계가 “AIOps = 이상 탐지”라는 오해가 생기는 지점입니다.
Anomaly Detection은 이 단계의 일부 기능입니다.
이 단계가 하는 두 가지 작업:

왜 군집화(Clustering)가 중요한가:
DB 장애 1건이 200개 알림을 발생시킬 때, Clustering은 이를 “DB 클러스터” 1개로 압축합니다.
이 과정 없이 Correlation 단계에 200개가 그대로 넘어가면 Correlation도 실패합니다.
Clustering과 Correlation은 상호 작용합니다 — Clustering으로 노이즈를 줄인 이벤트가 Correlation에 입력되고, Correlation 결과가 다시 클러스터를 정제합니다. 둘 다 RCA 이전에 수행되어야 합니다.
| 방법 | 특징 | 적합한 상황 |
|---|---|---|
| z-score / MAD | 단순, 빠름, 설명 가능 | 정상 분포를 따르는 메트릭 |
| Isolation Forest | 비선형 이상 탐지 | 고차원 특성, Unknown 패턴 |
| LSTM / Transformer | 시계열 패턴 학습 | 주기성·계절성 있는 트래픽 |
| Prophet | 트렌드·휴일 효과 반영 | 비즈니스 사이클 있는 지표 |
한계: 어떤 방법도 학습 데이터에 없는 완전히 새로운 장애 패턴(Novel Failure)은 탐지 못합니다.
이것이 #13에서 AIOps의 완전 자동화를 제한하는 이유 중 하나입니다.
⑤ Remediation & Automation (조치 추천 및 자동화)
→ #13에서 상세 설명 (3단계 자동화 모델 및 제한적 Remediation의 근거)
1.4 Capability 간 의존 관계 — 무엇이 실패하면 무엇이 망가지는가
5가지 Capability는 엄격한 직렬 파이프라인이 아니지만, 입력-출력 의존 관계는 명확합니다.
특히 ③(Correlation)과 ④(Pattern Recognition)는 상호 작용하거나 병렬 실행될 수 있습니다.
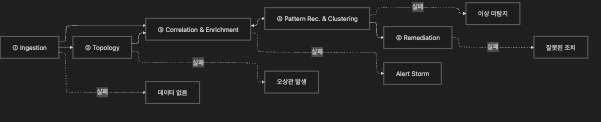
각 Capability는 이전 단계의 출력 품질에 의존합니다.
AIOps의 실제 장벽이 알고리즘보다 데이터 수집·정규화·토폴로지 관리에 있는 이유가 이것입니다.
AIOps가 무엇을 하는 계층인지 이해했다면, 이제 AIOps가 데이터를 공급받는 하위 계층인 Observability를 살펴볼 차례입니다.
2. Observability vs Monitoring — 시스템 속성 vs 실천 행위
2.1 핵심 차이
| 구분 | Monitoring | Observability |
|---|---|---|
| 전제 | 알고 있는 문제를 감시 | 처음 보는 문제도 탐색·설명 가능 |
| 방향 | 미리 정의한 임계치 → 알림 | 시스템 내부 상태를 외부에서 추론 |
| 질문 | “CPU가 80% 넘었나?” | “왜 이 서비스만 응답이 느려졌나?” |
| 대표 도구 | Nagios, Zabbix, CloudWatch Alarms | Jaeger, Loki, Tempo (OTel은 수집 표준/프레임워크) |
| 한계 | Unknown unknowns에 무력 | 데이터 수집 비용·복잡도 높음 |
2.2 관계 구조
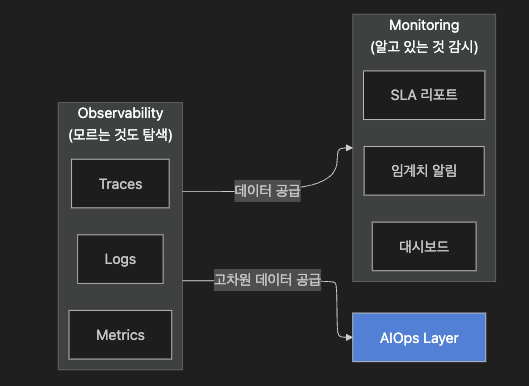
Monitoring과 Observability는 대립 관계가 아닙니다.
Monitoring은 Observability 데이터를 활용하는 실천 행위이고, Observability는 그 데이터를 만들어내는 시스템 속성입니다.
AIOps는 Observability가 수집한 고차원 데이터 위에서 동작합니다.
앞서 #1 다이어그램의 “Observability Platform”이 바로 이 계층을 말합니다. Logs·Metrics·Traces를 수집·저장·조회할 수 있게 해주는 플랫폼입니다.
Observability를 실제로 구현하고 운영하는 조직 단위가 SRE입니다. DevOps·SRE·AIOps 세 개념이 어떤 관계인지는 #3에서 정리합니다.
3. DevOps / SRE / AIOps — 관계 구조
Google SRE Workbook은 SRE를 class SRE implements interface DevOps로 정의합니다.
SRE는 DevOps의 하위 단계가 아니라 DevOps 철학의 구체적 구현체입니다.
세 개념의 관계는 계층이 아닌 철학 → 구현 → 도구 구조로 이해해야 합니다.

| 계층 | 핵심 역할 | AIOps와의 관계 |
|---|---|---|
| DevOps | 개발-운영 협업 철학·CI/CD 자동화 | AIOps는 DevOps 파이프라인에서 배포 영향을 감지하고 롤백 판단을 보조 |
| SRE | DevOps의 구체적 구현. SLO/Error Budget 관리·Toil 제거 | AIOps는 SRE의 의사결정을 데이터 기반으로 가속 |
| AIOps | 운영 의사결정 보조 도구 계층 | Observability + 운영 이벤트 데이터를 소비하여 SRE·Ops에 인사이트 제공 |
SRE가 신뢰성을 측정하는 핵심 도구가 SLO와 Error Budget입니다.
AIOps가 SRE의 의사결정을 “가속”한다는 것이 구체적으로 무엇을 의미하는지 #4에서 살펴봅니다.
4. SLO · SLI · SLA · Error Budget — 신뢰성 측정 체계
4.1 용어 정의
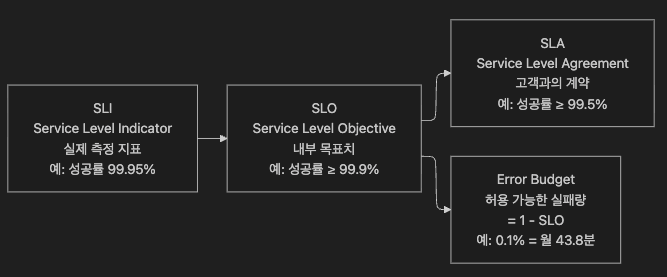
4.2 Error Budget 계산 예시
[전제]
아래 표는 가용성(Availability) SLO 기준입니다.지연시간 SLO라면 Error Budget = “허용 가능한 느린 요청 수”, 정확도 SLO라면 “허용 가능한 실패 요청 수”가 된다.
“다운타임”으로 직접 환산되는 건 가용성 SLO에만 해당한다. (Google SRE Workbook #Implementing SLOs)
| SLO | Error Budget (월 평균 30.44일 기준) | Error Budget (30일 정확 계산) |
|---|---|---|
| 99.9% | 43.8분 | 43.2분 |
| 99.95% | 21.9분 | 21.6분 |
| 99.99% | 4.38분 | 4.32분 |
계산 근거: 30일 × 24h × 60min = 43,200분. 99.9% → 43,200 × 0.001 = 43.2분.
업계에서 흔히 인용하는 43.8분은 월 평균(365일/12 ≈ 30.44일) 기준 값입니다.
4.3 SLI 측정 윈도우
SLI는 rolling window 기준으로 측정합니다.
Google SRE Workbook은 주 단위(integral number of weeks) rolling window를 권장하며, 일반적인 예시로 4주(28일) rolling window를 제시합니다.
30일은 업계에서 흔히 쓰이는 예시값이지만, Google SRE의 공식 권장값으로 단정하기는 어렵습니다.
이 윈도우가 Error Budget 소진의 기준 기간이 됩니다.
4.4 Burn Rate — 소진 속도 지표
Burn Rate는 Error Budget이 얼마나 빠른 속도로 소진되고 있는가를 나타내는 배수입니다.
Burn Rate = 현재 오류율 / (1 - SLO)
예: SLO = 99.9% → (1 - SLO) = 0.1%
현재 오류율 = 1% → Burn Rate = 1% / 0.1% = 10
→ Error Budget이 계획보다 10배 빠르게 소진 중- Burn Rate = 1: 정확히 예산을 다 쓰는 속도 (허용 범위)
- Burn Rate > 1: 예산 초과 소진 → 대응 필요
- Burn Rate ≫ 1: 즉각 조치 필요
4.5 Burn Rate 알림 윈도우 — 실무
단순 임계치 알림 vs Burn Rate 기반 알림의 핵심 차이
| 방식 | 기준 | 특징 |
|---|---|---|
| 임계치 알림 | 에러율 > X% | 일시적 스파이크에 오탐, 느린 소진엔 미탐 |
| Burn Rate 알림 — Tier 1 (긴급) | 1h 창 Burn Rate > 14.4 AND 5분 창 Burn Rate > 14.4 | 예산 2% 1시간 내 소진 시 즉시 페이지 (Google SRE 권장) |
| Burn Rate 알림 — Tier 2 (경고) | 6h 창 Burn Rate > 6 AND 30분 창 Burn Rate > 6 | 예산 5% 6시간 내 소진 시 페이지 (Google SRE 권장) |
[Multi-window 설계 이유]
긴 창(long window)은 느린 소진을 감지, 짧은 창(short window)은
이미 회복된 일시적 스파이크의 오탐을 방지한다.
두 조건 모두 충족 시에만 알림 발생.
4.6 AIOps와 Error Budget 연결
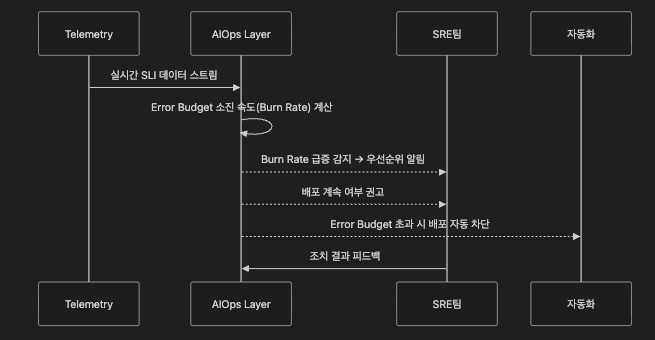
AIOps는 Error Budget이라는 정량적 지표를 기반으로 “지금 배포할지”, “어떤 장애를 먼저 처리할지”를 데이터 기반으로 판단하게 해주는 실행 엔진입니다.
SLO 달성 여부를 측정하려면 실제 데이터가 필요합니다. “어느 서비스의 성공률이 SLO를 위반했는가”를 알려면 Logs·Metrics·Traces가 있어야 합니다. #5에서는 이 데이터를 수집하는 표준인 OpenTelemetry와 각 신호의 역할을 살펴봅니다.
5. OpenTelemetry — 3대 신호 수집 표준
5.1 OpenTelemetry란
OpenTelemetry는 벤더 중립적 오픈소스 Instrumentation & Collection Framework입니다.
Traces·Metrics·Logs 모두 단일 SDK/API를 제공합니다. Logs API/SDK는 현재 Stable 상태입니다.
다만 실무에서는 기존 로깅 생태계(log4j, zap, winston 등)가 방대하기 때문에, 기존 logging library + OTel Bridge/Appender 방식으로 연계하는 패턴이 가장 흔합니다.
어떤 백엔드(Datadog, Grafana, Jaeger 등)로도 전송 가능한 것이 핵심 가치입니다.
이 문서에서는 Logs·Metrics·Traces 3대 신호에 집중합니다.
#1에서 언급한 Events는 별도 신호가 아니라 Logs의 구조화된 형태이거나 Alerting 레이어의 출력물입니다.
OTel은 Profiles(Continuous Profiling)를 4번째 신호로 Experimental Specification 단계에서 개발 중이며, 아직 Stable 상태가 아니므로 1주차 범위에서는 제외합니다.
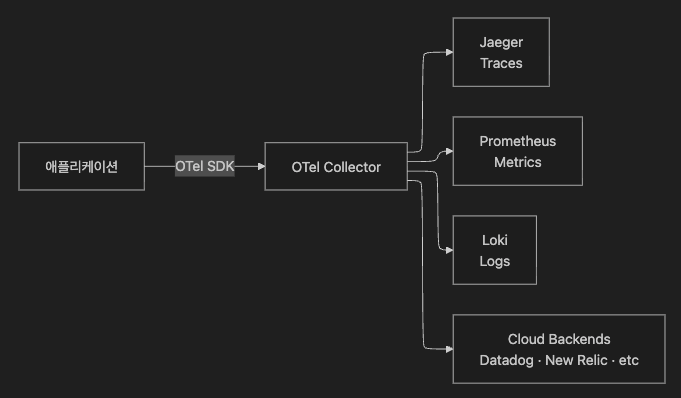
5.2 3대 신호 비교
| 신호 | 형태 | 목적 | 비용 | 예시 |
|---|---|---|---|---|
| Logs | 이벤트 텍스트 | 상세 맥락·디버깅 | 높음 (볼륨 큼) | ERROR: DB connection failed at 13:45:02 |
| Metrics | 수치 시계열 | 추세·SLO 계산·알림 | 낮음 (집계됨) | http_requests_total{status="500"} 42 |
| Traces | 요청 실행 흐름 | 서비스 간 지연·병목 | 중간 (샘플링) | 마이크로서비스 A→B→C 호출 체인 |
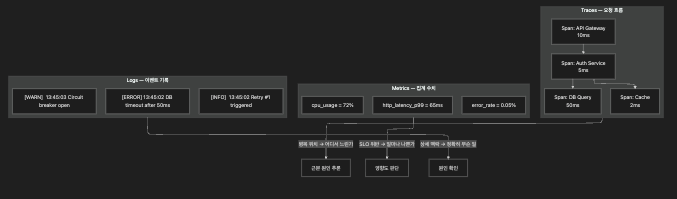
5.3 신호 간 상관관계 — AIOps의 핵심
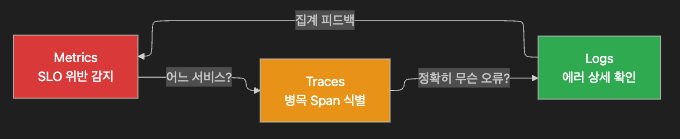
AIOps는 이 세 신호를 자동으로 상관분석하여 운영자가 수동으로 3개 탭을 오가는 시간을 줄입니다.
단, 이 자동 상관분석이 가능하려면 전제 조건이 하나 있습니다. 세 신호를 하나로 묶는 공통 키입니다.
5.4 상관분석이 가능한 이유 — 공통 키
세 신호를 자동으로 묶으려면 공통 컨텍스트 키가 필수입니다.
이 키가 없으면 AIOps의 자동 상관분석은 동작하지 않습니다.
| 키 | 용도 | 예시 |
|---|---|---|
trace_id | Trace ↔︎ Log 연결 | 4bf92f3577b34da6a3ce929d0e0e4736 |
span_id | 특정 Span ↔︎ Log 연결 | 00f067aa0ba902b7 |
resource.service.name | 서비스 단위 집계 | payment-service |
k8s.pod.name | 인프라 단위 연결 | payment-7d9f8b-xkq2p |
service.version | 배포 버전 상관 | v2.3.1 |
OTel은 로그 상관을 time + trace context + resource context 세 축으로 정의합니다.
Context Propagation(Baggage) 을 통해 서비스 간 비즈니스 우선순위(user_tier=premium 등)도 전달할 수 있어 AIOps가 “어떤 요청이 더 중요한가”를 판단하는 데 활용됩니다.
참고: 위 표의
resource.service.name은 “Resource에 속하는service.name속성”을 나타내는 표현입니다.OTel Semantic Conventions의 실제 attribute key는
service.name이며,service.version도 마찬가지로deployment.version이 아닌service.version이 정식 key입니다.
이제 Logs·Metrics·Traces를 수집하는 방법을 알았습니다.
현실에서는 “모든 데이터를 완벽하게 수집할 수 없다”는 제약이 있습니다.
이 제약의 네 가지 구체적 형태인 Sampling, Cardinality, Clock Skew, Missing Data를 살펴봅니다.
6. Sampling 전략 — Head-based vs Tail-based
6.1 왜 Sampling이 필요한가
대규모 서비스에서 발생하는 모든 트레이스를 저장하면 관측 비용이 서비스 운영 비용을 초과하는 역설이 생깁니다.
예를 들어 1,000 RPS 서비스는 하루에 8,640만 건의 트레이스를 생성합니다.
저장·처리 비용이 관측 대상 자체보다 커지는 이 역설을 해결하는 것이 Sampling입니다.
6.2 Head-based vs Tail-based
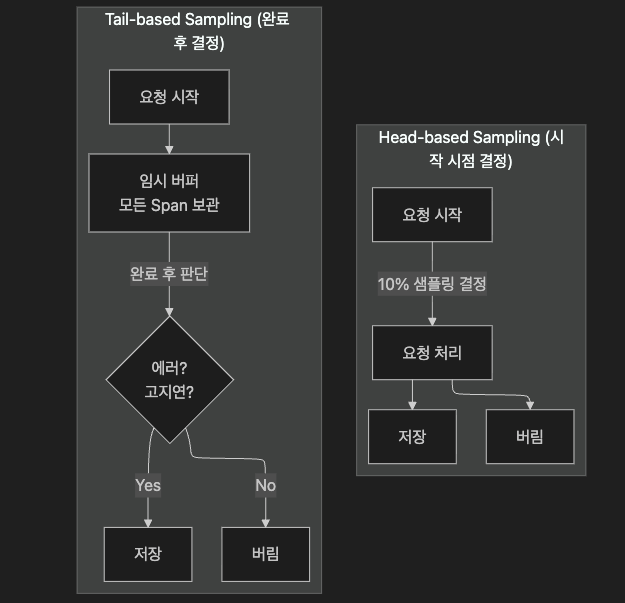
| 기준 | Head-based | Tail-based |
|---|---|---|
| 결정 시점 | 요청 시작 | 요청 완료 후 |
| 처리 위치 | SDK 레벨 (애플리케이션 내) | Collector/백엔드 레벨 (OTel Collector 등) |
| 오류 트레이스 보존 | 보장 안 됨 | 가능성 높음 (단, late span·partial trace·collector 과부하 시 미보장) |
| 구현 복잡도 | 낮음 | 높음 (버퍼·상태 관리) |
| 메모리 오버헤드 | 낮음 | 높음 |
| 비용 예측 | 쉬움 | 어려움 |
| 적합한 상황 | 균일 트래픽, 저비용 우선 | 오류·장애 트레이스 반드시 보존 필요 |
운영 주의: Tail Sampling — Partial Trace 위험
Tail-based 결정은 전체 Span이 Collector에 도달한 이후에 이뤄진다.
분산 시스템에서 일부 Span이 늦게 도착하거나 유실되면 불완전한 trace(partial trace) 로 판단이 이뤄질 수 있다.
또한 모든 Span을 일시 버퍼링해야 하므로 추가 메모리·처리 비용이 발생한다.
Tip: 대부분의 프로덕션 환경은 Head-based를 기본값(SDK 레벨) 으로 두고, 에러·고지연 트레이스는 Tail-based(Collector 레벨)로 예외 보존하는 혼합 전략을 사용한다.
Sampling은 “얼마나 수집하는가”의 문제입니다. 다음 섹션의 Cardinality는 “무엇을 태그로 붙이는가”의 문제입니다.
7. Cardinality — 태그 설계가 성능을 결정한다
7.1 Cardinality vs Dimensionality 구분
두 개념은 자주 혼용되지만 유발하는 문제가 다릅니다.
| 개념 | 정의 | 예시 | 유발 문제 |
|---|---|---|---|
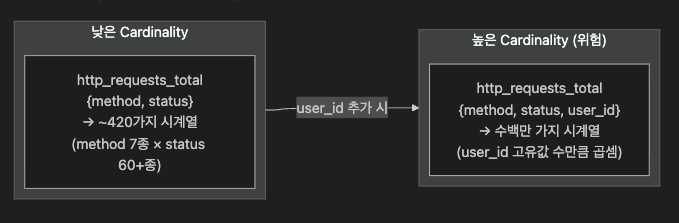
| Cardinality | 특정 태그(Key)가 가질 수 있는 고유값(Value)의 수 | user_id → 수백만 가지 값 | 데이터 희소성 → TSDB 시계열 폭증 |
| Dimensionality | 데이터에 붙는 태그(Key)의 수 | service, region, version, host → 4개 차원 | 차원의 저주 → ML 학습 불안정 |
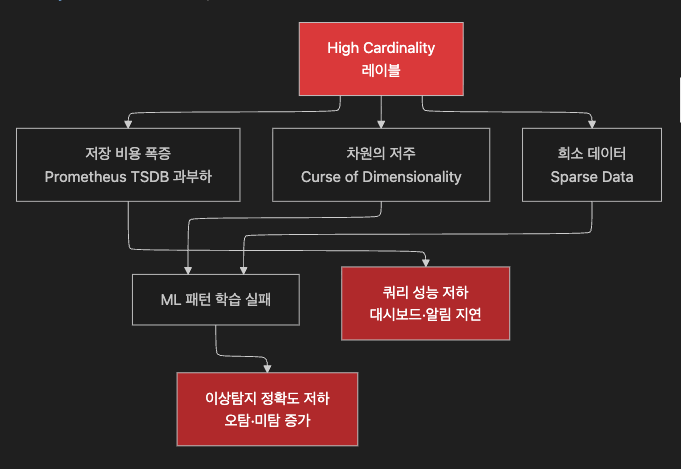
AIOps ML 모델 관점에서 Cardinality는 데이터 희소성 문제를, Dimensionality는 차원의 저주 문제를 유발합니다.
둘 다 높으면 ML 성능이 동시에 저하됩니다.
| 낮은 Cardinality | 높은 Cardinality |
|---|---|
| HTTP Method (GET/POST/PUT/DELETE) → 4가지 | User ID → 수백만 가지 |
| HTTP Status Code → ~10가지 | Session ID → 무한 |
| Region (ap-northeast-2 등) → ~20가지 | Order ID → 무한 |
주의: High Cardinality가 항상 나쁜 건 아닙니다.
- Metrics TSDB(Prometheus 등): 치명적 — 시계열 수 × 저장 비용이 기하급수적 증가
- Logs / Traces: 저장·인덱싱 정책을 달리하면 높은 Cardinality를 감당 가능
> → 고 Cardinality 데이터는 Metrics 대신 **Logs나 Traces에서 처리**하는 것이 정석7.2 Cardinality Explosion
7.3 AIOps ML에 미치는 영향
7.4 해결 전략
- 분리 수집: 고 Cardinality 데이터는 Metrics 대신 Logs나 Traces에서 처리
- OTel Collector 전처리: 불필요한 고 Cardinality 레이블 제거 후 백엔드로 전송
- 집계 설계: 개별 ID 대신 버킷(예: 응답시간 히스토그램) 활용
- 레이블 정책 수립: 팀 단위 레이블 사용 기준 문서화
Cardinality는 “무엇을 태그로 붙이는가”의 문제였습니다.
Clock Skew는 “언제 기록했는가”의 문제입니다.
데이터를 수집했더라도 시간 기록이 틀리면 인과관계 분석이 불가능해집니다.
8. Clock Skew — 분산 Telemetry의 숨겨진 함정
8.1 정의
Cardinality가 태그 설계의 문제라면, Clock Skew는 시간 기록의 문제입니다.
분산 시스템에서 노드 간 시계가 어긋나면 인과관계 분석이 왜곡되거나 신뢰도가 크게 저하됩니다.
Clock Skew(시계 편차) 란 분산 시스템의 노드 간 시계가 서로 다른 시간을 가리키는 현상입니다.
NTP로 동기화하지만 네트워크 지연·드리프트로 인해 완벽한 동기화는 불가능합니다.
8.2 분산 Trace에 미치는 영향
Service B의 시계가 실제 시간보다 50ms 느린(뒤처진) 경우를 예로 들면, B가 기록하는 타임스탬프가 실제보다 50ms 이른 값으로 찍힙니다.
그 결과 Trace 기록 상 B의 Span이 A가 요청을 보내기 전에 시작된 것처럼 보이게 됩니다.
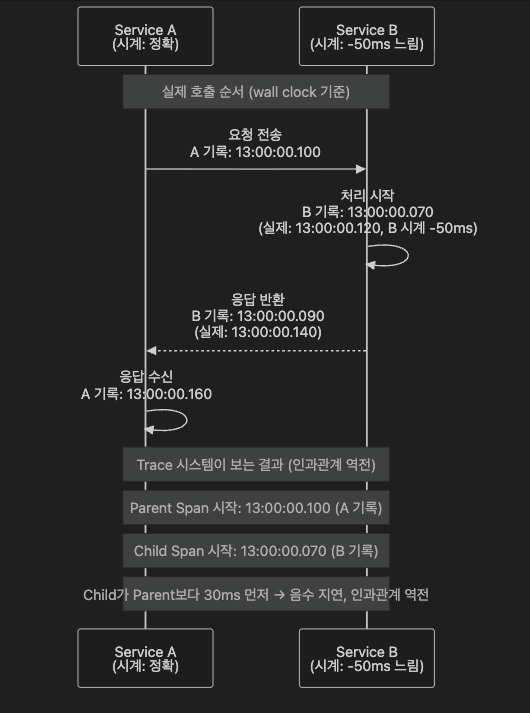
8.3 실질적 피해
| 증상 | 원인 | 결과 |
|---|---|---|
| Child Span이 Parent보다 먼저 시작 | 노드 B 시계가 느림(-50ms) → B 타임스탬프가 이른 값으로 찍힘 | 트레이스 인과관계 왜곡 |
| 음수(negative) 지연 시간 | Span 간 시간 역전 | Jaeger·Zipkin 오류 표시 |
| 로그-트레이스 타임라인 불일치 | 다른 시계 기준 타임스탬프 | 사고 재구성(incident replay) 실패 |
| AIOps 이상탐지 오탐 | Clock Skew를 이상 패턴으로 오인 | 불필요한 알림 발생 |
8.4 완화 방법
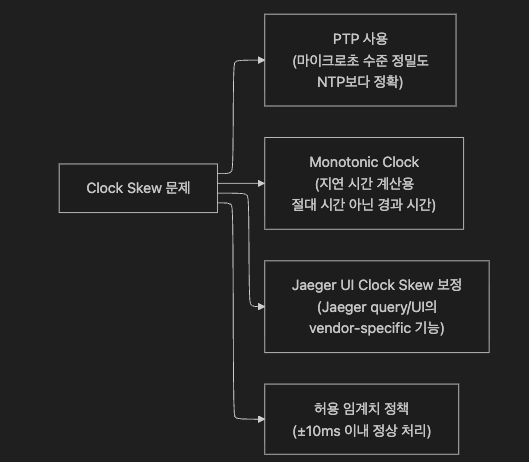
참고:
OTel Clock Skew Adjuster는 OTel Collector 공식 processor 목록에 없다.Clock Skew 보정 기능은 Jaeger UI/query 레벨의 vendor-specific 기능입니다.
OTel Collector 레벨에서는 별도 커스텀 processor 구현 또는 Jaeger 연동으로 처리한다.
Clock Skew는 “언제 기록했는가”의 문제였습니다. 다음은 “데이터가 아예 도달하지 않는” 상황입니다.
9. Missing Data — 침묵하는 장애, 가장 감지하기 어려운 데이터 품질 문제
9.1 Missing Data란
Missing Data(누락 데이터)란 수집되어야 할 텔레메트리가 파이프라인 어딘가에서 유실되어 저장·분석 시스템에 도달하지 못하는 현상입니다.
정상: ──●──●──●──●──●──●──●── (일정 간격으로 메트릭 도착)
Missing Data: ──●──●── ──●── (2분 구간 완전 유실)
↑
이 구간에서 장애가 발생해도 알림 없음 → Silent FailurePrometheus에서 메트릭이 사라지면 rate(http_requests_total[5m]) > 100 조건은 false가 아니라 “빈 결과(empty)”를 반환합니다. 대부분의 알림 시스템은 빈 결과를 “조건 미충족”으로 해석하고 아무것도 발생시키지 않습니다. 장애를 조용히 삼키는 것입니다.
9.2 Sampling vs Missing Data — 의도적 손실 vs 비의도적 유실
| 구분 | Sampling | Missing Data |
|---|---|---|
| 발생 원인 | 비용 절감을 위한 의도적 설계 | 에이전트 장애·네트워크 파티션 등 비의도적 유실 |
| 사전 인지 | 알고 있음 (샘플링 비율 설정값 존재) | 모름 (발생 자체를 인지 못할 수 있음) |
| 데이터 대표성 | 통계적으로 전체를 대표 | 유실 구간의 실제 상태를 알 수 없음 |
| AIOps 영향 | 예측 가능한 편향 (보정 가능) | 예측 불가 공백 → Silent Failure, False Negative |
9.3 발생 원인 — 파이프라인 유실 지점

| 지점 | 원인 | 증상 |
|---|---|---|
| ① 애플리케이션 | 앱 크래시, 재배포 중단, 계측 코드 버그 | 특정 서비스 메트릭만 사라짐 |
| ② SDK | 메모리 압박으로 내부 큐 드롭 | 일부 Span·로그 랜덤 유실 |
| ③ OTel Collector | OOM Kill, 설정 오류, 과부하 | Collector 하위 모든 서비스 데이터 일괄 유실 |
| ④ 네트워크 | 패킷 로스, 방화벽 정책 변경 | 특정 구간 데이터 일괄 유실 |
| ⑤ 백엔드/저장소 | TSDB 과부하로 쓰기 실패 | 수집은 됐지만 저장 안 됨 |
9.4 AIOps에 미치는 위험
| 위험 유형 | 상세 |
|---|---|
| Silent Failure | 장애 발생 중인데 데이터 없어 알림 미발생 — AIOps 판단 불가 |
| False Negative (미탐) | 이상탐지 모델이 공백 구간을 “정상 상태”로 학습 → 유사 패턴 오판 |
| RCA 인과 체인 단절 | 원인-결과 체인의 한 단계가 비어 있으면 RCA가 잘못된 원인 지목 |
| SLO 과대 계산 | 에러 이벤트 미기록 → 에러율 실제보다 낮게 집계 → Error Budget 소진량 과소평가 |
핵심: “데이터가 없다 = 문제 없다”는 가정은 AIOps에서 절대 허용되지 않습니다.
데이터 유실과 서비스 정상을 구분하지 못하면 AIOps 전체의 신뢰도가 무너집니다.
9.5 감지 전략 — Dead Man’s Switch / Heartbeat 패턴
Missing Data 감지의 핵심 원리: “데이터가 없을 때 알림” 대신 “항상 존재해야 할 신호가 없을 때 알림” 으로 설계합니다.
# Prometheus Watchdog Alert — 항상 발화(firing)해야 하는 알림
groups:
-name: watchdog
rules:
-alert: Watchdog
expr: vector(1) # 항상 true → 항상 발화
annotations:
summary:"이 알림이 멈추면 Prometheus/Alertmanager 파이프라인 전체 장애"# 특정 서비스 메트릭 유실 감지
-alert: PaymentServiceMetricsMissing
expr: absent_over_time(http_requests_total{service="payment-service"}[5m])
for: 1m
labels:
severity: critical| 함수 | 동작 | 사용 시점 |
|---|---|---|
absent(metric) | 현재 시점에 메트릭 없으면 1 반환 | 즉시 감지 (노이즈 있음) |
absent_over_time(metric[5m]) | 지정 기간 내내 없을 때 1 반환 | 일시적 지연과 진짜 유실 구분 |
9.6 Gap Filling 전략
| 전략 | 적합한 상황 | 주의 |
|---|---|---|
zero fill (or vector(0)) | 이벤트성 메트릭 (발생 없으면 0이 맞음) | 카운터 메트릭에 사용 금지 |
| 이전 값 유지 (LOCF) | 완만하게 변화하는 게이지 메트릭 | 급변 구간에서 오해 유발 |
| 보간(Interpolation) | 연속적 게이지 메트릭 | 공백이 길수록 부정확 |
| 명시적 NULL 유지 | ML 모델 학습 데이터 전처리 | 권장 — 공백 구간을 분석에서 제외하고 신뢰도 점수 전파 |
실무 원칙: 보간된 데이터는 반드시
data_quality_flag로 마킹 — AIOps 모델이 보간 아티팩트를 실제 이상으로 오인하는 것을 방지합니다.
10. Data Quality 종합 — AIOps의 현실적 한계
앞서 살펴본 네 가지 제약은 모두 Data Quality 문제의 구체적 사례입니다.
Sampling은 수집량 문제(비용 때문에 모든 트레이스를 저장할 수 없다),
Cardinality는 차원 문제(태그를 잘못 설계하면 저장·ML 비용이 폭증한다),
Clock Skew는 시간 문제(시계가 맞지 않으면 인과관계 분석이 틀어진다),
Missing Data는 유실 문제(데이터가 도달하지 않으면 AIOps 자체가 작동하지 않습니다) 입니다.
데이터가 많다는 것이 데이터가 좋다는 의미는 아닙니다.
AIOps의 실제 장벽은 알고리즘보다 데이터 품질에 있는 경우가 더 많습니다.
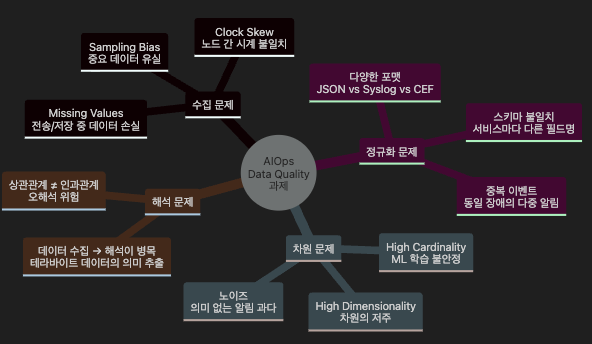
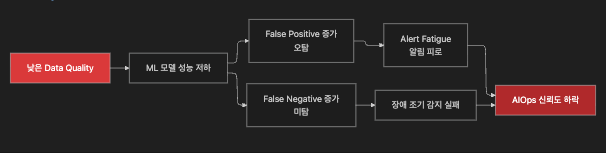
10.1 데이터 품질이 AIOps에 미치는 영향 체인
11. 인시던트 라이프사이클 — AIOps가 장애를 처음부터 끝까지 다루는 방법
데이터 품질 제약을 이해했다면, 이제 실제 장애 대응 흐름 전체에서 AIOps가 어떤 역할을 하는지 살펴봅니다.
탐지(Detection) 이후에 AIOps가 개입하는 단계들을 전체 수명주기로 연결해 보겠습니다.
11.1 표준 5단계 인시던트 라이프사이클

각 단계는 독립된 활동이 아니라 피드백 루프를 형성합니다.
포스트모텀의 학습 결과가 탐지 모델과 런북을 개선하고, 다음 인시던트의 MTTD·MTTR을 단축합니다.
| 단계 | 핵심 지표 | AIOps 없이 | AIOps 적용 시 |
|---|---|---|---|
| 탐지 (Detection) | MTTD | 정적 임계치 → 느린 소진·미묘한 이상에 무력 | 동적 Baseline 학습 → 조기 이상 감지 |
| 트리아지 (Triage) | MTTA | 수백 개 알림 수동 분류 → 수십 분 소요 | Alert Correlation → 단일 인시던트로 통합, 자동 라우팅 |
| 진단 (Diagnosis/RCA) | MTTI | 로그·메트릭·트레이스 탭 오가며 수동 상관분석 | 3대 신호 자동 상관 → 유력 근본 원인 후보 제시 |
| 해결 (Resolution) | MTTR | 런북 수동 참조·실행, 야간 장애 시 대응 지연 | 알려진 패턴에 Runbook 자동 실행 (Semi/Full auto) |
| 포스트모텀 | MTBF↑ | 회고 문서 수동 작성 → 시간 부족으로 생략 | 인시던트 타임라인 자동 생성 → 팀은 검토·개선에 집중 |
11.2 인시던트 라이프사이클과 Error Budget 연결
인시던트 발생 → MTTD 동안 SLO 위반 진행 중
→ MTTA + MTTI 동안 Error Budget 계속 소진
→ MTTR 완료 시점에 소진 멈춤
Error Budget 소진량 = MTTR(분) / 43,200분 × 100%
예: MTTR = 20분, SLO = 99.9%
소진 = 20 / 43,200 = 0.046% → 월 Error Budget(43.2분)의 46% 소진
→ AIOps로 MTTR을 3분으로 단축 시: 동일 인시던트 14번 발생해도 버짓 유지핵심: AIOps가 SRE의 의사결정을 “가속”한다는 것 = MTTD·MTTR 단축 → Error Budget 보존 → 기능 배포 기회 확보
11.3 핵심 지표 정리
| 지표 | 풀네임 | AIOps 단축 기여 |
|---|---|---|
| MTTD | Mean Time to Detect | 동적 이상탐지로 단축 |
| MTTA | Mean Time to Acknowledge | 자동 라우팅으로 단축 |
| MTTI | Mean Time to Identify | 자동 RCA로 단축 |
| MTTR | Mean Time to Repair | 자동 Runbook으로 단축 |
| MTBF | Mean Time Between Failures | 포스트모텀 → 장기적 향상 |
포스트모텀 원칙: Blameless — 개인 책임이 아닌 시스템·프로세스 개선에 집중합니다.
AIOps는 인시던트 타임라인과 관련 이벤트를 자동 수집하여 포스트모텀 초안을 생성합니다.
12. Event Correlation — 상관분석은 왜 어려운가
12.1 Event Correlation이란
AIOps의 핵심 흐름 중 “correlation” 단계는 단순히 두 알림을 묶는 작업이 아닙니다.
수백 개의 이벤트를 실시간으로 받아 “같은 원인에서 발생한 것들”을 자동으로 그룹화하는 과정입니다.
Event Correlation = 동일한 근본 원인(root cause)에서 파생된 이벤트 집합을
단일 인시던트(Incident)로 통합하는 과정상관분석이 없다면 DB 연결 장애 하나가 발생했을 때 수십 개의 다운스트림 알림이 각각 별개의 인시던트로 처리됩니다. 운영자는 전체 그림을 볼 수 없고, 가장 중요한 알림은 노이즈 속에 묻힙니다.
12.2 상관분석의 3가지 유형
현대 AIOps에서는 아래 세 가지 방식이 조합되어 사용됩니다.
| 유형 | 작동 원리 | 강점 | 한계 |
|---|---|---|---|
| Temporal Correlation (시간 기반) | 짧은 시간 창(time window) 안에 발생한 이벤트를 그룹화 | 구현 단순, 빠른 처리 | 원인-결과 지연이 길면 놓침 (예: 메모리 누수 → 수십 분 후 OOM) |
| Topological Correlation (위상 기반) | 서비스/인프라 의존성 그래프(CMDB, topology map)를 기반으로 연관 노드의 이벤트를 묶음 | 직접 의존 관계를 정확히 포착 | CMDB 정확도에 전적으로 의존. stale topology면 오히려 오상관 |
| Semantic Correlation (의미 기반) | 이벤트 메시지·레이블의 의미적 유사성(LLM 임베딩 등)을 분석하여 연관성 판단 | 미지정 의존성·신규 패턴 탐지 가능 | 계산 비용 높음, 허위 유사성(false similarity) 위험 |
2025년 트렌드: BigPanda, Datadog, IBM AIOps Insights 등 주요 플랫폼은 세 방식을 앙상블로 조합합니다.
LLM 기반 Semantic Correlation은 2024년부터 프로덕션 환경에 본격 도입되기 시작했으며,
CMDB 갱신이 느린 환경에서 Topological Correlation의 보완재로 활용됩니다.
12.3 왜 상관분석은 보기보다 어려운가 — Alert Storm과 의존성 체인
Alert Storm (알림 폭풍)
대형 장애 시 단일 원인이 연쇄적으로 수백 개의 알림을 발생시키는 현상입니다.
예: DB Primary Node 장애 발생
→ DB 연결 실패 알림 × N개 (서비스 수만큼)
→ HTTP 500 에러율 급증 알림 × M개
→ SLO Burn Rate 임계치 돌파 알림 × K개
→ Downstream 서비스 응답시간 초과 알림 × P개
총 수백 건 → 실제 원인(DB 장애)은 1건Alert Storm이 발생하면 운영자는 어떤 알림이 원인이고 어떤 것이 결과인지 구분하기 어렵습니다. Alert Correlation 없이는 MTTR(평균 복구 시간)이 폭발적으로 증가합니다.
[Gartner 2025 수치] EIS 도입의 핵심 동기로 이벤트 볼륨 감소를 꼽으며, “극단적인 경우 인간이 개입해야 하는 이벤트가 95% 이상 감소”한다고 기술합니다. — Gartner, Market Guide for Event Intelligence Solutions, March 2025
Alert Fatigue (알림 피로)
Alert Storm이 반복되면 운영자는 알림에 무감각해집니다. 이를 Alert Fatigue라고 합니다.
업계 조사에 따르면 중대형 엔터프라이즈 환경의 알림 중 80% 이상이 액션이 필요 없는 노이즈입니다.
Alert Fatigue가 발생하면 실제 중요한 장애 알림을 무시하는 미탐(false negative) 위험이 증가합니다.

Dependency Chain (의존성 체인) 문제
현대 마이크로서비스 환경에서 서비스 간 의존성은 수십 단계에 걸쳐 형성됩니다.
하나의 이벤트가 다음 이벤트의 원인인지 결과인지를 판단하려면 전체 의존성 그래프가 필요합니다.
의존성 그래프가 불완전하거나 stale하면 Topological Correlation이 엉뚱한 서비스를 원인으로 지목합니다.
이것이 AIOps가 CMDB·topology 데이터를 입력으로 요구하는 이유입니다.
12.4 Telemetry 데이터 품질이 상관분석에 미치는 영향
앞서 살펴본 #6~#8의 데이터 품질 문제가 Event Correlation에 직접적 영향을 줍니다.
| 데이터 품질 문제 | 상관분석에 미치는 영향 |
|---|---|
| Sampling (#6) | Head-based Sampling으로 오류 트레이스 70~90% 유실 시, Temporal Correlation이 “같은 시간대의 관련 이벤트”를 찾지 못함 → 연관 인시던트 분리 처리 |
| High Cardinality (#7) | 수백만 개의 고유 레이블이 붙은 이벤트는 Topological Correlation 그래프 구성을 방해. ML 모델이 “어떤 서비스에서 온 이벤트인지” 특정하지 못함 |
| Clock Skew (#8) | 이벤트 타임스탬프 역전 → Temporal Correlation이 원인·결과 순서를 뒤집어 그룹화 → 잘못된 Root Cause 지목 |
핵심: 상관분석 알고리즘이 아무리 정교해도, 입력 데이터의 품질이 낮으면 결과는 신뢰할 수 없습니다.
AIOps의 상관분석 품질은 데이터 수집 파이프라인의 품질 상한선을 초과할 수 없습니다.
12.5 핵심 용어 정리
| 용어 | 정의 |
|---|---|
| Alert Fatigue | 알림이 너무 많아 운영자가 알림에 무감각해지는 현상. 실제 중요 장애 미탐 위험 증가 |
| Alert Storm | 단일 장애 원인이 연쇄적으로 수백 개의 알림을 발생시키는 현상 |
| Event Correlation | 동일 근본 원인에서 파생된 이벤트들을 하나의 인시던트로 그룹화하는 과정 |
| Topology-based Correlation | 서비스·인프라 의존성 그래프를 기반으로 이벤트 연관성을 판단하는 상관분석 방식 |
13. Recommendation vs Remediation — 자동화의 경계선
13.1 AIOps 운영 흐름 재정리
#1에서 AIOps의 기능 중 하나로 “조치 추천 및 자동화(Remediation Suggestion / Automation)”를 언급했습니다.
실무에서는 이 항목을 하나로 묶으면 안 됩니다. 추천(Recommendation)과 자동화(Automation) 사이에는 명확한 경계선이 존재하며, 현재(2025년) AIOps 시스템의 대부분은 이 경계선 왼쪽에 위치합니다.
13.2 3단계 자동화 모델
현대 AIOps 플랫폼들은 자동화 수준을 세 단계로 구분합니다.
| 단계 | 명칭 | 동작 방식 | 인간 역할 | 2025년 적용 범위 |
|---|---|---|---|---|
| 1단계 | Recommendation (추천) | AI가 가능한 조치를 제안하고 이유를 설명 | 운영자가 검토 후 직접 실행 | 거의 모든 고위험 시나리오 |
| 2단계 | Semi-automated Remediation (반자동화) | AI가 Runbook을 준비하고, 운영자가 승인(Approval) 시 시스템이 실행 | 실행 승인 | 잘 알려진 반복 장애 유형 |
| 3단계 | Full Automation (완전 자동화) | 인간 승인 없이 시스템이 직접 조치 | 사후 감사(Audit)만 | 저위험·고반복 작업 (알림 중복 제거, 스케일링 등) |
업계 현황 (2025):
Salesforce AIOps 사례 연구에 따르면, 인시던트의 약 30%만 완전 자동화로 처리되며,
30%는 AI 분석 + 인간 실행의 반자동화, 나머지 40%는 AI 추천 + 인간 최종 결정 구조입니다.
13.3 왜 AIOps는 완전 자동화에 제한적인가 — 제한적 Remediation의 근거
(1) 거버넌스와 책임 경계
자동화 조치가 시스템에 새로운 장애를 유발할 수 있습니다.
장애 책임(accountability)이 “AI가 자동으로 실행한 것”에 있을 때, 조직의 사후 분석(post-mortem)이 복잡해집니다.
이 때문에 대부분의 엔터프라이즈는 Approval Gate(승인 게이트) 를 필수 요소로 설계합니다.
(2) 모델 신뢰도의 현실적 한계
AIOps 모델은 학습 데이터에 없던 새로운 장애 패턴(Novel Failure)에 취약합니다.
2025년 기준 대부분의 AIOps 플랫폼은 알려진 장애 유형(Known Failure Patterns) 에 한해서만 자동 조치를 권장합니다.
Unknown failure에 대한 자동 조치는 상황을 악화시킬 위험이 있습니다.
(3) 데이터 품질 의존성
앞서 살펴본 것처럼 Sampling, Cardinality, Clock Skew 문제로 AIOps 입력 데이터는 항상 불완전합니다.
불완전한 데이터 위에서 내린 자동 조치 결정은 잘못된 RCA에 기반할 수 있습니다.
(4) Thoughtworks 2025 관찰
“자율적 복구(autonomous remediation)는 리스크, 거버넌스, 책임 경계에 의해 제한되며,
통제된 환경 밖으로 확장되지 못하고 있다.
엔터프라이즈가 성숙한 AI 거버넌스 기반을 갖추기 전까지 AIOps는 인간의 의사결정을 대체하지 않는다.
AIOps의 역할은 자율적 에이전시(autonomous agency)가 아닌 인지적 증강(cognitive augmentation)이다.”
— Thoughtworks, AIOps: What We Learned in 2025
13.4 제한적 Remediation의 설계 원칙
안전한 자동화의 조건:
1. 위험도 분류: 조치의 영향 범위(blast radius)를 사전에 정의
2. 점진적 확대: 알림 중복제거 → 인시던트 보강 → 진단 제안 → Runbook 실행 순으로 단계적 도입
3. 인간 개입 루프: 고위험·미지 패턴에는 반드시 승인 게이트 유지
4. 자동 롤백: 자동 조치 후 지표 악화 시 즉시 롤백되는 회로 차단기(circuit breaker) 설계
5. 감사 로그: 모든 자동 조치의 근거·결과·영향을 추적 가능한 형태로 기록AIOps는 운영자를 대체하지 않습니다. 운영자가 더 빠르고 정확하게 판단할 수 있도록 돕습니다.
이것이 #1에서 정의한 “운영 의사결정 보조 계층”의 의미가 Remediation 단계에서 구체화되는 방식입니다.
14. 개념 경계 (Concept Boundaries) — AIOps는 어디서 끝나는가
14.1 왜 개념 경계가 중요한가
AIOps를 실제 도입할 때 가장 흔한 혼선은 “이 기능은 AIOps 영역인가, 아니면 다른 플랫폼의 역할인가”입니다.
개념 경계가 흐릿하면 중복 투자, 책임 공백, 도구 난립이 발생합니다.
14.2 AIOps vs Observability Platform
| 구분 | Observability Platform | AIOps |
|---|---|---|
| 핵심 역할 | 데이터 수집·저장·조회 | 수집된 데이터로 의사결정 보조 |
| 주요 질문 | “무슨 일이 일어났는가?” | “왜 일어났으며 어떻게 해야 하는가?” |
| 출력물 | 대시보드, 알림, 쿼리 결과 | 상관된 인시던트, RCA 결과, 조치 추천 |
| 대표 도구 | Prometheus, Grafana, Jaeger, Loki | IBM AIOps Insights, BigPanda, Datadog Watchdog |
| ML 사용 | 제한적 (임계치 기반 알림이 주) | 핵심 (상관분석, RCA, 예측이 ML 의존) |
| 입력 범위 | Logs, Metrics, Traces | Observability 출력 + Topology + CMDB + Ticket |
경계선: Observability Platform은 데이터를 만들고, AIOps는 그 데이터를 소비합니다.
AIOps Layer 없이 Observability만 있으면 운영자가 직접 상관분석·RCA를 수행해야 합니다.
Gartner가 2025년 AIOps 시장을 EIS로 재프레이밍한 것도 이 역할 차이를 명확히 하기 위함입니다.
14.3 AIOps vs MLOps
| 구분 | AIOps | MLOps |
|---|---|---|
| 대상 | IT 운영 인프라 | ML 모델 파이프라인 |
| 목표 | MTTR 단축, 알림 노이즈 감소, 운영 자동화 | 모델 배포 안전성, 프로덕션 모델 정확도 유지 |
| 입력 데이터 | Logs, Metrics, Traces, Topology, Tickets | 학습 데이터, Feature Store, 실험 결과 |
| 주요 메트릭 | MTTR, Alert Noise Ratio, SLO Burn Rate | 모델 정확도(Accuracy, F1), Data Drift, Latency |
| 담당 조직 | SRE, Ops 팀 | ML Engineering, Data Science 팀 |
경계선: AIOps는 ML을 사용하는 운영 레이어입니다. MLOps는 ML 모델 자체를 운영하는 방법론입니다.
AIOps 플랫폼 내부에 ML 모델이 있다면, 그 모델을 관리하는 파이프라인이 MLOps입니다.
즉, 성숙한 조직에서는 AIOps 안에서 MLOps가 동작합니다.
14.4 AIOps vs ITSM
| 구분 | ITSM (IT Service Management) | AIOps |
|---|---|---|
| 핵심 기능 | 인시던트 관리, 변경 관리, 문제 관리 프로세스 | 이벤트 상관분석, 자동 RCA, 조치 추천 |
| 작동 방식 | 사람이 정의한 워크플로우 + 티켓 시스템 | AI/ML 기반 자동 분석 |
| 반응 속도 | 분~시간 단위 (수동 프로세스) | 초~분 단위 (자동 감지·분석) |
| 대표 도구 | ServiceNow ITSM, Jira Service Management | ServiceNow ITOM/AIOps, BigPanda, PagerDuty AIOps |
| 데이터 방향 | AIOps → ITSM (AIOps가 티켓 생성·업데이트) | ITSM 이력 데이터 → AIOps (학습 데이터로 활용) |
경계선: ITSM은 프로세스 관리 시스템이고, AIOps는 의사결정 지원 시스템입니다.
실무에서 두 시스템은 통합 운영됩니다. AIOps가 인시던트를 감지·분석하면 ITSM 티켓이 자동 생성되고,
ITSM의 과거 인시던트 이력이 AIOps의 RCA 학습 데이터로 활용됩니다.
ServiceNow는 2025년 ITOM(AIOps)과 ITSM을 단일 Service Operations Workspace로 통합했으나,
개념상 두 역할의 경계는 여전히 유효합니다.
14.5 개념 경계 한 눈에 보기

실무에서 자주 헷갈리는 경계 질문을 정리합니다.
| 경계 질문 | 답 |
|---|---|
| “Grafana 대시보드는 AIOps인가?” | 아닙니다. Observability Platform의 시각화 기능. |
| “Prometheus 알림 규칙은 AIOps인가?” | 아닙니다. 임계치 기반 Monitoring. AIOps의 입력이 될 수 있음. |
| “ServiceNow 티켓 자동 생성은 AIOps인가?” | AIOps의 출력을 ITSM에 전달하는 통합 포인트. AIOps 자체는 아님. |
| “Anomaly Detection 모델은 AIOps인가?” | AIOps의 기능 중 하나. AIOps 전체가 아님. |
| “ML 모델 학습 파이프라인 관리는 AIOps인가?” | MLOps 영역. AIOps가 이 모델을 사용함. |
15. 핵심 정리 — 1주차 요약
15.1 1주차 핵심 질문과 답
| 핵심 질문 | 답 |
|---|---|
| AIOps가 이상탐지와 다른 점은? | 이상탐지는 AIOps의 한 기능. AIOps = 운영 의사결정 보조 계층 전체 |
| Gartner EIS와 AIOps의 관계는? | Gartner가 2025년 AIOps 시장을 EIS(Event Intelligence Solutions) 관점으로 재프레이밍. 5가지 핵심 Capability: Ingestion → Topology → Correlation → Pattern Recognition → Remediation |
| Observability와 Monitoring의 차이? | Monitoring = 알고 있는 것 감시 / Observability = 모르는 것도 탐색 가능 |
| SRE와 AIOps의 접점? | Error Budget 소진 속도를 분석하고 배포·장애 우선순위 판단을 자동화 |
| 인시던트 라이프사이클과 AIOps? | Detection(MTTD) → Triage(MTTA) → RCA(MTTI) → Resolution(MTTR) → Postmortem. MTTR 단축 = Error Budget 보존 |
| Logs·Metrics·Traces 언제 각각 쓰나? | Metrics → “얼마나 나쁜가” / Traces → “어디서 느린가” / Logs → “정확히 무슨 일” |
| Sampling 전략은 어떻게 선택? | 비용 우선 → Head / 오류 보존 우선 → Tail / 실무 → 혼합 |
| Cardinality가 왜 위험한가? | 저장 비용 폭증 + ML 학습 실패 → AIOps 신뢰도 저하 |
| Clock Skew를 왜 신경 써야 하나? | Trace 인과관계 왜곡 → RCA 실패 → AIOps 판단 오류 |
| Missing Data가 Sampling보다 위험한 이유? | Sampling은 의도적 손실, Missing Data는 비의도적 유실 — 감지 자체가 불가능해 Silent Failure 유발 |
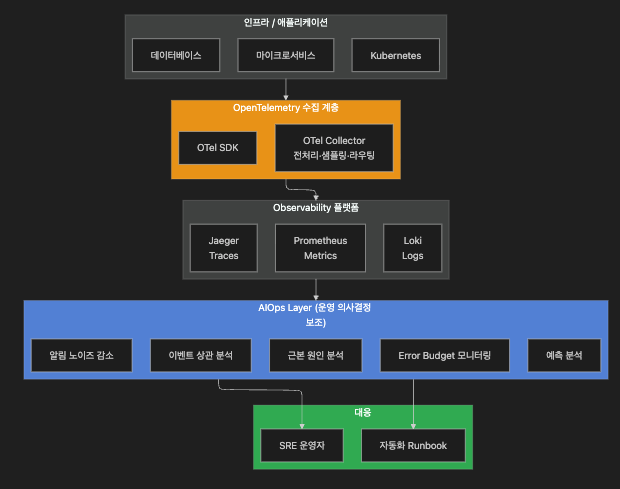
15.2 AIOps 전체 구조 — 1주차 종합
참고 자료
- IBM: What is AIOps?
- IBM: AIOps and Observability
- AWS: What is AIOps?
- Thoughtworks: AIOps in 2025
- OpenTelemetry: Sampling
- OpenTelemetry: Metrics Data Model
- Google SRE: Error Budget Policy
- Sedai: SRE Error Budgets
- BetterStack: OpenTelemetry Sampling Guide
- ACM: AIOps in the Era of LLMs Survey
- Google SRE: How SRE Relates to DevOps
- Google SRE: Implementing SLOs
- OpenTelemetry: Signals
- OpenTelemetry: Logs
- OpenTelemetry: Profiles (4th signal)
- OpenTelemetry: Collector Processors
- Jaeger: Clock Skew Adjustment
- BigPanda: Event Correlation in AIOps
- BigPanda: Why Event Correlation and How is AIOps Involved
- Algomox: Integrating LLM with AIOps for Enhanced Event Correlation
- Acure: Guide to Event Correlation in AIOps
- INOC: Event Correlation and Automation — What’s Possible in 2025
- Salesforce Engineering: AIOps — How AI and Automation Slash Manual Hours
- InsightFinder: AIOps vs MLOps Key Differences
- BMC: AIOps vs MLOps vs DevOps vs Observability
- LogicMonitor: AIOps vs DevOps vs MLOps vs Agentic AIOps
- ServiceNow: What is AIOps
- Selector AI: AIOps in 2025 — 4 Components and 4 Key Capabilities
