1. Deduplication — 중복 제거
1.1 왜 중복 제거가 필요한가
새벽 3시, DB 연결이 끊겼다고 가정합시다.
DB에 연결하는 서비스가 20개라면 알림이 20개 울립니다.
5분마다 재발화(re-fire)되는 규칙이 있다면 1시간 후에는 240개입니다.
실제로 확인해야 할 유니크한 상황은 단 1건입니다.
Deduplication(중복 제거) 은 이 문제를 해결하는 첫 번째 방어선입니다.
[중복 발생 예시]
13:00:01 ALERT: DB connection failed - service-A
13:00:03 ALERT: DB connection failed - service-B
13:00:05 ALERT: DB connection failed - service-C
13:05:01 ALERT: DB connection failed - service-A (5분 후 재발화)
13:05:03 ALERT: DB connection failed - service-B (5분 후 재발화)
...
Dedup 후 → 1건의 인시던트 "DB connection failure"로 압축1.2 Deduplication의 3가지 방식
| 방식 | 원리 | 장점 | 단점 |
|---|---|---|---|
| Hash-based | 이벤트의 핵심 필드를 해시 → 동일 해시면 중복 | 처리 빠름, 구현 단순 | 필드 값이 조금만 달라도 다른 이벤트로 인식 |
| Content-based | 메시지 내용의 의미적 유사도 비교 | 자연어 변형에도 중복 인식 | 계산 비용 높음, 임계치 설정 어려움 |
| Time-window | 지정된 시간 창 안에서 같은 출처·유형의 이벤트를 묶음 | 재발화 이벤트 처리에 효과적 | 창 크기 설정이 결과에 크게 영향 |
실무에서는 세 방식을 조합합니다. PagerDuty의 dedup_key, BigPanda의 primary/secondary property 방식이 대표적 구현입니다.
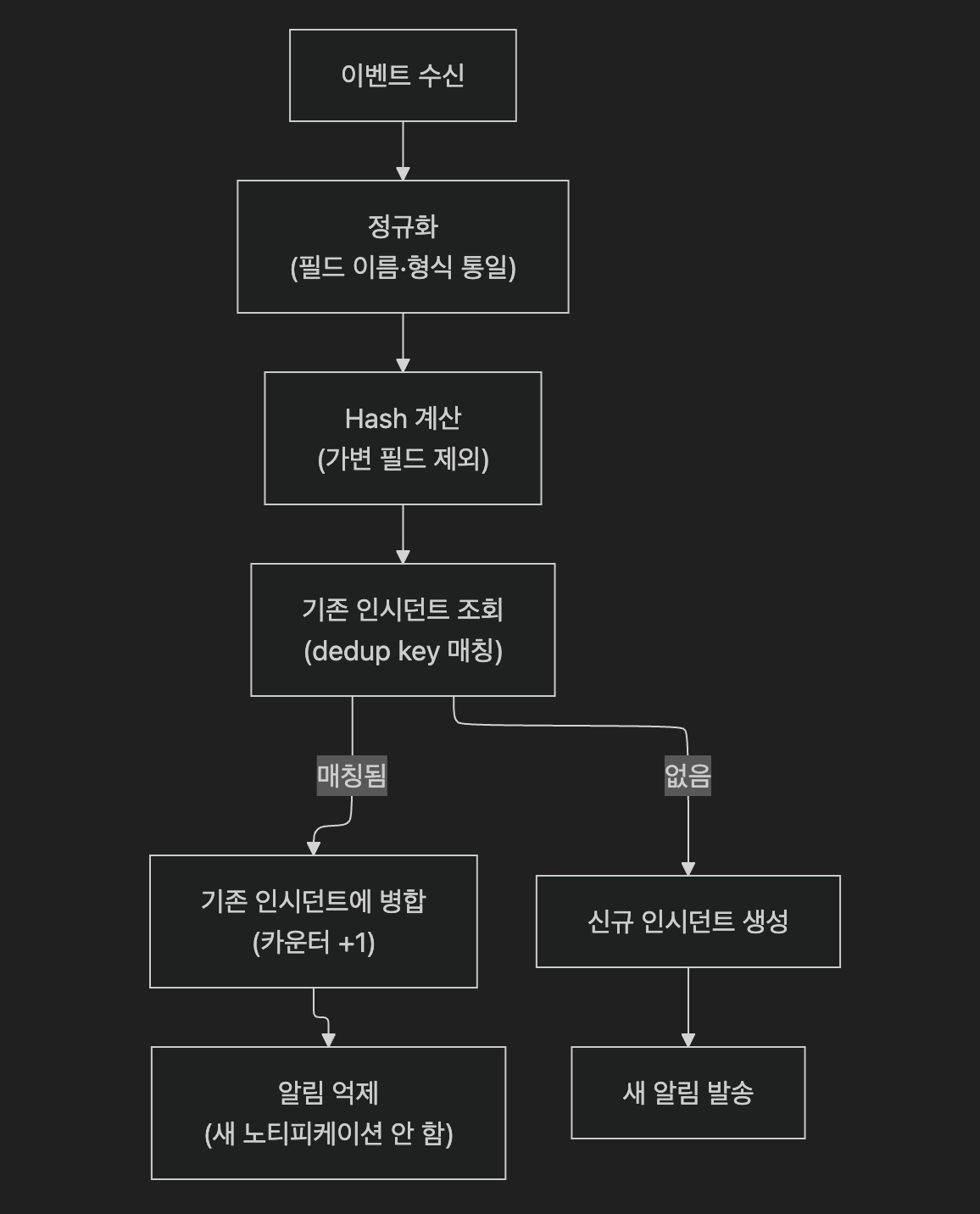
1.3 Hash-based Deduplication 동작 원리
import hashlib
def compute_dedup_key(event: dict) -> str:
"""핵심 필드만 추출해 해시 키 생성"""
key_fields = {
"source": event.get("source"),
"check_name": event.get("check"),
"severity": event.get("severity"),
"service": event.get("service"),
}
# 타임스탬프, UUID 같은 가변 필드는 반드시 제외
key_str = str(sorted(key_fields.items()))
return hashlib.md5(key_str.encode()).hexdigest()핵심: 해시 생성 시 타임스탬프, UUID, 자동 증가 ID 같은 가변 필드는 반드시 제외해야 합니다. 포함되면 같은 이벤트도 매번 다른 해시가 되어 dedup이 동작하지 않습니다.
1.4 Content-based Deduplication
로그 메시지는 동일한 오류라도 포맷이 다양합니다:
"Connection to DB refused at 192.168.1.10:5432"
"Failed to connect to database: connection refused"
"DB connection error: host=192.168.1.10 port=5432 status=refused"Hash-based 방식으론 중복으로 인식하지 못합니다.
Content-based dedup은 TF-IDF, 임베딩 벡터 유사도, 또는 LLM을 사용해 의미적으로 같은 이벤트를 묶습니다.
| 방식 | 유사도 계산 | 적합한 데이터 |
|---|---|---|
| Cosine Similarity (TF-IDF) | 단어 빈도 기반 벡터 거리 | 구조화된 로그 메시지 |
| Embedding 벡터 유사도 | 사전학습 언어모델 임베딩 | 자연어 혼합 로그 |
| Edit Distance (Levenshtein) | 문자 변환 횟수 | 템플릿 기반 로그 |
1.5 Deduplication 파이프라인
2. Baselining — 정상의 기준선
2.1 정적 임계치의 한계: “CPU 80% = 위험?”은 틀린 질문
운영 초기에 가장 흔히 쓰는 방식이 정적 임계치(static threshold)입니다:
alert: HighCPU
expr: cpu_usage > 80
for: 5m
labels:
severity: warning비유하면: “체온이 36.5°C를 넘으면 무조건 병원에 가세요” 와 같습니다.
달리기 직후, 여름 낮에는 37°C를 넘는 게 완전히 정상입니다.
CPU도 마찬가지입니다
새벽 3시 CPU 30% → 정상 (트래픽 없음)
낮 12시 CPU 85% → 정상 (점심 피크)
오전 9시 CPU 85% → 주의 (평시보다 높음)
새벽 3시 CPU 60% → 이상! (배치 작업 없는데 높음)정적 임계치는 이 맥락을 무시합니다.
결과는 낮에는 오탐 폭주(Alert Fatigue), 밤에는 미탐(사고 누락)입니다.
2.2 Baselining의 진화

| 세대 | 방식 | 특징 | 적합한 상황 |
|---|---|---|---|
| 1세대 | 정적 임계치 | 구현 단순, 맥락 무시 | 단조로운 메트릭 |
| 2세대 | 이동 평균 | 단기 추세 반영 | 완만한 변화 |
| 3세대 | z-score / Percentile | 통계적 이상 감지 | 정규분포에 가까운 메트릭 |
| 4세대 | STL 계절성 분해 | 주기적 패턴 분리 | 일/주 단위 주기성 |
| 5세대 | ML 기반 | 복합 패턴 학습 | 비즈니스 사이클 |
2.3 z-score 방식
현재 값이 평균에서 표준편차의 몇 배만큼 떨어져 있는지를 측정합니다.
z = (현재값 - 이동평균) / 이동표준편차
예: 이동평균 = 50%, 이동표준편차 = 5%
현재 CPU = 70%
z = (70 - 50) / 5 = 4.0
일반적 임계치: |z| > 3이면 이상 (99.7% 구간 밖)def zscore_anomaly(series, window=60, threshold=3.0):
rolling_mean = series.rolling(window).mean()
rolling_std = series.rolling(window).std()
z_scores = (series - rolling_mean) / rolling_std
return z_scores.abs() > threshold # True = 이상z-score의 약점: 정규분포를 가정합니다. 실제 운영 메트릭은 치우쳐 있거나(skewed) 두꺼운 꼬리(heavy-tailed)를 갖는 경우가 많아 오탐이 발생합니다.
2.4 계절성 분해 (STL)
실제 메트릭에는 규칙적 패턴이 있습니다
- 일별: 출근 시간에 CPU 오르고, 새벽에 낮아짐
- 주별: 주말에 트래픽 급감
- 월별: 급여일, 결산일에 DB 부하 폭증
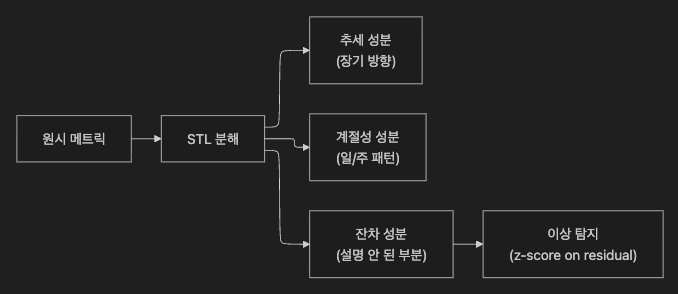
STL(Seasonal-Trend Decomposition using Loess) 은 시계열을 세 성분으로 분해합니다
관측값(Observed) = 추세(Trend) + 계절성(Seasonal) + 잔차(Residual)
이상 탐지는 Residual(설명되지 않은 부분)에서 수행
→ "원래 높아야 할 시간에 높다"는 이유의 오탐 제거참고: STL은 기본적으로 가산 모델(additive model)을 사용합니다.
계절 진폭이 수준에 비례하는 메트릭(예: 지수적 성장 트래픽)에는
로그 변환 후 STL 적용(사실상 곱셈 모델 효과)이 권장됩니다.
2.5 상용 플랫폼의 Dynamic Baselining
Datadog Anomaly Detection (3가지 알고리즘):
| 알고리즘 | 내부 방식 | 적합한 메트릭 |
|---|---|---|
| Basic | Rolling quantile (이동 분위수) | 계절성 없는 단순 메트릭 |
| Agile | SARIMA (계절성 ARIMA) | 계절성 있고 baseline 이동 잦은 메트릭 |
| Robust | STL (계절성-추세 분해) | 안정적 반복 패턴을 가진 메트릭 |
Dynatrace Davis AI의 Multi-dimensional Baselining:
- 지역(geo) x 브라우저 x OS x 사용자 액션 조합별로 개별 baseline 학습
- 예: “뉴욕에서 Chrome으로 결제 페이지 접근 시 응답시간” = 별도 baseline
- 즉시 작동(별도 학습 대기 기간 없음), 트래픽 패턴 변화에 자동 적응
- “특정 지역의 특정 브라우저에서만 느려지는” 이슈도 감지 가능
2025년 업데이트: Dynatrace는 Davis AI에 Preventive Operations 기능을 추가했습니다.
이상 탐지(reactive)를 넘어 장애 발생 전 예방적으로 조치를 취하는 예방적 AIOps입니다.
3. Event Correlation 심화
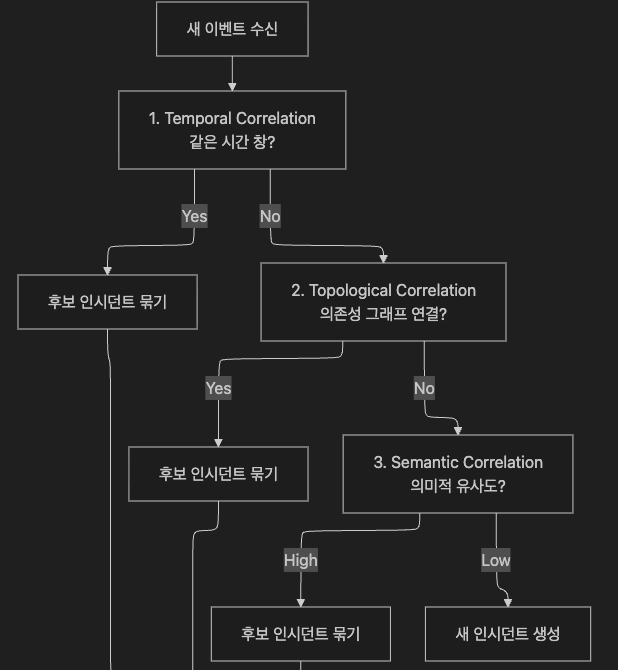
2주차에서 Event Correlation의 3가지 유형(Temporal, Topological, Semantic)을 소개했습니다.
3주차에서는 각 유형이 어떻게 동작하고, 어떤 상황에서 조합하는지 깊이 살펴봅니다.
3.1 Temporal Correlation — 시간 창 기반
“같은 시간대에 발생한 이벤트는 같은 원인일 가능성이 높다”는 가정입니다.
시간 창: 5분
[13:00:01] DB connection failed - service-A ┐
[13:00:03] DB connection failed - service-B │ 같은 창
[13:00:05] HTTP 500 spike - service-A ├→ 단일 인시던트
[13:01:30] Latency spike - service-B │
[13:02:00] SLO burn rate alert - payment ┘
[13:08:00] Memory OOM - service-C → 새 인시던트 (다른 창)한계 — 느린 원인-결과 체인
메모리 누수 시나리오:
[11:00] 메모리 사용량 증가 시작 (이상 없음)
[11:30] 메모리 80% 초과 (알림 발생)
[12:00] OOM Kill 발생
→ 11:30과 12:00은 30분 차이 → 5분 창으로는 상관 실패
→ 원인-결과 관계가 있어도 시간 차가 크면 별개 인시던트로 처리3.2 Topological Correlation — 의존성 그래프 기반
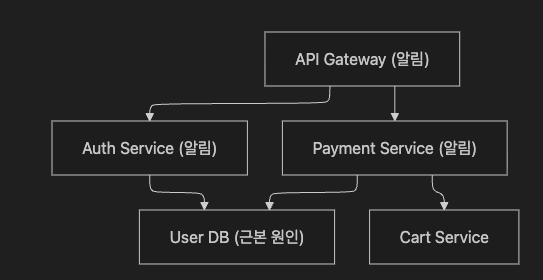
- Topological Correlation 없이 4개 서비스 알림 = 4개 별개 인시던트
- Topological Correlation 있으면 DB가 공통 의존성 → DB 장애 1건으로 통합, Root Cause 지목
핵심 위험 — Stale Topology
실제: service-A → new-db (3주 전 마이그레이션)
CMDB: service-A → old-db (마이그레이션 전 정보)
→ 엉뚱한 DB가 root cause로 지목 → MTTR 증가3.3 Semantic Correlation — 의미 기반
Temporal과 Topological이 모두 실패하는 경우를 보완합니다.
이벤트 1: "Authentication service returning 503 - dependency timeout"
이벤트 2: "User login API response time exceeded 5000ms"
이벤트 3: "JWT validation failed - service unavailable"
→ "authentication", "login", "JWT" 의미적 유사성 높음
→ Topological 연결 없어도 같은 인시던트로 그룹화| 방식 | 정밀도 | 비용 |
|---|---|---|
| TF-IDF 코사인 유사도 | 낮음 | 낮음 |
| Word2Vec/FastText 임베딩 | 중간 | 중간 |
| BERT/Sentence-BERT | 높음 | 높음 |
| LLM (GPT/Claude) | 매우 높음 | 매우 높음 |
최근 트렌드 (2025~2026): BigPanda, Datadog, IBM AIOps Insights는 세 방식을 앙상블로 조합합니다.
LLM 기반 Semantic Correlation은 2024년부터 프로덕션에 본격 도입되었으며,
2025~2026년에는 Agentic AIOps가 핵심 트렌드로 부상했습니다:
Correlation → 진단 → Remediation까지 AI 에이전트가 자율적으로 수행하는 구조입니다.
3.4 세 가지 Correlation의 조합 전략
4. Noise Reduction 파이프라인
4.1 전체 구조

4.2 각 단계의 효과
| 단계 | 제거 대상 | 기대 감소율 | 위험 |
|---|---|---|---|
| 필터링 | 임계치 미달, 테스트 환경 | 20~30% | 중요 이벤트도 필터될 위험 |
| Deduplication | 동일 이벤트 재발화 | 40~60% | 미묘하게 다른 이벤트 오인 |
| Correlation | 단일 원인 파생 다수 알림 | 70~90% | Stale topology 오상관 |
| Suppression | 예정된 유지보수, 알려진 FP | 5~15% | 실제 장애 억제 위험 |
BigPanda 사례: 고객사 평균 노이즈 감소율은 80~98%.
Transnetyx 사례에서는 96%의 이메일 알림 감소를 달성했습니다.
4.3 Suppression — 안전장치
suppression_rules:
- name: "DB Maintenance Window"
services: ["payment-db", "user-db"]
start: "2025-01-15 02:00 KST"
end: "2025-01-15 04:00 KST"
reason: "DB Index 재구성 작업"안전장치
1. Suppression 적용된 인시던트도 로그에는 기록 (감사 추적)
2. 임계 심각도(P1/Critical) 이상은 Suppression 예외 처리
3. Suppression 종료 후 미처리 인시던트 자동 재활성화
4. Suppression 규칙 만료일 강제 (무기한 Suppression 금지)
5. Anomaly Detection 진화 과정
5.1 4세대 진화
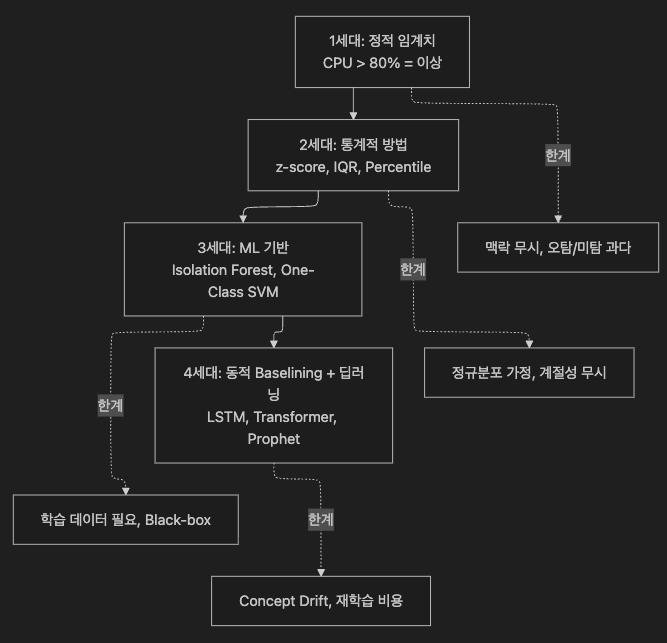
5.2 방법별 비교
| 방법 | 설명 가능성 | 계산 비용 | 계절성 | 새 패턴 탐지 | 학습 데이터 |
|---|---|---|---|---|---|
| 정적 임계치 | ★★★★★ | 매우 낮음 | X | X | 불필요 |
| z-score / IQR | ★★★★ | 낮음 | X | △ | 최소 |
| STL + 통계 | ★★★★ | 중간 | O | △ | 중간 |
| Isolation Forest | ★★ | 중간 | △ | O | 필요 |
| LSTM Autoencoder | ★ | 높음 | O | O | 대량 |
| Prophet | ★★★★ | 중간 | O | △ | 중간 |
5.3 TSB-AD 벤치마크의 발견 (NeurIPS 2024)
2024년 NeurIPS에 발표된 TSB-AD(“The Elephant in the Room”) 벤치마크는 업계의 상식을 뒤집었습니다.
40개 데이터셋, 1,070개 시계열, 40개 알고리즘을 비교한 결과
“심층 신경망의 우수성에 대한 통념에 의문을 제기하며, 단순한 아키텍처와 통계적 방법이 고급 신경망 아키텍처보다 더 나은 성능을 보이는 경우가 많다는 것을 밝혔습니다.”
상위 12개 방법 중
- 6개 이상: 통계 기반 방법 (Sub-PCA 1위)
- 2개: 신경망 기반 (USAD, CNN)
- 1개: Foundation Model (MOMENT)시사점
복잡한 딥러닝 모델이 항상 더 좋은 건 아닙니다.
도메인 특성에 맞는 방법 선택이 중요합니다.
6. 전통적 기법의 구조적 한계
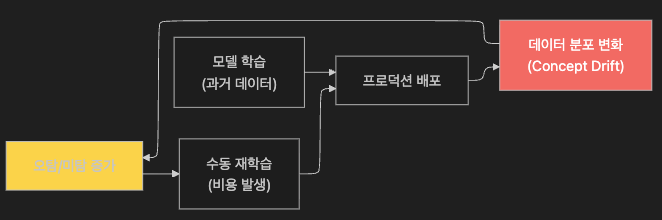
6.1 Concept Drift — “정상”의 정의가 시간에 따라 변한다
Concept Drift
란 학습 당시와 운영 시점에서 데이터 분포가 달라지는 현상입니다.
1년 전에 졸업한 학생의 성적 분포로 지금 학생을 평가하는 것과 같습니다.
Concept Drift의 3가지 유형
| 유형 | 설명 | 예시 |
|---|---|---|
| Gradual (점진) | 분포가 서서히 이동 | 서비스 성장에 따른 트래픽 증가 |
| Abrupt (급격) | 분포가 갑자기 변화 | 대규모 배포, 아키텍처 변경 |
| Recurring (반복) | 특정 조건에서 주기적으로 변화 | 세일 이벤트, 결산일 |
점진적 드리프트
모델 학습 시점: 일평균 요청 100만 건, CPU 평균 40%
6개월 후: 일평균 요청 500만 건, CPU 평균 70%
→ 기존 모델: CPU 70% = 이상 탐지 (사실은 새로운 정상)
급격한 드리프트
배포 전: 응답시간 50ms
새 기능 배포 후: 응답시간 200ms (더 많은 연산이 추가)
→ 기존 모델: 200ms = 이상 탐지 (사실은 의도된 변화)6.2 정적 임계치의 근본적 한계
같은 CPU 80%라도 맥락에 따라 의미가 완전히 다릅니다
| 맥락 | CPU 80%의 의미 |
|---|---|
| 평일 낮 12시 | 정상 피크 트래픽 |
| 새벽 3시 배치 없는 상황 | 심각한 이상 |
| 배포 직후 워밍업 중 | 일시적, 곧 정상화 |
| 마케팅 이벤트 시작 직후 | 예상된 증가 |
정적 임계치는 이 네 맥락을 전혀 구분할 수 없습니다.
6.3 상황 의존적 정상 개념
“지금 이 상황”이 정상의 기준을 결정합니다.
배포 직후 시나리오
배포 10분 전: CPU 30%, 응답시간 50ms → 정상
배포 직후: CPU 70%, 응답시간 150ms → "이상?" 아니면 "워밍업 중"?
배포 20분 후: CPU 40%, 응답시간 60ms → 정상
전통적 AIOps
→ 배포 직후 CPU 70% = 이상 탐지 = 오탐
→ 운영자가 "배포 직후라 일시적"이라고 무시
→ Alert Fatigue 심화| 상황 | 변경되어야 할 정상 기준 |
|---|---|
| 배포 직후 | CPU·메모리 증가 허용, 응답시간 허용 범위 확대 |
| 마케팅 이벤트 | 트래픽·DB 연결 수 임계치 상향 |
| DB 백업 시간 | I/O 급증 허용 |
| 결산/월말 | 재무 배치 프로세스 CPU 증가 허용 |
핵심: 전통적 기법은 배포 이력, 이벤트 캘린더, 업무 일정 같은 외부 컨텍스트를 소비할 구조가 없습니다.
6.4 수동 재학습 비용의 현실
서비스 100개 × 주요 메트릭 50개 = 5,000개 개별 baseline 모델
주간 배포 10회 × 서비스 10개 영향 = 주당 500개 재검토 필요
→ 전담 인력 없이는 "재학습 못 함" → Concept Drift 방치
→ 오탐 증가 → Alert Fatigue → 실제 장애 미탐6.5 한계 종합
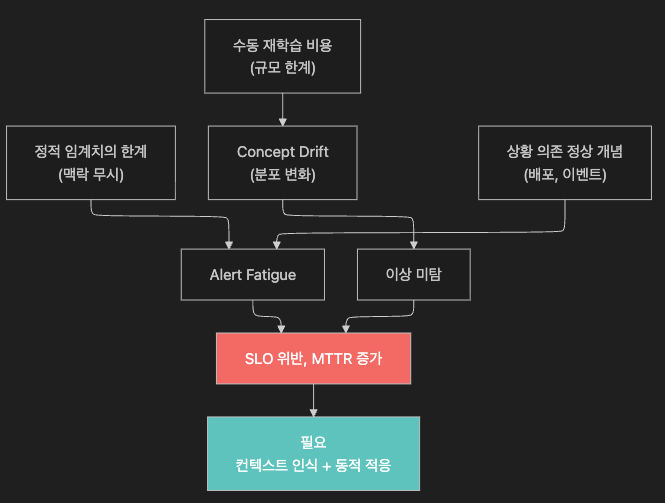
| 한계 | 근본 원인 | 필요한 해결 방향 |
|---|---|---|
| 정적 임계치 | 맥락(context) 무시 | 시간대·상황별 동적 임계치 |
| Concept Drift | 분포 변화 미감지 | 자동 드리프트 감지 + 적응 |
| 상황 의존 정상 | 외부 이벤트 통합 없음 | 이벤트 컨텍스트(covariate) 통합 |
| 재학습 비용 | 수동 MLOps | Zero-shot 또는 자동 continuous learning |
7. 전통에서 현대로 — 패러다임 전환의 큰 그림
7.1 5세대 기술 진화

7.2 각 세대별 대표 도구
1세대 (규칙 기반, ~2010)
- Nagios, Zabbix의 임계값 경보
- 장점: 설명 가능성 최고, 설정 단순
- 단점: 규칙 유지 비용 폭발, 동적 환경 대응 불가
2세대 (통계 기반, 2010~2016)
- Facebook Prophet, Netflix Atlas, Twitter Breakout Detection
- 장점: 계절성 자동 처리, 통계적 신뢰 구간
- 단점: 복잡한 비선형 패턴 처리 어려움, 시리즈별 피팅 필요
3세대 (ML 기반, 2016~2023)
- Isolation Forest, LSTM Autoencoder, RRCF (AWS CloudWatch 채택)
- 장점: 복잡한 패턴 학습 가능
- 단점: 도메인별 재학습 필요, Concept Drift 취약
4세대 (Foundation Model, 2023~현재)
- Chronos-2 (Amazon), TimesFM 2.5 (Google), Moirai (Salesforce)
- 장점: 일반화 능력, 빠른 배포, Zero-shot
- 단점: 높은 초기 계산 비용, 설명 가능성 제한
8. TSAD 최신 연구 동향
8.1 TSAD란?
Time Series Anomaly Detection(TSAD) 는 시계열 데이터에서 정상 패턴으로부터 이탈한 지점이나 구간을 자동으로 식별하는 기술입니다.
정상 패턴: ─────╱╲─────╱╲─────╱╲─────
Point: ─────╱╲──█──╱╲─────╱╲───── (단일 스파이크)
Level Shift:─────╱╲────────────╱╲───── (기준선 변화)
Contextual: ─────╱╲─────╱╲─█───╱╲───── (계절성 맥락에서 이상)
Collective: ─────╱╲──█████──╱╲──────── (연속 이상 구간)8.2 TSAD의 3대 핵심 도전
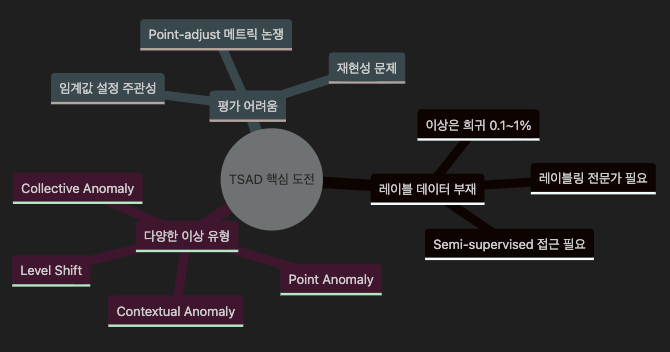
평가의 어려움 — 충격적 발견 (VLDB 2022)
“Towards a Rigorous Evaluation of Time-Series Anomaly Detection” 연구에서 기존 벤치마크의 무작위 분류기(random classifier)가 SOTA 모델과 비슷한 성능을 보이는 경우가 있었습니다. 널리 쓰이던 “point-adjust” 평가 방식의 허점 때문이었습니다.
8.3 주요 TSAD 벤치마크
| 벤치마크 | 규모 | 특징 |
|---|---|---|
| TSB-UAD | 1,980개 시계열, 18개 알고리즘 | 공정한 표준화 평가 |
| TimeEval | 700+ 데이터셋, 70개 알고리즘 | 도커 기반 재현 가능 평가 |
| TSB-AD (NeurIPS 2024) | 1,070개 시계열, 40개 알고리즘 | 통계 방법 vs 딥러닝 대규모 비교 |
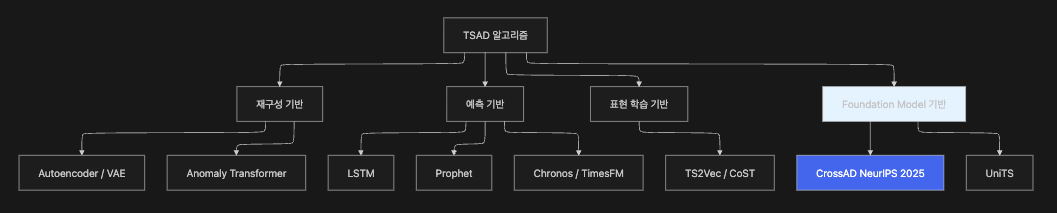
8.4 TSAD 알고리즘 분류
9. CrossAD — 스케일 경계를 넘는 이상 탐지 (NeurIPS 2025)
9.1 해결하는 문제
기존 TSAD의 중요한 한계는 고정 윈도우 + 단일 스케일 문제입니다.
슬라이딩 윈도우 방식은 창 바깥의 맥락을 활용하지 못하고, 단일 해상도로만 패턴을 보기 때문에 다양한 스케일의 이상 패턴을 놓칩니다.
AIOps에서 이는 다음과 같은 문제를 유발합니다:
- 1분 단위 메트릭에서 포착되지 않는 이상이 5분 단위에서는 뚜렷하게 보이는 경우
- 좁은 시간 창이 장기 맥락(주간 패턴, 배포 사이클)을 차단하는 경우
- 이상이 발생할 때 스케일 간 관계가 정상 때와 다르게 변화하는 특성 미활용
9.2 CrossAD의 핵심 아이디어
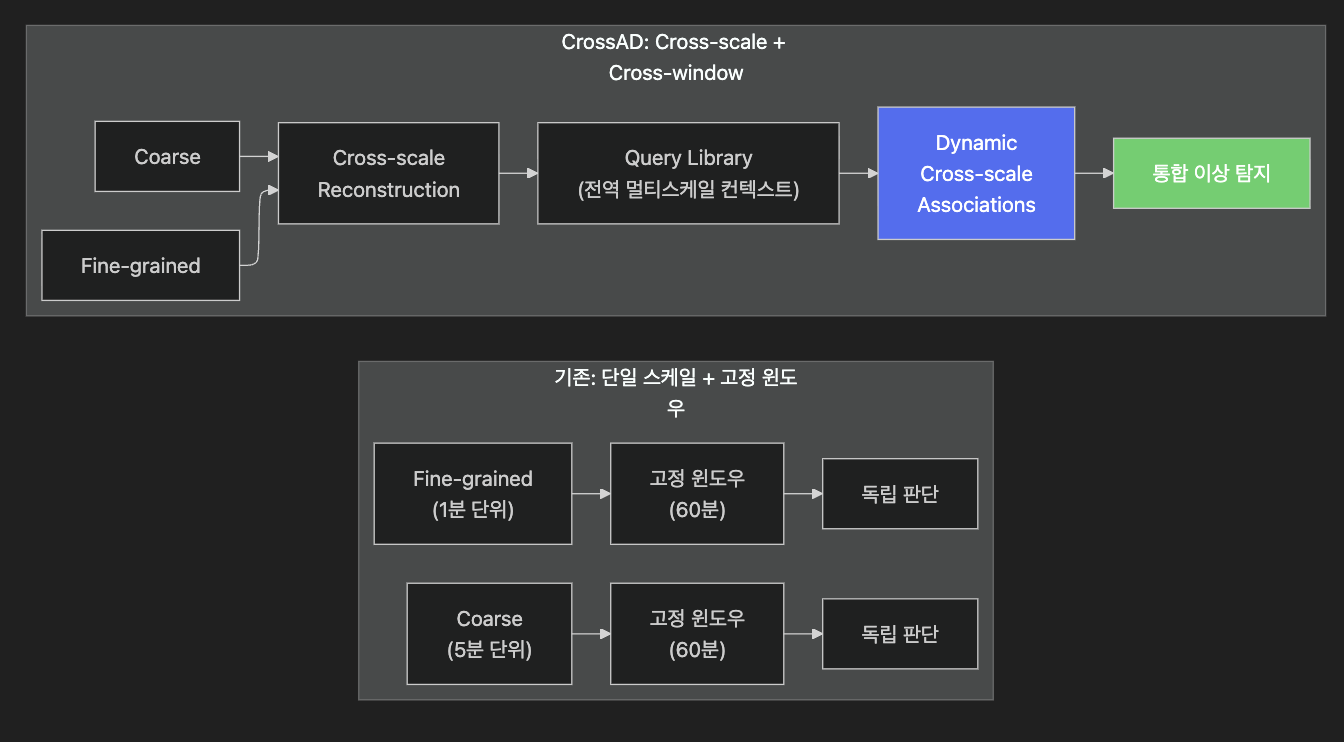
핵심 기술
1. Cross-scale Reconstruction
거친 해상도(coarse) 시계열에서 세밀 해상도(fine-grained)를 재구성하여,
스케일 간 연관성을 명시적으로 학습
- Cross-window Modeling (Query Library)
전역 멀티스케일 컨텍스트를 유지하는 쿼리 라이브러리로 고정 윈도우 한계 극복
- Dynamic Cross-scale Associations
이상 발생 시 스케일 간 관계가 어떻게 변화하는지 동적으로 모델링
9.3 기존 방법과 차별점
| 특성 | 기존 단일 스케일 | CrossAD |
|---|---|---|
| 스케일 처리 | 단일 해상도 독립 처리 | 멀티스케일 교차 연관 학습 |
| 컨텍스트 활용 | 고정 창 내부만 | 전역 쿼리 라이브러리로 확장 |
| 이상 패턴 인식 | 스케일별 독립 판단 | 스케일 간 동적 변화 활용 |
| 모델 복잡도 | 스케일별 별도 모델 또는 고정 창 | 단일 통합 모델 |
실제 성과
- 7개 실제 데이터셋, 9개 평가 지표에서 SOTA 달성
- GitHub: decisionintelligence/CrossAD
10. Forecasting Foundation Model 개요
10.1 Foundation Model이란
NLP에서 GPT·BERT가 수백억 텍스트로 사전 학습된 후 다양한 태스크에 재사용되듯,
시계열 Foundation Model은 같은 아이디어를 숫자 데이터에 적용한 것입니다.
기존: 에너지 → 에너지 모델 / 트래픽 → 트래픽 모델 / CPU → CPU 모델
FFM: 에너지·날씨·금융·IoT·트래픽 등 수억 시계열로 사전 학습
→ 처음 보는 서버 CPU 데이터도 즉시 예측 가능| 구분 | Task-Specific 모델 | Foundation Model |
|---|---|---|
| 학습 데이터 | 특정 도메인 (수천~수만) | 수십억 다양한 시계열 |
| 신규 태스크 | 재학습 필요 | Zero-shot 즉시 적용 |
| 유지보수 | 도메인별 모델 관리 | 단일 모델 관리 |
| Concept Drift | 재학습해야 적응 | 사전 학습 패턴으로 자동 적응 |
10.2 “Foundation”인 이유 — 방대한 다양성
핵심은 모델의 크기가 아니라 도메인의 다양성입니다. 에너지·교통·금융·클라우드 운영·날씨·웹 트래픽 등 수십억 개의 실제 시계열로 학습하여 “시계열이 일반적으로 어떻게 생겼는지”를 이미 알고 있습니다.
마치 수십 년간 다양한 분야의 데이터를 본 전문가처럼, 처음 보는 데이터도 기존 패턴에서 유추해 예측합니다.
10.3 Zero-Shot 예측
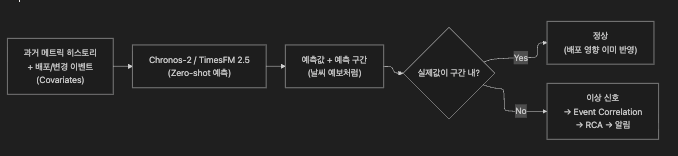
Zero-Shot Forecasting은 모델이 특정 데이터셋을 한 번도 본 적 없어도 예측하는 능력입니다.
전통적 시계열 모델
1. 데이터 수집 → 2. 피처 엔지니어링 → 3. 모델 훈련
→ 4. 검증·튜닝 → 5. 배포
→ 최소 수일~수주
FFM Zero-Shot
1. 최근 히스토리 준비 → 2. FFM에 입력 → 3. 즉시 예측
→ 수초 이내10.4 FFM 생태계 (2025~2026)
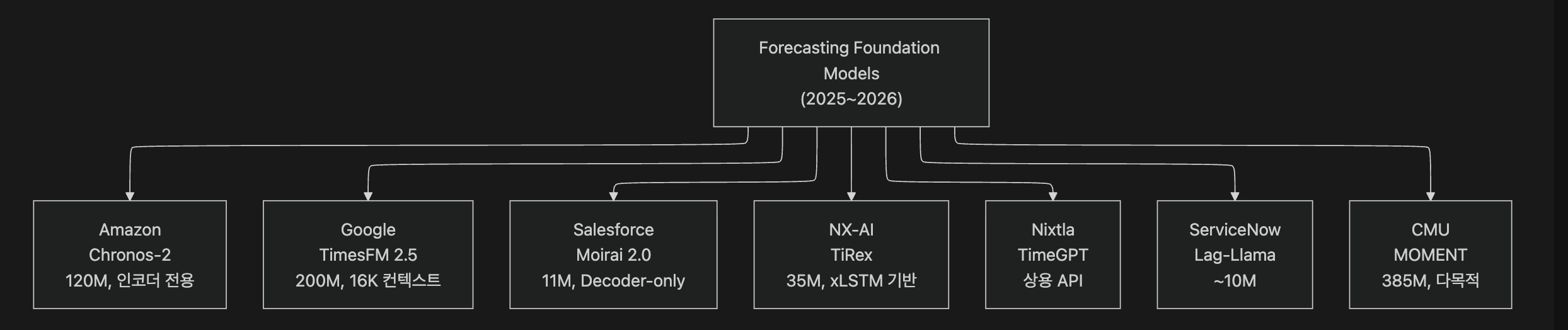
| 모델 | 개발사 | 파라미터 | 특징 | 오픈소스 |
|---|---|---|---|---|
| Chronos-2 | Amazon | 120M | 다변량+공변량, Group Attention | O |
| TimesFM 2.5 | 200M | 16K 컨텍스트, XReg 공변량 | O | |
| Moirai 2.0 | Salesforce | 11M | Decoder-only, Multi-token prediction | O |
| TiRex | NX-AI | 35M | xLSTM 기반, Transformer 비의존 | O |
| TimeGPT | Nixtla | - | API 서비스, 이상탐지 내장 | X (상용) |
| Lag-Llama | ServiceNow | ~10M | 확률론적, Llama 기반 | O |
| MOMENT | CMU | 385M | 다목적 (예측·분류·이상탐지 직접 지원) | O |
11. Chronos-2 (Amazon)
논문: Chronos-2: From Univariate to Universal Forecasting (arXiv:2510.15821, 2025)
GitHub: amazon-science/chronos-forecasting
11.1 v1 → v2: 무엇이 바뀌었나
Chronos v1(2024)의 핵심 한계는 단변량만 처리 가능이었습니다. CPU 하나만 보고 예측할 수는 있지만, “CPU + 메모리 + 배포 여부”를 함께 고려하는 것은 불가능했습니다.
Chronos-2는 이 한계를 없앴습니다. 제목 “From Univariate to Universal”이 이를 표현합니다.
| 항목 | Chronos v1 | Chronos-2 |
|---|---|---|
| 지원 입력 | 단변량 | 단변량 + 다변량 + 공변량 |
| 아키텍처 | T5 인코더-디코더 | T5 인코더 전용 |
| 분위수 수 | 9개 | 21개 (0.01 ~ 0.99) |
| 최대 컨텍스트 | 2,048 토큰 | 8,192 토큰 |
| 핵심 메커니즘 | Patch-based | Group Attention (신규) |
| 파라미터 수 | 205M (Base) | 120M |
11.2 아키텍처 — 시계열의 언어화
Chronos의 핵심 아이디어는 시계열 값을 토큰으로 변환해 언어 모델처럼 처리하는 것입니다.

11.3 Group Attention — 핵심 혁신
일반 Attention이 하나의 시계열 내 시간 흐름을 처리한다면,
Group Attention은 여러 시계열 간의 관계를 학습합니다.
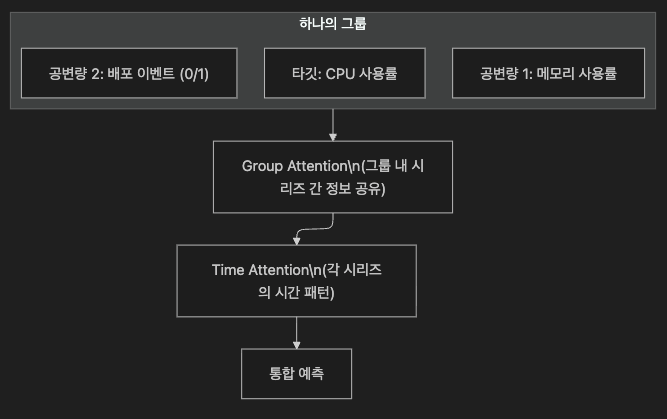
이를 통해:
- 단변량: 시계열 1개 → 기존 방식과 동일
- 다변량: 연관된 여러 시계열을 하나의 그룹으로 처리
- 공변량 포함: 타깃 시계열 + 외부 변수(배포 이벤트 등)를 함께 그룹화
11.4 벤치마크 성능
| 벤치마크 | 태스크 수 | Chronos-2 승률 | 2위 모델 |
|---|---|---|---|
| fev-bench | 100개 | 90.7% | TiRex (80.8%) |
| GIFT-Eval | 97개 | 81.9% | TimesFM-2.5 (77.5%) |
| Chronos Benchmark II | 27개 | 79.8% | TiRex (70.4%) |
12. TimesFM 2.5 (Google)
논문: A decoder-only foundation model for time-series forecasting (arXiv:2310.10688, ICML 2024)
GitHub: google-research/timesfm
12.1 버전 계보
| 버전 | 파라미터 | 컨텍스트 | 주요 특징 |
|---|---|---|---|
| 1.0 | 200M | 512 | 최초 decoder-only 시계열 FM |
| 2.0 | 500M | 2,048 | GIFT-Eval 1위 (2025 초) |
| 2.5 | 200M | 16,384 | 파라미터 60% 감소, 컨텍스트 8배 확장, XReg |
주목: 2.5는 파라미터를 절반 이하로 줄이면서 성능은 향상되었습니다. 모델 크기와 성능이 비례하지 않는다는 사례입니다.
12.2 아키텍처 — Decoder-Only Transformer
GPT와 유사한 구조를 시계열에 적용합니다.

12.3 16K 컨텍스트가 AIOps에서 중요한 이유
TimesFM 1.0 (512 스텝, 1분 단위): 약 8.5시간 히스토리
TimesFM 2.5 (16,384 스텝, 1분 단위): 약 11.4일 히스토리
→ 주간 패턴(월요일 트래픽 급증 등) 충분히 학습
→ 배포 주기(보통 1~2주) 커버
→ 드물게 발생하는 월말 배치 작업 패턴도 인식실무 참고:
16,384는 아키텍처상 지원 최대값이며, 기본 설정(max_context=1024)은
약 17시간(1분 단위)입니다.
장기 패턴이 필요한 경우 max_context를 늘릴 수 있으나,
메모리와 추론 비용도 증가합니다.
12.4 XReg — 공변량 지원
TimesFM 2.5의 XReg(External Regressor) 는 4가지 유형의 공변량을 지원합니다
| 유형 | 설명 | AIOps 예시 |
|---|---|---|
| Static Categorical | 시리즈당 고정 카테고리 | 서비스 유형 (API/배치/스트리밍) |
| Static Numerical | 시리즈당 고정 숫자 | 서버 티어, SLO 임계치 |
| Dynamic Categorical | 시간에 따라 변하는 카테고리 | 배포 상태 (배포중/안정/롤백) |
| Dynamic Numerical | 시간에 따라 변하는 숫자 | 동시 접속자 수, 큐 깊이 |
import timesfm
model = timesfm.TimesFM_2p5_200M_torch.from_pretrained(
"google/timesfm-2.5-200m-pytorch"
)
# 공변량 포함 예측
forecast = model.forecast_with_covariates(
inputs=historical_metrics,
dynamic_numerical_covariates={
"deployment_flag": deployment_series,
"upstream_latency": upstream_latency,
},
dynamic_categorical_covariates={
"event_type": event_type_series,
},
static_categorical_covariates={
"service_tier": ["critical"],
},
)13. FFM 기반 간접 이상 탐지
13.1 핵심 원칙: Forecasting FFM은 예측 기반 간접 탐지를 사용한다
Chronos-2와 TimesFM 2.5는 “이것은 이상이다”라고 직접 말하지 않습니다.
이 모델들은 forecasting 전문 모델로, 이상 탐지는 예측 결과를 이용한 간접 탐지 경로로 이루어집니다.
참고: MOMENT(CMU)나 TimeGPT(Nixtla)처럼 이상 탐지를 직접 수행하도록 설계된 FFM도 존재합니다.
MOMENT는 사전 학습된 reconstruction head로 zero-shot 이상 점수를 직접 출력하고,
TimeGPT는anomaly_detection()API로 이상 여부를 직접 플래그합니다.
본 섹션에서 소개하는 간접 탐지는 Chronos-2, TimesFM 2.5 같은 순수 forecasting FFM에 해당합니다.
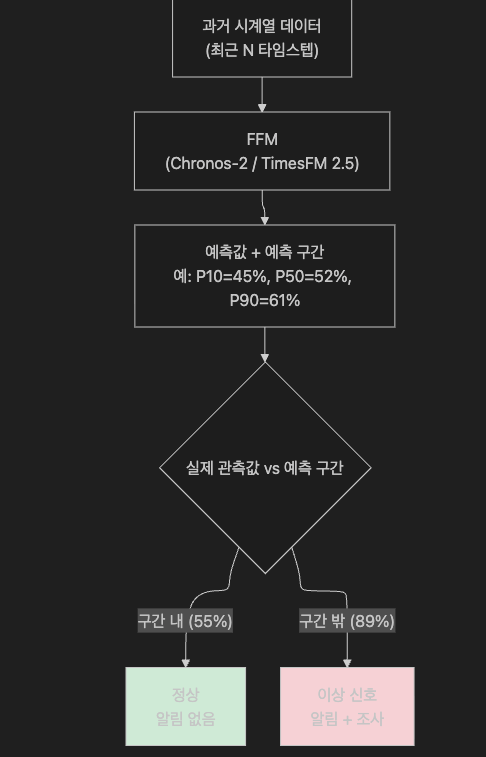
13.2 예측 구간이란
FFM의 예측 결과는 단일 숫자가 아니라 확률 분포입니다.
예측 시각: 2025-04-16 14:00
타깃: payment-service CPU 사용률
FFM 예측:
P10 = 42% (하위 10%)
P25 = 47%
P50 = 53% (중앙값)
P75 = 59%
P90 = 66% (상위 10%)
실제 관측값: 87%
→ P90(66%)을 크게 초과 → 이상 신호마치 기상청에서 “최저 18°C ~ 최고 26°C 예상”이라고 했는데 35°C가 나오면 이상 기상인 것과 같습니다.
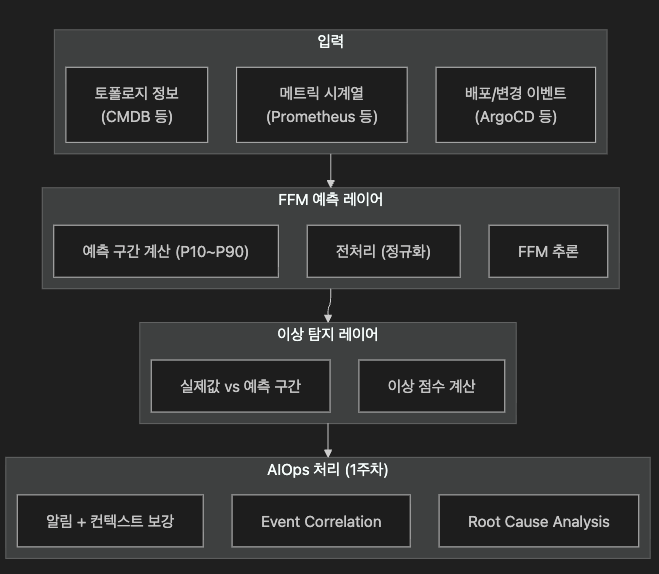
13.3 AIOps 파이프라인에서의 위치
13.4 실용적 서빙 아키텍처
FFM을 실시간 탐지에 직접 사용하면 레이턴시 문제가 생깁니다.
실무에서는 배치 예측 + 캐싱 방식을 권장합니다

이 아키텍처의 장점
- 실제 탐지 경로에서 FFM 추론 비용 제거
- 예측 구간이 캐싱되어 밀리초 수준 탐지 가능
- GPU 자원을 배치로 효율적 사용
13.5 Conformal Prediction — 예측 구간의 통계적 보장
FFM의 예측 구간이 의미 있으려면 “P90 구간”이 실제로 90%를 커버해야 합니다.
Conformal Prediction은 분포 가정 없이 통계적으로 보증된 Coverage를 제공하며, 2026년 현재 FFM 예측 구간 보정의 산업 표준으로 자리 잡고 있습니다. ICLR 2026 채택 연구(“Adaptive Conformal Anomaly Detection with FFM”)는 False Alarm Rate를 수학적으로 제어 가능하게 만들었습니다.
상세: Conformal Prediction의 기법별 비교(Split/Adaptive/CPTC)와 학습 리소스는 보조 자료 §7을 참고하세요.
14. Covariate-informed Forecasting 심화
14.1 Covariate란?
Covariate(공변량) 는 예측 대상 시계열 외에 예측에 영향을 주는 추가 정보입니다.
일반 예측: ŷ(t) = f(y(t-1), y(t-2), ..., y(t-n))
Covariate 예측: ŷ(t) = f(y(t-1), ..., y(t-n), x₁(t), x₂(t), ..., xₖ(t))14.2 AIOps에서의 4가지 핵심 Covariate
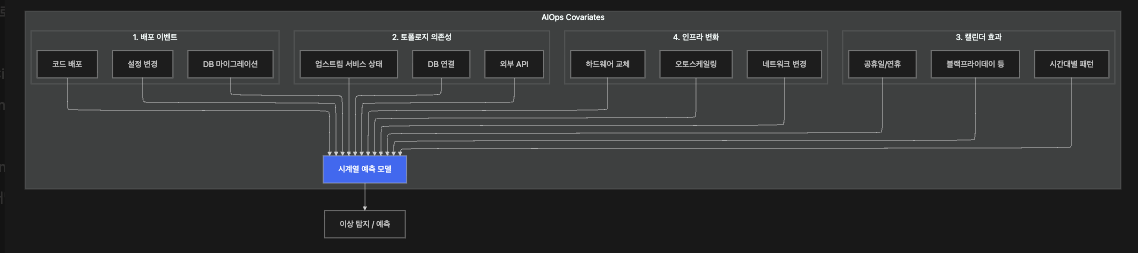
14.3 배포 이벤트 — 가장 효과적인 Covariate
배포 Covariate 없는 탐지:
응답시간: ───50ms──[배포]──200ms────100ms─────
탐지: 정상 ████이상████ 정상 ← 잘못된 경보!
배포 Covariate 포함 탐지:
응답시간: ───50ms──[배포=1]──200ms────100ms─────
탐지: 정상 정상(배포 중) 정상 ← 올바른 판단!14.4 토폴로지 의존성 — 연쇄 반응 예측
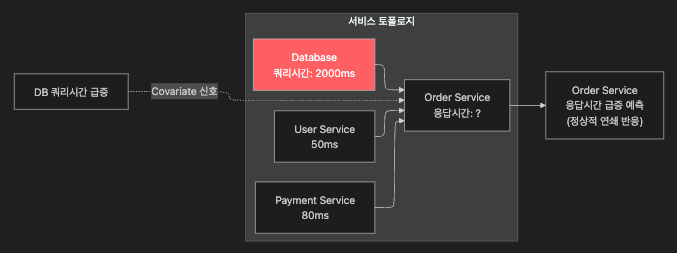
14.5 Covariate의 False Positive 감소 효과
| Covariate 유형 | FP 감소율 | 적용 난이도 |
|---|---|---|
| 배포 이벤트 | 30~50% | 낮음 (CI/CD 연동) |
| 캘린더 효과 | 20~35% | 매우 낮음 |
| 토폴로지 의존성 | 25~40% | 중간 (Service Mesh 필요) |
| 인프라 변화 | 15~25% | 높음 (CMDB 연동) |
| 모든 Covariate 결합 | 50~70% | 높음 |
15. 종합 비교 — 전통 vs FFM 기반 이상 탐지
15.1 상세 비교표
| 비교 차원 | 규칙 기반 | 통계 (ARIMA/Prophet) | ML (LSTM/IF) | Foundation Model |
|---|---|---|---|---|
| 학습 방식 | 규칙 수동 작성 | 시리즈별 피팅 | 도메인별 학습 | 대규모 사전학습 + Zero-shot |
| Concept Drift | 수동 규칙 업데이트 | 주기적 재피팅 | 재학습 파이프라인 | 자연스러운 적응 |
| Zero-shot | N/A | 불가 | 불가 | 가능 |
| Covariate 지원 | 규칙에 하드코딩 | Prophet: 제한적 | 피처로 입력 | TimesFM 2.5: 완전 지원 |
| 설명 가능성 | 매우 높음 | 높음 | 중간 | 낮음 (black-box) |
| 운영 비용 | 규칙 유지 높음 | 재학습 시 낮음 | 재학습 인프라 | 추론 GPU, 관리 낮음 |
| 데이터 요구량 | 없음 | 1~2시즌 | 수천~수만 포인트 | 없음 (Zero-shot) |
| 확장성 (시리즈 수) | 낮음 (규칙 폭발) | 중간 | 높음 | 매우 높음 |
| 실시간 처리 | 매우 빠름 | 빠름 | 중간 | 느림 (GPU) |
| 적합 시나리오 | 컴플라이언스 | 안정적·계절성 명확 | 데이터 풍부 | 다양한 도메인, 새 서비스 |
15.2 방법론 선택 가이드
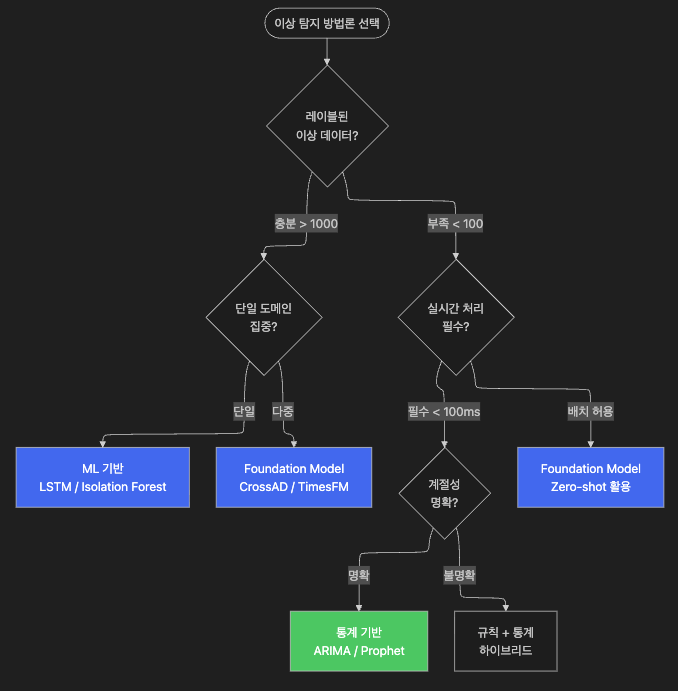
16. 실무 적용 로드맵
Foundation Model이 아무리 뛰어나도 “빅뱅” 방식의 전체 교체는 위험합니다.
점진적 3단계 접근을 권장합니다.
Phase 1: 전통 기법으로 기반 구축
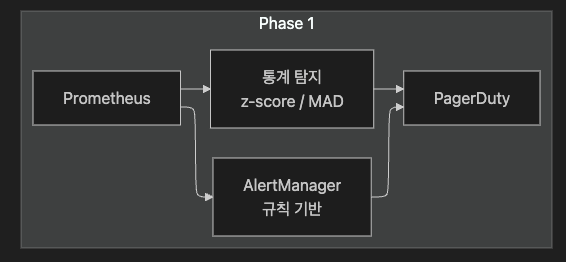
주요 작업
1. 모든 서비스에 Golden Signals (Latency, Traffic, Errors, Saturation) 커버
2. 기본 통계 탐지 (z-score, Percentile) 도입
3. CI/CD → 이벤트 수집 파이프라인 구축 (배포 이벤트 저장)
4. 현재 False Positive Rate, MTTD, MTTR 측정 (기준선 확립)
성공 기준: Golden Signals 커버리지 100%, Alert Storm 30% 감소
Phase 2: FFM 도입으로 보완
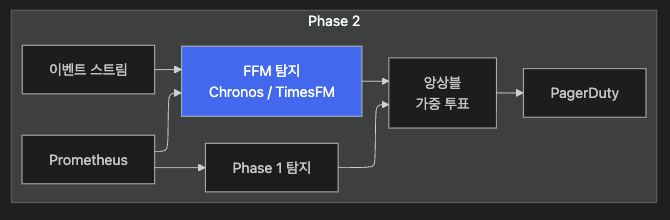
주요 작업:
1. 잘 아는 메트릭 3~5개로 FFM 파일럿
2. 배포 이벤트를 Covariate로 연동
3. A/B 비교: Shadow mode(FFM 결과 로그만 기록, 실제 경보는 Phase 1 사용)
4. 2~3개월 검증 후 점진적 비중 이동
성공 기준: FFM Precision > 85%, 배포 관련 FP 50% 감소
Phase 3: 하이브리드 파이프라인
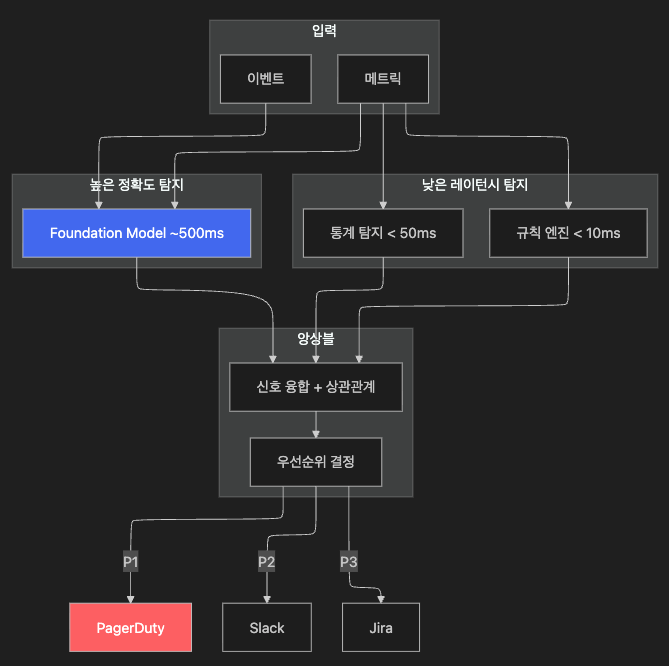
핵심 설계 원칙
def ensemble_anomaly_score(rule_score, stat_score, ffm_score,
has_deployment_event=False):
"""상황에 따른 동적 가중치 앙상블"""
if has_deployment_event:
# 배포 중에는 FFM(covariate 포함) 가중치 높임
weights = {"rule": 0.1, "stat": 0.2, "ffm": 0.7}
else:
weights = {"rule": 0.3, "stat": 0.3, "ffm": 0.4}
return (weights["rule"] * rule_score +
weights["stat"] * stat_score +
weights["ffm"] * ffm_score)성공 기준: FP Rate < 10%, MTTD 50% 감소, 야간 호출 70% 감소
단계별 리소스 요약
| 항목 | Phase 1 | Phase 2 | Phase 3 |
|---|---|---|---|
| 팀 구성 | 1~2 SRE | +1 ML 엔지니어 | +1 데이터 엔지니어 |
| 인프라 | Prometheus/Grafana | + GPU 서버 (소형) | + GPU 클러스터 |
| 기간 | 3~6개월 | 6~9개월 | 지속적 개선 |
| 핵심 도구 | Prometheus, AlertManager | Chronos, TimesFM | CrossAD, 커스텀 앙상블 |
| 예상 효과 | 기반 구축 | Alert 30% 감소 | Alert 70% 감소 |
16-1. 2026년 핵심 트렌드: Agentic AIOps
본문에서 학습한 전통 AIOps + FFM 탐지는 “고품질 알림을 만드는” 레이어입니다.
2025~2026년에 급부상한 Agentic AIOps는 알림을 받아 스스로 진단하고 행동까지 완료하는 다음 단계입니다.
Agentic AIOps란
LLM 기반 AI 에이전트가 이상 탐지 → RCA → Runbook 실행 → 복구까지 자율적으로 수행하는 패러다임입니다.
단일 에이전트가 아닌 Multi-Agent 오케스트레이션이 핵심으로, 탐지/진단/복구 전문 에이전트가 협업합니다.
2025~2026 상용 사례
| 플랫폼 | 기능 | 출시 |
|---|---|---|
| Dynatrace Intelligence | Deterministic AI + Agentic AI 결합, 사전 예방적 운영 | 2025.02 |
| PagerDuty SRE Agent | 자율 인시던트 조사, MCP 기반 멀티에이전트 협업 | 2025 H2 GA |
| AWS DevOps Agent | CloudWatch 알람 → 자동 진단 → 복구 (4분 이내) | 2025 |
| New Relic SRE Agent | MCP 서버로 ServiceNow/Atlassian/PagerDuty 연동 | 2026 |
| Azure SRE Agent | MCP 서버로 Dynatrace/New Relic/Datadog 연동 자동 복구 | 2026 |
현재 한계
- OpenRCA(Microsoft, ICLR 2025) 벤치마크: 최고 모델도 11.34% 해결률 — 자율 복구는 아직 초기 단계
- 고위험 조치에는 여전히 Approval Gate(승인 게이트) 필수
상세: Agentic AIOps의 심화 분석, MCP(Model Context Protocol) 표준, OWASP 보안 고려사항은 보조 자료 §16, §23을 참고하세요.
참고: AIOpsLab (MLSys 2025) / OpenRCA (ICLR 2025) / AWS DevOps Agent
17. 핵심 정리
3주차 핵심 질문과 답
| 질문 | 답 |
|---|---|
| Deduplication은 왜 필요한가? | DB 장애 1건이 240개 알림으로 폭발하는 것을 1건으로 압축하는 첫 번째 방어선 |
| 정적 임계치의 근본 문제는? | 맥락 무시 — 같은 CPU 80%가 낮과 밤에 다른 의미를 가짐 |
| Dynamic Baselining은 무엇인가? | 시간대·계절성을 학습하여 “지금 이 시간에 정상인 범위”를 자동으로 계산 |
| Concept Drift가 위험한 이유? | 학습 당시의 “정상”이 6개월 후에는 “정상”이 아니게 되어 모델이 무효화 |
| FFM이 Foundation인 이유? | 수십억 다양한 시계열로 사전 학습 — 처음 보는 데이터에도 즉시 예측 |
| FFM은 이상을 직접 분류하는가? | 모델에 따라 다릅니다. Chronos-2·TimesFM 2.5 같은 forecasting FFM은 간접 탐지. MOMENT·TimeGPT는 직접 탐지도 지원 |
| Covariate-informed 예측이 중요한 이유? | 배포 이벤트·토폴로지 의존성을 입력으로 받아 상황별 False Positive 50~70% 감소 |
| Chronos-2의 핵심 혁신? | Group Attention — 단변량에서 다변량+공변량으로 확장 |
| TimesFM 2.5의 핵심 개선? | 16K 컨텍스트 + XReg — 11일 히스토리 활용, 4가지 공변량 유형 지원 |
| CrossAD (NeurIPS 2025)가 해결하는 문제? | 고정 윈도우 + 단일 스케일 한계 — Cross-scale reconstruction과 Cross-window modeling으로 다해상도 이상 패턴 탐지 |
| 전통 방법을 버려야 하나? | 아닙니다. 하이브리드 접근이 최선 — 규칙/통계(빠른 탐지) + FFM(정확한 탐지) |
종합 흐름
18. 기타 (같이 알면 좋은 개념)
19. 토론 — 동적 Baselining & 예측 구간 이상 임계
2주차 본문을 바탕으로 두 가지 토론 질문에 답을 정리합니다.
19.1 두 질문이 묻는 것
Q1. CPU 동적 baselining, 어느 서비스부터 적용할 것인가
- 의도: "모든 지표에 AI를 적용할 수는 없다"는 현실을 이해하고 있는가.
- 핵심: 모든 마이크로서비스에 동적 baselining을 걸면 Alert Fatigue 가 발생합니다. 비즈니스 중요도가 높고 정적 임계치로 오탐이 잦은 웹 서비스 레이어·트래픽 유입 구간부터 우선 적용할 기준을 세울 수 있어야 합니다.
Q2. 예측 구간(PI) 이탈을 이상으로 정의할 때 임계를 어떻게 정할 것인가
- 의도: 예측값 자체보다 신뢰 구간(Confidence Interval) 을 어떻게 관리할 것인가.
- 핵심:
- 통계적 접근 — 3σ 원칙 vs 분위수(Quantile) 기반.
- 실무적 접근 — 서비스 성격별 민감도 조절(결제는 좁은 구간, 로그 수집은 넓은 구간).
- 지속성 — 단발성 이탈은 무시, N회 연속 이탈 시에만 이상으로 처리.
19.2 Q1 답 — CPU 동적 Baselining 우선순위
결론: CPU 원시값(raw %)이 아니라, CPU 포화가 사용자·비즈니스에 드러나는 지표부터 시작합니다.
파일럿 메트릭 선정 체크리스트
| 조건 | 설명 |
|---|---|
| 시즌성이 명확한가 | 평일/주말, 주간/야간 패턴이 있어야 baseline이 학습할 대상이 생깁니다 |
| 트래픽과 상관이 강한가 | Request Rate를 Covariate로 붙여 FP를 추가로 감소시킬 수 있어야 합니다 |
| 표본 수가 충분한가 | 저트래픽 엔드포인트는 분위수가 불안정해 PI 폭이 과도하게 넓어집니다 |
| 알림 오너가 명확한가 | 고칠 사람이 없는 알람은 Alert Fatigue만 가중시킵니다 |
| 서비스 단위로 수집 가능한가 | K8s 환경에서 Host 평균은 리밸런싱으로 baseline이 요동칩니다 |
환경별 상위 5 메트릭
| 순위 | 모바일 (APM/RUM) | 서버 (인프라/앱) | 일반 서비스 (Golden Signals) |
|---|---|---|---|
| 1 | 앱 시작 시간 (TTID/TTFD) | Pod CPU + Throttling % | Request Rate (Traffic) |
| 2 | User Action Duration (로그인·결제) | API Gateway·핵심 서비스 CPU | Latency P95/P99 |
| 3 | Frozen Frames / UI Jank | DB·Cache CPU Saturation | Error Rate / SLO Burn |
| 4 | ANR / App Hang / Crash Rate | Runtime CPU (JVM/Node + GC) | Service CPU Saturation |
| 5 | 앱 버전·OS별 Hot View | Worker / Consumer CPU | Dependency Saturation (Pool/Queue) |
왜 이 순서인가
모바일에서 raw CPU %는 우선 지표가 아닙니다. UX 증상이 먼저 신호를 줍니다(TTID/TTFD·Frozen Frames는 Datadog RUM·Android Jetpack에서 표준, Dynatrace는 명칭·지원 범위가 일부 다름). 서버에서 Host 평균 CPU는 K8s 리밸런싱에 흔들려 후순위입니다. 일반 서비스는 Traffic을 가장 먼저 baseline해야 CPU 해석에 맥락이 생깁니다.
19.3 Q2 답 — 예측 구간 이탈 임계 설계
결론: 단일 임계치는 반드시 실패합니다. 5가지 조건을 동시에 통과할 때에만 알람을 발생시키는 다층 게이트를 권장합니다.
PI 이상 탐지 도입 체크리스트
| 조건 | 설명 |
|---|---|
| 시즌성이 명확한가 | 시즌성 없는 메트릭은 FFM의 장점이 드러나지 않습니다 |
| 기존 정적 임계의 오탐이 기록되어 있는가 | Ground Truth가 있어야 A/B 비교로 ROI 증명이 가능합니다 |
| 배포 주기가 너무 짧지 않은가 | 하루 수 차례 배포되는 서비스는 Concept Drift 발생이 잦아 baseline 수렴 난이도가 급증하고 재학습 부하가 큽니다 (배포 태그를 Covariate로 넣어 완화 가능) |
| SLO 직결 메트릭이 아닌가 | SLI에서 오탐 1회에 신뢰가 깨집니다. 내부 리소스 메트릭(CPU, Memory)부터 시작 |
5단 게이트
| 게이트 | 쉬운 말 | Warning | Major | Critical |
|---|---|---|---|---|
| ① Quantile | 얼마나 드문 값? | P90/P10 | P95/P5 | P99/P1 |
| ② Magnitude | 예상 범위를 넘은 정도 | |z| > 2 | |z| > 2.5 | |z| > 3 |
| ③ Duration | 얼마나 오래? | 5분 또는 3/5 포인트 | 10분 | 15분 |
| ④ Calibration | 모델 신뢰도 | 목표 Coverage ± 2%p 유지 | 동일 | 목표 대비 5%p 이상 하락 시 재보정 |
| ⑤ Business | 중요도 | 일반 | SLO Burn 동반 | P1 서비스 + Error 동반 |
서비스 성격별 민감도 (이중 기준)
| 서비스 성격 | 프리셋 | 이유 |
|---|---|---|
| 결제·로그인·인증 | P90 + 2~3분 | FN(미탐) 방지 우선 |
| 일반 API | P95 + 5분 | 기본값 |
| 로그 수집기·배치 | P99 + 15분 | FP(오탐) 억제 우선 |
19.4 핵심 정리
| 질문 | 답 |
|---|---|
| CPU 메트릭부터 baseline하면 되는가? | 아닙니다. CPU 포화의 증상(Frozen Frames, Throttling, Latency)이 먼저 신호를 줍니다 |
| 모든 서비스에 동적 baselining을 걸어도 되는가? | 아닙니다. 5가지 조건을 만족하는 1~2개 서비스부터 단계적으로 적용합니다 |
| 3σ vs Quantile, 어느 쪽을 쓸 것인가? | 둘 다 사용합니다. 후보군은 Quantile(P95/P99) 이탈로 걸러내고, Magnitude는 z-score(|z| > 2/2.5/3)로 강도를 판정합니다 |
| 민감도는 어떻게 조절하는가? | 결제는 P90+2~3분, 일반은 P95+5분, 로그 수집은 P99+15분 이중 기준 |
| 단발성 이탈은 어떻게 필터링하는가? | Duration 게이트로 해결. 3/5 포인트 또는 5분 이상 지속 시에만 알람 |
| Concept Drift는 어떻게 대응하는가? | Rolling Conformal Coverage가 빠지면 알람 억제 + 재보정 우선 |
공통 교훈
- 어디에 적용할지를 먼저 정합니다. 모든 메트릭에 한 번에 도입하지 않습니다.
- 조건을 쌓아 알람을 설계합니다. 단일 임계·단일 기준은 반드시 실패합니다.
- 비즈니스 중요도에 따라 민감도를 다르게 둡니다. 하나의 정책으로 모든 서비스를 덮으려 하지 않습니다.
20. 참고 자료
논문 — Forecasting Foundation Model
| 제목 | 저자/기관 | 발표 | 링크 |
|---|---|---|---|
| Chronos-2: From Univariate to Universal Forecasting | Ansari et al. (Amazon) | 2025 | arXiv:2510.15821 |
| Chronos: Learning the Language of Time Series | Ansari et al. (Amazon) | TMLR 2024 | arXiv:2403.07815 |
| A decoder-only foundation model for time-series forecasting (TimesFM) | Das et al. (Google) | ICML 2024 | arXiv:2310.10688 |
| Unified Training of Universal Time Series Forecasting Transformers (Moirai) | Woo et al. (Salesforce) | ICML 2024 | arXiv:2402.02592 |
| Lag-Llama: Towards Foundation Models for Probabilistic Time Series Forecasting | Rasul et al. | 2023 | arXiv:2310.08278 |
| MOMENT: A Family of Open Time-series Foundation Models | Goswami et al. | ICML 2024 | arXiv:2402.03885 |
논문 — TSAD (시계열 이상 탐지)
| 제목 | 발표 | 링크 |
|---|---|---|
| CrossAD: Time Series Anomaly Detection with Cross-scale Associations and Cross-window Modeling | NeurIPS 2025 | arXiv:2510.12489 |
| TSB-AD: The Elephant in the Room (40개 알고리즘 벤치마크) | NeurIPS 2024 | NeurIPS Proceedings |
| TSB-UAD: End-to-End Benchmark for Univariate TSAD | VLDB 2022 | ACM DL |
| Anomaly Transformer: Time Series Anomaly Detection with Association Discrepancy | ICLR 2022 | arXiv:2110.02642 |
| Towards a Rigorous Evaluation of Time-Series Anomaly Detection | AAAI 2022 | arXiv:2109.05257 |
| Deep Learning for Time Series Anomaly Detection: A Survey | ACM CSUR 2023 | arXiv:2211.05244 |
| Time Series Foundational Models: Their Role in Anomaly Detection | 2024 | arXiv:2412.19286 |
논문 — 서베이 & Concept Drift
| 제목 | 발표 | 링크 |
|---|---|---|
| A Survey on Time Series Foundation Models | 2024 | arXiv:2405.02358 |
| Large Language Models for Time Series: A Survey | 2024 | arXiv:2402.01801 |
| Concept Drift Survey | Frontiers in AI 2024 | Frontiers |
| AIOps: Real-World Challenges and Research Innovations | ICSE 2019 | IEEE Xplore |
GitHub 레포지토리
| 레포지토리 | 설명 |
|---|---|
| amazon-science/chronos-forecasting | Chronos / Chronos-2 공식 |
| google-research/timesfm | TimesFM 공식 |
| SalesforceAIResearch/uni2ts | Moirai 공식 |
| time-series-foundation-models/lag-llama | Lag-Llama 공식 |
| decisionintelligence/CrossAD | CrossAD 공식 |
| TheDatumOrg/TSB-UAD | TSB-UAD 벤치마크 |
| TheDatumOrg/TSB-AD | TSB-AD 벤치마크 |
| TimeEval/TimeEval | TimeEval 평가 프레임워크 |
| thuml/Time-Series-Library | 포괄적 시계열 모델 라이브러리 |
| yzhao062/pyod | Python 이상 탐지 라이브러리 |
| salesforce/Merlion | Salesforce 시계열 ML 프레임워크 |
| unit8co/darts | 통합 시계열 예측 라이브러리 |
| mala-lab/Awesome-Anomaly-Detection-Foundation-Models | 이상 탐지 FM 논문 모음 |
공식 문서 — 상용 플랫폼
| 서비스 | 링크 |
|---|---|
| Datadog Anomaly Detection | docs.datadoghq.com/monitors/types/anomaly |
| Dynatrace Davis AI | docs.dynatrace.com/docs/discover-dynatrace/platform/davis-ai |
| AWS CloudWatch Anomaly Detection | docs.aws.amazon.com/AmazonCloudWatch |
| PagerDuty Alerts & Deduplication | support.pagerduty.com/main/docs/alerts |
| PagerDuty Time-Based Alert Grouping | support.pagerduty.com/main/docs/time-based-alert-grouping |
| BigPanda Alert Noise Reduction | bigpanda.io/blog/alert-noise-reduction-strategies |
| BigPanda Event Correlation | bigpanda.io/blog/event-correlation |
기술 블로그
| 제목 | 출처 | 링크 |
|---|---|---|
| Introducing Chronos-2 | Amazon Science | amazon.science/blog |
| TimesFM Foundation Model for Forecasting | Google Research | research.google/blog |
| TimesFM-2.5 External Covariates Tutorial | AI Horizon Forecast | aihorizonforecast.substack.com |
| Anomaly Detection with TimeGPT | Nixtla | nixtla.io/blog |
| AIOps: What We Learned in 2025 | Thoughtworks | thoughtworks.com |
