1. 들어가며 — Alert Noise는 양적 문제가 아닌 구조적 문제다
오늘날의 마이크로서비스는 결코 외로운 섬이 아닙니다. 넷플릭스가 사내에서 “Death Star” 라고 부르던 의존성 다이어그램처럼, 수백 개의 서비스가 거미줄로 엮인 환경에서는 한 개의 DB 장애가 한 개의 알람으로 끝나지 않습니다. 바로 이 구조가 Alert Noise의 근원입니다.
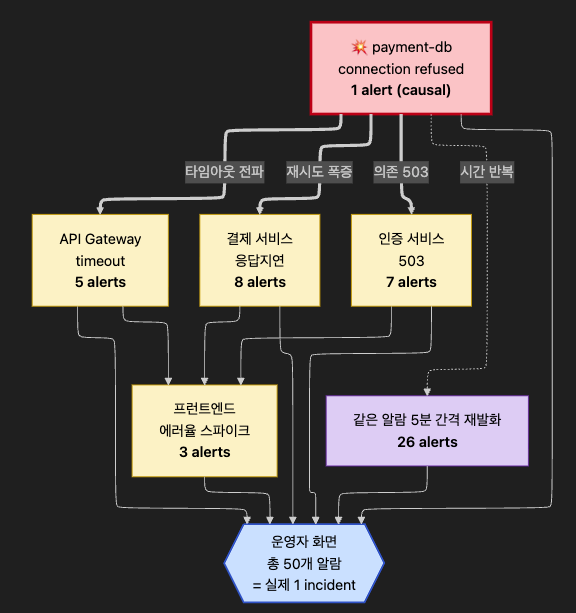
새벽 3시, 데이터베이스 하나가 멈췄다고 합시다.
운영자의 화면에는 50개의 알람이 뜹니다.
DB 자체의 connection refused 알람이 1개, 그 뒤로 API Gateway 타임아웃 5개, 결제 서비스 응답지연 8개, 인증 서비스 503 7개, 프런트엔드 에러율 스파이크 3개, 그리고 같은 메시지가 5분 간격으로 재발화된 사본들 — 모두 합쳐 50개입니다.
실제로는 1개의 인시던트입니다.
흔한 처방은 “규칙을 덜 까다롭게 만들자”입니다. 하지만 임계치를 올리면 야간 알람은 줄어도 주간 실제 장애까지 놓칩니다.
이 처방이 안 되는 이유는 원인 진단이 틀렸기 때문입니다. Alert Noise는 알람 개수의 문제가 아니라 의존 구조의 문제입니다.
분산 시스템은 본질적으로 한 개의 실패가 여러 계층으로 번집니다. 한 번의 failure가 downstream 서비스들에 타임아웃·재시도·회로차단기 발동을 유발하고, 각 계층마다 서로 다른 이름의 알람을 만듭니다. 운영자가 보는 “수백 개의 노이즈”는 대부분 하나의 원인이 만든 수많은 증상 알람입니다.
해결 방향은 간단합니다. 줄이지 말고 묶으세요. 알람의 숫자가 아니라 알람들 사이의 관계를 볼 줄 알아야 합니다. Correlation이 정확히 그 일을 합니다.
Google SRE Book은 이렇게 말합니다:
"Potential-cause alerts have poor correlation to real problems, but symptom-of-user-pain alerts better allow you to understand user impacts."
(Honeycomb, Observability Engineering Ch 12 재인용)
이 구분이 9절에서 다룰 SLO 기반 alerting의 출발점입니다.
2. Correlation이란 — 줄이는 게 아니라 묶는 것이다
3주차 파이프라인을 복기하면 이렇습니다.

위 파이프라인에서 4주차의 자리는 Correlation과 Grouping (노란 박스) 두 단계입니다.
Dedup / Correlation / Suppression은 자주 혼용됩니다. 다음 표로 경계를 구분합니다.
| 단계 | 입력 | 처리 | 출력 | 대표 실패 모드 |
|---|---|---|---|---|
| Deduplication | 동일 이벤트 반복 | 핵심 필드 해시 / 내용 유사도 | 1건으로 압축 | 가변 필드 포함 시 중복 인식 실패 |
| Correlation | 서로 다른 증상 이벤트 | 시간·토폴로지·의미 축으로 묶기 | 인시던트 1건 | Stale topology로 인한 오상관 |
| Suppression | 예정·알려진 상황 이벤트 | 룰 기반 억제 | 알림 차단(단, 로그 보관) | 실제 장애 억제 위험 |
통계 용어로서 correlation은 “둘 이상의 엔터티 사이의 관계·연관성을 식별하는 것”이고, AIOps 맥락에서는 그 관계를 근거로 이벤트를 묶어 운영자가 인시던트 단위로 인지할 수 있게 만듭니다.
다만 이벤트 계층의 correlation은 쉽지 않습니다. 타임스탬프가 들쭉날쭉하고, 출처마다 포맷이 다르며, 순차 패턴이 잘 드러나지 않기 때문입니다. 그래서 이벤트 계층에서는 DBSCAN 같은 밀도 기반 클러스터링이 자주 쓰입니다 — dense cluster + noise를 함께 다루기에 유리합니다.
3. Alert Noise·Alert Storm의 해부
Alert Noise의 3가지 메커니즘을 구분해야 각각에 맞는 도구가 보입니다.
| 메커니즘 | 예시 | 기본 대응 |
|---|---|---|
| 중복 재발화 (Re-fire / flapping) | DB 다운 후 5분마다 같은 알람 반복 | Deduplication (3주차) |
| 파생 증상 (Symptom spread) | DB 다운 → API 응답지연 → 프런트엔드 5xx | Correlation (4주차) |
| 캐스케이드 (Cascading failure) | 원본 장애 + Circuit Breaker 개방 + Retry Storm | Correlation + Topology (4주차) |
Google SRE 용어로는 앞서 언급한 symptom alert vs causal alert의 구분입니다. 예를 들어:
[13:00:01] causal: DB connection pool exhausted (payment-db)
[13:00:03] symptom: API gateway 504 for /payment/*
[13:00:05] symptom: Auth service 503 (depends on payment)
[13:00:07] symptom: Frontend error rate 8.2% (threshold 1%)
[13:00:09] symptom: Synthetic monitor timeout on /checkout
[13:05:01] re-fire: DB connection pool exhausted (payment-db) ← 같은 원인 재발화
[13:05:03] re-fire: API gateway 504 for /payment/*
...원본은 1건, 관측되는 알람은 수십 건입니다.
3.1 왜 정적 임계치로는 막을 수 없나
Honeycomb의 Observability Engineering(Ch 12)은 분산 시스템이 조합적 폭발(combinatorial explosion) 을 만든다고 지적합니다.
“As systems become more complex, they create a combinatorial explosion of potential failure modes. Ops teams … will rely on their intuition, best guesses, and memories of past outages … That approach isn’t sustainable. The checks aren’t maintainable, often the knowledge isn’t transferable, and past historical behavior doesn’t necessarily predict failures likely to occur in the future.”
수십 개 서비스 × 수십 개 메트릭 × 수십 개 replica가 곱해지면 모든 failure mode를 예측해 rule을 심는 것은 사실상 불가능합니다. 그래서 9절에서 다룰 SLO 기반 alerting이 근본 해결책으로 등장합니다.
3.2 정량 지표
팀마다 다르지만 실무에서 자주 쓰는 지표 3개입니다.
| 지표 | 의미 | 경고 수준 |
|---|---|---|
| Alert-per-incident 비율 | 인시던트 1건당 평균 알람 수 | 10 이상이면 correlation 필요 |
| Alert rate spike index | 평시 대비 알람 발생률 배수 | 5배 이상이면 storm 의심 |
| Noise reduction % | correlation 전/후 알람 수 비교 | 70~90% 권장 (BigPanda 벤더 주장 기준) |
“Understanding and Handling Alert Storm for Online Service Systems” (Zhao et al., ICSE-SEIP 2020)은 alert storm의 entropy 기반 탐지와 완화 프레임워크를 학술적으로 제시한 고전입니다.
4. Event Correlation 3축 비교 — Temporal / Label-based / Topological
2주차에서 Event Correlation의 세 가지 유형(Temporal / Topological / Semantic)이 있다고 소개했습니다. 여기서는 4주차의 정의(Temporal / Label / Topology + 보조 Semantic)에 맞춰 각 축의 알고리즘·입력 데이터·실패 모드를 파헤칩니다.
세 축(+ 보조 Semantic)은 경쟁이 아니라 보완이며, 실무는 거의 항상 앙상블입니다.
| 축 | 신호 | 대표 알고리즘 | 적합한 상황 | 실패 모드 |
|---|---|---|---|---|
| Temporal | 발생 시각 | Fixed/Sliding/Session window | 즉각적 동시 장애 | 느린 cause-effect 체인(30분 이상 lag) |
| Label-based | label/attribute 매칭 | exact match, namespace 매핑 | 같은 서비스·클러스터 내 다중 알람 | label namespace 불일치로 cross-team incident 누락 |
| Topological | 의존성 그래프 | DAG traversal (BFS/PageRank 변형) | 대부분의 인프라 장애 | Stale topology (7절) |
| Semantic (보조) | 이벤트 텍스트 | TF-IDF → BERT → LLM | 미계측 서비스, 텍스트 기반 로그 | 유사성 ≠ 인과성 |
4.1 Temporal 심화
Prometheus AlertManager의 세 매개변수를 올바로 이해하는 것이 시작입니다.
route:
receiver: sre-team
group_by: ['alertname', 'cluster', 'service']
group_wait: 30s # 같은 그룹의 첫 알람 도착 후, 추가 합류 대기 시간
group_interval: 5m # 기존 그룹에 새 알람이 추가됐을 때 재송신 간격
repeat_interval: 4h # 그룹 내용이 바뀌지 않아도 재통지하는 간격자주 하는 실수: group_by에 instance나 pod를 넣으면 동일 서비스의 여러 replica가 각각 별도 그룹으로 쪼개져 grouping이 실패합니다. instance는 빼고 cluster·service 수준에서 묶으세요.
Temporal은 “같은 5분 창”이라는 단순한 가정 위에 돕기 때문에 느린 원인-결과 체인에 약합니다. 메모리 누수가 11:00에 시작해서 11:30에 알람을 발동하고 12:00에 OOM Kill이 일어나는 시나리오에서는 5분 창으로 두 알람이 분리됩니다.
실무 팁 한 가지. Topology가 아직 없을 때 Temporal 창만으로 인시던트를 묶어야 한다면 15분 또는 30분을 시작점으로 잡는 편이 안전합니다. 대부분의 마이크로서비스 재시도·타임아웃·Circuit Breaker 복구 주기가 이 구간에 수렴합니다. 너무 짧으면 캐스케이딩 장애를 놓치고, 너무 길면 별개 장애가 합쳐져 버립니다.
4.2 Label-based Correlation 심화
Label 기반 correlation은 같은 대상(서비스·클러스터·팀)에서 나온 알람을 묶는 데 강합니다. Prometheus group_by: ['alertname', 'cluster', 'service']처럼 속성값이 일치하는 알람을 묶는 방식이 대표적입니다.
그러나 분산 시스템의 incident는 종종 label 경계를 벗어납니다.
[13:00:01] checkout-api 5xx rate spike (label: {service:checkout, team:order})
[13:00:03] payment-db connection reset (label: {service:payment-db, team:payment})
[13:00:05] istio-ingressgateway upstream timeout (label: {component:istio, ns:istio-system})
[13:00:07] synthetic-monitor /checkout probe timeout (label: {probe:checkout, env:prod})네 알람은 같은 incident일 수 있지만 label namespace가 제각각입니다. 시간창과 label 매칭은 같은 서비스 이름이 붙은 알람끼리는 잘 묶지만, 원인 서비스(payment-db)와 영향 서비스(checkout, ingress, synthetic)가 다른 label 집합에 있을 때는 놓치기 쉽습니다.
핵심 한계: 시간창·label만으로는 label namespace가 다른 알람을 하나의 incident로 묶기 어렵습니다. upstream causal alert와 downstream impacted alert의 구분은 topology 없이 불가능합니다(→ 4.3절).
4.3 Topological 심화
5·6·7절에서 본격적으로 다룹니다. 여기서는 포지셔닝만 짚겠습니다. Topological correlation은 causal vs impacted 분리에 가장 직접적인 신호를 제공하는 축입니다. 다만 “가장 강력하다”는 단정보다는, topology가 신선하고 커버리지가 충분할 때 causal candidate ranking에 가장 효과적이라는 표현이 정확합니다. Topology가 stale하거나 coverage가 낮으면 오히려 오상관 위험이 커집니다(→ 상세 알고리즘은 5.6절).
4.4 Semantic 심화
3주차에서 TF-IDF / 임베딩 / LLM 비교표를 봤습니다. 4주차에서 강조할 점은 하나입니다.
Semantic similarity ≠ Causality
두 알람의 메시지가 유사하다고 해서 인과관계가 있는 것은 아닙니다. “Authentication service 503” 두 건이 같은 인시던트일 수도 있지만, 서로 다른 테넌트의 독립 장애일 수도 있습니다. Semantic은 topology가 비어 있거나 미계측 서비스에서 보조 신호로 사용해야 하지, 단독 판정 근거로 삼으면 위험합니다.
4.5 분산 트레이싱은 “4번째 축”이 아니라 Topology의 입력
요즘 일부 자료는 trace-based correlation을 네 번째 축으로 제시합니다. 여기서는 3축 프레임을 유지하고, 트레이싱은 Topology의 실시간 입력 소스로 봅니다(6절 OpenTelemetry Service Graph Connector에서 다시 다룹니다).
5. Topology-aware Correlation 심화 — Network vs Application Topology
토폴로지는 한 덩어리가 아닙니다. 실무에서는 토폴로지를 Network Topology와 Application Topology 두 레이어로 분리해서 설계하는 것이 일반적입니다. 두 레이어는 신호가 다르고, 저장 방식도 다르고, 알고리즘도 다릅니다.
한 가지만 짚고 넘어가겠습니다. topology-aware correlation은 root cause를 증명하는 엔진이 아닙니다. causal candidate를 ranking하고 impacted alert을 분리하는 엔진입니다. 대규모 분산 시스템에서 사실상 필수에 가깝다는 표현은 가능해도, 단독으로 모든 인시던트를 해결한다는 식의 단정은 피하는 게 좋습니다.
5.1 용어 정리
용어가 엉켜서 혼란이 큰 영역이니 한 번 깔끔히 정리합니다.
| 용어 | 의미 | 출처 |
|---|---|---|
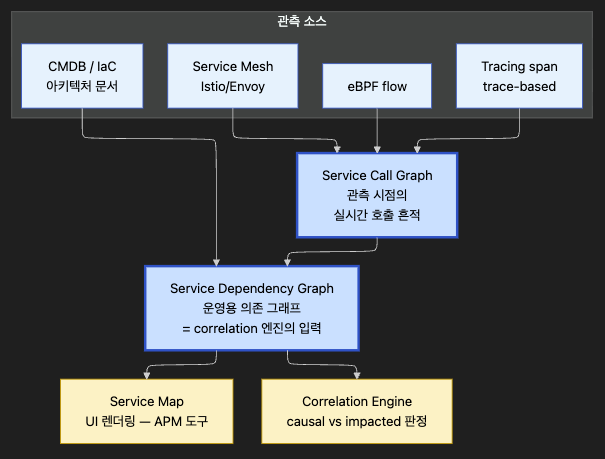
| Service Call Graph | 관측 시점의 실제 호출 흔적 | 분산 트레이싱 / eBPF(Linux 커널 관측 기술) |
| Service Dependency Graph (SDG) | 상관분석 엔진이 참조하는 운영용 의존 그래프 | CMDB / 아키텍처 문서 |
| Service Map | UI 용어. 위 둘 중 하나를 렌더링 | 거의 모든 APM 도구 |
| Network Topology | 물리/가상 네트워크 연결도 (스위치·라우터·LB) | 네트워크 discovery(SNMP/ICMP) |
| Application Topology | 앱 컴포넌트 간 의존도 (availability + performance) | CMDB + AIOps 학습 |
Call graph는 SDG의 실시간 보강재이지 SDG 전체와 동의어가 아닙니다. 그래서 trace-based correlation을 “4번째 축”이 아니라 topology의 입력으로 보는 게 맞습니다.
5.2 Network Topology Correlation
신호: 네트워크 연결도. 알고리즘: 상위 CI(스위치·라우터·방화벽·LB)의 장애가 발생했을 때, 그 하위에 연결된 모든 CI의 알람을 impacted로 분류하고 상위 알람만 causal로 승격합니다.
{"network_topology": [
{"child-ci": "payment-app-1", "parent-ci": "ntwrk-switch-1"},
{"child-ci": "payment-app-2", "parent-ci": "ntwrk-switch-1"},
{"child-ci": "payment-db-1", "parent-ci": "ntwrk-switch-1"},
{"child-ci": "ntwrk-lb-1", "parent-ci": "ntwrk-switch-1"}
]}네트워크 모니터링 실무의 공통 조언은 명료합니다.
이 correlation은 event management 계층이 아니라 network monitoring 계층에서 처리하는 편이 정확합니다.
ICMP/SNMP로 실시간 가용성을 감시하는 도구가 토폴로지를 함께 갖고 있으면 정확도가 가장 높습니다. 거기서 impacted 알람은 정보 심각도로, causal 알람은 Critical로 라벨링해 상위 event bus로 흘려 보내는 패턴이 권장됩니다.
토폴로지 스냅샷 갱신 주기는 dynamic한 환경이 아니면 24시간 또는 weekly면 충분하다고 지적합니다. Cloud·SDI 환경은 API로 실시간 갱신하세요.
5.3 Application Topology Correlation
Application topology는 availability + performance를 모두 봐야 합니다. Network topology처럼 “스위치 다운 → 하위 전부 영향”으로 끝나지 않습니다.
시나리오: payment-db 프로세스(not DB 서버) 다운
├─ DB-level alert: 'payment-db process down'
├─ App-level alert: 'payment-app queue depth > 1000'
├─ URL-level alert: 'payment-service response time > 3s'
└─ Synthetic alert: 'checkout synthetic probe timeout'네 개의 알람은 서로 다른 계층에서 발생했지만 같은 원인입니다. Application topology가 있어야 이걸 묶습니다.
다만 CMDB로 Application topology를 정확하게 유지하는 일은 어렵습니다. 현장에서 자주 마주치는 장애물은 크게 세 가지입니다.
- 도메인 지식 부재 — Discovery 도구 전문가가 수십~수백 개 애플리케이션의 내부 구조를 다 알 수 없음
- 정보 federation — 네트워크팀·DB팀·앱팀·SAP팀 등 여러 팀의 도구에 정보가 흩어져 있음
- 보안 승인 장벽 — 애플리케이션 로그에 PII/PHI가 섞여 있어 보안·법무 승인이 막힘
5.4 CMDB가 불완전할 때 — AIOps 4가지 학습 신호
CMDB(Configuration Management Database, 구성 관리 DB)를 완벽히 유지하는 대신, AIOps 엔진이 런타임 데이터에서 의존성을 학습하는 네 가지 신호가 있습니다.
- Hostname / IP 유사성
- 같은 애플리케이션의 서버는 공통 prefix(
payment-app-1,payment-app-2)나 같은 subnet을 쓰는 경향
- 같은 애플리케이션의 서버는 공통 prefix(
- 이벤트 도착 시간 패턴
- 함께 자주 터지는 알람 쌍은 기록에서 반복됨
- 메시지 텍스트 분류
- “timeout”, “refused”, “OOM” 등의 키워드와 서비스명을 묶어 availability vs performance 카테고리 자동 배정
- Event class + source (OMDBs)
- vCenter(가상화) / SAP(앱) / SCCM(엔드포인트) 등 operational management DB의 데이터를 이용해 VM ↔︎ ESX ↔︎ Cluster, 앱 ↔︎ 서비스 매핑을 역추적
이 네 신호를 조합하면 CMDB가 50%만 채워져 있어도 correlation의 실무 임계치를 넘길 수 있습니다.
5.5 JSON 기반 Application Topology 예시
{"application_topology": [
{"child-ci": "payment-app-1", "parent-ci": "payment-db-1",
"application": "payment", "kpi": {"type": "service", "name": "payment_service"}},
{"child-ci": "payment-app-2", "parent-ci": "payment-db-2",
"application": "payment", "kpi": {"type": "service", "name": "payment_service"}},
{"child-ci": "checkout-web-1", "parent-ci": "ntwrk-lb-1",
"application": "payment", "kpi": {"type": "url", "name": "checkout.example.com"}}
]}Cloud/SDI 환경이 아니면 월간 또는 분기간 갱신으로 충분합니다.
K8s 네이티브 표현 — 라벨·애노테이션 패턴
쿠버네티스 환경에서는 SDG를 JSON 외부 저장 없이 오브젝트 라벨·애노테이션으로 직접 표현할 수 있습니다. 이 방식의 장점은 서비스 매니페스트가 곧 SDG의 1차 소스가 된다는 점입니다.
apiVersion: v1
kind: Service
metadata:
name: payment-app
labels:
app.kubernetes.io/part-of: payment-stack
annotations:
sdg.io/depends-on: "payment-db,cache-redis"
sdg.io/impact-radius: "checkout-web,order-api"OTel Collector나 사내 operator가 라벨·애노테이션을 읽어 동적으로 SDG를 합성하면, CMDB drift 위험이 줄어듭니다.
5.6 Causal vs Impacted 판정 알고리즘 개요
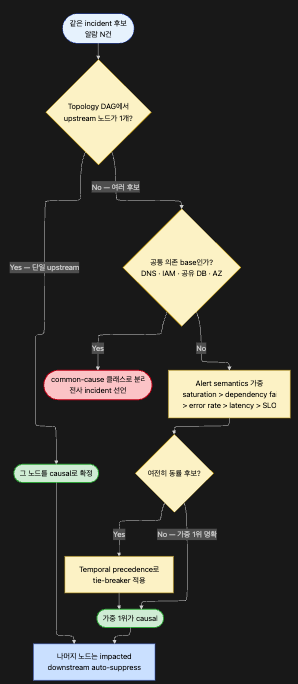
판정 기준은 3단계로 해야 한다고 생각합니다.
시간만 보면 늦게 감지된 원인을 놓칠 수 있고, topology만 보면 stale edge에 취약하기 때문입니다.
| 단계 | 기준 | 역할 |
|---|---|---|
| 1차 | Topology 방향 (upstream vs downstream) | causal candidate ranking |
| 2차 | Alert semantics (saturation > dependency failure > error rate > latency > SLO burn) | candidate 가중치 |
| 3차 | Temporal precedence (발생 시각 순서) | tie-breaker, confidence 보정 |
즉 Topology > Alert semantics > Temporal 순서로 두는 것이 안전합니다 (§15.2 Q2의 7단 운영 파이프라인과 동일). 시간 신호를 tie-breaker로 두는 이유는 detection latency 차이 때문에 “먼저 관측된 것이 먼저 발생한 것”이 아닐 수 있기 때문입니다(상세 근거 §15.2). 이 엔진의 출력은 증명된 원인이 아니라 순위 매겨진 후보입니다(→ 한계·언어 가드레일은 §14.6 참조).
def identify_causal_and_impacted(alerts, sdg):
"""토폴로지 DAG에서 causal CI를 찾고 나머지는 impacted로 표기"""
# 1. 알람이 걸려 있는 CI들을 DAG 상에서 위치 확인
alerted_nodes = {a.ci for a in alerts}
# 2. 모든 alerted_nodes의 공통 조상(LCA) 또는
# 그들 중 다른 alerted_nodes의 upstream인 노드를 causal 후보로
causal_candidates = []
for n in alerted_nodes:
if all(is_ancestor_or_self(n, m, sdg) for m in alerted_nodes):
causal_candidates.append(n)
# 3. severity 가중치로 최종 causal 선택
causal = max(causal_candidates, key=lambda n: severity_weight(n, alerts))
impacted = alerted_nodes - {causal}
return causal, impacted실제 IBM Netcool 내부 구현은 이 로직에 PageRank 변형·시간 순서 가중을 더한 형태라고 알려져 있습니다.
5.7 Causal / Impacted / Common-cause — 3-class 판정
실무에서는 causal과 impacted 이분법으로 풀리지 않는 케이스가 자주 나옵니다. 그래서 3-class + causal score 로 판정하는 편이 안전합니다.
| 클래스 | 정의 | 대표 패턴 |
|---|---|---|
| causal | 의존성 방향 상 자기보다 상위에 알람이 없는 노드 | DB 다운 → 그 위 모든 서비스 |
| impacted | causal로부터 reachable한 downstream 알람 | 위 시나리오의 API/FE/synthetic |
| common-cause | 여러 incident가 공유하는 기반 인프라 장애. topology 상 “모두가 다 의존”이라 후보가 폭증 | DNS / IAM / 공유 DB / AZ outage / control-plane |
왜 별도 클래스인가 — common-cause는 “자기보다 상위에 알람 없는 노드”라는 정의가 의미가 없을 만큼 의존성 폭이 넓습니다. causal candidate ranking으로 잡으려 하면 후보가 폭증해 운영자에게 “모두가 원인입니다”라는 무익한 답이 돌아갑니다. 별도 클래스로 분리해야 “이건 공통 모드 장애”라는 이름이 붙고, 그에 맞는 대응(전사 incident 선언, 의존자 일괄 통보)을 트리거할 수 있습니다.
Topology만으로 풀리지 않는 3가지 예외
- 공통 모드 장애 — 위 표의 common-cause 클래스로 분리.
- Stale / incomplete topology — 신규 서비스나 새 엣지가 반영되기 전에는 그래프 신뢰도가 낮으므로 temporal 비중을 올림(§7).
- 변경 이벤트 — 배포·flag flip·config rollout·schema migration은 topology에 나타나지 않지만, 실무에서 가장 강력한 causal 신호. 별도 신호 채널로 수집해 판정 1차 입력에 합류시키세요.
Dependency type별로 causal 규칙이 달라집니다
“A → B” 엣지 하나로는 부족합니다. 엣지의 종류에 따라 적용 규칙이 달라져야 합니다.
| Dependency type | 특징 | 판정 규칙 |
|---|---|---|
sync RPC | request-response | 기존 topology 프레임 작동 |
async messaging | queue lag, DLQ, poison message | request-response로 풀리지 않음. queue/topic binding을 IaC 매니페스트로 별도 캡처 |
data dependency | DB·cache | shared fate 성격 강함 → common-cause로 기울기 쉬움 |
control-plane | DNS·IAM·service discovery | 한 번 깨지면 전체 동시 영향 → 전형적 common-cause |
infra co-location | 같은 node·AZ | 의존 관계가 아닌데도 동시 실패하는 noisy neighbor 패턴 |
6. SDG 구축 경로 비교 — CMDB / OTel Tracing / Service Mesh / eBPF
SDG의 품질이 correlation 품질의 상한입니다. 어디서 SDG를 얻을지는 correlation 아키텍처 결정의 첫 단추입니다.
6.1 네 가지 소스 비교표
| 소스 | 대표 도구 | 정확도 | 커버리지 | 업데이트 지연 | 운영 부담 | 한계 |
|---|---|---|---|---|---|---|
| CMDB 수작업/반자동 | ServiceNow Discovery, BMC Helix | 높음 (신선할 때) | 엔터프라이즈 전체 | 시간~일 단위 | 높음 | drift·stale |
| 분산 트레이싱 (OTel) | OTel, Jaeger, Tempo | 앱 레이어 정확 | 계측된 서비스만 | 분 단위 | 중간 (계측 비용) | 서버리스 일부·외부 SaaS 누락 |
| Service Mesh | Istio+Envoy, Linkerd, Kiali UI | L4~L7 정확 | 메시 내부만 | 초 단위 | 중간 (sidecar 비용) | 메시 외부 SaaS 불가시 |
| eBPF | Cilium Hubble, Pixie, Odigos, OBI (OTel eBPF Instrumentation) | 커널 레벨 | 노드 전체 (무계측) | 초 단위 | 낮음 (관측), 중간 (운영) | L3/L4 흐름만으로 앱 인과 확정 불가 |
같은 정보를 정확도 × 커버리지 2축으로 보면 각 소스의 위치가 더 직관적으로 보입니다.
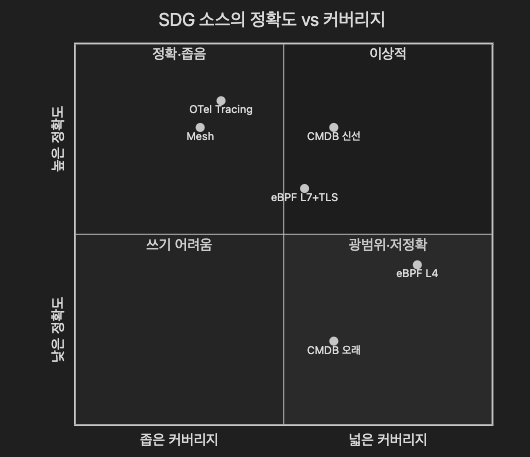
어느 소스도 단독으로 우상단(이상적)에 있지 않다는 점이 핵심입니다. 그래서 §6.4의 4소스 병합 패턴이 필요합니다.
6.2 eBPF 과장에 대한 경고
“eBPF는 zero overhead, 100% 정확한 실시간 의존성 맵”이라는 주장이 자주 있습니다. 반은 맞고 반은 틀립니다.
- 맞는 부분: L3/L4 흐름 관측은 zero-instrumentation에 가깝게 얻을 수 있습니다. 노드에 상주한 eBPF 프로브가 패킷 헤더를 읽기 때문입니다.
- 틀린 부분: L7 파싱과 TLS 풀기는 비용이 있습니다. 그리고 네트워크 흐름이 보인다고 해서 애플리케이션 인과가 확정되는 것은 아닙니다. 같은 TCP 연결 위에서 여러 종류의 비즈니스 호출이 다중화될 수 있기 때문입니다.
Service Mesh(mTLS)와의 혼선 주의
Istio·Linkerd처럼 mTLS로 트래픽이 암호화된 환경에서 eBPF가 L7 수준의 의미 해석을 하려면 사이드카 오버헤드보다 더 큰 CPU 비용이 드는 경우가 있습니다. 암호화된 페이로드를 커널에서 풀어내는 것이 싸지 않기 때문입니다. Mesh 환경에서는 사이드카 메트릭을 1차 소스로 두고 eBPF는 보조로 조합하는 편이 현실적입니다.
eBPF는 좋은 1차 소스이지만 응용 계층 인과는 여전히 OTel span이나 앱 로그의 correlation ID가 필요합니다.
6.3 OpenTelemetry Service Graph Connector
OpenTelemetry Collector Contrib의 servicegraphconnector는 client-server span pair를 매칭해 SDG를 자동 생성합니다. 벤더 중립 표준이 되어 가고 있습니다.
receivers:
otlp:
protocols:
grpc:
endpoint: 0.0.0.0:4317
connectors:
servicegraph:
dimensions:
- cluster
- namespace
store:
ttl: 2s
max_items: 200000
exporters:
prometheus:
endpoint: 0.0.0.0:9090
service:
pipelines:
traces:
receivers:
- otlp
exporters:
- servicegraph
metrics/servicegraph:
receivers:
- servicegraph
exporters:
- prometheus현 상태 (2026-04 확인): Traces → Metrics 변환 파이프라인의 안정성이 alpha로 표기되어 있습니다.
Distributed tracing의 client span과 server span이 같은 Collector 인스턴스에 모여야 SDG edge가 올바르게 생성되기 때문에, Load Balancing Exporter로 Trace ID 기반 일관 해싱을 걸어 주는 것이 사실상 필수입니다.
이 요구사항 때문에 단일 Collector 토폴로지로 시작한 환경에서는 자주 오동작이 발견됩니다. 아직 프로덕션 표준이라고 단정할 단계는 아닙니다.
6.4 통합 패턴
현실에서는 네 소스를 합쳐서 쓰는 편이 가장 안전합니다. 네트워크 토폴로지는 SNMP, 앱 토폴로지는 OTel, 쿠버네티스 내부는 eBPF, 기준선은 CMDB를 병합합니다.
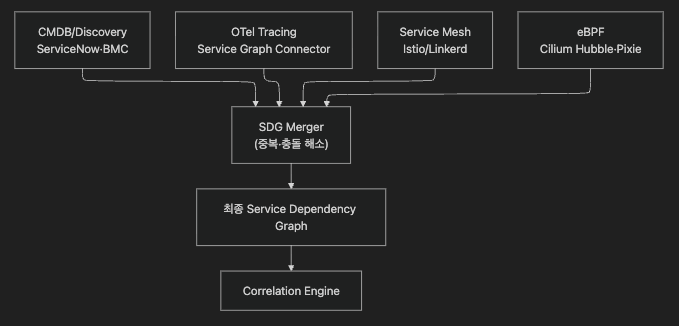
환경별 SDG 1차 출처 선택 가이드 (이미지 텍스트 버전)
| 환경 | 권장 1차 소스 | 비고 |
|---|---|---|
| K8s 네이티브 | OTel Service Graph Connector | 계측 서비스 SDG 자동 생성. Load Balancing Exporter 필수(§6.3) |
| 레거시 온프렘 | CMDB + eBPF (Cilium Hubble) | 무계측 L3/L4 의존성 + CMDB 앱 계층 보완 |
| Service Mesh 환경 | Service Mesh (Istio/Linkerd) | L4~L7 실시간 정밀도, sidecar 비용 감수 |
| 멀티클라우드 이기종 | OTel + CMDB 병합 | 클라우드 간 일관 관측. Mesh 외부는 OTel로 보완 |
| 엔터프라이즈 전체 | 4소스 병합 | CMDB + OTel + Mesh + eBPF. 조직 규모별 3단계 도입은 §13.2 참조 |
6.5 Edge 메타데이터 4차원 — 단일 소스의 체계적 편향에 대응
각 출처는 저마다 다른 방식으로 진실을 놓칩니다. 그래서 SDG의 엣지 하나를 “있다/없다”의 boolean이 아니라 4차원 메타데이터로 저장하는 것이 안전합니다.
| 출처 | 결측·편향 유형 |
|---|---|
| Tracing | sampling 누락, 계측 gap, trace propagation break, 3rd-party hop 누락 → false negative |
| eBPF | 애플리케이션 의미 부족, NAT/sidecar layering, short-lived connection 해석 복잡 → false positive edge |
| Service Mesh | non-mesh·async·DB·queue consumer 누락, L7 방향=의존 방향 동일시 위험 → semantic ambiguity |
| CMDB | 업데이트 지연, shadow dependency 누락, intended ≠ observed |
Edge 4차원 스키마:
{
"from": "checkout-api", "to": "payment-db",
"confidence": 0.92, // 출처 신뢰도 가중 평균
"freshness": "2026-04-25T14:03Z", // 마지막 관측 시각
"evidence_type": "trace_span", // trace_span | mesh_telemetry | ebpf_flow | cmdb_decl
"source_provenance": ["otel-collector-eu", "cilium-hubble"]
}그리고 출처 간 diff 자체를 운영 시그널로 써야 합니다.
- Tracing은 못 봤는데 eBPF에는 있다 → 계측 gap
- eBPF에는 있는데 CMDB에는 없다 → shadow IT
- CMDB에는 있는데 runtime에는 안 보인다 → dead dependency 또는 미사용 코드 경로
이 diff가 관측 가능성 개선의 실마리가 됩니다.
7. Stale Topology 함정과 운영 가드레일
Topology 없음보다 더 위험한 것은 오래된 토폴로지를 맞다고 믿는 것입니다.
엉뚱한 CI가 root cause로 지목되어 엉뚱한 팀이 호출되고, MTTR이 오히려 악화됩니다.
7.1 Stale Topology의 5가지 원천
- 배포 후 미반영 — 3주차 예시 재사용:
service-A → new-db로 3주 전 마이그레이션했는데 CMDB에는old-db가 그대로 - Ephemeral workload — 쿠버네티스 pod churn, auto-scaling으로 매 분 노드가 바뀜
- Sidecar/mesh 미편입 — 새 서비스가 mesh에 합류하기 전에는 observability 사각지대
- Shared dependency — 공유 Redis·멀티테넌트 DB는 한쪽 문제가 다른쪽으로 오탐됨
- External SaaS dependency — 외부 결제·메시지·인증 API는 자체 SDG에 안 보임
7.2 “없음” vs “틀림” 위험 비교
| 상황 | 증상 | 심각도 |
|---|---|---|
| 토폴로지 없음 | Correlation이 Temporal·Semantic으로 fallback | 중간 — 정확도 낮지만 일관된 fallback |
| 토폴로지 틀림 | 엉뚱한 CI가 causal로 지목 | 높음 — MTTR 증가, 운영 신뢰 저하 |
7.3 완화 패턴
- 토폴로지 소스를 이중화 (CMDB + OTel이 불일치하면 경고)
- Drift 감지 알림 — 토폴로지 데이터 자체의 변경률이 임계 이상이면 SRE에게 알림
- 배포 웹훅 — CI/CD에서 서비스 추가/제거 시 토폴로지 store에 쓰기
8. Alert Grouping 전략 — Time-window / Fingerprint / Causal Chain
Correlation이 “묶는 로직”이라면 Grouping은 “묶은 결과를 어떻게 운영자에게 보여 줄지”의 문제입니다(Dedup·Suppression과의 경계는 2절 구분표 참조).
같은 correlation 로직을 쓰더라도 grouping 전략에 따라 체감이 완전히 달라집니다.
8.1 세 전략과 하이브리드
| 전략 | 원리 | 적합 상황 | 대표 제품 |
|---|---|---|---|
| Time-window | 같은 시간 창의 알람을 묶기 | 즉각적 동시 장애 | Prometheus AlertManager, PagerDuty Time-Based |
| Fingerprint | 핵심 필드 해시로 묶기 | 구조화된 이벤트 | PagerDuty dedup_key, BigPanda primary/secondary |
| Causal chain | Topology DAG 따라 parent-child 묶기 | 캐스케이드 장애 | IBM Cloud Pak for AIOps, ServiceNow Event Management |
| Hybrid (ML) | 위 셋 + 학습 | 대규모 운영 | PagerDuty Intelligent Alert Grouping, Dynatrace Davis |
8.2 Fingerprint 설계 원칙 — 절대 포함 금지 필드
Fingerprint를 만들 때 반드시 빼야 할 필드가 있습니다.
NEVER_IN_FINGERPRINT = {
"timestamp", # 매번 변함
"uuid", "event_id",
"pod_hash", # K8s replica마다 다름
"replica_id",
"trace_id", # 매 호출마다 다름
"hostname", # auto-scaling으로 바뀜 (cluster·service 수준으로 대체)
}
def make_fingerprint(event: dict) -> str:
keys = {k: v for k, v in event.items() if k not in NEVER_IN_FINGERPRINT}
# 정규화(소문자·trim) 후 해시
normalized = {k: str(v).strip().lower() for k, v in sorted(keys.items())}
return hashlib.sha256(json.dumps(normalized).encode()).hexdigest()[:16]8.3 Prometheus AlertManager route 트리 예제
route:
receiver: default
group_by:
- alertname
- cluster
group_wait: 30s
group_interval: 5m
repeat_interval: 4h
routes:
- matchers:
- severity=~"critical|high"
- team="payment"
receiver: payment-pager
group_by:
- alertname
- cluster
- service
continue: true # inhibition 쪽으로도 전달
- matchers:
- severity="warning"
receiver: slack-oncall
group_wait: 2m # warning은 조금 더 기다렸다가 묶어서
inhibit_rules:
# DB 다운이 확실할 때 그 DB에 의존하는 서비스의 latency/error 알람은 억제
- source_matchers:
- alertname="DBConnectionFailed"
target_matchers:
- alertname=~"HighLatency|HighErrorRate"
equal:
- cluster
- service_dependency_groupinhibit_rules가 이 설정의 핵심입니다. Causal alert가 이미 운영자에게 전달되면 파생 symptom alert는 자동으로 억제되어 체감 노이즈가 크게 줄어듭니다.
8.4 상용 ML grouping의 현실
PagerDuty Intelligent Alert Grouping은 공식 문서상 즉시 동작합니다(minimal-to-zero training necessary). 다만 팀 고유의 merge/unmerge 피드백이 쌓일수록 정확도가 개선되며, Preview 모드는 과거 45일치 데이터를 기반으로 하루 1회 그룹을 제안합니다. 초기 배포 시에는 Content-Based·Time-Based grouping을 안전망으로 병행해야 합니다.
공식 문서: PagerDuty AIOps Quickstart · Preview Intelligent Alert Grouping.
8.5 End-to-end 케이스 — 50개 알람을 1개 incident로 묶기까지
payment-db 장애 하나가 어떻게 50개 알람으로 불어나고, 그 50개가 운영자 화면에서 1개로 압축되는지 끝까지 따라가 보겠습니다.
전제 — payment-db 단일 인스턴스 connection pool 고갈 (실제 원인 13:00:00)
분류: single causal(공통 모드 장애 아님). DNS·IAM·공유 DB 같은
common-cause케이스의 처리는 §5.7을 별도로 보세요 — 이번 케이스는 causal 후보가 폭증하지 않으므로 가장 깔끔한 시나리오입니다.
[원시 알람 50건]
13:00:01 payment-db DB connection pool exhausted (causal)
13:00:03 api-gateway 504 for /payment/* (symptom)
13:00:05 auth-service 503 (depends on payment) (symptom)
13:00:07 frontend-web error rate 8.2% (symptom)
13:00:09 synthetic /checkout probe timeout (symptom)
13:00:12 queue-worker payment.event.queue depth > 1000 (symptom)
13:01.. 같은 알람 5분 간격 재발화 × 8회 (re-fire)
13:02:15 payment-db 동일 알람 SLO burn fast (compounding)
...파이프라인이 50건을 어떻게 1건으로 줄이는가

압축비 50x (50건 → 1 incident). 각 단계의 처리를 표로 펼치면 다음과 같습니다.
| 단계 | 입력 | 처리 | 출력 |
|---|---|---|---|
| 1. Normalization (2주차) | 6종 도구의 50건 | 공통 스키마(PD-CEF 등)로 필드 표준화 | 50건 (필드만 정규화) |
| 2. Deduplication (3주차) | 50건 | re-fire 8회를 fingerprint로 압축 | 18건 |
| 3. Temporal clustering (§4.1, §15.2 Q2 #1) | 18건 | 5분 sliding window | 1개 후보 묶음 (18건) |
| 4. Topology projection (§5.6, §15.2 Q2 #2) | 18건 + SDG | weakly-connected subgraph 1개 | 후보 incident 1건 (18 alerts) |
| 5. Causal candidate ranking (§5.6, §15.2 Q2 #4) | 18건 | upstream 추적: payment-db만 “자기보다 위에 알람 없는 노드” | causal=payment-db |
| 6. Alert semantics 가중 (§15.2 Q2 #5) | 18건 | saturation(connection pool) > error rate > latency | causal=payment-db (확정) |
| 7. Impacted suppression (§8.3 inhibit_rules) | 17건 (causal 제외) | reachable downstream 자동 억제 (단, severity≥critical은 예외) | 운영자 화면에는 1개 incident + 2건 critical impacted만 표시 |
최종 운영자 화면:
[INCIDENT-2026-04-25-001] payment-db connection pool exhausted (causal)
└─ blast radius: 7 services (api-gateway, auth, frontend, synthetic, queue-worker, ...)
└─ suppressed: 17 downstream symptom alerts
└─ visible critical: api-gateway 504 (P1), checkout synthetic timeout (P1)
└─ change context: deploy 2026-04-25 12:54 payment-db config v1.42 (top causal hint)측정 결과 (§14.1 지표 적용)
- Incident compression ratio: 50 → 1 = 50x
- Causal precision (post-mortem): payment-db 정답 → 100%
- MTTA: 4분 → 30초 (운영자가 50개 화면 스크롤 대신 1개 카드 검토)
이 흐름을 한 번 따라가면 §3의 “50개 알람” 문제와 §13.5의 파이프라인이 같은 이야기였다는 점이 드러납니다.
9. SLO 기반 Alerting — Alert Fatigue의 근본 해결책
1절에서 말씀드린 “줄이지 말고 묶기”는 주어진 알람을 가장 잘 처리하는 전략이었습니다. 그런데 입력 자체가 잘못되어 있다면 아무리 잘 묶어도 한계가 있습니다.
Honeycomb의 Observability Engineering(Ch 12~13)은 한 단계 위에서 질문을 던집니다.
SLO 기반 alerting은 correlation·grouping의 대체가 아니라, correlation 엔진으로 흘러드는 입력 품질을 높이는 전략입니다. 둘은 상호 보완 관계입니다(§14.3에서 한 번 더 정리합니다). 한 단계 위의 질문은 단순합니다 — 애초에 알람을 무엇에 걸고 있었습니까?
9.1 Potential-cause vs Symptom-of-user-pain
CPU 90% / 메모리 85% / 디스크 I/O 스파이크 같은 알람은 potential-cause alert입니다. 시스템 내부 지표가 “이상해질 수 있는 징조”를 보여줍니다. 문제는 이 징조가 사용자 영향을 반영하지 않는다는 점입니다. CPU 90%여도 사용자는 멀쩡하고, CPU 30%인데 사용자 페이지는 느릴 수 있습니다.
Google SRE가 강조하는 건 symptom-of-user-pain alert — 사용자가 실제로 겪는 고통에 걸린 알람입니다. 이 관점이 SLO의 뿌리입니다.
9.2 SLI / SLO 요약 (간단히)
SLI (Service Level Indicator): 이벤트 기반 지표
예: "요청의 99%가 300ms 이내에 성공적으로 응답되었는가?"
SLO (Service Level Objective): SLI의 목표치
예: "지난 30일 동안 99.9%"
Error Budget: 허용된 실패량
예: 월 43분 (99.9% × 30일)
Burn Rate Alert: Error budget을 얼마나 빨리 소진 중인가
- Fast burn: 1시간에 예산의 2% 이상 소진 → 즉시 경보
- Slow burn: 6시간에 예산의 10% 이상 소진 → 완만한 경보Honeycomb 책은 Event-based SLI가 Time-based SLI보다 정확하다고 권합니다. “5분 창에서 99th percentile이 300ms 이내”보다 “각 요청을 개별 판정해 OK/error로 분류”가 에러를 덜 숨깁니다.
Burn Rate 3단 권장값 (실무 참고)
Google SRE Workbook과 GCP Cloud Monitoring 가이드 기준으로 실무에서 자주 쓰이는 3단 구성입니다(30일 SLO 기준).
| Burn Rate | Lookback Window | Budget 소진 비율 | 알람 채널 | 사용 맥락 |
|---|---|---|---|---|
| Fast burn | 1시간 | 2% | 즉시 pager | 급성 장애 — 온콜 즉시 응답 |
| Slow burn | 6시간 | 10% | 업무시간 ticket | 점진적 성능 저하 |
| Trend burn | 3일 | 10% | 주간 리포트 | 서비스 수준의 구조적 하락 |
세 단계를 동시에 걸어 두면 “잠깐 터졌다 사라지는 blip”과 “장기 하락 추세”를 각각 다른 채널로 분리할 수 있습니다.
9.3 케이스 스터디 — Honeycomb Shepherd (2019)
책에 실린 실제 사례입니다.
Shepherd 서비스(고객 데이터 수집 엔드포인트)의 SLO가 01:29에 번(burn)을 시작했습니다. Error budget 30일치 중 대부분이 이 때 20분간 1.5% brownout으로 소진되었습니다. 문제는 잠시 후 자연스럽게 회복된 것처럼 보였다는 점입니다.
온콜 엔지니어가 새벽에 호출을 받았지만 서비스가 정상처럼 보이니 “일시적 blip”이라 판단하고 다시 잤습니다. 그런데 같은 SLO 알람이 네 번째로 09:55에 떴을 때 — 팀은 그제야 인시던트를 선언했습니다. 전통적 모니터링은 여전히 발동하지 않았습니다(연속 probe 실패 임계 미달).
조사 결과: 메모리 누수. 각 클러스터 노드가 OOM으로 동기화돼 재시작하고 있었습니다. SLO alert는 문제를 7~8시간 빨리 잡아냈습니다.
9.4 SLO가 Correlation 부담을 줄입니다
SLO alert는 대부분 단일 증상(사용자 경험 악화)으로 정리되어 올라옵니다.
10개의 내부 지표 알람이 몰려오는 대신 “payment SLO burn rate: fast” 1건이 옵니다. Correlation 엔진이 붙들고 있어야 할 입력이 처음부터 적어집니다.
결국 correlation을 잘하려고 애쓰기 전에 알람의 입력 자체를 다시 봐야 합니다. SLO 기반 alerting이 Alert Fatigue의 최상위 해결책인 이유입니다.
GCP Cloud Monitoring의 SLO burn rate (fast/slow) 2단 경보가 이 철학의 대표적 클라우드 구현입니다(10절).
9.5 추천 도서
- Implementing Service Level Objectives — Alex Hidalgo (O’Reilly) — SLO 실무 심화
- Observability Engineering — Majors, Fong-Jones, Miranda (O’Reilly) — SLO + Observability
10. Public Cloud 사례 — AWS / Azure / GCP
세 클라우드는 correlation 설계 철학이 다릅니다.
| 구분 | 중심 철학 | 대표 기능 |
|---|---|---|
| AWS | 서비스맵 중심 | CloudWatch Application Signals + Application Map |
| Azure | 규칙 엔진 중심 | Alert Processing Rules + Action Groups |
| GCP | SLO 중심 | Service Monitoring + SLO burn rate |
10.1 종합 비교표
| 기능 | AWS | Azure | GCP |
|---|---|---|---|
| 자동 토폴로지 발견 | Application Signals + App Map | Application Insights App Map | Application Monitoring (topology view Preview) |
| 규칙 기반 묶음 | Composite Alarm | Alert Processing Rules | Alerting policy group_by |
| ML/자동 insight | DevOps Guru | Smart Detection | Service Monitoring |
| 억제(Suppression) | (조합 필요) | Alert Processing Rules Suppress | Alerting policy condition |
| SLO 지원 | Application Signals SLO | Service Level Indicators | Service Monitoring SLO + burn rate |
| Agentic AIOps | DevOps Agent (GA 2026-04) | SRE Agent (GA 2026-03-10) | Gemini Cloud Assist investigations (Preview 2026-02) |
10.2 자주 잘못 알려진 사실 3가지
- AWS Systems Manager Incident Manager는 "종료"가 아니라 "신규 고객 중단" (2025-11-07). 기존 고객은 계속 사용 가능. 마이그레이션 권장 경로: Systems Manager OpsCenter + 서드파티 페이징.
- Azure VM Insights Map은 은퇴 절차 진행 중 (2025-06 발표 → 2025-09 신규 온보딩 제한 → 2028-06-30 완전 은퇴). 대체: Application Insights App Map + Azure Resource Graph.
- GCP native incident grouping은 단일 incident로 완전 집계가 불가능하다는 한계가 공식 문서에 명시. 다중 조건 alerting policy를 써도 시계열별로 incident가 분할됩니다.
11. 상용·OSS 사례 — 3 archetype + Capability Matrix
Public cloud가 자기 생태계 내부에 강하다면, 상용·OSS는 이기종 신호 통합에 강합니다. 다만 단일 도구 하나로 끝내려는 시도는 거의 실패합니다. 실무에서는 AlertManager + OTel + ITSM 조합처럼 여러 계층을 얇게 쌓는 편이 성공률이 높습니다.
11.1 3 archetype — 속성·토폴로지·OSS 라우팅
벤더 카탈로그를 외우는 대신, correlation 엔진이 어떤 신호를 1차로 쓰는지 3가지 archetype을 보면 시장 전체가 정리됩니다.
Archetype 1. 속성 기반 (BigPanda)
- Primary / Secondary Property로 이벤트를 정규화한 뒤 matching → correlation pattern 순으로 묶습니다.
- 3주차의 primary/secondary가 dedup 키였다면, 4주차에서는 correlation 키로 재포지셔닝됩니다.
- 강점: 이기종 알람의 정규화가 빠름. 한계: topology 신호는 외부 입력 의존.
Archetype 2. Topology 기반 (IBM Cloud Pak for AIOps, ServiceNow Predictive AIOps)
- IBM은 Temporal + Topological + Scope-based를 동시에 쓰는 전통 NOC 계보(전 Netcool). ServiceNow는 CMDB CI 관계를 1차 신호로 사용.
- 강점: causal chain·blast radius 추적이 정밀. 한계: CMDB 품질이 낮으면 오히려 영향 분석이 잘못 퍼집니다. 품질 관리 선행 필수.
Archetype 3. OSS 라우팅/grouping (Prometheus AlertManager)
route트리 +group_by+inhibit_rules조합으로 routing/grouping까지는 탁월.- 엄밀히는 causal correlation 엔진이 아닙니다. Cross-cluster correlation, topology-aware parent-child suppression 같은 고급 기능은 별도 조합이 필요합니다.
PagerDuty(Intelligent/Content/Time-Based 3종, §8.4 참조), Moogsoft(Sigaliser + Cookbook), Elastic(Relevance-score grouping), OpenSearch(Alerting monitors)는 위 3 archetype의 변형입니다. capability matrix에 한 줄씩 정리합니다.
11.2 벤더 7개 capability matrix
| 제품 | Time-window | Fingerprint | Causal Chain | LLM/Semantic | 도입 난이도 |
|---|---|---|---|---|---|
| BigPanda | ○ | ◎ | ○ | 일부 | 중간 |
| Moogsoft | ○ | ○ | ◎ | 일부 | 중간 |
| PagerDuty | ◎ | ◎ | △ | ○ | 낮음 |
| IBM Cloud Pak | ◎ | ○ | ◎ | ○ | 높음 |
| ServiceNow | ○ | ○ | ◎ | 일부 | 높음 |
| AlertManager | ◎ | ◎ | △ (inhibit_rules) | ✗ | 낮음 |
| Elastic | ○ | ○ | △ | ○ | 중간 |
기호: ◎=강함, ○=기본 제공, △=제한적, ✗=없음
12. 2025~2026 최신 트렌드 — Agentic / LLM Causal / eBPF / OTel SG / MCP
Correlation은 더 이상 독립 기능으로 머무르지 않습니다. 2025~2026년에는 RCA·Remediation 에이전트의 입력 레이어로 승격되고 있습니다. (OTel Service Graph Connector 성숙 상황은 §6.3 참조.)
12.1 eBPF 기반 zero-instrumentation topology
- Cilium Hubble: Kubernetes 네트워크 관측성 + L7 파싱
- Pixie: K8s 자동 계측 + 프로파일링
- Odigos: eBPF → OTel 형식 자동 변환
- OBI (OpenTelemetry eBPF Instrumentation): 2025-11-03 Grafana가 Beyla를 OpenTelemetry 프로젝트로 기증하면서 OBI로 흡수됨. 언어 agnostic eBPF auto-instrumentation이 OTel 공식 프로젝트로 승격된 사례
(eBPF의 L3/L4 한계는 §6.2 참조)
12.2 LLM 기반 Causal Correlation
단순 semantic similarity가 아닌 causal reasoning으로 진화 중입니다. Chain-of-Thought, Retrieval-Augmented Incident Matching, Causal Discovery 같은 기법이 논문 수준을 넘어 제품에 들어가기 시작했습니다.
리스크: hallucination, 설명 불충분, 학습 데이터 의존성. 고위험 조치는 여전히 Approval Gate가 필요합니다.
12.3 Agentic AIOps — Correlation 레이어의 재정의
2025~2026년에 주요 클라우드·SRE 플랫폼이 모두 Agentic AI를 GA로 출시했습니다(Dynatrace 2025-02, AWS DevOps Agent 2026-04, Azure SRE Agent 2026-03-10, GCP Gemini Cloud Assist Preview 2026-02). 모두 correlation 출력을 RCA·remediation 에이전트의 입력 컨텍스트로 소비하는 구조입니다.
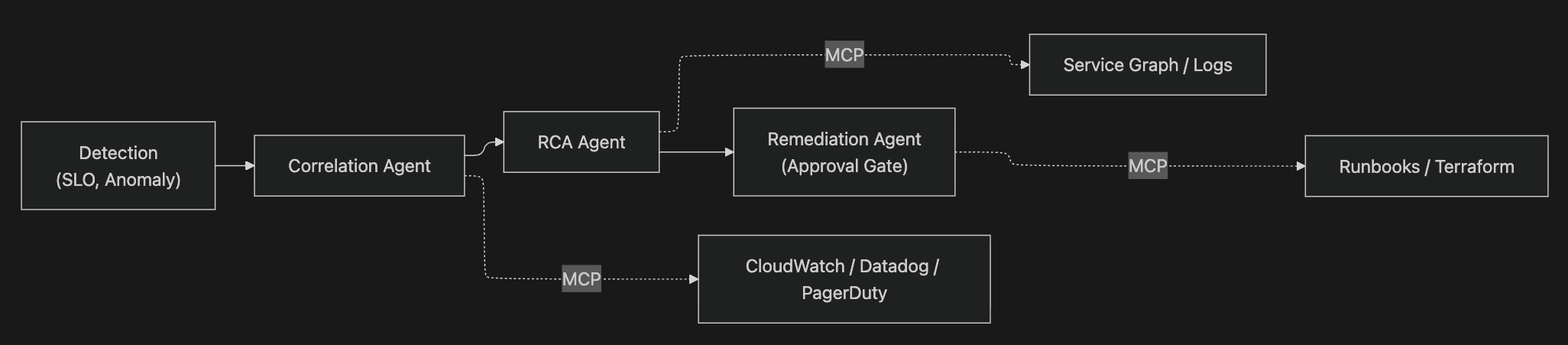
12.4 MCP (Model Context Protocol) — 에이전트 도구 통합 표준
2025-12-09 Anthropic이 MCP를 Linux Foundation 산하 Agentic AI Foundation(AAIF) 에 기부했습니다 (Anthropic·OpenAI·Block 공동 설립). MCP의 의미는 커넥터 파편화 문제를 표준 프로토콜로 해소한 것입니다 — PagerDuty/Datadog/ServiceNow마다 별도 커넥터 대신 MCP 서버 하나로 모든 Agentic AI가 인프라 상태를 조회할 수 있습니다. A2A(Agent-to-Agent)는 다른 계층 — MCP는 tool 연결, A2A는 에이전트 간 오케스트레이션입니다. (5주차 RCA 에이전트에서 본격적으로 다룹니다.)
12.5 연구 / 벤치마크
| 논문 / 벤치마크 | 발표 | 의의 |
|---|---|---|
| A Survey of AIOps in the Era of LLMs | ACM CSUR 2025 (arXiv:2507.12472) | 2025 현재 LLM×AIOps 연구의 종합 지도 |
| OpenRCA: Can LLMs Locate the Root Cause of Software Failures? | ICLR 2025 | Claude 3.5 + RCA-agent setup에서 11.34% 해결률 — 자율 복구는 아직 초기 |
| AIOpsLab | MLSys 2025 (arXiv:2501.06706) | 에이전트 평가 프레임워크 |
| STRATUS: A Multi-agent System for Autonomous Reliability Engineering of Modern Clouds | NeurIPS 2025 (arXiv:2506.02009) | Transactional No-Regression(TNR) 안전 사양, 1.5× 성능 향상 |
| Flow-of-Action: SOP Enhanced LLM Multi-Agent RCA | WWW 2025 Industry | SOP 기반 에이전트 오케스트레이션 |
OpenRCA의 11.34% 해결률(ICLR 2025, Claude 3.5 + RCA-agent setup 기준)은 현실 체크의 앵커입니다. “AI가 correlation을 완벽 자동화”라는 마케팅 주장은 이 숫자 앞에서 재검토해야 합니다. 단 이 수치는 특정 세팅의 예시이며, Claude 4.7 등 신규 모델로 재측정되면 값이 바뀔 가능성이 있습니다.
13. 실무 적용 패턴 — Correlation 아키텍처 블루프린트
벤더 선택보다 아키텍처 결정 4가지가 먼저입니다. “올인원 벤더 한 번에 도입”보다 기존 도구에 correlation 레이어 한 장 얹기가 성공률이 높습니다.
13.1 결정 1 — Topology source 선택
§6.4의 환경별 1차 출처 가이드를 다시 한 번 의사결정 다이어그램으로 보면 다음과 같습니다. 어떤 소스를 고르든 결과 SDG의 엣지는 §6.5의 4차원 메타데이터(confidence · freshness · evidence_type · source_provenance)로 저장하는 것이 안전합니다 — 이 형식이 있어야 다음에 나올 SDG Merger(§13.2.1 3단계)가 출처 간 충돌을 정량적으로 해소할 수 있습니다.
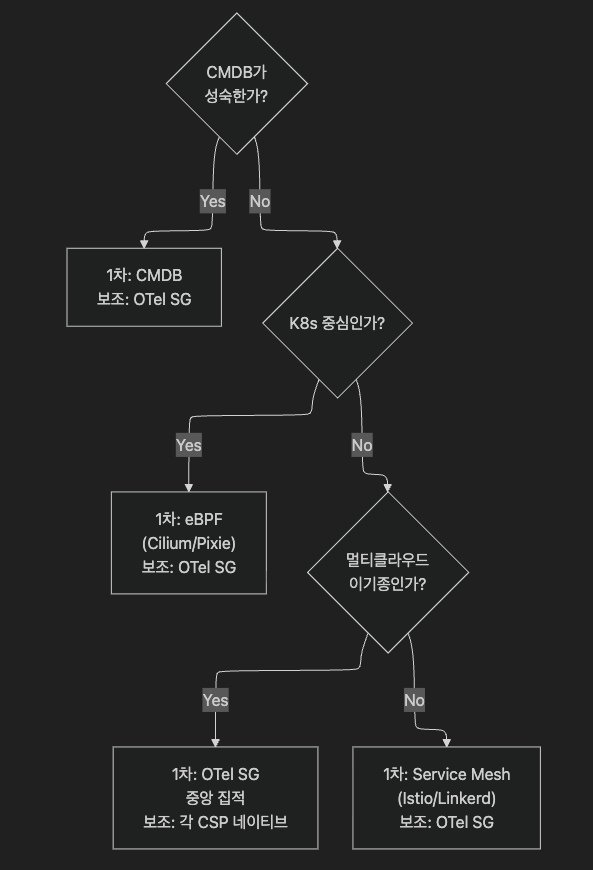
13.2 결정 2 — Correlation 엔진 위치
| 위치 | 장점 | 단점 | 추천 |
|---|---|---|---|
| Edge (AlertManager 수준) | 낮은 지연, 팀 자율 | Cross-team grouping 부족 | 중소 조직 |
| Central (BigPanda / Moogsoft) | Cross-team / cross-cluster | 도입 비용, 벤더 lock-in | 대규모 엔터프라이즈 |
| Hybrid | 양자의 장점 | 아키텍처 복잡도 | 중규모 조직 |
13.2.1 조직 규모별 단계적 도입 경로
“4개 SDG 소스를 전부 합쳐서 써라”는 조언은 대부분 조직에게 비현실적입니다. 현실적인 3단계는 이렇습니다.
| 단계 | 조직 규모 | 도입 구성 | 다음 단계로 넘어가는 신호 |
|---|---|---|---|
| 1단계 | 1명 SRE, 서비스 20개 미만 | OTel Service Graph Connector 단일 소스 | 서비스 수 증가 · alert-per-incident > 10 |
| 2단계 | 소규모 SRE 팀 | OTel SG + eBPF (Cilium Hubble 또는 Pixie) 교차검증 | 멀티클러스터 · 이기종 런타임 · CMDB 필요 |
| 3단계 | 엔터프라이즈 | 네 소스(CMDB + OTel + Mesh + eBPF) + SDG Merger (엣지는 §6.5 4차원 형식으로 저장) | 해당 없음 (지속 개선) |
중요한 원칙: 작게 시작해 topology를 점진적으로 채웁니다. 처음부터 엔터프라이즈 구성을 시도하면 조직 역량이 따라가지 못해 실패 확률이 높아집니다.
13.3 결정 3 — Grouping 계층
3단 구조가 현실적입니다.
[Team routing] 팀·오너십 기준 1차 라우팅 (AlertManager route)
↓
[Service fingerprint] 서비스·클러스터 단위 2차 grouping (dedup_key)
↓
[Incident causal] Topology DAG 기반 3차 causal chain (상용 엔진)13.4 결정 4 — Suppression 경계
- 유지보수 창 (사전 정의)
- 알려진 FP (severity gate로 critical/P1은 예외)
- 계절성 이벤트 (세일·배포 중)
- 무기한 suppression 금지 — 모든 suppression은 만료일 필수
13.5 4주차 최종 Noise Reduction Pipeline
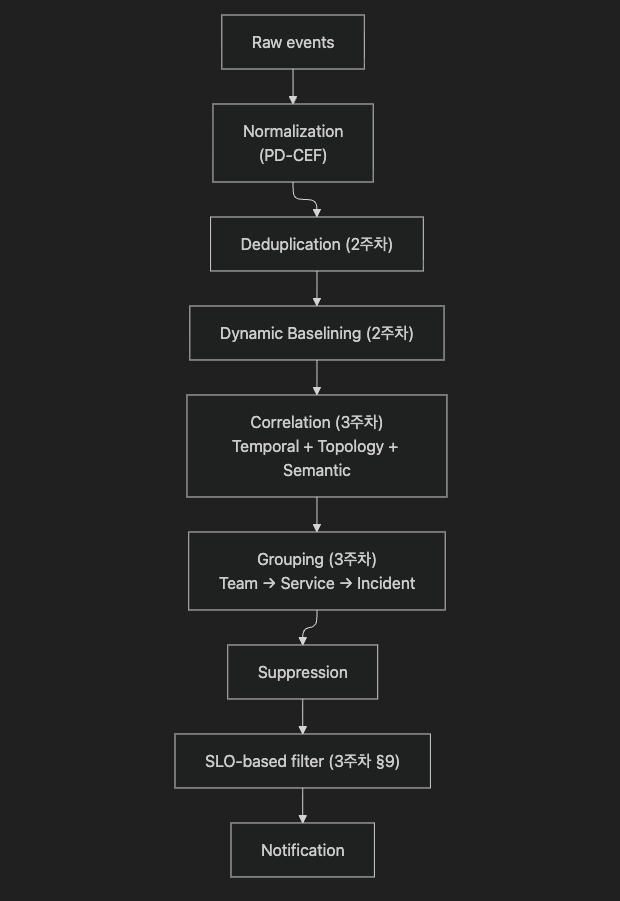
5주차로 넘어가면 그림이 더 선명해집니다. Agentic AIOps 관점에서 correlation 레이어는 RCA 에이전트의 입력 컨텍스트입니다. correlation이 만든 incident.causal_ci + impacted_cis 묶음이 MCP tool call의 primary context로 흘러가고, RCA 에이전트는 여기에 trace·log·metric을 추가로 fetch합니다. 결국 correlation 품질이 RCA 에이전트 입력 토큰의 품질을 결정합니다.
14. 한계와 주의점 — “The Misleading Promise of AIOps”
Honeycomb의 Observability Engineering(Ch 8)은 AIOps를 비판적으로 바라봅니다. 이 관점을 외면하면 벤더 마케팅에 쉽게 휘둘립니다.
“AI technology isn’t magic. AI can help only if clearly discernible patterns exist and aren’t buried by an overwhelming amount of noise… In an innovative environment with system behavior that changes frequently, it’s more likely that AI will draw a box of the wrong size. The box will be either too small — identifying a great deal of perfectly normal behavior as anomalies, or too large — miscategorizing anomalies as normal behavior.”
— Majors, Fong-Jones, Miranda
14.1 Correlation 품질 측정 — “좋은 correlation”의 운영 지표
“알람 99% 감소” 같은 벤더 수치만으로는 correlation 품질을 판단할 수 없습니다. 노이즈 감소와 운영 품질은 다른 축이기 때문입니다. 실무에서는 보통 다음 다섯 지표를 같이 봅니다.
| 지표 | 정의 | 측정 방법 | 목표 방향 |
|---|---|---|---|
| Incident compression ratio | (입력 알람 수) / (출력 incident 수) | 일/주 단위 집계 | 클수록 좋음 (단, false merge 동반 확인) |
| False merge rate | 서로 다른 incident가 하나로 합쳐진 비율 | 운영자가 사후 split한 사례 / 전체 incident | 5% 미만 권장 |
| False split rate | 같은 incident가 여러 건으로 쪼개진 비율 | 운영자가 사후 merge한 사례 / 전체 incident | 10% 미만 권장 |
| Causal precision | causal로 지목된 CI가 실제 RCA 결론과 일치한 비율 | post-mortem 라벨링 | 70%+ 권장 |
| MTTA / MTTR delta | 도입 전후 평균 인지/복구 시간 차이 | before/after A·B 비교 | MTTA·MTTR 모두 감소 |
중요: incident compression ratio만 단독으로 보면 위험합니다. False merge가 늘어도 비율은 좋아 보이기 때문입니다. compression × precision 두 축으로 동시에 모니터해야 합니다.
14.2 Correlation 고유 실패 모드
| 실패 모드 | 증상 | 완화 |
|---|---|---|
| False Merge | 서로 다른 인시던트가 하나로 합쳐짐 | Topology 이중 소스 검증, severity gate |
| False Split | 같은 인시던트가 쪼개짐 | Time window 확대, fingerprint 재설계 |
| Missing Edges | SDG에 없는 의존성 놓침 | eBPF·OTel 보조 소스, 정기 drift 감사 |
| Explainability 결여 | LLM correlation의 블랙박스 | Deterministic rule과 병행, 이유 노출 UI |
14.3 벤더 주장에 대한 8가지 체크
- “알람 99% 감소” — 노이즈 감소가 MTTR 감소와 같은 말은 아닙니다. 둘을 자동으로 동치로 두지 마세요.
- “AI가 완벽히 자동 correlation” — OpenRCA 벤치마크 11.34% 해결률 한계를 반드시 함께 언급해야 합니다.
- “CMDB 없이도 AIOps 완전 작동” — 토폴로지 품질이 떨어지면 correlation 품질도 같이 떨어집니다. Tag/learning으로 대체는 가능하지만 등가는 아닙니다.
- “eBPF = zero overhead, 100% 정확” — L7 파싱·TLS 풀기에는 비용이 있고, L3/L4만으로는 앱 인과를 확정할 수 없습니다.
- “MCP가 모든 AI agent 통합 표준” — 2026-04 현재 early majority 진입 중. A2A 등 경쟁 프로토콜이 공존합니다.
- “AWS DevOps Agent 4분 자동 복구” — re:Invent 데모 기준입니다.
- “OTel servicegraph connector가 프로덕션 표준” — 2026-04 현재 Traces→Metrics 파이프라인이 아직 alpha 상태입니다.
- “SLO 도입 = Alert Fatigue 해결” — SLO는 potential-cause 알람을 줄이지만, symptom 알람의 correlation·grouping 필요성까지 없애지는 않습니다. §9와 §1~§8은 상호 보완이지 대체가 아닙니다.
14.4 용어 가드레일
실제 글·보고서에서 지켜야 할 언어 규칙입니다.
| 쓰지 말 것 | 대신 쓸 것 | 이유 |
|---|---|---|
| “root cause” | “root cause 후보”, “probable causal node” | AIOps가 단정하기엔 이른 단계 많음 |
| “semantic similarity = causality” | 둘을 구분 | 유사성은 인과의 증거일 뿐 |
| “correlation = 중복 제거” | 엄격 구분 | 2절 참조 |
| “알람 수 감소 = MTTR 감소” | 각각 측정 | 벤더 주장 함정 |
| “Incident Manager 종료” | “신규 고객 중단, 기존 고객 계속 사용” | 사실 정확성 |
14.5 운영 가드레일 체크리스트
- 모든 correlation 결과에 이유(evidence) 필드가 노출되는가?
- Suppression에 만료일이 강제되는가?
- 토폴로지 drift 감지 알림이 있는가?
- 학습 기반 grouping이 팀 고유 merge 패턴을 충분히 반영할 만큼 피드백 데이터를 확보했는가?
- LLM correlation이 내린 판단을 deterministic rule과 교차 검증하는가?
- 벤더 수치는 “~라고 밝혔다” / “~라고 주장한다” 형식으로 인용되는가?
14.6 Root cause는 단정이 아니라 후보 — 그래도 correlation은 필요합니다
5.6절에서 소개한 판정 알고리즘의 핵심 원칙을 실무 언어로 다시 정리합니다.
Correlation이 제시하는 것은 root cause가 아니라 root cause 후보입니다. (§5.6 판정 알고리즘 참조)
자동 판단을 과신하지 않고 검증 가능한 hypothesis로 다루는 자세만 지키면, correlation은 여전히 분산 시스템 운영의 필수 도구입니다. 좋은 데이터 · 신선한 topology · 명시적 가드레일 · 설명 가능한 결과 네 가지가 함께 있어야 correlation이 자산이 되고, 이 네 가지 없이 도입하면 새로운 블랙박스가 되어 다음 인시던트의 원인이 됩니다.
15. 핵심 정리 + FAQ + 참고자료
15.1 4주차 핵심 질문과 답
| 질문 | 답 |
|---|---|
| Alert Noise의 근본 원인은? | 규칙 수가 아니라 의존 구조. 파생 증상을 개별 사건처럼 취급해서 생김 |
| Correlation과 Deduplication의 차이는? | Dedup은 같은 이벤트 지우기, Correlation은 서로 다른 증상을 하나의 인시던트로 해석 |
| 가장 강력한 correlation 축은? | Topological — 유일하게 causal vs impacted를 구분 가능 |
| Network topology와 Application topology를 왜 분리하나? | 신호·저장·알고리즘이 다름. Network는 availability, App은 availability+performance |
| SDG를 어디서 얻나? | CMDB / OTel Tracing / Service Mesh / eBPF 네 소스를 조합. 단일 소스로는 부족 |
| Stale Topology는 왜 위험? | “없음”보다 “틀림”이 더 위험. 엉뚱한 CI가 root cause로 지목됨 |
| Alert Grouping 3전략은? | Time-window / Fingerprint / Causal chain — 계층적으로 조합 |
| Alert Fatigue 근본 해결책? | SLO 기반 alerting — potential-cause → symptom-of-user-pain |
| Public cloud 3사의 correlation 철학? | AWS = 서비스맵, Azure = 규칙 엔진, GCP = SLO |
| “AI가 correlation 자동화”를 믿어도 되나? | OpenRCA 기준 11.34%만 해결. 보조 수단으로 사용, 단독 신뢰 금지 |
15.2 토론 논의
스터디에서 두 가지 질문이 남았습니다. 어느 쪽도 단일 정답이 있는 질문은 아닙니다. 제 판단과 그 근거를 적고, 마지막에 현업 질문 몇 개로 마무리하겠습니다.
Q1. SDG는 어떤 출처에서 시작할 것인가
CMDB, 분산 트레이싱 span, service mesh 텔레메트리, eBPF 중 무엇을 1차 출처로 두고, 부족한 부분은 어떻게 보완할 것인가.
제 판단 — runtime-observed first, CMDB/IaC overlay second. runtime 신호를 그래프의 뼈대로 두고, CMDB는 의미(소유자·티어·의도된 의존)를 입히는 오버레이로 씁니다.
근거. CMDB는 의도(intended)를 말하고 runtime은 실제(observed)를 말합니다. incident에서 필요한 건 실제 흐름이지 의도된 그림이 아닙니다.
그렇다고 단일 runtime 소스만 믿으면 위험합니다. Tracing·eBPF·Mesh는 각각 다른 방식으로 진실을 놓치기 때문입니다 — 그래서 출처 간 diff를 운영 시그널로 써야 합니다(§6.5).
마지막으로 L4 트래픽 방향이 논리적 의존 방향과 항상 같진 않습니다. polling·webhook·pub/sub ack에서는 packet initiator와 의존자가 뒤집힙니다. 방향성의 semantic truth가 필요한 곳에서는 tracing이 가장 강합니다.
환경에 따라 1차 출처는 갈립니다.
| 환경 | 1차 | 보조 |
|---|---|---|
| 계측 성숙한 MSA | 분산 트레이싱 span | eBPF, mesh |
| K8s + Mesh 성숙 | Mesh + Tracing | eBPF (mesh 밖) |
| 레거시 / VM | eBPF / netflow | 점진적 tracing |
| 멀티클라우드·서버리스 | 분산 트레이싱 | eBPF, mesh |
현업에 대입해보면 — 지금 우리 조직의 SDG는 CMDB가 뼈대인가요, runtime이 뼈대인가요? 그 뼈대가 마지막 incident에서 정확했나요? Tracing/eBPF/Mesh 출처 사이의 diff를 본 적이 있나요? 있다면 그건 shadow IT를 발견할 수 있는 단서입니다.
Q2. Causal과 Impacted를 어떤 기준으로 가를 것인가
Temporal(발생 시각 순서)과 Topology(의존 방향) 중 무엇을 우선할 것인가.
제 판단 — 우선순위는 Topology > Alert semantics > Temporal. 단순 2-class가 아니라 causal / impacted / common-cause 3-class로 봅니다. 그리고 change event(배포·flag flip)는 topology보다도 먼저 보는 1순위 신호입니다.
근거. 시간은 자주 거짓말합니다. 합성 모니터(30s)와 SLO burn(multi-window)의 detection latency 차이에다 clock skew, grouping delay까지 겹치면 다운스트림이 업스트림보다 먼저 울리는 역전이 흔합니다.
반면 의존성 방향은 측정 시점과 독립적인 구조적 진실입니다. A → B 엣지가 있으면 B의 실패가 A에 영향 가능하다는 방향은 확정적입니다(예외: metastable failure).
그리고 공통 모드 장애(DNS·IAM·공유 DB·AZ)는 2-class로 안 풀립니다 — "모두가 다 의존"이라 causal candidate가 폭증하므로 별도 common-cause 클래스가 필요합니다.
전형적인 시간 역전 예시입니다.
[13:00:03] API gateway 504 for /payment/* ← 먼저 울림 (합성 모니터 30s 주기)
[13:00:07] Frontend error rate 8.2% ← 증상
[13:02:15] Payment DB connection pool exhausted ← 실제 원인 (5m rolling window)알고리즘과 7단 운영 파이프라인은 §5.6, 3-class와 dependency type별 규칙은 §5.7에 있습니다.
현업에 대입해보면 — 우리 팀의 가장 최근 incident에서 “먼저 울린 알람이 실제 원인이었나?” 한 건만 떠올려보면 답이 나옵니다. 그리고 change event를 incident와 자동 연결하는 채널이 있나요? 없다면 무엇이 막고 있나요? 우리는 causal / impacted 2-class로 다루나요, 아니면 common-cause를 따로 처리하는 운영 규칙이 있나요?
두 질문을 같이 놓고 보면 답은 비슷합니다. 구조적 진실(topology·dependency direction)과 실측 신호(runtime flow·alert timing)의 하이브리드입니다. 한쪽만으로는 — topology만 쓰면 drift, runtime 신호만 쓰면 방향성·noise 문제가 생깁니다.
15.3 참고자료
필독 3선
이 글의 핵심 논거가 가장 많이 빚진 자료들입니다.
| 제목 | 종류 | 역할 | 링크 |
|---|---|---|---|
| Observability Engineering (Majors, Fong-Jones, Miranda) | 책 (O’Reilly/Honeycomb 2022) | §3.1 combinatorial explosion · §9 SLO 프레임 · §14 AIOps 비판 | — |
| Hands-on AIOps (Sabharwal & Bhardwaj) | 책 (Apress 2022) | §5 Topology-Based Correlation · §13 도입 단계 | — |
| OpenRCA: Can LLMs Locate the Root Cause of Software Failures? | 논문 (ICLR 2025) | §12.5/§14.3 “11.34% 해결률” 현실 체크 앵커 | https://openreview.net/pdf?id=M4qNIzQYpd |
전체 자료 목록
논문 (9개)
| 제목 | 발표 | 링크 |
|---|---|---|
| Understanding and Handling Alert Storm for Online Service Systems | ICSE-SEIP 2020 | https://dl.acm.org/doi/10.1145/3377813.3381363 |
| A Survey on Intelligent Management of Alerts and Incidents in IT Services | JNCA 2024 | https://netman.aiops.org/wp-content/uploads/2024/08/A-survey-on-intelligent-management-of-alerts-and-incidents-in-IT-services.pdf |
| A Survey of AIOps in the Era of Large Language Models | ACM CSUR 2025 | https://arxiv.org/abs/2507.12472 |
| OpenRCA: Can LLMs Locate the Root Cause of Software Failures? | ICLR 2025 | https://openreview.net/pdf?id=M4qNIzQYpd |
| AIOpsLab: Holistic Framework for AI Agents | MLSys 2025 | https://arxiv.org/abs/2501.06706 |
| STRATUS: A Multi-agent System for Autonomous Reliability Engineering of Modern Clouds | NeurIPS 2025 | https://arxiv.org/abs/2506.02009 |
| Flow-of-Action: SOP Enhanced LLM Multi-Agent RCA | WWW 2025 Industry | https://openreview.net/forum?id=X7dQuJqs8c |
| Root Cause Analysis of Failures in Microservices through Causal Discovery | NeurIPS 2022 | https://proceedings.neurips.cc/paper_files/paper/2022/file/c9fcd02e6445c7dfbad6986abee53d0d-Paper-Conference.pdf |
| Root Cause Analysis in Microservice Using Neural Granger Causal Discovery | 2024 | https://arxiv.org/abs/2402.01140 |
책 (3개)
| 제목 | 저자 | 출판 | 인용 위치 |
|---|---|---|---|
| Hands-on AIOps | Sabharwal, N. & Bhardwaj, G. | Apress, 2022 | Ch 8 Correlation / Topology-Based Correlation, Ch 9 Setting Up AIOps |
| Observability Engineering | Majors, C., Fong-Jones, L., Miranda, G. | O’Reilly / Honeycomb, 2022 | Ch 6 Tracing, Ch 8 Misleading Promise of AIOps, Ch 12~13 SLO |
| Implementing Service Level Objectives | Hidalgo, A. | O’Reilly, 2020 | §9 SLO 심화 레퍼런스 |
벤더 / 클라우드 공식 문서 (14개)
GitHub (10개)
| 레포지토리 | 설명 | 링크 |
|---|---|---|
| cilium/hubble | eBPF 기반 쿠버네티스 네트워크 관측성 | https://github.com/cilium/hubble |
| pixie-io/pixie | K8s auto-instrumentation (eBPF) | https://github.com/pixie-io/pixie |
| odigos-io/odigos | eBPF → OTel 형식 자동 변환 | https://github.com/odigos-io/odigos |
| open-telemetry/obi | OpenTelemetry eBPF Instrumentation (前 Grafana Beyla, 2025-11-03 OTel 기증) | https://github.com/open-telemetry/obi |
| microsoft/OpenRCA | LLM RCA 벤치마크 (ICLR 2025) | https://github.com/microsoft/OpenRCA |
| kiali/kiali | Istio service graph UI | https://github.com/kiali/kiali |
| modelcontextprotocol | MCP 공식 스펙 및 SDK | https://github.com/modelcontextprotocol |
| open-telemetry/opentelemetry-collector-contrib | OTel Service Graph Connector 포함 | https://github.com/open-telemetry/opentelemetry-collector-contrib |
| prometheus/alertmanager | Prometheus AlertManager | https://github.com/prometheus/alertmanager |
| istio/istio | Istio service mesh | https://github.com/istio/istio |
기술 블로그 / 발표 (7개)
