4주차에서 Death Star 위 50개 알람을 1개의 인시던트로 묶었다면,
5주차에서는 그 묶음 안의 "왜" 를 답합니다.
주제는 단 하나 — RCA (Root Cause Analysis) 입니다.
1. 들어가며 — "그래서 왜 터졌는가?"
4주차에서 우리는 새벽 3시 50개 알람을 1개의 인시던트로 묶었습니다.
Death Star 그래프 위에서 DB 한 개의 장애가 API·결제·인증·프런트엔드까지 번지는 모습을 추적했고, topology를 축으로 causal / impacted / common-cause를 구분했습니다.
그리고 화면에는 마침내 한 줄이 떴습니다.
[INC-2026-0507-001] 영향: checkout-web → payment-app → payment-db
상태: 진행 중 (15분 경과)
Causal candidate: payment-db ?여기서 4주차는 멈춥니다. 범위는 묶었지만, 원인은 모릅니다.
운영자는 다시 묻습니다.
"그래서 왜 터졌는가?"
이 한 마디가 5주차의 시작입니다. 4주차가 "이 인시던트의 범위는 어디까지인가" 였다면, 5주차는 그 범위 안에서 "무엇이 원인인가" 를 답합니다. 같은 service graph를 입력으로 쓰지만 질문이 한 단계 깊어집니다.

이번 주차의 자리는 빨간 박스입니다.
그리고 이 자리는 detection·correlation과 본질적으로 성격이 다릅니다.
Detection은 시계열 안에서 닫힙니다. Correlation은 그래프와 시간 윈도우 안에서 닫힙니다.
그러나 RCA는 데이터 안에서 닫혀 풀리지 않습니다. 토폴로지·인과 구조·운영자의 암묵지(tribal knowledge)가 동원돼야 하고,
그래도 정답을 찍는 것이 아니라 후보를 좁히는 작업입니다.
이 글의 척추가 되는 한 문장입니다.
RCA는 정답을 찍는 작업이 아니라, confidence가 부여된 probable cause 후보들을 압축해 운영자의 조사 순서를 추천하는 작업이다.
이 한 문장이 흔들리지 않도록, 글 전체에서 응급실 트리아지 비유를 마스터로 두고 갑니다.
| 단계 | 응급실 비유 | 시스템 |
|---|---|---|
| Detection | 환자가 응급실 문을 통과 | 알람 발생 |
| Correlation (4주차) | "이 환자들 모두 같은 식중독 사건" | 인시던트 묶기 |
| RCA (5주차) | "그 식중독을 일으킨 식당·메뉴·재료·세균을 좁히는 작업" | 원인 후보화 |
| Probable cause + confidence | 의사: "노로바이러스 70%, 살모넬라 20%, 기타 10%" | 모델 출력 |
| Human-in-the-loop | 최종 진단은 의사 + 보건소 협업 | 운영자 검증 |
응급실 의사도 CT 한 장으로 수술 결정을 내리지 않습니다. RCA 모델도 마찬가지입니다.
2. RCA의 본질 — Symptom vs Root Cause
2.1 출력은 'cause'가 아니라 'probable cause + confidence'
신입 운영자가 빠지기 쉬운 함정은 RCA를 한 줄짜리 답으로 기대하는 것입니다.
? RCA: "원인 = payment-db"
? RCA: "원인 = payment-db CPU 100%"학술적·실무적으로 정확한 RCA 출력은 다릅니다.
✓ RCA(top-3 probable cause)
1. payment-db (confidence 0.62)
2. payment-app (confidence 0.21)
3. payment-cache (confidence 0.09)
+ 결정적 단서 후보: ConfigMap diff(db.pool.max 50→5), deploy event 11:42, db.wait p99 ↑여기에 두 가지가 들어 있습니다.
- probable cause 후보 리스트 (대개 top-k)
- confidence score (모델이 그 후보를 얼마나 강하게 의심하는지)
이는 일기예보의 강수확률과 유사합니다. "70% 비"는 "내가 70% 확신한다"가 아니라 "비슷한 상황에서 70%는 비가 왔다" 를 의미합니다. confidence 0.62는 "62% 확실히 원인"이 아니라 "비슷한 패턴에서 62%는 이 노드가 원인이었다" 입니다.
이 차이를 무시하면 automation surprise가 발생합니다.
운영자가 top-1을 자동으로 incident root cause 라벨로 박는 순간, 잘못된 학습 신호가 모델로 다시 들어가 누적됩니다(§11에서 다시).
2.2 Detection · Correlation · RCA의 입출력
세 단계의 입출력을 분리해 보면 RCA의 자리가 분명해집니다.
| 단계 | 입력 | 출력 | 닫혀 풀리는가 |
|---|---|---|---|
| Detection | 단일 시계열·로그 | "이상이다 / 아니다" | ✅ 데이터 안에서 닫힘 |
| Correlation (4주차) | 다수 알람 + 토폴로지 | "이 알람들은 1개 인시던트" | ✅ 그래프·윈도우 안에서 닫힘 |
| RCA (5주차) | 인시던트 + 토폴로지 + 시계열 + 변경 이력 | probable cause 후보 + confidence | ❌ 데이터만으로 안 닫힘 |
마지막 행이 핵심입니다. Detection·Correlation은 데이터가 충분하면 정의상 풀립니다.
RCA는 그렇지 않습니다.
같은 시계열·토폴로지를 줘도 모델마다 다른 후보를 출력하고, 정답 라벨은 운영자의 사후 조사로만 확정됩니다.

1개의 root cause가 N개의 symptom을 만듭니다. 그러나 N개의 symptom으로부터 1개의 root cause를 역추적하는 것은 자명하지 않습니다. 같은 symptom 묶음이 다른 root cause에서도 나올 수 있기 때문입니다(예: pool exhaustion vs DB 자체 부하 vs 네트워크 정체).
이것이 RCA를 어렵게 만드는 첫 번째 이유입니다. 다음 장에서 본격적으로 다룹니다.
3. 왜 RCA는 구조적으로 어려운가 — 5가지 원천
이번 글의 가장 중요한 장입니다. 알고리즘 설명보다 먼저 "왜 어려운가" 를 정직하게 짚어야 7장의 벤치마크 gap이 자연스럽게 이해됩니다.
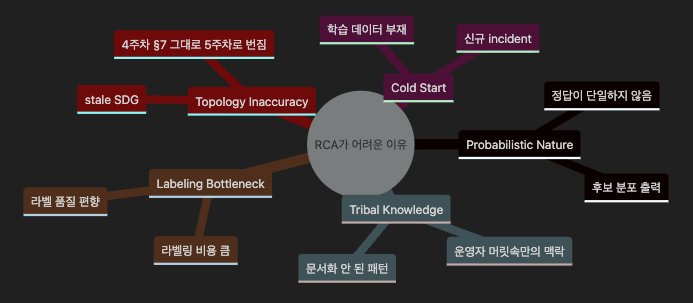
3.1 Probabilistic Nature — 정답이 단일하지 않다
머신러닝 기반 RCA는 본질적으로 확률적입니다.
같은 입력에 같은 모델을 돌려도 토폴로지가 살짝 바뀌면 후보 순위가 바뀝니다.
이는 버그가 아니라 설계상의 출력 형태 입니다.
"We rank candidates; we do not designate the cause."
실무 함의: top-1만 보고 incident를 종결하지 마세요. top-3까지 보고 결정적 단서(§9)와 교차 검증해야 합니다.
3.2 Cold Start — 신규 incident에는 학습 데이터가 없다
처음 보는 fault type, 처음 배포한 서비스, 처음 일어난 의존성 변화에는 학습 데이터가 없습니다.
신입 운영자에게 첫 새벽 콜이 오면 무엇을 합니까? 매뉴얼을 펴고, 그래도 모르면 선임에게 전화합니다. 모델도 똑같습니다. 학습 데이터가 부재하면 confidence 자체가 의미 없어지고, top-k 후보는 "그냥 자주 보던 노드"로 채워집니다.
대응: cold start 영역을 표시하는 신뢰 구간(uncertainty estimation)이 모델 출력에 함께 나와야 합니다. 일부 최신 RCA 시스템은 "이 case는 학습 분포 밖" 이라는 신호를 같이 출력합니다.
3.3 Tribal Knowledge Dependency — 운영자 머릿속의 맥락
[03:42] alert: payment-app latency p99 = 4.2s
선임 SRE: "아, 또 그 캐시야. 어제 인덱스 마이그레이션 풀 때 캐시 워밍이 안 끝나서 그래."
모델: "candidate: payment-db (0.71), payment-app (0.18)"선임의 진단은 정확하지만, 그 지식은 어디에도 학습 데이터로 들어가 있지 않습니다. 이것이 tribal knowledge 의존성입니다. 모델은 학습한 적 없는 패턴을 추론할 수 없고, feedback loop가 들어와야만 학습됩니다.
대응: 모델의 top-k 옆에 "맞았다 / 틀렸다 / 이게 진짜 원인이다" 를 운영자가 한 클릭으로 기록하는 UI가 있어야 합니다. 이게 없으면 RCA 모델은 영원히 처음 그 자리입니다.
3.4 Labeling Bottleneck — 라벨링 비용이 크고 편향이 있다
지도학습 RCA는 "이 incident의 진짜 원인은 X였다" 라벨이 필요합니다. 그러나:
- 비용: 1건의 incident에서 진짜 원인을 확정하려면 운영자가 수십 분~수 시간을 들여 트레이스·로그·diff를 조사해야 합니다.
- 편향: 라벨된 case는 대개 해결된 incident입니다. 미해결·오진 case는 라벨이 안 달립니다 — 모델은 "쉬운 incident"만 학습합니다.
- 시간 왜곡: 사후 라벨링은 "그때 알았다면 이게 원인이었다"는 식으로 되어, 실시간에는 안 보였던 신호까지 반영합니다.
3.5 Topology Inaccuracy — stale SDG가 5주차에서 더 큰 해악으로 번진다
4주차 §7에서 stale topology가 correlation을 왜곡한다고 지적했습니다. 5주차에서는 더 나쁩니다.
| 측면 | Correlation (4주차) | RCA (5주차) |
|---|---|---|
| 입력 그래프가 틀리면 | 묶음이 어긋남 | 엉뚱한 노드를 root cause로 지목 |
| 해악의 형태 | 한 인시던트 ≠ 두 인시던트 | 운영자가 잘못된 노드를 조사 → 골든 타임 손실 |
| 회복 방법 | 토폴로지 갱신 후 재상관 | 토폴로지 갱신 + RCA 재계산 + 라벨 정정 |
즉, 4주차에서 SDG 정확도가 correlation의 천장이었다면, 5주차에서는 RCA의 천장입니다. 그리고 그 천장은 더 낮아집니다 — correlation은 "묶음이 약간 어긋나도" 운영자가 수동으로 합치면 되지만, RCA는 "후보 노드 자체가 틀리면" 운영자가 30분을 잃습니다.
이 5가지가 누적되면 어떤 일이 벌어지는지가 7장의 RCAEval/How Far Are We? 가 정량적으로 보여줍니다. 그 전에, 두 갈래의 접근법을 먼저 봅니다.
4. Graph-based RCA 심화 — MicroRCA
4.1 비유 — 평면도를 든 설비 기사
천장에서 물이 떨어진다.
설비 기사는 건물 평면도(SDG)를 펴고, 물자국이 번진 흔적을 따라 배관도를 거슬러 올라간다.
가장 위쪽에서 누수 지점이 발견된다.MicroRCA는 정확히 이 일을 service graph 위에서 합니다. 단, 평면도가 틀리면 엉뚱한 방을 뜯게 됩니다(§3.5).
4.2 입력과 알고리즘
MicroRCA (Wu, Tordsson, Elmroth, Kao, NOMS 2020)는 attributed graph + Personalized PageRank로 root cause localization을 풉니다. 핵심은 두 가지.
- Attributed graph = 서비스 노드 + 호스트 노드를 한 그래프에 함께 두고, 각 노드에 anomaly score를 attribute로 붙임.
- Personalized PageRank (PPR) = anomaly score를 personalization vector로 두고 그래프 전체에서 propagation을 시뮬레이션 → 후보 노드 ranking. 구조적으로는 personalization vector를 갖는 random walk — 균등하게 방황하는 대신 anomaly가 큰 노드로 더 자주 되돌아가는 random walk가 만드는 정상분포가 곧 root cause ranking입니다.
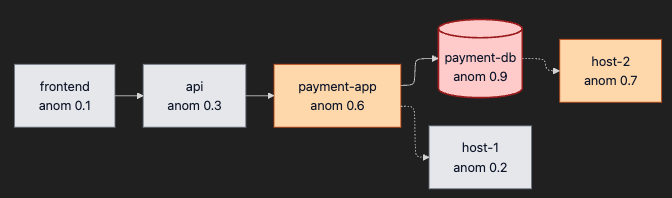
빨간 노드(payment-db)가 가장 높은 anomaly score를 받았고, PPR이 그 점수를 그래프 위에서 propagation시키면 payment-db가 top-1 후보로 올라옵니다. 점선 화살표(서비스 → 호스트)는 자원 사용 관계를 표현해, 호스트 자원 이상도 root cause 후보로 함께 들어옵니다.
논문 발표 성능: 89% precision, 97% MAP (microservice benchmark + Kubernetes에 fault injection 한 환경).
4.3 가정과 한계
여기서 89%가 production에서도 89%인가? 가 핵심 질문입니다. MicroRCA의 가정을 정리하면 한계가 보입니다.
| 가정 | 현실 | 가정이 깨질 때 |
|---|---|---|
| SDG가 정확하다 | stale topology 흔함 (4주차 §7) | PPR이 엉뚱한 노드로 propagation |
| anomaly score가 의미 있다 | low-traffic 노드는 신호 빈약 | 영향 큰 노드도 score 낮게 나옴 |
| anomaly가 그래프 따라 전파한다 | 비동기 큐·캐시 우회 시 그래프와 신호가 어긋남 | 후보가 선후 관계와 무관하게 ranking |
| Performance issue가 주 대상 | 배포·설정·보안 이슈는 다른 신호 필요 | configmap·deploy 이력 없으면 cause 안 보임 |
마지막 행이 5주차 토론 질문(§9)의 핵심입니다. MicroRCA만으로는 ConfigMap 오기재를 root cause로 지목하지 못합니다. 변경 이력이 그래프에 들어가야 비로소 보입니다.
5. Causal Discovery 기반 RCA — AERCA
5.1 비유 — 지도 없는 도미노 분석가
경기 영상을 본다. 도미노가 줄지어 쓰러진다.
지도(서비스 토폴로지)는 없다. 단, 각 도미노가 흔들리는 시간과 강도는 기록돼 있다.
누가 첫 도미노를 밀었는가?이게 causal discovery 기반 RCA의 정신입니다. 그래프를 주어진 입력으로 받지 않고, 시계열로부터 인과 구조를 학습해서 root cause를 찾습니다.
5.2 Granger causality / PC algorithm 직관 (수식 최소)
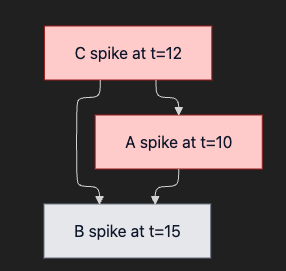
Granger Causality: "A가 울고 나면 항상 B가 운다 → A가 B를 울게 한 것 같다."
엄밀히는 통계적 선행성입니다. A가 B를 원인적으로 일으켰다는 보장은 없습니다. 둘 다 같은 다른 원인(C, lurking variable)에서 나왔을 수도 있기 때문입니다. 위 그림에서 C가 진짜 원인이지만 Granger만으로는 A↔B만 보일 수 있습니다.
PC Algorithm: "용의자 명단에서 서로 무관한 쌍을 하나씩 지워가며 인과 구조를 줄여나가는 형사."
조건부 독립성 검정(conditional independence test)을 반복 적용해 가능한 인과 그래프 후보를 좁힙니다. 결과는 유일한 그래프가 아니라 동치류(Markov equivalence class)일 때가 많아, 추가 가정이 필요합니다.
5.3 AERCA — ICLR 2025 Oral
AERCA (Han, Absar, Zhang, Yuan, ICLR 2025 Oral)는 정식 제목이 "Root Cause Analysis of Anomalies in Multivariate Time Series through Granger Causal Discovery" 입니다. microservice 특화가 아니라 multivariate time-series RCA라는 점을 분명히 해야 합니다 — microservice에 적용할 수 있는 후보일 뿐, 처음부터 그것을 위해 설계된 것이 아닙니다(이 표현이 PLAN의 P0 가드레일입니다).
핵심 가정 한 줄.
"이상(anomaly)은 외생변수(exogenous variable)에 가해진 intervention이다."
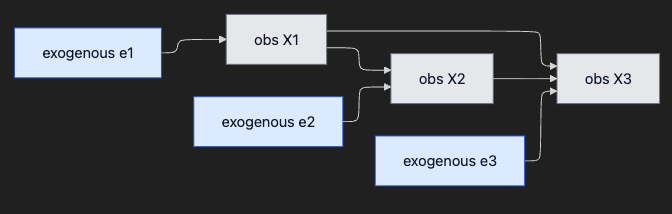
AERCA는 (1) 시계열들 사이의 Granger 인과 구조를 학습하고, (2) 정상 상태에서 외생변수의 분포를 모델링한 뒤, (3) 이상 시점에 외생변수가 정상 분포에서 얼마나 벗어났는지로 root cause를 식별합니다. 이는 사실상 counterfactual question을 묻는 것입니다: "만약 e₂가 정상 분포 안에 있었다면, X₃의 이상이 일어났을까?"
코드는 hanxiao0607/AERCA에서 공개되어 있으니 재현이 가능합니다.
5.4 Counterfactual reasoning 한 줄 정리
"만약 그 식당에 안 갔다면, 식중독이 났을까?"이게 RCA의 궁극적 질문 형태입니다. 그러나 실 시스템에서는 검증 불가능합니다 — 이미 일어난 incident를 되돌릴 수 없으니까요. 대신:
- Simulation: chaos engineering으로 비슷한 fault를 다시 주입해 본다.
- Shadow traffic: 변경 전 설정으로 traffic의 일부를 흘려 비교한다.
- A/B replay: 사고 시점 데이터로 다른 설정을 replay 한다.
모두 근사입니다. AERCA가 출력한 confidence는 이 근사가 얼마나 그럴듯한지의 점수입니다.
6. 두 접근의 가정 비교 — Graph vs Causal Discovery

표 형태로 한 번 더.
| 차원 | Graph-based (MicroRCA) | Causal Discovery (AERCA) |
|---|---|---|
| 입력 | SDG (사전 주어짐) + 노드 메트릭 | 시계열 행렬만 |
| 가정 | 토폴로지가 현재 상태를 정확히 반영 | 이상은 외생변수에 가해진 intervention |
| 출력 | 그래프 위 노드 ranking (PPR score) | 외생변수의 정상 분포 이탈 ranking |
| 강한 상황 | performance issue가 그래프 따라 전파 | 토폴로지가 부정확/없는 환경 |
| 약한 상황 | 비동기·캐시·외부 의존 우회 | 학습 데이터가 분포를 못 덮음 |
| 평가 데이터 | K8s 벤치마크 + fault injection | synthetic + real MTS 데이터 |
핵심은 둘 중 하나가 더 좋다는 게 아닙니다. 다른 가정 위의 다른 trade-off입니다.
| 환경 | 1차 추천 | 보조 |
|---|---|---|
| 계측 성숙한 K8s + tracing | MicroRCA류 (SDG가 신뢰 가능) | AERCA류 (cross-check) |
| 토폴로지가 자주 바뀌는 서버리스 | AERCA류 | MicroRCA류 (가능한 곳만) |
| 멀티클라우드·이종 인프라 | AERCA + 변경 이력 결합 | MicroRCA를 부분 그래프에 |
| Greenfield 신규 서비스 | (cold start) 운영자 + 단순 휴리스틱 | 둘 다 데이터 모일 때까지 보조 |
마지막 행에 주의: 두 접근 모두 cold start에서는 제 역할을 못 합니다(§3.2).
7. 벤치마크가 보여주는 격차 — RCAEval & "How Far Are We?"
7.1 RCAEval — 9 datasets / 735 cases / 11 fault types
RCAEval (Pham et al., FSE'26 / WWW'25 / ASE'24)은 microservice RCA 분야의 벤치마크 표준화 시도입니다. 구성을 정리하면 다음과 같습니다.
| 벤치마크 슈트 | failure cases | 데이터 | fault type |
|---|---|---|---|
| RE1 | 375 | metric-only | CPU, MEM, DISK, DELAY, LOSS (5종) |
| RE2 | 270 | metric + log + trace (multi-source) | RE1 + SOCKET (6종) |
| RE3 | 90 | multi-source, 코드 레벨 fault | F1~F5 (5종) |
| 합계 | 735 | — | 11 fault types |
각 슈트는 3개 시스템 위에서 돌립니다 — Online Boutique, Sock Shop, Train Ticket. 즉 3 슈트 × 3 시스템 = 9 datasets, 합쳐서 735 failure cases입니다(PROMPT의 "9 datasets / 735 failure cases" 표현이 정확합니다).
또한 RCAEval은 15개의 reproducible baseline을 함께 제공합니다 — metric-based, trace-based, multi-source RCA 방법들입니다.
7.2 평가 지표 — Top-k Accuracy / MAR
| 지표 | 정의 | 직관 |
|---|---|---|
| AC@k (Top-k Accuracy) | top-k 후보 중 정답이 포함된 case 비율 | "1순위 빗나가도 5순위 안엔 들어가나?" |
| Avg@k | k=1..K의 AC@k 평균 | "전 k 구간 평균 적중률" |
| MAR (Mean Average Rank) | 정답 root cause의 평균 순위 | 작을수록 좋음 |
| MFR (Mean First Rank) | 첫 번째로 정답을 맞춘 순위의 평균 | MAR과 비슷하나 정의 미묘하게 다름 |
용어 함정 주의: 논문마다 같은 약어를 다르게 정의합니다. RCAEval/MicroRCA/AERCA를 비교할 때는 "이 논문에서의 정의" 를 매번 확인해야 합니다. 이 글에서 인용하는 모든 수치는 해당 논문의 정의 그대로입니다.
7.3 논문 성능과 운영 성능의 gap 3가지
"How Far Are We from RCA for Microservice Systems?" (Pham, Ha, Zhang, ASE 2024)는 9개의 causal discovery 방법과 21개의 RCA 방법을 RCAEval 위에서 평가합니다. 결론은 한 줄로 요약됩니다.
"각 방법은 효과성·효율성·파라미터 민감도 중 하나 이상에서 약점을 보였다. 어떤 방법도 보편적으로 우수하지 않았다."
즉 "이 방법 하나만 쓰면 된다" 는 답은 없습니다. 그리고 더 중요한 것은, synthetic 데이터셋의 성능이 real system의 성능을 그대로 보여주지 않습니다.
gap의 원천은 세 갈래입니다.
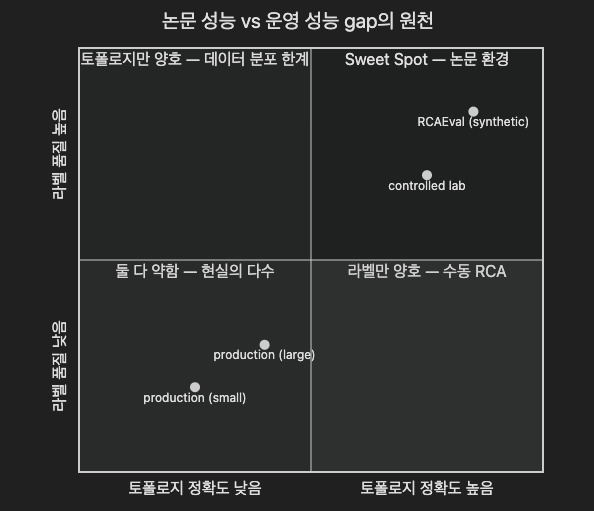
1. 데이터 분포의 차이 (fault injection ≠ production fault)
벤치마크는 인위적으로 주입한 fault를 학습/평가합니다. 실제 production fault는 분포가 다릅니다 — 더 길고, 더 복합적이며, 사람의 상호작용이 끼어듭니다(잘못된 롤백, 부분 복구 등).
2. 토폴로지 정확도
벤치마크의 SDG는 정확합니다. 운영 환경의 SDG는 stale입니다(4주차 §7). 정확도 50%의 SDG 위에서 PPR을 돌리면 후보 ranking이 자명하게 흔들립니다.
3. 라벨 품질
벤치마크는 fault injection으로 정답이 명확합니다. 운영 환경의 incident "진짜 원인"은 운영자의 사후 조사로만 정해지고, 그 라벨에는 §3.4의 모든 편향이 들어갑니다.
핵심 메시지: 벤치마크 수치를 production 기대치로 등치하지 마세요. 벤치마크에서 90% 가 운영에서 90% 를 의미하지 않습니다.
비교 대상으로 한 번 더 짚으면 — 4주차에서 인용한 OpenRCA(LLM 기반 RCA, ICLR 2025) 의 해결률은 11.34% 였습니다. 도구가 발전하고 있지만, "AI가 원인을 자동으로 짚는다" 는 마케팅 단정과는 거리가 큽니다.
8. Kubernetes 맥락 — RCA 신호의 재배치
5주차의 토론 질문은 K8s 환경에서 일어납니다. K8s가 제공하는 RCA 신호들을 유형별로 정리합니다.
8.1 Kubernetes Events — OOMKilled / CrashLoopBackOff
$ kubectl get events -n payments --sort-by=.lastTimestamp
LAST SEEN TYPE REASON MESSAGE
2m Normal ScalingReplicaSet Scaled up replica set payment-app-7f9c
2m Normal SuccessfulCreate Created pod: payment-app-7f9c-x4kp2
1m Warning Unhealthy Readiness probe failed: HTTP 503
30s Warning BackOff Back-off restarting failed container| 이벤트 | RCA에서의 역할 |
|---|---|
| OOMKilled | 컨테이너 자원 부족 → 직접 cause 후보 (메모리 누수·heap 폭주) |
| CrashLoopBackOff | 시작 직후 실패 반복 → 설정·의존성 cause 후보 |
| Unhealthy (probe fail) | 의존성 또는 자체 문제 → impacted 또는 causal 분리 필요 |
| ScalingReplicaSet | 변경 시점 마커 — 그 자체로 원인은 아니지만 시간 매칭에 결정적 |
| BackOff | 동일 실패의 재반복 표시 → noise 가중 |
가드레일: latency spike만 보고 있으면 OOM과 pool exhaustion이 헷갈립니다. OOM은 컨테이너가 죽고, pool exhaustion은 컨테이너가 안 죽고 hang 합니다. 이번 토론 질문은 후자입니다.
8.2 Deployment rollout 이력 / ConfigMap·Secret 변경 추적
$ kubectl rollout history deployment/payment-app -n payments
REVISION CHANGE-CAUSE
1 Initial deployment
2 kubectl set image deployment/payment-app app=payment:v1.2.0
3 kubectl set image deployment/payment-app app=payment:v1.2.1
4 kubectl apply -f payment-app-cfg.yaml ← 11:42, 사고 시점 직전!
$ kubectl get configmap payment-config -n payments -o yaml
data:
db.pool.max: "5" ← 50에서 5로 바뀌었다 (변경 이력 git에서 확인)여기가 이번 토론 질문의 결정적 단서가 들어오는 자리입니다. ConfigMap diff와 deploy event 시점이 결합되면, MicroRCA가 출력한 top-k 후보 위에 변경의 의미 자체 가 추가 layer로 얹힙니다.
Secret도 같은 추적 경로가 필요합니다 — 다만 값이 노출되지 않으므로 resourceVersion·annotation·sealed-secret 해시 등 메타데이터 diff 로 변경을 감지합니다.
$ kubectl get secret payment-db-credentials -n payments \\
-o jsonpath='{.metadata.resourceVersion}{"\\t"}{.metadata.annotations.kubectl\\.kubernetes\\.io/last-applied-configuration}'
84321 ← 사고 직전 rotation, last-applied 해시 변경DB password rotation으로 connection이 일제히 재인증되면서 pool이 초기화되는 패턴은 같은 시나리오의 자매 케이스로, ConfigMap diff와 동일한 "변경 시점 × 변경 내용" 결합으로 풀립니다.
8.3 OpenTelemetry trace 기반 span-level RCA
OpenTelemetry Service Graph Connector(4주차 §6)는 trace로부터 service graph를 만듭니다. 5주차에서는 그 trace 자체에서 더 깊은 신호를 뽑습니다.
trace_id: abc-123
span: GET /pay (payment-app, 4.2s) ← 증상 발생 지점
span: db.query SELECT ... (payment-db, 4.0s)
attribute: db.wait = 3.9s ← 결정적 신호: pool에서 대기
attribute: db.statement = SELECT ...
attribute: db.connection.acquired = falsedb.wait 가 3.9초라는 사실은 latency가 DB 대기에서 발생함을 입증합니다. 그러나 왜 대기하는지 는 trace만으로 안 보입니다 — pool size 자체를 봐야 합니다.
8.4 가드레일 — ConfigMap propagation의 eventual consistency
자주 빠지는 함정: "ConfigMap을 11:42에 변경했고 alert가 11:45에 떴으니 ConfigMap이 원인이다."
이게 늘 맞지 않습니다. ConfigMap은 즉시 적용되지 않습니다.
| 주입 방식 | 갱신 시점 |
|---|---|
| Volume mount | kubelet sync 주기 의존 (기본 ~1분), 컨테이너 재시작 불필요 |
| subPath mount | 갱신 안 됨, 재시작 필요 |
| env from configMapKeyRef | 컨테이너 재시작 전 미반영 |
| Helm/ArgoCD가 함께 배포 | rollout이 트리거되면 새 pod에서 비로소 새 값 |
따라서 "ConfigMap diff가 있다" 와 "그 변경이 사고 시점에 실제로 적용됐다" 는 별개로 검증해야 합니다. RCA 엔진이 이 차이를 모르면 시간만 맞으면 ConfigMap을 원인으로 단정하는 오류를 냅니다.
9. 토론 질문 풀이 — 새 배포 → DB pool 오류 → latency 급증
질문(요약): "K8s 새 버전 배포 → DB connection pool 설정 오류 → API latency 급증" 시나리오에서, latency라는 증상으로부터 pool 설정이라는 원인까지 도달하기 위해 어떤 신호와 어떤 토폴로지가 필요한가. 어느 신호가 결정적 단서인가.
9.1 5단계 신호 결합 골격
1) 증상 확인 : alert(latency P99 > 2s on /pay)
2) 영향 범위 묶기 : (4주차 결과 재사용) checkout-web → payment-app → payment-db
3) 후보 노드 ranking : MicroRCA / Granger 류 (causal discovery·AERCA류 포함) 점수 → payment-app, payment-db 상위
4) 결정적 단서 식별 : 변경 시점 × 변경 내용 × 직접 증거의 시간순 결합
5) 검증·롤백 : kubectl rollout undo / shadow traffic / canary9.2 신호별 평가표 — 결정적 단서는 무엇인가
| 신호 | 정보량 | 한계 | 결정적 단서 가능성 |
|---|---|---|---|
latency P99 metric | 증상의 시작 시점·영향 노드 | 무엇이 원인인지는 불명 | 낮음 (증상) |
error log: pool exhausted | 직접적 원인 어휘 | 노이즈에 묻힐 수 있음 | 중–높음 |
K8s event: deployment rolled | 변경 발생 시점 | 어떤 변경인지는 불명 | 높음 (시점 매칭용) |
ConfigMap diff: db.pool.max 50→5 | 변경의 의미 자체 | 즉시 적용 여부 별도 확인 | 결정적 |
trace span: db.wait p99 ↑ | latency가 DB 대기에서 발생함을 입증 | trace coverage 의존 | 높음 |
metric: connections.in_use vs max | pool 포화 상태 직접 관측 | 노출 안 돼 있을 수 있음 | 결정적 (직접 증거) |
OOMKilled / CrashLoopBackOff | 컨테이너 죽음 | pool 고갈 시나리오에서는 발생 안 함 | 부수 신호 |
핵심: 결정적 단서는 단일 신호가 아니라 세 신호의 시간순 결합입니다.
deploy event(11:42) × ConfigMap diff(db.pool.max 50→5) × pool in_use=max & db.wait↑(11:43~)
↓
smoking gun각각 따로는 이렇게 됩니다.
- deploy event만 있으면: "뭔가 바뀌었다"만 알지 그게 무엇인지 모름.
- ConfigMap diff만 있으면: "이 값이 바뀌었다"만 알지 사고 시점에 적용됐는지 모름(§8.4).
- pool 직접 증거만 있으면: pool이 고갈됐다는 사실은 알지만 왜 인지 모름.
세 신호를 하나의 다이어그램으로 합성하면 운영자가 즉시 root cause를 압축할 수 있습니다.
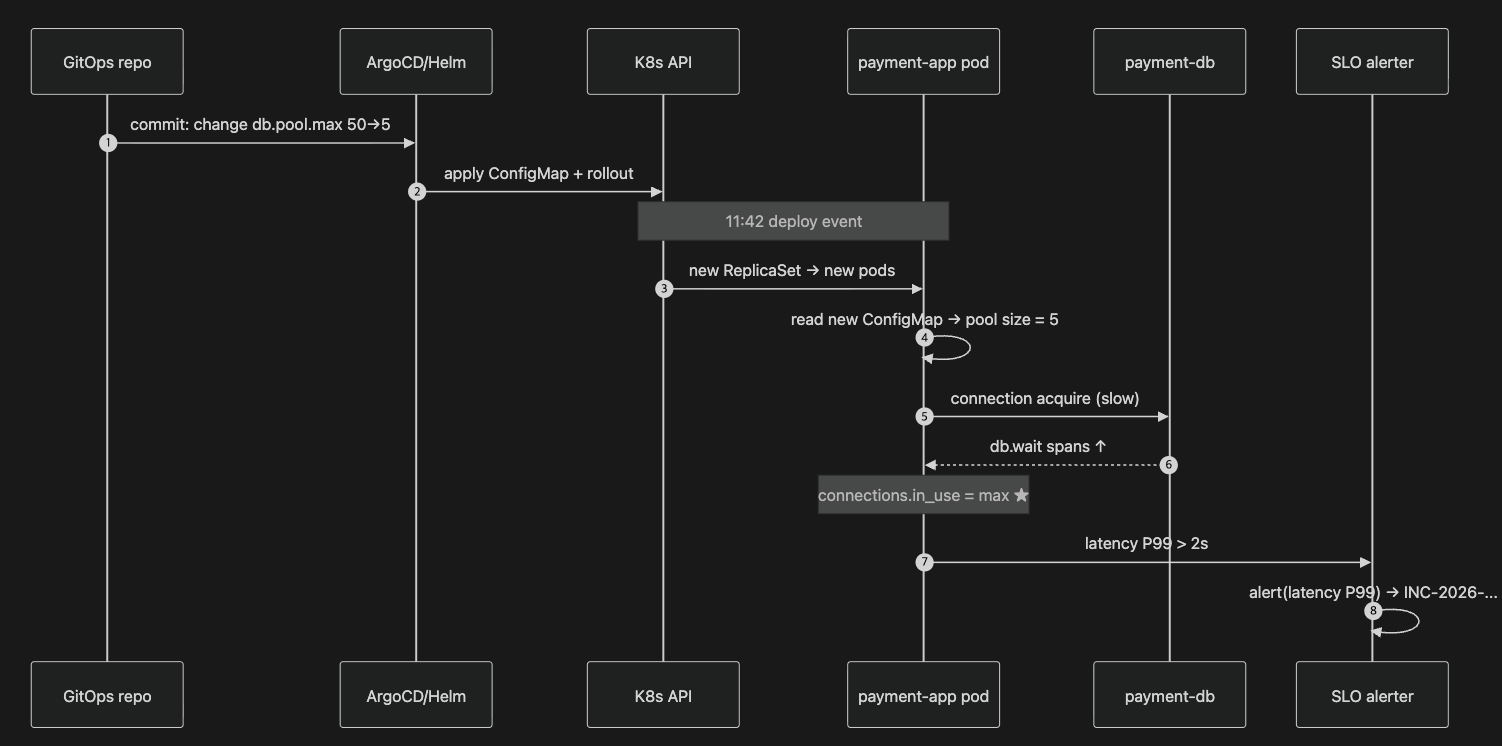
★ 표시한 시점이 결정적 단서가 직접 관측된 순간입니다. 그 위로 deploy event(시점)와 ConfigMap diff(내용)가 결합되면, 후보가 root cause로 압축됩니다.
9.3 토폴로지 — 세 층의 합성
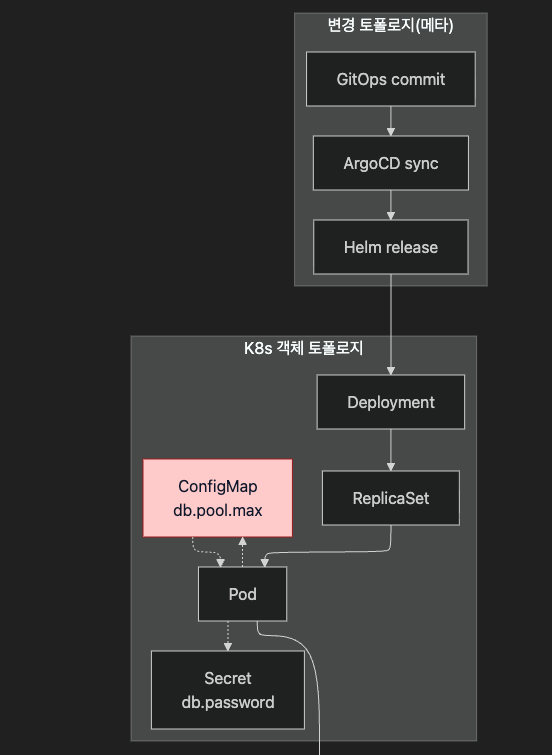
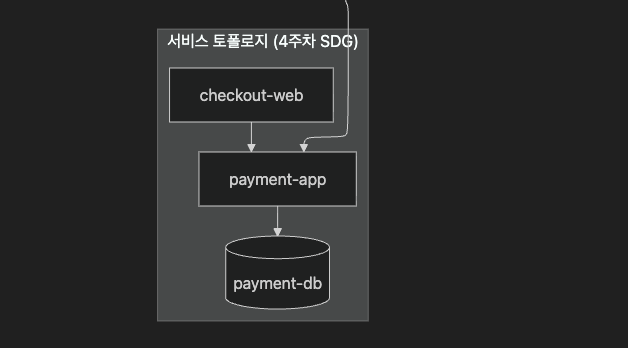
세 층이 모두 RCA 엔진에 들어와야 합니다. 어느 한 층이 빠지면 결정적 단서가 사라집니다.
| 토폴로지 빠뜨림 | 잃는 단서 |
|---|---|
| 서비스 토폴로지만 보면 | 변경의 시점·내용 안 보임 |
| K8s 객체 토폴로지만 보면 | 누가 왜 바꿨는지 안 보임 |
| 변경 토폴로지만 보면 | 변경이 어떤 노드에 영향 가는지 안 보임 |
9.4 강조할 단서 vs 깎을 단서
| 분류 | 신호 |
|---|---|
| 강조 (스모킹 건 4종 결합) | ConfigMap diff · deploy event 시점 · pool metric · db.wait span |
| 깎기 (이 시나리오에서는 부수) | latency spike 자체 · OOMKilled / CrashLoopBackOff · 일반 CPU/메모리 alert |
이 구분을 본문에서 정직하게 보여주는 것이 RCA 글의 신뢰도 자체입니다 — 운영자가 처음 보는 것은 항상 latency·error spike지만, 그 신호 자체는 root cause가 아닙니다.
10. 마무리 — RCA는 자동화가 아니라 "조사 순서 추천"이다
이번 글의 한 문장 요약입니다.
이 글은 RCA를 자동 정답기가 아니라 후보 압축기 로 정직하게 그렸다. MicroRCA(토폴로지 위 anomaly propagation)와 AERCA(시계열 인과 발견)는 다른 가정 위의 다른 trade-off이며, RCAEval이 보여주는 gap의 원천(데이터 분포 / 토폴로지 정확도 / 라벨 품질)은 운영에서 더 크게 벌어진다.
자동화의 목표는 "운영자를 빼는 것" 이 아니라 "운영자가 짧은 시간에 옳은 곳을 보게 만드는 것" 입니다. 그래서 RCA의 운영 모델은 항상 Human-in-the-loop입니다.

피드백 노드(노란 박스)가 빠지면 모델은 첫날 그 자리에 영원히 머무릅니다(§3.3).
10.1 운영 안티패턴 4가지
이 글에서 반복해서 등장한 위험을 한 번에 정리합니다.
- Confidence score 자동 처리 — top-1을 자동으로 incident root cause 라벨로 박는 것. cold start와 결합되면 잘못된 학습 신호로 누적됨.
- Feedback loop 미설계 — 운영자가 "맞았다 / 틀렸다"를 한 클릭으로 기록할 UI가 없음. 모델은 학습할 수 없음.
- Topology-only 의존 — SDG 정확도가 RCA 정확도의 천장. 4주차 §7 stale topology의 해악이 5주차에서 더 커짐.
- 벤치마크 수치를 production 기대치로 오해 — 논문 90% ≠ 운영 90%. RCAEval/How Far Are We?의 메시지를 한 번 더.
10.2 RCA 도구 지형도 (참고)
직접 실행은 본문 분량을 늘리니 링크와 한 줄 코멘트만.
| 도구 | 분류 | 한 줄 |
|---|---|---|
| MicroRCA | Graph-based RCA | NOMS 2020 원논문의 참조 구현 |
| AERCA | Causal Discovery | ICLR 2025 Oral 공식 코드 |
| RCAEval | Benchmark | 9 datasets / 735 cases / 15 baselines |
| PyRCA (Salesforce) | OSS 라이브러리 | 다양한 RCA 알고리즘 통합 인터페이스 |
| Eadro | Multi-modal RCA | log + trace + metric을 함께 |
| CausalRCA | Causal RCA | Causal structure learning 기반 |
| Sage (MSR) | Vendor 연구 | Microsoft Research RCA 연구 |
| Pixie | Observability + RCA | eBPF 기반 K8s 자동 계측 |
벤더 솔루션(Datadog Watchdog, Dynatrace Davis, New Relic AI, ServiceNow Predictive AIOps)은 인용 시 "벤더가 주장하는 바" 라벨을 붙입니다. 마케팅 페이지를 1차 단정의 근거로 쓰지 않는 것이 이 글의 원칙입니다.
10.3 5주차 핵심 질문과 답
| 질문 | 답 |
|---|---|
| RCA의 출력은 무엇인가? | 단일 cause가 아니라 probable cause + confidence의 후보 리스트 |
| Detection·Correlation과의 차이는? | 데이터 안에서 닫혀 풀리지 않음 — 토폴로지·인과·암묵지가 동원돼야 함 |
| RCA가 어려운 5가지 이유? | Probabilistic / Cold Start / Tribal Knowledge / Labeling Bottleneck / Topology Inaccuracy |
| MicroRCA의 핵심 알고리즘은? | attributed graph + Personalized PageRank |
| MicroRCA의 가장 큰 약점은? | stale topology가 그대로 wrong RC가 됨 |
| AERCA의 핵심 가정은? | 이상 = 외생변수에 가해진 intervention |
| AERCA는 microservice RCA인가? | 아님. multivariate time-series RCA. microservice는 적용 후보일 뿐 |
| Graph-based vs Causal Discovery 중 무엇이 우월한가? | 둘은 다른 가정 위의 다른 trade-off — 환경에 따라 다름 |
| RCAEval은 몇 개 데이터셋·몇 케이스인가? | 9 datasets (RE1/RE2/RE3 × 3 systems), 735 failure cases, 11 fault types |
| 논문 성능과 운영 성능의 gap 원천은? | 데이터 분포 · 토폴로지 정확도 · 라벨 품질 |
| 토론 시나리오의 결정적 단서는? | deploy event × ConfigMap diff × pool 직접 증거 의 시간순 결합 (단일 신호 아님) |
| ConfigMap 변경은 즉시 적용되나? | 아님 (volume mount는 kubelet sync 의존, env는 재시작 필요) |
| RCA 자동화의 현실적 목표는? | 운영자를 빼는 것이 아니라 운영자가 짧은 시간에 옳은 곳을 보게 만드는 것 |
10.4 토론 시나리오 심화
§10.3에서 한 줄로 답한 토론 시나리오를 풀어둔다. Codex / Gemini / Claude 세 LLM에 동일 컨텍스트로 독립 분석을 요청하고 교차검증한 결과를 기반으로 한다.
시나리오 정리
| 항목 | 내용 |
|---|---|
| 출발 증상 | API p95/p99 latency 급증 |
| 도달해야 할 원인 | DB connection pool 설정값 (예: pool_size 50 → 5) |
| 트리거 | K8s 새 버전 배포 + ConfigMap 변경 |
| 핵심 질문 | latency → pool 설정까지 도달하기 위해 어떤 신호·토폴로지가 필요한가, 그중 결정적 단서는? |
필요한 신호
| # | 신호 | 답하는 질문 | LLM 합의 |
|---|---|---|---|
| 1 | API latency metric (p95/p99) | 증상이 언제 시작됐는가? (분석 기준점 t₀) | 3/3 |
| 2 | Trace span (db.wait, connection_acquire) | latency가 어느 구간에서 발생하는가? | 3/3 |
| 3 | DB Pool metric (waiting, active, idle, acquire_timeout) | Pool이 실제로 포화·고갈됐는가? | 3/3 |
| 4 | Application log (HikariCP timeout 등) | App이 pool 부족을 인지했는가? | 2/3 |
| 5 | K8s Deployment / Rollout 이력 | 변경이 언제 적용됐는가? | 3/3 |
| 6 | ConfigMap diff (pool_size 등) | 무엇이 바뀌었는가? | 3/3 |
| 7 | K8s Pod Events (Ready 시각, Restart) | 변경이 실제로 Pod에 반영됐는가? | 3/3 |
필요한 토폴로지 (3계층, 만장일치 3/3)
| 계층 | 역할 |
|---|---|
| 서비스 토폴로지 (API → DB) | DB 신호를 API latency와 정당하게 연결 |
| K8s 객체 토폴로지 (Pod ↔ ConfigMap mount 방식) | 적용 시각 추정에 필수 |
| 변경 토폴로지 (배포 ↔ 변경 리소스) | 동시 변경과 구분, 인과 연결 |
한 계층이라도 빠지면 단서 사슬이 끊어진다.
결정적 단서: 시간순 3중 결합
[배포 rollout 시각]
↓
[Pod Ready / 컨테이너 재시작 시각] ← ConfigMap의 실질 적용 시각
↓
[db.wait span 급증 / Pool waiting↑] ← pool 획득 대기 메커니즘
↓
[API p99 latency 급증] ← 사용자 영향 (증상)| 신호 | 역할 | 한 마디 |
|---|---|---|
| ConfigMap diff | What | "pool_size 50 → 5로 변경됨" |
| Pod Ready / Rollout 시각 | When applied | 변경 시각 ≠ 적용 시각 가정의 오류 교정 |
Trace db.wait | Why | latency의 직접 원인이 pool 대기임을 인과적 증명 |
결정적이지 않은 단서
| 신호 단독 | 결정적이지 않은 이유 |
|---|---|
| API latency metric | 증상일 뿐. 네트워크·쿼리·GC·락 경합 등과 구별 불가 |
| Deployment 이력 | 시간 근접 = 상관관계, 인과관계 아님 |
db.wait 증가 | DB 슬로우쿼리·네트워크·pool 고갈 모두로 설명 가능 |
| Pool 포화 metric | pool_size 축소 vs 트래픽 증가 구별 불가 |
| DB CPU/Memory | Pool 설정 오류는 클라이언트 측 대기로 발현 → DB 엔진 지표는 정상 |
ConfigMap diff 단독이 부족한 이유
| 함정 | 설명 |
|---|---|
| Volume mount 방식 | kubelet sync 주기 의존(~1분 지연) → 변경 시각 ≠ 적용 시각 |
| env var 방식 | 컨테이너 재시작 없이는 미적용 |
| 인과 방향 미증명 | "pool_size가 줄었지만 충분했을 수도" 반론을 db.wait 없이 배제 불가 |
| 동시 변경 간섭 | 같은 배포의 다른 ConfigMap 키가 진짜 원인일 가능성 |
→ ConfigMap diff는 후보 생성용 단서. 결정은 Pod Ready + db.wait + Pool waiting의 결합으로 내려야 한다.
10.5 참고자료
필독 4선
| 제목 | 종류 | 역할 | 링크 |
|---|---|---|---|
| MicroRCA: Root Cause Localization of Performance Issues in Microservices (Wu et al.) | 논문 NOMS 2020 | §4 graph-based RCA의 표준 reference | https://doi.org/10.1109/NOMS47738.2020.9110353 |
| Root Cause Analysis of Anomalies in Multivariate Time Series through Granger Causal Discovery (AERCA, Han et al.) | 논문 ICLR 2025 Oral | §5 causal discovery RCA의 최신 reference | https://openreview.net/forum?id=k38Th3x4d9 |
| RCAEval: A Benchmark for RCA of Microservice Systems with Telemetry Data (Pham et al.) | 논문 FSE'26/WWW'25/ASE'24 | §7.1 벤치마크 standard | https://arxiv.org/abs/2412.17015 |
| Root Cause Analysis for Microservice System based on Causal Inference: How Far Are We? (Pham, Ha, Zhang) | 논문 ASE 2024 | §7.3 논문↔운영 gap 학술 근거 | https://arxiv.org/abs/2408.13729 |
인접 자료
| 제목 | 종류 | 역할 | 링크 |
|---|---|---|---|
| OpenRCA (LLM 기반 RCA) | 논문 ICLR 2025 | §7.3 비교 — LLM은 11.34% | https://openreview.net/pdf?id=M4qNIzQYpd |
| Root Cause Analysis of Failures in Microservices through Causal Discovery | 논문 NeurIPS 2022 | causal discovery 분야 origin work | https://proceedings.neurips.cc/paper_files/paper/2022/file/c9fcd02e6445c7dfbad6986abee53d0d-Paper-Conference.pdf |
| Root Cause Analysis in Microservice Using Neural Granger Causal Discovery | 논문 2024 | AERCA의 인접 라인 | https://arxiv.org/abs/2402.01140 |
| Observability Engineering (Majors et al.) | 책 | Human-in-the-loop 정신 | O'Reilly/Honeycomb 2022 |
| Hands-on AIOps (Sabharwal & Bhardwaj) | 책 | Topology-aware RCA 운영 | Apress 2022 |
Kubernetes / OpenTelemetry 공식 문서
| 제목 | 링크 |
|---|---|
| Pod Lifecycle | https://kubernetes.io/docs/concepts/workloads/pods/pod-lifecycle/ |
| kubectl rollout history | https://kubernetes.io/docs/reference/kubectl/generated/kubectl_rollout/kubectl_rollout_history/ |
| Updating ConfigMap | https://kubernetes.io/docs/tutorials/configuration/updating-configuration-via-a-configmap/ |
| OTel Service Graph Connector | https://opentelemetry.io/docs/collector/components/connector/ |
OSS RCA 도구
MicroRCA · AERCA · RCAEval · PyRCA · Eadro · CausalRCA · Sage · Pixie. 본문 §11.2 표 참고.
11 분석 대상 오픈소스 추리기
추리는 기준
- AIOps 5단계 중 어느 단계를 다루는가
- 분석해서 얻을 수 있는 것 — 알고리즘, 인터페이스 설계, 데이터 모델, 운영화 패턴 중 무엇인가
- 분석 시 어디를 먼저 봐야 하는가 (코드 / 문서 / 논문)
분석 대상
| OSS | 다루는 단계 | 분석해서 얻을 것 | 분석 시 볼 부분 | 한계·주의 | GitHub |
|---|---|---|---|---|---|
| Coroot | Ingestion + Topology + Correlation + Pattern Recognition (RCA) + 일부 Remediation 후보 | eBPF 기반 telemetry 수집부터 서비스 맵, SLO, predefined inspections, RCA까지 한 제품 안에 묶은 OSS. K8s/MSA RCA 중심 AIOps에 가장 가까운 단일 도구 | predefined inspections 카탈로그(DB pool · CPU throttling · OOM · Network packet loss 등), 서비스 맵 자동 생성 로직, SLO 이상치 highlight 흐름 | Observability/APM + RCA 성격이며 "AIOps 전체"는 아님. 본체는 Apache-2.0, node-agent의 BPF code는 GPL-2.0 포함 | coroot/coroot · coroot-node-agent · coroot-cluster-agent |
| PyRCA | Pattern Recognition (RCA) | MicroRCA, Bayesian Network, causal discovery, graph-based scoring 등 여러 metric-based RCA 알고리즘을 단일 인터페이스로 다루는 라이브러리. 알고리즘 학습용 실험실 성격 | pyrca/analyzers/ 하위 알고리즘별 구현, SDG(서비스 의존성 그래프) 입력 포맷, 점수 산출 방식 | 라이브러리이며 운영화·수집 평면은 별도. SDG 품질에 결과가 종속. BSD-3-Clause | salesforce/PyRCA |
| Pixie | Ingestion + Topology | eBPF로 코드 변경 없이 K8s L7 트래픽·DB 호출·서비스 맵을 런타임에 자동 추출하는 데이터 평면. 정적 토폴로지보다 최신성 유지가 쉬움 | PEM(Edge) / Vizier(Control plane) / Cloud 3계층 설계, PxL DSL, 보존 정책 | 커널 5.8+ 의존, 클러스터 리소스·운영 컴포넌트 필요. AIOps 도구가 아닌 ingestion/topology 계층. Apache-2.0 (CNCF Sandbox) | pixie-io/pixie |
| Keep | Correlation + 일부 Remediation 자동화 | 여러 모니터링 도구의 알람을 한곳에 모아 correlation·중복제거·라우팅·자동화하는 alert management 플랫폼. AI 기반 alert correlation / incident candidate 제안 기능 포함 | alert grouping·enrichment 로직, YAML 기반 workflow 엔진, AI correlation 모듈 | 운영 컴포넌트 다수, AGPL-3.0 라이선스 검토 필요 | keephq/keep |
| Robusta | Correlation + Remediation | K8s 이벤트와 Prometheus alert를 받아 context 수집, 알림 enrich, playbook action, remediation job으로 연결하는 이벤트 기반 자동화 프레임워크 | playbook 정의 방식, K8s 이벤트 → 액션 매핑, alert enrichment 흐름 | 본체 기준 MIT, 조직 내 다른 리포는 Apache-2.0 혼재 | robusta-dev/robusta |
정리
분석을 해보고 싶은 오픈소스는 Coroot 1순위, Robusta 2순위 두가지 입니다.
분석을 기본 전제로 하되. 벤치마킹해서 개발하는 것을 목표로 삼고 있습니다.
